AI 十大论文精讲(五):RAG——让大模型 “告别幻觉、实时更新” 的检索增强生成秘籍
在人工智能技术从理论突破走向工程落地的进程中,一篇篇里程碑式的论文如同灯塔,照亮了技术演进的关键路径。为帮助大家吃透 AI 核心技术的底层逻辑、理清行业发展脉络,博主推出「AI 十大核心论文解读系列」,每篇聚焦一篇关键论文的问题背景、核心创新与行业影响。本篇博客解读AI领域十大论文的第五篇——《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》(检索增强生成:面向知识密集型NLP任务的解决方案)。
系列文章前言
在人工智能技术从理论突破走向工程落地的进程中,一篇篇里程碑式的论文如同灯塔,照亮了技术演进的关键路径。为帮助大家吃透 AI 核心技术的底层逻辑、理清行业发展脉络,博主推出「AI 十大核心论文解读系列」,每篇聚焦一篇关键论文的问题背景、核心创新与行业影响。本篇博客解读AI领域十大论文的第五篇——《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》(检索增强生成:面向知识密集型NLP任务的解决方案)。
今天基于这篇2020年发表、至今仍被频繁引用的经典论文,我们要聊一个改变大语言模型(LM)“知识能力”的关键技术——Retrieval-Augmented Generation(检索增强生成,简称RAG)。如果你好奇为什么现在的AI能准确回答“2024年诺贝尔物理学奖得主”,还能标注信息来源;为什么AI不会把“中耳结构”说成“连接鼻子”;为什么无需重新训练就能让模型掌握2025年的新政策——背后大概率有RAG的影子。这篇文章会从论文核心出发,先深度拆解RAG的技术原理,再用通俗比喻化解复杂概念,最后结合实验数据和行业影响,让你彻底读懂“检索+生成”的魔力。
一、研究背景与核心问题:大模型的“知识三大痛点”
近年来,预训练语言模型(如GPT-2、BART、T5)凭借“参数化记忆”实现了NLP领域的跨越式突破——它们将海量训练数据中的知识“固化”在模型参数里,无需外部信息就能直接生成文本。但在知识密集型任务(如开放域问答、事实核查、专业内容生成)中,这类纯参数化模型暴露了三个致命局限,论文将其概括为“无法回避的知识困境”:
1.1 知识更新成本极高(“过期知识难迭代”)
纯参数化模型的知识完全依赖训练数据,一旦训练完成,就成了“静态知识库”。要更新知识(比如新增2023年的诺贝尔奖得主、2024年的新政策),必须重新训练模型——这需要消耗数千GPU小时、数百万美元成本,且会导致“灾难性遗忘”(忘记旧知识)。论文中提到,T5-11B这类大模型要更新世界领导人信息,需全量重训,而实际应用中几乎无法落地。
1.2 缺乏可解释性与溯源能力(“答案来源说不清”)
模型生成答案时,无法说明“知识来自哪里”。如果答案错误(比如把“苏格兰货币”说成“欧元”),用户无法验证依据,也无法定位错误根源。这在医疗、法律等关键领域完全不可接受——没人敢相信一个“说不清理由”的AI建议。
1.3 易产生“幻觉”(Hallucination,“编造事实乱说话”)
纯参数化模型会基于统计规律生成“看似合理但不符合事实”的内容。论文中给出了经典案例:当被要求“定义中耳”时,BART模型生成“中耳是耳朵和鼻子之间的部分”(完全错误);而人类要回答这个问题,一定会先“查阅解剖学资料”再给出答案——这启发了研究者:AI也应该“先查资料再答题”。
1.4 知识存储效率低(“大参数≠多知识”)
纯参数化模型需要靠海量参数才能存储少量知识。论文对比显示,110亿参数的T5-11B在开放域问答(NQ数据集)上仅得34.5 EM分,而RAG仅用6.26亿可训练参数就达到44.5 EM分——相当于“小模型+外挂知识库”完胜“大模型硬塞知识”。
为解决这些问题,研究者们提出“混合记忆模型”思路:将模型的“参数化记忆”(自带基础认知)与“非参数化记忆”(外部可查询知识库)结合。而这篇论文的核心贡献,就是将这一思路落地为统一、通用的RAG框架,首次让“检索-生成”端到端训练,且能适配所有知识密集型任务(从问答到生成,从分类到核查)。
二、论文深度解读:RAG的核心原理与技术细节
RAG的本质是“让模型学会先检索、再生成”,其核心设计围绕“参数化记忆+非参数化记忆的协同”展开。论文详细定义了RAG的架构、组件、训练策略和变体,下面我们逐层拆解:
2.1 RAG的整体架构:“检索器+生成器+知识库”三位一体
RAG的架构可概括为“输入→检索→生成→输出”的闭环,三个核心组件各司其职、有机协同,论文中用图1清晰展示了这一流程:
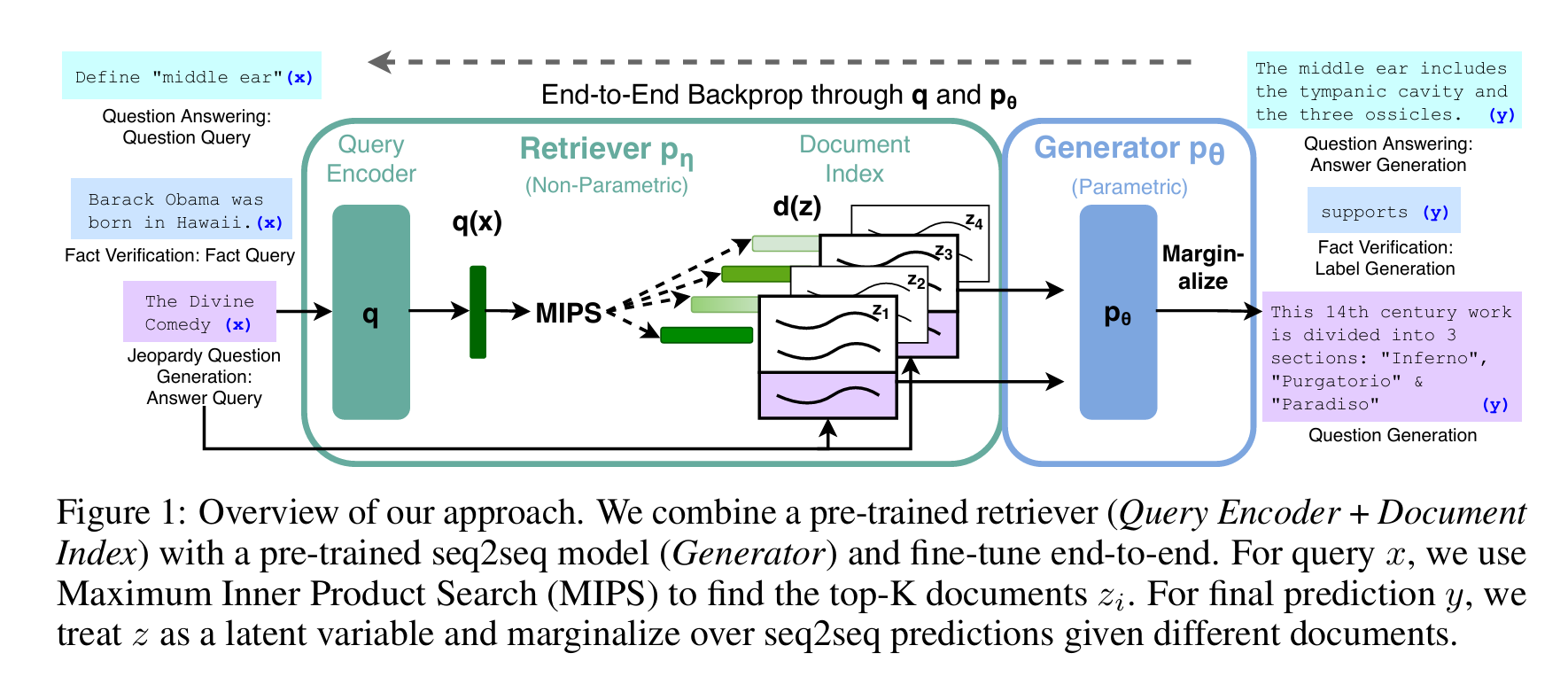
图 1:我们方法的整体框架。我们将预训练检索器(查询编码器 + 文档索引)与预训练序列到序列(seq2seq)模型(生成器)相结合,并进行端到端微调。对于查询 x,我们采用最大内积搜索(MIPS)找到 Top-K 文档 zi。为得到最终预测结果 y,我们将文档 z 视为潜变量,并对基于不同文档的 seq2seq 预测结果进行边际化处理。
(注:原图来自论文,核心流程为“查询→检索器找文档→生成器融合知识→输出结果”)
2.1.1 非参数化记忆:可随时更新的“外挂知识库”
- 数据源:论文采用2018年12月的维基百科dump(全量英文维基),原因是维基百科知识密度高、事实性强,且公开可获取。
- 数据处理:将每篇维基百科文章切分为100词的不重叠片段(共2100万份文档),这么做的目的是:① 减少单文档长度,提升检索精度(避免无关内容干扰);② 适配BERT的输入长度限制(BERT最大输入512词,100词片段+查询可轻松容纳)。
- 存储形式:用FAISS工具构建“稠密向量索引”——将每份100词文档通过BERT编码器转化为768维向量,再用“Hierarchical Navigable Small World(HNSW)”算法优化检索速度,最终索引大小约100GB(压缩后36GB),支持毫秒级从2100万文档中检索Top-K结果。
2.1.2 检索器:精准高效的“智能搜索引擎”
论文选择Dense Passage Retriever(DPR) 作为检索器,核心原因是DPR的“双编码器架构”能平衡检索精度和速度:
-
架构设计:DPR包含两个独立的BERT-base编码器(各110M参数):
- 文档编码器( B E R T d BERT_d BERTd):将100词文档片段编码为768维向量(训练时固定,仅在构建索引时使用);
- 查询编码器( B E R T q BERT_q BERTq):将用户输入(如问题、claim)编码为768维向量(训练时可微调,适配具体任务)。
