AI 十大论文精讲(七):Switch Routing 如何破解 MoE 的路由、通信与稳定性三大痛点
解读 Switch Transformer:k=1 路由、负载均衡损失与三重并行实现万亿参数稳定训练,并对比预训练/下游结果及工业界密集模型+RAG 的权衡。
系列文章前言
在人工智能技术从理论突破走向工程落地的进程中,一篇篇里程碑式的论文如同灯塔,照亮了技术演进的关键路径。为帮助大家吃透 AI 核心技术的底层逻辑、理清行业发展脉络,博主推出「AI 十大核心论文解读系列」,每篇聚焦一篇关键论文的问题背景、核心创新与行业影响。本篇博客解读AI领域十大论文的第五篇——《Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity》
一、引言:密集型模型的瓶颈与稀疏化的破局思路
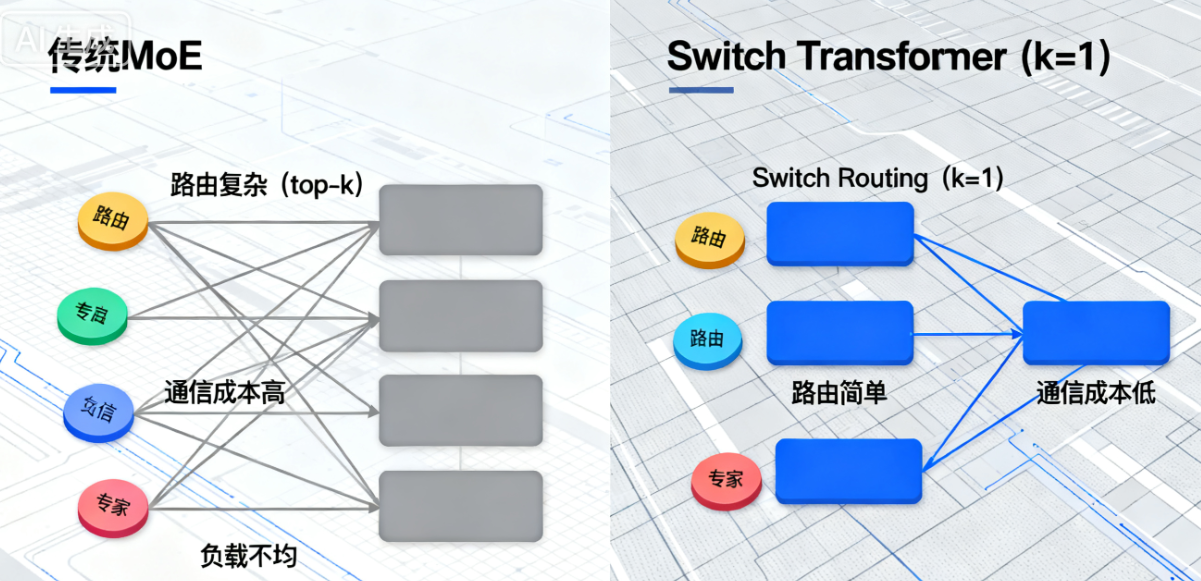
在大语言模型的发展历程中,“规模即能力”已被多次验证,但传统密集型Transformer架构面临核心瓶颈:模型参数与计算成本(FLOPs)呈线性绑定,每增加一个参数,所有输入token的前向传播都需调用该参数,导致训练万亿参数模型时,计算资源消耗呈指数级增长。混合专家(Mixture of Experts, MoE)模型虽提出“稀疏激活”思路——为每个输入选择部分子网络(专家)运行,实现参数规模与计算成本解耦,但此前的MoE存在三大问题:路由算法复杂(top-k选择需协调多个专家)、跨设备通信成本高、训练过程极易不稳定,限制了其大规模应用。
Switch Transformers的核心目标正是解决这些痛点:通过简化MoE的路由机制、优化训练策略、设计高效并行架构,在保持“参数规模大”的同时,让“单token计算成本低”,最终实现万亿参数模型的稳定训练,且预训练速度、下游任务性能均超越同计算预算的密集型模型。
用简单的话来说,早期的MoE模型就像“组建了一个专家团队”——每个专家只擅长一个领域,遇到问题时找几个最相关的专家一起解决,但麻烦的是:怎么选专家(路由)要纠结半天,专家之间沟通成本高(跨设备通信),还经常出现有的专家忙到崩溃、有的闲到摸鱼(训练不稳定)的情况,团队协作效率极低。
而Switch Transformers的思路的是:“优化专家团队的工作模式”——给团队配一个高效“调度员”,每个问题只找一个最擅长的专家解决,不用多个专家协调;同时优化团队分工(并行架构)和工作规则(训练策略),让专家团队既能“人多势众”(万亿参数),又能“高效干活”(单token计算快),花更少的钱办更大的事。
二、论文深度解读
1. 核心创新:Switch Routing——让稀疏化更简单、更高效
Switch Transformer的核心突破是Switch Routing,它对传统MoE的top-k路由进行了颠覆性简化:将“每个token路由到top-k个专家”改为“每个token仅路由到1个专家(k=1)”,这一改动并非妥协,而是经过实证的优化选择。
1.1 路由机制的数学表达与逻辑
-
路由函数:对于输入token的表征x,通过路由权重Wr计算logits: h ( x )
W r ⋅ x h(x)=Wr·x h(x)=Wr⋅x,经softmax归一化后得到每个专家的选择概率 p i ( x )
e ( h ( x ) i ) / Σ j e ( h ( x ) j ) pi(x)=e^(h(x)i)/Σj e^(h(x)j) pi(x)=e(h(x)i)/Σje(h(x)j) -
选择逻辑:通过argmax选择概率最高的专家,token仅由该专家处理,输出为 y
E i ( x ) ⋅ p i ( x ) y=Ei(x)·pi(x) y=Ei(x)⋅pi(x)(Ei为选中专家的网络输出,pi为路由权重); - 三大优势:
① 路由计算量从O(k·N)降至O(N)(N为专家数),计算效率提升;
② 每个专家的批处理量至少减半(因每个token仅分配给1个专家),内存利用率更高;
③ 路由实现简化,跨设备通信仅需传递“选中专家的输出”,通信成本显著降低。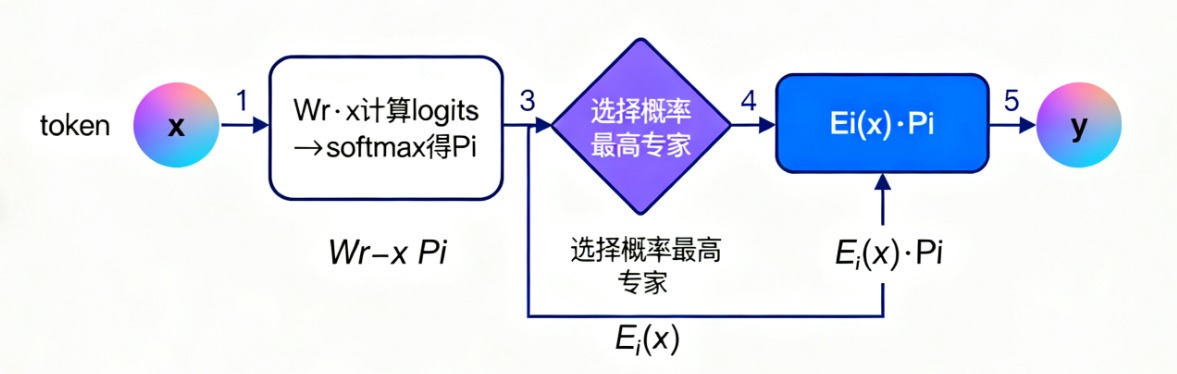
