AI 十大论文精讲(八):知识蒸馏如何让大模型 “瘦身不减能”
系列第八篇精读 DistilBERT:相较直接剪枝 teacher,为何要在预训练阶段做知识蒸馏并叠加三重损失,学生模型的结构删减策略,以及在 GLUE、IMDb、SQuAD 与端到端吞吐上换来了哪些折中答案。
系列文章前言
在人工智能技术从理论突破走向工程落地的进程中,一篇篇里程碑式的论文如同灯塔,照亮了技术演进的关键路径。为帮助大家吃透 AI 核心技术的底层逻辑、理清行业发展脉络,博主推出「AI 十大核心论文解读系列」,每篇聚焦一篇关键论文的问题背景、核心创新与行业影响。本篇博客解读AI领域十大论文的第八篇——《DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter》
一、研究背景:大模型的“甜蜜烦恼”——规模与落地的核心矛盾
近年来,迁移学习在自然语言处理(NLP)领域迎来爆发式普及,以BERT为代表的大规模预训练语言模型通过“预训练-微调”范式,在情感分类、问答系统、文本推理等众多下游任务中实现了性能飞跃,成为现代NLP技术栈的核心基础。然而,这些模型的“大尺寸”特性逐渐显现出不可忽视的现实困境:
一方面,模型参数规模呈指数级增长,从BERT-base的1.1亿参数到后续MegatronLM等超大规模模型的千亿级参数,带来了惊人的计算与能源消耗。正如Schwartz等人[2019]在《Green AI》中指出的,大模型训练过程的碳排放量相当于数辆汽车的终身碳足迹;Strubell等人[2019]的研究也显示,训练一个大型NLP模型的能源消耗甚至超过普通家庭数十年的用电量,环境代价与可持续性问题日益突出。
另一方面,大模型的部署门槛极高。其庞大的内存占用(BERT-base推理需占用数十GB显存)和高延迟(CPU端单批次推理耗时数百秒),使其难以适配边缘设备(如智能手机、智能穿戴设备、工业传感器)的实时计算场景。而边缘设备的离线处理、低延迟响应、数据隐私保护等需求,恰恰是AI技术从“云端”走向“终端”的关键突破口——用户需要无需联网的离线翻译、低延迟的语音助手、本地处理敏感文本的分析工具,这些场景都对模型的轻量化提出了刚性要求。
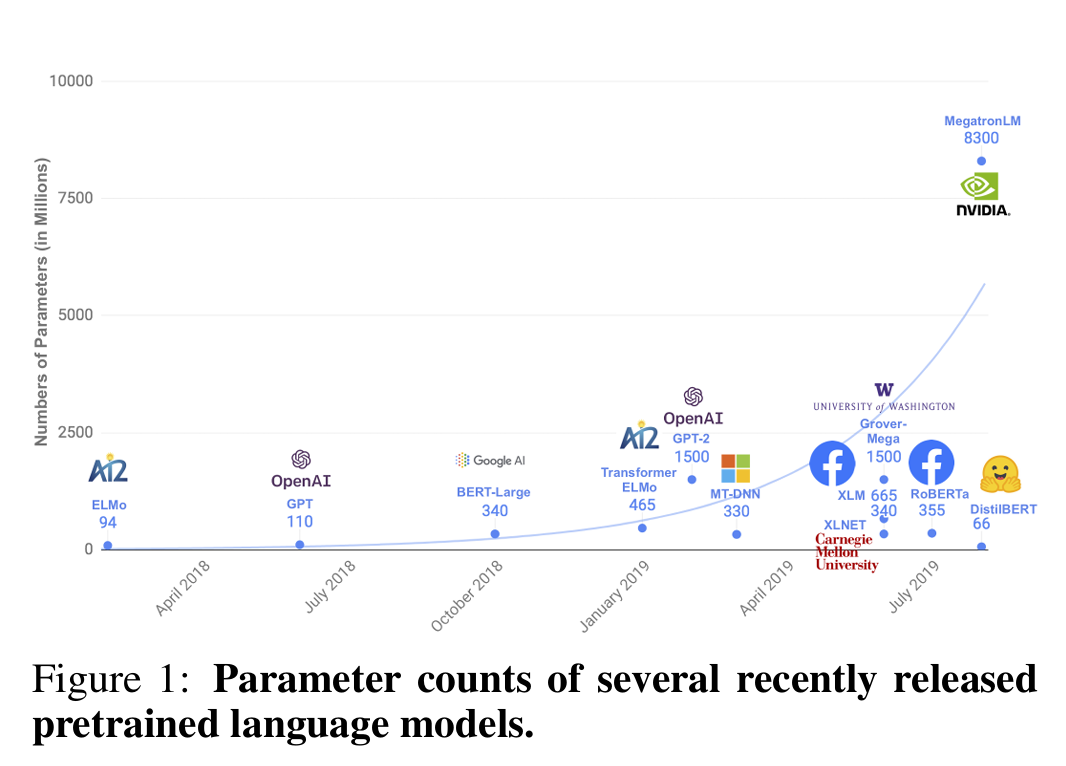
核心痛点已明确:现有大模型的“规模-效率”失衡,缺乏一种既能保留通用语言理解能力,又能适配低资源环境部署的通用解决方案。 DistilBERT的诞生,正是为了破解这一矛盾。
二、论文深度解读:知识蒸馏驱动的通用模型轻量化方案
1. 核心方案:预训练蒸馏+三重损失+轻量化架构设计
DistilBERT的核心创新在于将知识蒸馏技术从“任务特定阶段”迁移至“预训练阶段”,构建通用型轻量化模型,而非针对单个下游任务定制压缩模型。其技术路径可拆解为“蒸馏框架设计”“模型架构优化”“训练策略创新”三大模块,形成闭环优化。
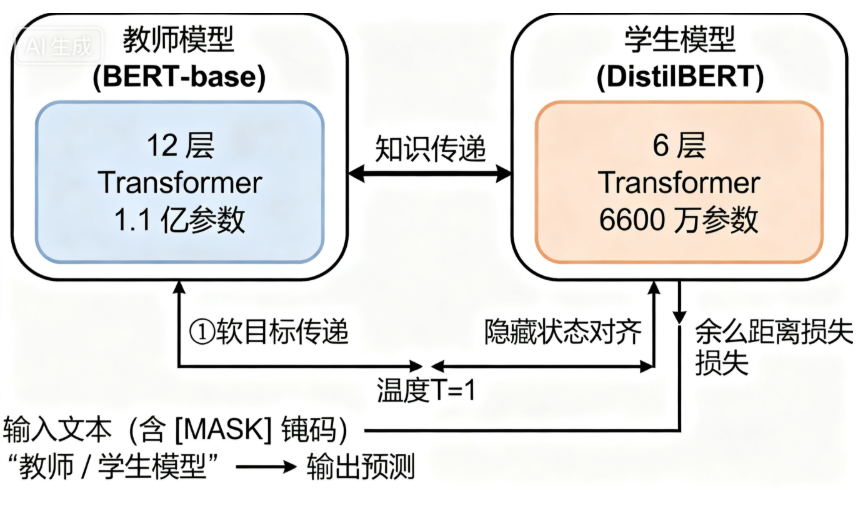
1.1 知识蒸馏的本质与三重损失函数
知识蒸馏(Knowledge Distillation)的核心逻辑是:让参数紧凑的“学生模型”(DistilBERT)通过学习参数庞大的“教师模型”(BERT-base)的“知识”,实现性能逼近。这里的“知识”不仅包括教师模型的最终预测结果(硬目标),更包括其预测分布中蕴含的泛化信息(软目标)。为实现高效知识迁移,论文设计了三重损失函数(Triple Loss),各组件各司其职且相互补充:
-
蒸馏损失( L c e L_{ce} Lce:Cross-Entropy Loss)
核心目标是让学生模型模仿教师模型的软目标概率分布。传统分类任务中,模型输出的硬目标(one-hot向量)仅包含正确标签的信息,而软目标(通过温度参数T平滑后的概率分布)能反映教师模型对不同类别(或token)的置信度差异,蕴含更丰富的泛化知识。
具体计算过程为:-
对教师模型和学生模型的原始输出(logits)分别应用带温度T的软max函数,得到软目标概率: p i
exp ( z i / T ) ∑ j exp ( z j / T ) p_i = \frac{\exp(z_i/T)}{\sum_j \exp(z_j/T)} pi=∑jexp(zj/T)exp(zi/T),其中 z i z_i zi为模型对类别i的原始得分,T为温度参数(论文中T=1)。 -
蒸馏损失为学生软目标与教师软目标的交叉熵: L c e
∑ i t i ⋅ log ( s i ) L_{ce} = \sum_i t_i \cdot \log(s_i) Lce=∑iti⋅log(si),其中 t i t_i ti为教师软目标概率, s i s_i si为学生软目标概率。 - 该损失确保学生模型不仅“学会答案”,更“学会教师的思考方式”。
-
-
掩码语言建模损失( L m l m L_{mlm} Lmlm:Masked Language Modeling Loss)
继承BERT的核心预训练目标,通过随机掩码输入文本中的部分token(如15%的token被掩码),让模型预测被掩码的原始token。这一损失确保学生模型不会因模仿教师而丢失基础语言理解能力(如词汇语义、语法结构),为通用语言任务提供底层支撑。
论文中,DistilBERT采用了动态掩码策略(与RoBERTa一致),即每个训练批次对文本重新生成掩码,而非固定掩码模式,提升了预训练数据的多样性。 -
余弦距离损失( L c o s L_{cos} Lcos:Cosine-Distance Loss)
目标是对齐学生模型与教师模型的隐藏状态向量空间。具体而言,计算教师模型和学生模型对应层的隐藏状态向量的余弦相似度,最小化二者的距离: L c o s1 − cos ( h t , h s ) L_{cos} = 1 - \cos(h_t, h_s) Lcos=1−cos(ht,hs),其中 h t h_t ht为教师隐藏状态, h s h_s hs为学生隐藏状态。
该损失的核心作用是确保学生模型的特征表示空间与教师模型一致——即使模型结构简化,其提取的语言特征仍能保留教师模型的语义层次,避免因结构压缩导致特征失真。
最终的训练目标为三重损失的加权和: L t o t a l
α L c e + β L m l m + γ L c o s L_{total} = \alpha L_{ce} + \beta L_{mlm} + \gamma L_{cos} Ltotal=αLce+βLmlm+γLcos(论文中未明确给出权重,但通过消融实验验证了三者的必要性)。
1.2 轻量化架构设计:聚焦“高效压缩”而非“盲目缩减”
DistilBERT并未对BERT的核心Transformer架构进行颠覆性修改,而是基于“计算效率优先级”进行针对性优化,确保压缩后仍能保留Transformer的并行计算优势:
| 优化方向 | 具体措施 | 设计依据 |
|---|---|---|
| 移除冗余组件 | 删除token-type嵌入和pooler层 | 1. token-type嵌入用于区分句子对(如MNLI任务中的前提句与假设句),但DistilBERT预训练阶段移除了下一句预测(NSP)任务,该嵌入失去作用;2. pooler层用于生成句子级别的固定维度表示(适用于分类任务),但DistilBERT作为通用模型,微调时可通过简单的均值池化或全连接层替代,移除后可减少参数冗余。 |
