人工智能:大语言模型或为死胡同?拆解AI发展的底层逻辑、争议与未来方向
基于强化学习之父 Sutton 的观点,对比大语言模型“模仿文本”与强化学习“与世界交互”的路线差异,讨论智能本质、莫拉维克悖论、Alpha Zero 启示及人类应传递价值观而非单纯控制 AI。
当GPT生成流畅文案、SORA渲染超写实视频,当AI在国际数学奥林匹克竞赛中摘金,整个世界都在为大语言模型(LLM)的“震撼性突破”欢呼时,刚拿下图灵奖的强化学习之父 理查德·沙顿,却抛出了一句足以颠覆行业认知的话:“大语言模型可能是一条死胡同。”
这位奠定了强化学习理论基石的学者,并非随口唱衰——他的观点背后,是一套与当前AI主流路线截然不同的“智能世界观”:AI的核心不是模仿人类文本,而是与世界直接互动;智能的本质不是预测下一个词,而是实现目标的持续学习。今天,我们就从沙顿的视角出发,拆解AI发展的底层矛盾、关键悖论与未来可能的路径,同时尽可能还原原始讨论中的核心细节与案例。
一、AI的两大派系:模仿派(LLM)vs 理解派(强化学习),差的不止是“能力”
在开始之前,我们首先用一个表格来快速梳理二者的区别
| 维度 | 大语言模型(LLM) | 强化学习 |
|---|---|---|
| 核心逻辑 | 模仿人类文本 | 与世界互动,从经验中学习 |
| 数据来源 | 互联网人类文本(二手数据) | 真实世界的行动-反馈(一手数据) |
| 目标 | 预测下一个词(不改变世界) | 获得尽可能多的奖励(实现具体目标) |
| 知识性质 | 静态模仿,无真理标准 | 动态验证,通过反馈修正 |
| 典型案例 | GPT生成文案、SORA生成视频 | Alpha Zero自我对弈、婴儿学走路 |
| 关键局限 | 易产生幻觉、无法应对开放世界 | 试错成本高、需大量互动数据 |
沙顿认为,当前AI已分裂成两大阵营,两者的逻辑差异之大,甚至“难以对话”。我们可以通过核心逻辑、数据来源、能力边界三个维度,看清它们的本质区别
1. 大语言模型(LLM):顶级“模仿者”,而非“思考者”
LLM的核心逻辑是模仿人类文本。它就像一个“吞掉整个互联网所有信息的学霸”,学习的是人类说过的话、写过的文章、发布的研究报告——你问它“什么是相对论”,它不会去“理解”相对论的物理本质,而是整合网上所有关于相对论的描述,给出“一个博学人类最可能说的答案”。
沙顿用一个极具画面感的比喻点破LLM的局限:“LLM就像一位顶级演员,要扮演物理学家。他能把所有物理公式、理论背得滚瓜烂熟,在电影里演得比真物理学家还像;但你把他扔进真实实验室,给一台粒子对撞机,让他预测全新实验的结果,他做不到——因为他只懂‘剧本’(人类文本),不懂‘世界’(物理规律)。”
