机器视觉:智能车大赛视觉组技术文档——第20届智能车比赛视觉组视觉模块多种思路分析
第二十届全国大学生智能汽车竞赛智能视觉组有着较复杂的机器视觉处理与运动控制任务。此前,我们已围绕色块检测、YOLO3 Nano目标检测、eIQ训练分类模型等基础技术展开了初步探讨,这些技术为视觉模块的搭建提供了核心支撑。但结合本届比赛的具体规则——需完成红色立方体定位、15类工程师周边物品分类及0-99手写数字奇偶性判断,且需适配NXP微控制器与指定图像处理模块,单一技术方案难以满足所有场景需求。本文将基于比赛实际约束,深入分析视觉模块的多种实现思路,为参赛队伍提供更具针对性的技术参考。
机器视觉:智能车大赛视觉组技术文档——OpenArt结合OpenMV实现色块检测
机器视觉:智能车大赛视觉组技术文档——用 YOLO3 Nano 实现目标检测并部署到 OpenART
机器视觉:智能车大赛视觉组技术文档——用eIQ工具高效训练分类模型
机器视觉:智能车大赛视觉组技术文档——第20届智能车比赛视觉组视觉模块多种思路分析
前言
第二十届全国大学生智能汽车竞赛智能视觉组有着较复杂的机器视觉处理与运动控制任务。此前,我们已围绕色块检测、YOLO3 Nano目标检测、eIQ训练分类模型等基础技术展开了初步探讨,这些技术为视觉模块的搭建提供了核心支撑。但结合本届比赛的具体规则——需完成红色立方体定位、15类工程师周边物品分类及0-99手写数字奇偶性判断,且需适配NXP微控制器与指定图像处理模块,单一技术方案难以满足所有场景需求。本文将基于比赛实际约束,深入分析视觉模块的多种实现思路,为参赛队伍提供更具针对性的技术参考。
一、定位红色箱子思路
思路一:openart垂直向下/斜向下看定位(yolo目标检测)
这个是从去年的视觉组比赛传承下来的思路,优点是用于目标检测的openart和用于识别分类的openart放在一起,不需要做太多的映射和微调,基本可以实现目标检测的art定位到中心的时候,分类的art也定位到差不多的地方。示意图如下:
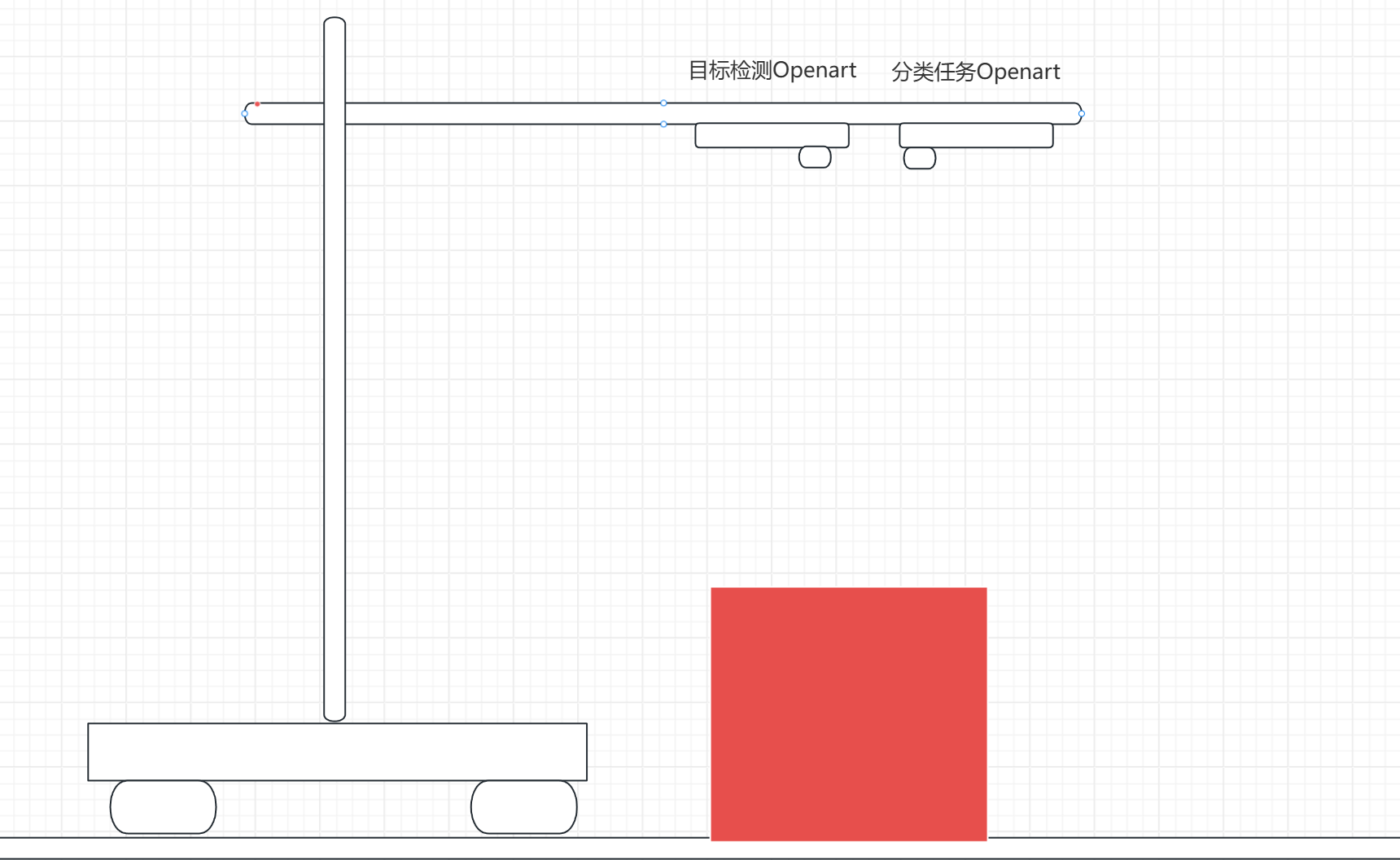
这样的话openart直接返回箱子中心与openart镜头中心的误差给主控进行定位矫正既可,可能由于两个art的位置偏差需要进行中心点的偏移处理
优点:实现简单,只需要处理少量的位置偏移不需要进行映射。
缺点:特征性相对思路二没有那么强,有可能会出现误判的情况。由于openart的性能与yolo模型的限制,整体性能较低,只能跑到15帧
思路二:openart水平向前看定位(yolo目标检测 / 色块检测)
这个是根据今年的视觉组定制的思路,也是逐飞官方给出的思路,将openart放在支撑杆上水平向前看,定位art,将红色块大小数据映射为距离的数据,可以使用yolo3 nano模型也可以使用色块检测,示意图如下:
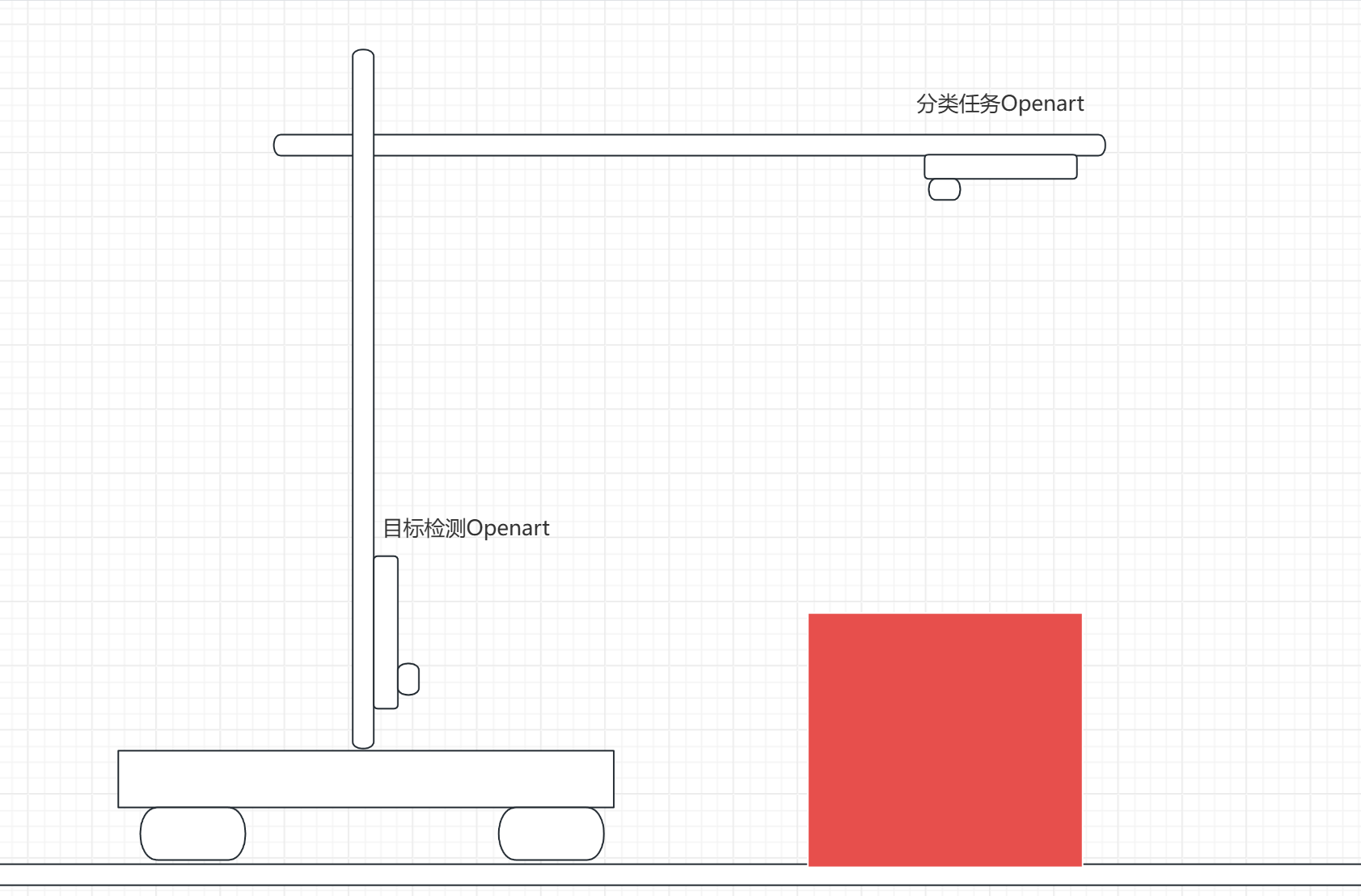
这样的话openart返回箱子中心与检测到的ROI大小给主控进行定位矫正既可。
优点:鲁班性较强,由于箱子的侧面是固定的红色图案,与背景差异明显,所以无论是色块检测还是yolo模型目标检测,都有非常强的鲁班性。并且色块检测的帧率会远超yolo模型,进一步提高性能。并且对于左右便宜的定位非常清晰。
缺点:设置较为复杂,需要处理箱子大小到距离的映射。需要考虑背景中其他的箱子对于定位的影响(设置最小色块阈值)
