机器视觉:智能车大赛视觉组技术文档——用 YOLO3 Nano 实现目标检测并部署到 OpenART
本文为智能车视觉组系列:以 TensorFlow 2.x 上的 YOLO3 Nano 为主线,说明 VOC 标注(LabelImg/官方标注包)、config 与 TFRecord 转换、k-means 锚框、训练与评估,以及将带后处理的 TFLite 部署到 OpenART(QVGA 实时检测示例代码)与 PC 验证思路。
机器视觉:智能车大赛视觉组技术文档——OpenArt结合OpenMV实现色块检测
机器视觉:智能车大赛视觉组技术文档——用 YOLO3 Nano 实现目标检测并部署到 OpenART
机器视觉:智能车大赛视觉组技术文档——用eIQ工具高效训练分类模型
机器视觉:智能车大赛视觉组技术文档——第20届智能车比赛视觉组视觉模块多种思路分析
前言
上一篇博客 我们在讲色块检测的时候有提到,很多情况下我们也会选择yolo目标检测作为一种更加稳定的方案,他不需要现场调节阈值,可以很稳定的实现对选定目标的框取定位。
而在比赛之外,在嵌入式设备上实现高效的目标检测,一直是计算机视觉领域的热门需求。无论是智能小车避障、无人机巡检,还是便携式安防设备,都需要轻量级、低功耗且精度足够的模型。今天,我们就来聊聊如何利用YOLO3 Nano——一个基于TensorFlow 2.x的轻量级YOLO3实现,完成从数据打标、模型训练到部署到OpenART硬件的全流程。
本文适合对目标检测感兴趣的初学者,无需深厚的深度学习理论基础,跟着步骤操作就能上手。让我们一步步把“目标检测”搬进openart中吧
一、YOLO3算法简介
在聊YOLO3 Nano之前,我们先简单了解下它的“前辈”——YOLO3算法。
YOLO(You Only Look Once)是经典的单阶段目标检测算法,核心优势是“快”。与两阶段算法(如Faster R-CNN)相比,YOLO将目标检测视为一个端到端的回归问题,直接从图像中预测目标的边界框和类别,省去了复杂的区域提案(Region Proposal)步骤,因此推理速度极快,适合实时场景。
YOLO3在YOLOv1、v2的基础上做了多项改进:
- 多尺度检测:通过3个不同尺度的特征图(13×13、26×26、52×52),分别检测大、中、小目标,提升了对小目标的识别能力;
- 特征融合:使用跳跃连接(Skip Connection)融合不同层级的特征(浅层特征含细节,深层特征含语义),让检测更精准;
- 骨干网络升级:采用Darknet-53作为特征提取网络,兼顾精度和速度;
