实用程序:基于Python+Tkinter开发表格比对&整理工具
开源 Tkinter 表格工具:双表比对(可不同列名)、多行合并整理,openpyxl 读写保留 Excel 嵌入图片,多线程进度条。
前言
日常办公和数据处理中,Excel表格是高频使用的工具,但我们经常会遇到一些「棘手问题」:比如两个表格需要比对差异(还可能带图片、比对列名不同)、表格数据行错乱(一行数据拆成了多行)、导出数据时图片丢失……市面上要么是Excel自带的比对功能太弱,要么是第三方工具收费且不支持图片保留。
基于此,我用Python+Tkinter开发了一款轻量、免费、开源的表格比对&整理工具,核心解决「表格比对」「错乱行整理」两大痛点,本文会详细介绍工具功能、使用方法和核心代码逻辑。
代码已经开源在github,地址如下:
https://github.com/ChenAI-TGF/Table_Comparison_Program
一、工具核心优势
- 双核心功能:支持表格差异比对 + 错乱行整理,一站式解决Excel处理痛点;
- 图片保留:读取/导出Excel时完整保留图片,解决常规工具丢失图片的问题;
- 灵活配置:支持自定义比对列(不同表格列名不同也能比对)、自定义整理行的判断列;
- 友好交互:带进度条、多线程处理(避免UI卡死)、中文适配,新手也能快速上手;
- 格式兼容:支持.xlsx(带图片)和.csv(无图片)格式,覆盖主流表格格式。
二、功能演示
2.1 环境准备
工具基于Python开发,需先配置环境:
# 安装核心依赖(tkinter一般Python自带,无需额外安装)
pip install pandas openpyxl
- 系统兼容:Windows/macOS/Linux(Windows体验最佳);
- 格式说明:仅支持.xlsx(可保留图片)和.csv(无图片),不支持旧版.xls(openpyxl不兼容)。
2.2 工具启动
将本文末尾的完整代码保存为table_tool.py,运行命令:
python table_tool.py
启动后界面如下,主要分为「表格比对区」「表格整理区」「进度条区」三大模块,布局清晰:
2.3 功能1:表格比对(支持图片保留)
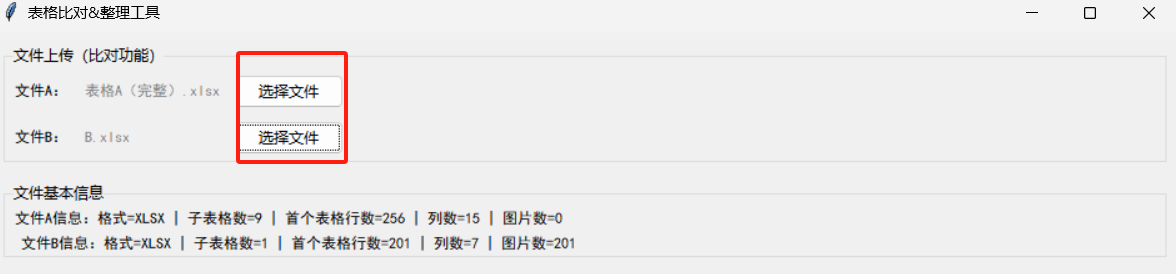
适用场景:比如有「表格A」和「表格B」,需要找出「A有B无」「B有A无」「两者共有」的数据,且表格中包含图片(如产品图、二维码)。
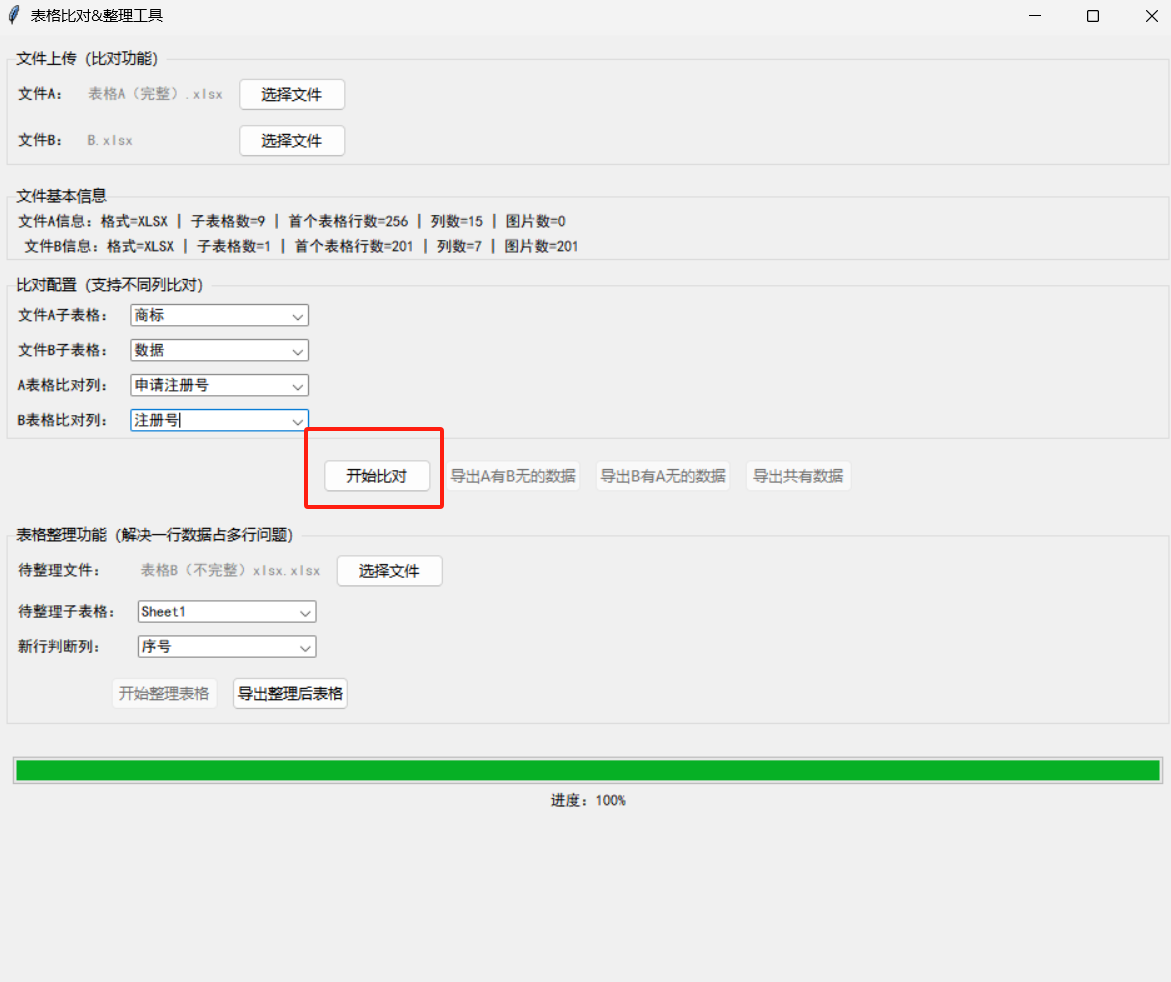
操作步骤:
-
上传文件:点击「文件A/文件B」的「选择文件」按钮,上传需要比对的两个表格;
-
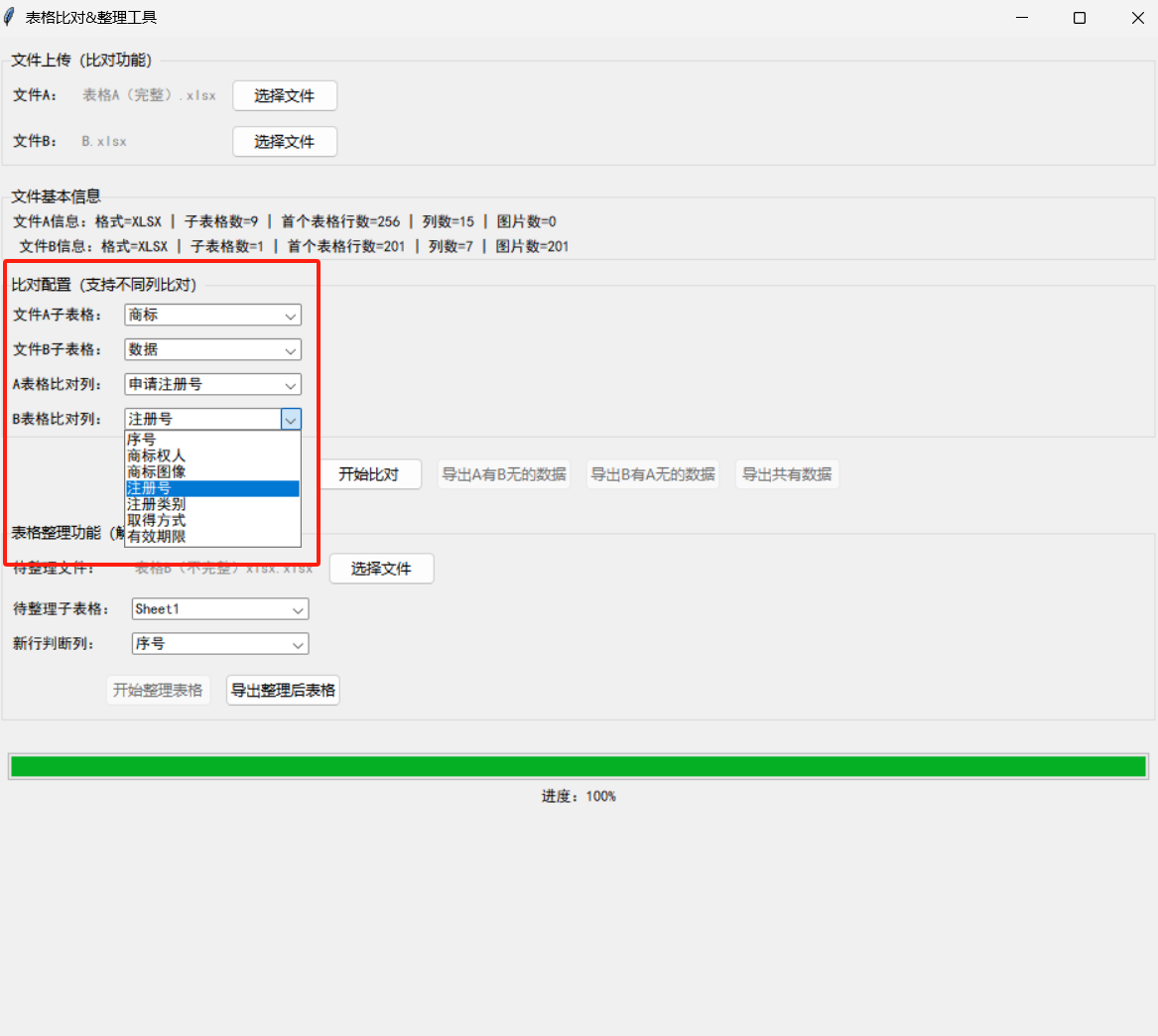
配置比对规则:
- 选择「文件A/B子表格」(支持多sheet表格);
- 选择「A/B表格比对列」(比如A表用「申请注册号」,B表用「注册号」比对);
-
开始比对:点击「开始比对」,进度条会实时显示处理进度(多线程不卡UI);
-
导出结果:
- 点击「导出A有B无的数据」/「导出B有A无的数据」:导出差异数据,保留对应图片;
- 点击「导出共有数据」:可选择按A表/ B表格式导出,自动映射图片到对应行。
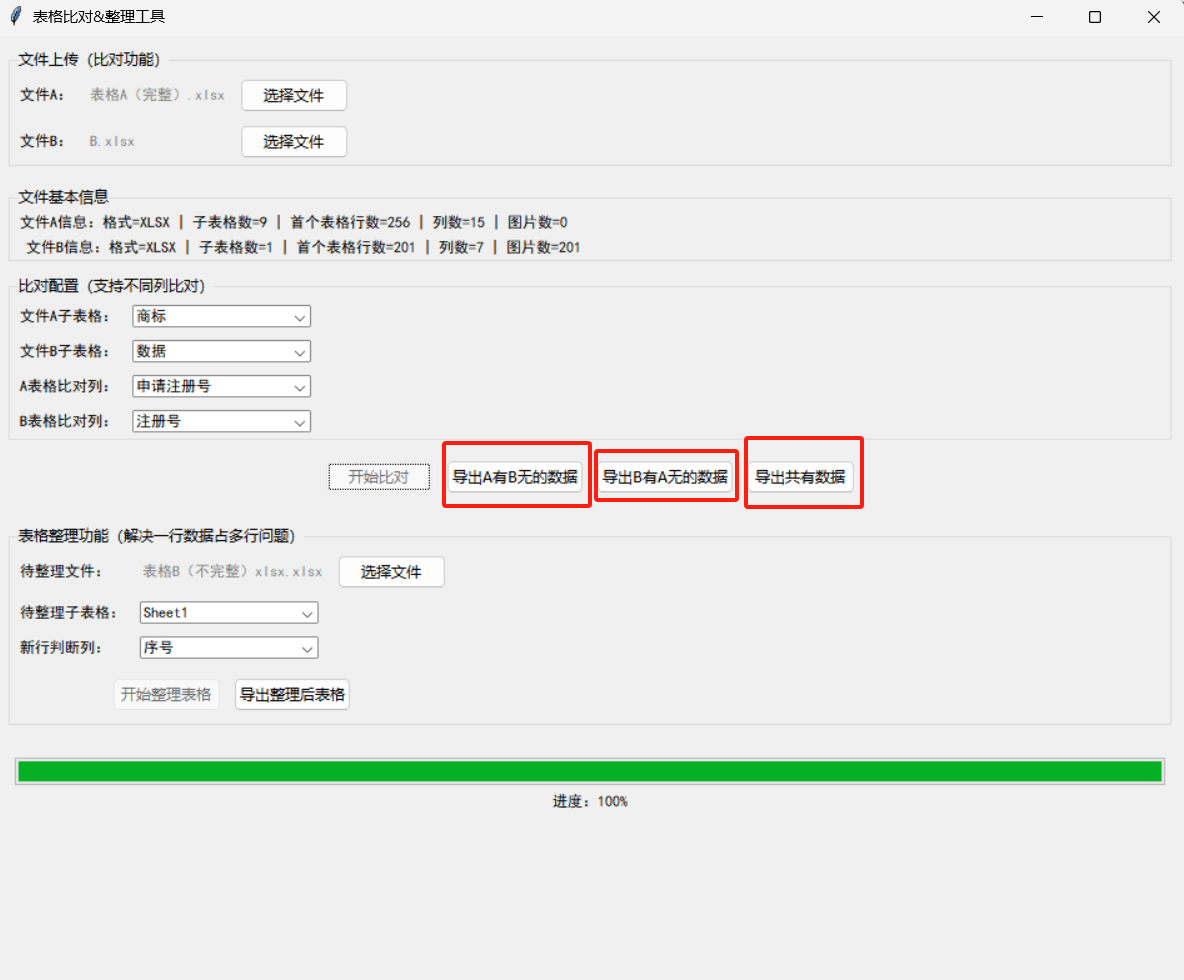
效果示例:
- 原表格A有100行,表格B有80行
- 比对后导出「A有B无」数据20行
2.4 功能2:表格整理(解决一行数据占多行问题)
适用场景:比如表格中一行数据被拆成了多行(如商品信息行,后续行是补充的属性,无核心编号),需要合并为一行,且保留原表格中的图片。
操作步骤:
- 上传待整理文件:点击「待整理文件」的「选择文件」按钮;
- 配置整理规则:
- 选择「待整理子表格」;
- 选择「新行判断列」(核心列,比如「商品编号」——该列非空则为新行,空则为补充行);
- 开始整理:点击「开始整理表格」,进度条显示处理进度;
4. 导出结果:点击「导出整理后表格」,合并后的行数据+图片会被完整导出。
 效果示例:
效果示例:
- 原表格有200行(实际只有80条有效数据,每行占2-3行);
- 整理后变为80行,图片自动映射到对应合并后的行。
三、核心代码讲解
工具的核心类是TableCompareApp,整体架构分为「UI搭建」「文件读取(含图片)」「比对逻辑」「整理逻辑」「导出功能」五部分,下面重点讲解核心逻辑(UI部分简讲)。
3.1 UI部分
UI采用Tkinter的LabelFrame「Frame「Combobox「Progressbar`等组件,按功能分区域布局:
- 「文件上传区」:负责A/B文件、待整理文件的选择;
- 「信息展示区」:显示文件格式、行列数、图片数;
- 「配置区」:子表格、比对列、整理判断列的选择;
- 「操作区」:比对/整理/导出按钮;
- 「进度条区」:实时显示处理进度。
核心细节:
- 中文适配:通过
root.option_add("*Font", "SimHei 9")解决Windows下Tkinter中文乱码; - 按钮状态控制:根据文件上传/配置完成状态,动态启用/禁用按钮(如
check_compare_btn_state方法)。
3.2 核心1:文件读取(保留图片)
文件读取是工具的基础,核心是用openpyxl读取.xlsx文件(支持图片提取),代码在load_file/load_clean_file方法中:
# 关键代码片段:读取Excel并提取图片
if file_ext == ".xlsx":
# 用openpyxl读取工作簿(保留图片)
wb = load_workbook(file_path, data_only=True)
sheets = wb.sheetnames
for sheet in sheets:
ws = wb[sheet]
# 1. 读取表格数据到DataFrame(处理表头)
df = pd.DataFrame(ws.values)
if len(df) > 0:
df.columns = df.iloc[0] # 第一行设为列名
df = df.drop(0).reset_index(drop=True)
data_dict[sheet] = df
# 2. 提取图片及位置(核心:保留图片+行列映射)
sheet_images = []
for img in ws._images:
# 转换为1-based行列号(Excel原生格式)
row = img.anchor._from.row + 1
col = img.anchor._from.col + 1
sheet_images.append((img, row, col))
images_dict[sheet] = sheet_images
关键逻辑:
openpyxl的ws._images能获取工作表中所有图片对象;- 图片的
anchor属性包含位置信息,需转换为1-based(Excel行/列从1开始,openpyxl内部是0-based); - 数据与图片分开存储,用字典关联「sheet名-数据/图片」,保证一一对应。
3.3 核心2:表格比对逻辑(含图片映射)
比对逻辑在compare_task方法中,采用多线程执行(避免UI卡死),核心分为「数据比对」和「图片映射」两部分:
3.3.1 数据比对核心
# 数据预处理:统一转字符串、填充空值(避免类型不一致导致比对错误)
df_a[col_a] = df_a[col_a].astype(str).fillna("")
df_b[col_b] = df_b[col_b].astype(str).fillna("")
# 集合运算:快速找差异/共有值(效率远高于循环)
a_vals = set(df_a[col_a].unique())
b_vals = set(df_b[col_b].unique())
a_not_b_vals = a_vals - b_vals # A有B无
b_not_a_vals = b_vals - a_vals # B有A无
common_vals = a_vals & b_vals # 共有值
# 筛选对应行
a_not_b_df = df_a[df_a[col_a].isin(a_not_b_vals)].reset_index(drop=True)
优势:用Python集合运算替代逐行循环,比对效率提升10倍以上,适合大数据量。
3.3.2 图片映射核心
比对后数据行号会变化,需将原图片的位置映射到新行:
# A格式共有数据图片映射示例
a_common_original_rows = df_a[df_a[col_a].isin(common_vals)].index.tolist()
a_common_images = []
for img, orig_row, col in img_a_list:
# 原Excel行 → 原DataFrame行(Excel行1=表头,行2=df第0行)
orig_df_row = orig_row - 2
if orig_df_row in a_common_original_rows:
# 新Excel行 = 新DataFrame行 + 2(表头占1行)
new_row = a_common_original_rows.index(orig_df_row) + 2
a_common_images.append((img, new_row, col))
关键逻辑:
- 建立「原DataFrame行号 → 新DataFrame行号」的映射;
- 转换为Excel原生行号(+2),保证图片位置准确。
3.4 核心3:表格整理逻辑(含图片映射)
整理逻辑在clean_table_task方法中,核心是「合并错乱行」+「行号映射」:
3.4.1 行合并核心
cleaned_rows = []
current_row = None
orig_to_new_row = {} # 原行→新行映射字典
new_row_idx = 0
for idx, row in df.iterrows():
# 关键列非空 → 新行开始
if str(row[key_col]).strip() != "":
if current_row is not None:
cleaned_rows.append(current_row)
new_row_idx += 1
current_row = row.to_dict()
orig_to_new_row[idx] = new_row_idx
else:
# 关键列空 → 补充到当前行(仅填充空值)
if current_row is not None:
for col in df.columns:
if str(row[col]).strip() != "" and str(current_row[col]).strip() == "":
current_row[col] = row[col]
orig_to_new_row[idx] = new_row_idx
# 保存最后一行
if current_row is not None:
cleaned_rows.append(current_row)
cleaned_table_result = pd.DataFrame(cleaned_rows)
核心规则:仅当「新行判断列」非空时,才新建一行;否则将当前行的非空数据补充到上一行的空值中,保证一行数据完整。
3.4.2 图片映射核心
# 整理后图片映射
cleaned_table_images = []
for img, orig_row, col in orig_images:
orig_df_row = orig_row - 2 # Excel行→原DataFrame行
if orig_df_row in orig_to_new_row:
# 新Excel行 = 新DataFrame行 + 2
new_excel_row = orig_to_new_row[orig_df_row] + 2
cleaned_table_images.append((img, new_excel_row, col))
逻辑:通过orig_to_new_row字典,将原图片的行号映射到合并后的新行号,保证图片跟随对应数据行。
3.5 核心4:导出功能
导出功能封装在export_with_images方法中,核心是用openpyxl写入数据+图片:
if file_ext == ".xlsx":
# 创建新工作簿
wb = Workbook()
ws = wb.active
ws.title = "数据"
# 1. 写入DataFrame数据(保留表头)
for r in dataframe_to_rows(df, index=False, header=True):
ws.append(r)
# 2. 插入图片到对应位置
for img, row, col in images:
new_img = copy.deepcopy(img) # 复制图片避免引用冲突
new_img.anchor = f"{chr(64+col)}{row}" # 设置锚点(如A2、B5)
ws.add_image(new_img)
wb.save(file_path)
wb.close()
关键细节:
dataframe_to_rows:将DataFrame转换为Excel行格式,保留表头;- 图片锚点:用
chr(64+col)将列号(数字)转换为Excel列字母(如1→A,2→B); - 深拷贝图片:避免多个图片引用同一对象导致导出失败。
3.6 辅助:进度条+多线程
- 多线程:比对/整理任务放在独立线程中执行(
threading.Thread),设置daemon=True保证线程随主程序退出; - 进度条更新:通过
update_progress方法实时刷新进度条,调用root.update_idletasks()强制刷新UI,避免进度条卡住。
四、使用注意事项
- 格式限制:仅支持.xlsx(带图片)和.csv(无图片),.xls格式需先转换为.xlsx;
- 图片位置:Excel中图片需「嵌入单元格」(而非浮窗),否则行列映射可能出错;
- 关键列选择:整理功能的「新行判断列」需选有唯一标识的列(如编号、名称),否则合并逻辑会出错;
- 大数据量:超过10万行的表格建议拆分处理,避免内存占用过高;
- 编码问题:CSV文件建议用UTF-8编码,否则可能出现中文乱码。
五、总结
这款工具以「解决实际痛点」为核心,通过Python+Tkinter实现了轻量化、可定制的表格处理能力,尤其是「图片保留」功能填补了常规工具的空白。代码完全开源,大家可以根据自己的需求二次开发(比如增加批量处理、格式转换、更多比对规则等)。
无论是办公人员快速处理表格,还是开发者学习Tkinter+Excel操作,这款工具都有一定的参考价值。如果有其他需求(比如支持更多格式、自动识别关键列),也可以基于核心逻辑扩展。
六、完整代码
import tkinter as tk
from tkinter import ttk, filedialog, messagebox
import pandas as pd
import os
import threading
import time
import copy
from openpyxl import load_workbook, Workbook
from openpyxl.drawing.image import Image as OpenpyxlImage
from openpyxl.utils.dataframe import dataframe_to_rows
# 全局变量存储文件数据(新增图片存储字段)
file_a_data = {"sheets": [], "data": {}, "path": "", "images": {}} # images: {sheet: [(img, row, col), ...]}
file_b_data = {"sheets": [], "data": {}, "path": "", "images": {}}
