AI 十大论文精讲(六):拆解 LLM 智能体的 “通用密码”
精讲复旦 NLP 综述《The Rise and Potential of Large Language Model Based Agents》:大脑-感知-行动框架、单/多/人机与社群场景、工具 SKMA 与安全评估四维体系及开放问题。
系列文章前言
在人工智能技术从理论突破走向工程落地的进程中,一篇篇里程碑式的论文如同灯塔,照亮了技术演进的关键路径。为帮助大家吃透 AI 核心技术的底层逻辑、理清行业发展脉络,博主推出「AI 十大核心论文解读系列」,每篇聚焦一篇关键论文的问题背景、核心创新与行业影响。本篇博客解读AI领域十大论文的第六篇——《The Rise and Potential of Large Language Model Based Agents》
一、引言:为什么这篇文章是LLM智能体领域的“里程碑”?
《The Rise and Potential of Large Language Model Based Agents》是复旦NLP团队于2023年发表的重磅综述,系统梳理了2023年之前LLM驱动的智能体(Agent)领域的研究成果、技术框架与应用场景。作为AGI(通用人工智能)的关键探索方向,LLM-based智能体突破了传统智能体“任务专用、泛化能力弱”的瓶颈——传统智能体多聚焦于特定算法优化或单一任务性能提升,而该综述首次提出“大脑-感知-行动”的通用框架,将LLM作为智能体的核心决策单元,整合多模态感知与多样化行动能力,为通用智能体的设计提供了统一范式。文章不仅覆盖单智能体、多智能体、人机协作等核心应用场景,还深入探讨了智能体社群的涌现现象、落地实践要点与开放问题,成为该领域最具权威性的入门与参考文献。
二、论文深度解读
1. 核心框架:智能体的“三大核心模块”——大脑、感知、行动
该综述提出的通用框架是LLM-based智能体的核心创新,三大模块各司其职且形成“感知-决策-行动”的闭环:
- 大脑(Brain):以LLM为核心,承担记忆存储、知识调用、推理规划与泛化迁移等核心功能。具体包括自然语言交互(多轮对话、意图理解)、知识体系(语言知识、常识知识、专业领域知识)、记忆机制(长短期记忆存储、摘要压缩、高效检索)、推理与规划(链式思维CoT、任务分解、计划反思)、迁移与泛化(零样本/少样本学习、持续学习)五大子模块,是智能体实现智能行为的核心驱动。
- 感知(Perception):负责将外部多模态信息转化为LLM可理解的格式,突破传统LLM“仅处理文本”的局限。涵盖文本输入(指令理解、隐含意图挖掘)、视觉输入(图像/视频编码、跨模态对齐)、听觉输入(音频 spectrogram 处理、语音识别)及其他输入(触觉、手势、3D地图等),让智能体能够“感知”真实世界的复杂信息。
- 行动(Action):将大脑的决策转化为具体操作,拓展智能体的“影响范围”。包括文本输出(高质量语言生成)、工具使用(工具理解、学习使用、自主创造工具)、具身行动(物理世界交互,如机器人操作、虚拟环境导航)三大方向,使智能体从“被动响应”升级为“主动改变环境”。
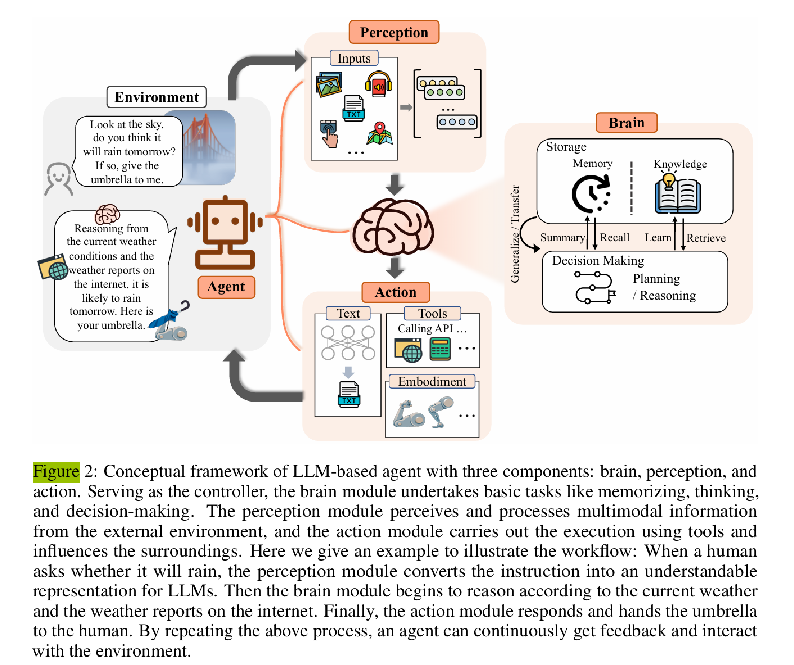
图 2:基于 LLM 的智能体概念框架,包含三大核心组件:大脑(brain)、感知(perception)与行动(action)。其中,大脑模块作为核心控制器,承担记忆、思考与决策等基础任务;感知模块负责感知并处理来自外部环境的多模态信息;行动模块通过工具执行操作,进而对环境产生影响。以下结合示例说明其工作流程:当人类询问 “是否会下雨” 时,感知模块先将该指令转化为 LLM 可理解的表示形式;随后大脑模块结合当前天气状况与互联网气象预报进行推理;最终行动模块作出回应,并将雨伞递给人类。通过重复上述过程,智能体能够持续获取反馈并与环境进行交互。