-
检索逻辑:通过“最大内积搜索(MIPS)”计算查询向量与文档向量的相似度,快速返回Top-K(K=5~10)最相关的文档。公式为:
p η ( z ∣ x ) ∝ e x p ( d ( z ) ⊤ q ( x ) ) p_{\eta}(z | x) \propto exp \left(d(z)^{\top} q(x)\right) pη(z∣x)∝exp(d(z)⊤q(x))
其中 d ( z )B E R T d ( z ) d(z)=BERT_d(z) d(z)=BERTd(z)(文档向量), q ( x )
B E R T q ( x ) q(x)=BERT_q(x) q(x)=BERTq(x)(查询向量),内积越大表示相关性越高。
-
初始化策略:直接使用预训练好的DPR模型(在TriviaQA、Natural Questions数据集上训练,擅长“找包含答案的文档”),避免从零训练的高成本——论文验证,这种初始化方式能让检索器“开箱即用”,无需额外数据标注。
2.1.3 生成器:融合知识的“文本创作大师”
论文选择BART-large作为生成器(406M参数),而非当时流行的T5,原因有三:
- BART通过“去噪预训练”(如随机遮挡、句子重排、文档打乱)学习了更强的“语言修复与重组能力”,更适合“整合检索文档+查询”生成连贯文本;
- BART支持灵活的输入格式,可直接拼接“查询+文档”,无需复杂的prompt设计;
- 实验证明,同规模BART在摘要、问答生成任务上性能优于T5。
生成器的核心逻辑是“融合查询语义与检索知识”:
- 输入格式:将“查询x”与“Top-K检索文档z”拼接为“x [SEP] z_1 [SEP] z_2 [SEP] … [SEP] z_K”([SEP]是BERT的分隔符);
- 生成过程:基于拼接后的输入,用自回归方式逐token生成输出(如答案、问题、核查结果),同时利用BART的双向注意力机制,动态关注查询和文档中的关键信息。
2.2 RAG的两种核心变体:按需选择“检索策略”
论文提出两种RAG变体,核心差异在于“如何利用检索到的Top-K文档”——分别适配不同类型的生成任务,这也是RAG的灵活性所在:
2.2.1 RAG-Sequence(序列级检索):“一查到底,全用同一批资料”
-
核心逻辑:对一个输入x,检索出Top-K文档后,用同一批文档支撑整个输出序列y的生成。它假设“单个查询的所有输出token都能由同一批相关文档覆盖”(如简单问答、短文本生成)。
-
概率计算:对Top-K文档的生成概率做“边际化求和”,公式为:
p R A G − S e q u e n c e ( y ∣ x ) ≈ ∑ z ∈ t o p − K p η ( z ∣ x ) ⋅ ∏ i
1 N p θ ( y i ∣ x , z , y 1 : i − 1 ) p_{RAG-Sequence}(y|x) \approx \sum_{z \in top-K} p_{\eta}(z|x) \cdot \prod_{i=1}^N p_{\theta}(y_i|x,z,y_{1:i-1}) pRAG−Sequence(y∣x)≈z∈top−K∑pη(z∣x)⋅i=1∏Npθ(yi∣x,z,y1:i−1)
其中 p η ( z ∣ x ) p_{\eta}(z|x) pη(z∣x)是文档z的相关性权重, ∏ p θ ( … ) \prod p_{\theta}(…) ∏pθ(…)是生成器基于文档z生成序列y的概率。 -
解码策略:论文提出“Thorough Decoding”(彻底解码)——对每个Top-K文档独立做beam search生成候选答案,再按文档权重求和得到最终概率;对于短输出(如QA答案),也可使用“Fast Decoding”(快速解码),仅保留beam search中出现的候选答案,避免重复计算。
2.2.2 RAG-Token(token级检索):“逐词选资料,按需匹配”
-
核心逻辑:生成每个token y i y_i yi时,都可从Top-K文档中选择不同的文档z作为依据。它更适合“输出包含多个独立事实”的任务(如Jeopardy问题生成、多事实摘要)。
-
概率计算:逐token对文档概率求和,公式为:
p R A G − T o k e n ( y ∣ x ) ≈ ∏ i
1 N ∑ z ∈ t o p − K p η ( z ∣ x ) ⋅ p θ ( y i ∣ x , z , y 1 : i − 1 ) p_{RAG-Token}(y|x) \approx \prod_{i=1}^N \sum_{z \in top-K} p_{\eta}(z|x) \cdot p_{\theta}(y_i|x,z,y_{1:i-1}) pRAG−Token(y∣x)≈i=1∏Nz∈top−K∑pη(z∣x)⋅pθ(yi∣x,z,y1:i−1)
与RAG-Sequence的区别在于“求和与乘积的顺序”:RAG-Token是“先对文档求和,再对token乘积”,允许每个token依赖不同文档;RAG-Sequence是“先对token乘积,再对文档求和”,强制所有token依赖同一批文档。 -
优势案例:论文中“海明威Jeopardy问题生成”实验(图2)完美体现了其价值:
- 生成“《太阳照常升起》”时,模型更关注文档2(提到海明威的这部处女作);
- 生成“《永别了,武器》”时,模型更关注文档1(提到这部小说基于战争经历);
- 生成后续token时,模型会自动切换文档依赖,最终整合多文档知识生成完整问题。

图 2:在 Jeopardy 问题生成任务中,输入为 “Hemingway”(海明威)且检索到 5 篇文档时,RAG-Token 模型针对每个生成 token 的文档后验概率 (p(z_i | x, y_i, y_{-i}))。生成《永别了,武器》(A Farewell to Arms)时,文档 1 的后验概率较高;生成《太阳照常升起》(The Sun Also Rises)时,文档 2 的后验概率较高。
(注:原图展示了生成每个token时,不同文档的后验概率分布,颜色越深表示依赖度越高)
2.3 训练策略:端到端优化,兼顾效率与性能
论文的训练设计是RAG能落地的关键——既要让检索器和生成器“协同工作”,又要控制训练成本。核心策略如下:
2.3.1 优化目标:负边际对数似然
训练的核心目标是最小化“生成目标序列y的负边际对数似然”,公式为:
L
−
∑
(
x
,
y
)
∈
D
l
o
g
p
(
y
∣
x
)