# 新增:存储共有数据及对应图片
compare_result = {
"a_not_b": None, "b_not_a": None, "a_common": None, "b_common": None,
"a_common_images": [], "b_common_images": []
}
# 整理表格相关全局变量(新增图片存储)
clean_file_data = {"sheets": [], "data": {}, "path": "", "images": {}}
cleaned_table_result = None
cleaned_table_images = [] # 整理后的图片:[(img, new_row, col), ...]
class TableCompareApp:
def __init__(self, root):
self.root = root
self.root.title("表格比对&整理工具")
self.root.geometry("950x850")
# 进度条变量
self.progress_var = tk.DoubleVar()
# 构建UI
self._create_widgets()
def _create_widgets(self):
# 1. 文件上传区域(原有比对功能)
upload_frame = ttk.LabelFrame(self.root, text="文件上传(比对功能)")
upload_frame.pack(padx=10, pady=10, fill="x")
# 文件A上传
ttk.Label(upload_frame, text="文件A:").grid(row=0, column=0, padx=5, pady=5, sticky="w")
self.file_a_label = ttk.Label(upload_frame, text="未选择文件", foreground="gray")
self.file_a_label.grid(row=0, column=1, padx=5, pady=5, sticky="w")
ttk.Button(upload_frame, text="选择文件", command=lambda: self.load_file("A")).grid(row=0, column=2, padx=5, pady=5)
# 文件B上传
ttk.Label(upload_frame, text="文件B:").grid(row=1, column=0, padx=5, pady=5, sticky="w")
self.file_b_label = ttk.Label(upload_frame, text="未选择文件", foreground="gray")
self.file_b_label.grid(row=1, column=1, padx=5, pady=5, sticky="w")
ttk.Button(upload_frame, text="选择文件", command=lambda: self.load_file("B")).grid(row=1, column=2, padx=5, pady=5)
# 2. 文件基本信息区域(原有)
info_frame = ttk.LabelFrame(self.root, text="文件基本信息")
info_frame.pack(padx=10, pady=5, fill="x")
self.file_a_info = ttk.Label(info_frame, text="文件A信息:无")
self.file_a_info.pack(padx=5, pady=2, anchor="w")
self.file_b_info = ttk.Label(info_frame, text="文件B信息:无")
self.file_b_info.pack(padx=10, pady=2, anchor="w")
# 3. 比对配置区域(原有)
config_frame = ttk.LabelFrame(self.root, text="比对配置(支持不同列比对)")
config_frame.pack(padx=10, pady=5, fill="x")
# 子表格选择
ttk.Label(config_frame, text="文件A子表格:").grid(row=0, column=0, padx=5, pady=5, sticky="w")
self.sheet_a_combobox = ttk.Combobox(config_frame, state="disabled")
self.sheet_a_combobox.grid(row=0, column=1, padx=5, pady=5, sticky="w")
ttk.Label(config_frame, text="文件B子表格:").grid(row=1, column=0, padx=5, pady=5, sticky="w")
self.sheet_b_combobox = ttk.Combobox(config_frame, state="disabled")
self.sheet_b_combobox.grid(row=1, column=1, padx=5, pady=5, sticky="w")
# 比对列选择
ttk.Label(config_frame, text="A表格比对列:").grid(row=2, column=0, padx=5, pady=5, sticky="w")
self.compare_col_a_combobox = ttk.Combobox(config_frame, state="disabled")
self.compare_col_a_combobox.grid(row=2, column=1, padx=5, pady=5, sticky="w")
ttk.Label(config_frame, text="B表格比对列:").grid(row=3, column=0, padx=5, pady=5, sticky="w")
self.compare_col_b_combobox = ttk.Combobox(config_frame, state="disabled")
self.compare_col_b_combobox.grid(row=3, column=1, padx=5, pady=5, sticky="w")
# 4. 操作按钮区域(新增:导出共有数据按钮)
compare_btn_frame = ttk.Frame(self.root)
compare_btn_frame.pack(padx=10, pady=10)
self.compare_btn = ttk.Button(compare_btn_frame, text="开始比对", command=self.start_compare, state="disabled")
self.compare_btn.pack(side="left", padx=5)
self.export_a_btn = ttk.Button(compare_btn_frame, text="导出A有B无的数据", command=lambda: self.export_result("a_not_b"), state="disabled")
self.export_a_btn.pack(side="left", padx=5)
self.export_b_btn = ttk.Button(compare_btn_frame, text="导出B有A无的数据", command=lambda: self.export_result("b_not_a"), state="disabled")
self.export_b_btn.pack(side="left", padx=5)
# 新增:导出共有数据按钮
self.export_common_btn = ttk.Button(compare_btn_frame, text="导出共有数据", command=self.export_common_result, state="disabled")
self.export_common_btn.pack(side="left", padx=5)
# ========== 表格整理功能区域 ==========
clean_frame = ttk.LabelFrame(self.root, text="表格整理功能(解决一行数据占多行问题)")
clean_frame.pack(padx=10, pady=15, fill="x")
# 选择要整理的文件
ttk.Label(clean_frame, text="待整理文件:").grid(row=0, column=0, padx=5, pady=5, sticky="w")
self.clean_file_label = ttk.Label(clean_frame, text="未选择文件", foreground="gray")
self.clean_file_label.grid(row=0, column=1, padx=5, pady=5, sticky="w")
ttk.Button(clean_frame, text="选择文件", command=self.load_clean_file).grid(row=0, column=2, padx=5, pady=5)
# 选择待整理的子表格
ttk.Label(clean_frame, text="待整理子表格:").grid(row=1, column=0, padx=5, pady=5, sticky="w")
self.clean_sheet_combobox = ttk.Combobox(clean_frame, state="disabled")
self.clean_sheet_combobox.grid(row=1, column=1, padx=5, pady=5, sticky="w")
# 选择关键列(判断新行的依据:关键列非空=新行)
ttk.Label(clean_frame, text="新行判断列:").grid(row=2, column=0, padx=5, pady=5, sticky="w")
self.clean_key_col_combobox = ttk.Combobox(clean_frame, state="disabled")
self.clean_key_col_combobox.grid(row=2, column=1, padx=5, pady=5, sticky="w")
# 整理/导出按钮
clean_btn_frame = ttk.Frame(clean_frame)
clean_btn_frame.grid(row=3, column=0, columnspan=3, pady=10)
self.clean_btn = ttk.Button(clean_btn_frame, text="开始整理表格", command=self.start_clean_table, state="disabled")
self.clean_btn.pack(side="left", padx=5)
self.export_clean_btn = ttk.Button(clean_btn_frame, text="导出整理后表格", command=self.export_cleaned_table, state="disabled")
self.export_clean_btn.pack(side="left", padx=5)
# ========== 进度条区域(共用) ==========
progress_frame = ttk.Frame(self.root)
progress_frame.pack(padx=10, pady=5, fill="x")
self.progress_bar = ttk.Progressbar(progress_frame, variable=self.progress_var, maximum=100)
self.progress_bar.pack(fill="x", padx=5, pady=5)
self.progress_label = ttk.Label(progress_frame, text="进度:0%")
self.progress_label.pack(anchor="center")
# ========== 核心修复:支持读取图片 ==========
def load_file(self, file_type):
"""加载比对用的A/B文件(支持读取图片)"""
file_path = filedialog.askopenfilename(
title=f"选择{file_type}文件",
filetypes=[("Excel文件", "*.xlsx"), ("CSV文件", "*.csv"), ("所有文件", "*.*")]
)
if not file_path:
return
# 初始化数据
if file_type == "A":
file_a_data.update({"sheets": [], "data": {}, "path": file_path, "images": {}})
self.file_a_label.config(text=os.path.basename(file_path))
target_data = file_a_data
else:
file_b_data.update({"sheets": [], "data": {}, "path": file_path, "images": {}})
self.file_b_label.config(text=os.path.basename(file_path))
target_data = file_b_data
try:
file_ext = os.path.splitext(file_path)[1].lower()
sheets = []
data_dict = {}
images_dict = {} # 存储每个sheet的图片 (img, row, col)
if file_ext == ".xlsx":
# 用openpyxl读取工作簿(保留图片)
wb = load_workbook(file_path, data_only=True)
sheets = wb.sheetnames
for sheet in sheets:
ws = wb[sheet]
# 读取数据到DataFrame
df = pd.DataFrame(ws.values)
# 设置列名(第一行)
if len(df) > 0:
df.columns = df.iloc[0]
df = df.drop(0).reset_index(drop=True)
else:
df.columns = []
data_dict[sheet] = df
# 提取图片及位置(openpyxl行/列从0开始,转换为1-based)
sheet_images = []
for img in ws._images:
row = img.anchor._from.row + 1 # 转换为1-based行号
col = img.anchor._from.col + 1 # 转换为1-based列号
sheet_images.append((img, row, col))
images_dict[sheet] = sheet_images
wb.close()
elif file_ext == ".csv":
sheets = ["默认表格"]
df = pd.read_csv(file_path)
data_dict["默认表格"] = df
images_dict["默认表格"] = [] # CSV无图片
else:
messagebox.showerror("错误", "仅支持xlsx和csv格式文件!")