2. 应用场景:从“单打独斗”到“社群协作”的全维度落地
综述将LLM-based智能体的应用场景分为四大类,覆盖从个体到群体、从虚拟到现实的全场景:
-
单智能体场景(Single-Agent):聚焦个体智能体的独立任务处理能力,分为三类部署模式:
- 任务导向部署:处理日常具体任务(如网页导航、表单填写),核心是指令理解与步骤分解;
- 创新导向部署:支持科学研究、代码开发等创造性任务(如化学分子合成、代码编写与调试),依赖专业知识与工具调用;
- 生命周期导向部署:在开放环境中持续学习与生存(如Minecraft游戏中的终身探索),需具备持续学习与技能积累能力。

-
多智能体场景(Multi-Agent):多个智能体通过交互实现“1+1>2”的效果,包括协作交互(有序协作如MetaGPT的软件开发流程、无序协作如多智能体辩论)与对抗交互(通过竞争提升性能,如智能体辩论优化推理结果),核心是智能体间的分工、沟通与目标对齐
-
人机协作场景(Human-Agent):基于人类与智能体的优势互补,分为两类范式:
- 指导-执行者范式(Instructor-Executor):人类提供指令或反馈(定量评分、定性建议),智能体执行具体操作(如教育中的辅导、医疗中的诊断辅助);
- 平等伙伴范式(Equal Partnership):智能体具备共情能力与人类级协作能力(如游戏中的队友、心理疏导中的陪伴者),实现深度协同。
-
智能体社群(Agent Society):多个智能体在特定环境中形成模拟社会,展现出人类社会的涌现现象(如分工合作、信息传播、伦理决策),可用于社会现象模拟、政策制定推演等场景,核心是智能体的行为个性、环境适配与群体动力学。
3. 落地关键实践要点:让智能体“能用、好用、安全用”
综述明确了LLM-based智能体落地的三大核心实践要点,解决“从理论到应用”的鸿沟:
- 工具SKMA体系:即工具的选择(Selection)、知识(Knowledge)、管理(Management)与应用(Application)。智能体需先理解工具的功能与调用方式(通过零样本/少样本提示),再通过示范学习与反馈优化工具使用策略,甚至自主创造适配自身的工具(如生成可执行程序),实现工具能力与LLM决策能力的深度融合。具体而言,就是智能体得知道“用什么工具、怎么用工具”——比如要查实时天气,它得知道调用天气API;用错了还能自己调整,甚至自己做一个更顺手的工具(比如写个小脚本),不用每次都麻烦人类教。
- 安全护栏机制:防止智能体陷入失控循环(如无限调用工具、生成有害内容)。核心包括对抗鲁棒性增强(对抗训练、样本检测)、信任worthiness保障(减少幻觉、偏见修正)、伦理约束(拒绝恶意指令、符合人类价值观),避免智能体的行为对人类或环境造成伤害。简短来说,得防止智能体“乱做事”——比如不会被坏人误导生成危险内容,不会一直重复做一件没用的事(比如无限次搜索),也不会有偏见(比如歧视某个群体),确保它的行为安全无害。
- 结果检查机制:验证智能体行动结果的准确性与有效性。通过外部知识库校验(减少幻觉)、多智能体交叉验证(提升可靠性)、人类监督反馈(RLHF)等方式,确保智能体的输出符合任务要求,避免“差之毫厘谬以千里”的问题。也就是智能体做完事,得有人或系统“把关”——比如它写的报告要查一下事实对不对,它做的决策要交叉验证一下,避免出错。就像我们工作完要校对一样,智能体也需要“质检”环节。
4. 评估方法:怎么判断智能体“聪明不聪明、好用不好用”?
