机器视觉:智能车大赛视觉组技术文档——用eIQ工具高效训练分类模型
智能车视觉组用 NXP eIQ 训练 MobileNet_v2 分类模型:数据导入、增强、训练验证、int8 导出部署到 OpenART,附竞赛训练技巧与逐飞资源链接。
机器视觉:智能车大赛视觉组技术文档——OpenArt结合OpenMV实现色块检测
机器视觉:智能车大赛视觉组技术文档——用 YOLO3 Nano 实现目标检测并部署到 OpenART
机器视觉:智能车大赛视觉组技术文档——用eIQ工具高效训练分类模型
机器视觉:智能车大赛视觉组技术文档——第20届智能车比赛视觉组视觉模块多种思路分析
前言
随着智能车竞赛智能视觉组规则的更新,竞赛的核心挑战从赛道行驶转向了更高难度的图像识别任务。从16届仅需识别3大类目、以及后续竞赛要求精准识别15个小类目标不同,本次不止要识别15类小目标,还需要识别1-99手写数字,并且图片方向随机多变,这对模型的泛化能力和训练效率提出了更高要求。
前面我们讲过了色块检测以及yolo3 nano模型目标检测,(也有直接用yolo进行分类的模型,但是主流方案并没有采用这个,而是通过本文所说的eIQ工具进行分类模型的训练对yolo算法得到的目标ROI进行分类任务)
为帮助参赛同学应对这一挑战,NXP联合逐飞科技推出了专为竞赛场景优化的模型训练工具——eIQ,并通过多场技术直播提供指导。相较于NXP官网繁琐的下载流程,逐飞科技已获得授权并提供了便捷的工具包下载渠道,让同学们能够快速上手。本文将基于逐飞科技的官方教程,详细拆解如何使用eIQ工具完成分类模型的全流程训练。
一、基础知识
在开始eIQ工具的实操前,我们需要掌握几个与图像分类训练相关的核心概念,为后续操作奠定基础:
- 训练集与测试集:训练集用于模型的参数学习,测试集用于验证模型的泛化能力,合理的比例分配(可通过eIQ的SHUFFLE功能自动实现)能避免模型过拟合。
- 数据增强:通过对图片进行随机旋转、亮度调整等变换,人为扩充训练数据的多样性,提升模型对实际场景中多变图像的适应能力,这对本次竞赛中方向不确定的图片识别尤为重要。
- 模型量化:将模型参数从高精度(如float32)转换为低精度(如int8),在保证识别精度的前提下,降低模型的存储占用和推理延迟,适配智能车的嵌入式硬件(如OpenART mini)。
- 混淆矩阵:用于直观展示模型的分类效果,矩阵中绿色越深表示分类正确率越高,红色越深表示错误率越高,可快速定位模型的薄弱分类。
- 学习率:控制模型参数更新的步长,过大易导致训练震荡不收敛,过小则训练速度过慢,合理设置学习率是保证训练效果的关键。
二、eIQ介绍
eIQ是NXP推出的一站式AI模型开发工具,专为嵌入式场景设计,尤其适合智能车竞赛这类对硬件适配性要求较高的场景。其核心优势在于:
- 全流程覆盖:集成数据导入、数据增强、模型选择、训练、验证、导出等功能,无需切换多个工具,降低开发门槛。
- 轻量化适配:默认支持MobileNet_v2等轻量级模型,导出的模型可直接适配NXP系列MCU(如RT1064),完美兼容OpenART mini开发板。
- 操作便捷性:提供图形化界面和命令行两种操作方式,支持批量数据导入和自动化训练,大幅提升开发效率。
- 竞赛专属优化:针对本届智能车竞赛的数据集特点,预设了适配的训练参数和数据增强策略,减少同学们的参数调试成本。
此外,逐飞科技为竞赛同学提供了包含eIQ安装包、OpenMV IDE及配套教程的资源包,避免了官网注册下载的繁琐流程,进一步降低了入门难度。
三、eIQ安装
这边先附上逐飞官方的下载地址:
链接:https://pan.baidu.com/s/18-osV8mqPIbZOZpEJLi36w
提取码:idhq
如果链接失效 欢迎私信联系博主发送安装包
以下是官方的图解安装教程,已经写得非常详细这边就不在赘述了:
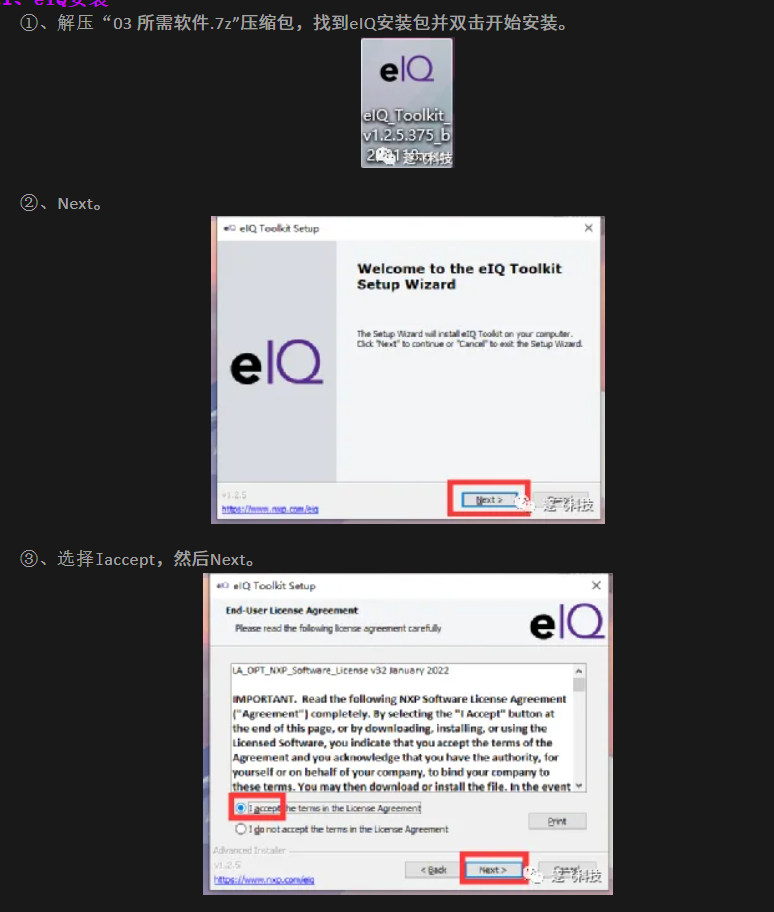
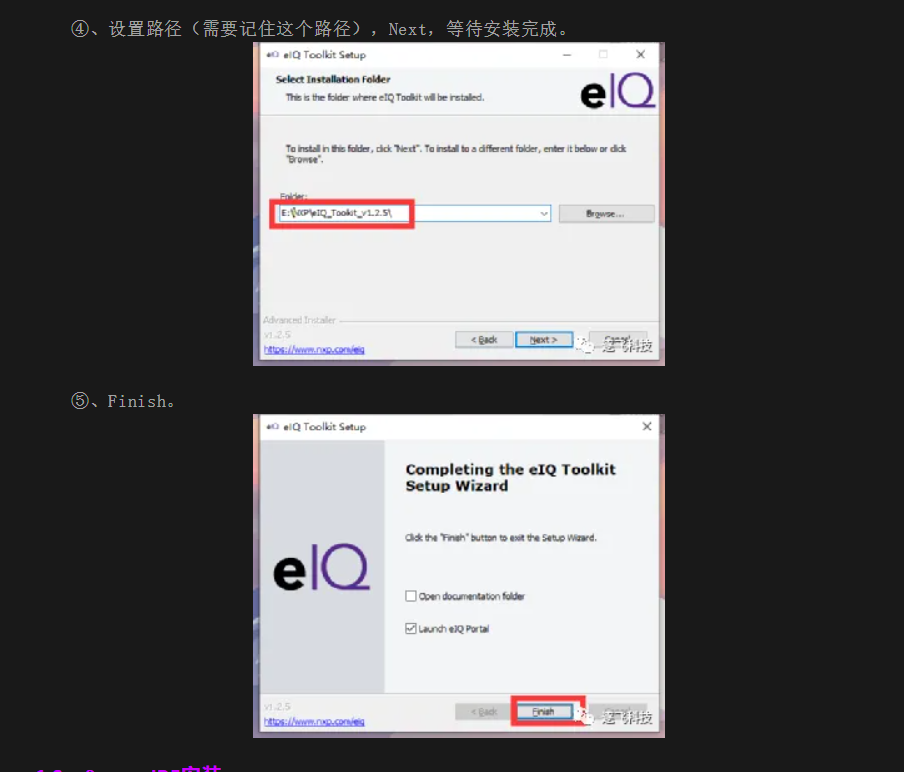