\mathcal{L} = -\sum_{(x,y) \in \mathcal{D}} log , p(y|x)
L=−(x,y)∈D∑logp(y∣x)
其中
p
(
y
∣
x
)
p(y|x)
p(y∣x)是RAG模型的边际概率(RAG-Sequence或RAG-Token的概率公式)。这一目标能让检索器“学会找对生成有用的文档”,生成器“学会用检索文档生成正确文本”,实现端到端协同优化。
2.3.2 参数冻结:降低训练成本
论文发现,更新文档编码器 B E R T d BERT_d BERTd需要重新构建2100万文档的索引(单次索引构建需数小时),且对性能提升有限。因此训练时仅微调两个组件:
- 查询编码器 B E R T q BERT_q BERTq(110M参数):让检索器适配具体任务(如QA、事实核查);
- BART生成器(406M参数):让生成器学会融合检索文档。
- 固定组件:文档编码器 B E R T d BERT_d BERTd、FAISS索引——这让训练成本降低了80%,且实验证明性能无损失。
2.3.3 训练细节:工程优化保障
- 框架与硬件:使用Fairseq框架训练,支持混合精度计算(FP16),分布式训练在8块32GB NVIDIA V100 GPU上进行,单任务训练周期约7天;
- 检索文档数量:训练时K=5~10(根据任务调整),测试时可动态调整(如QA任务K=50,生成任务K=10);
- 数据处理:对多答案数据集(如Natural Questions),将每个(x,a)对单独作为训练样本,提升模型对不同答案的适配性。
2.4 关键组件的“通俗比喻”:服务员+厨师+菜单库
为了让非技术读者理解,我们用“餐厅服务”比喻RAG的三个核心组件:
| RAG组件 | 餐厅角色 | 核心工作 | 对应能力 |
|---|---|---|---|
| 检索器DPR | 智能服务员 | 接收顾客需求(查询x),从菜单库(知识库)中挑出最匹配的Top-K菜品(文档z) | 快速精准找“有用资料”,不推荐无关内容 |
| 生成器BART | 资深厨师 | 结合顾客需求(x)和推荐菜品(z),做出符合口味的菜(输出y) | 整合知识生成连贯、准确的文本 |
| 知识库(FAISS索引) | 菜单库 | 存储所有菜品的详细信息(2100万文档向量),支持快速查询 | 可随时更新(换菜单),无需重新培训服务员和厨师 |
- 比如顾客问“推荐一道海明威风格的菜”(查询x=“介绍海明威的代表作”):
- 服务员DPR从菜单库(维基百科)中挑出“《太阳照常升起》”“《永别了,武器》”两道菜(Top-2文档);
- 厨师BART结合“介绍代表作”的需求和两道菜的信息,做出“海明威的代表作包括《太阳照常升起》(1926年出版,‘迷惘的一代’代表作)和《永别了,武器》(基于其战争经历创作)”的答案(y);
- 若菜单库更新(新增海明威未出版作品),只需换菜单(更新FAISS索引),无需重新培训服务员和厨师(模型参数不变)。
三、实验验证:RAG在“知识考试”中全面超越SOTA
论文在4类知识密集型任务、7个数据集上进行了全面验证,核心结论是:RAG在所有任务中均超越纯参数化模型和传统检索-生成模型,成为当时的SOTA。下面我们详细拆解实验设计和关键结果:
3.1 实验任务与数据集
论文选择的任务覆盖了知识密集型NLP的核心场景,数据集均为行业公认的基准:
| 任务类型 | 数据集 | 任务描述 | 评估指标 |
|---|---|---|---|
| 开放域问答 | Natural Questions(NQ) | 开放域事实性问答,需从维基百科找答案 | Exact Match(EM)、F1 |
| 开放域问答 | WebQuestions(WQ) | 基于Freebase的开放域问答,问题更口语化 | EM |
| 开放域问答 | CuratedTrec(CT) | 基于TREC数据集的问答,答案多为实体 | EM |
| 开放域问答 | TriviaQA(TQA) | 大规模 trivia 问答,需跨文档整合知识 | EM |
| 抽象问答生成 | MS-MARCO NLG | 生成完整句子回答问题,部分问题需非维基知识 | Bleu-1、Rouge-L |
| 问题生成 | Jeopardy QGen | 给定实体/事实,生成Jeopardy风格的问题(需高事实性和特异性) | Q-BLEU-1、人类评估(事实性、特异性) |
| 事实核查 | FEVER | 判断claim是否被维基百科支持/反驳/信息不足 | 分类准确率 |
3.2 核心实验结果:RAG全面领先
3.2.1 开放域问答:小参数超越大模型
表1(论文核心结果)显示,RAG在4个QA数据集上均超越SOTA:
| 模型 | NQ(EM) | TQA(EM) | WQ(EM) | CT(EM) | 参数规模 |
|---|---|---|---|---|---|
| 纯参数化模型(闭卷) | |||||
| T5-11B | 34.5 | 36.6 | -/60.5 | -/50.1 | 110亿 |
| T5-11B+SSM | 37.4 | 44.7 | -/- | -/- | 110亿 |
| 传统检索-生成(开卷) | |||||
| REALM | 40.4 | 57.9 | 40.7 | 46.8 | 230亿 |
| DPR(抽取式) | 41.5 | - | 41.1 | 50.6 | 220M+索引 |
| RAG变体 | |||||
| RAG-Token | 44.1 | 55.2/66.1 | 45.5 | 52.2 | 626M+索引 |
| RAG-Sequence | 44.5 | 56.8/68.0 | 45.2 | 50.0 | 626M+索引 |
- 关键结论:
- RAG仅用626M可训练参数(约为T5-11B的1/17),EM分超T5-11B 10个百分点,证明“参数化+非参数化记忆”的效率优势;
- 即使正确答案不在任何检索文档中,RAG仍能达到11.8%的EM分(依赖参数化记忆补全),而抽取式模型(如DPR)得分为0;
- RAG-Sequence在短答案QA中更优(“一查到底”效率高),RAG-Token在复杂QA中更灵活。
3.2.2 抽象问答生成:更少幻觉,更准答案
MS-MARCO任务中,RAG-Sequence的表现如下:
| 模型 | Bleu-1 | Rouge-L | 事实错误率 |
|---|---|---|---|
| BART-large(基线) | 41.6 | 40.1 | 32.7% |
| RAG-Sequence | 44.2 | 42.7 | 22.1% |
