基於機器視覺的唇語辨識演算法設計與系統開發
SRTP:AICLD 全自動增量建庫(約 140 萬樣本、5000+ 說話人),唇讀模型與訓練,產出 IEEE TIP 等多篇 Q1 論文及發明專利、軟著等智慧財產權。
福州大學 電氣工程與自動化學院
2024年5月——至今
專案背景
隨著人工智慧、電腦視覺與自然語言處理技術之深度融合,唇語辨識作為不依賴音訊之溝通方式,於多領域展現廣闊應用前景並具重要研究與應用價值,惟中文唇語辨識領域面臨底層資料基建(資料集規模有限、依賴人工標註等)與頂層演算法架構(低資源場景泛化差、時序建模不足等)之雙重瓶頸,且缺乏對技術演進脈絡之系統梳理,本次 SRTP(大學生創新訓練專案)聚焦資料基建與演算法最佳化兩大核心,旨在建置自動化可擴展中文唇語資料集、革新低資源演算法架構並梳理技術演進規律,填補領域空白、提供技術支撐。
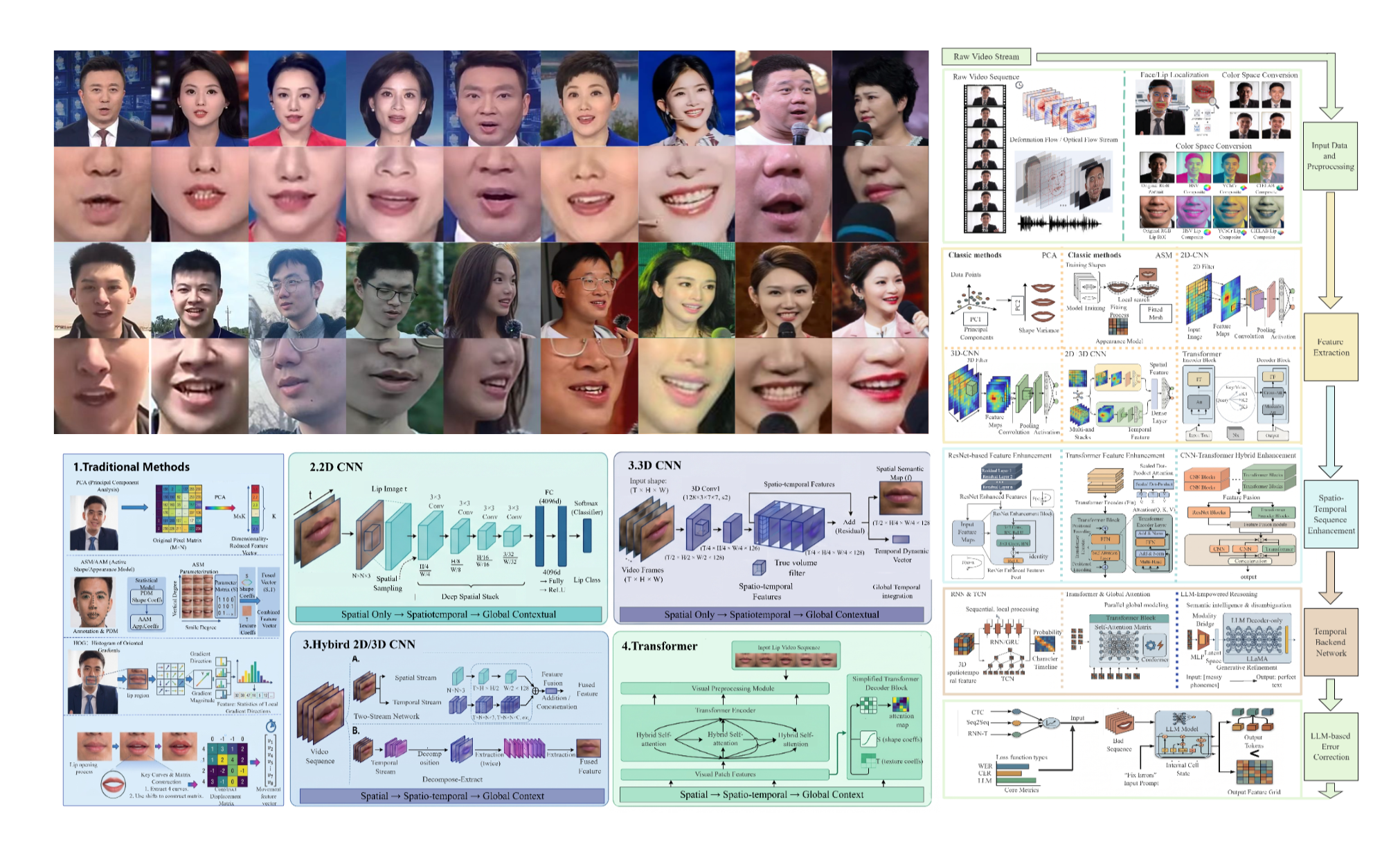
- 針對中文唇語資料集人工標註成本高、音畫同步難與擴容慢的痛點,建構分散式 AI 輔助增量採集管線:FFmpeg 標準化預處理結合鏡頭邊界偵測與 SyncNet 音畫對齊,整合 Aeneas/MFA 句子—單詞分級強制對齊,採用 MTCNN+KCF 雙重驗證與 ResNet-18 身份聚類完成唇區 ROI 擷取。基於此建成目前規模最大的 AICLD 語料(1,400,000+ 樣本、5,238 名說話人、110+ 小時,日增 3,000+),支撐 TIP 資料集論文與發明專利。
- 針對僅有影片資料難以分層實驗、入庫易出現統計口徑漂移的問題,定義統一元資料 schema(姿態角、關鍵影格、可靠性等)並建立抽檢與一致性校驗機制;於 AICLD 上建構涵蓋規模梯度、預處理對比、時間解析度敏感性及關鍵影格採樣之多維實驗矩陣,透過系統消融量化資料增益並確立最優處理範式,保障公開指標可核對與實驗可重現。
- 主導 AICLD 唇語識別資料庫平台架構設計與全端開發,基於 Streamlit 建構集資料索引、版本控制及任務管理於一體的 Web 入口,落地雲端全自動增量採集管線及標註/質檢工作流與即時監控,編寫技術文件與資料請求協定,支撐日級語料更新與團隊合規檢索使用(軟著)。