| 精简网络层数 | 将Transformer层数从12层减半至6层 | 论文通过实验验证:在固定参数预算下,Transformer层数对计算效率的影响远大于隐藏层维度(hidden size)——层数减少可直接降低推理时的串行计算步骤,而隐藏层维度缩减会导致特征表达能力大幅下降,且现代线性代数框架(如CUDA)对隐藏层维度的优化更充分,缩减带来的效率提升有限。 |
| 保持核心维度 | 隐藏层维度(768)、注意力头数(12)与BERT-base一致 | 确保学生模型与教师模型的特征维度兼容,为隐藏状态对齐(余弦距离损失)和层采样初始化提供基础。 |
1.3 训练策略:继承教师知识,加速收敛
为解决小模型训练易陷入局部最优的问题,DistilBERT采用了“教师模型参数初始化”策略:利用教师模型与学生模型的架构兼容性(层数减半),从教师模型中每两层抽取一层的参数作为学生模型对应层的初始参数(如教师第2层参数作为学生第1层,教师第4层作为学生第2层,以此类推)。
这种初始化方式的核心优势在于:学生模型无需从零开始学习语言知识,而是直接继承教师模型预训练后的“先验知识”,既能加速训练收敛(减少约30%的训练迭代次数),又能避免随机初始化导致的性能波动。
训练细节补充:
- 训练语料:与BERT-base完全一致,即英文维基百科(约25亿词)+多伦多图书语料库(约8亿词),确保预训练数据的一致性对比;
- 训练配置:使用8台16GB V100 GPU,通过梯度累积将批次大小扩大至4K(单GPU批次大小为512,8台GPU×512=4096),动态掩码,训练时长约90小时;
- 对比基准:RoBERTa(BERT的优化版本)需在1024台32GB V100 GPU上训练1天,DistilBERT的训练硬件成本仅为RoBERTa的约1/300,充分体现了“cheaper”的优势。
2. 实验结果:全方位验证“轻量化不减能”
论文从通用语言理解、下游任务适配、速度与部署、 ablation验证四个维度展开实验,全面验证DistilBERT的性能与效率优势。
2.1 通用语言理解:GLUE基准测试
GLUE基准包含9个不同类型的NLP任务(涵盖句子级分类、文本相似度、问答推理等),是评估通用语言模型能力的核心标准。实验采用“单任务微调”模式(不使用集成模型或多任务微调),确保结果的客观性。
核心结论:
- 性能保留率:DistilBERT的GLUE宏平均得分为77.0,相较于BERT-base的79.5,保留了97%的语言理解能力,而参数规模从1.1亿减少至6600万,压缩比达40%;
- 任务适配性:在所有9个任务中,DistilBERT均优于ELMo基线(最高在STS-B任务上提升19个准确率点),其中在SST-2(情感分类)、MRPC(句子对匹配)等任务上与BERT-base差距不足2个百分点,仅在RTE(文本推理)、WNLI(代词指代消解)等对推理能力要求较高的任务上差距略大(约5-10个百分点);
- 稳定性:实验报告5次不同随机种子的中位数结果,DistilBERT的标准差与BERT-base接近,说明其训练过程稳定,未因模型压缩导致泛化能力下降。
2.2 下游任务专项测试:IMDb与SQuAD
为验证DistilBERT在实际应用场景中的表现,论文选择了两个典型下游任务:
-
IMDb情感分类(二分类任务,测试集含25000条评论):
- DistilBERT测试准确率为92.82%,仅落后BERT-base(93.46%)0.64个百分点,证明其在单句子分类任务上的性能逼近大模型;
-
SQuAD 1.1问答任务(抽取式问答,含10万+问题):
- 基础版本:EM(精确匹配)=77.7,F1=85.8,与BERT-base(81.2/88.5)差距分别为3.5和2.7;
- 二次蒸馏版本(DistilBERT (D)):在微调阶段以BERT-base微调后的模型为教师,新增蒸馏损失,EM提升至79.1,F1提升至86.9,差距进一步缩小至2.1和1.6。
二次蒸馏的提升验证了“预训练蒸馏+微调蒸馏”的叠加效应——微调阶段的教师模型已适配具体任务,其知识更具针对性,能进一步弥补学生模型的性能差距。
2.3 速度与部署测试:边缘设备适配性
论文重点测试了DistilBERT在受限环境下的表现,为边缘部署提供数据支撑:
| 测试场景 | 测试条件 | 结果对比 |
|---|---|---|
| CPU推理速度 | Intel Xeon E5-2690 v3 @2.9GHz,单批次(batch size=1),STS-B任务 | DistilBERT推理时间410秒,BERT-base为668秒,速度提升60%;ELMo(1.8亿参数)为895秒,DistilBERT在参数更少的情况下速度远超ELMo。 |
| 移动端推理速度 | iPhone 7 Plus,排除分词步骤,问答任务 | DistilBERT平均推理时间比BERT-base快71%,模型体积仅207MB(BERT-base约410MB),支持本地存储与离线运行。 |
关键补充:论文提到可通过量化技术(如INT8量化)进一步压缩模型体积,预计可将207MB缩减至50MB以下,完全满足智能穿戴设备等内存受限场景的需求。
2.4 Ablation研究:拆解核心组件的贡献
为明确三重损失函数与初始化策略的必要性,论文进行了控制变量法实验(以GLUE宏得分为指标,基准分为77.0):
| 消融方案 | 性能变化(Δ) | 核心分析 |
|---|---|---|
| 移除余弦距离损失( L c o s L_{cos} Lcos) | -1.46(得分75.54) | 余弦距离损失确保了学生与教师的特征空间对齐,移除后特征表达出现偏差,导致下游任务性能下降,但影响相对有限,说明基础语言能力仍由 L m l m L_{mlm} Lmlm和 L c e L_{ce} Lce保障。 |
| 移除蒸馏损失( L c e L_{ce} Lce) | -2.96(得分74.04) | 蒸馏损失是传递教师泛化知识的核心,移除后学生模型仅依赖 L m l m L_{mlm} Lmlm学习基础语言知识,缺乏教师的“经验指导”,泛化能力大幅下降,证明蒸馏是性能保留的关键。 |
| 移除掩码语言建模损失( L m l m L_{mlm} Lmlm) | -0.31(得分76.69) | 影响最小,说明教师模型的软目标中已蕴含部分基础语言知识,学生模型通过模仿教师即可部分掌握,但 L m l m L_{mlm} Lmlm仍能提供补充信号,避免基础能力缺失。 |
| 随机初始化替代教师层采样 | -3.69(得分73.31) | 最大性能下降,证明教师模型的初始化参数为学生模型提供了关键的“知识起点”,随机初始化导致学生模型需重新学习语言规律,不仅训练收敛慢,且易陷入局部最优。 |
3. 相关工作对比:DistilBERT的核心差异化优势
在DistilBERT之前,NLP领域已有多种模型压缩方案,但DistilBERT通过“通用预训练蒸馏”的定位,形成了独特优势:
| 压缩方案类型 | 代表工作 | 核心特点 | DistilBERT的差异化优势 |
|---|---|---|---|
| 任务特定蒸馏 | Tang et al. [2019]、Chatterjee [2019] | 1. 针对单个下游任务(如分类、问答);2. 流程为“大模型微调→蒸馏为小模型”;3. 小模型仅适用于特定任务,灵活性差。 | 1. 预训练阶段蒸馏,得到通用型小模型;2. 可直接用于所有下游任务微调,无需重复蒸馏;3. 兼顾性能与灵活性,适配多样化场景。 |