安装完毕之后打开界面如下:
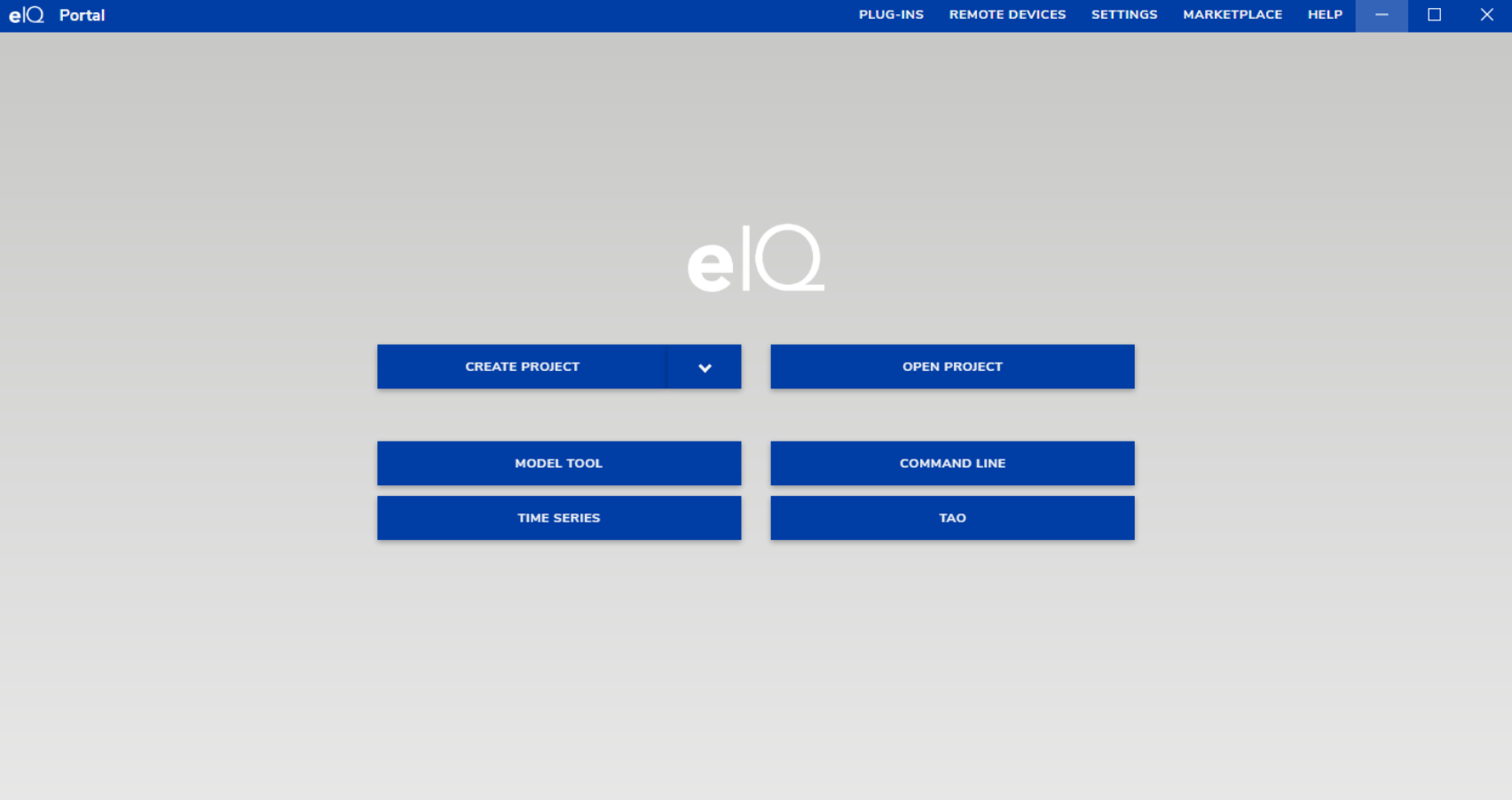
三、模型介绍
智能车竞赛推荐使用的模型为MobileNet_v2,该模型是轻量级卷积神经网络的经典代表,非常适合嵌入式设备的实时图像识别任务,其核心特点如下:
- 参数轻量化:通过深度可分离卷积替代传统卷积,在保证识别精度的同时,大幅减少模型参数数量和计算量,降低硬件资源消耗。
- 推理速度快:精简的网络结构使其在嵌入式MCU上的推理延迟显著降低,能够满足智能车竞赛中实时图像识别的需求。
- 泛化能力强:经过大规模图像数据集预训练,对自然场景中的各类目标具有良好的特征提取能力,适配竞赛中多类别的图像识别任务。
相较于其他复杂模型(如ResNet),MobileNet_v2在嵌入式硬件上的兼容性和运行效率更具优势,是本次竞赛的最优选择之一。
四、训练方法
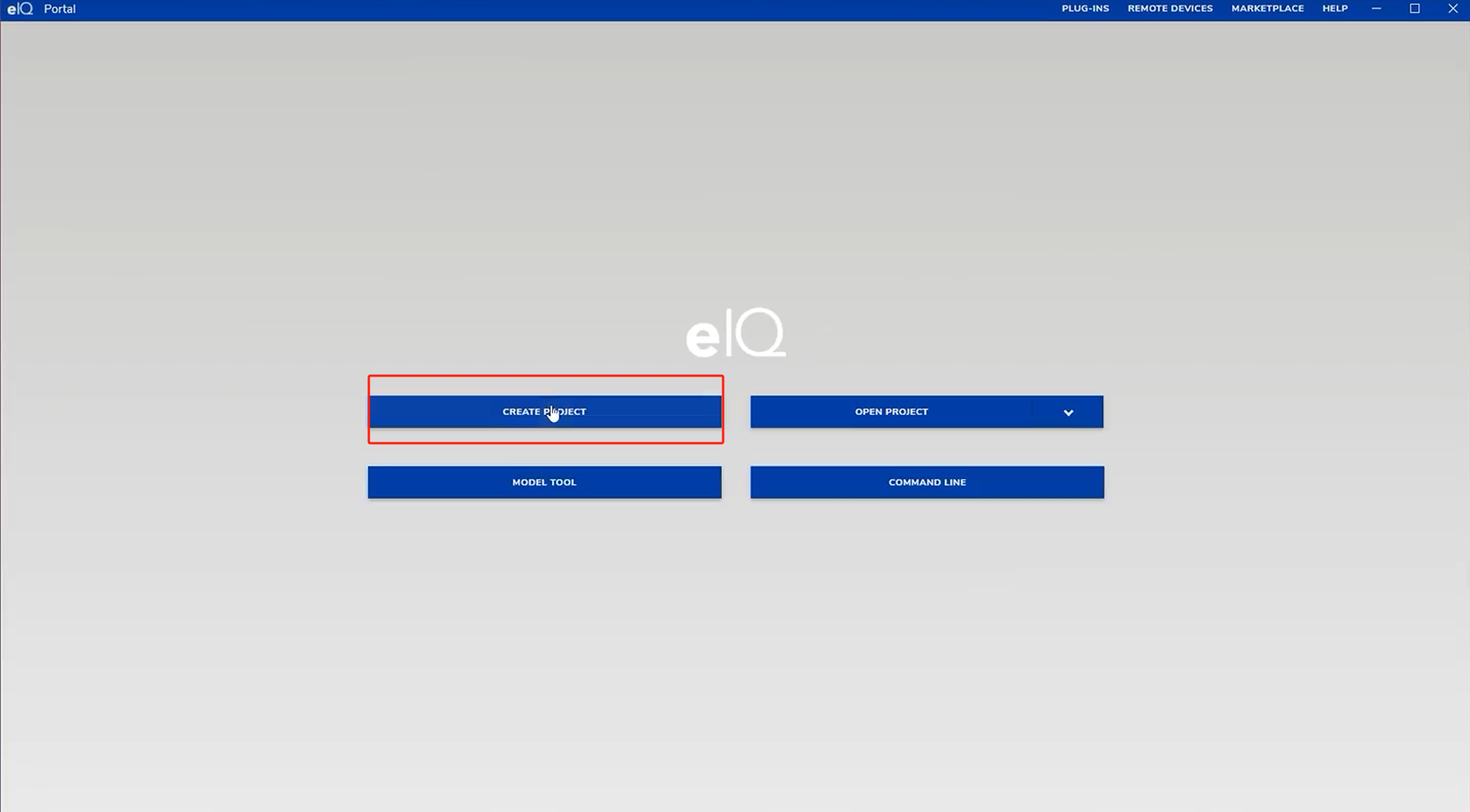
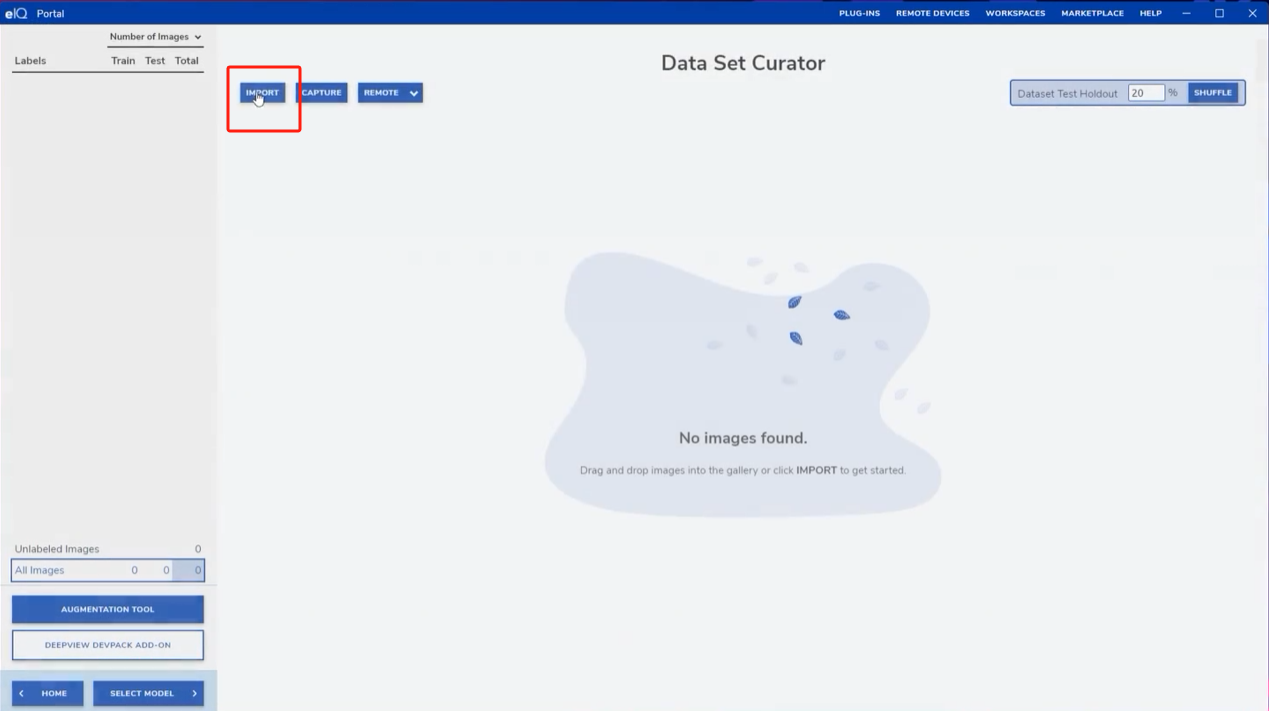
1. 数据导入
- 手动导入:点击CREATE PROJECT创建.eiqp后缀的工程,通过IMPORT功能选择图片并手动添加标签,利用Unlabeled Images分类筛选未标注图片,避免遗漏;也可以直接导入结构化的数据集,就是路径下有按类别分类的文件夹,文件夹里面是用于训练的该类别图片。可通过SHUFFLE功能按比例自动分配训练集与测试集。
3. 数据增强:提升模型泛化能力
点击左下角AUGMENTATION TOOL,可使用默认的增强策略(如随机旋转、亮度调整),也可新建自定义规则,添加多种图像变换方式。通过预览窗口可实时查看增强效果,确认后保存并返回主界面。数据增强能有效应对竞赛中图片方向不确定的问题,让模型在复杂环境下仍保持高识别率。
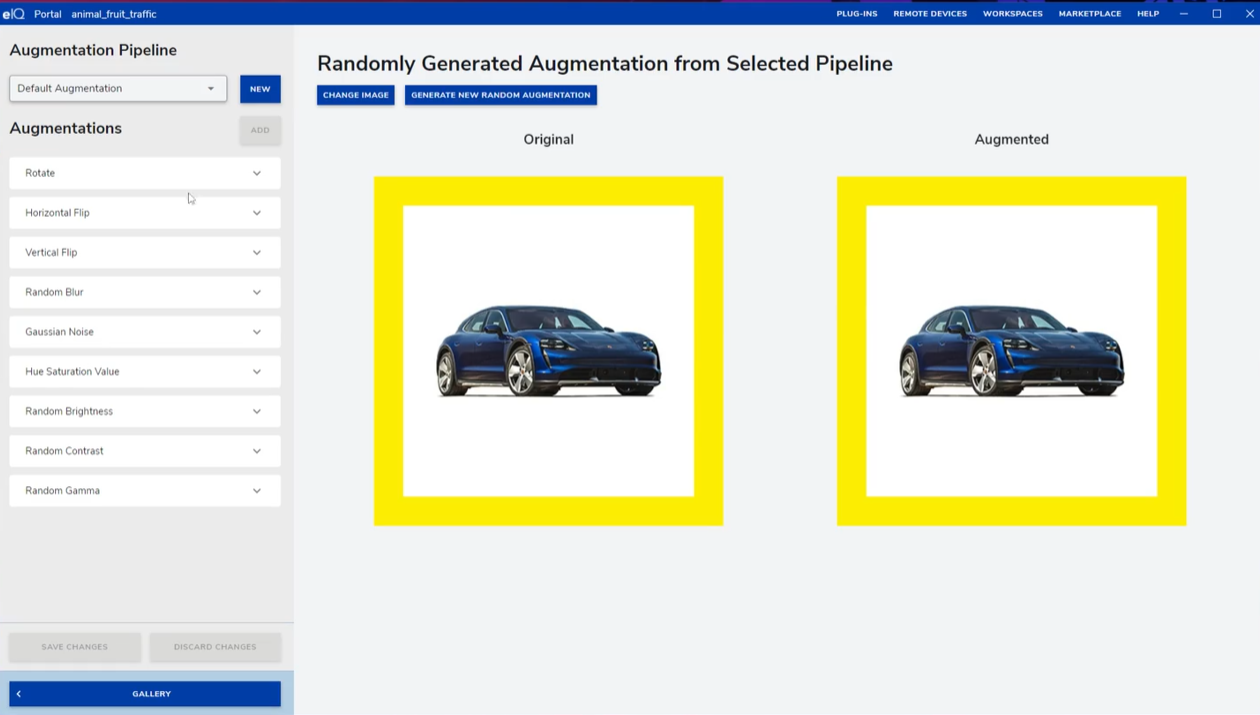
具体如下:
- Rotate(旋转):随机旋转图像,让模型适应不同朝向的目标。
- Horizontal Flip(水平翻转):沿垂直轴镜像翻转图像,增加左右方向的场景多样性。
- Vertical Flip(垂直翻转):沿水平轴镜像翻转图像,补充上下方向的变化场景。
- Random Blur(随机模糊):给图像添加不同程度的模糊,模拟拍摄模糊或运动模糊的场景。
- Gaussian Noise(高斯噪声):添加高斯分布的随机噪声,模拟传感器等引入的噪声干扰。
- Hue Saturation Value(HSV调整):调整色调、饱和度、亮度,适配不同色彩和光照的环境。
- Random Brightness(随机亮度):随机改变图像亮度,让模型适应强光、弱光等光照变化。
- Random Contrast(随机对比度):调整图像对比度,增强模型对不同明暗对比图像的识别。
- Random Gamma(随机伽马校正):非线性调整像素亮度分布,模拟不同设备或光照下的图像表现。
4. 模型选择与参数设置
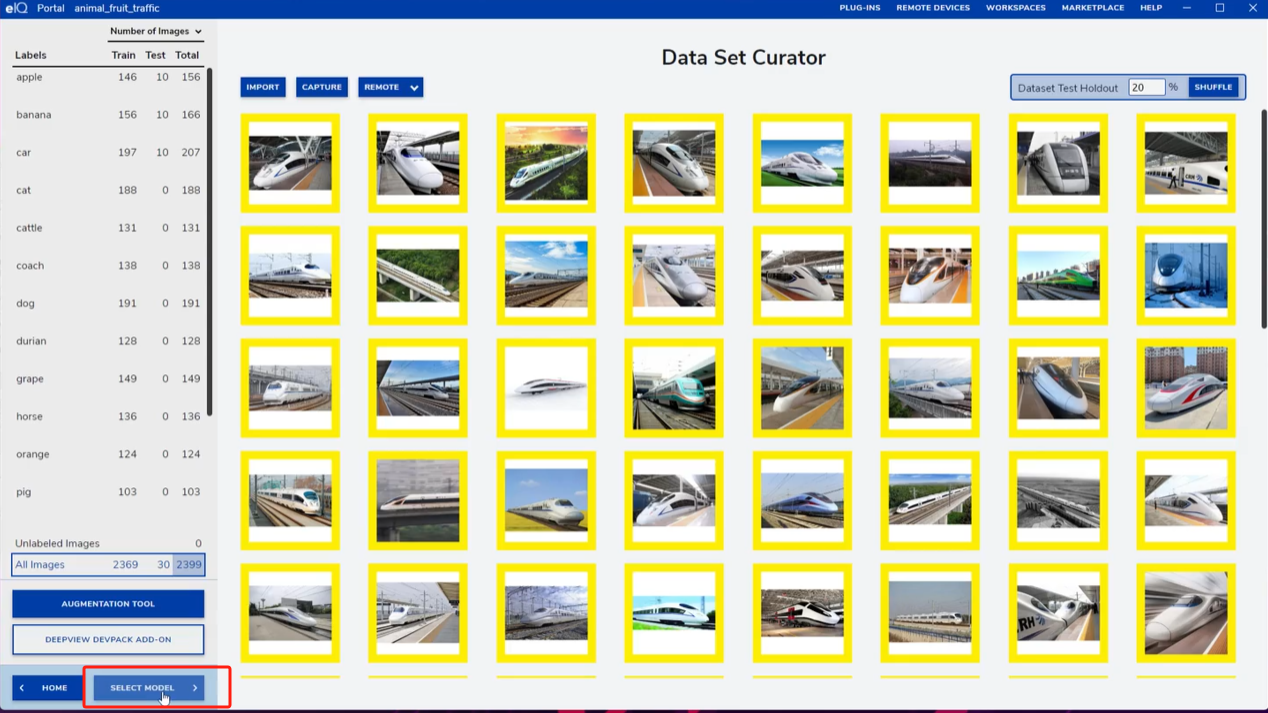
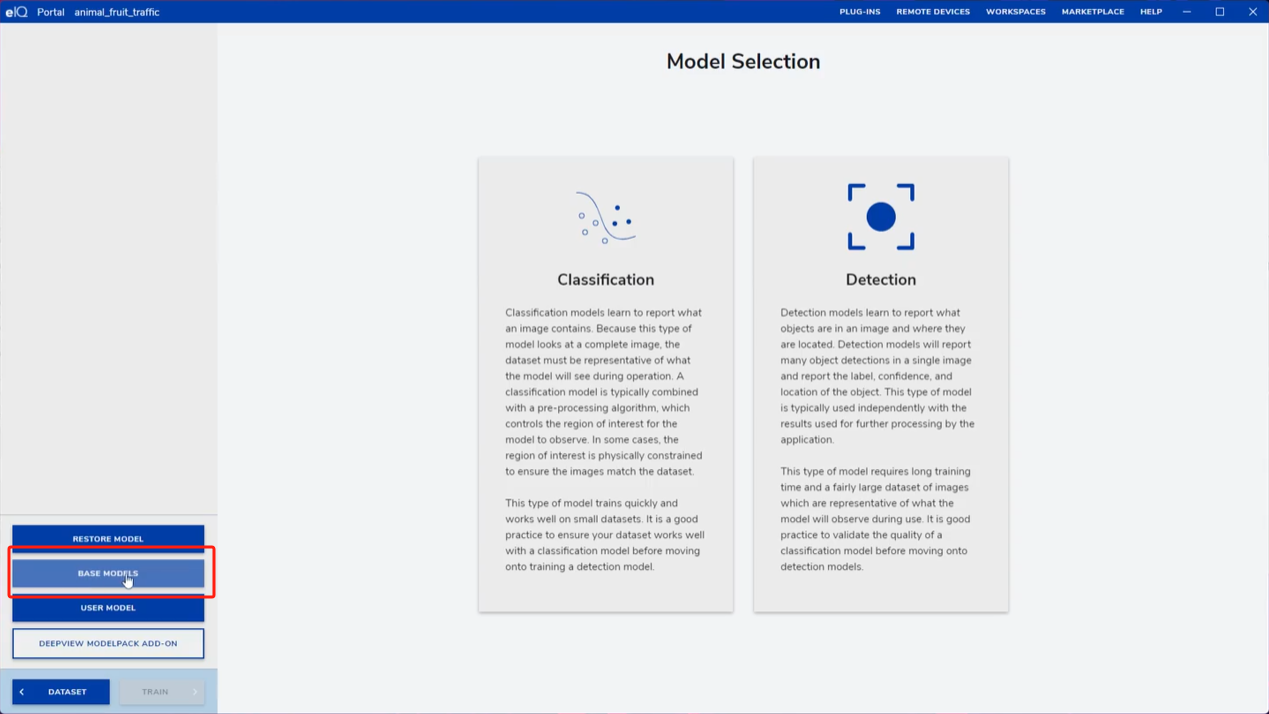
在主页面点击SELECT MODEL,选择MobileNet_v2作为基础模型。
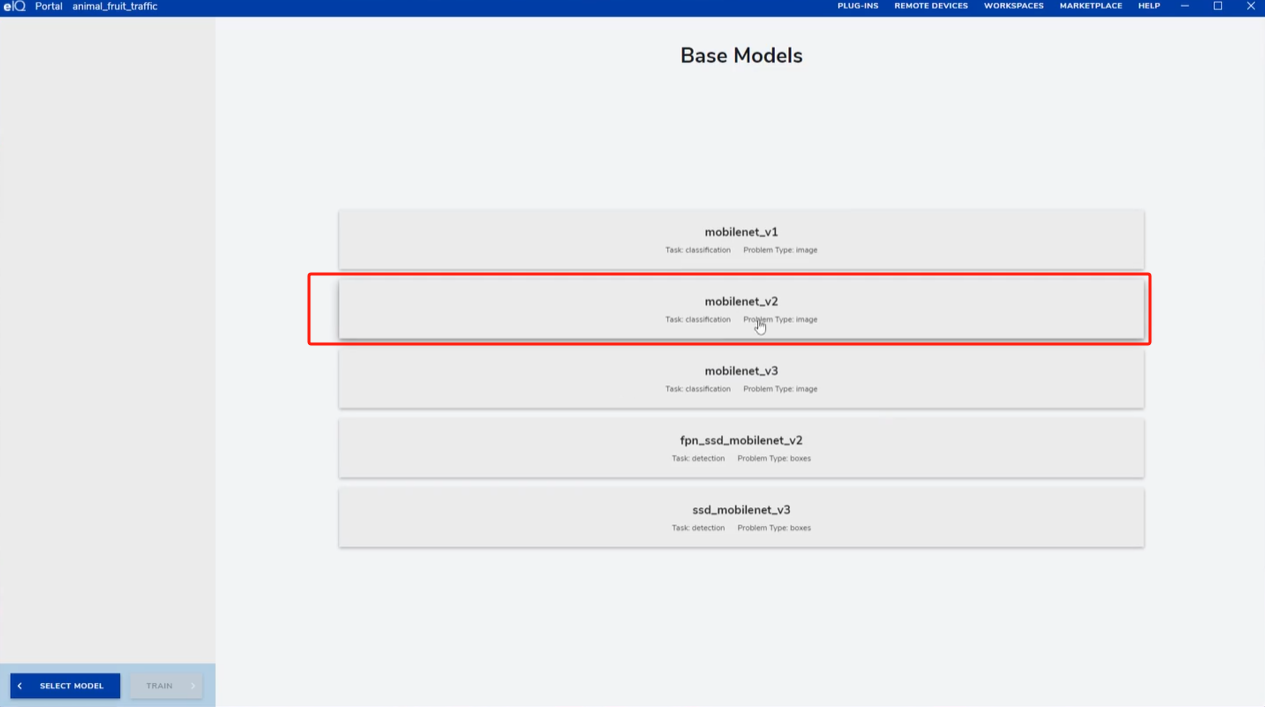
mobilenet_v1(分类模型)
基于深度可分离卷积(将传统卷积拆分为“深度卷积+逐点卷积”),大幅降低参数量与计算量,是轻量级分类模型的奠基之作。支持通过“宽度乘数”灵活调整模型复杂度,适配不同算力的嵌入式设备。mobilenet_v2(分类模型)
在v1基础上升级,核心创新是倒置残差结构和线性瓶颈层:先通过1×1卷积“扩张”通道数,再用深度可分离卷积提取特征,最后以线性1×1卷积“压缩”通道(避免ReLU破坏低维特征信息),在精度与效率间实现更优平衡。mobilenet_v3(分类模型)