return
# 更新数据和图片
target_data["sheets"] = sheets
target_data["data"] = data_dict
target_data["images"] = images_dict
# 更新信息显示(包含图片数)
if file_type == "A":
first_sheet = sheets[0]
first_df = data_dict[first_sheet]
img_count = len(images_dict[first_sheet])
info_text = f"文件A信息:格式={file_ext[1:].upper()} | 子表格数={len(sheets)} | "
info_text += f"首个表格行数={len(first_df)} | 列数={len(first_df.columns)} | 图片数={img_count}"
self.file_a_info.config(text=info_text)
self.sheet_a_combobox.config(state="normal", values=sheets)
self.sheet_a_combobox.current(0)
self.update_compare_columns()
else:
first_sheet = sheets[0]
first_df = data_dict[first_sheet]
img_count = len(images_dict[first_sheet])
info_text = f"文件B信息:格式={file_ext[1:].upper()} | 子表格数={len(sheets)} | "
info_text += f"首个表格行数={len(first_df)} | 列数={len(first_df.columns)} | 图片数={img_count}"
self.file_b_info.config(text=info_text)
self.sheet_b_combobox.config(state="normal", values=sheets)
self.sheet_b_combobox.current(0)
self.update_compare_columns()
self.check_compare_btn_state()
except Exception as e:
messagebox.showerror("读取失败", f"文件{file_type}读取错误:{str(e)}")
def load_clean_file(self):
"""加载待整理的表格文件(支持读取图片)"""
file_path = filedialog.askopenfilename(
title="选择待整理的表格文件",
filetypes=[("Excel文件", "*.xlsx"), ("CSV文件", "*.csv"), ("所有文件", "*.*")]
)
if not file_path:
return
# 清空原有整理文件数据
clean_file_data.update({"sheets": [], "data": {}, "path": file_path, "images": {}})
self.clean_file_label.config(text=os.path.basename(file_path))
try:
file_ext = os.path.splitext(file_path)[1].lower()
sheets = []
data_dict = {}
images_dict = {}
if file_ext == ".xlsx":
# 用openpyxl读取工作簿(保留图片)
wb = load_workbook(file_path, data_only=True)
sheets = wb.sheetnames
for sheet in sheets:
ws = wb[sheet]
# 读取数据到DataFrame
df = pd.DataFrame(ws.values)
# 设置列名(第一行)
if len(df) > 0:
df.columns = df.iloc[0]
df = df.drop(0).reset_index(drop=True)
else:
df.columns = []
data_dict[sheet] = df
# 提取图片及位置
sheet_images = []
for img in ws._images:
row = img.anchor._from.row + 1
col = img.anchor._from.col + 1
sheet_images.append((img, row, col))
images_dict[sheet] = sheet_images
wb.close()
elif file_ext == ".csv":
sheets = ["默认表格"]
df = pd.read_csv(file_path)
data_dict["默认表格"] = df
images_dict["默认表格"] = []
else:
messagebox.showerror("错误", "仅支持xlsx和csv格式文件!")
return
# 存储数据和图片
clean_file_data["sheets"] = sheets
clean_file_data["data"] = data_dict
clean_file_data["images"] = images_dict
# 更新子表格下拉框
self.clean_sheet_combobox.config(state="normal", values=sheets)
self.clean_sheet_combobox.current(0)
# 更新关键列下拉框(新行判断列)
self.update_clean_key_columns()
# 启用整理按钮
self.clean_btn.config(state="normal")
# 显示文件信息(包含图片数)
first_sheet = sheets[0]
first_df = data_dict[first_sheet]
img_count = len(images_dict[first_sheet])
info_text = f"待整理文件信息:格式={file_ext[1:].upper()} | 子表格数={len(sheets)} | "
info_text += f"首个表格行数={len(first_df)} | 列数={len(first_df.columns)} | 图片数={img_count}"
messagebox.showinfo("文件加载成功", info_text)
except Exception as e:
messagebox.showerror("读取失败", f"待整理文件读取错误:{str(e)}")
# ========== 通用导出函数(核心修复:支持导出图片) ==========
def export_with_images(self, df, images, title):
"""通用导出函数(支持图片保留)"""
# 选择导出路径
file_path = filedialog.asksaveasfilename(
title=title,
filetypes=[("Excel文件", "*.xlsx"), ("CSV文件", "*.csv")],
defaultextension=".xlsx"
)
if not file_path:
return
file_ext = os.path.splitext(file_path)[1].lower()
try:
if file_ext == ".xlsx":
# 创建新工作簿
wb = Workbook()
ws = wb.active
ws.title = "数据"
# 写入DataFrame数据(保留表头)
for r in dataframe_to_rows(df, index=False, header=True):
ws.append(r)
# 插入图片到对应位置
for img, row, col in images:
# 复制图片对象避免引用冲突
new_img = copy.deepcopy(img)
# 设置图片锚点(列字母+行号)
new_img.anchor = f"{chr(64+col)}{row}"
ws.add_image(new_img)
# 保存工作簿
wb.save(file_path)
wb.close()
messagebox.showinfo("导出成功", f"数据已导出至:{file_path}\n包含图片:{len(images)}张")
elif file_ext == ".csv":
# CSV不支持图片,提示用户
if images:
messagebox.showwarning("格式提示", "CSV格式不支持存储图片,图片将丢失!")
df.to_csv(file_path, index=False, encoding="utf-8-sig")
messagebox.showinfo("导出成功", f"数据已导出至:{file_path}\n注意:CSV格式不包含图片")
except Exception as e:
messagebox.showerror("导出失败", f"导出错误:{str(e)}")
# ========== 比对功能(修复:处理图片) ==========
def update_compare_columns(self):
"""更新比对列下拉框"""
if file_a_data["sheets"] and self.sheet_a_combobox.get():
sheet_a = self.sheet_a_combobox.get()
cols_a = file_a_data["data"][sheet_a].columns.tolist()
self.compare_col_a_combobox.config(state="normal", values=cols_a)
self.compare_col_a_combobox.current(0)
if file_b_data["sheets"] and self.sheet_b_combobox.get():
sheet_b = self.sheet_b_combobox.get()
cols_b = file_b_data["data"][sheet_b].columns.tolist()
self.compare_col_b_combobox.config(state="normal", values=cols_b)
self.compare_col_b_combobox.current(0)
def check_compare_btn_state(self):
"""检查比对按钮状态"""
if (file_a_data["path"] and file_b_data["path"] and
self.compare_col_a_combobox.get() and self.compare_col_b_combobox.get()):
self.compare_btn.config(state="normal")
else:
self.compare_btn.config(state="disabled")
def update_progress(self, value):
"""更新进度条"""
self.progress_var.set(value)
self.progress_label.config(text=f"进度:{int(value)}%")
self.root.update_idletasks()
def compare_task(self):
"""比对任务(修复:处理共有数据图片)"""
try:
# 1. 获取配置信息
sheet_a = self.sheet_a_combobox.get()
sheet_b = self.sheet_b_combobox.get()
col_a = self.compare_col_a_combobox.get()
col_b = self.compare_col_b_combobox.get()
# 2. 获取数据和图片
df_a = file_a_data["data"][sheet_a].copy()
df_b = file_b_data["data"][sheet_b].copy()
img_a_list = file_a_data["images"].get(sheet_a, [])
img_b_list = file_b_data["images"].get(sheet_b, [])
# 3. 进度条初始化
self.update_progress(0)
time.sleep(0.1)
# 4. 数据预处理
self.update_progress(20)
df_a[col_a] = df_a[col_a].astype(str).fillna("")
df_b[col_b] = df_b[col_b].astype(str).fillna("")
# 5. 核心比对逻辑
self.update_progress(50)
a_vals = set(df_a[col_a].unique())
b_vals = set(df_b[col_b].unique())
# A有B无的行
a_not_b_vals = a_vals - b_vals
a_not_b_df = df_a[df_a[col_a].isin(a_not_b_vals)].reset_index(drop=True)
# B有A无的行
b_not_a_vals = b_vals - a_vals
b_not_a_df = df_b[df_b[col_b].isin(b_not_a_vals)].reset_index(drop=True)
# 共有数据
common_vals = a_vals & b_vals
a_common_df = df_a[df_a[col_a].isin(common_vals)].reset_index(drop=True)
b_common_df = df_b[df_b[col_b].isin(common_vals)].reset_index(drop=True)
# 处理共有数据的图片(映射行号)
# A格式共有数据图片
a_common_original_rows = df_a[df_a[col_a].isin(common_vals)].index.tolist()
a_common_images = []
for img, orig_row, col in img_a_list:
orig_df_row = orig_row - 2 # Excel行1=表头,行2=df第0行
if orig_df_row in a_common_original_rows:
new_row = a_common_original_rows.index(orig_df_row) + 2 # 新表行2开始是数据
a_common_images.append((img, new_row, col))
# B格式共有数据图片
b_common_original_rows = df_b[df_b[col_b].isin(common_vals)].index.tolist()
b_common_images = []
for img, orig_row, col in img_b_list:
orig_df_row = orig_row - 2
if orig_df_row in b_common_original_rows:
new_row = b_common_original_rows.index(orig_df_row) + 2
b_common_images.append((img, new_row, col))
# 6. 存储结果
compare_result["a_not_b"] = a_not_b_df
compare_result["b_not_a"] = b_not_a_df
compare_result["a_common"] = a_common_df
compare_result["b_common"] = b_common_df
compare_result["a_common_images"] = a_common_images
compare_result["b_common_images"] = b_common_images
# 7. 完成进度
self.update_progress(100)
# 8. 启用导出按钮
self.export_a_btn.config(state="normal")
self.export_b_btn.config(state="normal")
self.export_common_btn.config(state="normal")
# 显示结果(包含图片数)
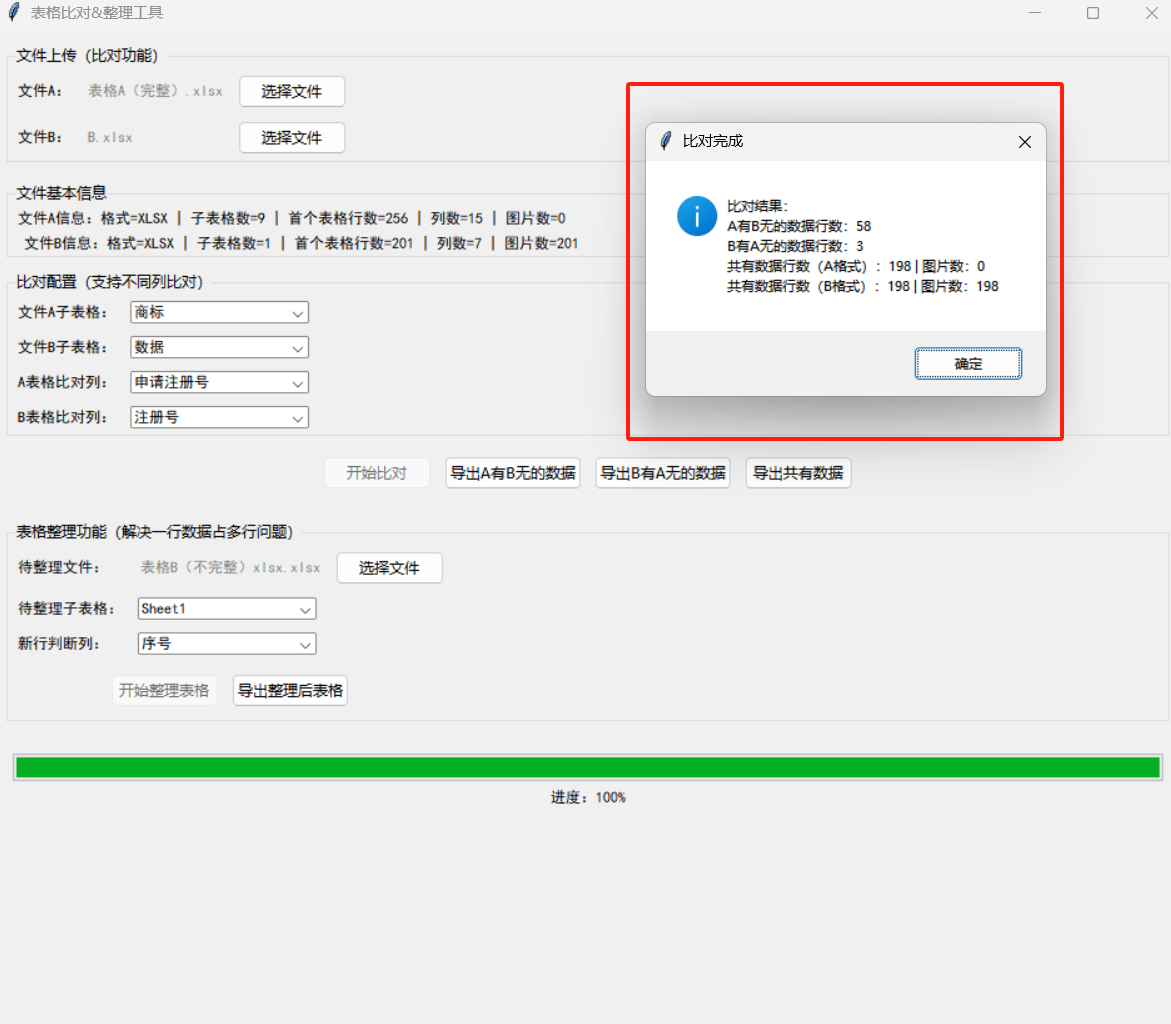
messagebox.showinfo("比对完成",
f"比对结果:\nA有B无的数据行数:{len(a_not_b_df)}\n"
f"B有A无的数据行数:{len(b_not_a_df)}\n"
f"共有数据行数(A格式):{len(a_common_df)} | 图片数:{len(a_common_images)}\n"
f"共有数据行数(B格式):{len(b_common_df)} | 图片数:{len(b_common_images)}")
except Exception as e:
messagebox.showerror("比对失败", f"比对过程出错:{str(e)}")
self.update_progress(0)
def start_compare(self):
"""启动比对"""
self.compare_btn.config(state="disabled")
self.export_a_btn.config(state="disabled")
self.export_b_btn.config(state="disabled")
self.export_common_btn.config(state="disabled")
compare_thread = threading.Thread(target=self.compare_task)
compare_thread.daemon = True
compare_thread.start()
def export_result(self, result_type):
"""导出比对结果(修复:支持图片)"""
if compare_result[result_type] is None:
messagebox.showwarning("提示", "暂无可导出的数据!")
