基于机器视觉的唇语识别算法设计与系统开发
SRTP:AICLD 全自动增量建库(约 140 万样本、5000+ 说话人),唇读模型与训练,产出 IEEE TIP 等多篇 Q1 论文及发明专利、软著等知识产权。
福州大学 电气工程与自动化学院
2024年5月——至今
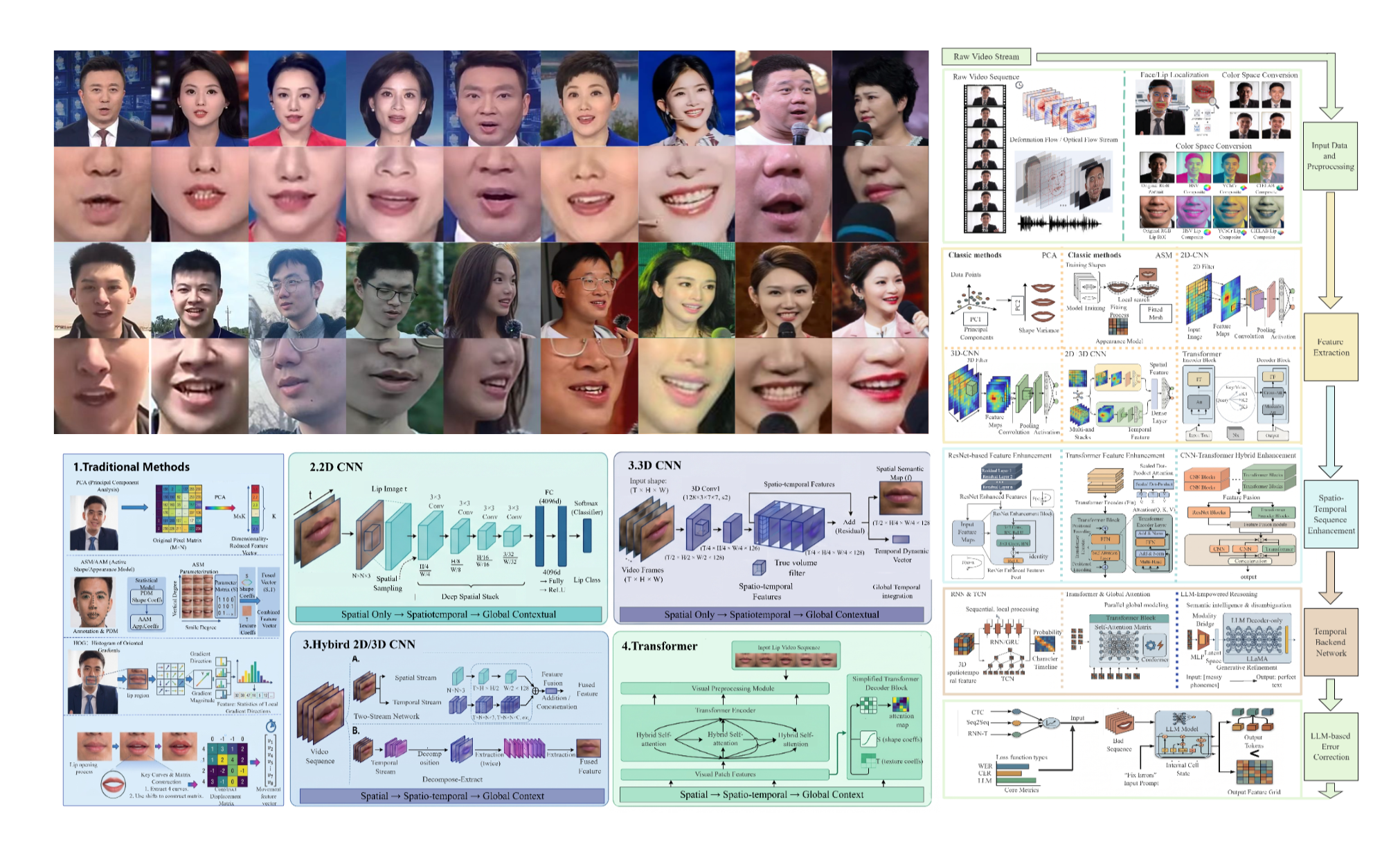
项目背景
随着人工智能、计算机视觉与自然语言处理技术的深度融合,唇语识别作为不依赖音频信号的沟通方式,在多领域展现出广阔应用前景且具有重要研究与应用价值,但中文唇语识别领域面临底层数据基建(数据集规模有限、依赖人工标注等)与顶层算法架构(低资源场景泛化差、时序建模不足等)的双重瓶颈,且缺乏对技术演进脉络的系统梳理,本次SRTP(大学生创新训练项目)聚焦数据基建与算法优化两大核心,旨在构建自动化可扩展中文唇语数据集、革新低资源算法架构并梳理技术演进规律,填补领域空白、提供技术支撑。
- 针对中文唇语数据集人工标注成本高、音画同步难与扩容慢的痛点,构建分布式 AI 辅助增量采集管线:FFmpeg 标准化预处理结合镜头边界检测与 SyncNet 音画对齐,集成 Aeneas/MFA 句子—单词分级强制对齐,采用 MTCNN+KCF 双重验证与 ResNet-18 身份聚类完成唇区 ROI 提取。基于此建成目前规模最大的 AICLD 语料(1,400,000+ 样本、5,238 名说话人、110+ 小时,日增 3,000+),支撑 TIP 数据集论文与发明专利。
- 针对仅有视频数据难以分层实验、入库易出现统计口径漂移的问题,定义统一元数据 schema(姿态角、关键帧、可靠性等)并建立抽检与一致性校验机制;在 AICLD 上构建涵盖规模梯度、预处理对比、时间分辨率敏感性及关键帧采样的多维实验矩阵,通过系统消融量化数据增益并确立最优处理范式,保障公开指标可核对与实验可复现。
- 主导 AICLD 唇语识别数据库平台架构设计与全栈开发,基于 Streamlit 构建集数据索引、版本控制及任务管理于一体的 Web 门户,落地云端全自动增量采集管线及标注/质检工作流与实时监控,编写技术文档与数据请求协议,支撑日级语料更新与团队合规检索使用(软著)。