结合神经架构搜索(NAS)自动优化网络结构,引入h-swish(平滑版ReLU)和h-sigmoid激活函数,同时加入SE(注意力)模块增强特征选择,进一步提升轻量性与分类性能,是MobileNet系列的最新迭代。fpn_ssd_mobilenet_v2(目标检测模型)
以mobilenet_v2为骨干,融合**FPN(特征金字塔网络)**与SSD(单阶段检测框架):FPN通过多尺度特征融合提升小目标检测能力,SSD则以单阶段流程保证实时性,适合嵌入式设备的实时目标检测任务。ssd_mobilenet_v3(目标检测模型)
采用mobilenet_v3为骨干,结合SSD架构实现多尺度目标检测。继承v3的h-swish激活和SE模块,在检测精度(尤其是小目标)与推理速度间更平衡,适配移动设备、边缘终端等低功耗场景。
这些模型覆盖了“轻量级分类→实时检测”的核心需求,可根据任务类型(分类/检测)和硬件资源选择适配的架构。
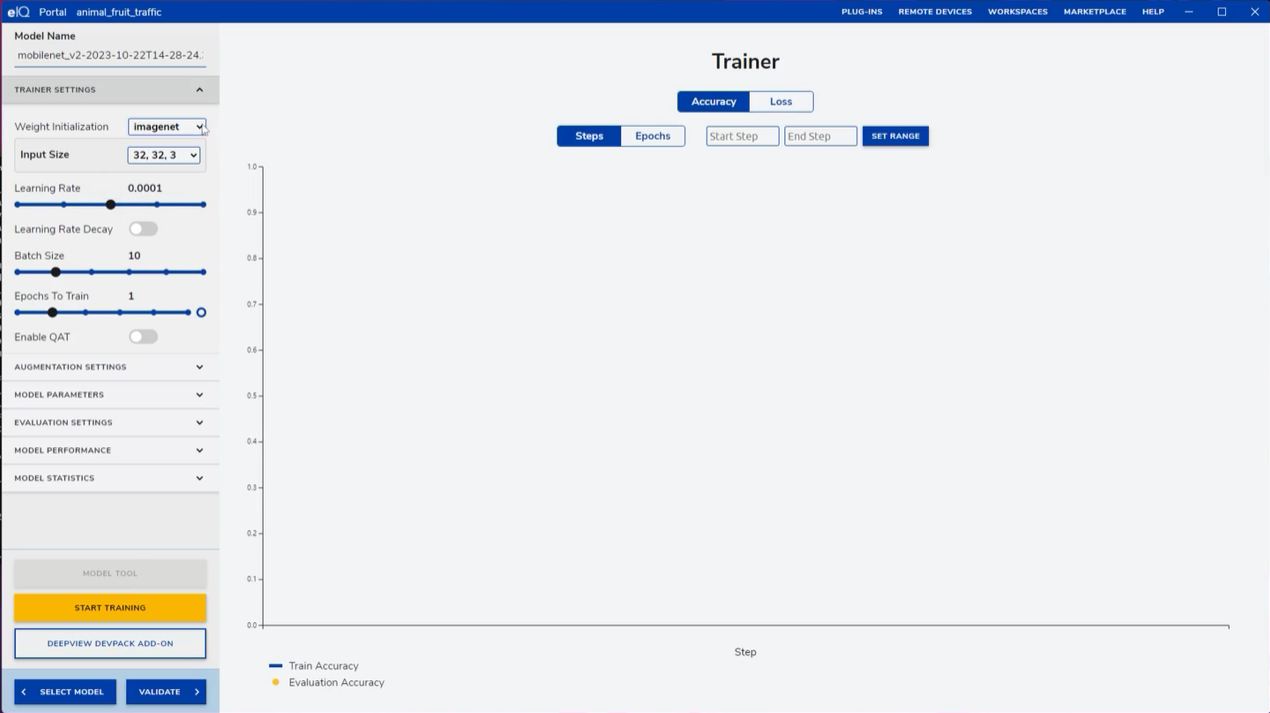
关键参数设置如下(仅为推荐设置,具体设置需要根据数据集和模型以及你的硬件条件来定,需要经验的积累):
- 训练参数:将Epochs To Train设为25,Input Size推荐64*64及以上,Learning Rate保持默认,Batch Size根据硬件性能调整。
- 增强设置:先选择No Augments进行基础训练,再选择Default Augmentation进行二次训练,让模型适应多变的数据特征。
- 验证设置:启用Enable Evaluation,设置每训练若干轮进行一次验证,同时启用可视化功能,实时监控训练效果。
5. 模型训练与监控
点击START TRAINING开始训练,过程中可随时终止,后续支持继续训练。训练过程中可查看训练集与测试集的正确率、损失值变化,通过切换视图(按步数或轮数)分析模型收敛情况。二次训练初期正确率可能下降,属于正常现象,随着训练推进,模型会逐渐适应增强后的数据。
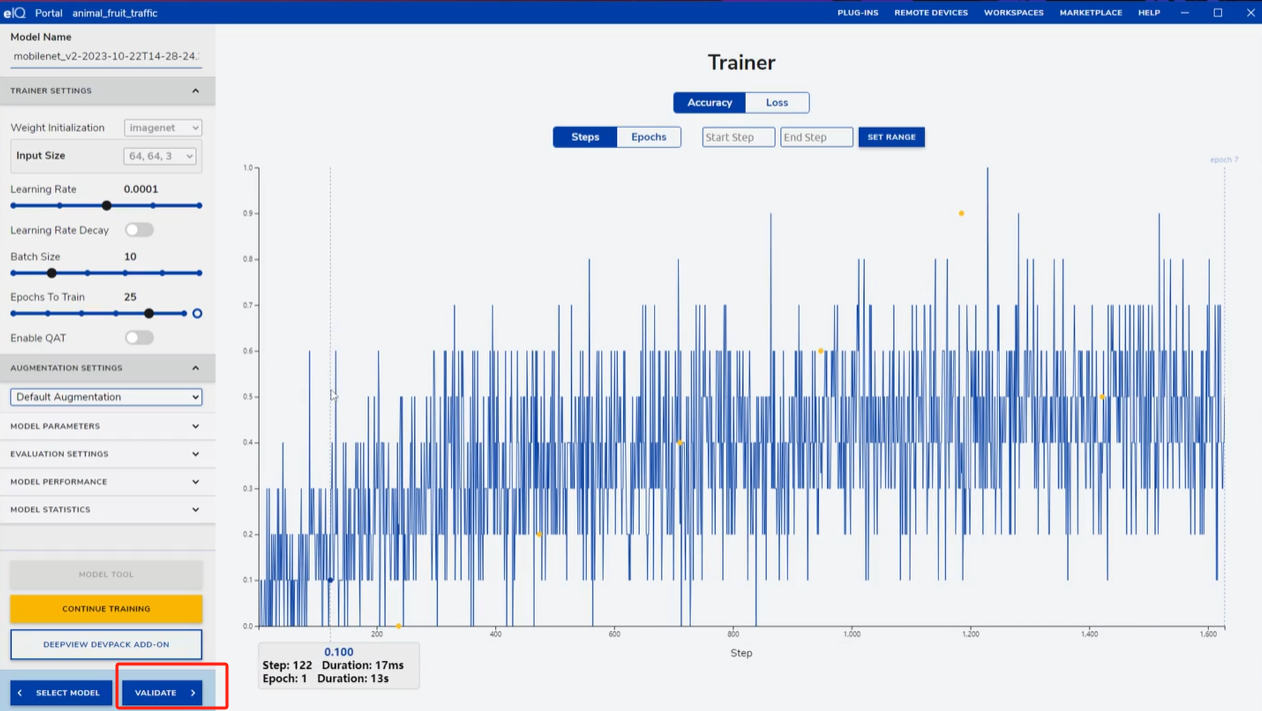
6. 模型验证与优化
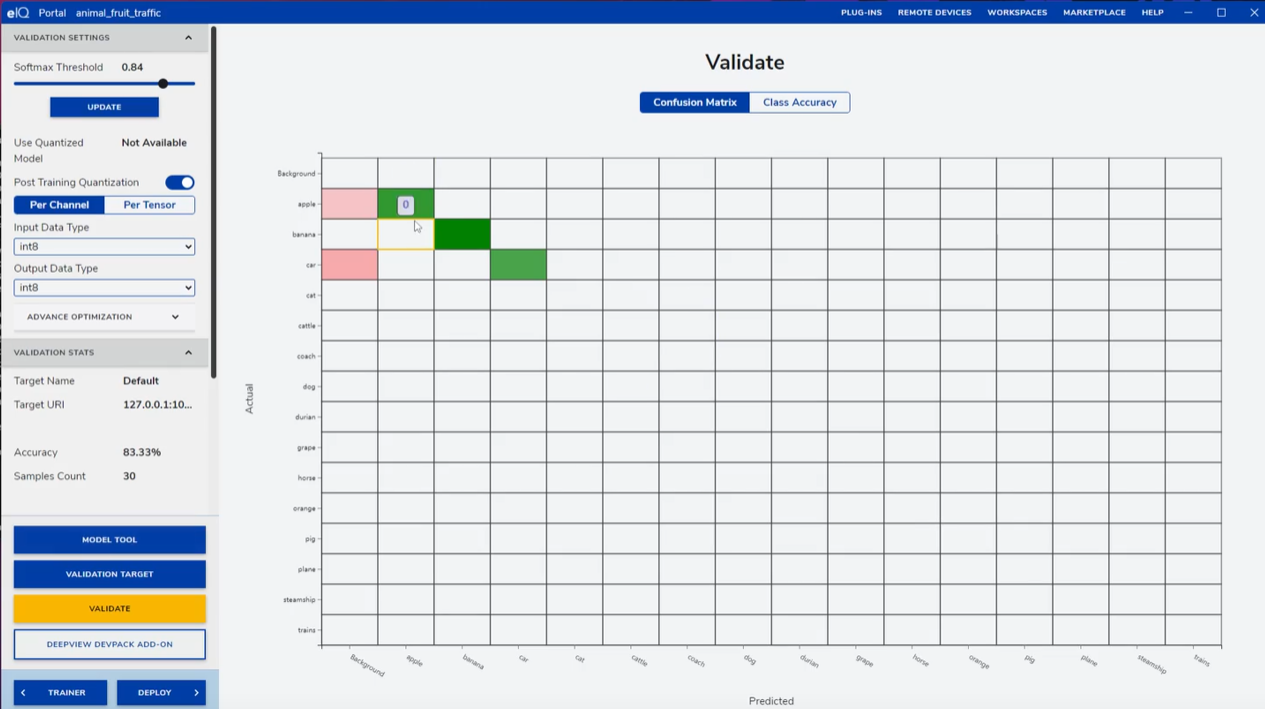
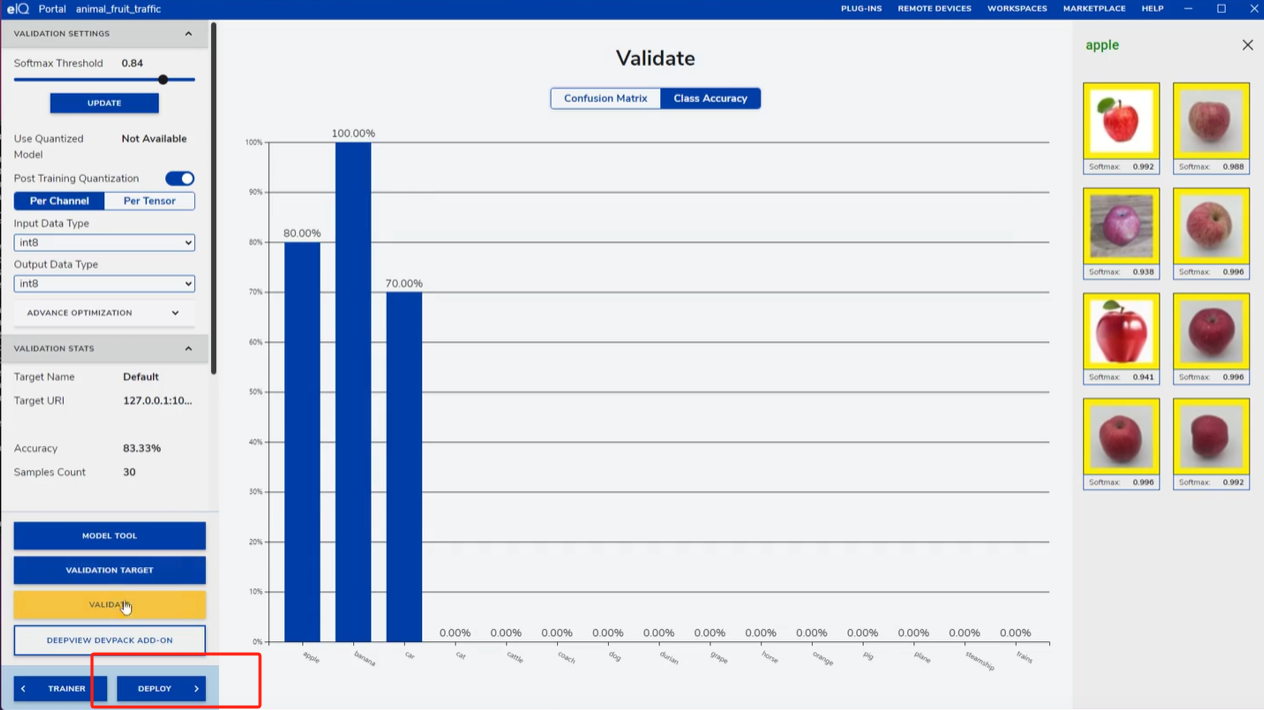
训练完成后,进入VALIDATE页面,设置合适的阈值,点击VALIDATE开始验证。验证结果可通过混淆矩阵查看分类错误的类别,或通过Class Accuracy查看每个小类的识别率,针对表现不佳的类别,可补充数据后重新训练。
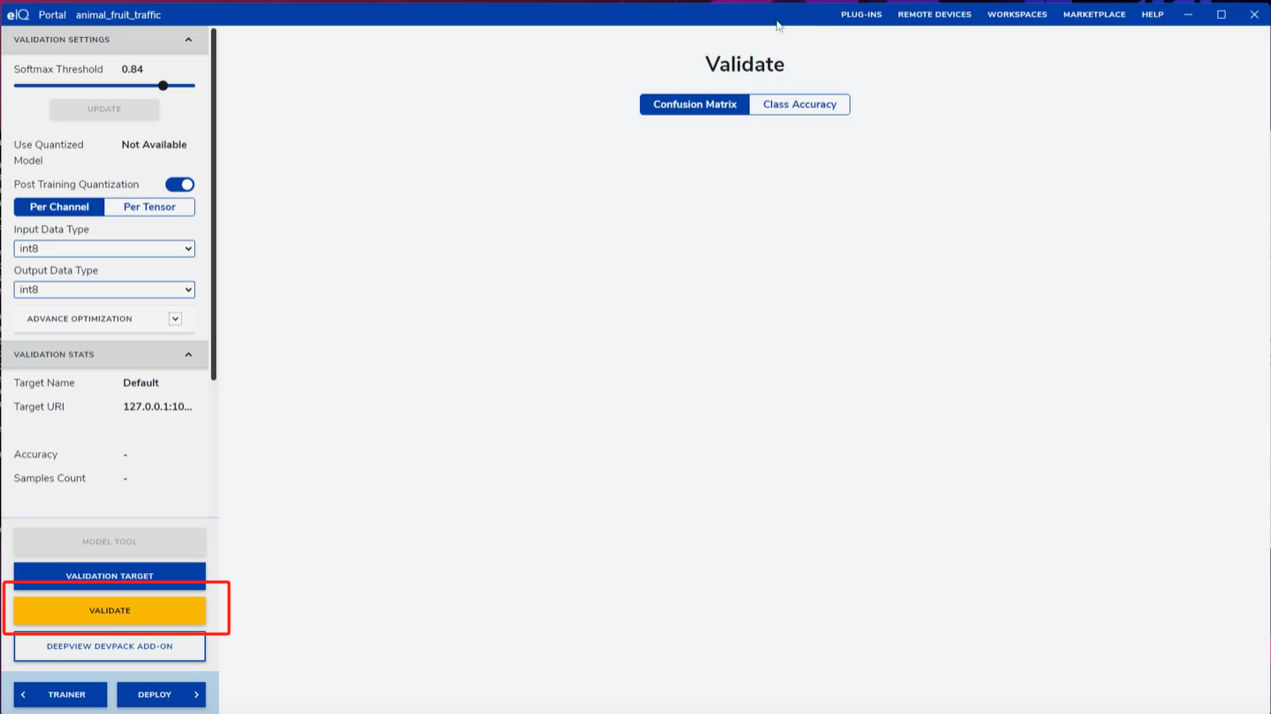
根据测试集的大小,可能需要等待一段较长的时间(当然时间太长的话也有可能是卡死,eIQ经常出现这种情况)
7. 模型导出与部署
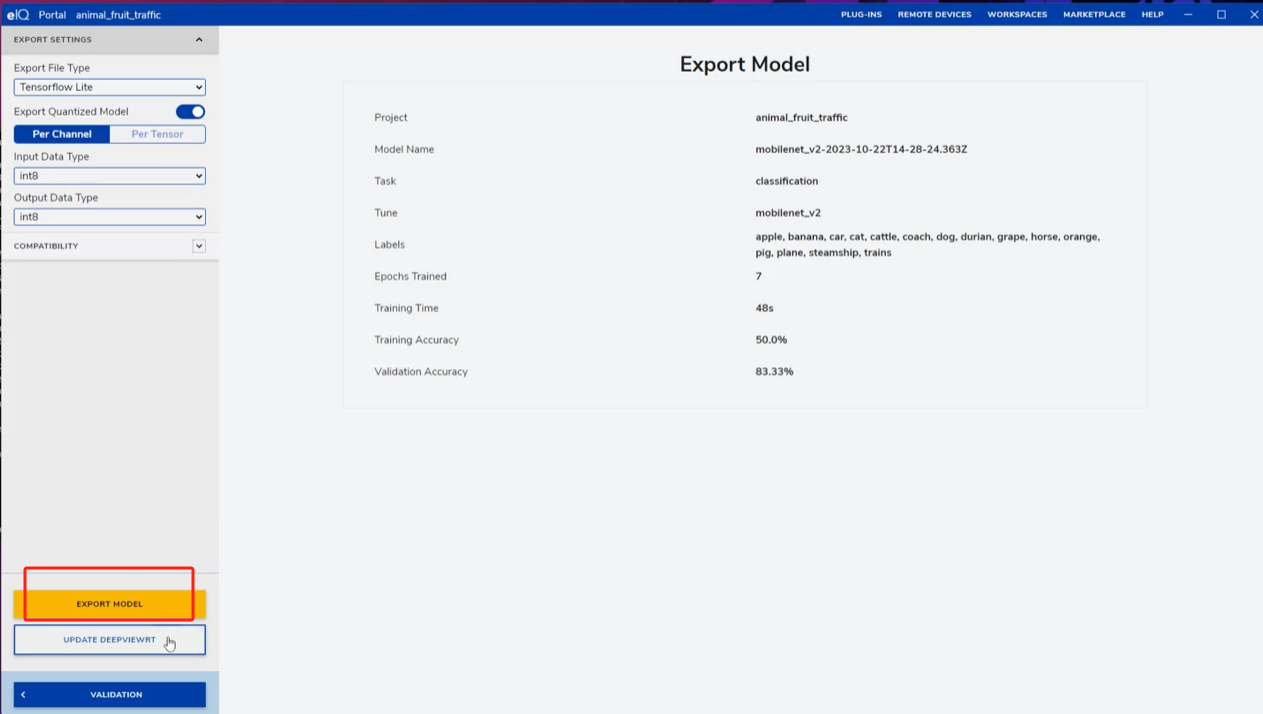
在DEPLOY页面,选择输出格式,将Input Data Type和Output Data Type设为int8(适配嵌入式硬件),点击EXPORT MODEL导出模型。将导出的.tflite模型和标签txt文件放入OpenART mini的SD卡中,通过OpenMV IDE连接设备并运行,即可实现实时图像识别。
五、训练技巧
- 优先使用命令行导入数据:当图片数量超过100张时,命令行导入能避免手动操作的繁琐,且能保证标签与分类的一致性,减少错误。
- 分阶段训练策略:先无增强训练建立基础模型,再用增强数据二次训练,既能保证模型的基础识别能力,又能提升泛化性,避免直接使用增强数据导致的训练震荡。
- 合理调整训练轮数:建议设置25轮左右的训练轮数,过少可能导致欠拟合,过多则易过拟合,可根据训练曲线判断是否提前终止或增加轮数。
- 重视混淆矩阵分析:针对混淆矩阵中红色较深的类别,可通过增加该类图片数量、单独标注错误样本等方式优化,重点提升薄弱类别的识别率。
- 模型量化必选int8格式:嵌入式设备的存储和计算资源有限,int8量化能在几乎不损失精度的前提下,大幅提升模型的运行速度,适配智能车的实时需求。