思路三:传感器融合辅助视觉决策
利用TOF或者超声波传感器辅助箱子前后距离以及左右偏移的矫正,可以大幅度提高定位的精确度。
例如:
1、根据TOF返回的距离参数直接调整距离箱子的前后位置大小。
2、根据返回的距离参数是否有调整左右偏移(可以考虑安装多个TOF)例如左边两个TOF有数据 右边TOF没数据则说明箱子偏左。
二、15类工程师周边物品分类
思路一:eIQ训练15分类模型
其实这个都差不多,特别是在模型选择方面,选取eIQ官方的模型和自己搭模型在准确率上的提高其实是不多的,更多的提升应该是在数据集方面(我们15分类是拍了2-3w张数据集),需要大量的数据集堆砌出一个比较好的分类效果。
具体的训练思路已经在上一篇博客讲过了,可以参考下:
机器视觉:智能车大赛视觉组技术文档——用eIQ工具高效训练分类模型
但是真实情况下如何训练,还是得靠自己慢慢积累经验。
三、0-99手写数字奇偶性判断
思路一:eIQ训练100分类模型
这个就是跟刚才15分类的思路一样了,都是最简单的实现思路,自行准备手写数据集然后拍照片,练模型
优点:实现思路简单,不需要考虑太多逻辑层面的问题就是做数据集练模型
缺点:这个方法实测下来是效果不是特别好(也可能是我数据集或者训练方法的问题),毕竟0-99分类难免会出现误识别的情况,很难训练出效果完美的分类模型。
思路二:十位数字和个位数字分开识别,同样用eIQ训练模型
这个思路也是逐飞官方给出的思路。是从目标检测阶段就训练单个手写数字的目标检测模型,然后再提取ROI的时候提取单个数字的ROI,进而进行分类任务
分类任务不只是对0-9数字进行十分类,还需要考虑数字的正向方向(因为规则里面说到箱子的摆放方向是不固定的,有可能出现角度倾斜0-360度的情况),[0,1,8]这三个数字通常是不考虑正反的,只用分成两类就可以(0度与90度),而剩下的所有数字都需要考虑(0,90,180,270)四种情况,所以按逻辑来说是得进行38分类或者更少的分类(0度的6和180度的9可以归为一类 同理180度的6也可以与0度的9归为一类 90度与270度也是对应的)。
根据识别的结果,即需要参考数字的识别结果,也需要考虑其朝向得到正确的箱子是如何摆的,应该把哪一个数字作为十位数,应该把哪一个数字作为个位数,是否需要考虑6和9倒置之后识别错的情况。
优点:分类数相对较少,并且由于分类中含有角度因素,所以分类的特征性很强,识别准确率会提高非常多,对数据集规模的要求也相对较低。不需要花大量的时间拍99分类数据集
缺点:实现逻辑复杂,需要结合目标检测进行调整。需要花一定的时间梳理逻辑。并且由于角度不固定,当箱子倾斜角为45、135、235、325时候很有可能在提取ROI的时候提取过多边缘区域导致另外一位数字的图像也被纳入ROI导致识别错误
总结
参赛队伍在选择方案时,需充分结合自身技术储备与硬件条件,并且可以对思路进行不同的调整。
例如:上述讲到十位数字和个位数字分开识别的时候,可以结合软件进行以下方案消除0-45度之间的角度误差
视觉端:定位的时候通过矩形检测传回箱子的倾斜角度
软件端:根据倾斜角度调整车正对箱子而非侧45度面对
这样的方案按逻辑来说是可以完美解决另外一位数字的图像也被纳入ROI的问题。但是对软件以及视觉都有更高的要求。所以各位还是自行选择