综述提出LLM-based智能体的四维评估体系,突破传统“单一任务评分”的局限:
- 效用(Utility):核心评估任务完成能力,包括任务成功率(如是否达成目标)、基础能力适配度(环境理解、推理、工具使用等)、效率(时间成本、资源消耗),代表智能体“能不能做事”。
- 社交性(Sociability):评估智能体的交互能力,包括语言沟通效率(自然语言理解与生成、隐含意图捕捉)、协作/谈判能力(多智能体协同效果)、角色一致性(长期任务中保持身份与行为统一),代表智能体“能不能和人/其他智能体好好相处”。
- 价值观(Values):评估智能体的伦理合规性,包括诚实性(避免幻觉、承认能力边界)、无害性(无偏见、无攻击性)、语境适配性(符合特定文化与场景的价值观),代表智能体“三观正不正”。
- 持续进化能力(Continual Evolution):评估智能体的长期适应能力,包括持续学习(学习新技能不遗忘旧技能)、自主目标生成(开放环境中主动探索)、跨环境泛化(从虚拟场景迁移到物理场景),代表智能体“能不能一直进步”。
5. 开放问题:LLM智能体领域的“未解之谜”
综述列出了LLM-based智能体领域尚未解决的四大核心开放问题,为未来研究指明方向:
- AGI路径之争:LLM-based智能体是否是实现AGI的有效路径?支持者认为LLM通过大规模数据预训练获得了泛化与推理能力,具备AGI的雏形;反对者则指出LLM的“下一个token预测”范式无法模拟人类真正的思维过程,缺乏世界模型,难以实现真正的通用智能。
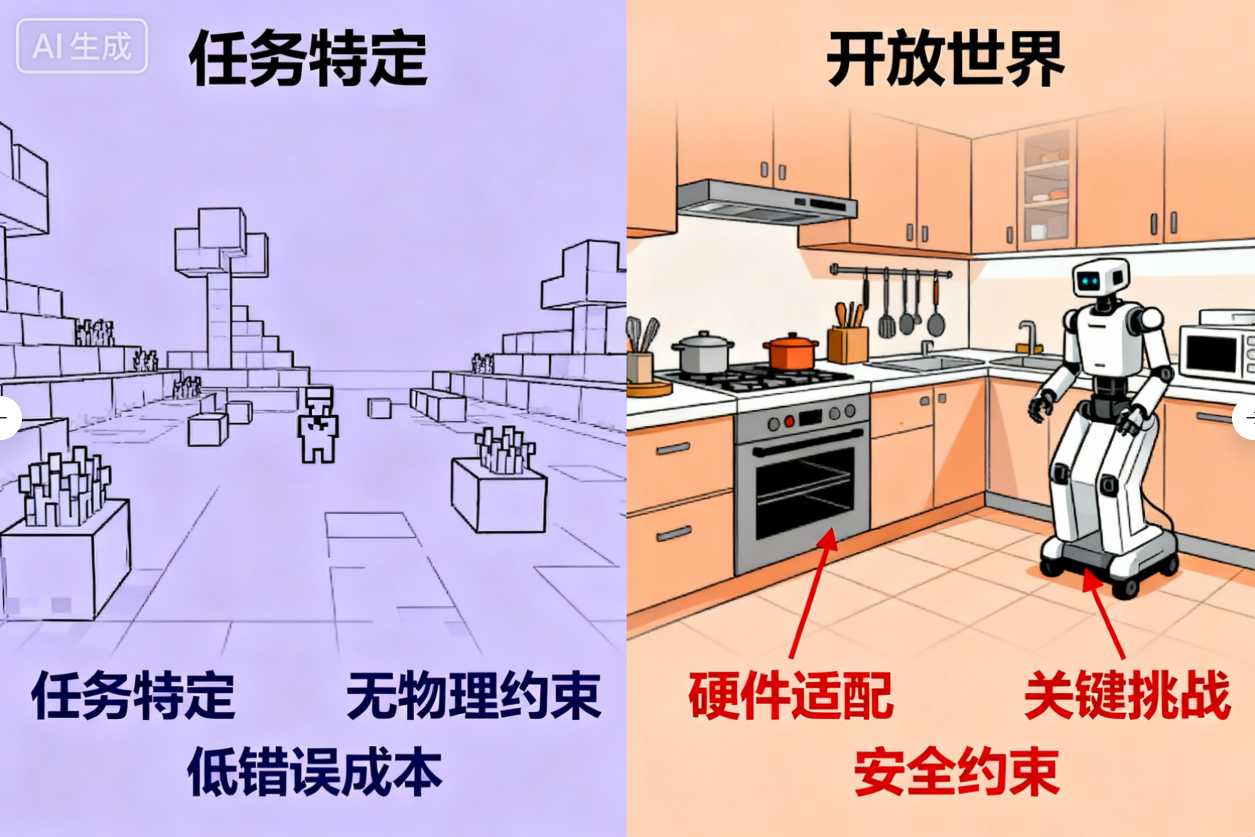
- 虚拟到物理的迁移鸿沟:智能体在虚拟环境(如Minecraft、文本游戏)中表现优异,但迁移到物理环境时面临硬件适配、环境不确定性、安全约束等问题,如何实现“虚拟智能”到“具身智能”的高效迁移仍是挑战。
- 集体智能的涌现机制:多智能体系统如何形成真正的“集体智能”?目前多智能体协作仍依赖人类设计的规则,如何让智能体自主形成分工、信任与协同,涌现出超越个体能力的群体行为,仍需深入研究。
