实用代码工具:Python打造PDF选区OCR / 截图批量处理工具(支持手动/全自动模式)
在日常办公和开发中,我们经常会遇到这样的需求:从大量PDF文件的指定区域提取文本(比如发票的日期、金额,报表的关键指标),或者对指定区域进行截图并汇总到Excel中。手动逐个处理效率极低,而通用的PDF OCR工具又无法精准定位区域。代码已开源在Github : 今天给大家分享一款我开发的Python工具——PDF区域OCR/截图逐个处理工具,它完美解决了上述痛点,支持手动审核+全自动批量处理,还内置了区域拖动缩放、Excel自动导出等实用功能,并且配备完善的UI界面,使用门槛极低。下面详细拆解它的功能和实现原理。
前言
在日常办公和开发中,我们经常会遇到这样的需求:从大量PDF文件的指定区域提取文本(比如发票的日期、金额,报表的关键指标),或者对指定区域进行截图并汇总到Excel中。手动逐个处理效率极低,而通用的PDF OCR工具又无法精准定位区域。
代码已开源在Github :https://github.com/ChenAI-TGF/PDF_SnapOCR
今天给大家分享一款我开发的Python工具——PDF区域OCR/截图逐个处理工具,它完美解决了上述痛点,支持手动审核+全自动批量处理,还内置了区域拖动缩放、Excel自动导出等实用功能,并且配备完善的UI界面,使用门槛极低。下面详细拆解它的功能和实现原理。先看一下整个程序的界面:
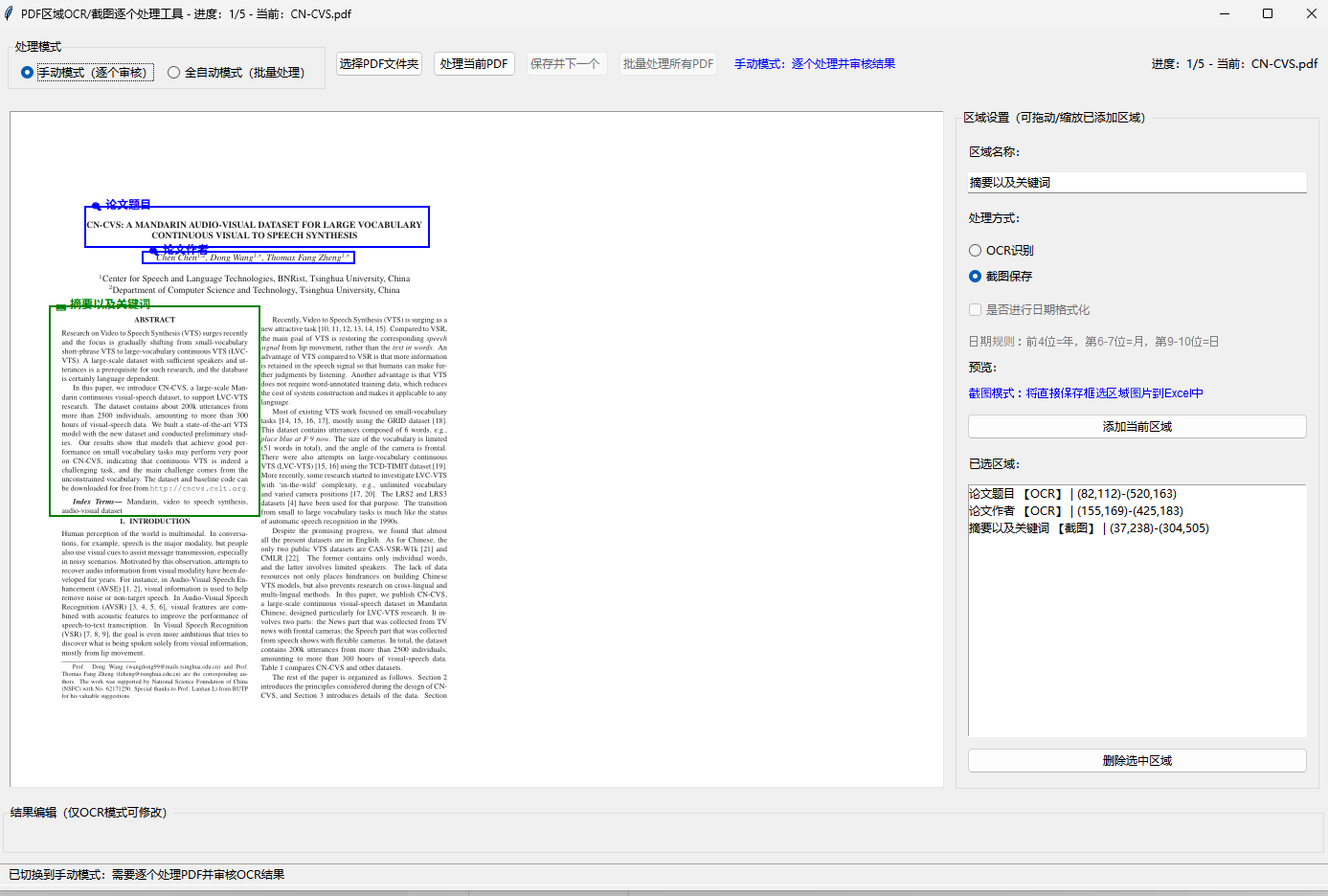
一、工具核心功能详解
这款工具基于tkinter构建可视化界面,整合了PyMuPDF(PDF处理)、easyocr(OCR识别)、openpyxl(Excel导出)等库,功能覆盖从PDF区域选择到结果汇总的全流程,具体如下:
1. 核心处理能力
| 功能点 | 详细说明 |
|---|---|
| 精准区域OCR识别 | 可框选PDF任意区域进行文字提取,支持中文+英文识别;内置OpenCV图像预处理(灰度化、自适应阈值、形态学操作),提升识别准确率 |
| 区域截图保存 | 支持将框选区域保存为图片,自动处理路径和文件名冲突(UUID生成唯一名称),避免特殊字符导致的保存失败 |
| 自定义日期格式化 | 针对OCR识别的日期文本,可按不同规则自动格式化(例:20251209 → 2025年12月09日),用户可自行设置,支持实时预览格式化效果 |
2. 交互与操作体验
区域可视化管理 :
框选的区域会在PDF预览界面显示(不同类型有不同颜色:OCR=蓝色/截图=绿色,选中=红色)
支持拖动(边线控制点)和缩放(右下角控制点),操作直观
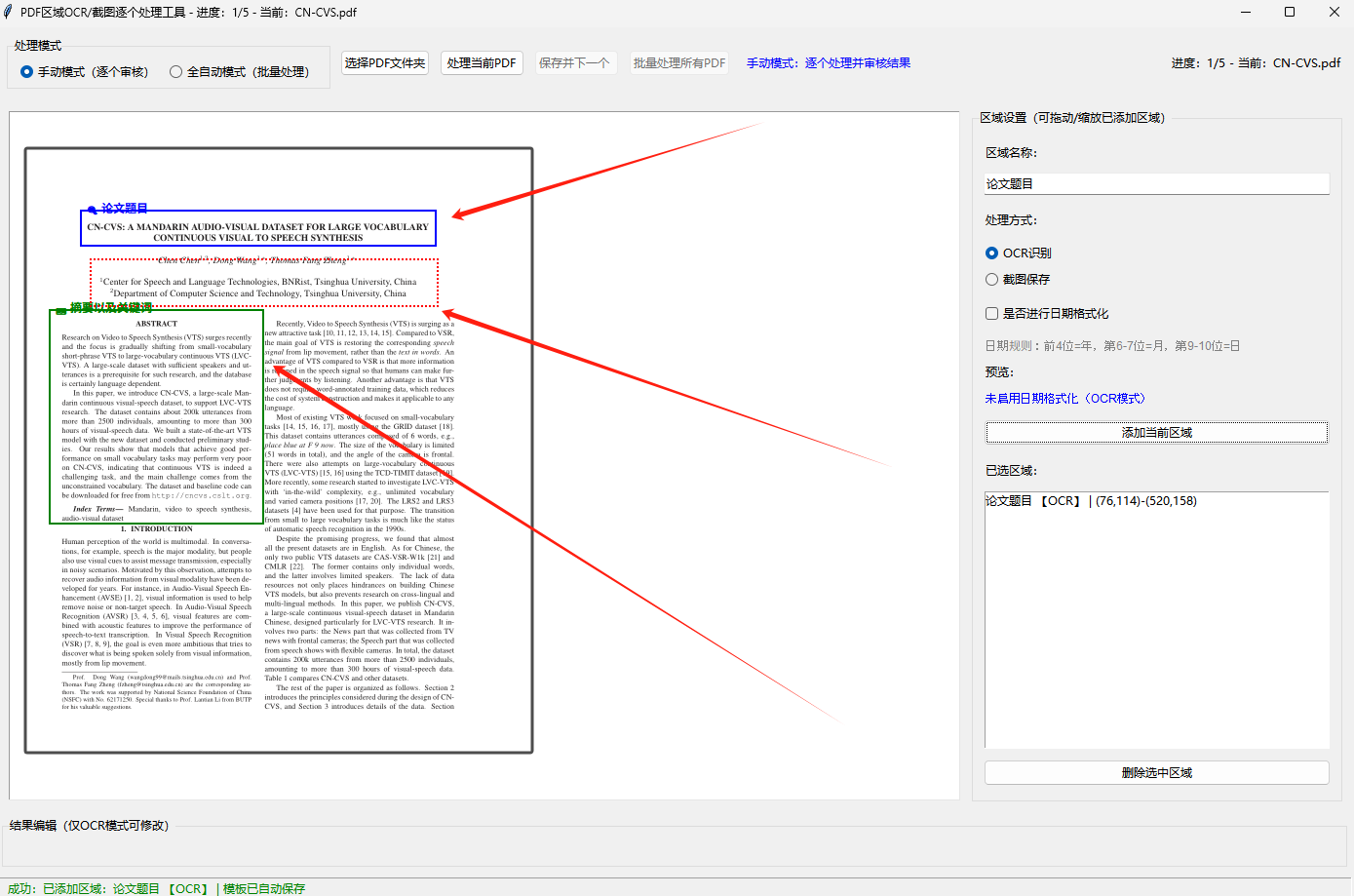
区域模板继承
为第一个PDF设置的区域会自动保存为模板,切换后续PDF时自动继承,无需重复框选;修改区域后模板实时更新,同时 支持拖动(边线控制点)和缩放(右下角控制点)上一个PDF保存下来的模版
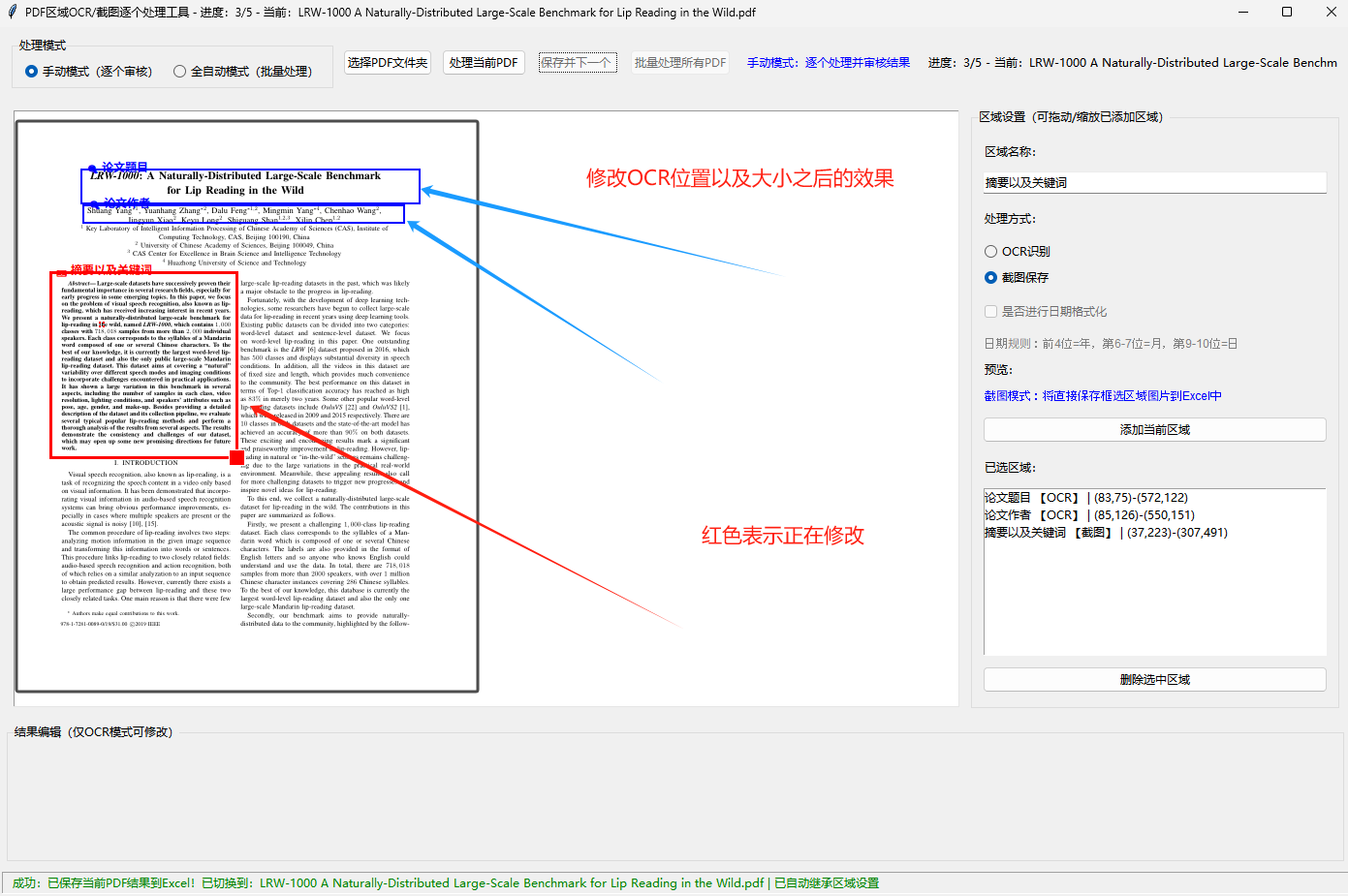
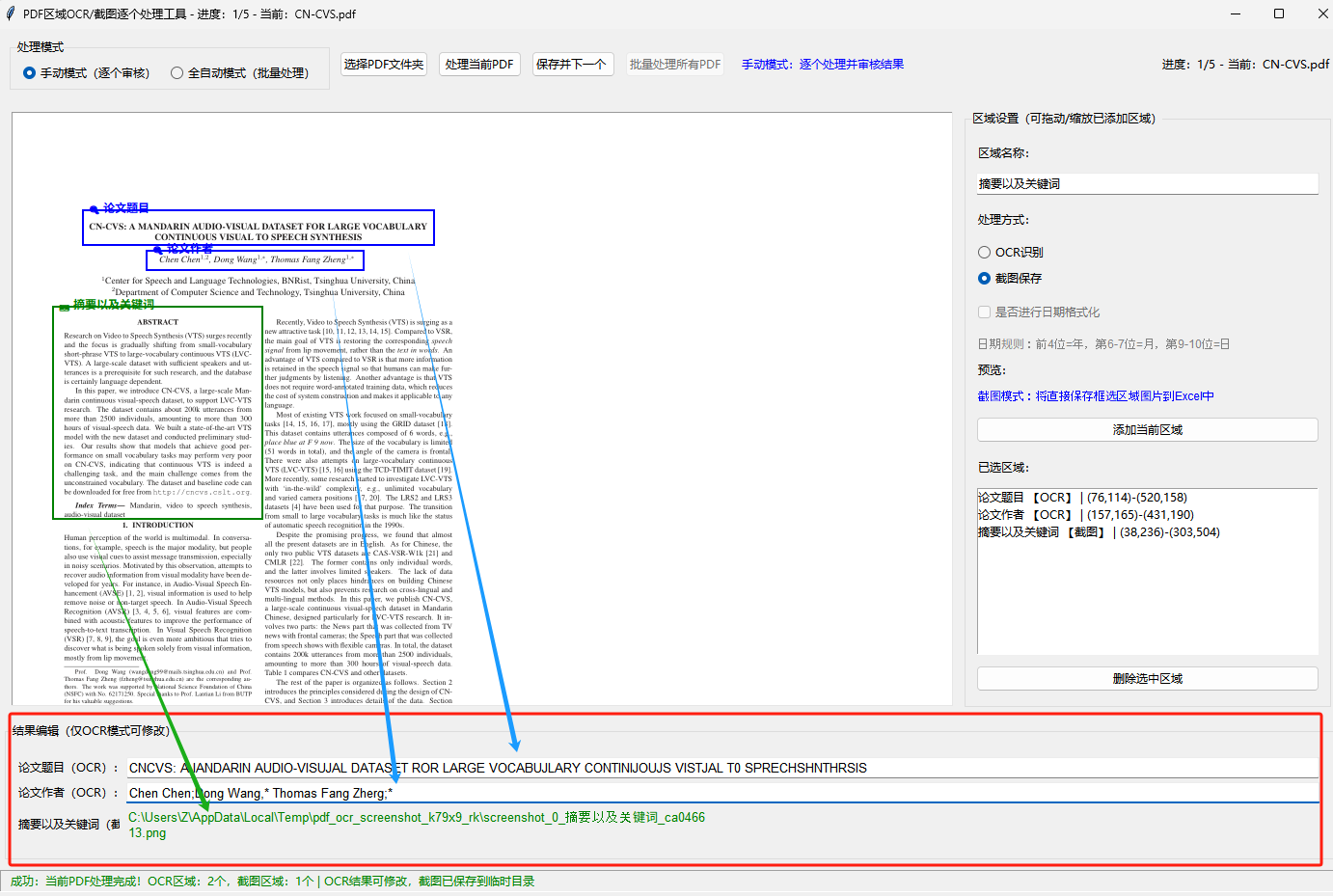
手动模式 - OCR结果审核与修改 :