1.2 负载均衡与专家容量设计
为解决“专家负载不均”问题,论文引入两大机制:
-
辅助负载均衡损失:损失函数为 α ⋅ N ⋅ Σ f i ⋅ P i α·N·Σfi·Pi α⋅N⋅Σfi⋅Pi
1 e − 2 α=1e-2 α=1e−2),通过梯度下降鼓励 f i fi fi和 P i Pi Pi均趋近于 1 / N 1/N 1/N(均匀分布),避免tokens集中于少数专家;就像公司的“绩效考核”——如果某个专家的任务量(fi)和调度员给的“预期工作量”(Pi)差太多,就扣调度员的分,逼着调度员把任务均匀分配;
(fi是分配给专家i的token占比, P i Pi Pi是路由概率分配给专家i的占比, α - 专家容量因子:专家容量=(每批次token数/专家数)×容量因子,容量因子>1.0(通常取1.0-1.5),为每个专家预留“备用处理能力”,避免因token分配不均导致的“专家溢出”(溢出token直接通过残差连接传递,不参与专家计算)。就像给每个专家的办公室留了“备用工位”——比如本来每个专家该处理10个token,容量因子设1.25,就预留12个工位,避免突然来了11个token导致有人没地方坐(溢出),虽然会浪费2个工位,但能保证工作不中断。

2. 关键技术:让万亿参数模型稳定训练的“三大法宝”
稀疏模型的训练天然比密集模型更复杂——路由的离散性、低精度计算的数值不稳定性、超大规模参数的并行难题,都可能导致训练崩溃。Switch Transformer通过三大优化策略,解决了这些问题:
2.1 选择性精度训练(Selective Precision)
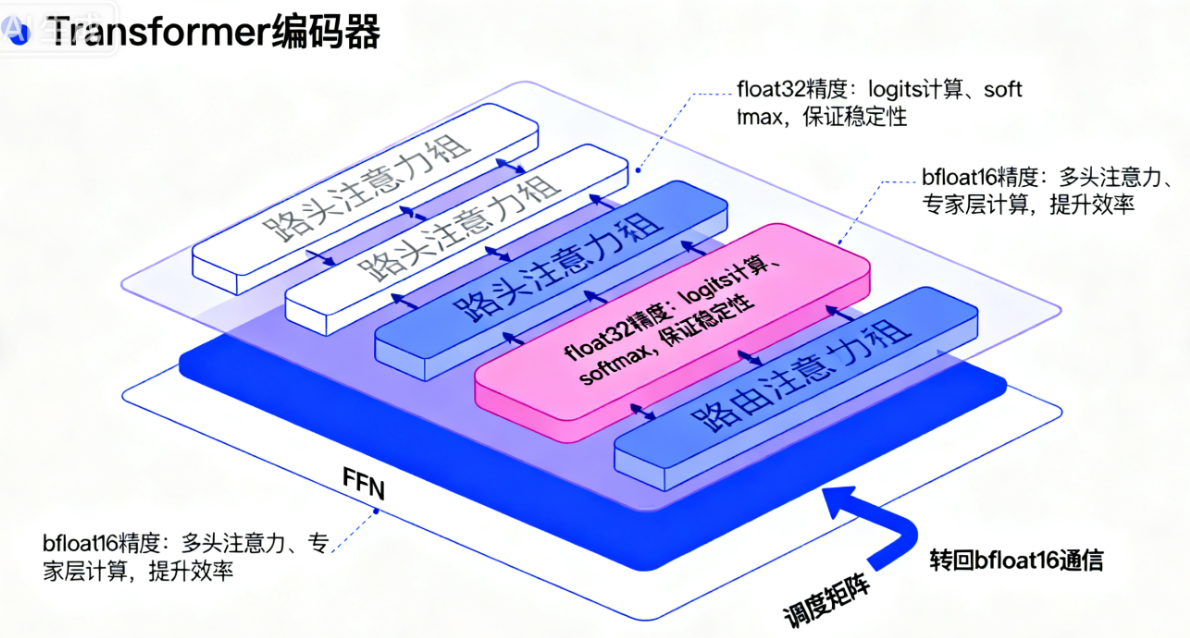
低精度格式(bfloat16)能提升计算速度、降低内存占用,但会导致路由模块的softmax计算不稳定(数值溢出或梯度消失)。论文提出“仅路由模块用float32精度,其余部分保持bfloat16”:
- 路由模块的输入、logits计算、softmax均用float32,保证数值稳定性;
- 路由输出的“调度矩阵”(dispatch tensor)和“合并矩阵”(combine tensor)再转回bfloat16,避免跨设备通信时的float32高成本;
- 实验证明:该策略既能达到bfloat16的训练速度(1390 examples/sec),又能获得float32的稳定性(负对数困惑度-1.716,与float32接近)。
2.2 初始化缩放与专家正则化
- 权重初始化:将传统Transformer的权重初始化 scale s从1.0降至0.1,权重标准差σ=√(s/n)(n为输入维度),避免训练初期因权重过大导致的梯度爆炸,实验显示该改动使训练方差从0.68降至0.01,稳定性显著提升;
- 专家dropout:微调阶段,非专家层保持dropout=0.1,专家层dropout提升至0.4,缓解稀疏模型因参数过多导致的过拟合,在GLUE、SuperGLUE等下游任务中性能提升0.5-1.0个百分点。
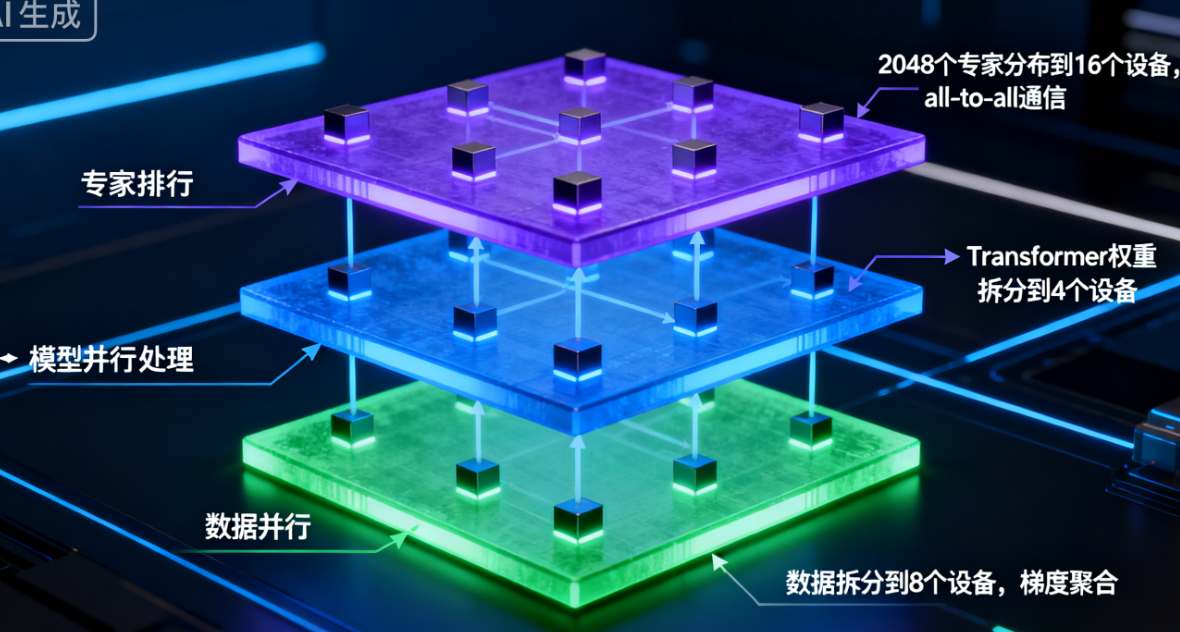
2.3 三重并行架构(Data + Model + Expert Parallelism)
为支撑万亿参数模型,论文设计了“数据并行+模型并行+专家并行”的混合架构:
- 数据并行:将训练数据拆分到多个设备,每个设备处理部分样本,梯度最后聚合;
- 模型并行:将Transformer的权重(如FFN层的W_in、W_out)拆分到多个设备,解决单设备内存限制;
- 专家并行:将所有专家分布在不同设备,每个设备仅存储部分专家的参数,token通过“all-to-all”通信路由到对应专家设备,实现专家数量与设备数量的线性扩展。
通过这种架构,论文成功训练出1.6万亿参数的Switch-C模型(2048个专家),且每个设备的内存占用保持在可接受范围。
3. 实验结果:稀疏模型的“碾压式”表现
3.1 预训练速度与性能