| 单一目标预训练压缩 | Turc et al. [2019] | 1. 仅使用掩码语言建模损失训练小模型;2. 未利用教师模型的知识,性能依赖数据量与训练策略。 | 1. 融合三重损失,充分吸收教师模型的泛化知识;2. 性能更优(GLUE得分77.0 vs Turc等人的约75.0)。 |
| 多教师蒸馏 | Yang et al. [2019] | 1. 利用多个教师模型的集成知识;2. 适用于特定任务(如问答系统),训练复杂度高。 | 1. 单教师模型蒸馏,训练成本低;2. 通用型模型,无需针对任务设计教师集成策略。 |
| 剪枝与量化 | Michel et al. [2019]、Gupta et al. [2015] | 1. 剪枝:移除冗余参数(如注意力头、神经元);2. 量化:降低参数数值精度(如FP32→INT8);3. 属于“后处理压缩”,需在训练后额外优化。 | 1. 属于“训练时压缩”,通过架构设计与蒸馏直接得到轻量化模型;2. 与剪枝、量化正交,可结合使用(如DistilBERT+量化,压缩比可达80%以上)。 |
4. 应用场景与产业价值:解锁边缘AI的无限可能
DistilBERT的核心价值在于打破了“大模型=高性能”与“小模型=低延迟”的二元对立,为AI技术在边缘设备的落地提供了“高性能+高效率”的解决方案。其典型应用场景包括:
4.1 离线NLP应用
- 场景需求:无网络环境下的文本处理(如野外作业的文档分析、无信号区域的翻译工具);
- 适配优势:207MB的模型体积可轻松存储于手机、平板等设备,离线推理速度满足实时响应(移动端单句处理耗时<100ms);
- 案例:离线翻译APP(如基于DistilBERT的英中翻译工具)、本地文本纠错软件。
4.2 低延迟实时交互系统
- 场景需求:语音助手、智能客服等需要快速响应的交互场景(延迟要求<500ms);
- 适配优势:CPU推理速度提升60%,无需依赖高端GPU,普通服务器即可支撑高并发请求;
- 案例:智能手表的语音转文字实时分析、电商平台的实时评论情感识别。
4.3 隐私保护型NLP工具
- 场景需求:医疗、金融等敏感领域的文本分析(如电子病历处理、客户隐私信息提取),数据不可上传云端;
- 适配优势:本地部署无需传输数据,避免隐私泄露,同时轻量化模型降低了本地硬件的计算压力;
- 案例:医院本地电子病历关键词提取系统、银行客户信息脱敏工具。
4.4 资源受限设备部署
- 场景需求:智能摄像头的文本识别(如车牌识别、快递单号读取)、物联网设备的简单文本处理;
- 适配优势:模型体积小、内存占用低(推理时内存占用<1GB),可运行于嵌入式芯片(如NVIDIA Jetson Nano);
- 案例:智能快递柜的单号自动识别、工业传感器的文本日志分析。
三、总结与未来展望
1. 核心贡献回顾
DistilBERT通过“预训练阶段知识蒸馏+三重损失函数+轻量化架构设计”的创新组合,成功实现了BERT模型的高效压缩:
- 性能层面:保留97%的通用语言理解能力,在下游任务中逼近BERT-base;
- 效率层面:参数减少40%,推理速度提升60%,训练成本降低数百倍;
- 落地层面:首次实现通用预训练模型的边缘部署,解锁了NLP技术的多样化应用场景。
其核心启示在于:模型压缩的关键并非“盲目缩减参数”,而是“高效传递知识”——通过蒸馏技术让小模型继承大模型的泛化能力,同时优化架构以匹配计算效率需求,才能实现“轻量化不减能”。
2. 局限性与未来方向
2.1 现存局限性
- 复杂推理任务性能差距:在需要深层语义推理的任务(如RTE、WNLI)上,与BERT-base仍有5-10个百分点的差距,说明蒸馏技术在传递复杂推理知识方面仍有提升空间;
- 单语言局限:仅支持英文,缺乏多语言版本,难以满足全球化部署需求;
- 损失函数权重未优化:论文未系统探索三重损失的最优权重组合,可能存在性能提升潜力。
2.2 未来研究方向
- 多语言DistilBERT:基于多语言BERT(mBERT)进行蒸馏,开发支持数十种语言的轻量化模型,适配跨境应用场景;
- 混合压缩技术:结合剪枝、量化、蒸馏,进一步提升压缩比(如参数减少80%仍保留95%性能);
- 任务自适应蒸馏:在预训练蒸馏的基础上,针对特定高价值任务(如医疗问答、法律文本分析)增加微调阶段的二次蒸馏,进一步缩小性能差距;
- 动态蒸馏框架:设计自适应温度参数T和损失权重,根据不同任务自动调整蒸馏策略,提升模型的通用性。
DistilBERT的出现,不仅为大模型压缩提供了可复用的技术范式,更推动了NLP技术从“实验室走向产业”的进程。在AI模型日益追求“高效、绿色、可落地”的今天,DistilBERT的设计思路将持续为后续轻量化模型的研发提供重要参考。
AI 十大論文精講(八):知識蒸餾如何讓大模型 “瘦身不減能”
第八篇精讀 DistilBERT:預訓練時期如何透過三重損失向 BERT Teacher 對齊,學生模型如何調整結構裁剪,並在 GLUE、IMDb、SQuAD 以及整體推論吞吐量上對比取捨。
來源:https://blog.csdn.net/2403_87969572/article/details/154950836
抓取時間(ISO本地):2026-05-18 05:17:14
系列文章前言
在人工智能技術從理論突破走向工程落地的進程中,一篇篇里程碑式的論文如同燈塔,照亮了技術演進的關鍵路徑。為幫助大家吃透 AI 核心技術的底層邏輯、理清行業發展脈絡,博主推出「AI 十大核心論文解讀系列」,每篇聚焦一篇關鍵論文的問題背景、核心創新與行業影響。本篇博客解讀AI領域十大論文的第八篇——《DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter》
文章目錄
- 系列文章前言
- 一、研究背景:大模型的“甜蜜煩惱”——規模與落地的核心矛盾
- 二、論文深度解讀:知識蒸餾驅動的通用模型輕量化方案
- 三、總結與未來展望
一、研究背景:大模型的“甜蜜煩惱”——規模與落地的核心矛盾
近年來,遷移學習在自然語言處理(NLP)領域迎來爆發式普及,以BERT為代表的大規模預訓練語言模型通過“預訓練-微調”範式,在情感分類、問答系統、文本推理等眾多下游任務中實現了性能飛躍,成為現代NLP技術棧的核心基礎。然而,這些模型的“大尺寸”特性逐漸顯現出不可忽視的現實困境:
一方面,模型參數規模呈指數級增長,從BERT-base的1.1億參數到後續MegatronLM等超大規模模型的千億級參數,帶來了驚人的計算與能源消耗。正如Schwartz等人[2019]在《Green AI》中指出的,大模型訓練過程的碳排放量相當於數輛汽車的終身碳足跡;Strubell等人[2019]的研究也顯示,訓練一個大型NLP模型的能源消耗甚至超過普通家庭數十年的用電量,環境代價與可持續性問題日益突出。
另一方面,大模型的部署門檻極高。其龐大的內存佔用(BERT-base推理需佔用數十GB顯存)和高延遲(CPU端單批次推理耗時數百秒),使其難以適配邊緣設備(如智能手機、智能穿戴設備、工業傳感器)的實時計算場景。而邊緣設備的離線處理、低延遲響應、數據隱私保護等需求,恰恰是AI技術從“雲端”走向“終端”的關鍵突破口——用戶需要無需聯網的離線翻譯、低延遲的語音助手、本地處理敏感文本的分析工具,這些場景都對模型的輕量化提出了剛性要求。