处理当前PDF后,所有OCR识别结果会生成可编辑输入框,支持手动审核、修正识别错误(截图模式仅显示保存路径)
编辑后的结果实时生效,点击「保存并下一个」可将修改后的内容写入Excel,同时自动切换到下一个PDF文件
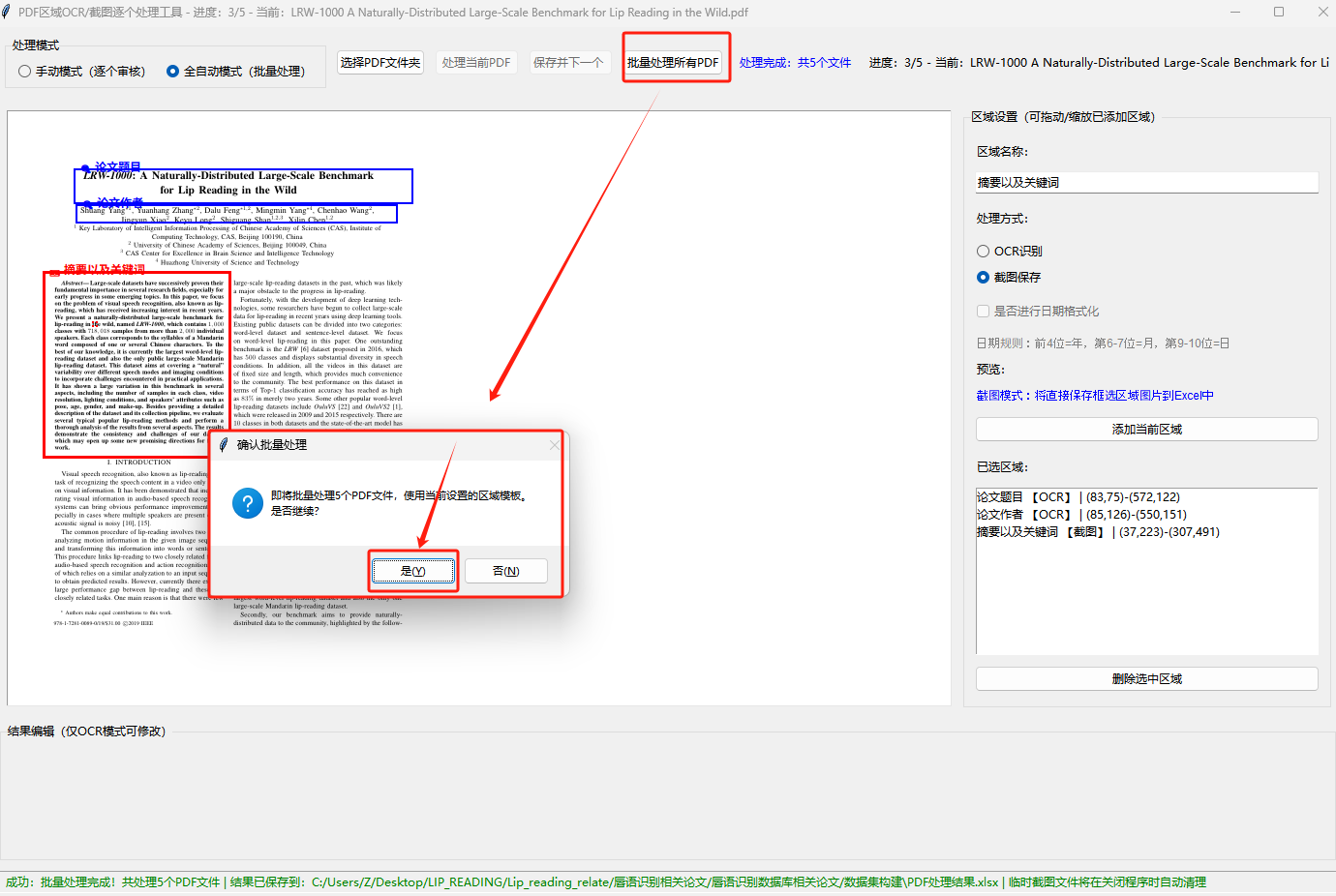
全自动模式 - 一键批量处理所有PDF :
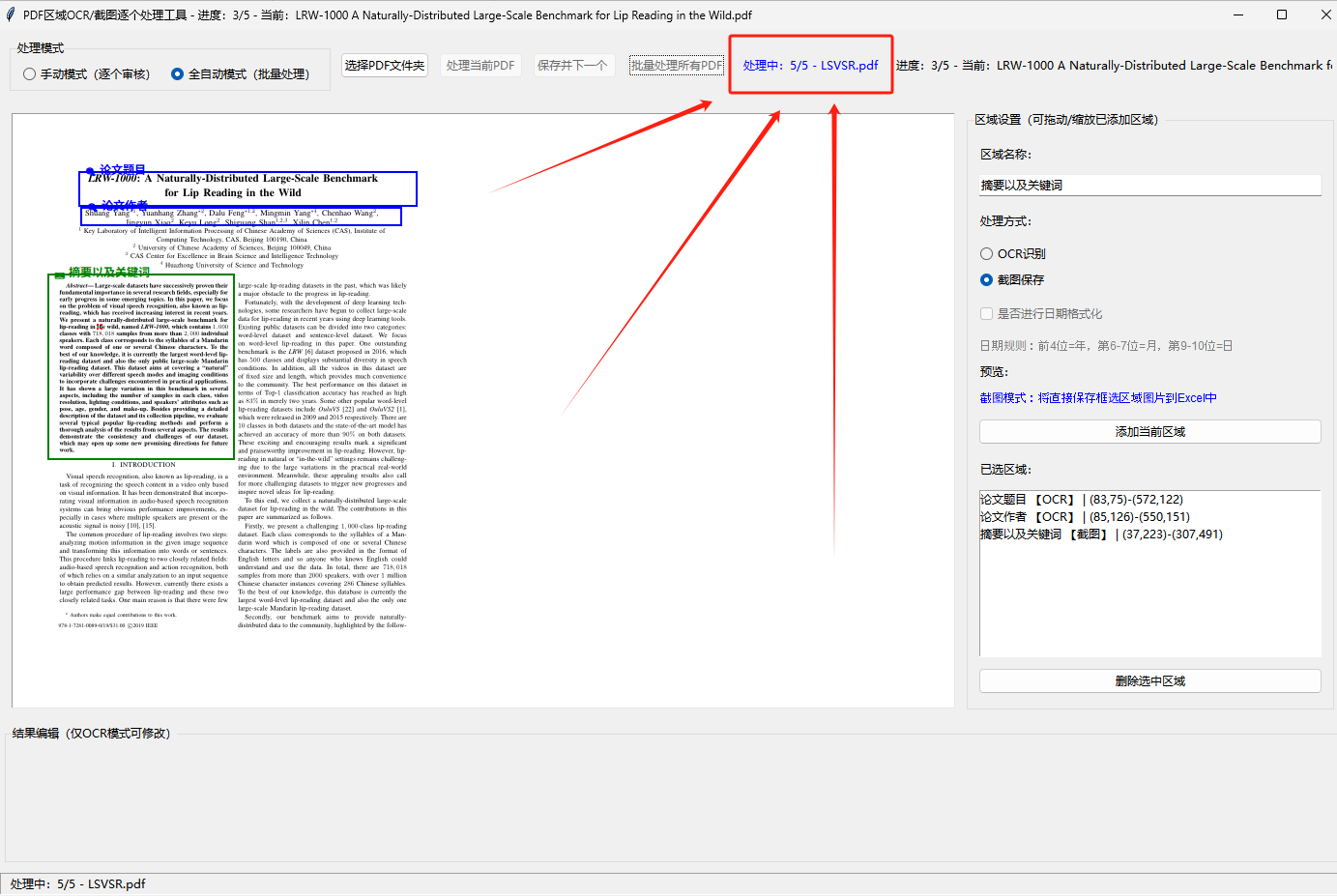
切换到全自动模式后,基于已设置的区域模板,点击「批量处理所有PDF」可后台线程执行(不卡死界面),避免单线程卡顿
实时显示处理进度(当前处理第N个/总数量 + 文件名),每处理10个文件自动保存一次Excel,防止数据丢失
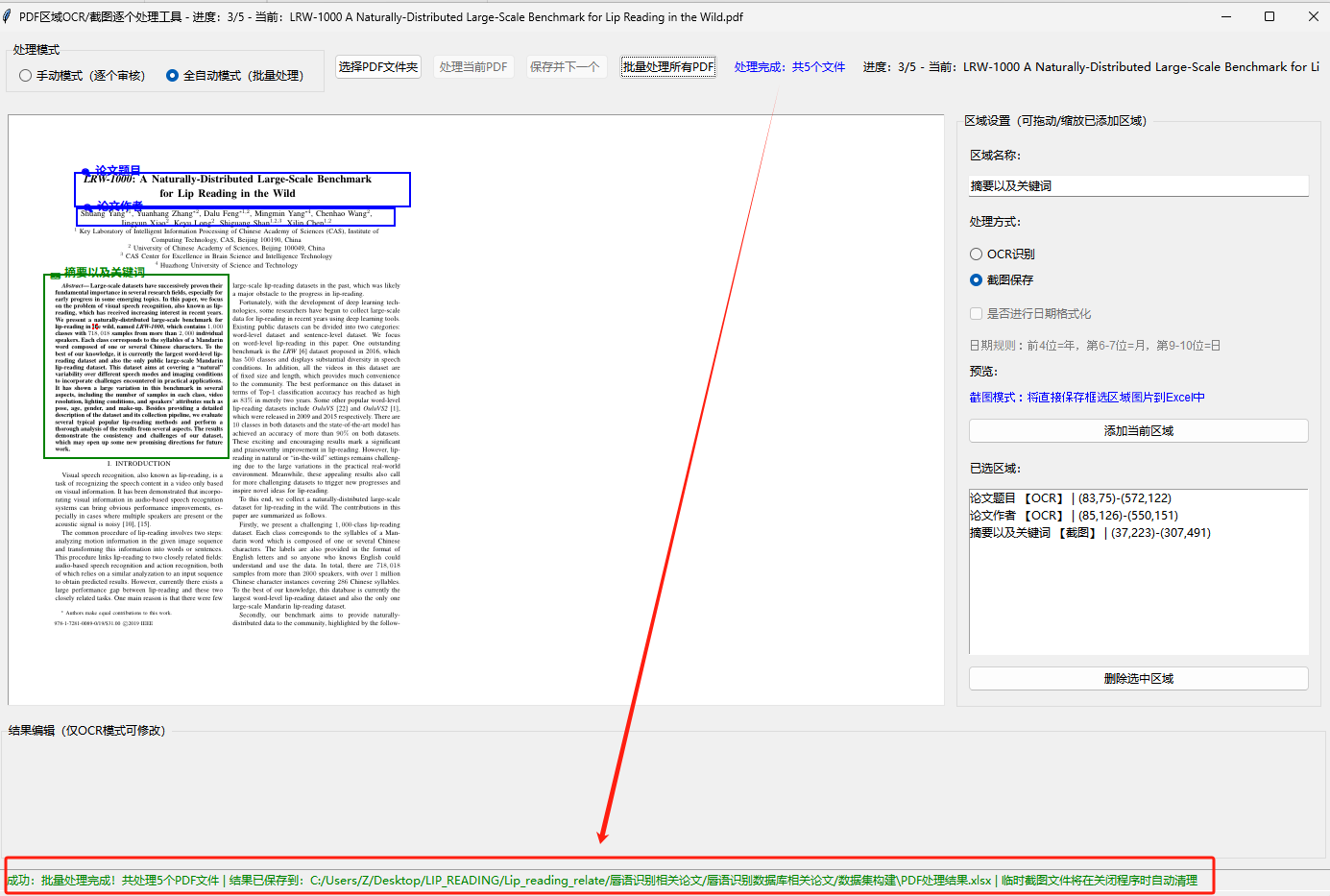
处理完成后弹窗提示结果文件路径,全程无需人工干预
结果导出 - Excel一体化存储(文本+截图) :
纯文本结果(OCR识别/修改后内容)与截图文件一体化写入Excel,截图自动插入对应单元格并适配尺寸(最大宽度150px,等比例缩放)
自动调整Excel列宽/行高适配内容,截图区域单元格标注清晰,文本区域可直接编辑
结果文件保存在PDF文件夹下(命名:PDF处理结果.xlsx),关闭程序时才清理临时截图文件,确保Excel中图片正常显示

二、环境准备与安装
使用前需安装以下依赖库,建议在虚拟环境中执行:
# 核心依赖
pip install pymupdf easyocr openpyxl
# 辅助依赖(数据处理/图像/界面)
pip install pandas opencv-python pillow numpy tkinter
注意:
tkinter通常随Python自带,若缺失可根据系统安装(如Ubuntu:sudo apt-get install python3-tk)。
三、代码核心原理简析
工具的代码结构清晰,分为基础配置、工具函数、主应用类、程序入口四部分,核心原理简单拆解如下:
1. 界面构建:tkinter
- 使用
tkinter+ttk构建可视化界面,分为“顶部操作栏”(模式切换、按钮、进度)、“顶右侧操作栏”、“中间预览区”(PDF画布+区域设置)、“结果编辑区”、“底部状态栏”;
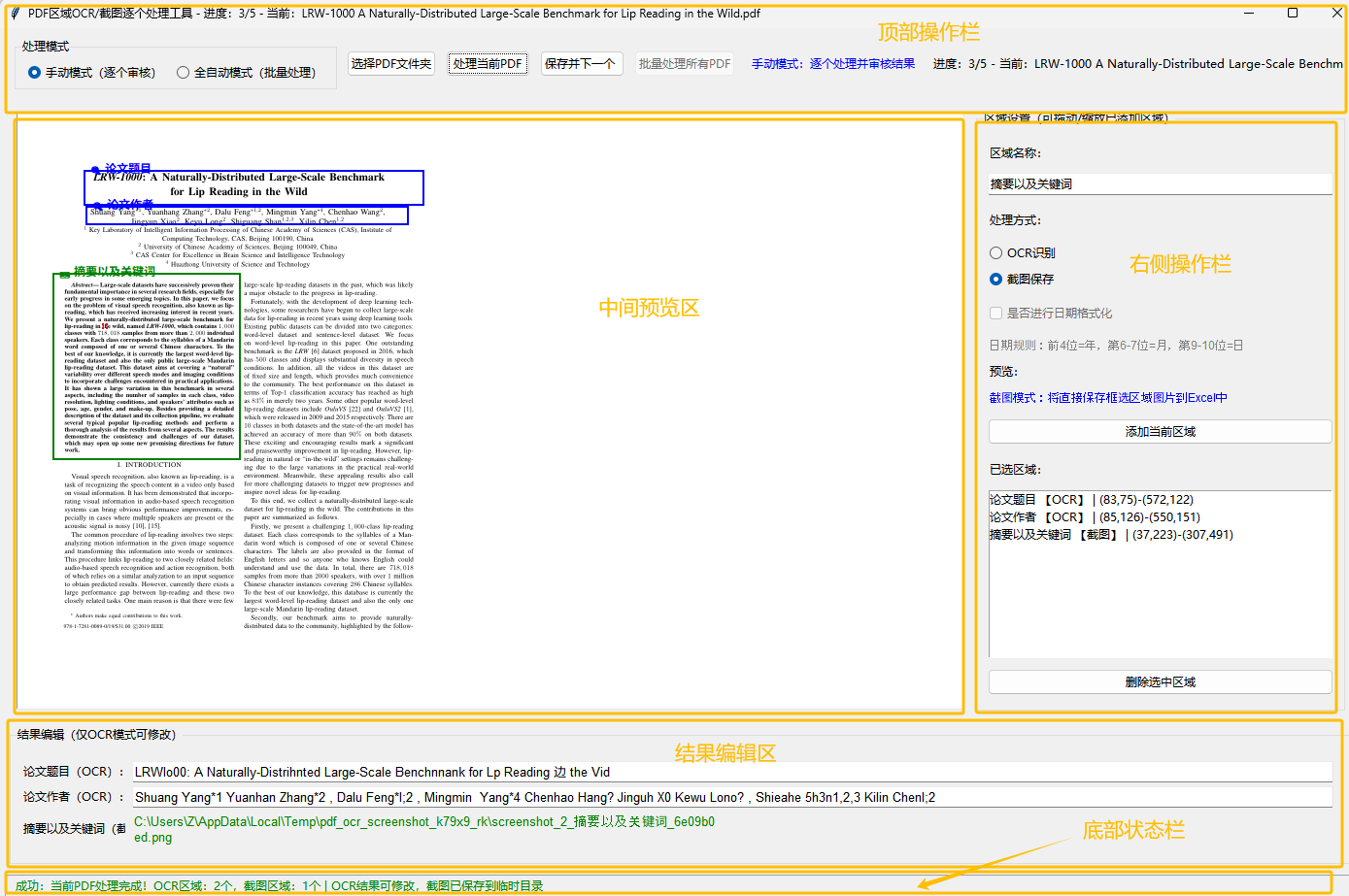
- 画布(Canvas)绑定鼠标事件(点击/拖动/释放),实现区域框选、拖动、缩放功能;

- 全局快捷键绑定(
bind_all),确保F2键在任意控件焦点下都能触发。
2. PDF处理:PyMuPDF(fitz)
- 打开PDF并读取第一页(
fitz.open(pdf_path)[0]); - 计算Canvas与PDF页面的缩放比例,实现PDF预览的等比例适配;
- 通过
page.get_pixmap(clip=rect)提取指定区域的像素数据,转换为OpenCV/PIL可处理的图像格式。
3. OCR识别:easyocr + OpenCV
easyocr.Reader(['ch_sim', 'en'])初始化中英双语识别器;- OpenCV对区域图像预处理(灰度化、自适应阈值、形态学开运算),减少噪声提升识别率;
- 自定义
format_date_text函数实现日期格式化,异常时返回原始文本,保证程序健壮性。
