语义搜索神器:GTE-中文-通用领域-Base 模型三分钟部署与实战指南(附已部署镜像)
三分钟部署 thenlper/gte-base-zh:环境依赖、编码测试、余弦相似度语义检索示例,以及 FastAPI 向量化 API 与部署优化建议。
1. 简介
GTE (General Text Embedding) 是由阿里巴巴达摩院(现通义实验室)开发的文本向量化模型。在 C-MTEB(中文多任务文本嵌入基准)榜单上,GTE 系列模型一直名列前茅。
GTE-Base-ZH 的特点:
- 性能均衡:Base 版本在计算开销和召回效果之间取得了极佳平衡。
- 场景广泛:适用于搜索、推荐、QA 问答对齐、长文本聚类等 RAG(检索增强生成)场景。
- 部署友好:对显存要求低,普通消费级显卡甚至 CPU 都能流畅运行。
2. 环境准备
首先,确保你的 Python 环境在 3.8 及以上。如果是在云服务器上的话可以直接选择部署好Pytorch 2.9的镜像,就可以忽略这一步
pip install torch transformers
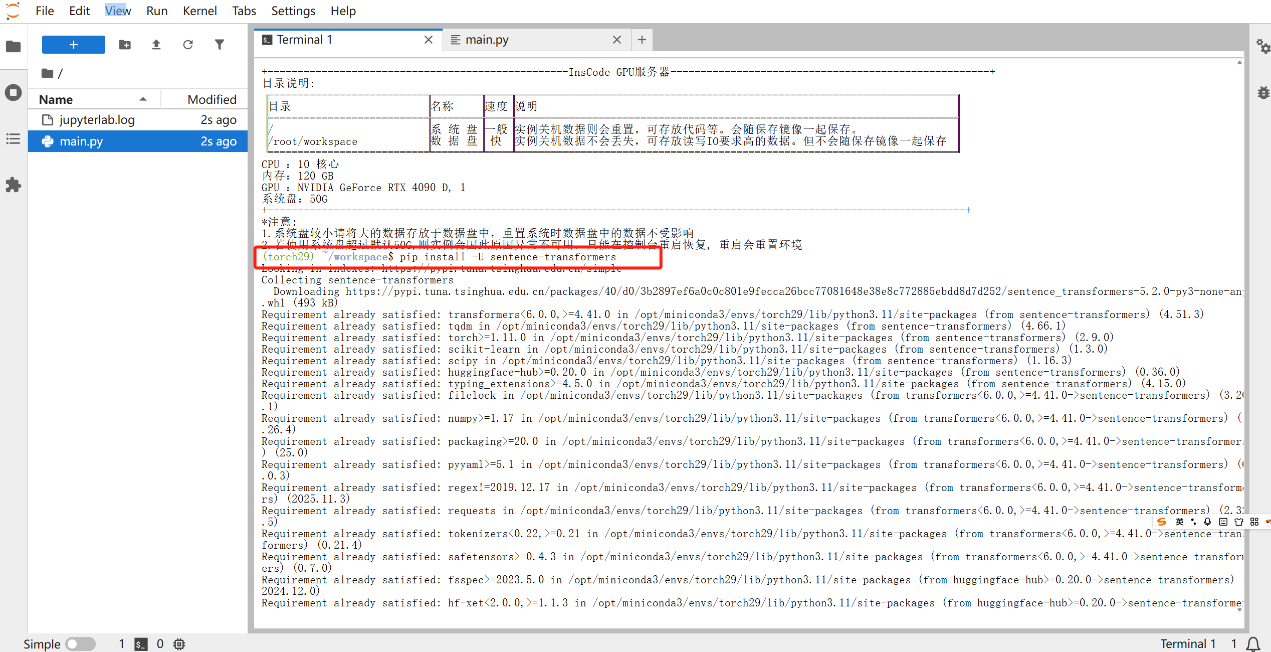
第二步,安装sentence-transformers
pip install -U sentence-transformers
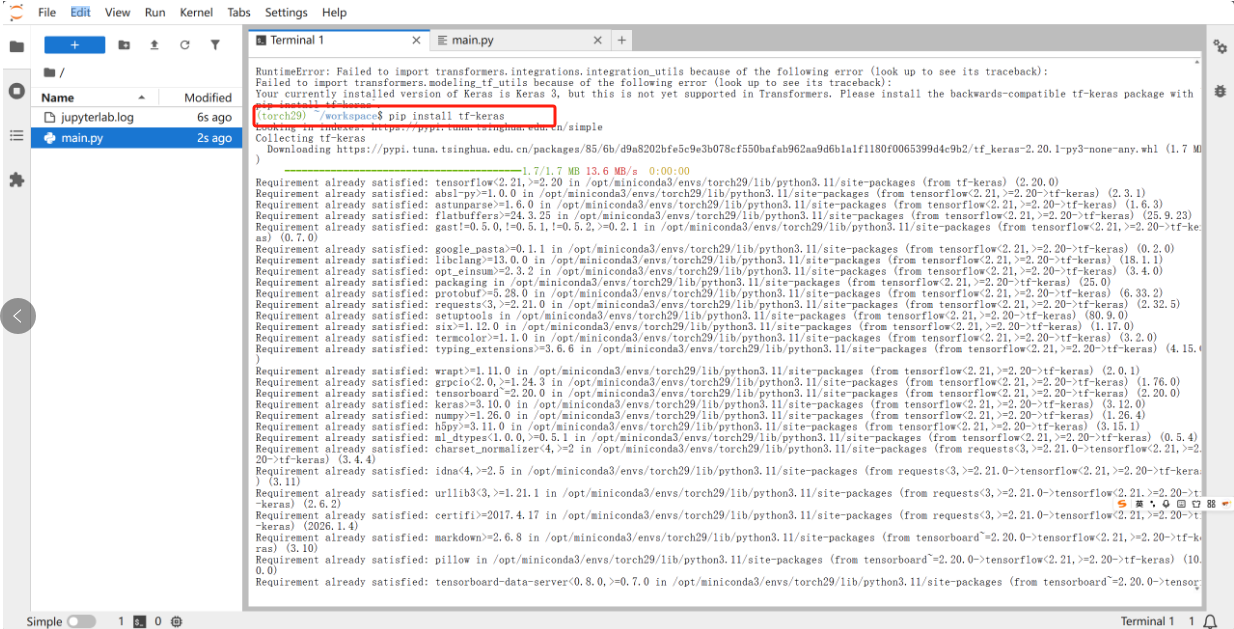
第三步、安装tf-keras
pip install tf-keras
3. 运行安装测试程序
import os
import warnings
# 必须在导入 sentence_transformers 之前执行
warnings.filterwarnings("ignore", category=FutureWarning)