核心痛點已明確:現有大模型的“規模-效率”失衡,缺乏一種既能保留通用語言理解能力,又能適配低資源環境部署的通用解決方案。 DistilBERT的誕生,正是為了破解這一矛盾。
二、論文深度解讀:知識蒸餾驅動的通用模型輕量化方案
1. 核心方案:預訓練蒸餾+三重損失+輕量化架構設計
DistilBERT的核心創新在於將知識蒸餾技術從“任務特定階段”遷移至“預訓練階段”,構建通用型輕量化模型,而非針對單個下游任務定製壓縮模型。其技術路徑可拆解為“蒸餾框架設計”“模型架構優化”“訓練策略創新”三大模塊,形成閉環優化。
1.1 知識蒸餾的本質與三重損失函數
知識蒸餾(Knowledge Distillation)的核心邏輯是:讓參數緊湊的“學生模型”(DistilBERT)通過學習參數龐大的“教師模型”(BERT-base)的“知識”,實現性能逼近。這裡的“知識”不僅包括教師模型的最終預測結果(硬目標),更包括其預測分佈中蘊含的泛化信息(軟目標)。為實現高效知識遷移,論文設計了三重損失函數(Triple Loss),各組件各司其職且相互補充:
-
蒸餾損失( L c e L_{ce} Lce:Cross-Entropy Loss)
核心目標是讓學生模型模仿教師模型的軟目標概率分佈。傳統分類任務中,模型輸出的硬目標(one-hot向量)僅包含正確標籤的信息,而軟目標(通過溫度參數T平滑後的概率分佈)能反映教師模型對不同類別(或token)的置信度差異,蘊含更豐富的泛化知識。
具體計算過程為:-
對教師模型和學生模型的原始輸出(logits)分別應用帶溫度T的軟max函數,得到軟目標概率: p i
exp ( z i / T ) ∑ j exp ( z j / T ) p_i = \frac{\exp(z_i/T)}{\sum_j \exp(z_j/T)} pi=∑jexp(zj/T)exp(zi/T),其中 z i z_i zi為模型對類別i的原始得分,T為溫度參數(論文中T=1)。 -
蒸餾損失為學生軟目標與教師軟目標的交叉熵: L c e
∑ i t i ⋅ log ( s i ) L_{ce} = \sum_i t_i \cdot \log(s_i) Lce=∑iti⋅log(si),其中 t i t_i ti為教師軟目標概率, s i s_i si為學生軟目標概率。 - 該損失確保學生模型不僅“學會答案”,更“學會教師的思考方式”。
-
-
掩碼語言建模損失( L m l m L_{mlm} Lmlm:Masked Language Modeling Loss)
繼承BERT的核心預訓練目標,通過隨機掩碼輸入文本中的部分token(如15%的token被掩碼),讓模型預測被掩碼的原始token。這一損失確保學生模型不會因模仿教師而丟失基礎語言理解能力(如詞彙語義、語法結構),為通用語言任務提供底層支撐。
論文中,DistilBERT採用了動態掩碼策略(與RoBERTa一致),即每個訓練批次對文本重新生成掩碼,而非固定掩碼模式,提升了預訓練數據的多樣性。 -
餘弦距離損失( L c o s L_{cos} Lcos:Cosine-Distance Loss)
目標是對齊學生模型與教師模型的隱藏狀態向量空間。具體而言,計算教師模型和學生模型對應層的隱藏狀態向量的餘弦相似度,最小化二者的距離: L c o s1 − cos ( h t , h s ) L_{cos} = 1 - \cos(h_t, h_s) Lcos=1−cos(ht,hs),其中 h t h_t ht為教師隱藏狀態, h s h_s hs為學生隱藏狀態。
該損失的核心作用是確保學生模型的特徵表示空間與教師模型一致——即使模型結構簡化,其提取的語言特徵仍能保留教師模型的語義層次,避免因結構壓縮導致特徵失真。
最終的訓練目標為三重損失的加權和: L t o t a l
α L c e + β L m l m + γ L c o s L_{total} = \alpha L_{ce} + \beta L_{mlm} + \gamma L_{cos} Ltotal=αLce+βLmlm+γLcos(論文中未明確給出權重,但通過消融實驗驗證了三者的必要性)。
1.2 輕量化架構設計:聚焦“高效壓縮”而非“盲目縮減”
DistilBERT並未對BERT的核心Transformer架構進行顛覆性修改,而是基於“計算效率優先級”進行針對性優化,確保壓縮後仍能保留Transformer的並行計算優勢:
| 優化方向 | 具體措施 | 設計依據 |
|---|---|---|
| 移除冗餘組件 | 刪除token-type嵌入和pooler層 | 1. token-type嵌入用於區分句子對(如MNLI任務中的前提句與假設句),但DistilBERT預訓練階段移除了下一句預測(NSP)任務,該嵌入失去作用;2. pooler層用於生成句子級別的固定維度表示(適用於分類任務),但DistilBERT作為通用模型,微調時可通過簡單的均值池化或全連接層替代,移除後可減少參數冗餘。 |
| 精簡網絡層數 | 將Transformer層數從12層減半至6層 | 論文通過實驗驗證:在固定參數預算下,Transformer層數對計算效率的影響遠大於隱藏層維度(hidden size)——層數減少可直接降低推理時的串行計算步驟,而隱藏層維度縮減會導致特徵表達能力大幅下降,且現代線性代數框架(如CUDA)對隱藏層維度的優化更充分,縮減帶來的效率提升有限。 |
| 保持核心維度 | 隱藏層維度(768)、注意力頭數(12)與BERT-base一致 | 確保學生模型與教師模型的特徵維度兼容,為隱藏狀態對齊(餘弦距離損失)和層採樣初始化提供基礎。 |
1.3 訓練策略:繼承教師知識,加速收斂
為解決小模型訓練易陷入局部最優的問題,DistilBERT採用了“教師模型參數初始化”策略:利用教師模型與學生模型的架構兼容性(層數減半),從教師模型中每兩層抽取一層的參數作為學生模型對應層的初始參數(如教師第2層參數作為學生第1層,教師第4層作為學生第2層,以此類推)。
這種初始化方式的核心優勢在於:學生模型無需從零開始學習語言知識,而是直接繼承教師模型預訓練後的“先驗知識”,既能加速訓練收斂(減少約30%的訓練迭代次數),又能避免隨機初始化導致的性能波動。
訓練細節補充:
- 訓練語料:與BERT-base完全一致,即英文維基百科(約25億詞)+多倫多圖書語料庫(約8億詞),確保預訓練數據的一致性對比;
- 訓練配置:使用8臺16GB V100 GPU,通過梯度累積將批次大小擴大至4K(單GPU批次大小為512,8臺GPU×512=4096),動態掩碼,訓練時長約90小時;
- 對比基準:RoBERTa(BERT的優化版本)需在1024臺32GB V100 GPU上訓練1天,DistilBERT的訓練硬件成本僅為RoBERTa的約1/300,充分體現了“cheaper”的優勢。
2. 實驗結果:全方位驗證“輕量化不減能”
論文從通用語言理解、下游任務適配、速度與部署、 ablation驗證四個維度展開實驗,全面驗證DistilBERT的性能與效率優勢。
2.1 通用語言理解:GLUE基準測試
GLUE基準包含9個不同類型的NLP任務(涵蓋句子級分類、文本相似度、問答推理等),是評估通用語言模型能力的核心標準。實驗採用“單任務微調”模式(不使用集成模型或多任務微調),確保結果的客觀性。