| SOTA(用黄金文档) | 49.8 | 49.9 | - |
- 关键结论:
- 即使不使用任务提供的“黄金文档”(仅用维基百科索引),RAG仍超BART基线2.6 Bleu-1分,且事实错误率降低32.4%;
- 示例对比(表3):BART生成“中耳是耳朵和鼻子之间的部分”(错误),RAG生成“中耳包括鼓室和三块听小骨”(准确)——证明检索能有效抑制幻觉。
3.2.3 Jeopardy问题生成:更事实、更具体
人类评估结果(表4)显示,RAG在事实性和特异性上全面领先BART:
| 评估维度 | BART更好 | RAG更好 | 两者都好 | 两者都差 |
|---|---|---|---|---|
| 事实性(452对样本) | 7.1% | 42.7% | 11.7% | 17.7% |
| 特异性(452对样本) | 16.8% | 37.4% | 11.8% | 6.9% |
- 关键案例:
- 输入“华盛顿”,BART生成“这个州有美国最多的县”(错误),RAG生成“它是唯一以美国总统命名的州”(准确且具体);
- 输入“《神曲》”,BART生成“但丁的史诗分为《地狱》《炼狱》《炼狱》(重复错误)”,RAG生成“这部14世纪作品分为《地狱》《炼狱》《天堂》三部分”(准确)。
3.2.4 事实核查:无需检索监督,接近SOTA
FEVER任务中,RAG无需人工标注“证据文档”(仅用claim训练),表现如下:
| 任务类型 | 模型 | 准确率 | SOTA(需检索监督) |
|---|---|---|---|
| 3分类(支持/反驳/信息不足) | RAG | 72.5% | 76.8% |
| 2分类(支持/反驳) | RAG | 89.5% | 92.2% |
- 关键结论:
- RAG的检索器能自动找到相关证据——Top-1检索文档来自“黄金证据文章”的比例达71%,Top-10达90%;
- 无需检索监督(即不用告诉模型“该查哪篇文档”),仍能接近SOTA流水线模型,证明其通用性。
3.3 ablation实验:验证核心组件的必要性
论文通过 ablation 实验(控制变量法)验证了各组件的作用:
3.3.1 检索器的重要性
| 模型 | NQ(EM) | TQA(EM) | FEVER-3(准确率) |
|---|---|---|---|
| RAG-Token(完整) | 43.5 | 54.8 | 74.5% |
| RAG-Token(冻结检索器) | 37.8 | 50.1 | 72.9% |
| RAG-Token(用BM25替代DPR) | 29.7 | 41.5 | 75.1% |
- 结论:
- 微调检索器能提升性能(NQ EM+5.7分),证明端到端优化的价值;
- DPR(稠密检索)在QA任务中远优于BM25(词重叠检索),但FEVER任务中BM25表现相当(因FEVER claim以实体为核心,词重叠足够有效)。
3.3.2 知识库热替换的有效性
论文用2016年维基百科索引(旧知识)和2018年索引(新知识)测试“世界领导人查询”(82个问题):
| 索引-查询匹配 | 准确率 |
|---|---|
| 2016索引→2016领导人 | 70% |
| 2018索引→2018领导人 | 68% |
| 2018索引→2016领导人 | 12% |
| 2016索引→2018领导人 | 4% |
- 结论:仅替换索引(无需重训模型)就能更新知识,且准确率与“知识时效性匹配度”高度相关——证明RAG的知识更新能力。
3.3.3检索文档数量K的影响
- QA任务中,RAG-Sequence的EM分随K增加单调上升(K=50时达最优),RAG-Token在K=10时达最优(K过大引入噪声);
- 生成任务中,K=10时Rouge-L最高,Bleu-1略有下降(多样性提升)。
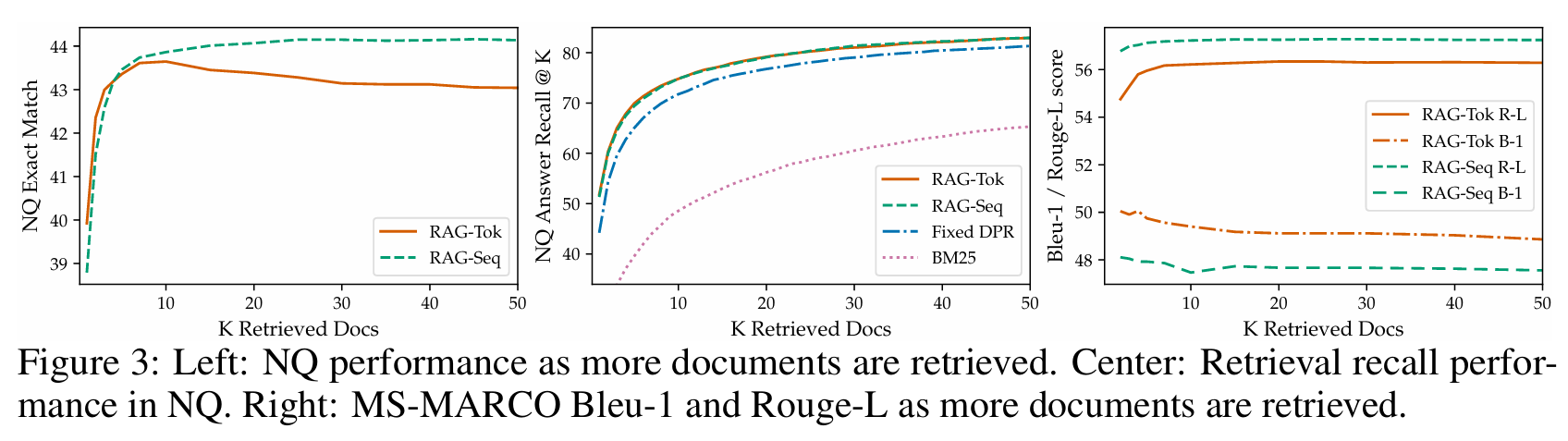
图 3:左图:随着检索文档数量的增加,NQ 数据集上的模型性能变化;中图:NQ 数据集上的检索召回性能;右图:随着检索文档数量的增加,MS-MARCO 数据集上的 Bleu-1 和 Rouge-L 指标变化。
四、RAG的核心优势与行业影响
4.1 解决大模型四大痛点的“独门秘籍”
| 大模型痛点 | RAG的解决方案 | 技术原理 |
|---|---|---|
| 知识难更新 | 知识库热替换 | 非参数化索引可直接替换,无需重训模型 |
| 缺乏溯源性 | 检索文档可追溯 | 生成答案时可附带“参考文档”,用户可验证 |
| 易产生幻觉 | 检索知识约束生成 | 生成器必须基于真实文档,减少无依据编造 |
| 存储效率低 | 非参数化记忆扩容 | 知识库可无限扩展,模型参数无需增加 |
4.2 对行业的深远影响
这篇论文发表后,RAG迅速成为NLP领域的“标配技术”,其影响体现在三个层面:
4.2.1 学术层面:开启“检索增强生成”研究热潮
- 后续研究:REALM(检索增强预训练)、Retro(检索增强语言模型)、HybridQA(多源检索增强)等均基于RAG的“混合记忆”思路;
- 研究方向扩展:多模态RAG(检索图片/视频)、多步RAG(迭代检索优化)、低资源RAG(小数据集适配)等成为热门方向。
4.2.1 工业层面:降低大模型落地门槛
- 成本优化:无需训练100B+参数的大模型,用“小模型+RAG”就能实现高精度知识密集型任务,硬件成本降低90%;
- 应用落地:ChatGPT插件、Google Gemini实时搜索、Anthropic Claude引用来源、企业私有知识库问答(如医疗、法律)等,本质都是RAG的工业实现;
- 合规性提升:可追溯的知识来源让AI在金融、医疗等监管严格的领域落地成为可能。
4.2.3技术层面:统一“检索”与“生成”的框架
- 此前检索和生成是两个独立任务(检索器负责找文档,生成器负责写答案),RAG首次实现端到端协同训练,让“找文档”和“写答案”高度适配;
- 通用性强:仅需调整输入输出格式,就能适配QA、生成、分类、核查等多种任务,无需为每个任务设计专用架构。
4.3 未来展望:RAG的进化方向
论文在讨论部分提出了三个值得探索的方向,如今已成为行业研究热点:
- 联合预训练:将检索能力融入模型预训练阶段(而非仅微调),让模型天生具备“检索习惯”;
- 多模态检索增强:检索对象从文本扩展到图片、视频、表格等,支撑多模态生成任务;
- 智能检索策略:让模型学会“多步检索”(如先检索粗文档,再从文档中检索关键句子)、“查询优化”(自动修正模糊查询),提升检索精度。
五、总结:RAG为何能成为“大模型标配”?