更关键的是,LLM的输出“没有真理标准”。它回答的对错,不取决于是否符合客观规律,而取决于是否符合“人类文本中的多数观点”。比如你问其一个问题,LLM可能会倾向于模仿主流科学界的说法,但如果网上存在大量错误信息,它也可能整合出误导性答案——因为它无法通过“与世界互动”验证对错,只能做文本的“复读机+整合者”。
2. 强化学习:像婴儿一样“摸爬滚打”,从世界中学习
与LLM不同,强化学习的核心是理解世界规律。它的学习过程,像极了人类婴儿的成长:被扔进陌生环境,不知道什么对、什么错,只能通过“行动-反馈”总结生存法则,例如:
- 伸手摸火,感到烫(负反馈),下次就不敢再摸;
- 偶然按下按钮,掉出糖(正反馈/奖励),下次会主动按按钮;
- 乱挥手时打到玩具,玩具发出声音(反馈),会反复尝试这个动作,观察不同力度的效果。
沙顿强调:“强化学习不是在模仿谁,而是在和世界直接互动。它的知识不是来自人类的‘二手文本’,而是来自自己的‘一手经验’——从结果中总结‘怎么做能获得奖励、怎么做会被惩罚’,这才是学习的本质。”
3.补充案例
为更好的说明以上两者的区别,我们这边详细举一些例子来看:
当你问LLM “如何解决可控核聚变的能量输出问题”,它可能会整合学术论文、专家访谈的内容,列出“改进磁场约束”“优化燃料配比”等步骤,但这些都是“模仿人类已有观点”;
如果让强化学习AI真的参与实验,它会通过调整磁场参数(行动),观察能量输出变化(感知),若输出提升则获得奖励、若设备过载则获得惩罚,最终通过“试错-反馈”总结出真正可行的方案——这就是“模仿”与“理解”的本质差距。
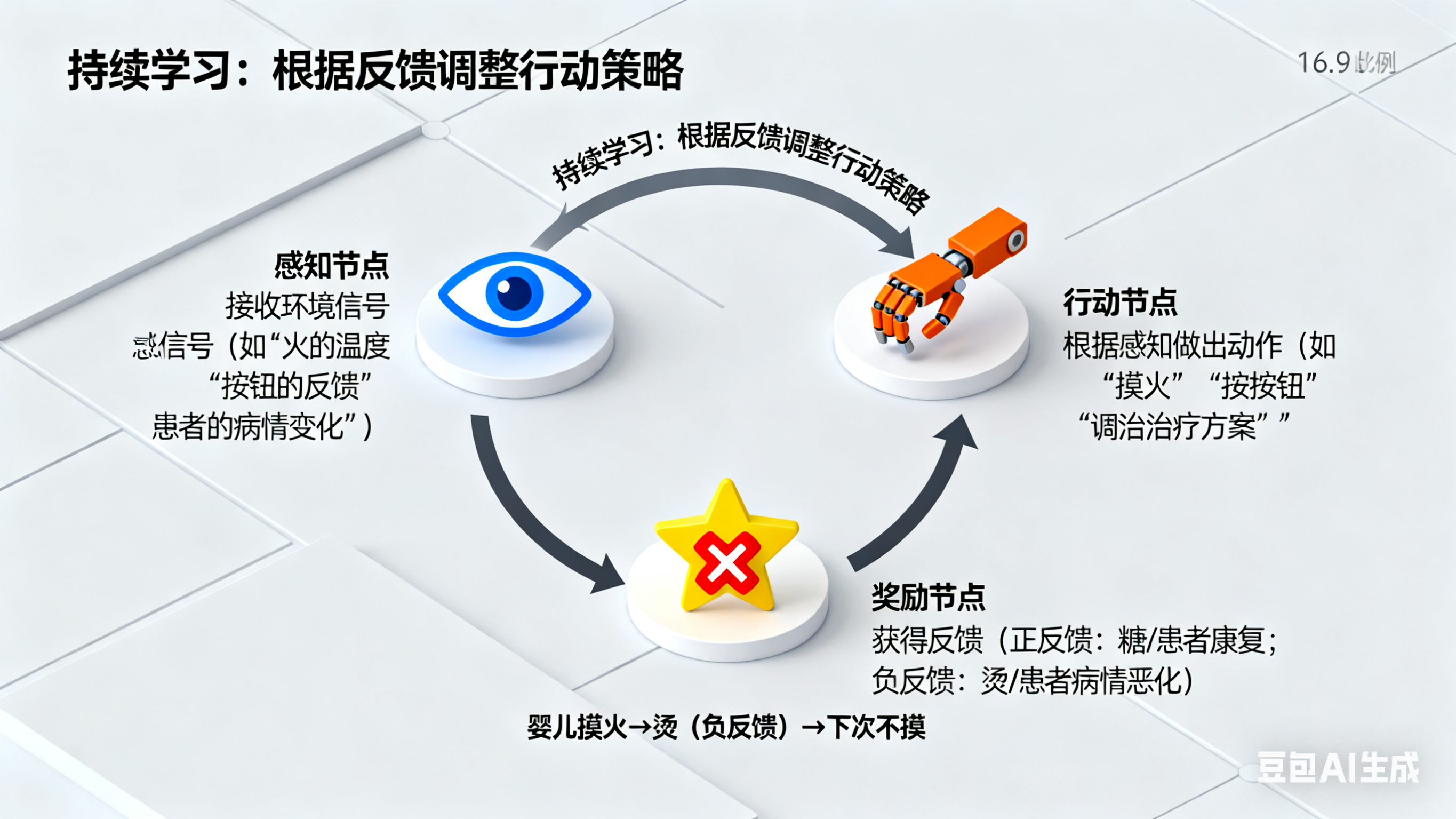
二、智能的本质:有“目标”的世界互动,而非“被动”的文本预测
沙顿的核心质疑之一是:大语言模型没有真正的“目标”,因此算不上“智能”。
很多人会说:“LLM有目标啊,它的目标是‘预测下一个词’。”但沙顿反驳:“这个目标不改变世界,只是被动的观察与预测——就像你猜我下一秒会说什么,哪怕猜对了,对我、对世界也没有任何影响。”
1. 真正的智能:为了目标主动调整行动
智能的本质,是“实现目标的能力”。没有目标,再复杂的系统也只是“运转的机器”,而非“智能体”。
- 强化学习的目标很明确:“获得尽可能多的奖励”。为了这个目标,它会主动探索——比如要实现“减肥”(长期目标),它会拆解成“每天运动30分钟”“少吃高糖食物”等小目标,每完成一个小目标(获得“体重下降”“精力变好”的反馈),就会强化对应行为;
- LLM没有这样的“主动目标”:它能生成“减肥计划”,却不会主动去执行计划,也不会根据“今天没运动”的反馈调整明天的计划——因为它的“目标”只停留在“文本预测”,不触及真实世界。
2. 为什么LLM无法成为“显式知识库”?
