AI 十大论文精讲(九):无损失量化革命——LLM.int8 () 破解千亿大模型内存困局
系列第九篇精读《LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale》:为何朴素 int8 会伤精度、混合矩阵分解怎样做 outlier/channel 分拆、实验证明可在千亿参数规模上压低显存而不失稳。
系列文章前言
在人工智能技术从理论突破走向工程落地的进程中,一篇篇里程碑式的论文如同灯塔,照亮了技术演进的关键路径。为帮助大家吃透 AI 核心技术的底层逻辑、理清行业发展脉络,博主推出「AI 十大核心论文解读系列」,每篇聚焦一篇关键论文的问题背景、核心创新与行业影响。本篇博客解读AI领域十大论文的第九篇——《LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale》
一、引言:大模型的“内存焦虑”与量化技术的使命
大型语言模型(LLMs)在自然语言处理领域的应用日益广泛,但千亿参数规模的模型(如175B参数的OPT-175B、BLOOM-176B)面临严重的推理内存瓶颈。传统模型通常采用16位浮点(FP16)或32位浮点(FP32)存储参数,导致单模型内存占用动辄超过百GB,需依赖多GPU集群才能运行。
量化技术作为解决该问题的核心方案,通过将高比特精度参数映射到低比特(如8位整数Int8),可大幅降低内存占用并提升计算效率。然而,现有8位量化方法在处理超过6.7B参数的大模型时,普遍存在性能退化问题,其核心矛盾在于量化过程中无法平衡内存节省与精度保留。2022年发表的《LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale》一文,针对这一痛点提出了突破性解决方案,首次实现了千亿参数模型的无精度损失8位量化推理。

二、论文详细解读
2.1 核心挑战:为什么普通量化会让大模型“变笨”?
论文通过实证分析发现,大模型量化性能退化的关键诱因是涌现性异常值特征。当模型参数规模超过6.7B时, transformer的注意力投影层和前馈网络层中,会出现少量(约0.1%)但系统性的大幅值特征(幅值可达普通特征的20倍)。这些异常值具有高度规律性:集中在少数特征维度(最多7个),但覆盖75%的序列维度和所有网络层,且对模型的注意力权重计算和预测性能至关重要——移除这些异常值会导致top-1注意力softmax概率下降20%以上,验证困惑度提升600-1000%。传统量化方法(如逐张量absmax量化)采用全局统一的缩放因子,异常值会主导缩放过程,导致普通特征的量化精度被严重压缩,进而引发模型性能退化。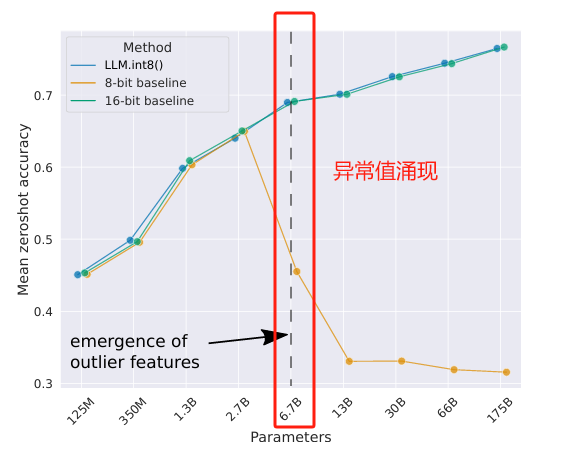
图1:OPT模型在WinoGrande、HellaSwag、PIQA和LAMBADA数据集上的零样本平均准确率。展示了16位基线模型、现有最精确的8位量化基线方法,以及本文提出的新型8位量化方法LLM.int8()。结果显示,当模型参数达到6.7B规模出现系统性异常值时,常规量化方法失效,而LLM.int8()仍能保持16位精度水平。
2.2 核心创新:LLM.int8()的混合精度量化方案
论文提出的LLM.int8()方法通过向量级量化与混合精度分解的双阶段策略,解决了异常值导致的量化精度问题:
- 向量级量化(Vector-wise Quantization):将矩阵乘法视为行向量与列向量的独立内积运算,为每个内积分配独立的归一化常数,而非全局统一缩放因子,从而提升普通特征的量化精度,可支持2.7B参数模型的无退化量化。
- 混合精度分解(Mixed-precision Decomposition):通过阈值α=6.0识别异常值特征维度,将占比0.1%的异常值特征分离出来,采用FP16精度进行矩阵乘法;其余99.9%的普通特征则采用Int8量化。该策略既保留了异常值的高精度计算,又维持了50%以上的内存节省(相比FP16),且额外内存开销仅0.1%。
整个流程为:先对FP16输入和权重进行异常值分解,再对普通特征执行向量级Int8量化与矩阵乘法,最后将Int8计算结果反归一化,并与异常值的FP16计算结果累加,输出FP16精度的最终结果。
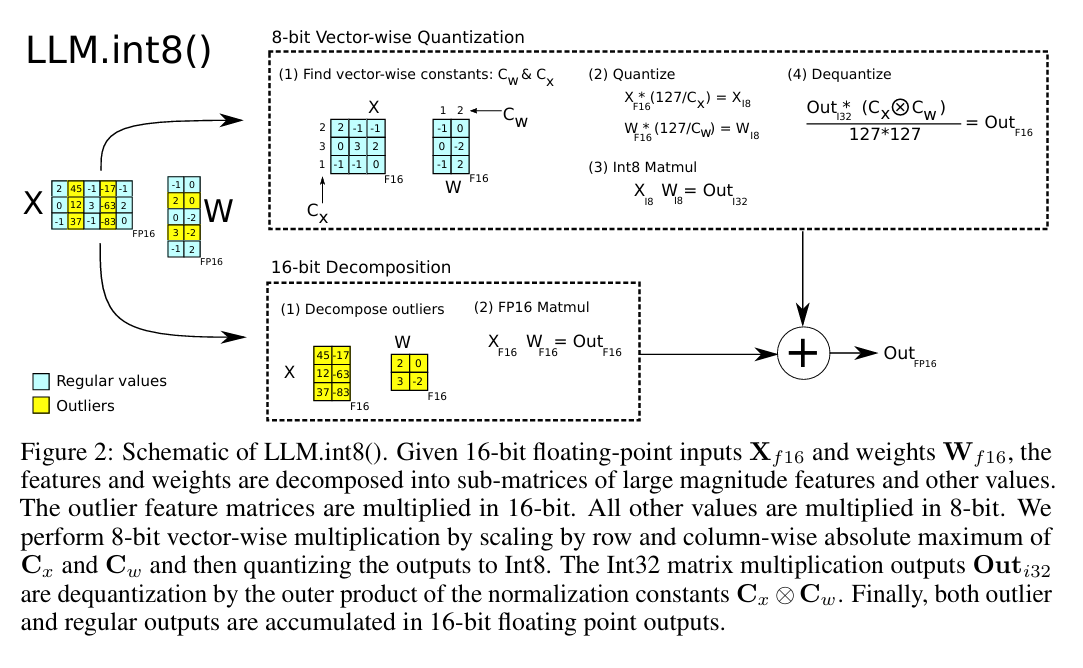
图2:LLM.int8()量化方法示意图。给定16位浮点型输入Xf16和权重Wf16,将特征与权重分解为大数值特征子矩阵及其他数值子矩阵:异常值特征矩阵采用16位精度执行乘法运算,其余所有数值均以8位精度计算。8位按向量乘法的实现流程为:通过Cx和Cw的行/列方向绝对最大值进行缩放,随后将输出量化为8位整型(Int8);8位整型矩阵乘法输出Outi32通过归一化常数Cx与Cw的外积完成反量化;最终将异常值输出与常规输出累加,得到16位浮点型最终结果。
2.3 实验验证:千亿参数模型的无退化量化奇迹
论文在125M到175B参数的多个模型(GPT-2、OPT、BLOOM等)上进行了验证,核心结果包括:
- 性能保持:在C4语料的语言建模任务中,LLM.int8()量化后的13B模型困惑度(12.45)与FP32基线完全一致,而传统Int8量化(absmax)的困惑度高达19.08;在WinoGrande、HellaSwag等零样本任务中,OPT-175B的量化模型准确率与FP16基线无差异,而传统8位量化模型性能退化至随机水平。
- 内存与效率:BLOOM-176B模型经LLM.int8()量化后,可在单台配备8张RTX 3090(24GB显存)的学术服务器上运行,而FP16版本需8张A100(40GB显存)才能支撑;对于175B参数模型,Int8矩阵乘法的推理速度比FP16快1.81倍,且端到端延迟接近FP16基线。
- 通用性:该方法适用于不同训练框架(Fairseq、OpenAI、TensorFlow-Mesh)和推理框架(Fairseq、Hugging Face Transformers),且对模型架构变体(旋转嵌入、残差缩放等)具有鲁棒性。
2.4 实际应用:大模型落地的“降本增效”神器
LLM.int8()的实际价值体现在大模型部署的全链条优化:
- 降低部署成本:通过将模型内存占用减半,减少了GPU硬件采购成本,例如学术机构无需依赖昂贵的A100集群,用消费级GPU即可开展千亿参数模型研究;云服务提供商可在相同GPU资源上部署更多模型实例,提升资源利用率。
- 加速原型开发:研究者可在本地GPU上快速加载大模型进行实验,无需等待集群资源,缩短迭代周期。
- 兼容参数高效微调:LLM.int8()可与LoRA等技术结合,在量化模型上进行任务特定微调,仅需训练少量适配器参数,即可进一步提升任务性能,且微调过程仍保持低内存占用。
2.5 局限与未来:量化技术的进一步探索
论文也指出了当前工作的局限:
- 仅支持Int8量化,未探索FP8等新型低比特浮点格式(受限于当前GPU硬件支持);