- Agent as a Service(AaaS)的落地挑战:如何将LLM-based智能体作为云服务提供给用户?面临数据安全与隐私保护、服务可扩展性、用户可控性等问题,同时需解决智能体的鲁棒性与信任worthiness,避免服务滥用。
三、总结:这篇综述的核心价值与领域影响
《The Rise and Potential of Large Language Model Based Agents》的核心价值在于:首次构建了LLM-based智能体的统一理论框架(大脑-感知-行动),系统梳理了从技术基础、应用场景到落地实践的全链条知识,明确了“LLM作为核心决策单元”的技术路线,为领域研究提供了统一范式。文章不仅整合了2023年前的研究成果,还通过开放问题的提出,引导后续研究聚焦AGI路径、具身迁移、集体智能等核心方向,其影响力贯穿学术研究与工业应用,成为LLM智能体领域的“入门圣经”与“研究指南”。
AI 十大論文精講(六):拆解 LLM 智能體的 “通用密碼”
精講復旦 NLP 綜述《The Rise and Potential of Large Language Model Based Agents》:大腦-感知-行動框架、單/多/人機與社群場景、工具 SKMA 與安全評估四維體系及開放問題。
來源:https://blog.csdn.net/2403_87969572/article/details/154902974
抓取時間(ISO本地):2026-05-18 05:17:08
系列文章前言
在人工智能技術從理論突破走向工程落地的進程中,一篇篇里程碑式的論文如同燈塔,照亮了技術演進的關鍵路徑。為幫助大家吃透 AI 核心技術的底層邏輯、理清行業發展脈絡,博主推出「AI 十大核心論文解讀系列」,每篇聚焦一篇關鍵論文的問題背景、核心創新與行業影響。本篇博客解讀AI領域十大論文的第六篇——《The Rise and Potential of Large Language Model Based Agents》
文章目錄
一、引言:為什麼這篇文章是LLM智能體領域的“里程碑”?