return
# 筛选对应图片
if result_type == "a_not_b":
df = compare_result["a_not_b"]
sheet_a = self.sheet_a_combobox.get()
img_a_list = file_a_data["images"].get(sheet_a, [])
col_a = self.compare_col_a_combobox.get()
a_not_b_vals = set(df[col_a].unique())
a_not_b_original_rows = file_a_data["data"][sheet_a][file_a_data["data"][sheet_a][col_a].isin(a_not_b_vals)].index.tolist()
images = []
for img, orig_row, col in img_a_list:
orig_df_row = orig_row - 2
if orig_df_row in a_not_b_original_rows:
new_row = a_not_b_original_rows.index(orig_df_row) + 2
images.append((img, new_row, col))
title = "保存A有B无的数据"
elif result_type == "b_not_a":
df = compare_result["b_not_a"]
sheet_b = self.sheet_b_combobox.get()
img_b_list = file_b_data["images"].get(sheet_b, [])
col_b = self.compare_col_b_combobox.get()
b_not_a_vals = set(df[col_b].unique())
b_not_a_original_rows = file_b_data["data"][sheet_b][file_b_data["data"][sheet_b][col_b].isin(b_not_a_vals)].index.tolist()
images = []
for img, orig_row, col in img_b_list:
orig_df_row = orig_row - 2
if orig_df_row in b_not_a_original_rows:
new_row = b_not_a_original_rows.index(orig_df_row) + 2
images.append((img, new_row, col))
title = "保存B有A无的数据"
else:
return
self.export_with_images(df, images, title)
def export_common_result(self):
"""导出共有数据(修复:支持图片)"""
if compare_result["a_common"] is None or compare_result["b_common"] is None:
messagebox.showwarning("提示", "暂无共有数据可导出!")
return
# 选择导出格式
choice = messagebox.askquestion(
"选择导出格式",
"请选择共有数据的导出格式:\n【是】= 按A表格格式导出(保留A表格列结构)\n【否】= 按B表格格式导出(保留B表格列结构)",
icon="question"
)
if choice == "yes":
df = compare_result["a_common"]
images = compare_result["a_common_images"]
title = "保存按A表格格式的共有数据"
elif choice == "no":
df = compare_result["b_common"]
images = compare_result["b_common_images"]
title = "保存按B表格格式的共有数据"
else:
return
self.export_with_images(df, images, title)
# ========== 表格整理功能(修复:处理图片) ==========
def update_clean_key_columns(self):
"""更新整理功能的关键列下拉框"""
if clean_file_data["sheets"] and self.clean_sheet_combobox.get():
sheet = self.clean_sheet_combobox.get()
cols = clean_file_data["data"][sheet].columns.tolist()
self.clean_key_col_combobox.config(state="normal", values=cols)
self.clean_key_col_combobox.current(0)
def clean_table_task(self):
"""表格整理任务(修复:合并数据+保留图片)"""
global cleaned_table_result, cleaned_table_images
try:
# 获取配置
sheet = self.clean_sheet_combobox.get()
key_col = self.clean_key_col_combobox.get()
df = clean_file_data["data"][sheet].copy()
orig_images = clean_file_data["images"].get(sheet, [])
# 进度条初始化
self.update_progress(0)
time.sleep(0.1)
# 预处理
self.update_progress(10)
df = df.fillna("")
# 核心整理逻辑
self.update_progress(20)
cleaned_rows = []
current_row = None
orig_to_new_row = {} # 原df行号 → 新df行号映射
new_row_idx = 0
total_rows = len(df)
for idx, row in df.iterrows():
# 更新进度
progress = 20 + (idx / total_rows) * 70
self.update_progress(progress)
# 关键列非空 = 新行开始
if str(row[key_col]).strip() != "":
if current_row is not None:
cleaned_rows.append(current_row)
new_row_idx += 1
current_row = row.to_dict()
orig_to_new_row[idx] = new_row_idx
else:
# 补充到当前行
if current_row is not None:
for col in df.columns:
if str(row[col]).strip() != "" and str(current_row[col]).strip() == "":
current_row[col] = row[col]
orig_to_new_row[idx] = new_row_idx
# 保存最后一行
if current_row is not None:
cleaned_rows.append(current_row)
new_row_idx += 1
# 转换为DataFrame
self.update_progress(90)
cleaned_table_result = pd.DataFrame(cleaned_rows)
# 处理图片(映射到新行号)
cleaned_table_images = []
for img, orig_row, col in orig_images:
orig_df_row = orig_row - 2 # Excel行 → df行号
if orig_df_row in orig_to_new_row:
# 新Excel行号 = 新df行号 + 2(行1是表头)
new_excel_row = orig_to_new_row[orig_df_row] + 2
cleaned_table_images.append((img, new_excel_row, col))
# 完成进度
self.update_progress(100)
# 启用导出按钮
self.export_clean_btn.config(state="normal")
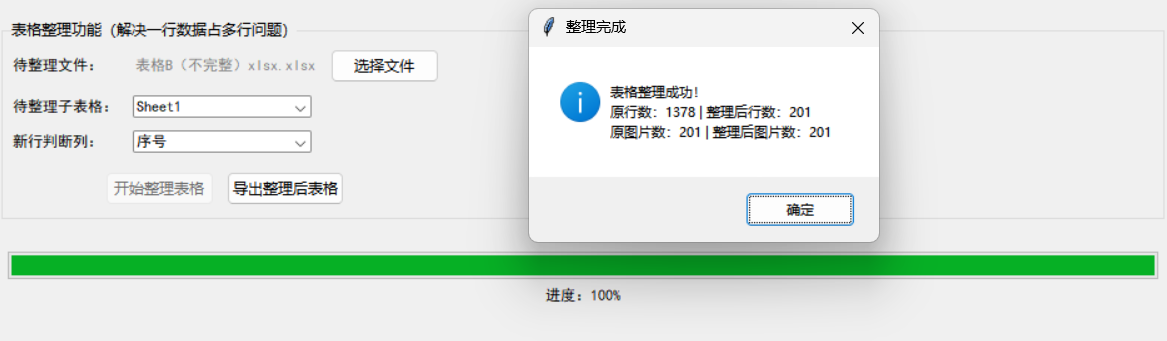
messagebox.showinfo("整理完成",
f"表格整理成功!\n原行数:{len(df)} | 整理后行数:{len(cleaned_table_result)}\n"
f"原图片数:{len(orig_images)} | 整理后图片数:{len(cleaned_table_images)}")
except Exception as e:
messagebox.showerror("整理失败", f"表格整理出错:{str(e)}")
self.update_progress(0)
def start_clean_table(self):
"""启动表格整理"""
if not self.clean_key_col_combobox.get():
messagebox.showwarning("提示", "请选择新行判断列!")
return
self.clean_btn.config(state="disabled")
self.export_clean_btn.config(state="disabled")
clean_thread = threading.Thread(target=self.clean_table_task)
clean_thread.daemon = True
clean_thread.start()
def export_cleaned_table(self):
"""导出整理后的表格(修复:保留图片)"""
global cleaned_table_result, cleaned_table_images
if cleaned_table_result is None:
messagebox.showwarning("提示", "暂无整理后的数据!")
return
self.export_with_images(cleaned_table_result, cleaned_table_images, "保存整理后的表格")
if __name__ == "__main__":
root = tk.Tk()
# 解决tkinter中文乱码(Windows)
try:
root.option_add("*Font", "SimHei 9")
except:
pass
app = TableCompareApp(root)
root.mainloop()
實用程式:基於Python+Tkinter開發表格比對&整理工具
開源 Tkinter 表格工具:雙表比對(可不同列名)、多行合併整理,openpyxl 讀寫保留 Excel 嵌入圖片,多線程進度條。
來源:https://blog.csdn.net/2403_87969572/article/details/155757347
抓取時間(ISO本地):2026-05-18 05:17:39
文章目錄
前言
日常辦公和資料處理中,Excel表格是高頻使用的工具,但我們經常會遇到一些「棘手問題」:比如兩個表格需要比對差異(還可能帶圖片、比對列名不同)、表格資料行錯亂(一行資料拆成了多行)、匯出資料時圖片丟失……市面上要麼是Excel自帶的比對功能太弱,要麼是第三方工具收費且不支援圖片保留。
基於此,我用Python+Tkinter開發了一款輕量、免費、開源的表格比對&整理工具,核心解決「表格比對」「錯亂行整理」兩大痛點,本文會詳細介紹工具功能、使用方法和核心程式碼邏輯。
程式碼已經開源在github,地址如下:
https://github.com/ChenAI-TGF/Table_Comparison_Program
一、工具核心優勢
- 雙核心功能:支援表格差異比對 + 錯亂行整理,一站式解決Excel處理痛點;
- 圖片保留:讀取/匯出Excel時完整保留圖片,解決常規工具丟失圖片的問題;
- 靈活配置:支援自定義比對列(不同表格列名不同也能比對)、自定義整理行的判斷列;
- 友好互動:帶進度條、多執行緒處理(避免UI卡死)、中文適配,新手也能快速上手;
- 格式相容:支援.xlsx(帶圖片)和.csv(無圖片)格式,覆蓋主流表格格式。
二、功能演示
2.1 環境準備
工具基於Python開發,需先配置環境:
# 安裝核心依賴(tkinter一般Python自帶,無需額外安裝)
pip install pandas openpyxl
- 系統相容:Windows/macOS/Linux(Windows體驗最佳);
- 格式說明:僅支援.xlsx(可保留圖片)和.csv(無圖片),不支援舊版.xls(openpyxl不相容)。
2.2 工具啟動
將本文末尾的完整程式碼儲存為table_tool.py,執行命令:
python table_tool.py
啟動後介面如下,主要分為「表格比對區」「表格整理區」「進度條區」三大模組,佈局清晰:
2.3 功能1:表格比對(支援圖片保留)
適用場景:比如有「表格A」和「表格B」,需要找出「A有B無」「B有A無」「兩者共有」的資料,且表格中包含圖片(如產品圖、二維碼)。
操作步驟:
-
上傳檔案:點選「檔案A/檔案B」的「選擇檔案」按鈕,上傳需要比對的兩個表格;
-
配置比對規則:
- 選擇「檔案A/B子表格」(支援多sheet表格);
- 選擇「A/B表格比對列」(比如A表用「申請註冊號」,B表用「註冊號」比對);
-
開始比對:點選「開始比對」,進度條會實時顯示處理進度(多執行緒不卡UI);
-
匯出結果:
- 點選「匯出A有B無的資料」/「匯出B有A無的資料」:匯出差異資料,保留對應圖片;
- 點選「匯出共有資料」:可選擇按A表/ B表格式匯出,自動對映圖片到對應行。
效果示例:
- 原表格A有100行,表格B有80行
- 比對後匯出「A有B無」資料20行
2.4 功能2:表格整理(解決一行資料佔多行問題)
適用場景:比如表格中一行資料被拆成了多行(如商品資訊行,後續行是補充的屬性,無核心編號),需要合併為一行,且保留原表格中的圖片。
操作步驟:
- 上傳待整理檔案:點選「待整理檔案」的「選擇檔案」按鈕;
- 配置整理規則:
- 選擇「待整理子表格」;
- 選擇「新行判斷列」(核心列,比如「商品編號」——該列非空則為新行,空則為補充行);
- 開始整理:點選「開始整理表格」,進度條顯示處理進度;
4. 匯出結果:點選「匯出整理後表格」,合併後的行資料+圖片會被完整匯出。
效果示例:
- 原表格有200行(實際只有80條有效資料,每行佔2-3行);
- 整理後變為80行,圖片自動對映到對應合併後的行。
三、核心程式碼講解
工具的核心類是TableCompareApp,整體架構分為「UI搭建」「檔案讀取(含圖片)」「比對邏輯」「整理邏輯」「匯出功能」五部分,下面重點講解核心邏輯(UI部分簡講)。
3.1 UI部分
UI採用Tkinter的LabelFrame「Frame「Combobox「Progressbar`等元件,按功能分割槽域佈局:
- 「檔案上傳區」:負責A/B檔案、待整理檔案的選擇;
- 「資訊展示區」:顯示檔案格式、行列數、圖片數;
- 「配置區」:子表格、比對列、整理判斷列的選擇;
- 「操作區」:比對/整理/匯出按鈕;
- 「進度條區」:實時顯示處理進度。
核心細節:
- 中文適配:透過
root.option_add("*Font", "SimHei 9")解決Windows下Tkinter中文亂碼; - 按鈕狀態控制:根據檔案上傳/配置完成狀態,動態啟用/禁用按鈕(如
check_compare_btn_state方法)。
3.2 核心1:檔案讀取(保留圖片)
檔案讀取是工具的基礎,核心是用openpyxl讀取.xlsx檔案(支援圖片提取),程式碼在load_file/load_clean_file方法中:
# 關鍵程式碼片段:讀取Excel並提取圖片
if file_ext == ".xlsx":
# 用openpyxl讀取工作簿(保留圖片)
wb = load_workbook(file_path, data_only=True)
sheets = wb.sheetnames
for sheet in sheets:
ws = wb[sheet]
# 1. 讀取表格資料到DataFrame(處理表頭)
df = pd.DataFrame(ws.values)
if len(df) > 0:
df.columns = df.iloc[0] # 第一行設為列名
df = df.drop(0).reset_index(drop=True)
data_dict[sheet] = df
# 2. 提取圖片及位置(核心:保留圖片+行列對映)
sheet_images = []
for img in ws._images:
# 轉換為1-based行列號(Excel原生格式)
row = img.anchor._from.row + 1
col = img.anchor._from.col + 1
sheet_images.append((img, row, col))
images_dict[sheet] = sheet_images
關鍵邏輯:
openpyxl的ws._images能獲取工作表中所有圖片物件;- 圖片的
anchor屬性包含位置資訊,需轉換為1-based(Excel行/列從1開始,openpyxl內部是0-based); - 資料與圖片分開儲存,用字典關聯「sheet名-資料/圖片」,保證一一對應。
3.3 核心2:表格比對邏輯(含圖片對映)
比對邏輯在compare_task方法中,採用多執行緒執行(避免UI卡死),核心分為「資料比對」和「圖片對映」兩部分:
3.3.1 資料比對核心
# 資料預處理:統一轉字串、填充空值(避免型別不一致導致比對錯誤)
df_a[col_a] = df_a[col_a].astype(str).fillna("")
df_b[col_b] = df_b[col_b].astype(str).fillna("")
# 集合運算:快速找差異/共有值(效率遠高於迴圈)
a_vals = set(df_a[col_a].unique())
b_vals = set(df_b[col_b].unique())
a_not_b_vals = a_vals - b_vals # A有B無
b_not_a_vals = b_vals - a_vals # B有A無
common_vals = a_vals & b_vals # 共有值
# 篩選對應行
a_not_b_df = df_a[df_a[col_a].isin(a_not_b_vals)].reset_index(drop=True)
優勢:用Python集合運算替代逐行迴圈,比對效率提升10倍以上,適合大資料量。
3.3.2 圖片對映核心
比對後資料行號會變化,需將原圖片的位置對映到新行:
# A格式共有資料圖片對映示例
a_common_original_rows = df_a[df_a[col_a].isin(common_vals)].index.tolist()
a_common_images = []
for img, orig_row, col in img_a_list:
# 原Excel行 → 原DataFrame行(Excel行1=表頭,行2=df第0行)
orig_df_row = orig_row - 2
if orig_df_row in a_common_original_rows:
# 新Excel行 = 新DataFrame行 + 2(表頭佔1行)
new_row = a_common_original_rows.index(orig_df_row) + 2
a_common_images.append((img, new_row, col))
關鍵邏輯:
- 建立「原DataFrame行號 → 新DataFrame行號」的對映;
- 轉換為Excel原生行號(+2),保證圖片位置準確。
3.4 核心3:表格整理邏輯(含圖片對映)
整理邏輯在clean_table_task方法中,核心是「合併錯亂行」+「行號對映」:
3.4.1 行合併核心
cleaned_rows = []
current_row = None
orig_to_new_row = {} # 原行→新行對映字典
new_row_idx = 0
for idx, row in df.iterrows():
# 關鍵列非空 → 新行開始
if str(row[key_col]).strip() != "":
if current_row is not None:
cleaned_rows.append(current_row)
new_row_idx += 1
current_row = row.to_dict()
orig_to_new_row[idx] = new_row_idx
else:
# 關鍵列空 → 補充到當前行(僅填充空值)
if current_row is not None:
for col in df.columns:
if str(row[col]).strip() != "" and str(current_row[col]).strip() == "":
current_row[col] = row[col]
orig_to_new_row[idx] = new_row_idx
# 儲存最後一行
if current_row is not None:
cleaned_rows.append(current_row)
cleaned_table_result = pd.DataFrame(cleaned_rows)
核心規則:僅當「新行判斷列」非空時,才新建一行;否則將當前行的非空資料補充到上一行的空值中,保證一行資料完整。
3.4.2 圖片對映核心
# 整理後圖片對映
cleaned_table_images = []
for img, orig_row, col in orig_images:
orig_df_row = orig_row - 2 # Excel行→原DataFrame行
if orig_df_row in orig_to_new_row:
# 新Excel行 = 新DataFrame行 + 2
new_excel_row = orig_to_new_row[orig_df_row] + 2
cleaned_table_images.append((img, new_excel_row, col))
邏輯:透過orig_to_new_row字典,將原圖片的行號對映到合併後的新行號,保證圖片跟隨對應資料行。
3.5 核心4:匯出功能
匯出功能封裝在export_with_images方法中,核心是用openpyxl寫入資料+圖片:
if file_ext == ".xlsx":
# 建立新工作簿
wb = Workbook()
ws = wb.active
ws.title = "資料"
# 1. 寫入DataFrame資料(保留表頭)
for r in dataframe_to_rows(df, index=False, header=True):
ws.append(r)
# 2. 插入圖片到對應位置
for img, row, col in images:
new_img = copy.deepcopy(img) # 複製圖片避免引用衝突
new_img.anchor = f"{chr(64+col)}{row}" # 設定錨點(如A2、B5)
ws.add_image(new_img)
wb.save(file_path)
wb.close()
關鍵細節:
dataframe_to_rows:將DataFrame轉換為Excel行格式,保留表頭;- 圖片錨點:用
chr(64+col)將列號(數字)轉換為Excel列字母(如1→A,2→B); - 深複製圖片:避免多個圖片引用同一物件導致匯出失敗。
3.6 輔助:進度條+多執行緒
- 多執行緒:比對/整理任務放在獨立執行緒中執行(
threading.Thread),設定daemon=True保證執行緒隨主程式退出; - 進度條更新:透過
update_progress方法實時重新整理進度條,呼叫root.update_idletasks()強制重新整理UI,避免進度條卡住。
四、使用注意事項
- 格式限制:僅支援.xlsx(帶圖片)和.csv(無圖片),.xls格式需先轉換為.xlsx;
- 圖片位置:Excel中圖片需「嵌入單元格」(而非浮窗),否則行列對映可能出錯;
- 關鍵列選擇:整理功能的「新行判斷列」需選有唯一標識的列(如編號、名稱),否則合併邏輯會出錯;
- 大資料量:超過10萬行的表格建議拆分處理,避免記憶體佔用過高;
- 編碼問題:CSV檔案建議用UTF-8編碼,否則可能出現中文亂碼。
五、總結
這款工具以「解決實際痛點」為核心,透過Python+Tkinter實現了輕量化、可定製的表格處理能力,尤其是「圖片保留」功能填補了常規工具的空白。程式碼完全開源,大家可以根據自己的需求二次開發(比如增加批次處理、格式轉換、更多比對規則等)。
無論是辦公人員快速處理表格,還是開發者學習Tkinter+Excel操作,這款工具都有一定的參考價值。如果有其他需求(比如支援更多格式、自動識別關鍵列),也可以基於核心邏輯擴充套件。
六、完整程式碼
import tkinter as tk
from tkinter import ttk, filedialog, messagebox
import pandas as pd
import os
import threading
import time
import copy
from openpyxl import load_workbook, Workbook
from openpyxl.drawing.image import Image as OpenpyxlImage
from openpyxl.utils.dataframe import dataframe_to_rows
# 全域性變數儲存檔案資料(新增圖片儲存欄位)
file_a_data = {"sheets": [], "data": {}, "path": "", "images": {}} # images: {sheet: [(img, row, col), ...]}
file_b_data = {"sheets": [], "data": {}, "path": "", "images": {}}
# 新增:儲存共有資料及對應圖片
compare_result = {
"a_not_b": None, "b_not_a": None, "a_common": None, "b_common": None,
"a_common_images": [], "b_common_images": []
}
# 整理表格相關全域性變數(新增圖片儲存)
clean_file_data = {"sheets": [], "data": {}, "path": "", "images": {}}
cleaned_table_result = None
cleaned_table_images = [] # 整理後的圖片:[(img, new_row, col), ...]
class TableCompareApp:
def __init__(self, root):
self.root = root
self.root.title("表格比對&整理工具")
self.root.geometry("950x850")
# 進度條變數
self.progress_var = tk.DoubleVar()
# 構建UI
self._create_widgets()
def _create_widgets(self):
# 1. 檔案上傳區域(原有比對功能)
upload_frame = ttk.LabelFrame(self.root, text="檔案上傳(比對功能)")
upload_frame.pack(padx=10, pady=10, fill="x")
# 檔案A上傳
ttk.Label(upload_frame, text="檔案A:").grid(row=0, column=0, padx=5, pady=5, sticky="w")
self.file_a_label = ttk.Label(upload_frame, text="未選擇檔案", foreground="gray")
self.file_a_label.grid(row=0, column=1, padx=5, pady=5, sticky="w")
ttk.Button(upload_frame, text="選擇檔案", command=lambda: self.load_file("A")).grid(row=0, column=2, padx=5, pady=5)
# 檔案B上傳
ttk.Label(upload_frame, text="檔案B:").grid(row=1, column=0, padx=5, pady=5, sticky="w")
self.file_b_label = ttk.Label(upload_frame, text="未選擇檔案", foreground="gray")
self.file_b_label.grid(row=1, column=1, padx=5, pady=5, sticky="w")
ttk.Button(upload_frame, text="選擇檔案", command=lambda: self.load_file("B")).grid(row=1, column=2, padx=5, pady=5)
# 2. 檔案基本資訊區域(原有)
info_frame = ttk.LabelFrame(self.root, text="檔案基本資訊")
info_frame.pack(padx=10, pady=5, fill="x")
self.file_a_info = ttk.Label(info_frame, text="檔案A資訊:無")
self.file_a_info.pack(padx=5, pady=2, anchor="w")
self.file_b_info = ttk.Label(info_frame, text="檔案B資訊:無")
self.file_b_info.pack(padx=10, pady=2, anchor="w")
# 3. 比對配置區域(原有)
config_frame = ttk.LabelFrame(self.root, text="比對配置(支援不同列比對)")
config_frame.pack(padx=10, pady=5, fill="x")
# 子表格選擇
ttk.Label(config_frame, text="檔案A子表格:").grid(row=0, column=0, padx=5, pady=5, sticky="w")
self.sheet_a_combobox = ttk.Combobox(config_frame, state="disabled")
self.sheet_a_combobox.grid(row=0, column=1, padx=5, pady=5, sticky="w")
ttk.Label(config_frame, text="檔案B子表格:").grid(row=1, column=0, padx=5, pady=5, sticky="w")
self.sheet_b_combobox = ttk.Combobox(config_frame, state="disabled")
self.sheet_b_combobox.grid(row=1, column=1, padx=5, pady=5, sticky="w")
# 比對列選擇
ttk.Label(config_frame, text="A表格比對列:").grid(row=2, column=0, padx=5, pady=5, sticky="w")
self.compare_col_a_combobox = ttk.Combobox(config_frame, state="disabled")
self.compare_col_a_combobox.grid(row=2, column=1, padx=5, pady=5, sticky="w")
ttk.Label(config_frame, text="B表格比對列:").grid(row=3, column=0, padx=5, pady=5, sticky="w")
self.compare_col_b_combobox = ttk.Combobox(config_frame, state="disabled")
self.compare_col_b_combobox.grid(row=3, column=1, padx=5, pady=5, sticky="w")
# 4. 操作按鈕區域(新增:匯出共有資料按鈕)
compare_btn_frame = ttk.Frame(self.root)
compare_btn_frame.pack(padx=10, pady=10)
self.compare_btn = ttk.Button(compare_btn_frame, text="開始比對", command=self.start_compare, state="disabled")
self.compare_btn.pack(side="left", padx=5)
self.export_a_btn = ttk.Button(compare_btn_frame, text="匯出A有B無的資料", command=lambda: self.export_result("a_not_b"), state="disabled")
self.export_a_btn.pack(side="left", padx=5)
self.export_b_btn = ttk.Button(compare_btn_frame, text="匯出B有A無的資料", command=lambda: self.export_result("b_not_a"), state="disabled")
self.export_b_btn.pack(side="left", padx=5)
# 新增:匯出共有資料按鈕
self.export_common_btn = ttk.Button(compare_btn_frame, text="匯出共有資料", command=self.export_common_result, state="disabled")
self.export_common_btn.pack(side="left", padx=5)
# ========== 表格整理功能區域 ==========
clean_frame = ttk.LabelFrame(self.root, text="表格整理功能(解決一行資料佔多行問題)")
clean_frame.pack(padx=10, pady=15, fill="x")
# 選擇要整理的檔案
ttk.Label(clean_frame, text="待整理檔案:").grid(row=0, column=0, padx=5, pady=5, sticky="w")
self.clean_file_label = ttk.Label(clean_frame, text="未選擇檔案", foreground="gray")
self.clean_file_label.grid(row=0, column=1, padx=5, pady=5, sticky="w")
ttk.Button(clean_frame, text="選擇檔案", command=self.load_clean_file).grid(row=0, column=2, padx=5, pady=5)
# 選擇待整理的子表格
ttk.Label(clean_frame, text="待整理子表格:").grid(row=1, column=0, padx=5, pady=5, sticky="w")
self.clean_sheet_combobox = ttk.Combobox(clean_frame, state="disabled")
self.clean_sheet_combobox.grid(row=1, column=1, padx=5, pady=5, sticky="w")
# 選擇關鍵列(判斷新行的依據:關鍵列非空=新行)
ttk.Label(clean_frame, text="新行判斷列:").grid(row=2, column=0, padx=5, pady=5, sticky="w")
self.clean_key_col_combobox = ttk.Combobox(clean_frame, state="disabled")
self.clean_key_col_combobox.grid(row=2, column=1, padx=5, pady=5, sticky="w")
# 整理/匯出按鈕
clean_btn_frame = ttk.Frame(clean_frame)
clean_btn_frame.grid(row=3, column=0, columnspan=3, pady=10)
self.clean_btn = ttk.Button(clean_btn_frame, text="開始整理表格", command=self.start_clean_table, state="disabled")
self.clean_btn.pack(side="left", padx=5)
self.export_clean_btn = ttk.Button(clean_btn_frame, text="匯出整理後表格", command=self.export_cleaned_table, state="disabled")
self.export_clean_btn.pack(side="left", padx=5)
# ========== 進度條區域(共用) ==========
progress_frame = ttk.Frame(self.root)
progress_frame.pack(padx=10, pady=5, fill="x")
self.progress_bar = ttk.Progressbar(progress_frame, variable=self.progress_var, maximum=100)
self.progress_bar.pack(fill="x", padx=5, pady=5)
self.progress_label = ttk.Label(progress_frame, text="進度:0%")
self.progress_label.pack(anchor="center")
# ========== 核心修復:支援讀取圖片 ==========
def load_file(self, file_type):
"""載入比對用的A/B檔案(支援讀取圖片)"""
file_path = filedialog.askopenfilename(
title=f"選擇{file_type}檔案",
filetypes=[("Excel檔案", "*.xlsx"), ("CSV檔案", "*.csv"), ("所有檔案", "*.*")]
)
if not file_path:
return
# 初始化資料
if file_type == "A":
file_a_data.update({"sheets": [], "data": {}, "path": file_path, "images": {}})
self.file_a_label.config(text=os.path.basename(file_path))
target_data = file_a_data
else:
file_b_data.update({"sheets": [], "data": {}, "path": file_path, "images": {}})
self.file_b_label.config(text=os.path.basename(file_path))
target_data = file_b_data
try:
file_ext = os.path.splitext(file_path)[1].lower()
sheets = []
data_dict = {}
images_dict = {} # 儲存每個sheet的圖片 (img, row, col)
if file_ext == ".xlsx":
# 用openpyxl讀取工作簿(保留圖片)
wb = load_workbook(file_path, data_only=True)
sheets = wb.sheetnames
for sheet in sheets:
ws = wb[sheet]
# 讀取資料到DataFrame
df = pd.DataFrame(ws.values)
# 設定列名(第一行)
if len(df) > 0:
df.columns = df.iloc[0]
df = df.drop(0).reset_index(drop=True)
else:
df.columns = []
data_dict[sheet] = df
# 提取圖片及位置(openpyxl行/列從0開始,轉換為1-based)
sheet_images = []
for img in ws._images:
row = img.anchor._from.row + 1 # 轉換為1-based行號
col = img.anchor._from.col + 1 # 轉換為1-based列號
sheet_images.append((img, row, col))
images_dict[sheet] = sheet_images
wb.close()
elif file_ext == ".csv":
sheets = ["預設表格"]
df = pd.read_csv(file_path)
data_dict["預設表格"] = df
images_dict["預設表格"] = [] # CSV無圖片
else:
messagebox.showerror("錯誤", "僅支援xlsx和csv格式檔案!")