- 规范标签管理:导入图片后立即完成标签标注,利用Unlabeled Images筛选未标注图片,避免因标签遗漏导致训练数据无效。
- 及时保存训练进度:训练过程中可定期保存模型,若后续训练出现问题,可回溯到之前的最佳状态,避免重复劳动。
结尾
eIQ工具作为NXP为智能车竞赛量身打造的AI训练解决方案,以其便捷的操作流程和出色的嵌入式适配性,成为攻克本届竞赛图像识别难题的关键工具。通过本文的详细拆解,相信大家已经掌握了从环境配置、数据处理到模型训练、部署的全流程方法。
如果对这方面还有疑问可以详细看我们车队的视频教程,本文档部分截图来自福州大学206智能车队在B站上的教学视频: 20届智能车视觉培训之eIQ Toolkit使用教程
機器視覺:智能車大賽視覺組技術文檔——用eIQ工具高效訓練分類模型
智能車視覺組用 NXP eIQ 訓練 MobileNet_v2 分類模型:資料導入、增強、訓練驗證、int8 匯出部署到 OpenART,附競賽訓練技巧與逐飛資源連結。
來源:https://blog.csdn.net/2403_87969572/article/details/153585855
抓取時間(ISO本地):2026-05-18 05:17:13
系列文章目錄
機器視覺:智能車大賽視覺組技術文檔——OpenArt結合OpenMV實現色塊檢測
機器視覺:智能車大賽視覺組技術文檔——用 YOLO3 Nano 實現目標檢測並部署到 OpenART
機器視覺:智能車大賽視覺組技術文檔——用eIQ工具高效訓練分類模型
機器視覺:智能車大賽視覺組技術文檔——第20屆智能車比賽視覺組視覺模塊多種思路分析
文章目錄
前言
隨著智能車競賽智能視覺組規則的更新,競賽的核心挑戰從賽道行駛轉向了更高難度的圖像識別任務。從16屆僅需識別3大類目、以及後續競賽要求精準識別15個小類目標不同,本次不止要識別15類小目標,還需要識別1-99手寫數字,並且圖片方向隨機多變,這對模型的泛化能力和訓練效率提出了更高要求。
前面我們講過了色塊檢測以及yolo3 nano模型目標檢測,(也有直接用yolo進行分類的模型,但是主流方案並沒有採用這個,而是通過本文所說的eIQ工具進行分類模型的訓練對yolo算法得到的目標ROI進行分類任務)
為幫助參賽同學應對這一挑戰,NXP聯合逐飛科技推出了專為競賽場景優化的模型訓練工具——eIQ,並通過多場技術直播提供指導。相較於NXP官網繁瑣的下載流程,逐飛科技已獲得授權並提供了便捷的工具包下載渠道,讓同學們能夠快速上手。本文將基於逐飛科技的官方教程,詳細拆解如何使用eIQ工具完成分類模型的全流程訓練。
一、基礎知識
在開始eIQ工具的實操前,我們需要掌握幾個與圖像分類訓練相關的核心概念,為後續操作奠定基礎:
- 訓練集與測試集:訓練集用於模型的參數學習,測試集用於驗證模型的泛化能力,合理的比例分配(可通過eIQ的SHUFFLE功能自動實現)能避免模型過擬合。
- 數據增強:通過對圖片進行隨機旋轉、亮度調整等變換,人為擴充訓練數據的多樣性,提升模型對實際場景中多變圖像的適應能力,這對本次競賽中方向不確定的圖片識別尤為重要。
- 模型量化:將模型參數從高精度(如float32)轉換為低精度(如int8),在保證識別精度的前提下,降低模型的存儲佔用和推理延遲,適配智能車的嵌入式硬件(如OpenART mini)。
- 混淆矩陣:用於直觀展示模型的分類效果,矩陣中綠色越深表示分類正確率越高,紅色越深表示錯誤率越高,可快速定位模型的薄弱分類。
- 學習率:控制模型參數更新的步長,過大易導致訓練震盪不收斂,過小則訓練速度過慢,合理設置學習率是保證訓練效果的關鍵。
二、eIQ介紹
eIQ是NXP推出的一站式AI模型開發工具,專為嵌入式場景設計,尤其適合智能車競賽這類對硬件適配性要求較高的場景。其核心優勢在於:
- 全流程覆蓋:集成數據導入、數據增強、模型選擇、訓練、驗證、導出等功能,無需切換多個工具,降低開發門檻。