核心結論:
- 性能保留率:DistilBERT的GLUE宏平均得分為77.0,相較於BERT-base的79.5,保留了97%的語言理解能力,而參數規模從1.1億減少至6600萬,壓縮比達40%;
- 任務適配性:在所有9個任務中,DistilBERT均優於ELMo基線(最高在STS-B任務上提升19個準確率點),其中在SST-2(情感分類)、MRPC(句子對匹配)等任務上與BERT-base差距不足2個百分點,僅在RTE(文本推理)、WNLI(代詞指代消解)等對推理能力要求較高的任務上差距略大(約5-10個百分點);
- 穩定性:實驗報告5次不同隨機種子的中位數結果,DistilBERT的標準差與BERT-base接近,說明其訓練過程穩定,未因模型壓縮導致泛化能力下降。
2.2 下游任務專項測試:IMDb與SQuAD
為驗證DistilBERT在實際應用場景中的表現,論文選擇了兩個典型下游任務:
-
IMDb情感分類(二分類任務,測試集含25000條評論):
- DistilBERT測試準確率為92.82%,僅落後BERT-base(93.46%)0.64個百分點,證明其在單句子分類任務上的性能逼近大模型;
-
SQuAD 1.1問答任務(抽取式問答,含10萬+問題):
- 基礎版本:EM(精確匹配)=77.7,F1=85.8,與BERT-base(81.2/88.5)差距分別為3.5和2.7;
- 二次蒸餾版本(DistilBERT (D)):在微調階段以BERT-base微調後的模型為教師,新增蒸餾損失,EM提升至79.1,F1提升至86.9,差距進一步縮小至2.1和1.6。
二次蒸餾的提升驗證了“預訓練蒸餾+微調蒸餾”的疊加效應——微調階段的教師模型已適配具體任務,其知識更具針對性,能進一步彌補學生模型的性能差距。
2.3 速度與部署測試:邊緣設備適配性
論文重點測試了DistilBERT在受限環境下的表現,為邊緣部署提供數據支撐:
| 測試場景 | 測試條件 | 結果對比 |
|---|---|---|
| CPU推理速度 | Intel Xeon E5-2690 v3 @2.9GHz,單批次(batch size=1),STS-B任務 | DistilBERT推理時間410秒,BERT-base為668秒,速度提升60%;ELMo(1.8億參數)為895秒,DistilBERT在參數更少的情況下速度遠超ELMo。 |
| 移動端推理速度 | iPhone 7 Plus,排除分詞步驟,問答任務 | DistilBERT平均推理時間比BERT-base快71%,模型體積僅207MB(BERT-base約410MB),支持本地存儲與離線運行。 |
關鍵補充:論文提到可通過量化技術(如INT8量化)進一步壓縮模型體積,預計可將207MB縮減至50MB以下,完全滿足智能穿戴設備等內存受限場景的需求。
2.4 Ablation研究:拆解核心組件的貢獻
為明確三重損失函數與初始化策略的必要性,論文進行了控制變量法實驗(以GLUE宏得分為指標,基準分為77.0):
| 消融方案 | 性能變化(Δ) | 核心分析 |
|---|---|---|
| 移除餘弦距離損失( L c o s L_{cos} Lcos) | -1.46(得分75.54) | 餘弦距離損失確保了學生與教師的特徵空間對齊,移除後特徵表達出現偏差,導致下游任務性能下降,但影響相對有限,說明基礎語言能力仍由 L m l m L_{mlm} Lmlm和 L c e L_{ce} Lce保障。 |
| 移除蒸餾損失( L c e L_{ce} Lce) | -2.96(得分74.04) | 蒸餾損失是傳遞教師泛化知識的核心,移除後學生模型僅依賴 L m l m L_{mlm} Lmlm學習基礎語言知識,缺乏教師的“經驗指導”,泛化能力大幅下降,證明蒸餾是性能保留的關鍵。 |
| 移除掩碼語言建模損失( L m l m L_{mlm} Lmlm) | -0.31(得分76.69) | 影響最小,說明教師模型的軟目標中已蘊含部分基礎語言知識,學生模型通過模仿教師即可部分掌握,但 L m l m L_{mlm} Lmlm仍能提供補充信號,避免基礎能力缺失。 |
| 隨機初始化替代教師層採樣 | -3.69(得分73.31) | 最大性能下降,證明教師模型的初始化參數為學生模型提供了關鍵的“知識起點”,隨機初始化導致學生模型需重新學習語言規律,不僅訓練收斂慢,且易陷入局部最優。 |
3. 相關工作對比:DistilBERT的核心差異化優勢
在DistilBERT之前,NLP領域已有多種模型壓縮方案,但DistilBERT通過“通用預訓練蒸餾”的定位,形成了獨特優勢:
| 壓縮方案類型 | 代表工作 | 核心特點 | DistilBERT的差異化優勢 |
|---|---|---|---|
| 任務特定蒸餾 | Tang et al. [2019]、Chatterjee [2019] | 1. 針對單個下游任務(如分類、問答);2. 流程為“大模型微調→蒸餾為小模型”;3. 小模型僅適用於特定任務,靈活性差。 | 1. 預訓練階段蒸餾,得到通用型小模型;2. 可直接用於所有下游任務微調,無需重複蒸餾;3. 兼顧性能與靈活性,適配多樣化場景。 |
| 單一目標預訓練壓縮 | Turc et al. [2019] | 1. 僅使用掩碼語言建模損失訓練小模型;2. 未利用教師模型的知識,性能依賴數據量與訓練策略。 | 1. 融合三重損失,充分吸收教師模型的泛化知識;2. 性能更優(GLUE得分77.0 vs Turc等人的約75.0)。 |
| 多教師蒸餾 | Yang et al. [2019] | 1. 利用多個教師模型的集成知識;2. 適用於特定任務(如問答系統),訓練複雜度高。 | 1. 單教師模型蒸餾,訓練成本低;2. 通用型模型,無需針對任務設計教師集成策略。 |
| 剪枝與量化 | Michel et al. [2019]、Gupta et al. [2015] | 1. 剪枝:移除冗餘參數(如注意力頭、神經元);2. 量化:降低參數數值精度(如FP32→INT8);3. 屬於“後處理壓縮”,需在訓練後額外優化。 | 1. 屬於“訓練時壓縮”,通過架構設計與蒸餾直接得到輕量化模型;2. 與剪枝、量化正交,可結合使用(如DistilBERT+量化,壓縮比可達80%以上)。 |
4. 應用場景與產業價值:解鎖邊緣AI的無限可能
DistilBERT的核心價值在於打破了“大模型=高性能”與“小模型=低延遲”的二元對立,為AI技術在邊緣設備的落地提供了“高性能+高效率”的解決方案。其典型應用場景包括:
4.1 離線NLP應用
- 場景需求:無網絡環境下的文本處理(如野外作業的文檔分析、無信號區域的翻譯工具);
- 適配優勢:207MB的模型體積可輕鬆存儲於手機、平板等設備,離線推理速度滿足實時響應(移動端單句處理耗時<100ms);
- 案例:離線翻譯APP(如基於DistilBERT的英中翻譯工具)、本地文本糾錯軟件。
4.2 低延遲實時交互系統
- 場景需求:語音助手、智能客服等需要快速響應的交互場景(延遲要求<500ms);
- 適配優勢:CPU推理速度提升60%,無需依賴高端GPU,普通服務器即可支撐高併發請求;
- 案例:智能手錶的語音轉文字實時分析、電商平臺的實時評論情感識別。
4.3 隱私保護型NLP工具