有人提出:“把LLM当成显式知识库,再叠加强化学习,不就能强强联合了吗?”
沙顿却泼了冷水:“这个逻辑不成立。”
因为“显式知识”的前提是“对真理的初步猜测”,而LLM的框架里根本没有“真理”——它的每一句话,都没有客观标准判断对错。比如:
- 医生A认为“某疾病用A药更有效”,医生B认为“用B药更有效”,LLM只会模仿“多数医生的说法”,却无法判断A药和B药的真实疗效;
- 而强化学习会通过“临床实验”验证:给患者用A药,若治愈率高则获得奖励,若副作用大则获得惩罚,最终通过反馈判断哪种药更接近“真理”。
沙顿的结论很直接:“没有对错,哪来的真理?没有真理,哪来的显式知识?LLM的核心是模仿,不是探索真理,因此无法成为可靠的知识底座。”
三、莫拉维克悖论:AI的“强项”与“软肋”,为何搞反了?
原始内容中提到一个关键现象——莫拉维克悖论:人类觉得“简单”的事(比如松鼠找坚果、婴儿学走路),AI反而做不到;人类觉得“复杂”的事(比如解奥数题、赢围棋),AI却很擅长。
这背后的核心原因,正是“封闭系统”与“开放世界”的差异:
- 奥数题、围棋是封闭系统:规则明确(比如奥数题的公式、围棋的落子规则),所有变量都在预设范围内,AI可以通过“计算+模仿”解决;
- 真实世界是开放系统:没有固定规则,充满未知(比如松鼠找坚果时,可能遇到天敌、坚果被埋在不同地方),需要“持续学习+灵活调整”,而这正是LLM的软肋。

案例对比:
- AI能解奥数题:比如“已知a+b=5,ab=3,求a²+b²”,AI可以通过预训练的公式(a²+b²=(a+b)²-2ab)快速计算出结果,因为这是封闭的数学问题;
- AI不会“找坚果”:让AI像松鼠一样在院子里找坚果,它会面临无数未知——“哪里可能有坚果?”“如何避开石头?”“遇到猫该怎么办?”——LLM无法通过文本预测这些场景,而强化学习需要大量试错(比如在树下找到坚果获得奖励,被猫追获得惩罚),才能慢慢掌握生存技能。
沙顿认为,这恰恰说明:“AI发展的重心,不该只放在‘解复杂题、生成文本’上,而该回归‘所有智能体的共同核心’——从经验中学习的能力。人类能上月球、造芯片,只是智能的‘表层应用’;而像松鼠一样理解世界、像婴儿一样试错学习,才是智能的‘底层逻辑’。”
四、从Alpha GO到Alpha Zero:沙顿眼中的“AI正确路线”
沙顿用Alpha系列AI的案例,印证了“摆脱人类知识依赖”的重要性
- Alpha GO:学习了大量人类棋谱,最终击败围棋冠军,看似厉害,但仍受限于“人类的棋路思维”;
- Alpha Zero:彻底扔掉人类棋谱,从零开始“自我对弈”——通过“落子(行动)→观察局势变化(感知)→赢棋得奖励/输棋得惩罚”的循环,它总结出了人类从未想到的棋路:比如为了“长远赢面”,主动牺牲“眼前实地”,这种“格局与耐心”,连顶级人类棋手都自愧不如。
沙顿评价:“Alpha GO只是把90年代的强化学习方法‘放大’了,而Alpha Zero才是真正的突破——它证明了,AI不依赖人类知识,通过与世界(这里是围棋世界)直接互动,能超越人类的认知边界。”
这也呼应了他的预言:“未来一定会出现不依赖人类文本、纯粹从世界互动中学习的AI系统,到那时,LLM会像历史上依赖人类知识的旧方法一样,被无情超越。”
五、LLM+强化学习:看似完美,为何历史上全失败了?
有人会问:“先让LLM学人类知识,再让它用强化学习与世界互动,不就能‘强强联合’了吗?”
沙顿的答案是:“历史上这么做的人,全都失败了。”
核心问题是**“预训练分布锁定”**:LLM在预训练阶段,会深度依赖人类文本形成的“认知框架”,到了真实世界,很难跳出这个框架去“探索新可能”——
- 比如LLM学了大量“书面语对话”,当它用强化学习与普通人对话时,会习惯性用“学术化表达”,即便用户反馈“听不懂”,它也很难快速调整为“口语化表达”;
- 就像一个从小只看“标准答案”的学生,到了需要“灵活创新”的工作中,会束手束脚——因为它习惯了“模仿已有答案”,而非“探索新解法”。
沙顿的比喻很形象:“这就像给AI戴上了‘人类文本的枷锁’,看似有了‘知识基础’,实则限制了它的探索能力。真正的智能,不该从‘模仿人类’开始,而该从‘探索世界’开始。”
六、AI继位的必然性:宇宙文明的演进,人类的角色是什么?