- 同计算预算下,Switch-Base(7B参数)比T5-Base(0.2B参数)预训练速度提升7倍,在C4数据集上,Switch-Base 64专家模型达到T5-Base相同负对数困惑度(-1.50)仅需1/7的时间;
- 万亿参数模型表现:Switch-XXL(395B参数)比T5-XXL(11B参数)预训练速度提升4倍,500k步后负对数困惑度达-1.008,超越T5-XXL的-1.095;1.6万亿参数的Switch-C模型,在仅训练503B tokens(T5-XXL的一半数据)的情况下,闭卷问答任务(TriviaQA)准确率达47.5%,超越T5-XXL的42.9%。
3.2 下游任务泛化
在10+ NLP任务中,FLOP匹配的Switch模型均优于T5基线:
- SuperGLUE:Switch-Base(7B)比T5-Base(0.2B)提升4.4个百分点(79.5 vs 75.1),Switch-Large(26B)比T5-Large(0.7B)提升2.0个百分点(84.7 vs 82.7);
- 闭卷问答:Switch-Large在TriviaQA上准确率达36.9%,比T5-Large的29.5%提升7.4个百分点;
- 摘要任务:XSum数据集上,Switch-Large的Rouge-2分数达22.3,超越T5-Large的20.9。
3.3 多语言能力
在mC4的101种语言上,mSwitch-Base(FLOP匹配mT5-Base)在所有语言上均实现性能提升,91%的语言预训练速度提升4倍以上,平均速度提升5倍,证明稀疏模型的泛化能力不仅限于单语言,还能迁移到多语言场景。
3.4 模型蒸馏:让大模型的“能力”浓缩到小模型
稀疏模型虽性能强,但部署成本高(需支持动态路由)。论文通过蒸馏将大稀疏模型的知识迁移到小密集模型:
- 将14.7B参数的Switch-Base蒸馏到0.223B参数的T5-Base,保留30%的性能增益,压缩率达99%;
- 微调后的稀疏模型蒸馏:将7.4B参数的Switch-Base(SuperGLUE分数81.3)蒸馏到0.223B的T5-Base,分数达76.6,保留30%的增益,部署成本大幅降低。
4. 工程挑战与行业后续选择
Switch Transformer虽证明了稀疏化的巨大潜力,但后续工业界部署中发现,稀疏模型面临三大工程挑战:
- 负载均衡的动态控制:实际推理时,输入分布可能与预训练分布差异较大,导致路由模块的负载均衡策略失效,部分专家成为性能瓶颈(token集中分配);
- 延迟与吞吐量权衡:动态路由需要实时计算专家分配,跨设备通信的延迟会随专家数量增加而上升,在低延迟场景(如实时对话)中难以满足要求;
- 硬件与框架适配:稀疏激活的计算模式与传统密集型计算的硬件(GPU/TPU)优化方向不一致,现有框架对“动态调度+三重并行”的支持不够成熟,需定制化开发。
这些挑战导致工业界逐渐转向“中等规模密集模型+高效检索+优质工具链”的组合:
- 中等规模密集模型(如10B-100B参数)的训练和部署复杂度低,数值稳定性强,推理延迟可控;
- 高效检索(如Retrieval-Augmented Generation, RAG)能弥补“参数规模不足”导致的知识缺口,通过外部知识库提供实时、准确的信息;
- 优质工具链(如模型压缩、量化、推理优化框架)能进一步降低部署成本,提升吞吐量。
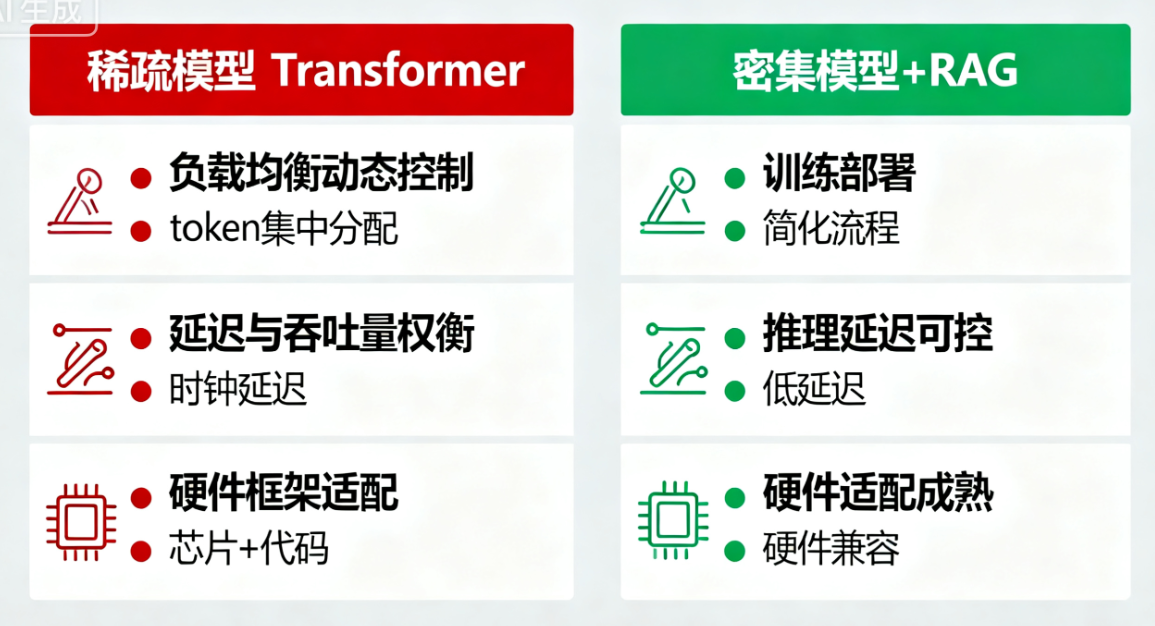
这种组合虽未达到稀疏模型的极致性能,但“性能-成本-复杂度”的权衡更优,实施难度更低,成为当前工业界的主流选择。
三、总结:稀疏化革命的意义与启示
Switch Transformer的核心贡献并非“训练了万亿参数模型”,而是验证了“参数规模与计算成本解耦”的可行性——通过条件计算(仅激活部分参数),模型可以突破密集型架构的参数上限,同时保持高效的推理速度。其技术创新(简化路由、选择性精度、三重并行)为后续稀疏模型的研究奠定了基础,而其工程挑战也为工业界提供了重要启示:模型设计的核心是“权衡”——性能、成本、部署复杂度三者不可兼得,没有绝对最优的方案,只有最适合场景的选择。