- 针对低资源唇读过拟合与泛化差距大的问题,基于 PyTorch 搭建 SimMIM 预训练、Swin V2 骨干与 GN 时序分支及分阶段课程学习训练管线,在 AICLD-500 上较 SwinLip 基线 Top-1 提升 1.91 个百分点,显著收窄训练—验证差距,支撑 TASLP 方法论文。
- 针对视觉语音识别文献按模型结构零散发表、缺少从预处理到解码贯通视角的问题,参与按五个技术时代组织代表性方法与典型架构,建立按粒度、采集环境、语言与模态划分的数据集分类学,并撰写开放问题与未来方向章节,形成可引用的系统性参考框架,支撑 ARC 综述论文。
项目产出
-
Structured Temporal Regularization and Curriculum Optimization for Visual Speech Recognition 面向视觉语音识别的结构化时序正则与课程优化
2026 · 审稿中 · IEEE Transactions on Audio, Speech, and Language Processing(JCR Q1, IF 5.2) · 审稿中
-
AICLD : AI-assisted Incremental Chinese Lip-reading Database AICLD:人工智能辅助增量式中文唇读数据库
2026 · 审稿中 · IEEE Transactions on Image Processing(JCR Q1, IF 15.3) · 审稿中
-
The Evolution of Visual Speech Recognition: From Deep Spatio-Temporal Modeling to LLM-Guided Reasoning 视觉语音识别演化:从深度时空建模到大模型引导推理
2026 · 审稿中 · International Journal of Computer Vision(JCR Q1, IF 10.3) · 审稿中
-
一种AI 辅助的大规模唇语识别数据集自动化构建方法
2026 · 中国发明专利 · 实质审核阶段
-
AICLD 人工智能辅助增量式中文唇语识别数据库平台
2026 · 计算机软件著作权登记 · 已登记
技术栈
Python, PyTorch, Swin Transformer, FFmpeg tooling