同时,无论选择哪种思路,都应重视数据增强、抗干扰处理和硬件适配,避免因细节问题导致罚时。
希望本文的思路分析能为参赛队伍提供有益参考,在之后的每一届智能车比赛中取得佳绩
機器視覺:智能車大賽視覺組技術文檔——第20屆智能車比賽視覺組視覺模塊多種思路分析
機器視覺:智能車大賽視覺組技術文檔——OpenArt結合OpenMV實現色塊檢測 機器視覺:智能車大賽視覺組技術文檔——用 YOLO3 Nano 實現目標檢測並部署到 OpenART 機器視覺:智能車大賽視覺組技術文檔——用eIQ工具高效訓練分類模型 機器視覺:智能車大賽視覺組技術文檔——第20屆智能車比賽視覺組視覺模塊多種思路分析
來源:https://blog.csdn.net/2403_87969572/article/details/153589720
抓取時間(ISO本地):2026-05-18 05:17:05
系列文章目錄
機器視覺:智能車大賽視覺組技術文檔——OpenArt結合OpenMV實現色塊檢測
機器視覺:智能車大賽視覺組技術文檔——用 YOLO3 Nano 實現目標檢測並部署到 OpenART
機器視覺:智能車大賽視覺組技術文檔——用eIQ工具高效訓練分類模型
機器視覺:智能車大賽視覺組技術文檔——第20屆智能車比賽視覺組視覺模塊多種思路分析
文章目錄
前言
第二十屆全國大學生智能汽車競賽智能視覺組有著較複雜的機器視覺處理與運動控制任務。此前,我們已圍繞色塊檢測、YOLO3 Nano目標檢測、eIQ訓練分類模型等基礎技術展開了初步探討,這些技術為視覺模塊的搭建提供了核心支撐。但結合本屆比賽的具體規則——需完成紅色立方體定位、15類工程師周邊物品分類及0-99手寫數字奇偶性判斷,且需適配NXP微控制器與指定圖像處理模塊,單一技術方案難以滿足所有場景需求。本文將基於比賽實際約束,深入分析視覺模塊的多種實現思路,為參賽隊伍提供更具針對性的技術參考。
一、定位紅色箱子思路
思路一:openart垂直向下/斜向下看定位(yolo目標檢測)
這個是從去年的視覺組比賽傳承下來的思路,優點是用於目標檢測的openart和用於識別分類的openart放在一起,不需要做太多的映射和微調,基本可以實現目標檢測的art定位到中心的時候,分類的art也定位到差不多的地方。示意圖如下:
這樣的話openart直接返回箱子中心與openart鏡頭中心的誤差給主控進行定位矯正既可,可能由於兩個art的位置偏差需要進行中心點的偏移處理
優點:實現簡單,只需要處理少量的位置偏移不需要進行映射。
缺點:特徵性相對思路二沒有那麼強,有可能會出現誤判的情況。由於openart的性能與yolo模型的限制,整體性能較低,只能跑到15幀
思路二:openart水平向前看定位(yolo目標檢測 / 色塊檢測)
這個是根據今年的視覺組定製的思路,也是逐飛官方給出的思路,將openart放在支撐杆上水平向前看,定位art,將紅色塊大小數據映射為距離的數據,可以使用yolo3 nano模型也可以使用色塊檢測,示意圖如下:
這樣的話openart返回箱子中心與檢測到的ROI大小給主控進行定位矯正既可。
優點:魯班性較強,由於箱子的側面是固定的紅色圖案,與背景差異明顯,所以無論是色塊檢測還是yolo模型目標檢測,都有非常強的魯班性。並且色塊檢測的幀率會遠超yolo模型,進一步提高性能。並且對於左右便宜的定位非常清晰。