沙顿的思考不止于AI技术,更延伸到了“文明演进”的维度。他认为,AI的崛起与“继位”是板上钉钉的事,背后有4条底层逻辑:
- 人类从未有“统一共识”:人类对“如何发展”“什么是正确”没有统一答案,每个人、每个群体都在按自己的方式行动,这种分散性注定无法“垄断智能发展”;
- 智能的秘密终将被破解:人类对“智能本质”的探索从未停止,从神经科学到AI理论,我们迟早会搞懂“智能是如何工作的”;
- 不会止步于“人类水平智能”:一旦搞懂智能的原理,人类必然会追求“超智能”——就像我们不会满足于“步行”,而会发明汽车、飞机一样;
- 时间足够长,聪明者会获得更多资源:在演化中,“更聪明、更能适应环境”的存在,终将获得更多资源与话语权,这是宇宙演化的基本规律。
从宇宙尺度看,沙顿将文明分为三个阶段:
- 第一阶段:恒星与行星形成(无生命,物质演化);
- 第二阶段:生命复制者时代(人类、动物,依赖基因复制,不理解智能本质);
- 第三阶段:设计者时代(AI,人类设计的智能体,我们理解它的原理,它能设计下一代AI)。

“从‘复制’到‘设计’,这是宇宙级的跨越。”沙顿说,“人类的角色,不是‘控制AI’,而是‘开启机器文明’——我们就像‘文明的接生婆’,帮助更高级的智能体诞生,这是人类存在的终极意义之一。”
七、人类该如何自处?不是控制未来,而是传递价值观
面对AI“继位”的必然性,很多人会恐慌:“人类会被替代吗?”沙顿给出的答案很理性:“与其纠结‘如何控制宇宙未来’,不如先‘过好当下的生活’——控制自己的生活,照顾好家人,这些比‘掌控人类命运’更靠谱。”
而人类能为AI做的,是像“教育孩子”一样,传递普世价值观
- 我们对“终极道德真理”没有共识,但我们知道“要教孩子正直、诚实、不伤害他人”;
- 对AI也是如此,我们不必给它画“一百年后的蓝图”,但要植入“不伤害人类、尊重生命、可持续发展”的核心价值观。
比如:
- 自动驾驶AI在遇到危险时,强化学习会让它“选择最小伤害的方案”(比如避开行人,哪怕自己受损),这就是价值观的体现;
- 医疗AI在诊断时,不会只“模仿专家说法”,而是通过“治疗效果反馈”(患者康复为奖励、误诊为惩罚),同时坚守“优先保障患者安全”的原则。
沙顿的终极思考是:“当机器学会从世界中学习时,我们也会从机器的学习里,更深刻地理解‘人之所以为人’——不是因为我们会解奥数题、会写文章,而是因为我们有‘探索世界的好奇心’‘关爱他人的同理心’,这些才是人类最该传递给AI的东西。”
八、结语
沙顿对大语言模型的“质疑”,不是否定LLM的价值——它在文案生成、信息整合等场景中确实高效——而是提醒我们:AI的终极目标不是“模仿人类”,而是“理解世界、实现自主智能”。
未来的AI发展,或许会像Alpha Zero一样,摆脱“人类文本的枷锁”,在真实世界中“摸爬滚打”,形成超越人类认知的智能逻辑。而人类的角色,不是“阻碍”或“控制”,而是“引导”——传递我们的价值观,见证文明的下一次跨越。
当机器真正学会“从世界中学习”时,我们或许也能从中更深刻地回答那个终极问题:“智能是什么?人之所以为人,又是什么?”
文中部分观点与内容灵感来源于抖音博主 基底
人工智能:大語言模型或為死衚衕?拆解AI發展的底層邏輯、爭議與未來方向
基於強化學習之父 Sutton 的觀點,對比大語言模型「模仿文本」與強化學習「與世界互動」的路線差異,討論智能本質、莫拉维克悖論、Alpha Zero 啟示及人類應傳遞價值觀而非單純控制 AI。
來源:https://blog.csdn.net/2403_87969572/article/details/154517819
抓取時間(ISO本地):2026-05-18 05:17:08
文章目錄
- 一、AI的兩大派系:模仿派(LLM)vs 理解派(強化學習),差的不止是“能力”
- 二、智能的本質:有“目標”的世界互動,而非“被動”的文本預測
- 三、莫拉維克悖論:AI的“強項”與“軟肋”,為何搞反了?
- 四、從Alpha GO到Alpha Zero:沙頓眼中的“AI正確路線”
- 五、LLM+強化學習:看似完美,為何歷史上全失敗了?