- 锚框机制:预设9种不同尺寸的锚框(Anchors),通过聚类数据集目标尺寸生成,提升边界框预测效率。
不过,YOLO3的Darknet-53网络仍有较多参数,在嵌入式设备上(比如说本次智能车大赛指定的openmv视觉模块或者是算力稍微好一点树莓派、Nano)运行时会面临算力和内存限制。因此,轻量级版本——YOLO3 Nano应运而生。
二、基于TensorFlow 2.x的轻量级YOLO3模型(YOLO3 Nano)简介
YOLO3 Nano是针对资源受限设备设计的轻量化YOLO3实现,核心特点是“轻量”和“易用”:
- 轻量级设计:简化了YOLO3的骨干网络,减少卷积层数量和通道数,大幅降低模型参数(通常只有原YOLO3的1/10左右),适合在嵌入式设备(如OpenART)上运行;
- TensorFlow 2.x支持:基于TensorFlow 2.x框架实现,兼容Keras高阶API,训练和部署更灵活,且支持导出为TFLite格式(轻量级推理格式);
- 完整工具链:配套提供了数据集转换、锚框生成、训练、评估、推理的全套脚本,无需从零搭建流程;
- OpenART适配:针对嵌入式硬件优化,可直接部署到OpenART设备(一种面向边缘计算的智能硬件),满足实时检测需求。
三、需要文件的下载安装
链接:https://pan.baidu.com/s/1EaHbtiiy0zJTN2bIdIjWpw
提取码:ciwu
下载解压之后是包含着四个文件或文件夹的,其具体作用在下面会详细介绍
三、打标教程及技巧:为训练准备高质量数据
模型训练的效果,很大程度上取决于数据集的质量。YOLO3 Nano支持VOC格式数据集,因此我们需要用工具标注图像,并生成VOC格式的标注文件。 打标的意思就是为数据添加标签,简单来说就是告诉模型这个图片里面的哪些区域是我要检测的东西,其属于哪个类别(不过在这边我们用的只有一个类别,因为我们暂时只需要进行目标检测)
工具准备:LabelImg
LabelImg是一款开源的图像标注工具,支持生成VOC格式(XML文件)的标注结果,操作简单,适合初学者。
安装命令(Windows/Mac/Linux通用):
pip install labelimg
安装完成后,在终端输入labelimg即可启动。
或者是这个压缩文件里面其实是提供了完整的打标工具的,进入label_img目录下直接运行mainUI.exe这个可执行文件既可进行打标
打标步骤
-
准备图像:
收集需要检测的目标图像,建议至少收集500张以上(数量越多,模型泛化能力越强)注意不可以直接用比赛官方提供的数据集进行标注,一定要把数据集全部打印出来用摄像头一张一张的拍下在真实环境中的真实图片(不过去年逐飞官方有提到一个p图的方法,也可以参考参考),在目标检测的时候倒是不需要拍下所有类别的所有照片,大概拍一部分500张以上就可以了,实测数据集在5000张以上的时候定位效果是非常稳定的。这个数据集也可以按拍照图片的类别保存后,后期经过yolo模型处理之后可以作为训练分类模型的数据集,就可以少拍一些之后的分类模型数据集了(这个才是最折磨人的) -
启动标注环境 导入图片(以逐飞官方提供的labe_img为例):
按上述步骤进入mainUI.exe之后界面如下,需要按图片步骤导入拍摄的图片路径:
点开导入之后有一个打开图片文件夹的选项,选中你存放拍摄的图片的路径下就可以了,效果如下:
-
新建工程
点击左上角的文件——然后选择新建工程——在弹出的界面中选择User Define Objects——在Input Types里面输入object(注意一定要是object 不可以是别的否则在训练的时候会报错,除非你的代码基础比较好可以直接尝试修改备注文件或者标注工程文件)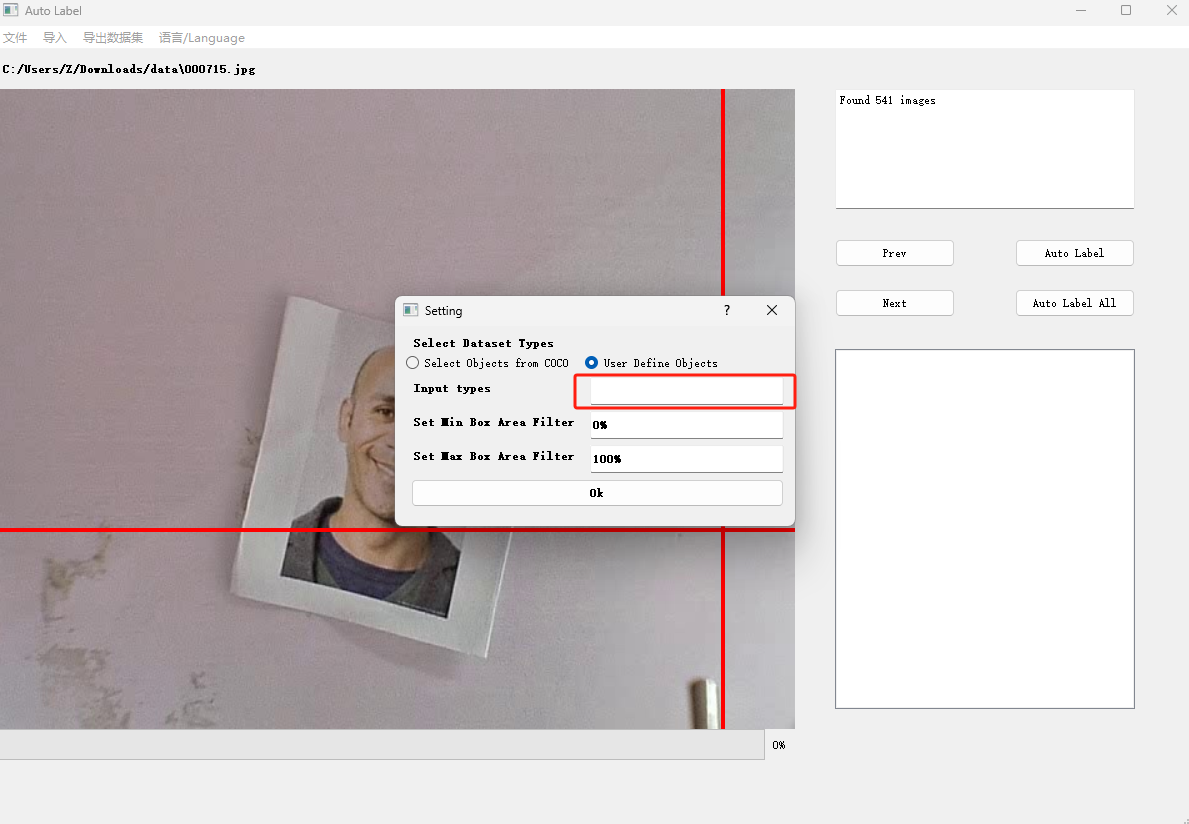
-
标注目标:
这里面的标注框选工具是默认唤醒的,直接进行框选就好,框选之后会出现类别的选择项,由于这边使用的是单目标检测,所以直接选择object_0就可以了
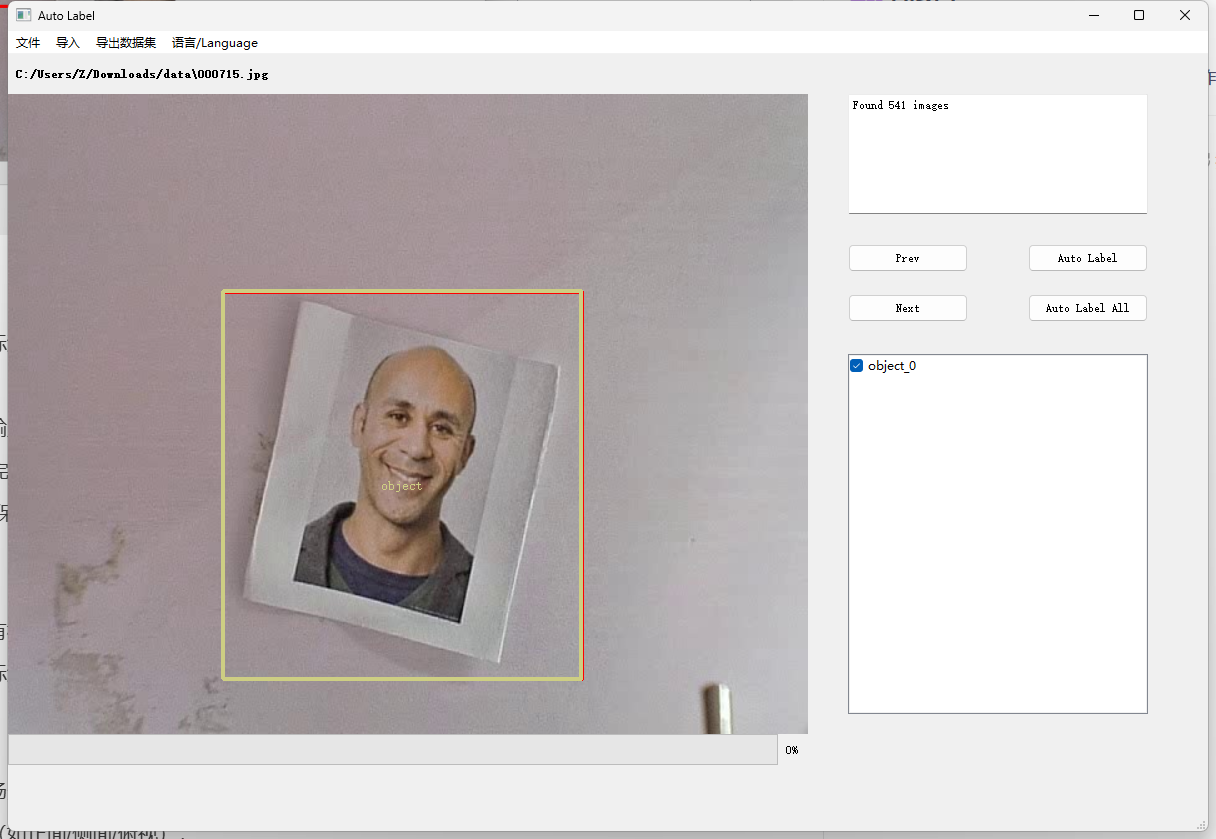
打完这张图的标记之后可以按Next进入下一张的标注
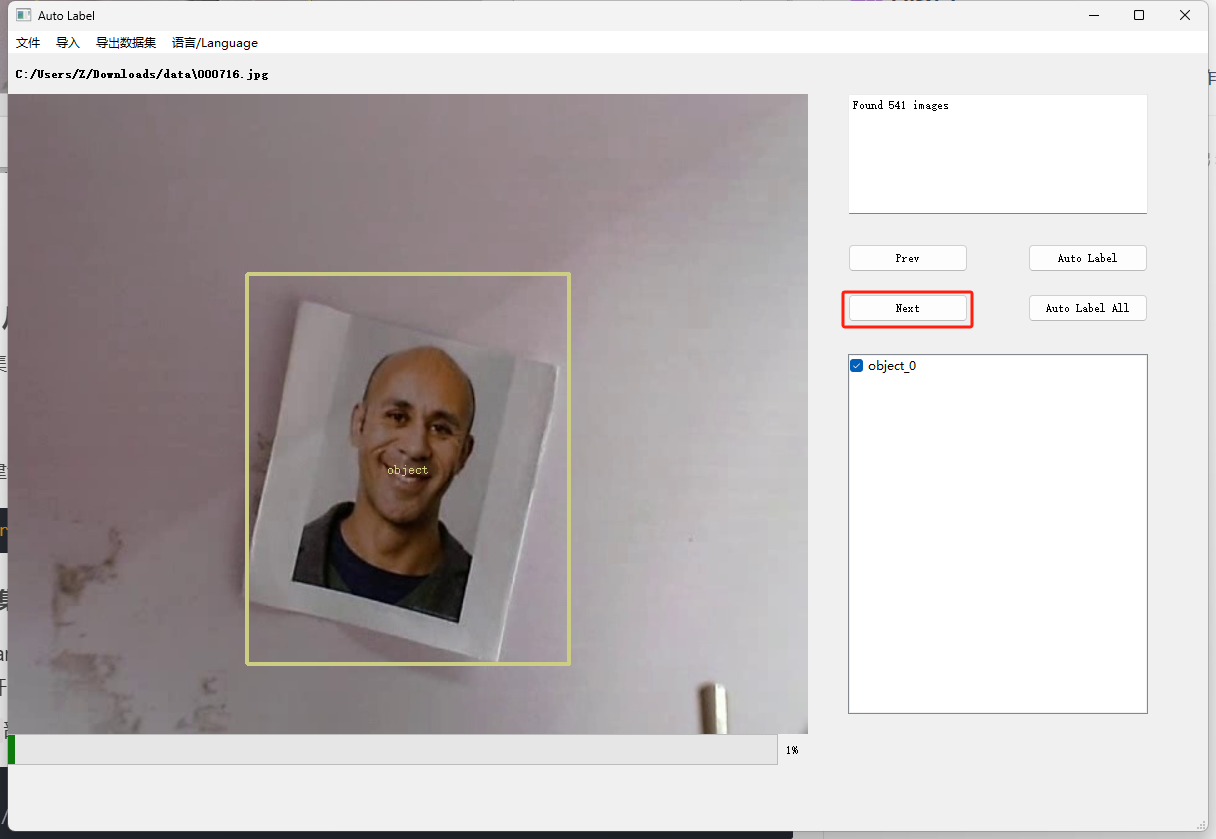
-
导出数据集:
按导出数据集——保存voc文件既可进行打标结果的保存,这个保存的数据集是直接适配于文件中的yolo3Nano的训练代码的,不需要再进行格式调整什么的。
保存之后的是一个tar压缩包,解压之后数据集格式如下:

JPEGImage就是原始的图片数据

Annotations文件夹是与图片一一对应的打标数据(文件名相同,猴嘴不同为xml文件)

<annotation> <folder>data</folder> <filename>000716.jpg</filename> <path>C:\Users\Z\Downloads\data\000716.jpg</path> <source> <database>Unknown</database> </source> <size> <width>640</width> <height>480</height> <depth>3</depth> </size> <segmented>0</segmented> <object> <name>object</name> <pose>Unspecified</pose> <truncated>0</truncated> <difficult>0</difficult> <bndbox> <xmin>191</xmin> <ymin>135</ymin> <xmax>449</xmax> <ymax>428</ymax> </bndbox> </object> </annotation>标注文件为 Pascal VOC 格式(常用于 YOLO 等模型训练),主要信息如下:
标注图像:位于 “data” 文件夹,文件名为 “000716.jpg”,路径为 “C:\Users\Z\Downloads\data\000716.jpg”;
图像尺寸:宽 640、高 480、深度 3(RGB 格式),无分割标注(segmented=0);
标注物体:1 个类别为 “object” 的物体,姿态未指定,未截断(truncated=0),不难识别(difficult=0),边界框坐标为 xmin=191、ymin=135、xmax=449、ymax=428。
打标技巧
1、进入下一张的时候可以直接按空格复刻上一次的按钮操作(Prev 或者 Next) 就不需要数据在框选和Next那边来回点击了
2、建议打一部分就按一次导出数据集——保存voc文件,不然万一这个程序抽风崩溃或者卡死前面的标就全部白打了
三、训练模型教程:从数据到可用模型
有了标注好的数据集,接下来我们用YOLO3 Nano的工具链训练模型。
环境准备
首先安装依赖库(建议用虚拟环境隔离):
pip install tensorflow==2.11.0 numpy==1.23.4 pillow opencv-python configparser argparse matplotlib
步骤1:配置数据集路径
- 打开刚才下载的文件夹里面yolo3_smartcar路径,找到项目根目录下的
config.cfg文件,用记事本或VS Code打开。 - 找到
[dataset]部分的voc_folder参数,填写VOC格式数据集的根目录路径:
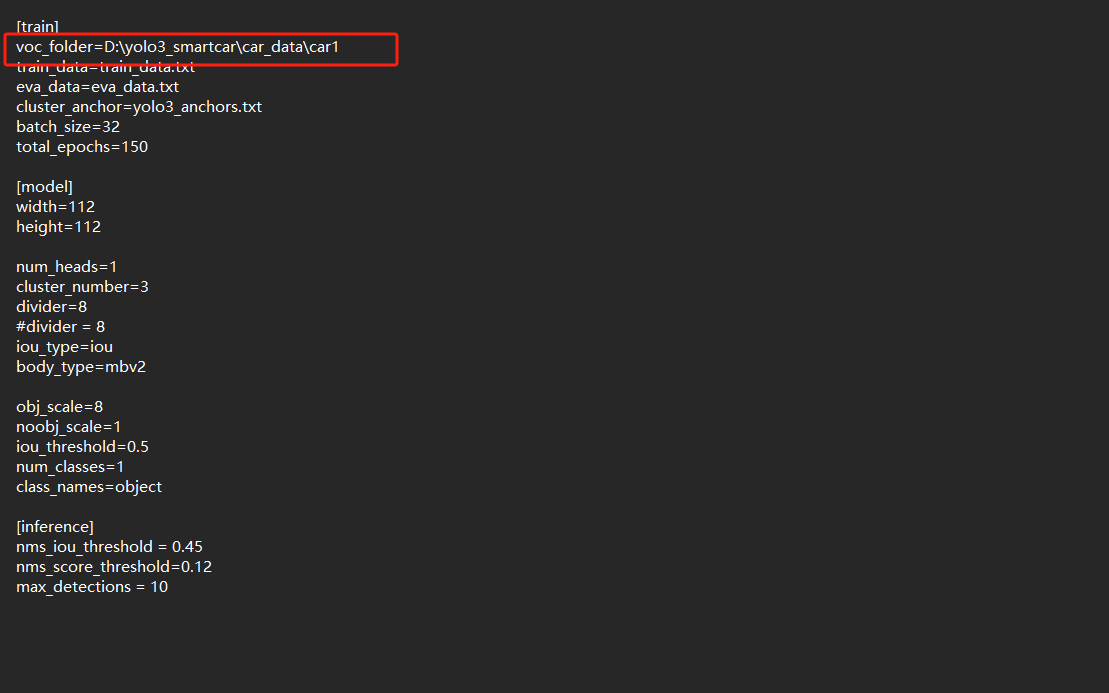
修改为刚才标注导出的tar文件的解压之后的路径