尽管当前工业界更倾向于密集型+检索的组合,但Switch Transformer的价值并未过时:在超大规模预训练、知识密集型任务等场景中,稀疏模型仍具有不可替代的优势;而其提出的“专家并行”“负载均衡损失”等技术,也已被广泛应用于各类大模型的并行训练中。未来,随着硬件技术的进步(如专门为稀疏计算设计的芯片)和框架的优化,稀疏模型有望在更多场景中落地,与密集型模型形成互补。
AI 十大論文精講(七):Switch Routing 如何破解 MoE 的路由、通信與穩定性三大痛點
解讀 Switch Transformer:k=1 路由、負載均衡損失與三重並行實現萬億參數穩定訓練,並對比預訓練/下游結果及工業界密集模型+RAG 的權衡。
來源:https://blog.csdn.net/2403_87969572/article/details/154904377
抓取時間(ISO本地):2026-05-18 05:17:11
系列文章前言
在人工智能技術從理論突破走向工程落地的進程中,一篇篇里程碑式的論文如同燈塔,照亮了技術演進的關鍵路徑。為幫助大家吃透 AI 核心技術的底層邏輯、理清行業發展脈絡,博主推出「AI 十大核心論文解讀系列」,每篇聚焦一篇關鍵論文的問題背景、核心創新與行業影響。本篇博客解讀AI領域十大論文的第五篇——《Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity》
文章目錄
一、引言:密集型模型的瓶頸與稀疏化的破局思路
在大語言模型的發展歷程中,“規模即能力”已被多次驗證,但傳統密集型Transformer架構面臨核心瓶頸:模型參數與計算成本(FLOPs)呈線性綁定,每增加一個參數,所有輸入token的前向傳播都需調用該參數,導致訓練萬億參數模型時,計算資源消耗呈指數級增長。混合專家(Mixture of Experts, MoE)模型雖提出“稀疏激活”思路——為每個輸入選擇部分子網絡(專家)運行,實現參數規模與計算成本解耦,但此前的MoE存在三大問題:路由算法複雜(top-k選擇需協調多個專家)、跨設備通信成本高、訓練過程極易不穩定,限制了其大規模應用。
Switch Transformers的核心目標正是解決這些痛點:通過簡化MoE的路由機制、優化訓練策略、設計高效並行架構,在保持“參數規模大”的同時,讓“單token計算成本低”,最終實現萬億參數模型的穩定訓練,且預訓練速度、下游任務性能均超越同計算預算的密集型模型。
用簡單的話來說,早期的MoE模型就像“組建了一個專家團隊”——每個專家只擅長一個領域,遇到問題時找幾個最相關的專家一起解決,但麻煩的是:怎麼選專家(路由)要糾結半天,專家之間溝通成本高(跨設備通信),還經常出現有的專家忙到崩潰、有的閒到摸魚(訓練不穩定)的情況,團隊協作效率極低。
而Switch Transformers的思路的是:“優化專家團隊的工作模式”——給團隊配一個高效“調度員”,每個問題只找一個最擅長的專家解決,不用多個專家協調;同時優化團隊分工(並行架構)和工作規則(訓練策略),讓專家團隊既能“人多勢眾”(萬億參數),又能“高效幹活”(單token計算快),花更少的錢辦更大的事。
二、論文深度解讀
1. 核心創新:Switch Routing——讓稀疏化更簡單、更高效
Switch Transformer的核心突破是Switch Routing,它對傳統MoE的top-k路由進行了顛覆性簡化:將“每個token路由到top-k個專家”改為“每個token僅路由到1個專家(k=1)”,這一改動並非妥協,而是經過實證的優化選擇。
1.1 路由機制的數學表達與邏輯
-
路由函數:對於輸入token的表徵x,通過路由權重Wr計算logits: h ( x )
W r ⋅ x h(x)=Wr·x h(x)=Wr⋅x,經softmax歸一化後得到每個專家的選擇概率 p i ( x )
e ( h ( x ) i ) / Σ j e ( h ( x ) j ) pi(x)=e^(h(x)i)/Σj e^(h(x)j) pi(x)=e(h(x)i)/Σje(h(x)j) -