- 未覆盖注意力函数的Int8量化,仅针对前馈层和注意力投影层;
- 聚焦推理阶段,Int8训练仍面临性能退化问题,需更复杂的量化策略;
- 仅验证了175B参数模型,更大规模模型可能出现新的涌现特征,需进一步适配。
未来方向包括:FP8量化适配、注意力机制的低比特优化、Int8训练技术研发,以及更大规模模型的量化探索。
三、总结:量化技术重塑大模型的可及性
LLM.int8()通过对transformer模型中涌现性异常值特征的深刻洞察,提出了向量级量化与混合精度分解的创新组合,首次实现了千亿参数规模大模型的无性能退化Int8量化。该方法不仅解决了长期以来低比特量化与模型精度的矛盾,更将千亿参数模型的部署门槛从企业级GPU集群降至消费级GPU,极大提升了大模型的可及性。其核心贡献在于揭示了大模型量化性能退化的本质原因(异常值主导的缩放失真),并提供了高效且通用的解决方案,为后续低比特量化技术的发展奠定了理论与实践基础。

AI 十大論文精講(九):無損失量化革命——LLM.int8 () 破解千億大模型內存困局
系列第九篇精读《LLM.int8()》:說明大規模張量乘法在 int8 下為何失真、如何透過混合拆分處理 outlier 與通道縮放,並回顧作者在超大模型上對記憶體/精準度的量化實驗。
來源:https://blog.csdn.net/2403_87969572/article/details/155166578
抓取時間(ISO本地):2026-05-18 05:17:19
系列文章前言
在人工智能技術從理論突破走向工程落地的進程中,一篇篇里程碑式的論文如同燈塔,照亮了技術演進的關鍵路徑。為幫助大家吃透 AI 核心技術的底層邏輯、理清行業發展脈絡,博主推出「AI 十大核心論文解讀系列」,每篇聚焦一篇關鍵論文的問題背景、核心創新與行業影響。本篇博客解讀AI領域十大論文的第九篇——《LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale》
文章目錄
一、引言:大模型的“內存焦慮”與量化技術的使命
大型語言模型(LLMs)在自然語言處理領域的應用日益廣泛,但千億參數規模的模型(如175B參數的OPT-175B、BLOOM-176B)面臨嚴重的推理內存瓶頸。傳統模型通常採用16位浮點(FP16)或32位浮點(FP32)存儲參數,導致單模型內存佔用動輒超過百GB,需依賴多GPU集群才能運行。
量化技術作為解決該問題的核心方案,通過將高比特精度參數映射到低比特(如8位整數Int8),可大幅降低內存佔用並提升計算效率。然而,現有8位量化方法在處理超過6.7B參數的大模型時,普遍存在性能退化問題,其核心矛盾在於量化過程中無法平衡內存節省與精度保留。2022年發表的《LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale》一文,針對這一痛點提出了突破性解決方案,首次實現了千億參數模型的無精度損失8位量化推理。
二、論文詳細解讀
2.1 核心挑戰:為什麼普通量化會讓大模型“變笨”?