- 輕量化適配:默認支持MobileNet_v2等輕量級模型,導出的模型可直接適配NXP系列MCU(如RT1064),完美兼容OpenART mini開發板。
- 操作便捷性:提供圖形化界面和命令行兩種操作方式,支持批量數據導入和自動化訓練,大幅提升開發效率。
- 競賽專屬優化:針對本屆智能車競賽的數據集特點,預設了適配的訓練參數和數據增強策略,減少同學們的參數調試成本。
此外,逐飛科技為競賽同學提供了包含eIQ安裝包、OpenMV IDE及配套教程的資源包,避免了官網註冊下載的繁瑣流程,進一步降低了入門難度。
三、eIQ安裝
這邊先附上逐飛官方的下載地址:
鏈接:https://pan.baidu.com/s/18-osV8mqPIbZOZpEJLi36w
提取碼:idhq
如果鏈接失效 歡迎私信聯繫博主發送安裝包
以下是官方的圖解安裝教程,已經寫得非常詳細這邊就不在贅述了:
安裝完畢之後打開界面如下:
三、模型介紹
智能車競賽推薦使用的模型為MobileNet_v2,該模型是輕量級卷積神經網絡的經典代表,非常適合嵌入式設備的實時圖像識別任務,其核心特點如下:
- 參數輕量化:通過深度可分離卷積替代傳統卷積,在保證識別精度的同時,大幅減少模型參數數量和計算量,降低硬件資源消耗。
- 推理速度快:精簡的網絡結構使其在嵌入式MCU上的推理延遲顯著降低,能夠滿足智能車競賽中實時圖像識別的需求。
- 泛化能力強:經過大規模圖像數據集預訓練,對自然場景中的各類目標具有良好的特徵提取能力,適配競賽中多類別的圖像識別任務。
相較於其他複雜模型(如ResNet),MobileNet_v2在嵌入式硬件上的兼容性和運行效率更具優勢,是本次競賽的最優選擇之一。
四、訓練方法
1. 數據導入
- 手動導入:點擊CREATE PROJECT創建.eiqp後綴的工程,通過IMPORT功能選擇圖片並手動添加標籤,利用Unlabeled Images分類篩選未標註圖片,避免遺漏;也可以直接導入結構化的數據集,就是路徑下有按類別分類的文件夾,文件夾裡面是用於訓練的該類別圖片。可通過SHUFFLE功能按比例自動分配訓練集與測試集。
3. 數據增強:提升模型泛化能力
點擊左下角AUGMENTATION TOOL,可使用默認的增強策略(如隨機旋轉、亮度調整),也可新建自定義規則,添加多種圖像變換方式。通過預覽窗口可實時查看增強效果,確認後保存並返回主界面。數據增強能有效應對競賽中圖片方向不確定的問題,讓模型在複雜環境下仍保持高識別率。
具體如下:
- Rotate(旋轉):隨機旋轉圖像,讓模型適應不同朝向的目標。
- Horizontal Flip(水平翻轉):沿垂直軸鏡像翻轉圖像,增加左右方向的場景多樣性。
- Vertical Flip(垂直翻轉):沿水平軸鏡像翻轉圖像,補充上下方向的變化場景。
- Random Blur(隨機模糊):給圖像添加不同程度的模糊,模擬拍攝模糊或運動模糊的場景。
- Gaussian Noise(高斯噪聲):添加高斯分佈的隨機噪聲,模擬傳感器等引入的噪聲干擾。
- Hue Saturation Value(HSV調整):調整色調、飽和度、亮度,適配不同色彩和光照的環境。
- Random Brightness(隨機亮度):隨機改變圖像亮度,讓模型適應強光、弱光等光照變化。
- Random Contrast(隨機對比度):調整圖像對比度,增強模型對不同明暗對比圖像的識別。
- Random Gamma(隨機伽馬校正):非線性調整像素亮度分佈,模擬不同設備或光照下的圖像表現。
4. 模型選擇與參數設置
在主頁面點擊SELECT MODEL,選擇MobileNet_v2作為基礎模型。
mobilenet_v1(分類模型)
基於深度可分離卷積(將傳統卷積拆分為“深度卷積+逐點卷積”),大幅降低參數量與計算量,是輕量級分類模型的奠基之作。支持通過“寬度乘數”靈活調整模型複雜度,適配不同算力的嵌入式設備。mobilenet_v2(分類模型)