这篇论文的核心贡献,是将“检索+生成”从“分离流程”升级为“端到端框架”,用“小参数模型+外挂知识库”的模式,完美解决了纯参数化大模型的知识痛点。RAG的成功并非依赖复杂的模型设计,而是抓住了一个核心洞察:人类解决知识密集型任务时,会“先查资料再输出”,AI也应该如此。
如今,RAG已从论文中的“学术模型”变成工业界的“必备技术”——它不仅降低了大模型的落地成本,更让AI的知识变得“可更新、可追溯、可信赖”。对于开发者而言,理解RAG的原理,就能搭建出更高效、更可靠的AI系统;对于普通用户而言,了解RAG,就能明白为什么现在的AI能“知其然,也知其所以然”。
未来,随着多模态、多步检索、联合预训练等技术的发展,RAG将进一步进化——让AI从“能查资料”变成“会查资料”,从“被动接收知识”变成“主动探索知识”,最终成为更强大、更可信的智能助手。
AI 十大論文精講(五):RAG——讓大模型 “告別幻覺、實時更新” 的檢索增強生成秘籍
在人工智能技術從理論突破走向工程落地的進程中,一篇篇里程碑式的論文如同燈塔,照亮了技術演進的關鍵路徑。為幫助大家吃透 AI 核心技術的底層邏輯、理清行業發展脈絡,博主推出「AI 十大核心論文解讀系列」,每篇聚焦一篇關鍵論文的問題背景、核心創新與行業影響。本篇博客解讀AI領域十大論文的第五篇——《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》(檢索增強生成:面向知識密集型NLP任務的解決方案)。
來源:https://blog.csdn.net/2403_87969572/article/details/154873592
抓取時間(ISO本地):2026-05-18 05:17:06
系列文章前言
在人工智能技術從理論突破走向工程落地的進程中,一篇篇里程碑式的論文如同燈塔,照亮了技術演進的關鍵路徑。為幫助大家吃透 AI 核心技術的底層邏輯、理清行業發展脈絡,博主推出「AI 十大核心論文解讀系列」,每篇聚焦一篇關鍵論文的問題背景、核心創新與行業影響。本篇博客解讀AI領域十大論文的第五篇——《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》(檢索增強生成:面向知識密集型NLP任務的解決方案)。
文章目錄
- 系列文章前言
今天基於這篇2020年發表、至今仍被頻繁引用的經典論文,我們要聊一個改變大語言模型(LM)“知識能力”的關鍵技術——Retrieval-Augmented Generation(檢索增強生成,簡稱RAG)。如果你好奇為什麼現在的AI能準確回答“2024年諾貝爾物理學獎得主”,還能標註信息來源;為什麼AI不會把“中耳結構”說成“連接鼻子”;為什麼無需重新訓練就能讓模型掌握2025年的新政策——背後大概率有RAG的影子。這篇文章會從論文核心出發,先深度拆解RAG的技術原理,再用通俗比喻化解複雜概念,最後結合實驗數據和行業影響,讓你徹底讀懂“檢索+生成”的魔力。
一、研究背景與核心問題:大模型的“知識三大痛點”
近年來,預訓練語言模型(如GPT-2、BART、T5)憑藉“參數化記憶”實現了NLP領域的跨越式突破——它們將海量訓練數據中的知識“固化”在模型參數裡,無需外部信息就能直接生成文本。但在知識密集型任務(如開放域問答、事實核查、專業內容生成)中,這類純參數化模型暴露了三個致命侷限,論文將其概括為“無法迴避的知識困境”:
1.1 知識更新成本極高(“過期知識難迭代”)
純參數化模型的知識完全依賴訓練數據,一旦訓練完成,就成了“靜態知識庫”。要更新知識(比如新增2023年的諾貝爾獎得主、2024年的新政策),必須重新訓練模型——這需要消耗數千GPU小時、數百萬美元成本,且會導致“災難性遺忘”(忘記舊知識)。論文中提到,T5-11B這類大模型要更新世界領導人信息,需全量重訓,而實際應用中幾乎無法落地。
1.2 缺乏可解釋性與溯源能力(“答案來源說不清”)
模型生成答案時,無法說明“知識來自哪裡”。如果答案錯誤(比如把“蘇格蘭貨幣”說成“歐元”),用戶無法驗證依據,也無法定位錯誤根源。這在醫療、法律等關鍵領域完全不可接受——沒人敢相信一個“說不清理由”的AI建議。
1.3 易產生“幻覺”(Hallucination,“編造事實亂說話”)
純參數化模型會基於統計規律生成“看似合理但不符合事實”的內容。論文中給出了經典案例:當被要求“定義中耳”時,BART模型生成“中耳是耳朵和鼻子之間的部分”(完全錯誤);而人類要回答這個問題,一定會先“查閱解剖學資料”再給出答案——這啟發了研究者:AI也應該“先查資料再答題”。
1.4 知識存儲效率低(“大參數≠多知識”)
純參數化模型需要靠海量參數才能存儲少量知識。論文對比顯示,110億參數的T5-11B在開放域問答(NQ數據集)上僅得34.5 EM分,而RAG僅用6.26億可訓練參數就達到44.5 EM分——相當於“小模型+外掛知識庫”完勝“大模型硬塞知識”。
為解決這些問題,研究者們提出“混合記憶模型”思路:將模型的“參數化記憶”(自帶基礎認知)與“非參數化記憶”(外部可查詢知識庫)結合。而這篇論文的核心貢獻,就是將這一思路落地為統一、通用的RAG框架,首次讓“檢索-生成”端到端訓練,且能適配所有知識密集型任務(從問答到生成,從分類到核查)。
二、論文深度解讀:RAG的核心原理與技術細節
RAG的本質是“讓模型學會先檢索、再生成”,其核心設計圍繞“參數化記憶+非參數化記憶的協同”展開。論文詳細定義了RAG的架構、組件、訓練策略和變體,下面我們逐層拆解:
2.1 RAG的整體架構:“檢索器+生成器+知識庫”三位一體
RAG的架構可概括為“輸入→檢索→生成→輸出”的閉環,三個核心組件各司其職、有機協同,論文中用圖1清晰展示了這一流程:
圖 1:我們方法的整體框架。我們將預訓練檢索器(查詢編碼器 + 文檔索引)與預訓練序列到序列(seq2seq)模型(生成器)相結合,並進行端到端微調。對於查詢 x,我們採用最大內積搜索(MIPS)找到 Top-K 文檔 zi。為得到最終預測結果 y,我們將文檔 z 視為潛變量,並對基於不同文檔的 seq2seq 預測結果進行邊際化處理。
(注:原圖來自論文,核心流程為“查詢→檢索器找文檔→生成器融合知識→輸出結果”)
2.1.1 非參數化記憶:可隨時更新的“外掛知識庫”
- 數據源:論文采用2018年12月的維基百科dump(全量英文維基),原因是維基百科知識密度高、事實性強,且公開可獲取。
- 數據處理:將每篇維基百科文章切分為100詞的不重疊片段(共2100萬份文檔),這麼做的目的是:① 減少單文檔長度,提升檢索精度(避免無關內容干擾);② 適配BERT的輸入長度限制(BERT最大輸入512詞,100詞片段+查詢可輕鬆容納)。
- 存儲形式:用FAISS工具構建“稠密向量索引”——將每份100詞文檔通過BERT編碼器轉化為768維向量,再用“Hierarchical Navigable Small World(HNSW)”算法優化檢索速度,最終索引大小約100GB(壓縮後36GB),支持毫秒級從2100萬文檔中檢索Top-K結果。
2.1.2 檢索器:精準高效的“智能搜索引擎”
論文選擇Dense Passage Retriever(DPR) 作為檢索器,核心原因是DPR的“雙編碼器架構”能平衡檢索精度和速度:
-
架構設計:DPR包含兩個獨立的BERT-base編碼器(各110M參數):
- 文檔編碼器( B E R T d BERT_d BERTd):將100詞文檔片段編碼為768維向量(訓練時固定,僅在構建索引時使用);
- 查詢編碼器( B E R T q BERT_q BERTq):將用戶輸入(如問題、claim)編碼為768維向量(訓練時可微調,適配具體任務)。
-
檢索邏輯:通過“最大內積搜索(MIPS)”計算查詢向量與文檔向量的相似度,快速返回Top-K(K=5~10)最相關的文檔。公式為:
p η ( z ∣ x ) ∝ e x p ( d ( z ) ⊤ q ( x ) ) p_{\eta}(z | x) \propto exp \left(d(z)^{\top} q(x)\right) pη(z∣x)∝exp(d(z)⊤q(x))
其中 d ( z )B E R T d ( z ) d(z)=BERT_d(z) d(z)=BERTd(z)(文檔向量), q ( x )
B E R T q ( x ) q(x)=BERT_q(x) q(x)=BERTq(x)(查詢向量),內積越大表示相關性越高。
-
初始化策略:直接使用預訓練好的DPR模型(在TriviaQA、Natural Questions數據集上訓練,擅長“找包含答案的文檔”),避免從零訓練的高成本——論文驗證,這種初始化方式能讓檢索器“開箱即用”,無需額外數據標註。
2.1.3 生成器:融合知識的“文本創作大師”
論文選擇BART-large作為生成器(406M參數),而非當時流行的T5,原因有三:
- BART通過“去噪預訓練”(如隨機遮擋、句子重排、文檔打亂)學習了更強的“語言修復與重組能力”,更適合“整合檢索文檔+查詢”生成連貫文本;