4. 批量处理:多线程
- 批量处理逻辑放在独立线程(
threading.Thread)中执行,避免主线程(界面)卡死; - 通过
root.after(0, 回调函数)更新UI状态(进度、提示),符合tkinter的线程安全规则。
5. Excel导出:openpyxl + pandas
pandas.DataFrame存储OCR文本结果,dataframe_to_rows写入Excel;openpyxl.drawing.image.Image插入截图,自动缩放图片尺寸并调整单元格大小;- 文本结果与截图路径分离存储,确保Excel导出时文本和图片一一对应。
四、工具使用教程(分步演示)
步骤1:启动工具
运行代码,若依赖齐全会弹出主界面,底部状态栏显示“就绪 - 请选择PDF文件夹开始操作”。
步骤2:选择PDF文件夹
点击“选择PDF文件夹”,选中存放待处理PDF的文件夹,工具会自动加载所有PDF文件(仅后缀为.pdf的文件),并显示第一个PDF的预览。
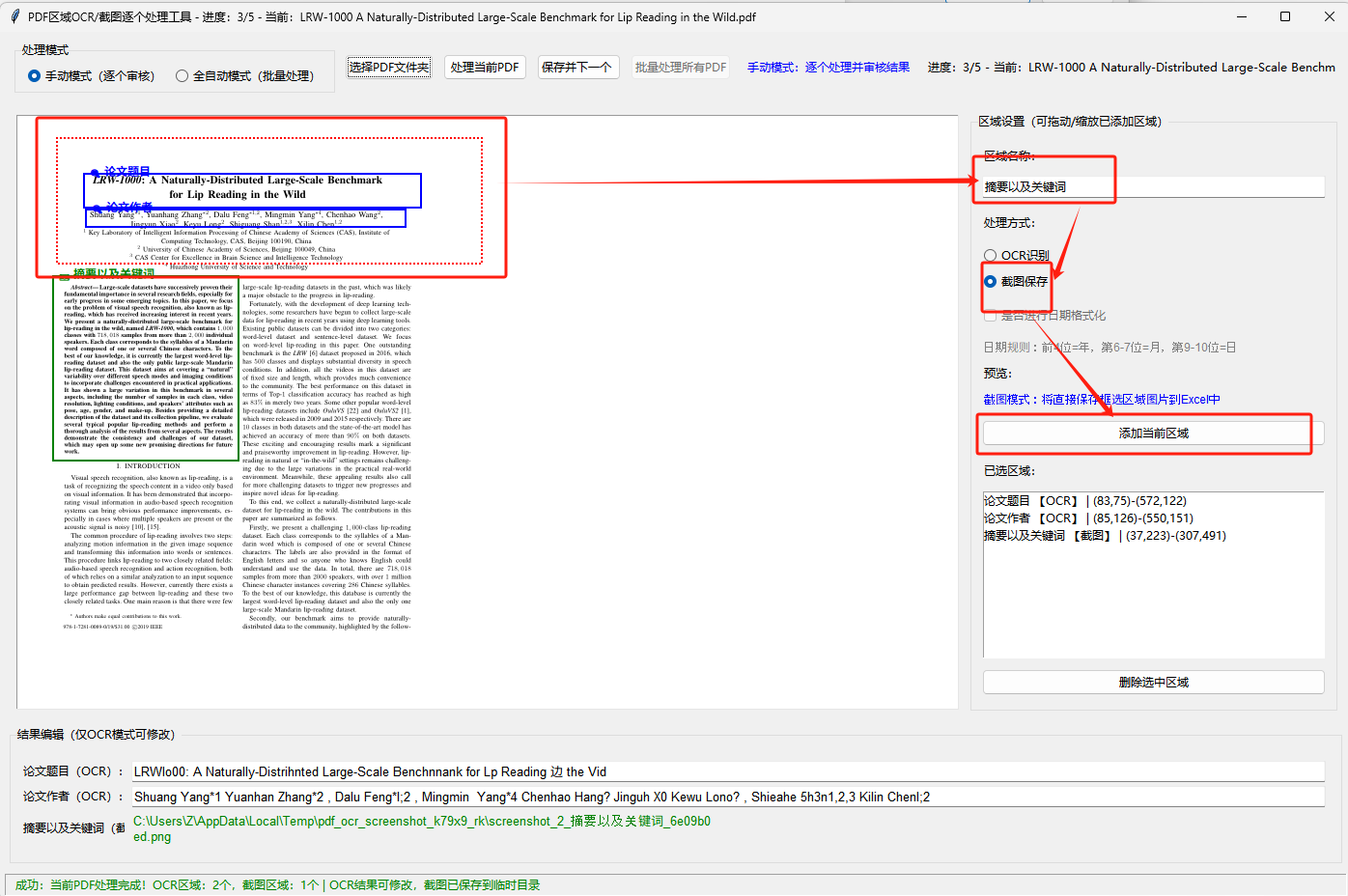
步骤3:设置处理区域(核心)
- 在PDF预览画布上按住鼠标左键拖动,框选需要处理的区域;
- 在右侧“区域设置”面板:
- 输入“区域名称”(如“开票日期”“金额”);
- 选择“处理方式”(OCR识别/截图保存);
- 若选OCR,可勾选“是否进行日期格式化”,实时预览格式化效果;
- 点击“添加当前区域”,区域会显示在画布上,同时出现在“已选区域”列表中;
- 如需调整区域:点击画布上的区域(变红),可拖动位置或拖动右下角控制点缩放。
步骤4:选择处理模式
模式A:手动模式(逐个审核)
- 点击“处理当前PDF”,工具会识别所有区域并显示结果(OCR结果可直接编辑);
- 确认结果无误后,点击“保存并下一个”,结果写入Excel并切换到下一个PDF;
- 重复上述步骤,直到所有PDF处理完成。
模式B:全自动模式(批量处理)
- 确保第一个PDF的区域设置完成(模板已保存);
- 切换到“全自动模式(批量处理)”,点击“批量处理所有PDF”;
- 确认后工具开始批量处理,顶部进度标签显示当前处理进度;
- 处理完成后会弹出提示,结果保存到PDF文件夹下的“PDF处理结果.xlsx”。
步骤5:查看结果
打开生成的Excel文件:
- OCR识别的文本直接显示在单元格中;
- 截图自动插入对应单元格,单元格大小已适配图片尺寸;
- 所有PDF的结果按行排列,列名为区域名称,第一列为PDF文件名。
五、总结与扩展
这款工具完美解决了PDF指定区域文本提取和截图汇总的痛点,兼顾“手动审核的精准性”和“批量处理的高效性”,适用于财务、行政、数据处理等多个场景。
- 工具核心价值:精准定位PDF区域+灵活的处理模式+智能Excel导出,解决批量PDF处理的效率问题;
- 核心技术栈:
PyMuPDF(PDF)+easyocr(OCR)+openpyxl(Excel)+tkinter(GUI); - 易用性设计:区域模板继承、快捷键、状态栏提示、自动清理临时文件,降低使用门槛。
如果日常工作中需要处理大量PDF的指定区域,这款工具能极大提升效率,建议根据实际需求微调日期格式化规则或OCR预处理参数,适配不同场景的PDF文件。