在v1基礎上升級,核心創新是倒置殘差結構和線性瓶頸層:先通過1×1卷積“擴張”通道數,再用深度可分離卷積提取特徵,最後以線性1×1卷積“壓縮”通道(避免ReLU破壞低維特徵信息),在精度與效率間實現更優平衡。mobilenet_v3(分類模型)
結合神經架構搜索(NAS)自動優化網絡結構,引入h-swish(平滑版ReLU)和h-sigmoid激活函數,同時加入SE(注意力)模塊增強特徵選擇,進一步提升輕量性與分類性能,是MobileNet系列的最新迭代。fpn_ssd_mobilenet_v2(目標檢測模型)
以mobilenet_v2為骨幹,融合**FPN(特徵金字塔網絡)**與SSD(單階段檢測框架):FPN通過多尺度特徵融合提升小目標檢測能力,SSD則以單階段流程保證實時性,適合嵌入式設備的實時目標檢測任務。ssd_mobilenet_v3(目標檢測模型)
採用mobilenet_v3為骨幹,結合SSD架構實現多尺度目標檢測。繼承v3的h-swish激活和SE模塊,在檢測精度(尤其是小目標)與推理速度間更平衡,適配移動設備、邊緣終端等低功耗場景。
這些模型覆蓋了“輕量級分類→實時檢測”的核心需求,可根據任務類型(分類/檢測)和硬件資源選擇適配的架構。
關鍵參數設置如下(僅為推薦設置,具體設置需要根據數據集和模型以及你的硬件條件來定,需要經驗的積累):
- 訓練參數:將Epochs To Train設為25,Input Size推薦64*64及以上,Learning Rate保持默認,Batch Size根據硬件性能調整。
- 增強設置:先選擇No Augments進行基礎訓練,再選擇Default Augmentation進行二次訓練,讓模型適應多變的數據特徵。
- 驗證設置:啟用Enable Evaluation,設置每訓練若干輪進行一次驗證,同時啟用可視化功能,實時監控訓練效果。
5. 模型訓練與監控
點擊START TRAINING開始訓練,過程中可隨時終止,後續支持繼續訓練。訓練過程中可查看訓練集與測試集的正確率、損失值變化,通過切換視圖(按步數或輪數)分析模型收斂情況。二次訓練初期正確率可能下降,屬於正常現象,隨著訓練推進,模型會逐漸適應增強後的數據。
6. 模型驗證與優化
訓練完成後,進入VALIDATE頁面,設置合適的閾值,點擊VALIDATE開始驗證。驗證結果可通過混淆矩陣查看分類錯誤的類別,或通過Class Accuracy查看每個小類的識別率,針對表現不佳的類別,可補充數據後重新訓練。
根據測試集的大小,可能需要等待一段較長的時間(當然時間太長的話也有可能是卡死,eIQ經常出現這種情況)
7. 模型導出與部署
在DEPLOY頁面,選擇輸出格式,將Input Data Type和Output Data Type設為int8(適配嵌入式硬件),點擊EXPORT MODEL導出模型。將導出的.tflite模型和標籤txt文件放入OpenART mini的SD卡中,通過OpenMV IDE連接設備並運行,即可實現實時圖像識別。
五、訓練技巧
- 優先使用命令行導入數據:當圖片數量超過100張時,命令行導入能避免手動操作的繁瑣,且能保證標籤與分類的一致性,減少錯誤。
- 分階段訓練策略:先無增強訓練建立基礎模型,再用增強數據二次訓練,既能保證模型的基礎識別能力,又能提升泛化性,避免直接使用增強數據導致的訓練震盪。
- 合理調整訓練輪數:建議設置25輪左右的訓練輪數,過少可能導致欠擬合,過多則易過擬合,可根據訓練曲線判斷是否提前終止或增加輪數。
- 重視混淆矩陣分析:針對混淆矩陣中紅色較深的類別,可通過增加該類圖片數量、單獨標註錯誤樣本等方式優化,重點提升薄弱類別的識別率。
- 模型量化必選int8格式:嵌入式設備的存儲和計算資源有限,int8量化能在幾乎不損失精度的前提下,大幅提升模型的運行速度,適配智能車的實時需求。
- 規範標籤管理:導入圖片後立即完成標籤標註,利用Unlabeled Images篩選未標註圖片,避免因標籤遺漏導致訓練數據無效。
- 及時保存訓練進度:訓練過程中可定期保存模型,若後續訓練出現問題,可回溯到之前的最佳狀態,避免重複勞動。