- 場景需求:醫療、金融等敏感領域的文本分析(如電子病歷處理、客戶隱私信息提取),數據不可上傳雲端;
- 適配優勢:本地部署無需傳輸數據,避免隱私洩露,同時輕量化模型降低了本地硬件的計算壓力;
- 案例:醫院本地電子病歷關鍵詞提取系統、銀行客戶信息脫敏工具。
4.4 資源受限設備部署
- 場景需求:智能攝像頭的文本識別(如車牌識別、快遞單號讀取)、物聯網設備的簡單文本處理;
- 適配優勢:模型體積小、內存佔用低(推理時內存佔用<1GB),可運行於嵌入式芯片(如NVIDIA Jetson Nano);
- 案例:智能快遞櫃的單號自動識別、工業傳感器的文本日誌分析。
三、總結與未來展望
1. 核心貢獻回顧
DistilBERT通過“預訓練階段知識蒸餾+三重損失函數+輕量化架構設計”的創新組合,成功實現了BERT模型的高效壓縮:
- 性能層面:保留97%的通用語言理解能力,在下游任務中逼近BERT-base;
- 效率層面:參數減少40%,推理速度提升60%,訓練成本降低數百倍;
- 落地層面:首次實現通用預訓練模型的邊緣部署,解鎖了NLP技術的多樣化應用場景。
其核心啟示在於:模型壓縮的關鍵並非“盲目縮減參數”,而是“高效傳遞知識”——通過蒸餾技術讓小模型繼承大模型的泛化能力,同時優化架構以匹配計算效率需求,才能實現“輕量化不減能”。
2. 侷限性與未來方向
2.1 現存侷限性
- 複雜推理任務性能差距:在需要深層語義推理的任務(如RTE、WNLI)上,與BERT-base仍有5-10個百分點的差距,說明蒸餾技術在傳遞複雜推理知識方面仍有提升空間;
- 單語言侷限:僅支持英文,缺乏多語言版本,難以滿足全球化部署需求;
- 損失函數權重未優化:論文未系統探索三重損失的最優權重組合,可能存在性能提升潛力。
2.2 未來研究方向
- 多語言DistilBERT:基於多語言BERT(mBERT)進行蒸餾,開發支持數十種語言的輕量化模型,適配跨境應用場景;
- 混合壓縮技術:結合剪枝、量化、蒸餾,進一步提升壓縮比(如參數減少80%仍保留95%性能);
- 任務自適應蒸餾:在預訓練蒸餾的基礎上,針對特定高價值任務(如醫療問答、法律文本分析)增加微調階段的二次蒸餾,進一步縮小性能差距;
- 動態蒸餾框架:設計自適應溫度參數T和損失權重,根據不同任務自動調整蒸餾策略,提升模型的通用性。
DistilBERT的出現,不僅為大模型壓縮提供了可複用的技術範式,更推動了NLP技術從“實驗室走向產業”的進程。在AI模型日益追求“高效、綠色、可落地”的今天,DistilBERT的設計思路將持續為後續輕量化模型的研發提供重要參考。
AI 十大论文精讲(八):知识蒸馏如何让大模型 “瘦身不减能”
Unpacks Hugging Face’s DistilBERT recipe—triple-loss distillation during pretraining, deliberate layer trims, deltas on GLUE/IMDb/SQuAD latency budgets, versus BERT-base.
系列文章前言
在人工智能技术从理论突破走向工程落地的进程中,一篇篇里程碑式的论文如同灯塔,照亮了技术演进的关键路径。为帮助大家吃透 AI 核心技术的底层逻辑、理清行业发展脉络,博主推出「AI 十大核心论文解读系列」,每篇聚焦一篇关键论文的问题背景、核心创新与行业影响。本篇博客解读AI领域十大论文的第八篇——《DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter》
一、研究背景:大模型的“甜蜜烦恼”——规模与落地的核心矛盾
近年来,迁移学习在自然语言处理(NLP)领域迎来爆发式普及,以BERT为代表的大规模预训练语言模型通过“预训练-微调”范式,在情感分类、问答系统、文本推理等众多下游任务中实现了性能飞跃,成为现代NLP技术栈的核心基础。然而,这些模型的“大尺寸”特性逐渐显现出不可忽视的现实困境:
一方面,模型参数规模呈指数级增长,从BERT-base的1.1亿参数到后续MegatronLM等超大规模模型的千亿级参数,带来了惊人的计算与能源消耗。正如Schwartz等人[2019]在《Green AI》中指出的,大模型训练过程的碳排放量相当于数辆汽车的终身碳足迹;Strubell等人[2019]的研究也显示,训练一个大型NLP模型的能源消耗甚至超过普通家庭数十年的用电量,环境代价与可持续性问题日益突出。
另一方面,大模型的部署门槛极高。其庞大的内存占用(BERT-base推理需占用数十GB显存)和高延迟(CPU端单批次推理耗时数百秒),使其难以适配边缘设备(如智能手机、智能穿戴设备、工业传感器)的实时计算场景。而边缘设备的离线处理、低延迟响应、数据隐私保护等需求,恰恰是AI技术从“云端”走向“终端”的关键突破口——用户需要无需联网的离线翻译、低延迟的语音助手、本地处理敏感文本的分析工具,这些场景都对模型的轻量化提出了刚性要求。
核心痛点已明确:现有大模型的“规模-效率”失衡,缺乏一种既能保留通用语言理解能力,又能适配低资源环境部署的通用解决方案。 DistilBERT的诞生,正是为了破解这一矛盾。
二、论文深度解读:知识蒸馏驱动的通用模型轻量化方案
1. 核心方案:预训练蒸馏+三重损失+轻量化架构设计
DistilBERT的核心创新在于将知识蒸馏技术从“任务特定阶段”迁移至“预训练阶段”,构建通用型轻量化模型,而非针对单个下游任务定制压缩模型。其技术路径可拆解为“蒸馏框架设计”“模型架构优化”“训练策略创新”三大模块,形成闭环优化。
1.1 知识蒸馏的本质与三重损失函数
知识蒸馏(Knowledge Distillation)的核心逻辑是:让参数紧凑的“学生模型”(DistilBERT)通过学习参数庞大的“教师模型”(BERT-base)的“知识”,实现性能逼近。这里的“知识”不仅包括教师模型的最终预测结果(硬目标),更包括其预测分布中蕴含的泛化信息(软目标)。为实现高效知识迁移,论文设计了三重损失函数(Triple Loss),各组件各司其职且相互补充:
-
蒸馏损失( L c e L_{ce} Lce:Cross-Entropy Loss)
核心目标是让学生模型模仿教师模型的软目标概率分布。传统分类任务中,模型输出的硬目标(one-hot向量)仅包含正确标签的信息,而软目标(通过温度参数T平滑后的概率分布)能反映教师模型对不同类别(或token)的置信度差异,蕴含更丰富的泛化知识。
具体计算过程为:-
对教师模型和学生模型的原始输出(logits)分别应用带温度T的软max函数,得到软目标概率: p i
exp ( z i / T ) ∑ j exp ( z j / T ) p_i = \frac{\exp(z_i/T)}{\sum_j \exp(z_j/T)} pi=∑jexp(zj/T)exp(zi/T),其中 z i z_i zi为模型对类别i的原始得分,T为温度参数(论文中T=1)。 -
蒸馏损失为学生软目标与教师软目标的交叉熵: L c e
∑ i t i ⋅ log ( s i ) L_{ce} = \sum_i t_i \cdot \log(s_i) Lce=∑iti⋅log(si),其中 t i t_i ti为教师软目标概率, s i s_i si为学生软目标概率。 - 该损失确保学生模型不仅“学会答案”,更“学会教师的思考方式”。
-
-