實用代碼工具:Python打造PDF選區OCR / 截圖批量處理工具(支持手動/全自動模式)
在日常辦公和開發中,我們經常會遇到這樣的需求:從大量PDF文件的指定區域提取文本(比如發票的日期、金額,報表的關鍵指標),或者對指定區域進行截圖並彙總到Excel中。手動逐個處理效率極低,而通用的PDF OCR工具又無法精準定位區域。代碼已開源在Github : 今天給大家分享一款我開發的Python工具——PDF區域OCR/截圖逐個處理工具,它完美解決了上述痛點,支持手動審核+全自動批量處理,還內置了區域拖動縮放、Excel自動導出等實用功能,並且配備完善的UI界面,使用門檻極低。下面詳細拆解它的功能和實現原理。
來源:https://blog.csdn.net/2403_87969572/article/details/156246552
抓取時間(ISO本地):2026-05-18 05:17:19
前言
在日常辦公和開發中,我們經常會遇到這樣的需求:從大量PDF文件的指定區域提取文本(比如發票的日期、金額,報表的關鍵指標),或者對指定區域進行截圖並彙總到Excel中。手動逐個處理效率極低,而通用的PDF OCR工具又無法精準定位區域。
代碼已開源在Github :https://github.com/ChenAI-TGF/PDF_SnapOCR
今天給大家分享一款我開發的Python工具——PDF區域OCR/截圖逐個處理工具,它完美解決了上述痛點,支持手動審核+全自動批量處理,還內置了區域拖動縮放、Excel自動導出等實用功能,並且配備完善的UI界面,使用門檻極低。下面詳細拆解它的功能和實現原理。先看一下整個程序的界面:
一、工具核心功能詳解
這款工具基於tkinter構建可視化界面,整合了PyMuPDF(PDF處理)、easyocr(OCR識別)、openpyxl(Excel導出)等庫,功能覆蓋從PDF區域選擇到結果彙總的全流程,具體如下:
1. 核心處理能力
| 功能點 | 詳細說明 |
|---|---|
| 精準區域OCR識別 | 可框選PDF任意區域進行文字提取,支持中文+英文識別;內置OpenCV圖像預處理(灰度化、自適應閾值、形態學操作),提升識別準確率 |
| 區域截圖保存 | 支持將框選區域保存為圖片,自動處理路徑和文件名衝突(UUID生成唯一名稱),避免特殊字符導致的保存失敗 |
| 自定義日期格式化 | 針對OCR識別的日期文本,可按不同規則自動格式化(例:20251209 → 2025年12月09日),用戶可自行設置,支持實時預覽格式化效果 |
2. 交互與操作體驗
區域可視化管理 :
框選的區域會在PDF預覽界面顯示(不同類型有不同顏色:OCR=藍色/截圖=綠色,選中=紅色)
支持拖動(邊線控制點)和縮放(右下角控制點),操作直觀
區域模板繼承
為第一個PDF設置的區域會自動保存為模板,切換後續PDF時自動繼承,無需重複框選;修改區域後模板實時更新,同時 支持拖動(邊線控制點)和縮放(右下角控制點)上一個PDF保存下來的模版
手動模式 - OCR結果審核與修改 :
處理當前PDF後,所有OCR識別結果會生成可編輯輸入框,支持手動審核、修正識別錯誤(截圖模式僅顯示保存路徑)