warnings.filterwarnings("ignore", message=".*TRANSFORMERS_CACHE.*")
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
os.environ['TF_ENABLE_ONEDNN_OPTS'] = '0'
os.environ['PYTHONWARNINGS'] = 'ignore'
from sentence_transformers import SentenceTransformer
warnings.filterwarnings("ignore", category=FutureWarning)
# 你的业务逻辑
model_name = 'thenlper/gte-base-zh'
model = SentenceTransformer(model_name)
sentences = ["如何部署大语言模型", "深度学习入门指南"]
embeddings = model.encode(sentences)
print(embeddings.shape)
创建这个py文件并运行
如果出现报错“No module named’transformers.modeling layers” 就是TensorFlow的版本有问题,运行以下命令即可:
pip install --upgrade transformers peft sentence-transformers
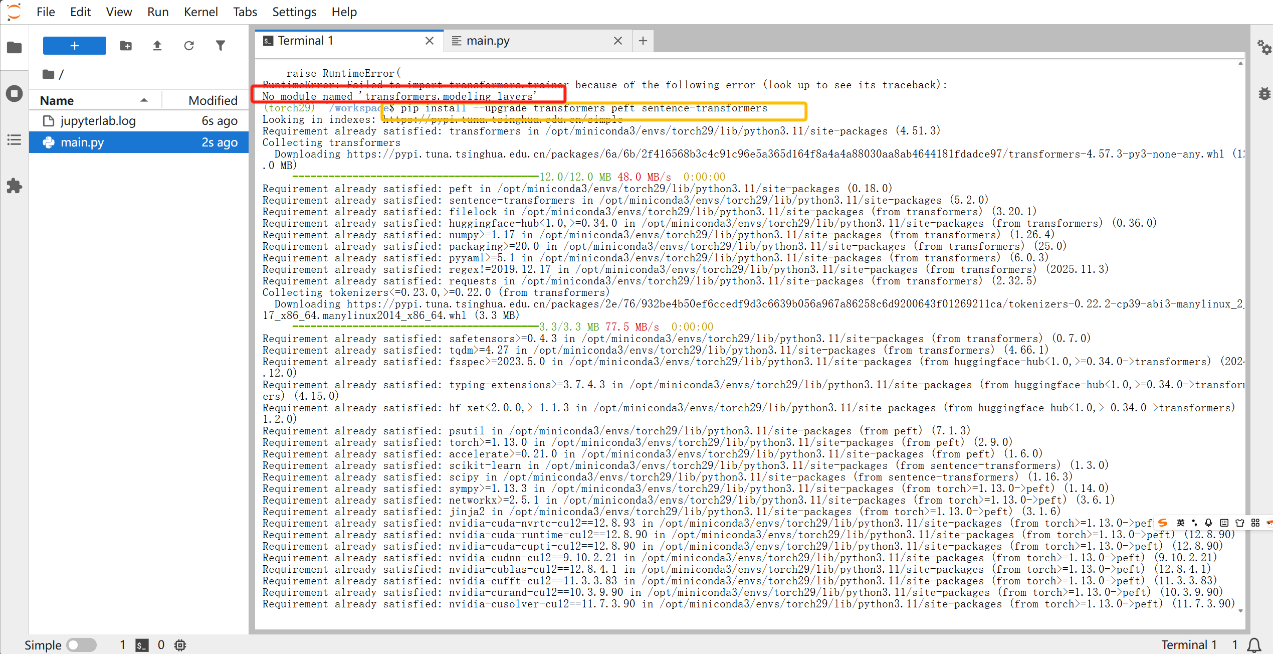
部署正确并运行的话出现的结果如下:
4. 使用示例:语义搜索匹配
import os
import warnings
warnings.filterwarnings("ignore", category=FutureWarning)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