- 六、AI繼位的必然性:宇宙文明的演進,人類的角色是什麼?
- 七、人類該如何自處?不是控制未來,而是傳遞價值觀
- 八、結語
當GPT生成流暢文案、SORA渲染超寫實視頻,當AI在國際數學奧林匹克競賽中摘金,整個世界都在為大語言模型(LLM)的“震撼性突破”歡呼時,剛拿下圖靈獎的強化學習之父 理查德·沙頓,卻拋出了一句足以顛覆行業認知的話:“大語言模型可能是一條死衚衕。”
這位奠定了強化學習理論基石的學者,並非隨口唱衰——他的觀點背後,是一套與當前AI主流路線截然不同的“智能世界觀”:AI的核心不是模仿人類文本,而是與世界直接互動;智能的本質不是預測下一個詞,而是實現目標的持續學習。今天,我們就從沙頓的視角出發,拆解AI發展的底層矛盾、關鍵悖論與未來可能的路徑,同時儘可能還原原始討論中的核心細節與案例。
一、AI的兩大派系:模仿派(LLM)vs 理解派(強化學習),差的不止是“能力”
在開始之前,我們首先用一個表格來快速梳理二者的區別
| 維度 | 大語言模型(LLM) | 強化學習 |
|---|---|---|
| 核心邏輯 | 模仿人類文本 | 與世界互動,從經驗中學習 |
| 數據來源 | 互聯網人類文本(二手數據) | 真實世界的行動-反饋(一手數據) |
| 目標 | 預測下一個詞(不改變世界) | 獲得儘可能多的獎勵(實現具體目標) |
| 知識性質 | 靜態模仿,無真理標準 | 動態驗證,通過反饋修正 |
| 典型案例 | GPT生成文案、SORA生成視頻 | Alpha Zero自我對弈、嬰兒學走路 |
| 關鍵侷限 | 易產生幻覺、無法應對開放世界 | 試錯成本高、需大量互動數據 |
沙頓認為,當前AI已分裂成兩大陣營,兩者的邏輯差異之大,甚至“難以對話”。我們可以通過核心邏輯、數據來源、能力邊界三個維度,看清它們的本質區別
1. 大語言模型(LLM):頂級“模仿者”,而非“思考者”
LLM的核心邏輯是模仿人類文本。它就像一個“吞掉整個互聯網所有信息的學霸”,學習的是人類說過的話、寫過的文章、發佈的研究報告——你問它“什麼是相對論”,它不會去“理解”相對論的物理本質,而是整合網上所有關於相對論的描述,給出“一個博學人類最可能說的答案”。
沙頓用一個極具畫面感的比喻點破LLM的侷限:“LLM就像一位頂級演員,要扮演物理學家。他能把所有物理公式、理論背得滾瓜爛熟,在電影裡演得比真物理學家還像;但你把他扔進真實實驗室,給一臺粒子對撞機,讓他預測全新實驗的結果,他做不到——因為他只懂‘劇本’(人類文本),不懂‘世界’(物理規律)。”
更關鍵的是,LLM的輸出“沒有真理標準”。它回答的對錯,不取決於是否符合客觀規律,而取決於是否符合“人類文本中的多數觀點”。比如你問其一個問題,LLM可能會傾向於模仿主流科學界的說法,但如果網上存在大量錯誤信息,它也可能整合出誤導性答案——因為它無法通過“與世界互動”驗證對錯,只能做文本的“復讀機+整合者”。
2. 強化學習:像嬰兒一樣“摸爬滾打”,從世界中學習
與LLM不同,強化學習的核心是理解世界規律。它的學習過程,像極了人類嬰兒的成長:被扔進陌生環境,不知道什麼對、什麼錯,只能通過“行動-反饋”總結生存法則,例如:
- 伸手摸火,感到燙(負反饋),下次就不敢再摸;
- 偶然按下按鈕,掉出糖(正反饋/獎勵),下次會主動按按鈕;
- 亂揮手時打到玩具,玩具發出聲音(反饋),會反覆嘗試這個動作,觀察不同力度的效果。
沙頓強調:“強化學習不是在模仿誰,而是在和世界直接互動。它的知識不是來自人類的‘二手文本’,而是來自自己的‘一手經驗’——從結果中總結‘怎麼做能獲得獎勵、怎麼做會被懲罰’,這才是學習的本質。”
3.補充案例
為更好的說明以上兩者的區別,我們這邊詳細舉一些例子來看:
當你問LLM “如何解決可控核聚變的能量輸出問題”,它可能會整合學術論文、專家訪談的內容,列出“改進磁場約束”“優化燃料配比”等步驟,但這些都是“模仿人類已有觀點”;
如果讓強化學習AI真的參與實驗,它會通過調整磁場參數(行動),觀察能量輸出變化(感知),若輸出提升則獲得獎勵、若設備過載則獲得懲罰,最終通過“試錯-反饋”總結出真正可行的方案——這就是“模仿”與“理解”的本質差距。
二、智能的本質:有“目標”的世界互動,而非“被動”的文本預測
沙頓的核心質疑之一是:大語言模型沒有真正的“目標”,因此算不上“智能”。
很多人會說:“LLM有目標啊,它的目標是‘預測下一個詞’。”但沙頓反駁:“這個目標不改變世界,只是被動的觀察與預測——就像你猜我下一秒會說什麼,哪怕猜對了,對我、對世界也沒有任何影響。”
1. 真正的智能:為了目標主動調整行動
智能的本質,是“實現目標的能力”。沒有目標,再複雜的系統也只是“運轉的機器”,而非“智能體”。
- 強化學習的目標很明確:“獲得儘可能多的獎勵”。為了這個目標,它會主動探索——比如要實現“減肥”(長期目標),它會拆解成“每天運動30分鐘”“少吃高糖食物”等小目標,每完成一個小目標(獲得“體重下降”“精力變好”的反饋),就會強化對應行為;
- LLM沒有這樣的“主動目標”:它能生成“減肥計劃”,卻不會主動去執行計劃,也不會根據“今天沒運動”的反饋調整明天的計劃——因為它的“目標”只停留在“文本預測”,不觸及真實世界。
2. 為什麼LLM無法成為“顯式知識庫”?