結尾
eIQ工具作為NXP為智能車競賽量身打造的AI訓練解決方案,以其便捷的操作流程和出色的嵌入式適配性,成為攻克本屆競賽圖像識別難題的關鍵工具。通過本文的詳細拆解,相信大家已經掌握了從環境配置、數據處理到模型訓練、部署的全流程方法。
如果對這方面還有疑問可以詳細看我們車隊的視頻教程,本文檔部分截圖來自福州大學206智能車隊在B站上的教學視頻: 20屆智能車視覺培訓之eIQ Toolkit使用教程
Machine Vision: Smart Car Vision Group — Training Classifiers with eIQ
Smart Car vision: eIQ + MobileNet_v2 pipeline—data, augmentation, training, int8 export to OpenART, with competition tips and Seekfree resources.
Captured at (local ISO): 2026-05-18 05:17:13
Series Index
OpenART + OpenMV color blobs
YOLO3 Nano on OpenART
eIQ classification (this post)
Multiple vision strategies
Preface
The smart-car vision group now stresses image recognition—not just track following. You must classify 15 fine-grained objects and handwritten digits 0–99 with random orientation. We already covered color blobs and YOLO3 Nano detection; mainstream stacks run eIQ classifiers on YOLO ROIs rather than end-to-end YOLO classification.
NXP and Seekfree provide eIQ with live tutorials. Seekfree hosts an authorized toolkit download so you skip NXP’s heavy portal flow. This post follows Seekfree’s guide for the full eIQ classification pipeline.
1. Basics
- Train/test split: SHUFFLE in eIQ helps avoid overfit.
- Augmentation: rotation, brightness, etc.—critical for arbitrary digit orientation.
- Quantization: float32 → int8 for OpenART mini storage and latency.
- Confusion matrix: spot weak classes quickly.
- Learning rate: too large oscillates; too small crawls.
2. eIQ overview
NXP’s end-to-end embedded AI IDE:
- Data import → augment → train → validate → export in one tool;
- Lightweight models (MobileNet_v2) for RT1064 / OpenART mini;
- GUI + CLI; contest-oriented defaults.
Seekfree bundle: eIQ + OpenMV IDE + docs.