選擇邏輯:通過argmax選擇概率最高的專家,token僅由該專家處理,輸出為 y
E i ( x ) ⋅ p i ( x ) y=Ei(x)·pi(x) y=Ei(x)⋅pi(x)(Ei為選中專家的網絡輸出,pi為路由權重); - 三大優勢:
① 路由計算量從O(k·N)降至O(N)(N為專家數),計算效率提升;
② 每個專家的批處理量至少減半(因每個token僅分配給1個專家),內存利用率更高;
③ 路由實現簡化,跨設備通信僅需傳遞“選中專家的輸出”,通信成本顯著降低。
1.2 負載均衡與專家容量設計
為解決“專家負載不均”問題,論文引入兩大機制:
-
輔助負載均衡損失:損失函數為 α ⋅ N ⋅ Σ f i ⋅ P i α·N·Σfi·Pi α⋅N⋅Σfi⋅Pi
1 e − 2 α=1e-2 α=1e−2),通過梯度下降鼓勵 f i fi fi和 P i Pi Pi均趨近於 1 / N 1/N 1/N(均勻分佈),避免tokens集中於少數專家;就像公司的“績效考核”——如果某個專家的任務量(fi)和調度員給的“預期工作量”(Pi)差太多,就扣調度員的分,逼著調度員把任務均勻分配;
(fi是分配給專家i的token佔比, P i Pi Pi是路由概率分配給專家i的佔比, α - 專家容量因子:專家容量=(每批次token數/專家數)×容量因子,容量因子>1.0(通常取1.0-1.5),為每個專家預留“備用處理能力”,避免因token分配不均導致的“專家溢出”(溢出token直接通過殘差連接傳遞,不參與專家計算)。就像給每個專家的辦公室留了“備用工位”——比如本來每個專家該處理10個token,容量因子設1.25,就預留12個工位,避免突然來了11個token導致有人沒地方坐(溢出),雖然會浪費2個工位,但能保證工作不中斷。
2. 關鍵技術:讓萬億參數模型穩定訓練的“三大法寶”
稀疏模型的訓練天然比密集模型更復雜——路由的離散性、低精度計算的數值不穩定性、超大規模參數的並行難題,都可能導致訓練崩潰。Switch Transformer通過三大優化策略,解決了這些問題:
2.1 選擇性精度訓練(Selective Precision)
低精度格式(bfloat16)能提升計算速度、降低內存佔用,但會導致路由模塊的softmax計算不穩定(數值溢出或梯度消失)。論文提出“僅路由模塊用float32精度,其餘部分保持bfloat16”:
- 路由模塊的輸入、logits計算、softmax均用float32,保證數值穩定性;
- 路由輸出的“調度矩陣”(dispatch tensor)和“合併矩陣”(combine tensor)再轉回bfloat16,避免跨設備通信時的float32高成本;
- 實驗證明:該策略既能達到bfloat16的訓練速度(1390 examples/sec),又能獲得float32的穩定性(負對數困惑度-1.716,與float32接近)。
2.2 初始化縮放與專家正則化
- 權重初始化:將傳統Transformer的權重初始化 scale s從1.0降至0.1,權重標準差σ=√(s/n)(n為輸入維度),避免訓練初期因權重過大導致的梯度爆炸,實驗顯示該改動使訓練方差從0.68降至0.01,穩定性顯著提升;
- 專家dropout:微調階段,非專家層保持dropout=0.1,專家層dropout提升至0.4,緩解稀疏模型因參數過多導致的過擬合,在GLUE、SuperGLUE等下游任務中性能提升0.5-1.0個百分點。
2.3 三重並行架構(Data + Model + Expert Parallelism)
為支撐萬億參數模型,論文設計了“數據並行+模型並行+專家並行”的混合架構:
- 數據並行:將訓練數據拆分到多個設備,每個設備處理部分樣本,梯度最後聚合;
- 模型並行:將Transformer的權重(如FFN層的W_in、W_out)拆分到多個設備,解決單設備內存限制;
- 專家並行:將所有專家分佈在不同設備,每個設備僅存儲部分專家的參數,token通過“all-to-all”通信路由到對應專家設備,實現專家數量與設備數量的線性擴展。