論文通過實證分析發現,大模型量化性能退化的關鍵誘因是湧現性異常值特徵。當模型參數規模超過6.7B時, transformer的注意力投影層和前饋網絡層中,會出現少量(約0.1%)但系統性的大幅值特徵(幅值可達普通特徵的20倍)。這些異常值具有高度規律性:集中在少數特徵維度(最多7個),但覆蓋75%的序列維度和所有網絡層,且對模型的注意力權重計算和預測性能至關重要——移除這些異常值會導致top-1注意力softmax概率下降20%以上,驗證困惑度提升600-1000%。傳統量化方法(如逐張量absmax量化)採用全局統一的縮放因子,異常值會主導縮放過程,導致普通特徵的量化精度被嚴重壓縮,進而引發模型性能退化。
圖1:OPT模型在WinoGrande、HellaSwag、PIQA和LAMBADA數據集上的零樣本平均準確率。展示了16位基線模型、現有最精確的8位量化基線方法,以及本文提出的新型8位量化方法LLM.int8()。結果顯示,當模型參數達到6.7B規模出現系統性異常值時,常規量化方法失效,而LLM.int8()仍能保持16位精度水平。
2.2 核心創新:LLM.int8()的混合精度量化方案
論文提出的LLM.int8()方法通過向量級量化與混合精度分解的雙階段策略,解決了異常值導致的量化精度問題:
- 向量級量化(Vector-wise Quantization):將矩陣乘法視為行向量與列向量的獨立內積運算,為每個內積分配獨立的歸一化常數,而非全局統一縮放因子,從而提升普通特徵的量化精度,可支持2.7B參數模型的無退化量化。
- 混合精度分解(Mixed-precision Decomposition):通過閾值α=6.0識別異常值特徵維度,將佔比0.1%的異常值特徵分離出來,採用FP16精度進行矩陣乘法;其餘99.9%的普通特徵則採用Int8量化。該策略既保留了異常值的高精度計算,又維持了50%以上的內存節省(相比FP16),且額外內存開銷僅0.1%。
整個流程為:先對FP16輸入和權重進行異常值分解,再對普通特徵執行向量級Int8量化與矩陣乘法,最後將Int8計算結果反歸一化,並與異常值的FP16計算結果累加,輸出FP16精度的最終結果。
圖2:LLM.int8()量化方法示意圖。給定16位浮點型輸入Xf16和權重Wf16,將特徵與權重分解為大數值特徵子矩陣及其他數值子矩陣:異常值特徵矩陣採用16位精度執行乘法運算,其餘所有數值均以8位精度計算。8位按向量乘法的實現流程為:通過Cx和Cw的行/列方向絕對最大值進行縮放,隨後將輸出量化為8位整型(Int8);8位整型矩陣乘法輸出Outi32通過歸一化常數Cx與Cw的外積完成反量化;最終將異常值輸出與常規輸出累加,得到16位浮點型最終結果。
2.3 實驗驗證:千億參數模型的無退化量化奇蹟
論文在125M到175B參數的多個模型(GPT-2、OPT、BLOOM等)上進行了驗證,核心結果包括:
- 性能保持:在C4語料的語言建模任務中,LLM.int8()量化後的13B模型困惑度(12.45)與FP32基線完全一致,而傳統Int8量化(absmax)的困惑度高達19.08;在WinoGrande、HellaSwag等零樣本任務中,OPT-175B的量化模型準確率與FP16基線無差異,而傳統8位量化模型性能退化至隨機水平。
- 內存與效率:BLOOM-176B模型經LLM.int8()量化後,可在單臺配備8張RTX 3090(24GB顯存)的學術服務器上運行,而FP16版本需8張A100(40GB顯存)才能支撐;對於175B參數模型,Int8矩陣乘法的推理速度比FP16快1.81倍,且端到端延遲接近FP16基線。
- 通用性:該方法適用於不同訓練框架(Fairseq、OpenAI、TensorFlow-Mesh)和推理框架(Fairseq、Hugging Face Transformers),且對模型架構變體(旋轉嵌入、殘差縮放等)具有魯棒性。