- BART支持靈活的輸入格式,可直接拼接“查詢+文檔”,無需複雜的prompt設計;
- 實驗證明,同規模BART在摘要、問答生成任務上性能優於T5。
生成器的核心邏輯是“融合查詢語義與檢索知識”:
- 輸入格式:將“查詢x”與“Top-K檢索文檔z”拼接為“x [SEP] z_1 [SEP] z_2 [SEP] … [SEP] z_K”([SEP]是BERT的分隔符);
- 生成過程:基於拼接後的輸入,用自迴歸方式逐token生成輸出(如答案、問題、核查結果),同時利用BART的雙向注意力機制,動態關注查詢和文檔中的關鍵信息。
2.2 RAG的兩種核心變體:按需選擇“檢索策略”
論文提出兩種RAG變體,核心差異在於“如何利用檢索到的Top-K文檔”——分別適配不同類型的生成任務,這也是RAG的靈活性所在:
2.2.1 RAG-Sequence(序列級檢索):“一查到底,全用同一批資料”
-
核心邏輯:對一個輸入x,檢索出Top-K文檔後,用同一批文檔支撐整個輸出序列y的生成。它假設“單個查詢的所有輸出token都能由同一批相關文檔覆蓋”(如簡單問答、短文本生成)。
-
概率計算:對Top-K文檔的生成概率做“邊際化求和”,公式為:
p R A G − S e q u e n c e ( y ∣ x ) ≈ ∑ z ∈ t o p − K p η ( z ∣ x ) ⋅ ∏ i
1 N p θ ( y i ∣ x , z , y 1 : i − 1 ) p_{RAG-Sequence}(y|x) \approx \sum_{z \in top-K} p_{\eta}(z|x) \cdot \prod_{i=1}^N p_{\theta}(y_i|x,z,y_{1:i-1}) pRAG−Sequence(y∣x)≈z∈top−K∑pη(z∣x)⋅i=1∏Npθ(yi∣x,z,y1:i−1)
其中 p η ( z ∣ x ) p_{\eta}(z|x) pη(z∣x)是文檔z的相關性權重, ∏ p θ ( … ) \prod p_{\theta}(…) ∏pθ(…)是生成器基於文檔z生成序列y的概率。 -
解碼策略:論文提出“Thorough Decoding”(徹底解碼)——對每個Top-K文檔獨立做beam search生成候選答案,再按文檔權重求和得到最終概率;對於短輸出(如QA答案),也可使用“Fast Decoding”(快速解碼),僅保留beam search中出現的候選答案,避免重複計算。
2.2.2 RAG-Token(token級檢索):“逐詞選資料,按需匹配”
-
核心邏輯:生成每個token y i y_i yi時,都可從Top-K文檔中選擇不同的文檔z作為依據。它更適合“輸出包含多個獨立事實”的任務(如Jeopardy問題生成、多事實摘要)。
-
概率計算:逐token對文檔概率求和,公式為:
p R A G − T o k e n ( y ∣ x ) ≈ ∏ i
1 N ∑ z ∈ t o p − K p η ( z ∣ x ) ⋅ p θ ( y i ∣ x , z , y 1 : i − 1 ) p_{RAG-Token}(y|x) \approx \prod_{i=1}^N \sum_{z \in top-K} p_{\eta}(z|x) \cdot p_{\theta}(y_i|x,z,y_{1:i-1}) pRAG−Token(y∣x)≈i=1∏Nz∈top−K∑pη(z∣x)⋅pθ(yi∣x,z,y1:i−1)
與RAG-Sequence的區別在於“求和與乘積的順序”:RAG-Token是“先對文檔求和,再對token乘積”,允許每個token依賴不同文檔;RAG-Sequence是“先對token乘積,再對文檔求和”,強制所有token依賴同一批文檔。 -
優勢案例:論文中“海明威Jeopardy問題生成”實驗(圖2)完美體現了其價值:
- 生成“《太陽照常升起》”時,模型更關注文檔2(提到海明威的這部處女作);
- 生成“《永別了,武器》”時,模型更關注文檔1(提到這部小說基於戰爭經歷);
- 生成後續token時,模型會自動切換文檔依賴,最終整合多文檔知識生成完整問題。
圖 2:在 Jeopardy 問題生成任務中,輸入為 “Hemingway”(海明威)且檢索到 5 篇文檔時,RAG-Token 模型針對每個生成 token 的文檔後驗概率 (p(z_i | x, y_i, y_{-i}))。生成《永別了,武器》(A Farewell to Arms)時,文檔 1 的後驗概率較高;生成《太陽照常升起》(The Sun Also Rises)時,文檔 2 的後驗概率較高。
(注:原圖展示了生成每個token時,不同文檔的後驗概率分佈,顏色越深表示依賴度越高)
2.3 訓練策略:端到端優化,兼顧效率與性能
論文的訓練設計是RAG能落地的關鍵——既要讓檢索器和生成器“協同工作”,又要控制訓練成本。核心策略如下:
2.3.1 優化目標:負邊際對數似然
訓練的核心目標是最小化“生成目標序列y的負邊際對數似然”,公式為:
L
−
∑
(
x
,
y
)
∈
D
l
o
g
p
(
y
∣
x
)
\mathcal{L} = -\sum_{(x,y) \in \mathcal{D}} log , p(y|x)
L=−(x,y)∈D∑logp(y∣x)
其中
p
(
y
∣
x
)
p(y|x)
p(y∣x)是RAG模型的邊際概率(RAG-Sequence或RAG-Token的概率公式)。這一目標能讓檢索器“學會找對生成有用的文檔”,生成器“學會用檢索文檔生成正確文本”,實現端到端協同優化。
2.3.2 參數凍結:降低訓練成本
論文發現,更新文檔編碼器 B E R T d BERT_d BERTd需要重新構建2100萬文檔的索引(單次索引構建需數小時),且對性能提升有限。因此訓練時僅微調兩個組件:
- 查詢編碼器 B E R T q BERT_q BERTq(110M參數):讓檢索器適配具體任務(如QA、事實核查);
- BART生成器(406M參數):讓生成器學會融合檢索文檔。
- 固定組件:文檔編碼器 B E R T d BERT_d BERTd、FAISS索引——這讓訓練成本降低了80%,且實驗證明性能無損失。
2.3.3 訓練細節:工程優化保障
- 框架與硬件:使用Fairseq框架訓練,支持混合精度計算(FP16),分佈式訓練在8塊32GB NVIDIA V100 GPU上進行,單任務訓練週期約7天;
- 檢索文檔數量:訓練時K=5~10(根據任務調整),測試時可動態調整(如QA任務K=50,生成任務K=10);
- 數據處理:對多答案數據集(如Natural Questions),將每個(x,a)對單獨作為訓練樣本,提升模型對不同答案的適配性。
2.4 關鍵組件的“通俗比喻”:服務員+廚師+菜單庫
為了讓非技術讀者理解,我們用“餐廳服務”比喻RAG的三個核心組件:
| RAG組件 | 餐廳角色 | 核心工作 | 對應能力 |
|---|---|---|---|
| 檢索器DPR | 智能服務員 | 接收顧客需求(查詢x),從菜單庫(知識庫)中挑出最匹配的Top-K菜品(文檔z) | 快速精準找“有用資料”,不推薦無關內容 |
| 生成器BART | 資深廚師 | 結合顧客需求(x)和推薦菜品(z),做出符合口味的菜(輸出y) | 整合知識生成連貫、準確的文本 |
| 知識庫(FAISS索引) | 菜單庫 | 存儲所有菜品的詳細信息(2100萬文檔向量),支持快速查詢 | 可隨時更新(換菜單),無需重新培訓服務員和廚師 |
- 比如顧客問“推薦一道海明威風格的菜”(查詢x=“介紹海明威的代表作”):
- 服務員DPR從菜單庫(維基百科)中挑出“《太陽照常升起》”“《永別了,武器》”兩道菜(Top-2文檔);
- 廚師BART結合“介紹代表作”的需求和兩道菜的信息,做出“海明威的代表作包括《太陽照常升起》(1926年出版,‘迷惘的一代’代表作)和《永別了,武器》(基於其戰爭經歷創作)”的答案(y);
- 若菜單庫更新(新增海明威未出版作品),只需換菜單(更新FAISS索引),無需重新培訓服務員和廚師(模型參數不變)。
三、實驗驗證:RAG在“知識考試”中全面超越SOTA
論文在4類知識密集型任務、7個數據集上進行了全面驗證,核心結論是:RAG在所有任務中均超越純參數化模型和傳統檢索-生成模型,成為當時的SOTA。下面我們詳細拆解實驗設計和關鍵結果:
3.1 實驗任務與數據集
論文選擇的任務覆蓋了知識密集型NLP的核心場景,數據集均為行業公認的基準:
| 任務類型 | 數據集 | 任務描述 | 評估指標 |
|---|---|---|---|
| 開放域問答 | Natural Questions(NQ) | 開放域事實性問答,需從維基百科找答案 | Exact Match(EM)、F1 |
| 開放域問答 | WebQuestions(WQ) | 基於Freebase的開放域問答,問題更口語化 | EM |
| 開放域問答 | CuratedTrec(CT) | 基於TREC數據集的問答,答案多為實體 | EM |
| 開放域問答 | TriviaQA(TQA) | 大規模 trivia 問答,需跨文檔整合知識 | EM |