《The Rise and Potential of Large Language Model Based Agents》是復旦NLP團隊於2023年發表的重磅綜述,系統梳理了2023年之前LLM驅動的智能體(Agent)領域的研究成果、技術框架與應用場景。作為AGI(通用人工智能)的關鍵探索方向,LLM-based智能體突破了傳統智能體“任務專用、泛化能力弱”的瓶頸——傳統智能體多聚焦於特定算法優化或單一任務性能提升,而該綜述首次提出“大腦-感知-行動”的通用框架,將LLM作為智能體的核心決策單元,整合多模態感知與多樣化行動能力,為通用智能體的設計提供了統一範式。文章不僅覆蓋單智能體、多智能體、人機協作等核心應用場景,還深入探討了智能體社群的湧現現象、落地實踐要點與開放問題,成為該領域最具權威性的入門與參考文獻。
二、論文深度解讀
1. 核心框架:智能體的“三大核心模塊”——大腦、感知、行動
該綜述提出的通用框架是LLM-based智能體的核心創新,三大模塊各司其職且形成“感知-決策-行動”的閉環:
- 大腦(Brain):以LLM為核心,承擔記憶存儲、知識調用、推理規劃與泛化遷移等核心功能。具體包括自然語言交互(多輪對話、意圖理解)、知識體系(語言知識、常識知識、專業領域知識)、記憶機制(長短期記憶存儲、摘要壓縮、高效檢索)、推理與規劃(鏈式思維CoT、任務分解、計劃反思)、遷移與泛化(零樣本/少樣本學習、持續學習)五大子模塊,是智能體實現智能行為的核心驅動。
- 感知(Perception):負責將外部多模態信息轉化為LLM可理解的格式,突破傳統LLM“僅處理文本”的侷限。涵蓋文本輸入(指令理解、隱含意圖挖掘)、視覺輸入(圖像/視頻編碼、跨模態對齊)、聽覺輸入(音頻 spectrogram 處理、語音識別)及其他輸入(觸覺、手勢、3D地圖等),讓智能體能夠“感知”真實世界的複雜信息。
- 行動(Action):將大腦的決策轉化為具體操作,拓展智能體的“影響範圍”。包括文本輸出(高質量語言生成)、工具使用(工具理解、學習使用、自主創造工具)、具身行動(物理世界交互,如機器人操作、虛擬環境導航)三大方向,使智能體從“被動響應”升級為“主動改變環境”。
圖 2:基於 LLM 的智能體概念框架,包含三大核心組件:大腦(brain)、感知(perception)與行動(action)。其中,大腦模塊作為核心控制器,承擔記憶、思考與決策等基礎任務;感知模塊負責感知並處理來自外部環境的多模態信息;行動模塊通過工具執行操作,進而對環境產生影響。以下結合示例說明其工作流程:當人類詢問 “是否會下雨” 時,感知模塊先將該指令轉化為 LLM 可理解的表示形式;隨後大腦模塊結合當前天氣狀況與互聯網氣象預報進行推理;最終行動模塊作出回應,並將雨傘遞給人類。通過重複上述過程,智能體能夠持續獲取反饋並與環境進行交互。
2. 應用場景:從“單打獨鬥”到“社群協作”的全維度落地
綜述將LLM-based智能體的應用場景分為四大類,覆蓋從個體到群體、從虛擬到現實的全場景:
-
單智能體場景(Single-Agent):聚焦個體智能體的獨立任務處理能力,分為三類部署模式:
- 任務導向部署:處理日常具體任務(如網頁導航、表單填寫),核心是指令理解與步驟分解;
- 創新導向部署:支持科學研究、代碼開發等創造性任務(如化學分子合成、代碼編寫與調試),依賴專業知識與工具調用;
- 生命週期導向部署:在開放環境中持續學習與生存(如Minecraft遊戲中的終身探索),需具備持續學習與技能積累能力。
-
多智能體場景(Multi-Agent):多個智能體通過交互實現“1+1>2”的效果,包括協作交互(有序協作如MetaGPT的軟件開發流程、無序協作如多智能體辯論)與對抗交互(通過競爭提升性能,如智能體辯論優化推理結果),核心是智能體間的分工、溝通與目標對齊
-
人機協作場景(Human-Agent):基於人類與智能體的優勢互補,分為兩類範式:
- 指導-執行者範式(Instructor-Executor):人類提供指令或反饋(定量評分、定性建議),智能體執行具體操作(如教育中的輔導、醫療中的診斷輔助);
- 平等夥伴範式(Equal Partnership):智能體具備共情能力與人類級協作能力(如遊戲中的隊友、心理疏導中的陪伴者),實現深度協同。
-
智能體社群(Agent Society):多個智能體在特定環境中形成模擬社會,展現出人類社會的湧現現象(如分工合作、信息傳播、倫理決策),可用於社會現象模擬、政策制定推演等場景,核心是智能體的行為個性、環境適配與群體動力學。
3. 落地關鍵實踐要點:讓智能體“能用、好用、安全用”
綜述明確了LLM-based智能體落地的三大核心實踐要點,解決“從理論到應用”的鴻溝:
- 工具SKMA體系:即工具的選擇(Selection)、知識(Knowledge)、管理(Management)與應用(Application)。智能體需先理解工具的功能與調用方式(通過零樣本/少樣本提示),再通過示範學習與反饋優化工具使用策略,甚至自主創造適配自身的工具(如生成可執行程序),實現工具能力與LLM決策能力的深度融合。具體而言,就是智能體得知道“用什麼工具、怎麼用工具”——比如要查實時天氣,它得知道調用天氣API;用錯了還能自己調整,甚至自己做一個更順手的工具(比如寫個小腳本),不用每次都麻煩人類教。
- 安全護欄機制:防止智能體陷入失控循環(如無限調用工具、生成有害內容)。核心包括對抗魯棒性增強(對抗訓練、樣本檢測)、信任worthiness保障(減少幻覺、偏見修正)、倫理約束(拒絕惡意指令、符合人類價值觀),避免智能體的行為對人類或環境造成傷害。簡短來說,得防止智能體“亂做事”——比如不會被壞人誤導生成危險內容,不會一直重複做一件沒用的事(比如無限次搜索),也不會有偏見(比如歧視某個群體),確保它的行為安全無害。
- 結果檢查機制:驗證智能體行動結果的準確性與有效性。通過外部知識庫校驗(減少幻覺)、多智能體交叉驗證(提升可靠性)、人類監督反饋(RLHF)等方式,確保智能體的輸出符合任務要求,避免“差之毫釐謬以千里”的問題。也就是智能體做完事,得有人或系統“把關”——比如它寫的報告要查一下事實對不對,它做的決策要交叉驗證一下,避免出錯。就像我們工作完要校對一樣,智能體也需要“質檢”環節。
4. 評估方法:怎麼判斷智能體“聰明不聰明、好用不好用”?
綜述提出LLM-based智能體的四維評估體系,突破傳統“單一任務評分”的侷限:
- 效用(Utility):核心評估任務完成能力,包括任務成功率(如是否達成目標)、基礎能力適配度(環境理解、推理、工具使用等)、效率(時間成本、資源消耗),代表智能體“能不能做事”。
- 社交性(Sociability):評估智能體的交互能力,包括語言溝通效率(自然語言理解與生成、隱含意圖捕捉)、協作/談判能力(多智能體協同效果)、角色一致性(長期任務中保持身份與行為統一),代表智能體“能不能和人/其他智能體好好相處”。
- 價值觀(Values):評估智能體的倫理合規性,包括誠實性(避免幻覺、承認能力邊界)、無害性(無偏見、無攻擊性)、語境適配性(符合特定文化與場景的價值觀),代表智能體“三觀正不正”。
- 持續進化能力(Continual Evolution):評估智能體的長期適應能力,包括持續學習(學習新技能不遺忘舊技能)、自主目標生成(開放環境中主動探索)、跨環境泛化(從虛擬場景遷移到物理場景),代表智能體“能不能一直進步”。
5. 開放問題:LLM智能體領域的“未解之謎”
綜述列出了LLM-based智能體領域尚未解決的四大核心開放問題,為未來研究指明方向:
- AGI路徑之爭:LLM-based智能體是否是實現AGI的有效路徑?支持者認為LLM通過大規模數據預訓練獲得了泛化與推理能力,具備AGI的雛形;反對者則指出LLM的“下一個token預測”範式無法模擬人類真正的思維過程,缺乏世界模型,難以實現真正的通用智能。
- 虛擬到物理的遷移鴻溝:智能體在虛擬環境(如Minecraft、文本遊戲)中表現優異,但遷移到物理環境時面臨硬件適配、環境不確定性、安全約束等問題,如何實現“虛擬智能”到“具身智能”的高效遷移仍是挑戰。
- 集體智能的湧現機制:多智能體系統如何形成真正的“集體智能”?目前多智能體協作仍依賴人類設計的規則,如何讓智能體自主形成分工、信任與協同,湧現出超越個體能力的群體行為,仍需深入研究。
- Agent as a Service(AaaS)的落地挑戰:如何將LLM-based智能體作為雲服務提供給用戶?面臨數據安全與隱私保護、服務可擴展性、用戶可控性等問題,同時需解決智能體的魯棒性與信任worthiness,避免服務濫用。
三、總結:這篇綜述的核心價值與領域影響
《The Rise and Potential of Large Language Model Based Agents》的核心價值在於:首次構建了LLM-based智能體的統一理論框架(大腦-感知-行動),系統梳理了從技術基礎、應用場景到落地實踐的全鏈條知識,明確了“LLM作為核心決策單元”的技術路線,為領域研究提供了統一範式。文章不僅整合了2023年前的研究成果,還通過開放問題的提出,引導後續研究聚焦AGI路徑、具身遷移、集體智能等核心方向,其影響力貫穿學術研究與工業應用,成為LLM智能體領域的“入門聖經”與“研究指南”。
AI Top Papers (6): The “Universal Code” of LLM Agents
Deep dive on Fudan NLP’s survey on LLM agents: Brain–Perception–Action framework, single/multi/human/society scenarios, tool SKMA and safety, four-dimensional evaluation, and open research questions.