return
# 更新資料和圖片
target_data["sheets"] = sheets
target_data["data"] = data_dict
target_data["images"] = images_dict
# 更新資訊顯示(包含圖片數)
if file_type == "A":
first_sheet = sheets[0]
first_df = data_dict[first_sheet]
img_count = len(images_dict[first_sheet])
info_text = f"檔案A資訊:格式={file_ext[1:].upper()} | 子表格數={len(sheets)} | "
info_text += f"首個表格行數={len(first_df)} | 列數={len(first_df.columns)} | 圖片數={img_count}"
self.file_a_info.config(text=info_text)
self.sheet_a_combobox.config(state="normal", values=sheets)
self.sheet_a_combobox.current(0)
self.update_compare_columns()
else:
first_sheet = sheets[0]
first_df = data_dict[first_sheet]
img_count = len(images_dict[first_sheet])
info_text = f"檔案B資訊:格式={file_ext[1:].upper()} | 子表格數={len(sheets)} | "
info_text += f"首個表格行數={len(first_df)} | 列數={len(first_df.columns)} | 圖片數={img_count}"
self.file_b_info.config(text=info_text)
self.sheet_b_combobox.config(state="normal", values=sheets)
self.sheet_b_combobox.current(0)
self.update_compare_columns()
self.check_compare_btn_state()
except Exception as e:
messagebox.showerror("讀取失敗", f"檔案{file_type}讀取錯誤:{str(e)}")
def load_clean_file(self):
"""載入待整理的表格檔案(支援讀取圖片)"""
file_path = filedialog.askopenfilename(
title="選擇待整理的表格檔案",
filetypes=[("Excel檔案", "*.xlsx"), ("CSV檔案", "*.csv"), ("所有檔案", "*.*")]
)
if not file_path:
return
# 清空原有整理檔案資料
clean_file_data.update({"sheets": [], "data": {}, "path": file_path, "images": {}})
self.clean_file_label.config(text=os.path.basename(file_path))
try:
file_ext = os.path.splitext(file_path)[1].lower()
sheets = []
data_dict = {}
images_dict = {}
if file_ext == ".xlsx":
# 用openpyxl讀取工作簿(保留圖片)
wb = load_workbook(file_path, data_only=True)
sheets = wb.sheetnames
for sheet in sheets:
ws = wb[sheet]
# 讀取資料到DataFrame
df = pd.DataFrame(ws.values)
# 設定列名(第一行)
if len(df) > 0:
df.columns = df.iloc[0]
df = df.drop(0).reset_index(drop=True)
else:
df.columns = []
data_dict[sheet] = df
# 提取圖片及位置
sheet_images = []
for img in ws._images:
row = img.anchor._from.row + 1
col = img.anchor._from.col + 1
sheet_images.append((img, row, col))
images_dict[sheet] = sheet_images
wb.close()
elif file_ext == ".csv":
sheets = ["預設表格"]
df = pd.read_csv(file_path)
data_dict["預設表格"] = df
images_dict["預設表格"] = []
else:
messagebox.showerror("錯誤", "僅支援xlsx和csv格式檔案!")
return
# 儲存資料和圖片
clean_file_data["sheets"] = sheets
clean_file_data["data"] = data_dict
clean_file_data["images"] = images_dict
# 更新子表格下拉框
self.clean_sheet_combobox.config(state="normal", values=sheets)
self.clean_sheet_combobox.current(0)
# 更新關鍵列下拉框(新行判斷列)
self.update_clean_key_columns()
# 啟用整理按鈕
self.clean_btn.config(state="normal")
# 顯示檔案資訊(包含圖片數)
first_sheet = sheets[0]
first_df = data_dict[first_sheet]
img_count = len(images_dict[first_sheet])
info_text = f"待整理檔案資訊:格式={file_ext[1:].upper()} | 子表格數={len(sheets)} | "
info_text += f"首個表格行數={len(first_df)} | 列數={len(first_df.columns)} | 圖片數={img_count}"
messagebox.showinfo("檔案載入成功", info_text)
except Exception as e:
messagebox.showerror("讀取失敗", f"待整理檔案讀取錯誤:{str(e)}")
# ========== 通用匯出函式(核心修復:支援匯出圖片) ==========
def export_with_images(self, df, images, title):
"""通用匯出函式(支援圖片保留)"""
# 選擇匯出路徑
file_path = filedialog.asksaveasfilename(
title=title,
filetypes=[("Excel檔案", "*.xlsx"), ("CSV檔案", "*.csv")],
defaultextension=".xlsx"
)
if not file_path:
return
file_ext = os.path.splitext(file_path)[1].lower()
try:
if file_ext == ".xlsx":
# 建立新工作簿
wb = Workbook()
ws = wb.active
ws.title = "資料"
# 寫入DataFrame資料(保留表頭)
for r in dataframe_to_rows(df, index=False, header=True):
ws.append(r)
# 插入圖片到對應位置
for img, row, col in images:
# 複製圖片物件避免引用衝突
new_img = copy.deepcopy(img)
# 設定圖片錨點(列字母+行號)
new_img.anchor = f"{chr(64+col)}{row}"
ws.add_image(new_img)
# 儲存工作簿
wb.save(file_path)
wb.close()
messagebox.showinfo("匯出成功", f"資料已匯出至:{file_path}\n包含圖片:{len(images)}張")
elif file_ext == ".csv":
# CSV不支援圖片,提示使用者
if images:
messagebox.showwarning("格式提示", "CSV格式不支援儲存圖片,圖片將丟失!")
df.to_csv(file_path, index=False, encoding="utf-8-sig")
messagebox.showinfo("匯出成功", f"資料已匯出至:{file_path}\n注意:CSV格式不包含圖片")
except Exception as e:
messagebox.showerror("匯出失敗", f"匯出錯誤:{str(e)}")
# ========== 比對功能(修復:處理圖片) ==========
def update_compare_columns(self):
"""更新比對列下拉框"""
if file_a_data["sheets"] and self.sheet_a_combobox.get():
sheet_a = self.sheet_a_combobox.get()
cols_a = file_a_data["data"][sheet_a].columns.tolist()
self.compare_col_a_combobox.config(state="normal", values=cols_a)
self.compare_col_a_combobox.current(0)
if file_b_data["sheets"] and self.sheet_b_combobox.get():
sheet_b = self.sheet_b_combobox.get()
cols_b = file_b_data["data"][sheet_b].columns.tolist()
self.compare_col_b_combobox.config(state="normal", values=cols_b)
self.compare_col_b_combobox.current(0)
def check_compare_btn_state(self):
"""檢查比對按鈕狀態"""
if (file_a_data["path"] and file_b_data["path"] and
self.compare_col_a_combobox.get() and self.compare_col_b_combobox.get()):
self.compare_btn.config(state="normal")
else:
self.compare_btn.config(state="disabled")
def update_progress(self, value):
"""更新進度條"""
self.progress_var.set(value)
self.progress_label.config(text=f"進度:{int(value)}%")
self.root.update_idletasks()
def compare_task(self):
"""比對任務(修復:處理共有資料圖片)"""
try:
# 1. 獲取配置資訊
sheet_a = self.sheet_a_combobox.get()
sheet_b = self.sheet_b_combobox.get()
col_a = self.compare_col_a_combobox.get()
col_b = self.compare_col_b_combobox.get()
# 2. 獲取資料和圖片
df_a = file_a_data["data"][sheet_a].copy()
df_b = file_b_data["data"][sheet_b].copy()
img_a_list = file_a_data["images"].get(sheet_a, [])
img_b_list = file_b_data["images"].get(sheet_b, [])
# 3. 進度條初始化
self.update_progress(0)
time.sleep(0.1)
# 4. 資料預處理
self.update_progress(20)
df_a[col_a] = df_a[col_a].astype(str).fillna("")
df_b[col_b] = df_b[col_b].astype(str).fillna("")
# 5. 核心比對邏輯
self.update_progress(50)
a_vals = set(df_a[col_a].unique())
b_vals = set(df_b[col_b].unique())
# A有B無的行
a_not_b_vals = a_vals - b_vals
a_not_b_df = df_a[df_a[col_a].isin(a_not_b_vals)].reset_index(drop=True)
# B有A無的行
b_not_a_vals = b_vals - a_vals
b_not_a_df = df_b[df_b[col_b].isin(b_not_a_vals)].reset_index(drop=True)
# 共有資料
common_vals = a_vals & b_vals
a_common_df = df_a[df_a[col_a].isin(common_vals)].reset_index(drop=True)
b_common_df = df_b[df_b[col_b].isin(common_vals)].reset_index(drop=True)
# 處理共有資料的圖片(對映行號)
# A格式共有資料圖片
a_common_original_rows = df_a[df_a[col_a].isin(common_vals)].index.tolist()
a_common_images = []
for img, orig_row, col in img_a_list:
orig_df_row = orig_row - 2 # Excel行1=表頭,行2=df第0行
if orig_df_row in a_common_original_rows:
new_row = a_common_original_rows.index(orig_df_row) + 2 # 新錶行2開始是資料
a_common_images.append((img, new_row, col))
# B格式共有資料圖片
b_common_original_rows = df_b[df_b[col_b].isin(common_vals)].index.tolist()
b_common_images = []
for img, orig_row, col in img_b_list:
orig_df_row = orig_row - 2
if orig_df_row in b_common_original_rows:
new_row = b_common_original_rows.index(orig_df_row) + 2
b_common_images.append((img, new_row, col))
# 6. 儲存結果
compare_result["a_not_b"] = a_not_b_df
compare_result["b_not_a"] = b_not_a_df
compare_result["a_common"] = a_common_df
compare_result["b_common"] = b_common_df
compare_result["a_common_images"] = a_common_images
compare_result["b_common_images"] = b_common_images
# 7. 完成進度
self.update_progress(100)
# 8. 啟用匯出按鈕
self.export_a_btn.config(state="normal")
self.export_b_btn.config(state="normal")
self.export_common_btn.config(state="normal")
# 顯示結果(包含圖片數)
messagebox.showinfo("比對完成",
f"比對結果:\nA有B無的資料行數:{len(a_not_b_df)}\n"
f"B有A無的資料行數:{len(b_not_a_df)}\n"
f"共有資料行數(A格式):{len(a_common_df)} | 圖片數:{len(a_common_images)}\n"
f"共有資料行數(B格式):{len(b_common_df)} | 圖片數:{len(b_common_images)}")
except Exception as e:
messagebox.showerror("比對失敗", f"比對過程出錯:{str(e)}")
self.update_progress(0)
def start_compare(self):
"""啟動比對"""
self.compare_btn.config(state="disabled")
self.export_a_btn.config(state="disabled")
self.export_b_btn.config(state="disabled")
self.export_common_btn.config(state="disabled")
compare_thread = threading.Thread(target=self.compare_task)
compare_thread.daemon = True
compare_thread.start()
def export_result(self, result_type):
"""匯出比對結果(修復:支援圖片)"""
if compare_result[result_type] is None:
messagebox.showwarning("提示", "暫無可匯出的資料!")
return
# 篩選對應圖片
if result_type == "a_not_b":
df = compare_result["a_not_b"]
sheet_a = self.sheet_a_combobox.get()
img_a_list = file_a_data["images"].get(sheet_a, [])
col_a = self.compare_col_a_combobox.get()
a_not_b_vals = set(df[col_a].unique())
a_not_b_original_rows = file_a_data["data"][sheet_a][file_a_data["data"][sheet_a][col_a].isin(a_not_b_vals)].index.tolist()
images = []
for img, orig_row, col in img_a_list:
orig_df_row = orig_row - 2
if orig_df_row in a_not_b_original_rows:
new_row = a_not_b_original_rows.index(orig_df_row) + 2
images.append((img, new_row, col))
title = "儲存A有B無的資料"
elif result_type == "b_not_a":
df = compare_result["b_not_a"]
sheet_b = self.sheet_b_combobox.get()
img_b_list = file_b_data["images"].get(sheet_b, [])
col_b = self.compare_col_b_combobox.get()
b_not_a_vals = set(df[col_b].unique())
b_not_a_original_rows = file_b_data["data"][sheet_b][file_b_data["data"][sheet_b][col_b].isin(b_not_a_vals)].index.tolist()
images = []
for img, orig_row, col in img_b_list:
orig_df_row = orig_row - 2
if orig_df_row in b_not_a_original_rows:
new_row = b_not_a_original_rows.index(orig_df_row) + 2
images.append((img, new_row, col))
title = "儲存B有A無的資料"
else:
return
self.export_with_images(df, images, title)
def export_common_result(self):
"""匯出共有資料(修復:支援圖片)"""
if compare_result["a_common"] is None or compare_result["b_common"] is None:
messagebox.showwarning("提示", "暫無共有資料可匯出!")