os.environ['USE_TORCH'] = '1'
from sentence_transformers import SentenceTransformer, util
# 1. 加载模型 (自动识别你安装好的路径或从国内镜像下载)
print("正在加载 GTE 模型...")
model = SentenceTransformer('thenlper/gte-base-zh')
# 2. 准备数据:一个查询问题,和几个候选答案
query = "怎么才能让身体更健康?"
documents = [
"保持充足的睡眠,每天坚持锻炼身体,多吃蔬菜水果。", # 相关
"健康是革命的本钱,合理的饮食结构对人体至关重要。", # 相关
"今天的天气真不错,非常适合出门郊游和野餐。", # 弱相关 (有出门运动暗示)
"Python是一种广泛使用的编程语言,适合开发AI模型。", # 完全无关
"由于全球气候变暖,北极熊的生存环境受到了威胁。" # 完全无关
]
print(f"\n用户问题: 【{query}】")
print("-" * 50)
# 3. 计算向量编码
# GTE 模型会将这些文本转化成一串 768 维的数字
query_embedding = model.encode(query)
doc_embeddings = model.encode(documents)
# 4. 计算余弦相似度 (Cosine Similarity)
# 范围在 0 到 1 之间,越接近 1 表示语义越接近
cos_scores = util.cos_sim(query_embedding, doc_embeddings)[0]
# 5. 结果排序并直观展示
results = zip(documents, cos_scores)