2.4 實際應用:大模型落地的“降本增效”神器
LLM.int8()的實際價值體現在大模型部署的全鏈條優化:
- 降低部署成本:通過將模型內存佔用減半,減少了GPU硬件採購成本,例如學術機構無需依賴昂貴的A100集群,用消費級GPU即可開展千億參數模型研究;雲服務提供商可在相同GPU資源上部署更多模型實例,提升資源利用率。
- 加速原型開發:研究者可在本地GPU上快速加載大模型進行實驗,無需等待集群資源,縮短迭代週期。
- 兼容參數高效微調:LLM.int8()可與LoRA等技術結合,在量化模型上進行任務特定微調,僅需訓練少量適配器參數,即可進一步提升任務性能,且微調過程仍保持低內存佔用。
2.5 侷限與未來:量化技術的進一步探索
論文也指出了當前工作的侷限:
- 僅支持Int8量化,未探索FP8等新型低比特浮點格式(受限於當前GPU硬件支持);
- 未覆蓋注意力函數的Int8量化,僅針對前饋層和注意力投影層;
- 聚焦推理階段,Int8訓練仍面臨性能退化問題,需更復雜的量化策略;
- 僅驗證了175B參數模型,更大規模模型可能出現新的湧現特徵,需進一步適配。
未來方向包括:FP8量化適配、注意力機制的低比特優化、Int8訓練技術研發,以及更大規模模型的量化探索。
三、總結:量化技術重塑大模型的可及性
LLM.int8()通過對transformer模型中湧現性異常值特徵的深刻洞察,提出了向量級量化與混合精度分解的創新組合,首次實現了千億參數規模大模型的無性能退化Int8量化。該方法不僅解決了長期以來低比特量化與模型精度的矛盾,更將千億參數模型的部署門檻從企業級GPU集群降至消費級GPU,極大提升了大模型的可及性。其核心貢獻在於揭示了大模型量化性能退化的本質原因(異常值主導的縮放失真),並提供了高效且通用的解決方案,為後續低比特量化技術的發展奠定了理論與實踐基礎。
AI Top Papers (9): Lossless Quantization Revolution—How LLM.int8() Breaks the Memory Wall for 100B+ Models
Deep dive into LLM.int8(): naive 8-bit GEMM outliers in hundred-billion-parameter stacks, structured mixed decomposition tricks, empirical memory wins without obvious quality regressions.
Captured at (local ISO): 2026-05-18 05:17:19
Series Preface
As AI moves from theory to engineering, landmark papers light the path forward. This “AI Top 10 Papers” series explains background, core ideas, and impact one paper at a time. This installment covers paper nine: LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale.