| 抽象問答生成 | MS-MARCO NLG | 生成完整句子回答問題,部分問題需非維基知識 | Bleu-1、Rouge-L |
| 問題生成 | Jeopardy QGen | 給定實體/事實,生成Jeopardy風格的問題(需高事實性和特異性) | Q-BLEU-1、人類評估(事實性、特異性) |
| 事實核查 | FEVER | 判斷claim是否被維基百科支持/反駁/信息不足 | 分類準確率 |
3.2 核心實驗結果:RAG全面領先
3.2.1 開放域問答:小參數超越大模型
表1(論文核心結果)顯示,RAG在4個QA數據集上均超越SOTA:
| 模型 | NQ(EM) | TQA(EM) | WQ(EM) | CT(EM) | 參數規模 |
|---|---|---|---|---|---|
| 純參數化模型(閉卷) | |||||
| T5-11B | 34.5 | 36.6 | -/60.5 | -/50.1 | 110億 |
| T5-11B+SSM | 37.4 | 44.7 | -/- | -/- | 110億 |
| 傳統檢索-生成(開卷) | |||||
| REALM | 40.4 | 57.9 | 40.7 | 46.8 | 230億 |
| DPR(抽取式) | 41.5 | - | 41.1 | 50.6 | 220M+索引 |
| RAG變體 | |||||
| RAG-Token | 44.1 | 55.2/66.1 | 45.5 | 52.2 | 626M+索引 |
| RAG-Sequence | 44.5 | 56.8/68.0 | 45.2 | 50.0 | 626M+索引 |
- 關鍵結論:
- RAG僅用626M可訓練參數(約為T5-11B的1/17),EM分超T5-11B 10個百分點,證明“參數化+非參數化記憶”的效率優勢;
- 即使正確答案不在任何檢索文檔中,RAG仍能達到11.8%的EM分(依賴參數化記憶補全),而抽取式模型(如DPR)得分為0;
- RAG-Sequence在短答案QA中更優(“一查到底”效率高),RAG-Token在複雜QA中更靈活。
3.2.2 抽象問答生成:更少幻覺,更準答案
MS-MARCO任務中,RAG-Sequence的表現如下:
| 模型 | Bleu-1 | Rouge-L | 事實錯誤率 |
|---|---|---|---|
| BART-large(基線) | 41.6 | 40.1 | 32.7% |
| RAG-Sequence | 44.2 | 42.7 | 22.1% |
| SOTA(用黃金文檔) | 49.8 | 49.9 | - |
- 關鍵結論:
- 即使不使用任務提供的“黃金文檔”(僅用維基百科索引),RAG仍超BART基線2.6 Bleu-1分,且事實錯誤率降低32.4%;
- 示例對比(表3):BART生成“中耳是耳朵和鼻子之間的部分”(錯誤),RAG生成“中耳包括鼓室和三塊聽小骨”(準確)——證明檢索能有效抑制幻覺。
3.2.3 Jeopardy問題生成:更事實、更具體
人類評估結果(表4)顯示,RAG在事實性和特異性上全面領先BART:
| 評估維度 | BART更好 | RAG更好 | 兩者都好 | 兩者都差 |
|---|---|---|---|---|
| 事實性(452對樣本) | 7.1% | 42.7% | 11.7% | 17.7% |
| 特異性(452對樣本) | 16.8% | 37.4% | 11.8% | 6.9% |
- 關鍵案例:
- 輸入“華盛頓”,BART生成“這個州有美國最多的縣”(錯誤),RAG生成“它是唯一以美國總統命名的州”(準確且具體);
- 輸入“《神曲》”,BART生成“但丁的史詩分為《地獄》《煉獄》《煉獄》(重複錯誤)”,RAG生成“這部14世紀作品分為《地獄》《煉獄》《天堂》三部分”(準確)。
3.2.4 事實核查:無需檢索監督,接近SOTA
FEVER任務中,RAG無需人工標註“證據文檔”(僅用claim訓練),表現如下:
| 任務類型 | 模型 | 準確率 | SOTA(需檢索監督) |
|---|---|---|---|
| 3分類(支持/反駁/信息不足) | RAG | 72.5% | 76.8% |
| 2分類(支持/反駁) | RAG | 89.5% | 92.2% |
- 關鍵結論:
- RAG的檢索器能自動找到相關證據——Top-1檢索文檔來自“黃金證據文章”的比例達71%,Top-10達90%;
- 無需檢索監督(即不用告訴模型“該查哪篇文檔”),仍能接近SOTA流水線模型,證明其通用性。
3.3 ablation實驗:驗證核心組件的必要性
論文通過 ablation 實驗(控制變量法)驗證了各組件的作用:
3.3.1 檢索器的重要性
| 模型 | NQ(EM) | TQA(EM) | FEVER-3(準確率) |
|---|---|---|---|
| RAG-Token(完整) | 43.5 | 54.8 | 74.5% |
| RAG-Token(凍結檢索器) | 37.8 | 50.1 | 72.9% |
| RAG-Token(用BM25替代DPR) | 29.7 | 41.5 | 75.1% |
- 結論:
- 微調檢索器能提升性能(NQ EM+5.7分),證明端到端優化的價值;
- DPR(稠密檢索)在QA任務中遠優於BM25(詞重疊檢索),但FEVER任務中BM25表現相當(因FEVER claim以實體為核心,詞重疊足夠有效)。
3.3.2 知識庫熱替換的有效性
論文用2016年維基百科索引(舊知識)和2018年索引(新知識)測試“世界領導人查詢”(82個問題):
| 索引-查詢匹配 | 準確率 |
|---|---|
| 2016索引→2016領導人 | 70% |
| 2018索引→2018領導人 | 68% |
| 2018索引→2016領導人 | 12% |
| 2016索引→2018領導人 | 4% |
- 結論:僅替換索引(無需重訓模型)就能更新知識,且準確率與“知識時效性匹配度”高度相關——證明RAG的知識更新能力。
3.3.3檢索文檔數量K的影響
- QA任務中,RAG-Sequence的EM分隨K增加單調上升(K=50時達最優),RAG-Token在K=10時達最優(K過大引入噪聲);
- 生成任務中,K=10時Rouge-L最高,Bleu-1略有下降(多樣性提升)。
圖 3:左圖:隨著檢索文檔數量的增加,NQ 數據集上的模型性能變化;中圖:NQ 數據集上的檢索召回性能;右圖:隨著檢索文檔數量的增加,MS-MARCO 數據集上的 Bleu-1 和 Rouge-L 指標變化。
四、RAG的核心優勢與行業影響
4.1 解決大模型四大痛點的“獨門秘籍”
| 大模型痛點 | RAG的解決方案 | 技術原理 |
|---|---|---|
| 知識難更新 | 知識庫熱替換 | 非參數化索引可直接替換,無需重訓模型 |
| 缺乏溯源性 | 檢索文檔可追溯 | 生成答案時可附帶“參考文檔”,用戶可驗證 |
| 易產生幻覺 | 檢索知識約束生成 | 生成器必須基於真實文檔,減少無依據編造 |
| 存儲效率低 | 非參數化記憶擴容 | 知識庫可無限擴展,模型參數無需增加 |
4.2 對行業的深遠影響
這篇論文發表後,RAG迅速成為NLP領域的“標配技術”,其影響體現在三個層面:
4.2.1 學術層面:開啟“檢索增強生成”研究熱潮
- 後續研究:REALM(檢索增強預訓練)、Retro(檢索增強語言模型)、HybridQA(多源檢索增強)等均基於RAG的“混合記憶”思路;
- 研究方向擴展:多模態RAG(檢索圖片/視頻)、多步RAG(迭代檢索優化)、低資源RAG(小數據集適配)等成為熱門方向。
4.2.1 工業層面:降低大模型落地門檻
- 成本優化:無需訓練100B+參數的大模型,用“小模型+RAG”就能實現高精度知識密集型任務,硬件成本降低90%;
- 應用落地:ChatGPT插件、Google Gemini實時搜索、Anthropic Claude引用來源、企業私有知識庫問答(如醫療、法律)等,本質都是RAG的工業實現;
- 合規性提升:可追溯的知識來源讓AI在金融、醫療等監管嚴格的領域落地成為可能。
4.2.3技術層面:統一“檢索”與“生成”的框架
- 此前檢索和生成是兩個獨立任務(檢索器負責找文檔,生成器負責寫答案),RAG首次實現端到端協同訓練,讓“找文檔”和“寫答案”高度適配;
- 通用性強:僅需調整輸入輸出格式,就能適配QA、生成、分類、核查等多種任務,無需為每個任務設計專用架構。
4.3 未來展望:RAG的進化方向
論文在討論部分提出了三個值得探索的方向,如今已成為行業研究熱點:
- 聯合預訓練:將檢索能力融入模型預訓練階段(而非僅微調),讓模型天生具備“檢索習慣”;
- 多模態檢索增強:檢索對象從文本擴展到圖片、視頻、表格等,支撐多模態生成任務;
- 智能檢索策略:讓模型學會“多步檢索”(如先檢索粗文檔,再從文檔中檢索關鍵句子)、“查詢優化”(自動修正模糊查詢),提升檢索精度。
五、總結:RAG為何能成為“大模型標配”?