sorted_results = sorted(results, key=lambda x: x[1], reverse=True)
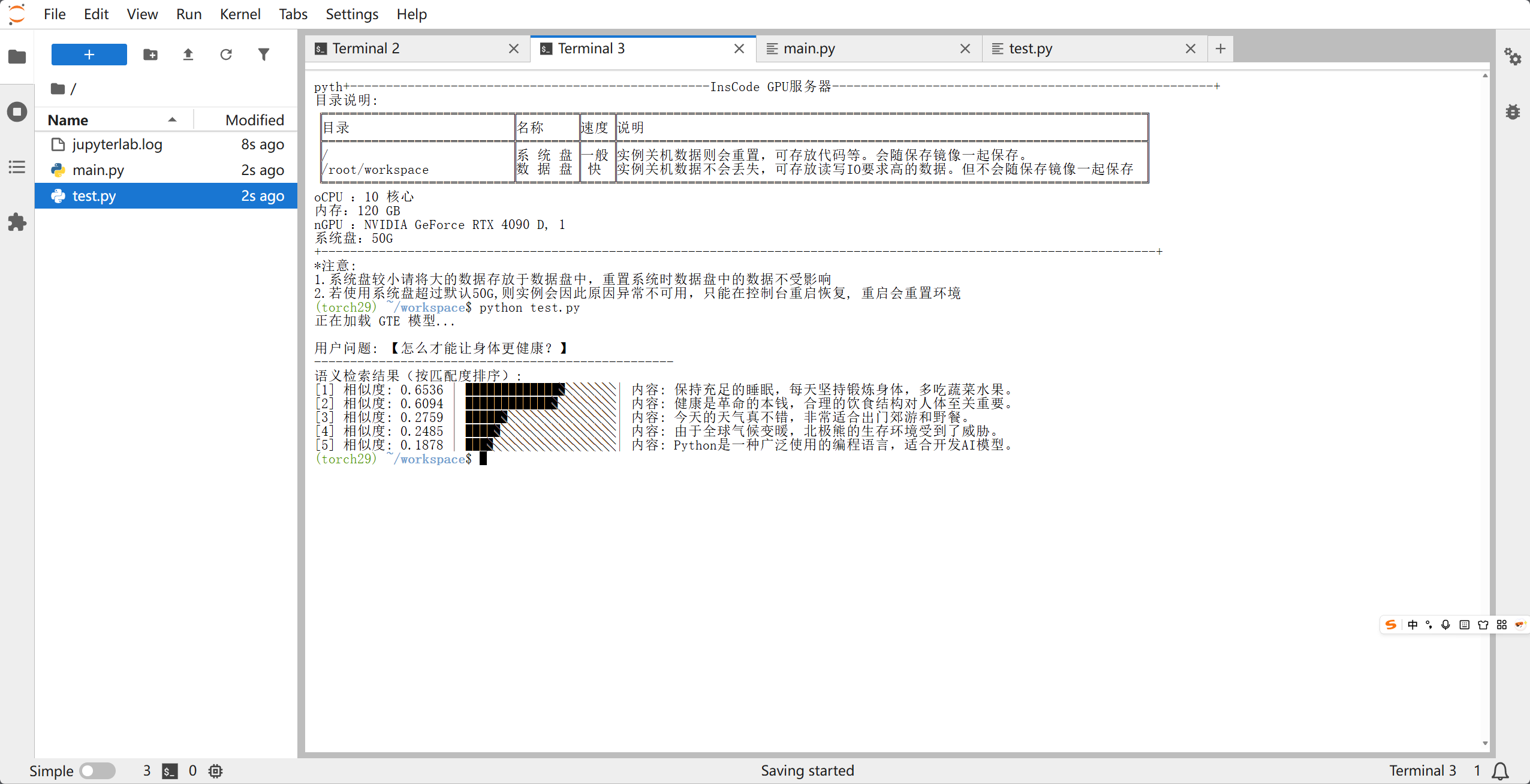
print("语义检索结果(按匹配度排序):")
for i, (doc, score) in enumerate(sorted_results):
# 根据分数生成一个简单的进度条,视觉更直观
bar_length = int(score * 20)
bar = "█" * bar_length + "░" * (20 - bar_length)
print(f"[{i+1}] 相似度: {score:.4f} | {bar} | 内容: {doc}")
创造python文件,复制当前代码并运行,结果如下:
5. 进阶:使用 FastAPI 部署 API 服务
在生产环境中,我们通常将其封装为 API 接口。
文件名:test2.py
from fastapi import FastAPI
from pydantic import BaseModel
from sentence_transformers import SentenceTransformer
import uvicorn
app = FastAPI()
model = SentenceTransformer('thenlper/gte-base-zh')
class TextRequest(BaseModel):
input: list[str]
@app.post("/v1/embeddings")
async def get_embeddings(request: TextRequest):
embeddings = model.encode(request.input).tolist()