掩码语言建模损失( L m l m L_{mlm} Lmlm:Masked Language Modeling Loss)
继承BERT的核心预训练目标,通过随机掩码输入文本中的部分token(如15%的token被掩码),让模型预测被掩码的原始token。这一损失确保学生模型不会因模仿教师而丢失基础语言理解能力(如词汇语义、语法结构),为通用语言任务提供底层支撑。
论文中,DistilBERT采用了动态掩码策略(与RoBERTa一致),即每个训练批次对文本重新生成掩码,而非固定掩码模式,提升了预训练数据的多样性。 -
余弦距离损失( L c o s L_{cos} Lcos:Cosine-Distance Loss)
目标是对齐学生模型与教师模型的隐藏状态向量空间。具体而言,计算教师模型和学生模型对应层的隐藏状态向量的余弦相似度,最小化二者的距离: L c o s1 − cos ( h t , h s ) L_{cos} = 1 - \cos(h_t, h_s) Lcos=1−cos(ht,hs),其中 h t h_t ht为教师隐藏状态, h s h_s hs为学生隐藏状态。
该损失的核心作用是确保学生模型的特征表示空间与教师模型一致——即使模型结构简化,其提取的语言特征仍能保留教师模型的语义层次,避免因结构压缩导致特征失真。
最终的训练目标为三重损失的加权和: L t o t a l
α L c e + β L m l m + γ L c o s L_{total} = \alpha L_{ce} + \beta L_{mlm} + \gamma L_{cos} Ltotal=αLce+βLmlm+γLcos(论文中未明确给出权重,但通过消融实验验证了三者的必要性)。
1.2 轻量化架构设计:聚焦“高效压缩”而非“盲目缩减”
DistilBERT并未对BERT的核心Transformer架构进行颠覆性修改,而是基于“计算效率优先级”进行针对性优化,确保压缩后仍能保留Transformer的并行计算优势:
| 优化方向 | 具体措施 | 设计依据 |
|---|---|---|
| 移除冗余组件 | 删除token-type嵌入和pooler层 | 1. token-type嵌入用于区分句子对(如MNLI任务中的前提句与假设句),但DistilBERT预训练阶段移除了下一句预测(NSP)任务,该嵌入失去作用;2. pooler层用于生成句子级别的固定维度表示(适用于分类任务),但DistilBERT作为通用模型,微调时可通过简单的均值池化或全连接层替代,移除后可减少参数冗余。 |
| 精简网络层数 | 将Transformer层数从12层减半至6层 | 论文通过实验验证:在固定参数预算下,Transformer层数对计算效率的影响远大于隐藏层维度(hidden size)——层数减少可直接降低推理时的串行计算步骤,而隐藏层维度缩减会导致特征表达能力大幅下降,且现代线性代数框架(如CUDA)对隐藏层维度的优化更充分,缩减带来的效率提升有限。 |
| 保持核心维度 | 隐藏层维度(768)、注意力头数(12)与BERT-base一致 | 确保学生模型与教师模型的特征维度兼容,为隐藏状态对齐(余弦距离损失)和层采样初始化提供基础。 |
1.3 训练策略:继承教师知识,加速收敛
为解决小模型训练易陷入局部最优的问题,DistilBERT采用了“教师模型参数初始化”策略:利用教师模型与学生模型的架构兼容性(层数减半),从教师模型中每两层抽取一层的参数作为学生模型对应层的初始参数(如教师第2层参数作为学生第1层,教师第4层作为学生第2层,以此类推)。
这种初始化方式的核心优势在于:学生模型无需从零开始学习语言知识,而是直接继承教师模型预训练后的“先验知识”,既能加速训练收敛(减少约30%的训练迭代次数),又能避免随机初始化导致的性能波动。
训练细节补充:
- 训练语料:与BERT-base完全一致,即英文维基百科(约25亿词)+多伦多图书语料库(约8亿词),确保预训练数据的一致性对比;
- 训练配置:使用8台16GB V100 GPU,通过梯度累积将批次大小扩大至4K(单GPU批次大小为512,8台GPU×512=4096),动态掩码,训练时长约90小时;
- 对比基准:RoBERTa(BERT的优化版本)需在1024台32GB V100 GPU上训练1天,DistilBERT的训练硬件成本仅为RoBERTa的约1/300,充分体现了“cheaper”的优势。
2. 实验结果:全方位验证“轻量化不减能”
论文从通用语言理解、下游任务适配、速度与部署、 ablation验证四个维度展开实验,全面验证DistilBERT的性能与效率优势。
2.1 通用语言理解:GLUE基准测试
GLUE基准包含9个不同类型的NLP任务(涵盖句子级分类、文本相似度、问答推理等),是评估通用语言模型能力的核心标准。实验采用“单任务微调”模式(不使用集成模型或多任务微调),确保结果的客观性。
核心结论:
- 性能保留率:DistilBERT的GLUE宏平均得分为77.0,相较于BERT-base的79.5,保留了97%的语言理解能力,而参数规模从1.1亿减少至6600万,压缩比达40%;
- 任务适配性:在所有9个任务中,DistilBERT均优于ELMo基线(最高在STS-B任务上提升19个准确率点),其中在SST-2(情感分类)、MRPC(句子对匹配)等任务上与BERT-base差距不足2个百分点,仅在RTE(文本推理)、WNLI(代词指代消解)等对推理能力要求较高的任务上差距略大(约5-10个百分点);
- 稳定性:实验报告5次不同随机种子的中位数结果,DistilBERT的标准差与BERT-base接近,说明其训练过程稳定,未因模型压缩导致泛化能力下降。
2.2 下游任务专项测试:IMDb与SQuAD
为验证DistilBERT在实际应用场景中的表现,论文选择了两个典型下游任务:
-
IMDb情感分类(二分类任务,测试集含25000条评论):
- DistilBERT测试准确率为92.82%,仅落后BERT-base(93.46%)0.64个百分点,证明其在单句子分类任务上的性能逼近大模型;
-
SQuAD 1.1问答任务(抽取式问答,含10万+问题):
- 基础版本:EM(精确匹配)=77.7,F1=85.8,与BERT-base(81.2/88.5)差距分别为3.5和2.7;
- 二次蒸馏版本(DistilBERT (D)):在微调阶段以BERT-base微调后的模型为教师,新增蒸馏损失,EM提升至79.1,F1提升至86.9,差距进一步缩小至2.1和1.6。
二次蒸馏的提升验证了“预训练蒸馏+微调蒸馏”的叠加效应——微调阶段的教师模型已适配具体任务,其知识更具针对性,能进一步弥补学生模型的性能差距。
2.3 速度与部署测试:边缘设备适配性
论文重点测试了DistilBERT在受限环境下的表现,为边缘部署提供数据支撑:
| 测试场景 | 测试条件 | 结果对比 |
|---|---|---|
| CPU推理速度 | Intel Xeon E5-2690 v3 @2.9GHz,单批次(batch size=1),STS-B任务 | DistilBERT推理时间410秒,BERT-base为668秒,速度提升60%;ELMo(1.8亿参数)为895秒,DistilBERT在参数更少的情况下速度远超ELMo。 |