編輯後的結果實時生效,點擊「保存並下一個」可將修改後的內容寫入Excel,同時自動切換到下一個PDF文件
全自動模式 - 一鍵批量處理所有PDF :
切換到全自動模式後,基於已設置的區域模板,點擊「批量處理所有PDF」可後臺線程執行(不卡死界面),避免單線程卡頓
實時顯示處理進度(當前處理第N個/總數量 + 文件名),每處理10個文件自動保存一次Excel,防止數據丟失
處理完成後彈窗提示結果文件路徑,全程無需人工干預
結果導出 - Excel一體化存儲(文本+截圖) :
純文本結果(OCR識別/修改後內容)與截圖文件一體化寫入Excel,截圖自動插入對應單元格並適配尺寸(最大寬度150px,等比例縮放)
自動調整Excel列寬/行高適配內容,截圖區域單元格標註清晰,文本區域可直接編輯
結果文件保存在PDF文件夾下(命名:PDF處理結果.xlsx),關閉程序時才清理臨時截圖文件,確保Excel中圖片正常顯示
二、環境準備與安裝
使用前需安裝以下依賴庫,建議在虛擬環境中執行:
# 核心依賴
pip install pymupdf easyocr openpyxl
# 輔助依賴(數據處理/圖像/界面)
pip install pandas opencv-python pillow numpy tkinter
注意:
tkinter通常隨Python自帶,若缺失可根據系統安裝(如Ubuntu:sudo apt-get install python3-tk)。
三、代碼核心原理簡析
工具的代碼結構清晰,分為基礎配置、工具函數、主應用類、程序入口四部分,核心原理簡單拆解如下:
1. 界面構建:tkinter
- 使用
tkinter+ttk構建可視化界面,分為“頂部操作欄”(模式切換、按鈕、進度)、“頂右側操作欄”、“中間預覽區”(PDF畫布+區域設置)、“結果編輯區”、“底部狀態欄”;
- 畫布(Canvas)綁定鼠標事件(點擊/拖動/釋放),實現區域框選、拖動、縮放功能;
- 全局快捷鍵綁定(
bind_all),確保F2鍵在任意控件焦點下都能觸發。
2. PDF處理:PyMuPDF(fitz)
- 打開PDF並讀取第一頁(
fitz.open(pdf_path)[0]); - 計算Canvas與PDF頁面的縮放比例,實現PDF預覽的等比例適配;
- 通過
page.get_pixmap(clip=rect)提取指定區域的像素數據,轉換為OpenCV/PIL可處理的圖像格式。
3. OCR識別:easyocr + OpenCV
easyocr.Reader(['ch_sim', 'en'])初始化中英雙語識別器;- OpenCV對區域圖像預處理(灰度化、自適應閾值、形態學開運算),減少噪聲提升識別率;
- 自定義
format_date_text函數實現日期格式化,異常時返回原始文本,保證程序健壯性。
4. 批量處理:多線程
- 批量處理邏輯放在獨立線程(
threading.Thread)中執行,避免主線程(界面)卡死; - 通過
root.after(0, 回調函數)更新UI狀態(進度、提示),符合tkinter的線程安全規則。
5. Excel導出:openpyxl + pandas