return {
"object": "list",
"data": [{"embedding": emb, "index": i} for i, emb in enumerate(embeddings)],
"model": "gte-base-zh"
}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
运行服务:
python test2.py
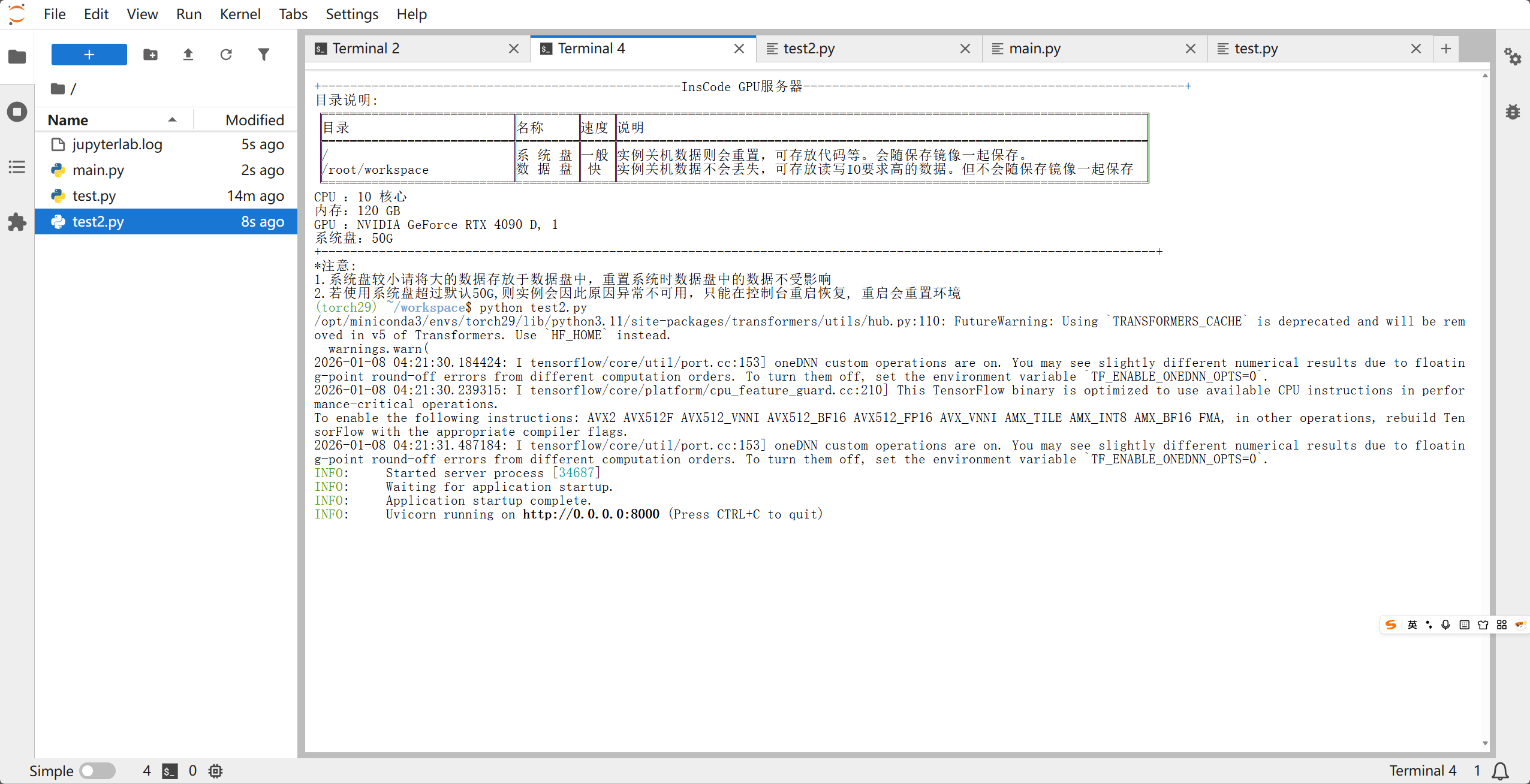
这样就是正常运行了,不过星图GPU并没有配备公网IP所以没办法查看界面
如果是在别的平台上部署且有公网IP的话,目前的程序是部署到8000端口,需要改为云服务器的映射端口或者如果是自己一个IP的话直接访问公网IP的8000端口即可
6. 部署建议与优化
- 显存消耗:GTE-Base-ZH 模型文件约 400MB,推理时显存占用约 1-2GB,对显卡极其友好。
- 长文本处理:GTE-Base 的默认最大长度通常为 512 Tokens。如果文本超长,建议进行物理切片后再向量化。
- 量化:如果要在 CPU 上提速,可以使用
onnxruntime对模型进行量化处理。 - Batch Processing:在处理大规模数据(如存入向量数据库)时,务必使用
model.encode(batch_size=32),这比单条处理快一个数量级。
7. 常见问题 (FAQ)
- Q: GTE-Small, Base, Large 选哪个?
- Small: 速度极快,适合端侧或极其廉价的服务器。
- Base: 性能与速度的甜点位,通用性最强。
- Large: 效果最好,但显存占用增加,适合对召回率有极致追求的场景。
- Q: 为什么计算出来的相似度都是 0.9 以上?