数据集目录结构需符合VOC格式(如下),其中JPEGImages放图像,Annotations放XML标注文件,ImageSets/Main下放train.txt和val.txt(记录训练/验证图像的文件名):VOC2007/ ├─ JPEGImages/ # 图像文件(.jpg) ├─ Annotations/ # 标注文件(.xml) └─ ImageSets/ └─ Main/ ├─ train.txt # 训练集图像文件名(无后缀) └─ val.txt # 验证集图像文件名(无后缀)
步骤2:转换数据集
YOLO3 Nano需要将VOC格式的XML文件转换为模型可直接读取的TFRecord格式(高效存储数据)。运行以下命令:
python voc_convertor.py
脚本会自动读取config.cfg中的数据集路径,生成train.tfrecord和val.tfrecord文件(保存在项目根目录)。

步骤3:生成锚框(Anchors)
锚框(Anchor Box) 是一种预先设定的、具有固定宽高比例的边界框,用于辅助模型更高效地预测图像中目标的位置和大小。它的核心作用是 “降低预测难度”—— 通过预设的 “模板框”,让模型只需学习 “如何调整模板”,而不是从零开始预测目标的边界框。
YOLO算法依赖锚框预测目标边界框,锚框的尺寸需要根据数据集的目标尺寸通过K-means聚类生成(更贴合数据分布)。运行:
python kmeans.py
脚本会输出9个锚框的尺寸(如[[10,13], [16,30], ...]),并自动更新到config.cfg的anchors参数中。
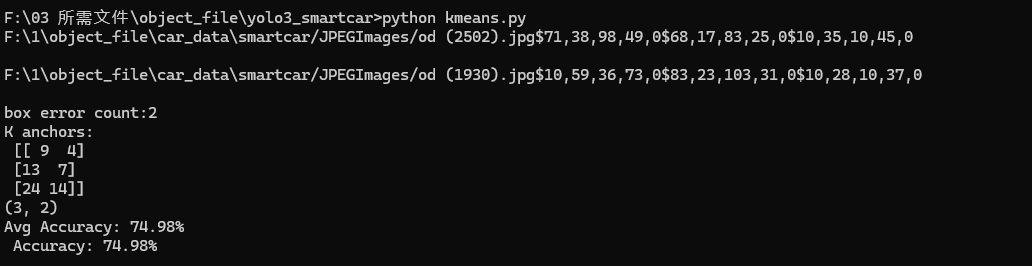
输出结果解析:
1、发现了 2 个无效标注框(需检查并修正,避免影响模型训练);
2、聚类得到 3 个锚框(9×4、13×7、24×14),这些锚框会被用于 YOLO3 Nano 模型的边界框预测;
3、锚框与真实目标的平均匹配度为 74.98%,聚类效果合格,可用于后续训练
步骤4:训练模型
运行训练脚本,开始模型训练:
python train.py
训练过程中,脚本会自动加载数据集、初始化模型、计算损失并更新参数。关键参数可在config.cfg中调整:
batch_size:批次大小(根据显卡显存调整,建议8-32);epochs:训练轮数(建议100-300轮,根据验证集精度调整);learning_rate:学习率(初始建议0.001,后期可衰减)。
训练过程中,模型会定期保存到checkpoints目录,同时在logs目录生成TensorBoard日志(可通过tensorboard --logdir=logs查看损失和精度曲线)。
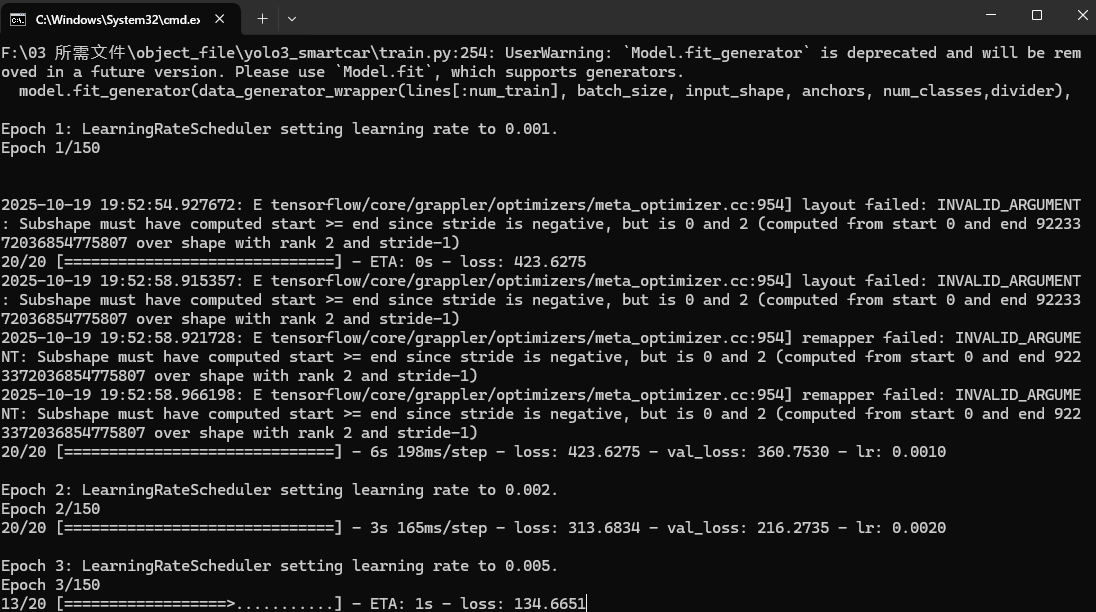