Captured at (local ISO): 2026-05-18 05:17:08
Series Preface
Milestone papers light the path from AI theory to engineering. This series unpacks ten core papers—background, ideas, and impact. Part 6 covers 《The Rise and Potential of Large Language Model Based Agents》.
1. Why this survey matters for LLM agents
Fudan NLP’s 2023 survey maps LLM-driven agents before the 2024 explosion. Unlike narrow, task-specific bots, it proposes a brain–perception–action framework with the LLM as the decision core, multimodal sensing, and diverse actions— a unified template for more general agents. It spans single-agent, multi-agent, human–agent teams, emergence in agent societies, deployment, and open questions—often treated as the field’s standard reference.
2. Deep dive
2.1 Brain, perception, action
A closed perceive → decide → act loop:
- Brain: LLM handles memory, knowledge, reasoning, planning, and transfer—dialogue, world/professional knowledge, short/long-term memory, CoT and reflection, zero/few-shot and continual learning.
- Perception: Converts multimodal inputs into LLM-ready representations—text, vision, audio, touch, gestures, 3D maps, etc.
- Action: Executes decisions—text generation, tool use (select, learn, even invent tools), and embodied control in robots or simulators.
Figure 2: Conceptual framework. The brain controls memory and planning; perception ingests the world; action uses tools to change the environment. Example: user asks “Will it rain?”—perception encodes the question; the brain reasons over weather data and forecasts; action replies and hands over an umbrella. The loop repeats with feedback.
2.2 Application scenarios
- Single-agent: task-focused (web/forms), innovation-focused (science, coding), or lifelong open-world learning (e.g. Minecraft).
- Multi-agent: collaboration (MetaGPT-style pipelines, debate) or competition to improve reasoning.
- Human–agent: instructor–executor vs equal partner (games, counseling).
- Agent society: emergent norms, information spread, policy sandboxes.
2.3 Production practices
- Tool SKMA: Selection, Knowledge, Management, Application—know which API to call, learn from feedback, sometimes codegen new tools.
- Safety guardrails: robustness, trustworthiness (hallucination/bias), ethics and refusal of harmful commands.
- Result checking: external KB verification, multi-agent cross-check, human RLHF-style oversight.
2.4 Evaluation
Four axes beyond single-task scores:
- Utility: success rate, capability fit, cost;
- Sociability: communication, negotiation, role consistency;
- Values: honesty, harmlessness, cultural fit;
- Continual evolution: lifelong learning, self-goals, sim-to-real transfer.
2.5 Open problems
- Are LLM agents a viable path to AGI?
- Sim-to-real gap for embodied deployment;
- Mechanisms of true collective intelligence beyond hand-written rules;
- Agent-as-a-Service: privacy, scale, controllability, abuse resistance.
3. Summary
The survey’s lasting contribution is the brain–perception–action template and an end-to-end map from theory to deployment, positioning the LLM as the central decision module. Its open questions steer work on AGI routes, embodiment, collective behavior, and cloud agent services—making it both primer and research agenda for LLM agents.