缺點:設置較為複雜,需要處理箱子大小到距離的映射。需要考慮背景中其他的箱子對於定位的影響(設置最小色塊閾值)
思路三:傳感器融合輔助視覺決策
利用TOF或者超聲波傳感器輔助箱子前後距離以及左右偏移的矯正,可以大幅度提高定位的精確度。
例如:
1、根據TOF返回的距離參數直接調整距離箱子的前後位置大小。
2、根據返回的距離參數是否有調整左右偏移(可以考慮安裝多個TOF)例如左邊兩個TOF有數據 右邊TOF沒數據則說明箱子偏左。
二、15類工程師周邊物品分類
思路一:eIQ訓練15分類模型
其實這個都差不多,特別是在模型選擇方面,選取eIQ官方的模型和自己搭模型在準確率上的提高其實是不多的,更多的提升應該是在數據集方面(我們15分類是拍了2-3w張數據集),需要大量的數據集堆砌出一個比較好的分類效果。
具體的訓練思路已經在上一篇博客講過了,可以參考下:
機器視覺:智能車大賽視覺組技術文檔——用eIQ工具高效訓練分類模型
但是真實情況下如何訓練,還是得靠自己慢慢積累經驗。
三、0-99手寫數字奇偶性判斷
思路一:eIQ訓練100分類模型
這個就是跟剛才15分類的思路一樣了,都是最簡單的實現思路,自行準備手寫數據集然後拍照片,練模型
優點:實現思路簡單,不需要考慮太多邏輯層面的問題就是做數據集練模型
缺點:這個方法實測下來是效果不是特別好(也可能是我數據集或者訓練方法的問題),畢竟0-99分類難免會出現誤識別的情況,很難訓練出效果完美的分類模型。
思路二:十位數字和個位數字分開識別,同樣用eIQ訓練模型
這個思路也是逐飛官方給出的思路。是從目標檢測階段就訓練單個手寫數字的目標檢測模型,然後再提取ROI的時候提取單個數字的ROI,進而進行分類任務
分類任務不只是對0-9數字進行十分類,還需要考慮數字的正向方向(因為規則裡面說到箱子的擺放方向是不固定的,有可能出現角度傾斜0-360度的情況),[0,1,8]這三個數字通常是不考慮正反的,只用分成兩類就可以(0度與90度),而剩下的所有數字都需要考慮(0,90,180,270)四種情況,所以按邏輯來說是得進行38分類或者更少的分類(0度的6和180度的9可以歸為一類 同理180度的6也可以與0度的9歸為一類 90度與270度也是對應的)。
根據識別的結果,即需要參考數字的識別結果,也需要考慮其朝向得到正確的箱子是如何擺的,應該把哪一個數字作為十位數,應該把哪一個數字作為個位數,是否需要考慮6和9倒置之後識別錯的情況。
優點:分類數相對較少,並且由於分類中含有角度因素,所以分類的特徵性很強,識別準確率會提高非常多,對數據集規模的要求也相對較低。不需要花大量的時間拍99分類數據集
缺點:實現邏輯複雜,需要結合目標檢測進行調整。需要花一定的時間梳理邏輯。並且由於角度不固定,當箱子傾斜角為45、135、235、325時候很有可能在提取ROI的時候提取過多邊緣區域導致另外一位數字的圖像也被納入ROI導致識別錯誤
總結
參賽隊伍在選擇方案時,需充分結合自身技術儲備與硬件條件,並且可以對思路進行不同的調整。
例如:上述講到十位數字和個位數字分開識別的時候,可以結合軟件進行以下方案消除0-45度之間的角度誤差
視覺端:定位的時候通過矩形檢測傳回箱子的傾斜角度
軟件端:根據傾斜角度調整車正對箱子而非側45度面對
這樣的方案按邏輯來說是可以完美解決另外一位數字的圖像也被納入ROI的問題。但是對軟件以及視覺都有更高的要求。所以各位還是自行選擇