这样就是正确开始训练了,耗时不会很长,具体根据你的batch_size和epochs等决定
步骤5:评估模型
训练完成后,用验证集评估模型性能(主要看mAP:平均精度均值):
python evaluate.py
输出结果中,mAP值越高(接近1),模型性能越好。如果精度较低,可增加数据集数量、调整训练参数或优化标注质量。
四、部署模型到OpenART
训练好的模型需要转换为嵌入式设备支持的格式,才能部署到OpenART。YOLO3 Nano已支持导出TFLite格式(轻量级推理格式),并附带后处理逻辑(简化部署流程)。
步骤1:导出TFLite模型
训练完成后,项目会自动生成包含后处理的TFLite模型(yolo3_iou_smartcar_final_with_post_processing.tflite),无需额外转换。
步骤2:部署到OpenART
OpenART是一款支持TFLite推理的嵌入式硬件,部署步骤超简单:
- 将
yolo3_iou_smartcar_final_with_post_processing.tflite复制到SD卡中; - 将SD卡插入OpenART硬件的SD卡槽;
- 启动OpenART,运行以下官方提供的代码(我已加上详细注释很好理解)。硬件会自动加载TFLite模型并运行目标检测:
# 导入必要的库
# seekfree/pyb:OpenART硬件专用库,用于控制底层硬件(如摄像头、IO口)
# sensor:摄像头传感器控制库,负责图像采集
# image:图像处理库,用于绘制检测框、图像预处理等
# time:时间工具库,用于计时和帧率计算
# tf:TensorFlow Lite推理库,用于加载模型并执行目标检测
# gc:垃圾回收库,嵌入式设备内存有限,用于主动释放内存避免溢出
import seekfree, pyb
import sensor, image, time, tf, gc
# ----------------------------
# 1. 摄像头传感器初始化配置
# ----------------------------
# 重置摄像头传感器(类似重启,确保初始状态正确)
sensor.reset()
# 设置像素格式:RGB565(每个像素占2字节,兼顾色彩显示和内存占用)
# 可选格式:GRAYSCALE(灰度图,1字节/像素,更省内存但无色彩)
sensor.set_pixformat(sensor.RGB565)