- 这是由于向量空间分布导致的,建议关注相对分值(即 A 比 B 更接近 C),或者在计算前进行 L2 归一化(
F.normalize)。
- 这是由于向量空间分布导致的,建议关注相对分值(即 A 比 B 更接近 C),或者在计算前进行 L2 归一化(
希望这篇教程能帮你快速上手 GTE 文本向量模型!如果有任何问题,欢迎在评论区留言讨论。
目前镜像正在审核中,等到审核过了我就把部署好的镜像搬到这边来
語義搜尋神器:GTE-中文-通用領域-Base 模型三分鐘部署與實戰指南(附已部署映象)
三分鐘部署 thenlper/gte-base-zh:環境依賴、編碼測試、餘弦相似度語義檢索示例,以及 FastAPI 向量化 API 與部署優化建議。
來源:https://blog.csdn.net/2403_87969572/article/details/156702204
抓取時間(ISO本地):2026-05-18 05:17:26
文章目錄
1. 簡介
GTE (General Text Embedding) 是由阿里巴巴達摩院(現通義實驗室)開發的文字向量化模型。在 C-MTEB(中文多工文字嵌入基準)榜單上,GTE 系列模型一直名列前茅。
GTE-Base-ZH 的特點:
- 效能均衡:Base 版本在計算開銷和召回效果之間取得了極佳平衡。
- 場景廣泛:適用於搜尋、推薦、QA 問答對齊、長文字聚類等 RAG(檢索增強生成)場景。
- 部署友好:對視訊記憶體要求低,普通消費級顯示卡甚至 CPU 都能流暢執行。
2. 環境準備
首先,確保你的 Python 環境在 3.8 及以上。如果是在雲伺服器上的話可以直接選擇部署好Pytorch 2.9的映象,就可以忽略這一步
pip install torch transformers
第二步,安裝sentence-transformers
pip install -U sentence-transformers
第三步、安裝tf-keras
pip install tf-keras
3. 執行安裝測試程式
import os
import warnings
# 必須在匯入 sentence_transformers 之前執行
warnings.filterwarnings("ignore", category=FutureWarning)
warnings.filterwarnings("ignore", message=".*TRANSFORMERS_CACHE.*")
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
os.environ['TF_ENABLE_ONEDNN_OPTS'] = '0'
os.environ['PYTHONWARNINGS'] = 'ignore'
from sentence_transformers import SentenceTransformer
warnings.filterwarnings("ignore", category=FutureWarning)
# 你的業務邏輯
model_name = 'thenlper/gte-base-zh'
model = SentenceTransformer(model_name)
sentences = ["如何部署大語言模型", "深度學習入門指南"]
embeddings = model.encode(sentences)
print(embeddings.shape)
建立這個py檔案並執行
如果出現報錯“No module named’transformers.modeling layers” 就是TensorFlow的版本有問題,執行以下命令即可:
pip install --upgrade transformers peft sentence-transformers
部署正確並執行的話出現的結果如下:
4. 使用示例:語義搜尋匹配
import os
import warnings
warnings.filterwarnings("ignore", category=FutureWarning)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
os.environ['USE_TORCH'] = '1'
from sentence_transformers import SentenceTransformer, util
# 1. 載入模型 (自動識別你安裝好的路徑或從國內映象下載)
print("正在載入 GTE 模型...")
model = SentenceTransformer('thenlper/gte-base-zh')
# 2. 準備資料:一個查詢問題,和幾個候選答案
query = "怎麼才能讓身體更健康?"