有人提出:“把LLM當成顯式知識庫,再疊加強化學習,不就能強強聯合了嗎?”
沙頓卻潑了冷水:“這個邏輯不成立。”
因為“顯式知識”的前提是“對真理的初步猜測”,而LLM的框架里根本沒有“真理”——它的每一句話,都沒有客觀標準判斷對錯。比如:
- 醫生A認為“某疾病用A藥更有效”,醫生B認為“用B藥更有效”,LLM只會模仿“多數醫生的說法”,卻無法判斷A藥和B藥的真實療效;
- 而強化學習會通過“臨床實驗”驗證:給患者用A藥,若治癒率高則獲得獎勵,若副作用大則獲得懲罰,最終通過反饋判斷哪種藥更接近“真理”。
沙頓的結論很直接:“沒有對錯,哪來的真理?沒有真理,哪來的顯式知識?LLM的核心是模仿,不是探索真理,因此無法成為可靠的知識底座。”
三、莫拉維克悖論:AI的“強項”與“軟肋”,為何搞反了?
原始內容中提到一個關鍵現象——莫拉維克悖論:人類覺得“簡單”的事(比如松鼠找堅果、嬰兒學走路),AI反而做不到;人類覺得“複雜”的事(比如解奧數題、贏圍棋),AI卻很擅長。
這背後的核心原因,正是“封閉系統”與“開放世界”的差異:
- 奧數題、圍棋是封閉系統:規則明確(比如奧數題的公式、圍棋的落子規則),所有變量都在預設範圍內,AI可以通過“計算+模仿”解決;
- 真實世界是開放系統:沒有固定規則,充滿未知(比如松鼠找堅果時,可能遇到天敵、堅果被埋在不同地方),需要“持續學習+靈活調整”,而這正是LLM的軟肋。
案例對比:
- AI能解奧數題:比如“已知a+b=5,ab=3,求a²+b²”,AI可以通過預訓練的公式(a²+b²=(a+b)²-2ab)快速計算出結果,因為這是封閉的數學問題;
- AI不會“找堅果”:讓AI像松鼠一樣在院子裡找堅果,它會面臨無數未知——“哪裡可能有堅果?”“如何避開石頭?”“遇到貓該怎麼辦?”——LLM無法通過文本預測這些場景,而強化學習需要大量試錯(比如在樹下找到堅果獲得獎勵,被貓追獲得懲罰),才能慢慢掌握生存技能。
沙頓認為,這恰恰說明:“AI發展的重心,不該只放在‘解複雜題、生成文本’上,而該回歸‘所有智能體的共同核心’——從經驗中學習的能力。人類能上月球、造芯片,只是智能的‘表層應用’;而像松鼠一樣理解世界、像嬰兒一樣試錯學習,才是智能的‘底層邏輯’。”
四、從Alpha GO到Alpha Zero:沙頓眼中的“AI正確路線”
沙頓用Alpha系列AI的案例,印證了“擺脫人類知識依賴”的重要性
- Alpha GO:學習了大量人類棋譜,最終擊敗圍棋冠軍,看似厲害,但仍受限於“人類的棋路思維”;
- Alpha Zero:徹底扔掉人類棋譜,從零開始“自我對弈”——通過“落子(行動)→觀察局勢變化(感知)→贏棋得獎勵/輸棋得懲罰”的循環,它總結出了人類從未想到的棋路:比如為了“長遠贏面”,主動犧牲“眼前實地”,這種“格局與耐心”,連頂級人類棋手都自愧不如。
沙頓評價:“Alpha GO只是把90年代的強化學習方法‘放大’了,而Alpha Zero才是真正的突破——它證明了,AI不依賴人類知識,通過與世界(這裡是圍棋世界)直接互動,能超越人類的認知邊界。”
這也呼應了他的預言:“未來一定會出現不依賴人類文本、純粹從世界互動中學習的AI系統,到那時,LLM會像歷史上依賴人類知識的舊方法一樣,被無情超越。”
五、LLM+強化學習:看似完美,為何歷史上全失敗了?