同時,無論選擇哪種思路,都應重視數據增強、抗干擾處理和硬件適配,避免因細節問題導致罰時。
希望本文的思路分析能為參賽隊伍提供有益參考,在之後的每一屆智能車比賽中取得佳績
Smart Car Vision: 20th Competition Vision Module — Multiple Approaches
OpenArt + OpenMV color blob detection YOLOv3 Nano detection on OpenART eIQ classification training This post: multi-approach analysis
Captured at (local ISO): 2026-05-18 05:17:05
Series Index
OpenArt + OpenMV color blob detection
YOLOv3 Nano detection on OpenART
eIQ classification training
This post: multi-approach analysis
Preface
The 20th National Smart Car vision group combines vision and motion control. We already covered blobs, YOLOv3 Nano, and eIQ. This season adds red cube localization, 15 engineer-item classes, and 0–99 digit parity on NXP MCUs and mandated cameras—one technique rarely fits all tasks. Below are practical design options under real rules.
I. Red Cube Localization
Approach 1: OpenART looking down / oblique down (YOLO)
Legacy from last year: detection OpenART and classification OpenART are co-located—minimal mapping; when detection centers the cube, classification is roughly aligned. Return center error vs. lens center; small offset calibration may be needed.
Pros: simple, little mapping. Cons: weaker features vs. forward view; ~15 FPS due to OpenART + YOLO limits.
Approach 2: OpenART forward (YOLO or color blobs)
Official-style mount on a pole, horizontal view. Map red blob size → distance (YOLOv3 Nano or color threshold).