documents = [
"保持充足的睡眠,每天堅持鍛鍊身體,多吃蔬菜水果。", # 相關
"健康是革命的本錢,合理的飲食結構對人體至關重要。", # 相關
"今天的天氣真不錯,非常適合出門郊遊和野餐。", # 弱相關 (有出門運動暗示)
"Python是一種廣泛使用的程式語言,適合開發AI模型。", # 完全無關
"由於全球氣候變暖,北極熊的生存環境受到了威脅。" # 完全無關
]
print(f"\n使用者問題: 【{query}】")
print("-" * 50)
# 3. 計算向量編碼
# GTE 模型會將這些文字轉化成一串 768 維的數字
query_embedding = model.encode(query)
doc_embeddings = model.encode(documents)
# 4. 計算餘弦相似度 (Cosine Similarity)
# 範圍在 0 到 1 之間,越接近 1 表示語義越接近
cos_scores = util.cos_sim(query_embedding, doc_embeddings)[0]
# 5. 結果排序並直觀展示
results = zip(documents, cos_scores)
sorted_results = sorted(results, key=lambda x: x[1], reverse=True)
print("語義檢索結果(按匹配度排序):")
for i, (doc, score) in enumerate(sorted_results):
# 根據分數生成一個簡單的進度條,視覺更直觀
bar_length = int(score * 20)
bar = "█" * bar_length + "░" * (20 - bar_length)
print(f"[{i+1}] 相似度: {score:.4f} | {bar} | 內容: {doc}")
創造python檔案,複製當前程式碼並執行,結果如下:
5. 進階:使用 FastAPI 部署 API 服務
在生產環境中,我們通常將其封裝為 API 介面。
檔名:test2.py
from fastapi import FastAPI
from pydantic import BaseModel
from sentence_transformers import SentenceTransformer
import uvicorn
app = FastAPI()
model = SentenceTransformer('thenlper/gte-base-zh')
class TextRequest(BaseModel):
input: list[str]
@app.post("/v1/embeddings")
async def get_embeddings(request: TextRequest):
embeddings = model.encode(request.input).tolist()
return {
"object": "list",
"data": [{"embedding": emb, "index": i} for i, emb in enumerate(embeddings)],
"model": "gte-base-zh"
}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
執行服務:
python test2.py
這樣就是正常執行了,不過星圖GPU並沒有配備公網IP所以沒辦法檢視介面
如果是在別的平臺上部署且有公網IP的話,目前的程式是部署到8000埠,需要改為雲伺服器的對映埠或者如果是自己一個IP的話直接訪問公網IP的8000埠即可
6. 部署建議與最佳化
- 視訊記憶體消耗:GTE-Base-ZH 模型檔案約 400MB,推理時視訊記憶體佔用約 1-2GB,對顯示卡極其友好。
- 長文字處理:GTE-Base 的預設最大長度通常為 512 Tokens。如果文字超長,建議進行物理切片後再向量化。
- 量化:如果要在 CPU 上提速,可以使用
onnxruntime對模型進行量化處理。 - Batch Processing:在處理大規模資料(如存入向量資料庫)時,務必使用
model.encode(batch_size=32),這比單條處理快一個數量級。
7. 常見問題 (FAQ)
- Q: GTE-Small, Base, Large 選哪個?
- Small: 速度極快,適合端側或極其廉價的伺服器。
- Base: 效能與速度的甜點位,通用性最強。
- Large: 效果最好,但視訊記憶體佔用增加,適合對召回率有極致追求的場景。
- Q: 為什麼計算出來的相似度都是 0.9 以上?
- 這是由於向量空間分佈導致的,建議關注相對分值(即 A 比 B 更接近 C),或者在計算前進行 L2 歸一化(
F.normalize)。
- 這是由於向量空間分佈導致的,建議關注相對分值(即 A 比 B 更接近 C),或者在計算前進行 L2 歸一化(
希望這篇教程能幫你快速上手 GTE 文字向量模型!如果有任何問題,歡迎在評論區留言討論。
目前映象正在稽核中,等到稽核過了我就把部署好的映象搬到這邊來
Semantic Search Powerhouse: GTE Chinese General Base — 3-Minute Deploy & Hands-On Guide (Prebuilt Image Coming)
GTE (General Text Embedding) is a text-embedding family from Alibaba DAMO / Tongyi Lab.On C-MTEB (Chinese MTEB), GTE models routinely rank near the top.GTE-Base-ZH traits: Balanced: Base size hits a sweet spot between cost and recall.
Captured at (local ISO): 2026-05-18 05:17:26
1. Overview
GTE (General Text Embedding) is a text-embedding family from Alibaba DAMO / Tongyi Lab. On C-MTEB (Chinese MTEB), GTE models routinely rank near the top.
GTE-Base-ZH traits:
- Balanced: Base size hits a sweet spot between cost and recall.
- Broad: Search, recs, QA alignment, long-text clustering—typical RAG paths.
- Deployable: Low VRAM—consumer GPUs or even CPU.