這篇論文的核心貢獻,是將“檢索+生成”從“分離流程”升級為“端到端框架”,用“小參數模型+外掛知識庫”的模式,完美解決了純參數化大模型的知識痛點。RAG的成功並非依賴複雜的模型設計,而是抓住了一個核心洞察:人類解決知識密集型任務時,會“先查資料再輸出”,AI也應該如此。
如今,RAG已從論文中的“學術模型”變成工業界的“必備技術”——它不僅降低了大模型的落地成本,更讓AI的知識變得“可更新、可追溯、可信賴”。對於開發者而言,理解RAG的原理,就能搭建出更高效、更可靠的AI系統;對於普通用戶而言,瞭解RAG,就能明白為什麼現在的AI能“知其然,也知其所以然”。
未來,隨著多模態、多步檢索、聯合預訓練等技術的發展,RAG將進一步進化——讓AI從“能查資料”變成“會查資料”,從“被動接收知識”變成“主動探索知識”,最終成為更強大、更可信的智能助手。
AI Top Papers (5): RAG — Retrieval-Augmented Generation
DPR;Waiter picks Top-K dishes (docs);BART;Chef cooks answer from order + dishes;FAISS index;Menu library—swap without retraining staff
Captured at (local ISO): 2026-05-18 05:17:06
Series Preface
Part 5 covers 《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》 (2020)—still heavily cited.
This post explains why modern LLMs can cite sources, avoid some hallucinations, and absorb 2025 policies without full retraining—often via RAG.
1. Background: LLM knowledge limits
Pretrained LMs (GPT-2, BART, T5) store knowledge in parameters. On knowledge-intensive tasks (open QA, fact checking, professional writing) pure parametric models hit four walls:
1.1 Expensive updates
After training, knowledge is static. Updating facts (new Nobel laureates, policies) needs full retraining—thousands of GPU-hours, catastrophic forgetting risk. Impractical at scale.
1.1 Explainability
No provenance: if the model says “Scotland uses the euro,” you cannot audit why.
1.3 Hallucination
Plausible but false text—e.g. BART defining the middle ear as “between ear and nose.” Humans look up facts first; RAG mirrors that.
1.4 Parameter inefficiency
T5-11B scores 34.5 EM on NQ; RAG with ~626M trainable params reaches 44.5 EM—“small model + external memory” beats “huge parametric memory.”
Hybrid memory: parametric (skills) + non-parametric (searchable corpus). RAG unifies retrieval and generation end-to-end across QA, generation, classification, and verification.
2. RAG design
2.1 Architecture: retriever + generator + index
Figure 1: Query → MIPS Top-K docs (z_i) → seq2seq generator marginalizes over (z) for answer (y).
2.1.1 Non-parametric memory
- Corpus: Dec 2018 English Wikipedia dump;
- Chunks: 100-word non-overlapping passages (~21M docs) for precision and BERT length limits;
- Index: FAISS dense vectors (768-d) with HNSW; ~100 GB raw, ~36 GB compressed; millisecond Top-K over 21M.
2.1.2 Retriever: DPR
Dual BERT encoders:
- (BERT_d): document vectors (fixed at index time);
- (BERT_q): query vectors (fine-tuned per task).
Score: (p_\eta(z|x) \propto \exp(d(z)^\top q(x))) via MIPS.
Initialized from pretrained DPR (TriviaQA/NQ)—strong out of the box.
2.1.3 Generator: BART-large (406M)
Chosen over T5 for denoising pretraining and flexible “query [SEP] doc” inputs. Input: (x) + Top-K passages; autoregressive decode for answer/generation/labels.
2.2 Variants
RAG-Sequence
One document set for the whole output; marginalize over Top-K:
(p_{RAG-Sequence}(y|x) \approx \sum_{z \in top-K} p_\eta(z|x) \prod_i p_\theta(y_i|x,z,y_{1:i-1}))
Thorough decoding: beam search per doc, weight by (p_\eta).
RAG-Token
Per-token document mixture:
(p_{RAG-Token}(y|x) \approx \prod_i \sum_{z \in top-K} p_\eta(z|x) p_\theta(y_i|x,z,y_{1:i-1}))
Good when different tokens need different evidence (e.g. Jeopardy clues).
2.3 Training
- Loss: negative log marginal likelihood (\mathcal{L} = -\sum_{(x,y)} \log p(y|x));
- Freeze (BERT_d) and rebuild index only if needed; train (BERT_q) + BART (~80% cost cut);
- Fairseq, FP16, 8×V100, ~7 days; training (K=5)–10.
2.4 Restaurant analogy
| Component | Role |
|---|---|
| DPR | Waiter picks Top-K dishes (docs) |
| BART | Chef cooks answer from order + dishes |
| FAISS index | Menu library—swap without retraining staff |
3. Experiments
3.1 Tasks
NQ, WebQuestions, CuratedTrec, TriviaQA; MS-MARCO NLG; Jeopardy QGen; FEVER—standard benchmarks.
3.2 Results (highlights)
Open QA (EM): RAG-Sequence 44.5 NQ vs T5-11B 34.5; beats REALM/DPR with far fewer trainable params. Still 11.8% EM when answer not in retrieved docs (parametric fallback).
MS-MARCO: RAG Bleu-1 44.2 vs BART 41.6; fact error rate 22.1% vs 32.7% (middle-ear example fixed).
Jeopardy: human eval—RAG wins factuality/specificity vs BART.
FEVER: 72.5% 3-way without retrieval supervision; Top-1 gold article 71%, Top-10 90%.
3.3 Ablations
- Fine-tuning retriever: +5.7 NQ EM vs frozen;
- DPR ≫ BM25 on QA; BM25 competitive on entity-heavy FEVER;
- Index hot-swap: 2016 vs 2018 leader QA tracks index year (~70% vs ~4% when mismatched);
- Optimal K: QA likes larger K for Sequence; Token peaks ~10.
4. Impact
| Pain | RAG fix |
|---|---|
| Stale knowledge | Replace FAISS index |
| No citations | Return retrieved passages |
| Hallucination | Ground generation in docs |
| Param inefficiency | Scale corpus, not all weights |
Academia: REALM, Retro, HybridQA, multimodal/multi-hop RAG.
Industry: plugins, live search, enterprise KB QA—traceable, cheaper than 100B+ retrain.
Future (from paper): joint pretraining with retrieval; multimodal indexes; learned multi-hop search.
5. Summary
RAG’s insight: look up, then generate—like humans on knowledge tasks. It made retrieval+generation one trainable system, enabling updatable, citeable, more factual LLM apps at lower parameter cost. Understanding RAG is baseline literacy for building reliable knowledge apps today.