| 移动端推理速度 | iPhone 7 Plus,排除分词步骤,问答任务 | DistilBERT平均推理时间比BERT-base快71%,模型体积仅207MB(BERT-base约410MB),支持本地存储与离线运行。 |
关键补充:论文提到可通过量化技术(如INT8量化)进一步压缩模型体积,预计可将207MB缩减至50MB以下,完全满足智能穿戴设备等内存受限场景的需求。
2.4 Ablation研究:拆解核心组件的贡献
为明确三重损失函数与初始化策略的必要性,论文进行了控制变量法实验(以GLUE宏得分为指标,基准分为77.0):
| 消融方案 | 性能变化(Δ) | 核心分析 |
|---|---|---|
| 移除余弦距离损失( L c o s L_{cos} Lcos) | -1.46(得分75.54) | 余弦距离损失确保了学生与教师的特征空间对齐,移除后特征表达出现偏差,导致下游任务性能下降,但影响相对有限,说明基础语言能力仍由 L m l m L_{mlm} Lmlm和 L c e L_{ce} Lce保障。 |
| 移除蒸馏损失( L c e L_{ce} Lce) | -2.96(得分74.04) | 蒸馏损失是传递教师泛化知识的核心,移除后学生模型仅依赖 L m l m L_{mlm} Lmlm学习基础语言知识,缺乏教师的“经验指导”,泛化能力大幅下降,证明蒸馏是性能保留的关键。 |
| 移除掩码语言建模损失( L m l m L_{mlm} Lmlm) | -0.31(得分76.69) | 影响最小,说明教师模型的软目标中已蕴含部分基础语言知识,学生模型通过模仿教师即可部分掌握,但 L m l m L_{mlm} Lmlm仍能提供补充信号,避免基础能力缺失。 |
| 随机初始化替代教师层采样 | -3.69(得分73.31) | 最大性能下降,证明教师模型的初始化参数为学生模型提供了关键的“知识起点”,随机初始化导致学生模型需重新学习语言规律,不仅训练收敛慢,且易陷入局部最优。 |
3. 相关工作对比:DistilBERT的核心差异化优势
在DistilBERT之前,NLP领域已有多种模型压缩方案,但DistilBERT通过“通用预训练蒸馏”的定位,形成了独特优势:
| 压缩方案类型 | 代表工作 | 核心特点 | DistilBERT的差异化优势 |
|---|---|---|---|
| 任务特定蒸馏 | Tang et al. [2019]、Chatterjee [2019] | 1. 针对单个下游任务(如分类、问答);2. 流程为“大模型微调→蒸馏为小模型”;3. 小模型仅适用于特定任务,灵活性差。 | 1. 预训练阶段蒸馏,得到通用型小模型;2. 可直接用于所有下游任务微调,无需重复蒸馏;3. 兼顾性能与灵活性,适配多样化场景。 |
| 单一目标预训练压缩 | Turc et al. [2019] | 1. 仅使用掩码语言建模损失训练小模型;2. 未利用教师模型的知识,性能依赖数据量与训练策略。 | 1. 融合三重损失,充分吸收教师模型的泛化知识;2. 性能更优(GLUE得分77.0 vs Turc等人的约75.0)。 |
| 多教师蒸馏 | Yang et al. [2019] | 1. 利用多个教师模型的集成知识;2. 适用于特定任务(如问答系统),训练复杂度高。 | 1. 单教师模型蒸馏,训练成本低;2. 通用型模型,无需针对任务设计教师集成策略。 |
| 剪枝与量化 | Michel et al. [2019]、Gupta et al. [2015] | 1. 剪枝:移除冗余参数(如注意力头、神经元);2. 量化:降低参数数值精度(如FP32→INT8);3. 属于“后处理压缩”,需在训练后额外优化。 | 1. 属于“训练时压缩”,通过架构设计与蒸馏直接得到轻量化模型;2. 与剪枝、量化正交,可结合使用(如DistilBERT+量化,压缩比可达80%以上)。 |
4. 应用场景与产业价值:解锁边缘AI的无限可能
DistilBERT的核心价值在于打破了“大模型=高性能”与“小模型=低延迟”的二元对立,为AI技术在边缘设备的落地提供了“高性能+高效率”的解决方案。其典型应用场景包括:
4.1 离线NLP应用
- 场景需求:无网络环境下的文本处理(如野外作业的文档分析、无信号区域的翻译工具);
- 适配优势:207MB的模型体积可轻松存储于手机、平板等设备,离线推理速度满足实时响应(移动端单句处理耗时<100ms);
- 案例:离线翻译APP(如基于DistilBERT的英中翻译工具)、本地文本纠错软件。
4.2 低延迟实时交互系统
- 场景需求:语音助手、智能客服等需要快速响应的交互场景(延迟要求<500ms);
- 适配优势:CPU推理速度提升60%,无需依赖高端GPU,普通服务器即可支撑高并发请求;
- 案例:智能手表的语音转文字实时分析、电商平台的实时评论情感识别。
4.3 隐私保护型NLP工具
- 场景需求:医疗、金融等敏感领域的文本分析(如电子病历处理、客户隐私信息提取),数据不可上传云端;
- 适配优势:本地部署无需传输数据,避免隐私泄露,同时轻量化模型降低了本地硬件的计算压力;
- 案例:医院本地电子病历关键词提取系统、银行客户信息脱敏工具。
4.4 资源受限设备部署
- 场景需求:智能摄像头的文本识别(如车牌识别、快递单号读取)、物联网设备的简单文本处理;
- 适配优势:模型体积小、内存占用低(推理时内存占用<1GB),可运行于嵌入式芯片(如NVIDIA Jetson Nano);
- 案例:智能快递柜的单号自动识别、工业传感器的文本日志分析。
三、总结与未来展望
1. 核心贡献回顾
DistilBERT通过“预训练阶段知识蒸馏+三重损失函数+轻量化架构设计”的创新组合,成功实现了BERT模型的高效压缩:
- 性能层面:保留97%的通用语言理解能力,在下游任务中逼近BERT-base;
- 效率层面:参数减少40%,推理速度提升60%,训练成本降低数百倍;
- 落地层面:首次实现通用预训练模型的边缘部署,解锁了NLP技术的多样化应用场景。
其核心启示在于:模型压缩的关键并非“盲目缩减参数”,而是“高效传递知识”——通过蒸馏技术让小模型继承大模型的泛化能力,同时优化架构以匹配计算效率需求,才能实现“轻量化不减能”。
2. 局限性与未来方向
2.1 现存局限性
- 复杂推理任务性能差距:在需要深层语义推理的任务(如RTE、WNLI)上,与BERT-base仍有5-10个百分点的差距,说明蒸馏技术在传递复杂推理知识方面仍有提升空间;
- 单语言局限:仅支持英文,缺乏多语言版本,难以满足全球化部署需求;
- 损失函数权重未优化:论文未系统探索三重损失的最优权重组合,可能存在性能提升潜力。
2.2 未来研究方向
- 多语言DistilBERT:基于多语言BERT(mBERT)进行蒸馏,开发支持数十种语言的轻量化模型,适配跨境应用场景;
- 混合压缩技术:结合剪枝、量化、蒸馏,进一步提升压缩比(如参数减少80%仍保留95%性能);
- 任务自适应蒸馏:在预训练蒸馏的基础上,针对特定高价值任务(如医疗问答、法律文本分析)增加微调阶段的二次蒸馏,进一步缩小性能差距;
- 动态蒸馏框架:设计自适应温度参数T和损失权重,根据不同任务自动调整蒸馏策略,提升模型的通用性。
DistilBERT的出现,不仅为大模型压缩提供了可复用的技术范式,更推动了NLP技术从“实验室走向产业”的进程。在AI模型日益追求“高效、绿色、可落地”的今天,DistilBERT的设计思路将持续为后续轻量化模型的研发提供重要参考。