1. Introduction: LLM “memory anxiety” and the mission of quantization
Large language models (LLMs) are everywhere, but 100B+ models (e.g. OPT-175B, BLOOM-176B) hit a hard inference memory wall. FP16/FP32 weights can exceed 100GB per model and need multi-GPU clusters. Quantization maps high-bit weights to low-bit integers (e.g. Int8) to cut memory and speed matmul—but past 6.7B parameters, many 8-bit methods degrade badly, trading memory for accuracy. The 2022 LLM.int8() paper targets that gap and reports lossless 8-bit inference at 100B+ scale for the first time.
2. Paper deep dive
2.1 Why naive quantization makes big models “dumber”
The authors show degradation comes from emergent outlier features. Beyond ~6.7B parameters, a small (~0.1%) but systematic set of very large activations appears in attention projections and FFN layers (up to ~20× typical magnitude). They concentrate in few feature dims (≤7) but span ~75% of sequence positions and all layers, and matter for attention and perplexity—removing them drops top-1 softmax mass by >20% and raises validation perplexity by 600–1000%. Global absmax scaling lets outliers dominate the scale factor and crushes precision for normal features.
Figure 1: Zero-shot average accuracy on WinoGrande, HellaSwag, PIQA, LAMBADA for OPT. At 6.7B+, standard 8-bit methods fail while LLM.int8() matches FP16.
2.2 Core innovation: hybrid-precision LLM.int8()
LLM.int8() combines vector-wise quantization and mixed-precision decomposition:
- Vector-wise quantization: treat matmul as independent dot products per row/column with per-dot scale—not one global scale—improving normal-feature precision (works to ~2.7B without degradation).
- Mixed-precision decomposition: with threshold α=6.0, split ~0.1% outlier dimensions to FP16 matmul; the other 99.9% use Int8. Keeps outlier fidelity, still ~50% memory vs FP16, with only ~0.1% extra memory.
Pipeline: decompose FP16 inputs/weights → Int8 vector-wise matmul on normal part → dequantize → add FP16 outlier product → FP16 output.
Figure 2: LLM.int8() schematic—outlier submatrices in FP16, bulk in Int8 with per-vector scales and dequantization.
2.3 Experiments: 100B-scale models without degradation
Results on 125M–175B models (GPT-2, OPT, BLOOM, etc.):
- Quality: On C4, 13B LLM.int8() perplexity 12.45 matches FP32; absmax Int8 hits 19.08. On zero-shot benchmarks, OPT-175B LLM.int8() matches FP16; naive 8-bit collapses toward random.
- Memory/speed: BLOOM-176B LLM.int8() runs on 8× RTX 3090 (24GB); FP16 needs 8× A40 40GB. At 175B, Int8 matmul is 1.81× faster than FP16 with near FP16 end-to-end latency.
- Generality: Works across training stacks (Fairseq, OpenAI, Mesh-TF) and inference (Fairseq, Hugging Face), robust to architectural tweaks.
2.4 Deployment: cost and efficiency wins
- Lower cost: halving memory cuts hardware needs—researchers can use consumer GPUs; clouds fit more instances per card.
- Faster iteration: load huge models locally without cluster queues.
- PEFT friendly: pairs with LoRA adapters on quantized weights for task tuning with low memory.
2.5 Limits and future work
- Int8 only in this work; FP8 awaits hardware;
- attention not Int8-quantized in the paper;
- inference-focused; Int8 training still hard;
- validated to 175B; larger models may need new tricks.
Future: FP8, low-bit attention, Int8 training, larger-scale studies.
3. Conclusion: quantization reshapes LLM accessibility
LLM.int8() explains outlier-driven scale collapse and fixes it with vector-wise Int8 plus FP16 outliers—enabling 100B+ deployment without accuracy loss. It lowers the bar from enterprise clusters toward consumer GPUs and sets a template for later low-bit methods.