- 針對低資源唇讀過擬合與泛化差距大之問題,基於 PyTorch 建置 SimMIM 預訓練、Swin V2 骨干與 GN 時序分支及分階段課程學習訓練管線,於 AICLD-500 上較 SwinLip 基線 Top-1 提升 1.91 個百分點,顯著縮窄訓練—驗證差距,支撐 TASLP 方法論文。
- 針對視覺語音識別文獻按模型結構零散發表、缺少由前處理至解碼貫通視角之問題,參與按五個技術時代組織代表性方法與典型架構,建立按粒度、採集環境、語言與模態劃分之資料集分類學,並撰寫開放問題與未來方向章節,形成可引用之系統性參考框架,支撐 ARC 綜述論文。
專案產出
-
Structured Temporal Regularization and Curriculum Optimization for Visual Speech Recognition 面向視覺語音識別的結構化時序正則與課程優化
2026 · 審稿中 · IEEE Transactions on Audio, Speech, and Language Processing(JCR Q1, IF 5.2) · 審稿中
-
AICLD : AI-assisted Incremental Chinese Lip-reading Database AICLD:人工智慧輔助增量式中文唇讀資料庫
2026 · 審稿中 · IEEE Transactions on Image Processing(JCR Q1, IF 15.3) · 審稿中
-
The Evolution of Visual Speech Recognition: From Deep Spatio-Temporal Modeling to LLM-Guided Reasoning 視覺語音識別演化:從深度時空建模到大模型引導推理
2026 · 審稿中 · International Journal of Computer Vision(JCR Q1, IF 10.3) · 審稿中
-
一种AI 辅助的大规模唇语识别数据集自动化构建方法 一種 AI 輔助的大規模唇語識別資料集自動化構建方法
2026 · 中國發明專利 · 實質審核階段
-
AICLD 人工智能辅助增量式中文唇语识别数据库平台 AICLD 人工智慧輔助增量式中文唇語識別資料庫平台
2026 · 計算機軟體著作權登記 · 已登記
技術棧
Python, PyTorch, Swin Transformer, FFmpeg tooling