通過這種架構,論文成功訓練出1.6萬億參數的Switch-C模型(2048個專家),且每個設備的內存佔用保持在可接受範圍。
3. 實驗結果:稀疏模型的“碾壓式”表現
3.1 預訓練速度與性能
- 同計算預算下,Switch-Base(7B參數)比T5-Base(0.2B參數)預訓練速度提升7倍,在C4數據集上,Switch-Base 64專家模型達到T5-Base相同負對數困惑度(-1.50)僅需1/7的時間;
- 萬億參數模型表現:Switch-XXL(395B參數)比T5-XXL(11B參數)預訓練速度提升4倍,500k步後負對數困惑度達-1.008,超越T5-XXL的-1.095;1.6萬億參數的Switch-C模型,在僅訓練503B tokens(T5-XXL的一半數據)的情況下,閉卷問答任務(TriviaQA)準確率達47.5%,超越T5-XXL的42.9%。
3.2 下游任務泛化
在10+ NLP任務中,FLOP匹配的Switch模型均優於T5基線:
- SuperGLUE:Switch-Base(7B)比T5-Base(0.2B)提升4.4個百分點(79.5 vs 75.1),Switch-Large(26B)比T5-Large(0.7B)提升2.0個百分點(84.7 vs 82.7);
- 閉卷問答:Switch-Large在TriviaQA上準確率達36.9%,比T5-Large的29.5%提升7.4個百分點;
- 摘要任務:XSum數據集上,Switch-Large的Rouge-2分數達22.3,超越T5-Large的20.9。
3.3 多語言能力
在mC4的101種語言上,mSwitch-Base(FLOP匹配mT5-Base)在所有語言上均實現性能提升,91%的語言預訓練速度提升4倍以上,平均速度提升5倍,證明稀疏模型的泛化能力不僅限於單語言,還能遷移到多語言場景。
3.4 模型蒸餾:讓大模型的“能力”濃縮到小模型
稀疏模型雖性能強,但部署成本高(需支持動態路由)。論文通過蒸餾將大稀疏模型的知識遷移到小密集模型:
- 將14.7B參數的Switch-Base蒸餾到0.223B參數的T5-Base,保留30%的性能增益,壓縮率達99%;
- 微調後的稀疏模型蒸餾:將7.4B參數的Switch-Base(SuperGLUE分數81.3)蒸餾到0.223B的T5-Base,分數達76.6,保留30%的增益,部署成本大幅降低。
4. 工程挑戰與行業後續選擇
Switch Transformer雖證明了稀疏化的巨大潛力,但後續工業界部署中發現,稀疏模型面臨三大工程挑戰:
- 負載均衡的動態控制:實際推理時,輸入分佈可能與預訓練分佈差異較大,導致路由模塊的負載均衡策略失效,部分專家成為性能瓶頸(token集中分配);
- 延遲與吞吐量權衡:動態路由需要實時計算專家分配,跨設備通信的延遲會隨專家數量增加而上升,在低延遲場景(如實時對話)中難以滿足要求;
- 硬件與框架適配:稀疏激活的計算模式與傳統密集型計算的硬件(GPU/TPU)優化方向不一致,現有框架對“動態調度+三重並行”的支持不夠成熟,需定製化開發。
這些挑戰導致工業界逐漸轉向“中等規模密集模型+高效檢索+優質工具鏈”的組合:
- 中等規模密集模型(如10B-100B參數)的訓練和部署複雜度低,數值穩定性強,推理延遲可控;
- 高效檢索(如Retrieval-Augmented Generation, RAG)能彌補“參數規模不足”導致的知識缺口,通過外部知識庫提供實時、準確的信息;
- 優質工具鏈(如模型壓縮、量化、推理優化框架)能進一步降低部署成本,提升吞吐量。
這種組合雖未達到稀疏模型的極致性能,但“性能-成本-複雜度”的權衡更優,實施難度更低,成為當前工業界的主流選擇。
三、總結:稀疏化革命的意義與啟示
Switch Transformer的核心貢獻並非“訓練了萬億參數模型”,而是驗證了“參數規模與計算成本解耦”的可行性——通過條件計算(僅激活部分參數),模型可以突破密集型架構的參數上限,同時保持高效的推理速度。其技術創新(簡化路由、選擇性精度、三重並行)為後續稀疏模型的研究奠定了基礎,而其工程挑戰也為工業界提供了重要啟示:模型設計的核心是“權衡”——性能、成本、部署複雜度三者不可兼得,沒有絕對最優的方案,只有最適合場景的選擇。