Return center + ROI size for pose correction. Pros: strong contrast (fixed red side pattern), high FPS with blobs, clear left/right. Cons: size→distance calibration; filter other red boxes (min area).
Approach 3: Sensor fusion
TOF/ultrasonic for range and lateral correction—e.g. adjust forward distance from TOF; multiple TOFs infer left/right bias (left sensors see target, right empty → cube is left).
II. 15-Class Engineer Items
Approach 1: eIQ 15-class model
Architecture choice matters less than data—we shot 20k–30k images. Training flow: eIQ classification post. Real-world tuning still takes iteration.
III. 0–99 Digit Parity
Approach 1: eIQ 100-class
Collect handwritten digits, train 100-way classifier. Pros: simple pipeline. Cons: confusion across 100 classes; hard to reach perfect accuracy.
Approach 2: Separate tens and ones (official-style)
Detect single digits, crop per-digit ROI, classify with orientation buckets: [0,1,8] ≈ 2 poses; others need 0/90/180/270 → up to 38 classes (with 6/9 symmetry merges). Fuse detections + orientation to pick tens/ones and handle inverted 6/9. Pros: fewer classes, strong features, less data. Cons: complex logic; at 45° box tilt ROIs may include both digits.
Summary
Pick schemes matching your stack. Example combo: vision returns box tilt; chassis squares to the face to avoid dual-digit ROIs at 45°—harder but cleaner. Always invest in augmentation, robustness, and hardware fit. Good luck in future seasons.