pandas.DataFrame存儲OCR文本結果,dataframe_to_rows寫入Excel;openpyxl.drawing.image.Image插入截圖,自動縮放圖片尺寸並調整單元格大小;- 文本結果與截圖路徑分離存儲,確保Excel導出時文本和圖片一一對應。
四、工具使用教程(分步演示)
步驟1:啟動工具
運行代碼,若依賴齊全會彈出主界面,底部狀態欄顯示“就緒 - 請選擇PDF文件夾開始操作”。
步驟2:選擇PDF文件夾
點擊“選擇PDF文件夾”,選中存放待處理PDF的文件夾,工具會自動加載所有PDF文件(僅後綴為.pdf的文件),並顯示第一個PDF的預覽。
步驟3:設置處理區域(核心)
- 在PDF預覽畫布上按住鼠標左鍵拖動,框選需要處理的區域;
- 在右側“區域設置”面板:
- 輸入“區域名稱”(如“開票日期”“金額”);
- 選擇“處理方式”(OCR識別/截圖保存);
- 若選OCR,可勾選“是否進行日期格式化”,實時預覽格式化效果;
- 點擊“添加當前區域”,區域會顯示在畫布上,同時出現在“已選區域”列表中;
- 如需調整區域:點擊畫布上的區域(變紅),可拖動位置或拖動右下角控制點縮放。
步驟4:選擇處理模式
模式A:手動模式(逐個審核)
- 點擊“處理當前PDF”,工具會識別所有區域並顯示結果(OCR結果可直接編輯);
- 確認結果無誤後,點擊“保存並下一個”,結果寫入Excel並切換到下一個PDF;
- 重複上述步驟,直到所有PDF處理完成。
模式B:全自動模式(批量處理)
- 確保第一個PDF的區域設置完成(模板已保存);
- 切換到“全自動模式(批量處理)”,點擊“批量處理所有PDF”;
- 確認後工具開始批量處理,頂部進度標籤顯示當前處理進度;
- 處理完成後會彈出提示,結果保存到PDF文件夾下的“PDF處理結果.xlsx”。
步驟5:查看結果
打開生成的Excel文件:
- OCR識別的文本直接顯示在單元格中;
- 截圖自動插入對應單元格,單元格大小已適配圖片尺寸;
- 所有PDF的結果按行排列,列名為區域名稱,第一列為PDF文件名。
五、總結與擴展
這款工具完美解決了PDF指定區域文本提取和截圖彙總的痛點,兼顧“手動審核的精準性”和“批量處理的高效性”,適用於財務、行政、數據處理等多個場景。
- 工具核心價值:精準定位PDF區域+靈活的處理模式+智能Excel導出,解決批量PDF處理的效率問題;
- 核心技術棧:
PyMuPDF(PDF)+easyocr(OCR)+openpyxl(Excel)+tkinter(GUI); - 易用性設計:區域模板繼承、快捷鍵、狀態欄提示、自動清理臨時文件,降低使用門檻。
如果日常工作中需要處理大量PDF的指定區域,這款工具能極大提升效率,建議根據實際需求微調日期格式化規則或OCR預處理參數,適配不同場景的PDF文件。
Practical Tool: Python PDF Region OCR & Screenshot Batch Processor (Manual / Auto)
Region OCR;Box any area; Chinese + English; OpenCV preprocess (grayscale, adaptive threshold, morphology);Region screenshot;Save crops; UUID filenames; safe paths;Blue = OCR, green = screenshot, red = selected; drag edges, scale corner handle.