Baidu pan: https://pan.baidu.com/s/18-osV8mqPIbZOZpEJLi36w code idhq (DM author if expired).
Install screenshots:
4. Models
Recommended: MobileNet_v2 — depthwise separable convs, fast on MCU, strong features.
Alternatives in eIQ:
mobilenet_v1— width multiplier for scaling;mobilenet_v2— inverted residuals + linear bottlenecks;mobilenet_v3— NAS, h-swish, SE blocks;fpn_ssd_mobilenet_v2— detection with FPN;ssd_mobilenet_v3— v3 backbone + SSD.
Pick classification vs detection by task.
5. Training workflow
5.1 Data import
CREATE PROJECT (.eiqp), IMPORT images/labels, or folder-per-class datasets; SHUFFLE split.
5.2 Augmentation
AUGMENTATION TOOL — rotate, flip, blur, noise, HSV, brightness, contrast, gamma.
5.3 Model & hyperparameters
SELECT MobileNet_v2. Suggested starting point (tune per dataset/hardware):
- Epochs ~25, input ≥64×64, default LR, batch per GPU;
- Train once No Augments, then Default Augmentation;
- Enable evaluation each N steps with plots.
–(11.png)
5.4 Train & monitor
START TRAINING; accuracy/loss curves; brief dip after adding aug is normal.
5.5 Validate
VALIDATE page, confusion matrix / per-class accuracy; add data for weak classes. eIQ may hang on large test sets.
5.6 Deploy
DEPLOY → int8 I/O → EXPORT → copy .tflite + labels to OpenART SD card; run in OpenMV IDE.
6. Tips
- CLI import for 100+ images;
- Two-stage training (no aug → aug);
- ~25 epochs baseline, watch curves;
- Fix red cells in confusion matrix with more samples;
- int8 export for real-time car use;
- Label every image; filter Unlabeled;
- Save checkpoints often.
Closing
eIQ is the practical path for this year’s classification tasks. Video walkthrough: 20th Smart Car Vision — eIQ Toolkit (Fuzhou University team 206).