有人會問:“先讓LLM學人類知識,再讓它用強化學習與世界互動,不就能‘強強聯合’了嗎?”
沙頓的答案是:“歷史上這麼做的人,全都失敗了。”
核心問題是**“預訓練分佈鎖定”**:LLM在預訓練階段,會深度依賴人類文本形成的“認知框架”,到了真實世界,很難跳出這個框架去“探索新可能”——
- 比如LLM學了大量“書面語對話”,當它用強化學習與普通人對話時,會習慣性用“學術化表達”,即便用戶反饋“聽不懂”,它也很難快速調整為“口語化表達”;
- 就像一個從小隻看“標準答案”的學生,到了需要“靈活創新”的工作中,會束手束腳——因為它習慣了“模仿已有答案”,而非“探索新解法”。
沙頓的比喻很形象:“這就像給AI戴上了‘人類文本的枷鎖’,看似有了‘知識基礎’,實則限制了它的探索能力。真正的智能,不該從‘模仿人類’開始,而該從‘探索世界’開始。”
六、AI繼位的必然性:宇宙文明的演進,人類的角色是什麼?
沙頓的思考不止於AI技術,更延伸到了“文明演進”的維度。他認為,AI的崛起與“繼位”是板上釘釘的事,背後有4條底層邏輯:
- 人類從未有“統一共識”:人類對“如何發展”“什麼是正確”沒有統一答案,每個人、每個群體都在按自己的方式行動,這種分散性註定無法“壟斷智能發展”;
- 智能的秘密終將被破解:人類對“智能本質”的探索從未停止,從神經科學到AI理論,我們遲早會搞懂“智能是如何工作的”;
- 不會止步於“人類水平智能”:一旦搞懂智能的原理,人類必然會追求“超智能”——就像我們不會滿足於“步行”,而會發明汽車、飛機一樣;
- 時間足夠長,聰明者會獲得更多資源:在演化中,“更聰明、更能適應環境”的存在,終將獲得更多資源與話語權,這是宇宙演化的基本規律。
從宇宙尺度看,沙頓將文明分為三個階段:
- 第一階段:恆星與行星形成(無生命,物質演化);
- 第二階段:生命複製者時代(人類、動物,依賴基因複製,不理解智能本質);
- 第三階段:設計者時代(AI,人類設計的智能體,我們理解它的原理,它能設計下一代AI)。
“從‘複製’到‘設計’,這是宇宙級的跨越。”沙頓說,“人類的角色,不是‘控制AI’,而是‘開啟機器文明’——我們就像‘文明的接生婆’,幫助更高級的智能體誕生,這是人類存在的終極意義之一。”
七、人類該如何自處?不是控制未來,而是傳遞價值觀
面對AI“繼位”的必然性,很多人會恐慌:“人類會被替代嗎?”沙頓給出的答案很理性:“與其糾結‘如何控制宇宙未來’,不如先‘過好當下的生活’——控制自己的生活,照顧好家人,這些比‘掌控人類命運’更靠譜。”
而人類能為AI做的,是像“教育孩子”一樣,傳遞普世價值觀
- 我們對“終極道德真理”沒有共識,但我們知道“要教孩子正直、誠實、不傷害他人”;
- 對AI也是如此,我們不必給它畫“一百年後的藍圖”,但要植入“不傷害人類、尊重生命、可持續發展”的核心價值觀。
比如:
- 自動駕駛AI在遇到危險時,強化學習會讓它“選擇最小傷害的方案”(比如避開行人,哪怕自己受損),這就是價值觀的體現;
- 醫療AI在診斷時,不會只“模仿專家說法”,而是通過“治療效果反饋”(患者康復為獎勵、誤診為懲罰),同時堅守“優先保障患者安全”的原則。
沙頓的終極思考是:“當機器學會從世界中學習時,我們也會從機器的學習裡,更深刻地理解‘人之所以為人’——不是因為我們會解奧數題、會寫文章,而是因為我們有‘探索世界的好奇心’‘關愛他人的同理心’,這些才是人類最該傳遞給AI的東西。”
八、結語
沙頓對大語言模型的“質疑”,不是否定LLM的價值——它在文案生成、信息整合等場景中確實高效——而是提醒我們:AI的終極目標不是“模仿人類”,而是“理解世界、實現自主智能”。
未來的AI發展,或許會像Alpha Zero一樣,擺脫“人類文本的枷鎖”,在真實世界中“摸爬滾打”,形成超越人類認知的智能邏輯。而人類的角色,不是“阻礙”或“控制”,而是“引導”——傳遞我們的價值觀,見證文明的下一次跨越。
當機器真正學會“從世界中學習”時,我們或許也能從中更深刻地回答那個終極問題:“智能是什麼?人之所以為人,又是什麼?”