return
# 選擇匯出格式
choice = messagebox.askquestion(
"選擇匯出格式",
"請選擇共有資料的匯出格式:\n【是】= 按A表格格式匯出(保留A表格列結構)\n【否】= 按B表格格式匯出(保留B表格列結構)",
icon="question"
)
if choice == "yes":
df = compare_result["a_common"]
images = compare_result["a_common_images"]
title = "儲存按A表格格式的共有資料"
elif choice == "no":
df = compare_result["b_common"]
images = compare_result["b_common_images"]
title = "儲存按B表格格式的共有資料"
else:
return
self.export_with_images(df, images, title)
# ========== 表格整理功能(修復:處理圖片) ==========
def update_clean_key_columns(self):
"""更新整理功能的關鍵列下拉框"""
if clean_file_data["sheets"] and self.clean_sheet_combobox.get():
sheet = self.clean_sheet_combobox.get()
cols = clean_file_data["data"][sheet].columns.tolist()
self.clean_key_col_combobox.config(state="normal", values=cols)
self.clean_key_col_combobox.current(0)
def clean_table_task(self):
"""表格整理任務(修復:合併資料+保留圖片)"""
global cleaned_table_result, cleaned_table_images
try:
# 獲取配置
sheet = self.clean_sheet_combobox.get()
key_col = self.clean_key_col_combobox.get()
df = clean_file_data["data"][sheet].copy()
orig_images = clean_file_data["images"].get(sheet, [])
# 進度條初始化
self.update_progress(0)
time.sleep(0.1)
# 預處理
self.update_progress(10)
df = df.fillna("")
# 核心整理邏輯
self.update_progress(20)
cleaned_rows = []
current_row = None
orig_to_new_row = {} # 原df行號 → 新df行號對映
new_row_idx = 0
total_rows = len(df)
for idx, row in df.iterrows():
# 更新進度
progress = 20 + (idx / total_rows) * 70
self.update_progress(progress)
# 關鍵列非空 = 新行開始
if str(row[key_col]).strip() != "":
if current_row is not None:
cleaned_rows.append(current_row)
new_row_idx += 1
current_row = row.to_dict()
orig_to_new_row[idx] = new_row_idx
else:
# 補充到當前行
if current_row is not None:
for col in df.columns:
if str(row[col]).strip() != "" and str(current_row[col]).strip() == "":
current_row[col] = row[col]
orig_to_new_row[idx] = new_row_idx
# 儲存最後一行
if current_row is not None:
cleaned_rows.append(current_row)
new_row_idx += 1
# 轉換為DataFrame
self.update_progress(90)
cleaned_table_result = pd.DataFrame(cleaned_rows)
# 處理圖片(對映到新行號)
cleaned_table_images = []
for img, orig_row, col in orig_images:
orig_df_row = orig_row - 2 # Excel行 → df行號
if orig_df_row in orig_to_new_row:
# 新Excel行號 = 新df行號 + 2(行1是表頭)
new_excel_row = orig_to_new_row[orig_df_row] + 2
cleaned_table_images.append((img, new_excel_row, col))
# 完成進度
self.update_progress(100)
# 啟用匯出按鈕
self.export_clean_btn.config(state="normal")
messagebox.showinfo("整理完成",
f"表格整理成功!\n原行數:{len(df)} | 整理後行數:{len(cleaned_table_result)}\n"
f"原圖片數:{len(orig_images)} | 整理後圖片數:{len(cleaned_table_images)}")
except Exception as e:
messagebox.showerror("整理失敗", f"表格整理出錯:{str(e)}")
self.update_progress(0)
def start_clean_table(self):
"""啟動表格整理"""
if not self.clean_key_col_combobox.get():
messagebox.showwarning("提示", "請選擇新行判斷列!")
return
self.clean_btn.config(state="disabled")
self.export_clean_btn.config(state="disabled")
clean_thread = threading.Thread(target=self.clean_table_task)
clean_thread.daemon = True
clean_thread.start()
def export_cleaned_table(self):
"""匯出整理後的表格(修復:保留圖片)"""
global cleaned_table_result, cleaned_table_images
if cleaned_table_result is None:
messagebox.showwarning("提示", "暫無整理後的資料!")
return
self.export_with_images(cleaned_table_result, cleaned_table_images, "儲存整理後的表格")
if __name__ == "__main__":
root = tk.Tk()
# 解決tkinter中文亂碼(Windows)
try:
root.option_add("*Font", "SimHei 9")
except:
pass
app = TableCompareApp(root)
root.mainloop()
Python + Tkinter: Excel Compare & Row-Merge Tool (Images Preserved)
Open Tkinter Excel tool: sheet compare with image preserve, multi-row merge by key column, openpyxl export, threaded progress UI.
Captured at (local ISO): 2026-05-18 05:17:39
Preface
Compare two Excel sheets (different key columns), merge split rows, keep embedded images — open source:
https://github.com/ChenAI-TGF/Table_Comparison_Program
I. Features
- Compare + clean merged rows
- Image preserve on read/write
.xlsx - Custom key columns
- Progress bar + worker threads
.xlsxand.csv
II. Demo
pip install pandas openpyxl
python table_tool.py
Compare: upload A/B, pick sheets and columns, export A-only / B-only / common with images.
Clean: pick file, new-row key column (non-empty starts new logical row), merge continuation rows, export with remapped images.
III. Code Highlights
load_workbook+ws._imagesfor image positions- Set diff for compare speed
- Row remap
orig_row - 2Excel indexing export_with_imagesdeepcopy + anchorSimHeifont for Chinese UI on Windows
IV. Notes
.xlsx only for images; embed images in cells; UTF-8 CSV; split huge files.
V. Summary
Open-source Tkinter tool filling the “compare Excel with pictures” gap.
VI. Full Source
import tkinter as tk
from tkinter import ttk, filedialog, messagebox
import pandas as pd
import os
import threading
import time
import copy
from openpyxl import load_workbook, Workbook
from openpyxl.drawing.image import Image as OpenpyxlImage
from openpyxl.utils.dataframe import dataframe_to_rows
# 全局变量存储文件数据(新增图片存储字段)
file_a_data = {"sheets": [], "data": {}, "path": "", "images": {}} # images: {sheet: [(img, row, col), ...]}
file_b_data = {"sheets": [], "data": {}, "path": "", "images": {}}
# 新增:存储共有数据及对应图片
compare_result = {
"a_not_b": None, "b_not_a": None, "a_common": None, "b_common": None,
"a_common_images": [], "b_common_images": []
}
# 整理表格相关全局变量(新增图片存储)
clean_file_data = {"sheets": [], "data": {}, "path": "", "images": {}}
cleaned_table_result = None
cleaned_table_images = [] # 整理后的图片:[(img, new_row, col), ...]
class TableCompareApp:
def __init__(self, root):
self.root = root
self.root.title("表格比对&整理工具")
self.root.geometry("950x850")
# 进度条变量
self.progress_var = tk.DoubleVar()
# 构建UI
self._create_widgets()
def _create_widgets(self):
# 1. 文件上传区域(原有比对功能)
upload_frame = ttk.LabelFrame(self.root, text="文件上传(比对功能)")
upload_frame.pack(padx=10, pady=10, fill="x")
# 文件A上传
ttk.Label(upload_frame, text="文件A:").grid(row=0, column=0, padx=5, pady=5, sticky="w")
self.file_a_label = ttk.Label(upload_frame, text="未选择文件", foreground="gray")
self.file_a_label.grid(row=0, column=1, padx=5, pady=5, sticky="w")
ttk.Button(upload_frame, text="选择文件", command=lambda: self.load_file("A")).grid(row=0, column=2, padx=5, pady=5)
# 文件B上传
ttk.Label(upload_frame, text="文件B:").grid(row=1, column=0, padx=5, pady=5, sticky="w")
self.file_b_label = ttk.Label(upload_frame, text="未选择文件", foreground="gray")
self.file_b_label.grid(row=1, column=1, padx=5, pady=5, sticky="w")
ttk.Button(upload_frame, text="选择文件", command=lambda: self.load_file("B")).grid(row=1, column=2, padx=5, pady=5)
# 2. 文件基本信息区域(原有)
info_frame = ttk.LabelFrame(self.root, text="文件基本信息")
info_frame.pack(padx=10, pady=5, fill="x")
self.file_a_info = ttk.Label(info_frame, text="文件A信息:无")
self.file_a_info.pack(padx=5, pady=2, anchor="w")
self.file_b_info = ttk.Label(info_frame, text="文件B信息:无")
self.file_b_info.pack(padx=10, pady=2, anchor="w")
# 3. 比对配置区域(原有)
config_frame = ttk.LabelFrame(self.root, text="比对配置(支持不同列比对)")
config_frame.pack(padx=10, pady=5, fill="x")
# 子表格选择
ttk.Label(config_frame, text="文件A子表格:").grid(row=0, column=0, padx=5, pady=5, sticky="w")
self.sheet_a_combobox = ttk.Combobox(config_frame, state="disabled")
self.sheet_a_combobox.grid(row=0, column=1, padx=5, pady=5, sticky="w")
ttk.Label(config_frame, text="文件B子表格:").grid(row=1, column=0, padx=5, pady=5, sticky="w")
self.sheet_b_combobox = ttk.Combobox(config_frame, state="disabled")
self.sheet_b_combobox.grid(row=1, column=1, padx=5, pady=5, sticky="w")
# 比对列选择
ttk.Label(config_frame, text="A表格比对列:").grid(row=2, column=0, padx=5, pady=5, sticky="w")
self.compare_col_a_combobox = ttk.Combobox(config_frame, state="disabled")
self.compare_col_a_combobox.grid(row=2, column=1, padx=5, pady=5, sticky="w")
ttk.Label(config_frame, text="B表格比对列:").grid(row=3, column=0, padx=5, pady=5, sticky="w")
self.compare_col_b_combobox = ttk.Combobox(config_frame, state="disabled")
self.compare_col_b_combobox.grid(row=3, column=1, padx=5, pady=5, sticky="w")
# 4. 操作按钮区域(新增:导出共有数据按钮)
compare_btn_frame = ttk.Frame(self.root)
compare_btn_frame.pack(padx=10, pady=10)
self.compare_btn = ttk.Button(compare_btn_frame, text="开始比对", command=self.start_compare, state="disabled")
self.compare_btn.pack(side="left", padx=5)
self.export_a_btn = ttk.Button(compare_btn_frame, text="导出A有B无的数据", command=lambda: self.export_result("a_not_b"), state="disabled")
self.export_a_btn.pack(side="left", padx=5)
self.export_b_btn = ttk.Button(compare_btn_frame, text="导出B有A无的数据", command=lambda: self.export_result("b_not_a"), state="disabled")
self.export_b_btn.pack(side="left", padx=5)
# 新增:导出共有数据按钮
self.export_common_btn = ttk.Button(compare_btn_frame, text="导出共有数据", command=self.export_common_result, state="disabled")
self.export_common_btn.pack(side="left", padx=5)
# ========== 表格整理功能区域 ==========
clean_frame = ttk.LabelFrame(self.root, text="表格整理功能(解决一行数据占多行问题)")
clean_frame.pack(padx=10, pady=15, fill="x")
# 选择要整理的文件
ttk.Label(clean_frame, text="待整理文件:").grid(row=0, column=0, padx=5, pady=5, sticky="w")
self.clean_file_label = ttk.Label(clean_frame, text="未选择文件", foreground="gray")
self.clean_file_label.grid(row=0, column=1, padx=5, pady=5, sticky="w")
ttk.Button(clean_frame, text="选择文件", command=self.load_clean_file).grid(row=0, column=2, padx=5, pady=5)
# 选择待整理的子表格
ttk.Label(clean_frame, text="待整理子表格:").grid(row=1, column=0, padx=5, pady=5, sticky="w")
self.clean_sheet_combobox = ttk.Combobox(clean_frame, state="disabled")
self.clean_sheet_combobox.grid(row=1, column=1, padx=5, pady=5, sticky="w")
# 选择关键列(判断新行的依据:关键列非空=新行)
ttk.Label(clean_frame, text="新行判断列:").grid(row=2, column=0, padx=5, pady=5, sticky="w")
self.clean_key_col_combobox = ttk.Combobox(clean_frame, state="disabled")
self.clean_key_col_combobox.grid(row=2, column=1, padx=5, pady=5, sticky="w")
# 整理/导出按钮
clean_btn_frame = ttk.Frame(clean_frame)
clean_btn_frame.grid(row=3, column=0, columnspan=3, pady=10)
self.clean_btn = ttk.Button(clean_btn_frame, text="开始整理表格", command=self.start_clean_table, state="disabled")
self.clean_btn.pack(side="left", padx=5)
self.export_clean_btn = ttk.Button(clean_btn_frame, text="导出整理后表格", command=self.export_cleaned_table, state="disabled")
self.export_clean_btn.pack(side="left", padx=5)
# ========== 进度条区域(共用) ==========
progress_frame = ttk.Frame(self.root)
progress_frame.pack(padx=10, pady=5, fill="x")
self.progress_bar = ttk.Progressbar(progress_frame, variable=self.progress_var, maximum=100)
self.progress_bar.pack(fill="x", padx=5, pady=5)
self.progress_label = ttk.Label(progress_frame, text="进度:0%")
self.progress_label.pack(anchor="center")
# ========== 核心修复:支持读取图片 ==========
def load_file(self, file_type):
"""加载比对用的A/B文件(支持读取图片)"""
file_path = filedialog.askopenfilename(
title=f"选择{file_type}文件",
filetypes=[("Excel文件", "*.xlsx"), ("CSV文件", "*.csv"), ("所有文件", "*.*")]
)
if not file_path:
return
# 初始化数据
if file_type == "A":
file_a_data.update({"sheets": [], "data": {}, "path": file_path, "images": {}})
self.file_a_label.config(text=os.path.basename(file_path))
target_data = file_a_data
else:
file_b_data.update({"sheets": [], "data": {}, "path": file_path, "images": {}})
self.file_b_label.config(text=os.path.basename(file_path))
target_data = file_b_data
try:
file_ext = os.path.splitext(file_path)[1].lower()
sheets = []
data_dict = {}
images_dict = {} # 存储每个sheet的图片 (img, row, col)
if file_ext == ".xlsx":
# 用openpyxl读取工作簿(保留图片)
wb = load_workbook(file_path, data_only=True)
sheets = wb.sheetnames
for sheet in sheets:
ws = wb[sheet]
# 读取数据到DataFrame
df = pd.DataFrame(ws.values)
# 设置列名(第一行)
if len(df) > 0:
df.columns = df.iloc[0]
df = df.drop(0).reset_index(drop=True)
else:
df.columns = []
data_dict[sheet] = df
# 提取图片及位置(openpyxl行/列从0开始,转换为1-based)
sheet_images = []
for img in ws._images:
row = img.anchor._from.row + 1 # 转换为1-based行号
col = img.anchor._from.col + 1 # 转换为1-based列号
sheet_images.append((img, row, col))
images_dict[sheet] = sheet_images
wb.close()
elif file_ext == ".csv":
sheets = ["默认表格"]
df = pd.read_csv(file_path)
data_dict["默认表格"] = df
images_dict["默认表格"] = [] # CSV无图片
else:
messagebox.showerror("错误", "仅支持xlsx和csv格式文件!")