儘管當前工業界更傾向於密集型+檢索的組合,但Switch Transformer的價值並未過時:在超大規模預訓練、知識密集型任務等場景中,稀疏模型仍具有不可替代的優勢;而其提出的“專家並行”“負載均衡損失”等技術,也已被廣泛應用於各類大模型的並行訓練中。未來,隨著硬件技術的進步(如專門為稀疏計算設計的芯片)和框架的優化,稀疏模型有望在更多場景中落地,與密集型模型形成互補。
AI Top Papers (7): Switch Routing — MoE Routing, Communication, and Stability
Switch Transformers: k=1 routing, load-balancing loss, triple parallelism for stable trillion-param training, benchmark wins, and why industry often picks dense models plus RAG.
Captured at (local ISO): 2026-05-18 05:17:11
Series Preface
Part 7 covers 《Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity》.
1. Dense bottlenecks and sparse MoE
“Scale brings capability,” but dense Transformers tie every parameter to every token—trillion-parameter training explodes FLOPs. Mixture of Experts (MoE) activates only a subset of experts per token, decoupling capacity from compute—but classic MoE suffered from complex top-k routing, expensive cross-device traffic, and unstable training.
Switch Transformers simplify routing, stabilize training, and add efficient parallelism so trillion-parameter models train reliably and often beat dense baselines at the same compute budget.
Analogy: old MoE = many experts per question, heavy coordination; Switch = one dispatcher assigns one expert per token, with better rules and hardware layout.
2. Paper deep dive
2.1 Switch Routing
Replace top-k experts with k = 1 (single expert per token)—not a weakness but an empirically strong design.
Routing math
- Logits: (h(x) = W_r \cdot x), softmax → (p_i(x));
- Pick (\arg\max_i p_i(x)); output (y = E_i(x) \cdot p_i(x));
- Benefits: cheaper routing, larger per-expert batches, simpler all-to-all.
Load balance & capacity