2. Environment setup
Python ≥ 3.8. On a cloud image with PyTorch 2.9 already baked in, you can skip the torch install.
pip install torch transformers
Then sentence-transformers:
pip install -U sentence-transformers
Third: tf-keras
pip install tf-keras
3. Smoke test script
import os
import warnings
# 必须在导入 sentence_transformers 之前执行
warnings.filterwarnings("ignore", category=FutureWarning)
warnings.filterwarnings("ignore", message=".*TRANSFORMERS_CACHE.*")
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
os.environ['TF_ENABLE_ONEDNN_OPTS'] = '0'
os.environ['PYTHONWARNINGS'] = 'ignore'
from sentence_transformers import SentenceTransformer
warnings.filterwarnings("ignore", category=FutureWarning)
# 你的业务逻辑
model_name = 'thenlper/gte-base-zh'
model = SentenceTransformer(model_name)
sentences = ["如何部署大语言模型", "深度学习入门指南"]
embeddings = model.encode(sentences)
print(embeddings.shape)
Save as .py and run:
If you see No module named 'transformers.modeling layers' (TensorFlow stack glitch):
pip install --upgrade transformers peft sentence-transformers
Healthy run looks like:
4. Example: semantic search matching
import os
import warnings
warnings.filterwarnings("ignore", category=FutureWarning)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
os.environ['USE_TORCH'] = '1'
from sentence_transformers import SentenceTransformer, util
# 1. 加载模型 (自动识别你安装好的路径或从国内镜像下载)
print("正在加载 GTE 模型...")
model = SentenceTransformer('thenlper/gte-base-zh')
# 2. 准备数据:一个查询问题,和几个候选答案
query = "怎么才能让身体更健康?"
documents = [
"保持充足的睡眠,每天坚持锻炼身体,多吃蔬菜水果。", # 相关
"健康是革命的本钱,合理的饮食结构对人体至关重要。", # 相关
"今天的天气真不错,非常适合出门郊游和野餐。", # 弱相关 (有出门运动暗示)
"Python是一种广泛使用的编程语言,适合开发AI模型。", # 完全无关
"由于全球气候变暖,北极熊的生存环境受到了威胁。" # 完全无关
]
print(f"\n用户问题: 【{query}】")
print("-" * 50)
# 3. 计算向量编码
# GTE 模型会将这些文本转化成一串 768 维的数字
query_embedding = model.encode(query)
doc_embeddings = model.encode(documents)
# 4. 计算余弦相似度 (Cosine Similarity)
# 范围在 0 到 1 之间,越接近 1 表示语义越接近
cos_scores = util.cos_sim(query_embedding, doc_embeddings)[0]
# 5. 结果排序并直观展示
results = zip(documents, cos_scores)
sorted_results = sorted(results, key=lambda x: x[1], reverse=True)
print("语义检索结果(按匹配度排序):")
for i, (doc, score) in enumerate(sorted_results):
# 根据分数生成一个简单的进度条,视觉更直观
bar_length = int(score * 20)
bar = "█" * bar_length + "░" * (20 - bar_length)
print(f"[{i+1}] 相似度: {score:.4f} | {bar} | 内容: {doc}")
Save, run—sample output:
5. Next level: FastAPI embedding service
In production, wrap inference as an API.
File: test2.py
from fastapi import FastAPI
from pydantic import BaseModel
from sentence_transformers import SentenceTransformer
import uvicorn
app = FastAPI()
model = SentenceTransformer('thenlper/gte-base-zh')
class TextRequest(BaseModel):
input: list[str]
@app.post("/v1/embeddings")
async def get_embeddings(request: TextRequest):
embeddings = model.encode(request.input).tolist()
return {
"object": "list",
"data": [{"embedding": emb, "index": i} for i, emb in enumerate(embeddings)],
"model": "gte-base-zh"
}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
Run:
python test2.py
This GPU box had no public IP—no browser check from outside.
On a host with a public IP, map 8000 or browse http://<public-ip>:8000 per your cloud rules.
6. Deployment tips
- VRAM: GTE-Base-ZH weights ~400 MB; inference often 1–2 GB—very friendly.
- Long text: default context ~512 tokens—chunk before embedding.
- Quantization:
onnxruntimequantization can speed CPU paths. - Batching: For index builds,
model.encode(batch_size=32)vs one-by-one is often 10× faster.
7. FAQ
- Q: GTE-Small vs Base vs Large?
- Small: fastest—edge / tiny VMs.
- Base: best default balance.
- Large: best recall, more VRAM—when every point of quality matters.
- Q: Why are all similarities > 0.9?
- Embedding geometry—watch relative gaps (A closer than B) or L2-normalize (
F.normalize) before cosine.
- Embedding geometry—watch relative gaps (A closer than B) or L2-normalize (
Hope this gets GTE running quickly—comment if you hit snags.
A prebuilt image is under review; I’ll link it here once approved.