return
# 更新数据和图片
target_data["sheets"] = sheets
target_data["data"] = data_dict
target_data["images"] = images_dict
# 更新信息显示(包含图片数)
if file_type == "A":
first_sheet = sheets[0]
first_df = data_dict[first_sheet]
img_count = len(images_dict[first_sheet])
info_text = f"文件A信息:格式={file_ext[1:].upper()} | 子表格数={len(sheets)} | "
info_text += f"首个表格行数={len(first_df)} | 列数={len(first_df.columns)} | 图片数={img_count}"
self.file_a_info.config(text=info_text)
self.sheet_a_combobox.config(state="normal", values=sheets)
self.sheet_a_combobox.current(0)
self.update_compare_columns()
else:
first_sheet = sheets[0]
first_df = data_dict[first_sheet]
img_count = len(images_dict[first_sheet])
info_text = f"文件B信息:格式={file_ext[1:].upper()} | 子表格数={len(sheets)} | "
info_text += f"首个表格行数={len(first_df)} | 列数={len(first_df.columns)} | 图片数={img_count}"
self.file_b_info.config(text=info_text)
self.sheet_b_combobox.config(state="normal", values=sheets)
self.sheet_b_combobox.current(0)
self.update_compare_columns()
self.check_compare_btn_state()
except Exception as e:
messagebox.showerror("读取失败", f"文件{file_type}读取错误:{str(e)}")
def load_clean_file(self):
"""加载待整理的表格文件(支持读取图片)"""
file_path = filedialog.askopenfilename(
title="选择待整理的表格文件",
filetypes=[("Excel文件", "*.xlsx"), ("CSV文件", "*.csv"), ("所有文件", "*.*")]
)
if not file_path:
return
# 清空原有整理文件数据
clean_file_data.update({"sheets": [], "data": {}, "path": file_path, "images": {}})
self.clean_file_label.config(text=os.path.basename(file_path))
try:
file_ext = os.path.splitext(file_path)[1].lower()
sheets = []
data_dict = {}
images_dict = {}
if file_ext == ".xlsx":
# 用openpyxl读取工作簿(保留图片)
wb = load_workbook(file_path, data_only=True)
sheets = wb.sheetnames
for sheet in sheets:
ws = wb[sheet]
# 读取数据到DataFrame
df = pd.DataFrame(ws.values)
# 设置列名(第一行)
if len(df) > 0:
df.columns = df.iloc[0]
df = df.drop(0).reset_index(drop=True)
else:
df.columns = []
data_dict[sheet] = df
# 提取图片及位置
sheet_images = []
for img in ws._images:
row = img.anchor._from.row + 1
col = img.anchor._from.col + 1
sheet_images.append((img, row, col))
images_dict[sheet] = sheet_images
wb.close()
elif file_ext == ".csv":
sheets = ["默认表格"]
df = pd.read_csv(file_path)
data_dict["默认表格"] = df
images_dict["默认表格"] = []
else:
messagebox.showerror("错误", "仅支持xlsx和csv格式文件!")
return
# 存储数据和图片
clean_file_data["sheets"] = sheets
clean_file_data["data"] = data_dict
clean_file_data["images"] = images_dict
# 更新子表格下拉框
self.clean_sheet_combobox.config(state="normal", values=sheets)
self.clean_sheet_combobox.current(0)
# 更新关键列下拉框(新行判断列)
self.update_clean_key_columns()
# 启用整理按钮
self.clean_btn.config(state="normal")
# 显示文件信息(包含图片数)
first_sheet = sheets[0]
first_df = data_dict[first_sheet]
img_count = len(images_dict[first_sheet])
info_text = f"待整理文件信息:格式={file_ext[1:].upper()} | 子表格数={len(sheets)} | "
info_text += f"首个表格行数={len(first_df)} | 列数={len(first_df.columns)} | 图片数={img_count}"
messagebox.showinfo("文件加载成功", info_text)
except Exception as e:
messagebox.showerror("读取失败", f"待整理文件读取错误:{str(e)}")
# ========== 通用导出函数(核心修复:支持导出图片) ==========
def export_with_images(self, df, images, title):
"""通用导出函数(支持图片保留)"""
# 选择导出路径
file_path = filedialog.asksaveasfilename(
title=title,
filetypes=[("Excel文件", "*.xlsx"), ("CSV文件", "*.csv")],
defaultextension=".xlsx"
)
if not file_path:
return
file_ext = os.path.splitext(file_path)[1].lower()
try:
if file_ext == ".xlsx":
# 创建新工作簿
wb = Workbook()
ws = wb.active
ws.title = "数据"
# 写入DataFrame数据(保留表头)
for r in dataframe_to_rows(df, index=False, header=True):
ws.append(r)
# 插入图片到对应位置
for img, row, col in images:
# 复制图片对象避免引用冲突
new_img = copy.deepcopy(img)
# 设置图片锚点(列字母+行号)
new_img.anchor = f"{chr(64+col)}{row}"
ws.add_image(new_img)
# 保存工作簿
wb.save(file_path)
wb.close()
messagebox.showinfo("导出成功", f"数据已导出至:{file_path}\n包含图片:{len(images)}张")
elif file_ext == ".csv":
# CSV不支持图片,提示用户
if images:
messagebox.showwarning("格式提示", "CSV格式不支持存储图片,图片将丢失!")
df.to_csv(file_path, index=False, encoding="utf-8-sig")
messagebox.showinfo("导出成功", f"数据已导出至:{file_path}\n注意:CSV格式不包含图片")
except Exception as e:
messagebox.showerror("导出失败", f"导出错误:{str(e)}")
# ========== 比对功能(修复:处理图片) ==========
def update_compare_columns(self):
"""更新比对列下拉框"""
if file_a_data["sheets"] and self.sheet_a_combobox.get():
sheet_a = self.sheet_a_combobox.get()
cols_a = file_a_data["data"][sheet_a].columns.tolist()
self.compare_col_a_combobox.config(state="normal", values=cols_a)
self.compare_col_a_combobox.current(0)
if file_b_data["sheets"] and self.sheet_b_combobox.get():
sheet_b = self.sheet_b_combobox.get()
cols_b = file_b_data["data"][sheet_b].columns.tolist()
self.compare_col_b_combobox.config(state="normal", values=cols_b)
self.compare_col_b_combobox.current(0)
def check_compare_btn_state(self):
"""检查比对按钮状态"""
if (file_a_data["path"] and file_b_data["path"] and
self.compare_col_a_combobox.get() and self.compare_col_b_combobox.get()):
self.compare_btn.config(state="normal")
else:
self.compare_btn.config(state="disabled")
def update_progress(self, value):
"""更新进度条"""
self.progress_var.set(value)
self.progress_label.config(text=f"进度:{int(value)}%")
self.root.update_idletasks()
def compare_task(self):
"""比对任务(修复:处理共有数据图片)"""
try:
# 1. 获取配置信息
sheet_a = self.sheet_a_combobox.get()
sheet_b = self.sheet_b_combobox.get()
col_a = self.compare_col_a_combobox.get()
col_b = self.compare_col_b_combobox.get()
# 2. 获取数据和图片
df_a = file_a_data["data"][sheet_a].copy()
df_b = file_b_data["data"][sheet_b].copy()
img_a_list = file_a_data["images"].get(sheet_a, [])
img_b_list = file_b_data["images"].get(sheet_b, [])
# 3. 进度条初始化
self.update_progress(0)
time.sleep(0.1)
# 4. 数据预处理
self.update_progress(20)
df_a[col_a] = df_a[col_a].astype(str).fillna("")
df_b[col_b] = df_b[col_b].astype(str).fillna("")
# 5. 核心比对逻辑
self.update_progress(50)
a_vals = set(df_a[col_a].unique())
b_vals = set(df_b[col_b].unique())
# A有B无的行
a_not_b_vals = a_vals - b_vals
a_not_b_df = df_a[df_a[col_a].isin(a_not_b_vals)].reset_index(drop=True)
# B有A无的行
b_not_a_vals = b_vals - a_vals
b_not_a_df = df_b[df_b[col_b].isin(b_not_a_vals)].reset_index(drop=True)
# 共有数据
common_vals = a_vals & b_vals
a_common_df = df_a[df_a[col_a].isin(common_vals)].reset_index(drop=True)
b_common_df = df_b[df_b[col_b].isin(common_vals)].reset_index(drop=True)
# 处理共有数据的图片(映射行号)
# A格式共有数据图片
a_common_original_rows = df_a[df_a[col_a].isin(common_vals)].index.tolist()
a_common_images = []
for img, orig_row, col in img_a_list:
orig_df_row = orig_row - 2 # Excel行1=表头,行2=df第0行
if orig_df_row in a_common_original_rows:
new_row = a_common_original_rows.index(orig_df_row) + 2 # 新表行2开始是数据
a_common_images.append((img, new_row, col))
# B格式共有数据图片
b_common_original_rows = df_b[df_b[col_b].isin(common_vals)].index.tolist()
b_common_images = []
for img, orig_row, col in img_b_list:
orig_df_row = orig_row - 2
if orig_df_row in b_common_original_rows:
new_row = b_common_original_rows.index(orig_df_row) + 2
b_common_images.append((img, new_row, col))
# 6. 存储结果
compare_result["a_not_b"] = a_not_b_df
compare_result["b_not_a"] = b_not_a_df
compare_result["a_common"] = a_common_df
compare_result["b_common"] = b_common_df
compare_result["a_common_images"] = a_common_images
compare_result["b_common_images"] = b_common_images
# 7. 完成进度
self.update_progress(100)
# 8. 启用导出按钮
self.export_a_btn.config(state="normal")
self.export_b_btn.config(state="normal")
self.export_common_btn.config(state="normal")
# 显示结果(包含图片数)
messagebox.showinfo("比对完成",
f"比对结果:\nA有B无的数据行数:{len(a_not_b_df)}\n"
f"B有A无的数据行数:{len(b_not_a_df)}\n"
f"共有数据行数(A格式):{len(a_common_df)} | 图片数:{len(a_common_images)}\n"
f"共有数据行数(B格式):{len(b_common_df)} | 图片数:{len(b_common_images)}")
except Exception as e:
messagebox.showerror("比对失败", f"比对过程出错:{str(e)}")
self.update_progress(0)
def start_compare(self):
"""启动比对"""
self.compare_btn.config(state="disabled")
self.export_a_btn.config(state="disabled")
self.export_b_btn.config(state="disabled")
self.export_common_btn.config(state="disabled")
compare_thread = threading.Thread(target=self.compare_task)
compare_thread.daemon = True
compare_thread.start()
def export_result(self, result_type):
"""导出比对结果(修复:支持图片)"""
if compare_result[result_type] is None:
messagebox.showwarning("提示", "暂无可导出的数据!")
return
# 筛选对应图片
if result_type == "a_not_b":
df = compare_result["a_not_b"]
sheet_a = self.sheet_a_combobox.get()
img_a_list = file_a_data["images"].get(sheet_a, [])
col_a = self.compare_col_a_combobox.get()
a_not_b_vals = set(df[col_a].unique())
a_not_b_original_rows = file_a_data["data"][sheet_a][file_a_data["data"][sheet_a][col_a].isin(a_not_b_vals)].index.tolist()
images = []
for img, orig_row, col in img_a_list:
orig_df_row = orig_row - 2
if orig_df_row in a_not_b_original_rows:
new_row = a_not_b_original_rows.index(orig_df_row) + 2
images.append((img, new_row, col))
title = "保存A有B无的数据"
elif result_type == "b_not_a":
df = compare_result["b_not_a"]
sheet_b = self.sheet_b_combobox.get()
img_b_list = file_b_data["images"].get(sheet_b, [])
col_b = self.compare_col_b_combobox.get()
b_not_a_vals = set(df[col_b].unique())
b_not_a_original_rows = file_b_data["data"][sheet_b][file_b_data["data"][sheet_b][col_b].isin(b_not_a_vals)].index.tolist()
images = []
for img, orig_row, col in img_b_list:
orig_df_row = orig_row - 2
if orig_df_row in b_not_a_original_rows:
new_row = b_not_a_original_rows.index(orig_df_row) + 2
images.append((img, new_row, col))
title = "保存B有A无的数据"
else:
return
self.export_with_images(df, images, title)
def export_common_result(self):
"""导出共有数据(修复:支持图片)"""
if compare_result["a_common"] is None or compare_result["b_common"] is None:
messagebox.showwarning("提示", "暂无共有数据可导出!")
return
# 选择导出格式
choice = messagebox.askquestion(
"选择导出格式",
"请选择共有数据的导出格式:\n【是】= 按A表格格式导出(保留A表格列结构)\n【否】= 按B表格格式导出(保留B表格列结构)",
icon="question"
)
if choice == "yes":
df = compare_result["a_common"]
images = compare_result["a_common_images"]
title = "保存按A表格格式的共有数据"
elif choice == "no":
df = compare_result["b_common"]
images = compare_result["b_common_images"]
title = "保存按B表格格式的共有数据"
else:
return
self.export_with_images(df, images, title)
# ========== 表格整理功能(修复:处理图片) ==========
def update_clean_key_columns(self):
"""更新整理功能的关键列下拉框"""
if clean_file_data["sheets"] and self.clean_sheet_combobox.get():
sheet = self.clean_sheet_combobox.get()
cols = clean_file_data["data"][sheet].columns.tolist()
self.clean_key_col_combobox.config(state="normal", values=cols)
self.clean_key_col_combobox.current(0)
def clean_table_task(self):
"""表格整理任务(修复:合并数据+保留图片)"""
global cleaned_table_result, cleaned_table_images
try:
# 获取配置
sheet = self.clean_sheet_combobox.get()
key_col = self.clean_key_col_combobox.get()
df = clean_file_data["data"][sheet].copy()
orig_images = clean_file_data["images"].get(sheet, [])
# 进度条初始化
self.update_progress(0)
time.sleep(0.1)
# 预处理
self.update_progress(10)
df = df.fillna("")
# 核心整理逻辑
self.update_progress(20)
cleaned_rows = []
current_row = None
orig_to_new_row = {} # 原df行号 → 新df行号映射
new_row_idx = 0
total_rows = len(df)
for idx, row in df.iterrows():
# 更新进度
progress = 20 + (idx / total_rows) * 70
self.update_progress(progress)
# 关键列非空 = 新行开始
if str(row[key_col]).strip() != "":
if current_row is not None:
cleaned_rows.append(current_row)
new_row_idx += 1
current_row = row.to_dict()
orig_to_new_row[idx] = new_row_idx
else:
# 补充到当前行
if current_row is not None:
for col in df.columns:
if str(row[col]).strip() != "" and str(current_row[col]).strip() == "":
current_row[col] = row[col]
orig_to_new_row[idx] = new_row_idx
# 保存最后一行
if current_row is not None:
cleaned_rows.append(current_row)
new_row_idx += 1
# 转换为DataFrame
self.update_progress(90)
cleaned_table_result = pd.DataFrame(cleaned_rows)
# 处理图片(映射到新行号)
cleaned_table_images = []
for img, orig_row, col in orig_images:
orig_df_row = orig_row - 2 # Excel行 → df行号
if orig_df_row in orig_to_new_row:
# 新Excel行号 = 新df行号 + 2(行1是表头)
new_excel_row = orig_to_new_row[orig_df_row] + 2
cleaned_table_images.append((img, new_excel_row, col))
# 完成进度
self.update_progress(100)
# 启用导出按钮
self.export_clean_btn.config(state="normal")
messagebox.showinfo("整理完成",
f"表格整理成功!\n原行数:{len(df)} | 整理后行数:{len(cleaned_table_result)}\n"
f"原图片数:{len(orig_images)} | 整理后图片数:{len(cleaned_table_images)}")
except Exception as e:
messagebox.showerror("整理失败", f"表格整理出错:{str(e)}")
self.update_progress(0)
def start_clean_table(self):
"""启动表格整理"""
if not self.clean_key_col_combobox.get():
messagebox.showwarning("提示", "请选择新行判断列!")
return
self.clean_btn.config(state="disabled")
self.export_clean_btn.config(state="disabled")
clean_thread = threading.Thread(target=self.clean_table_task)
clean_thread.daemon = True
clean_thread.start()
def export_cleaned_table(self):
"""导出整理后的表格(修复:保留图片)"""
global cleaned_table_result, cleaned_table_images
if cleaned_table_result is None:
messagebox.showwarning("提示", "暂无整理后的数据!")
return
self.export_with_images(cleaned_table_result, cleaned_table_images, "保存整理后的表格")
if __name__ == "__main__":
root = tk.Tk()
# 解决tkinter中文乱码(Windows)
try:
root.option_add("*Font", "SimHei 9")
except:
pass
app = TableCompareApp(root)
root.mainloop()