Captured at (local ISO): 2026-05-18 05:17:19
Preface
We often need text or crops from fixed regions across many PDFs—invoices, reports, KPIs. Manual work is slow; generic OCR cannot lock regions.
Open source: https://github.com/ChenAI-TGF/PDF_SnapOCR
This PDF region OCR/screenshot tool supports manual review and full-auto batch runs, drag/resize regions, and Excel export with embedded images. UI-first workflow:
I. Core Features
Built with tkinter, PyMuPDF, easyocr, openpyxl:
1. Processing
| Feature | Details |
|---|---|
| Region OCR | Box any area; Chinese + English; OpenCV preprocess (grayscale, adaptive threshold, morphology) |
| Region screenshot | Save crops; UUID filenames; safe paths |
| Date formatting | Rules like 20251209 → 2025年12月09日; live preview |
2. UX
Visual regions
Blue = OCR, green = screenshot, red = selected; drag edges, scale corner handle.
Template inheritance
First PDF defines a template reused on later files; edits update the template.
Manual mode
Editable OCR fields after each PDF; “Save & next” writes Excel and advances.
Auto mode
Background thread batch; progress N/total; autosave Excel every 10 files; completion dialog.
Excel export
Text + inline images (max width 150 px); column/row sizing; PDF处理结果.xlsx beside PDFs; temp images kept until exit.
II. Install