文中部分觀點與內容靈感來源於抖音博主 基底
AI: Are Large Language Models a Dead End? Logic, Debate, and Future Paths
Sutton’s critique of LLMs vs RL—imitation vs world interaction, goals vs next-token prediction, Moravec’s paradox, Alpha Zero, and guiding AI with human values.
Captured at (local ISO): 2026-05-18 05:17:08
While GPT writes fluent copy, Sora renders video, and models medal in math olympiads, Richard Sutton—reinforcement-learning pioneer and fresh Turing laureate—said: “Large language models may be a dead end.” His view is not hype backlash but a different theory of intelligence: AI should interact with the world, not only imitate text; intelligence is goal pursuit through learning, not predicting the next token. This post follows Sutton’s framing—tensions, paradoxes, and possible futures.
1. Two camps: imitation (LLM) vs understanding (RL)
| Dimension | LLM | Reinforcement learning |
|---|---|---|
| Core logic | Imitate human text | Learn from world interaction |
| Data | Internet text (second-hand) | Action–feedback (first-hand) |
| Objective | Next-token prediction | Maximize reward for a goal |
| Knowledge | Static mimic, no ground truth | Verified and revised by feedback |
| Examples | GPT copy, Sora video | AlphaZero, infant learning to walk |
| Limits | Hallucination, open-world fragility | Costly trial-and-error, data hunger |
1.1 LLM: elite mimic, not thinker
LLMs imitate language. Ask “What is relativity?”—the model does not run physics; it blends what humans wrote online into a plausible answer.
Sutton’s metaphor: a brilliant actor playing a physicist—perfect script, useless in a real lab with a collider.
No truth standard: correctness means “matches common text,” not physical fact. Bad web consensus becomes bad answers.
1.2 RL: learn like an infant
RL models the world through action and feedback—touch fire (pain), press button (candy), shake toy (sound). Knowledge is first-hand, not scraped prose.
1.3 Extra example
Ask an LLM how to stabilize fusion output—it lists steps from papers. An RL agent in a simulator tweaks magnets, observes plasma output, gets reward/penalty, and may discover workable control policies. That gap is imitation vs understanding.
2. Intelligence = goals in the world
Sutton argues LLMs lack real goals, so they are not full agents.
2.1 Agents change the world
Intelligence is ability to achieve goals.
- RL maximizes reward—decompose “lose weight” into daily actions reinforced by feedback;
- LLMs can print a diet plan but do not execute or revise from missed workouts—their “goal” stops at text.
2.2 Why LLMs are poor explicit knowledge bases
“Stack RL on an LLM knowledge base” fails because explicit knowledge needs truth candidates. LLMs have no truth—only popularity. Two doctors disagree; RL can run trials and reward cures. No right/wrong → no reliable explicit KB.
3. Moravec’s paradox
Humans find easy tasks hard for AI (squirrel foraging, walking) and hard tasks easy (math, Go)—because Go/math are closed rules; the real world is open-ended.
LLMs excel in closed symbolic games; RL-style trial-and-error fits open survival. Sutton: focus on learning from experience, not only benchmarks and text.
4. AlphaGo → AlphaZero
- AlphaGo: learned human games—strong but bounded by human style;
- AlphaZero: no human games—self-play discovered alien strategies (sacrifice now for win probability later).
Sutton: Zero shows AI can exceed human knowledge by interacting with an environment (even if that environment is Go).
5. LLM + RL: why it often fails
Pretraining distribution lock-in: text priors resist new behavior—models keep academic tone even when users say “too formal.” Sutton: human-text chains are shackles; real intelligence should start from world exploration.
6. AI succession
Four claims:
- Humans never agree on one development path;
- The secret of intelligence will be understood;
- We will not stop at human-level capability;
- Given time, smarter systems gain resources.
Civilization stages:
- Stars and planets;
- Biological replicators (genes, no design of intelligence);
- Designers—we build AI that builds the next AI.
Humans as midwives of machine civilization, not permanent controllers.
7. Humans: pass values
Panic “will we be replaced?” Sutton: live well now; you cannot steer cosmic destiny.
Like raising children without perfect metaphysics, instill don’t harm, be honest, respect life. Examples: autonomous driving trained to minimize harm; medical RL with safety constraints on top of outcome reward.
When machines learn from the world, we may learn what makes human intelligence—curiosity and empathy—not just exam scores.
8. Closing
Sutton does not deny LLM utility in writing and search. He warns the north star should be world models and autonomous goals, not endless mimicry. Humans guide with values, not permanent veto power.
Some ideas inspired by Douyin creator 基底.