- Auxiliary load-balancing loss (\alpha \cdot N \cdot \sum f_i P_i) with (\alpha = 10^{-2}), encouraging uniform expert load;
- Expert capacity factor (often 1.0–1.25× fair share) plus residual bypass for overflow tokens.
2.2 Stable training at scale
Selective precision
Router in float32; rest in bfloat16; dispatch/combine tensors back to bfloat16 for comms—fast and stable.
Init & regularization
- Init scale (s = 0.1) vs 1.0 cuts early variance;
- Expert dropout up to 0.4 at fine-tune reduces overfit.
Triple parallelism
Data + model + expert parallel: shards for samples, layer weights, and expert tables; all-to-all routes tokens. Trained 1.6T-parameter Switch-C (2048 experts).
2.3 Results
- Pretrain: Switch-Base (~7B) ~7× faster than T5-Base to same perplexity; Switch-XXL (~395B) beats T5-XXL; 1.6T Switch-C strong on TriviaQA with half the tokens of T5-XXL.
- Downstream: +4.4 SuperGLUE vs T5-Base; large gains on TriviaQA and XSum.
- Multilingual: mSwitch beats mT5 on 101 languages, ~5× average speedup.
- Distillation: 14.7B Switch → 223M T5 retains ~30% of gains for deployable dense models.
2.4 Engineering reality
Production pain points:
- Train/serve distribution shift breaks balance;
- Dynamic routing latency grows with expert count;
- Sparse patterns mismatch dense GPU kernels.
Industry often chooses mid-size dense models + RAG + tooling for better cost/latency/complexity tradeoffs.
3. Summary
Switch proved conditional computation can scale parameters without linear FLOPs growth. Ideas—single-expert routing, selective precision, expert parallelism, balance losses—still influence large-scale training. Sparse vs dense is a scenario tradeoff, not a single winner; better sparse hardware/frameworks may widen sparse adoption later.