# 核心依赖
pip install pymupdf easyocr openpyxl
# 辅助依赖(数据处理/图像/界面)
pip install pandas opencv-python pillow numpy tkinter
tkinteris usually bundled; on Ubuntu:sudo apt-get install python3-tk.
III. Architecture Sketch
1. UI: tkinter
Toolbar, preview canvas, result panel, status bar; mouse events for select/drag/resize; global F2 via bind_all.
2. PDF: PyMuPDF
Open page 0; scale canvas to page; page.get_pixmap(clip=rect) for crops.
3. OCR: easyocr + OpenCV
Reader(['ch_sim','en']); preprocess pipeline; format_date_text with fallback to raw text.
4. Batch: threading
Worker thread + root.after(0, ...) for thread-safe UI updates.
5. Excel: openpyxl + pandas
DataFrame rows; Image inserts with cell sizing.
IV. Usage Steps
Step 1: Launch
Run the script; status: ready—pick a PDF folder.
Step 2: Pick folder
Loads all .pdf files; shows first preview.
Step 3: Define regions
- Drag on canvas.
- Name region; choose OCR or screenshot; optional date format.
- “Add region”; select (red) to move/resize.
Step 4: Mode
Manual: Process current → edit → Save & next.
Auto: Template from first PDF → batch all → Excel path popup.
Step 5: Results
Excel rows per PDF; columns per region; images in cells.
V. Summary
Value: precise regions + manual/auto modes + Excel with images.
Stack: PyMuPDF + easyocr + openpyxl + tkinter.
UX: templates, shortcuts, status bar, temp file cleanup.
Tune date rules and OCR preprocess for your PDF types.