# 设置图像分辨率:QVGA(320x240)
# 选择原因:嵌入式设备算力有限,低分辨率可提升帧率(实时性更优);若需更高精度,可尝试VGA(640x480)但帧率会下降
sensor.set_framesize(sensor.QVGA)
# 跳过初始2000ms的图像帧
# 原因:摄像头刚启动时,曝光、白平衡等参数未稳定,前几帧图像可能偏暗/偏色,跳过可保证后续检测稳定性
sensor.skip_frames(time=2000)
# 创建时钟对象,用于计算实时帧率(FPS)
clock = time.clock()
# ----------------------------
# 2. 加载YOLO3 Nano模型
# ----------------------------
# 模型路径:TFLite模型存储在SD卡中(OpenART通常通过SD卡读取外部文件)
# 此处路径对应之前部署的"带后处理的模型"(已集成NMS等后处理逻辑,直接输出最终检测结果)
model_path = '/sd/yolo3_iou_smartcar_final_with_post_processing.tflite'
# 加载模型:通过tf.load()方法将模型从SD卡加载到内存
# 注意:若模型加载失败,可能是路径错误或模型文件损坏,需检查SD卡中的文件
net = tf.load(model_path)
# 主动触发一次垃圾回收,释放模型加载过程中可能产生的临时内存占用
gc.collect()
# ----------------------------
# 3. 实时目标检测主循环
# ----------------------------
while True:
# 记录当前时间(用于后续计算帧率)
clock.tick()
# 从摄像头获取一帧图像(snapshot()返回image对象,可直接用于检测和绘制)
img = sensor.snapshot()
# ----------------------------
# 3.1 执行目标检测
# ----------------------------
# 使用加载的模型检测图像中的目标
# tf.detect(net, img)返回检测结果列表:每个元素是一个目标的信息(坐标、类别、置信度)
# 注:模型输出的坐标是"归一化坐标"(范围0~1),需后续转换为实际像素坐标
detect_results = tf.detect(net, img)
# ----------------------------
# 3.2 处理检测结果
# ----------------------------
for obj in detect_results:
# 解析单个目标的信息:
# x1, y1:目标左上角坐标(归一化,0~1)
# x2, y2:目标右下角坐标(归一化,0~1)
# label:目标类别ID(对应训练时的类别,如0代表"车")
# scores:目标置信度(0~1,值越高,模型对该目标的判断越可靠)
x1, y1, x2, y2, label, scores = obj
# 过滤低置信度目标:只保留置信度>70%的结果
# 目的:减少误检(模型可能把背景误判为目标),提升检测可靠性
if scores > 0.7:
# 打印目标信息(调试用,可查看检测到的目标细节)
print(f"检测到目标:类别={label},置信度={scores:.2f},坐标=({x1:.2f},{y1:.2f})-({x2:.2f},{y2:.2f})")
# ----------------------------
# 3.3 坐标转换:归一化坐标 → 实际像素坐标
# ----------------------------
# 模型输出的x1,y1,x2,y2是相对于图像宽高的比例(0~1),需转换为实际像素值
# 图像实际宽高:img.width()=320,img.height()=240(对应QVGA分辨率)
img_width = img.width() # 图像宽度(像素)
img_height = img.height() # 图像高度(像素)
# 计算目标宽度和高度(归一化)
w_norm = x2 - x1 # 归一化宽度
h_norm = y2 - y1 # 归一化高度
# 转换为实际像素坐标(x1_offset是可选的校准参数,若检测框整体偏右,可减偏移量)
x1_pixel = int((x1 - 0.05) * img_width) # 左上角x像素(-0.05为示例校准值,可根据实际偏移调整)
y1_pixel = int(y1 * img_height) # 左上角y像素
w_pixel = int(w_norm * img_width) # 宽度像素
h_pixel = int(h_norm * img_height) # 高度像素
# 确保坐标在图像范围内(避免超出图像边界导致绘制错误)
x1_pixel = max(0, min(x1_pixel, img_width))
y1_pixel = max(0, min(y1_pixel, img_height))
w_pixel = max(1, min(w_pixel, img_width - x1_pixel)) # 宽度至少为1,避免无效框
h_pixel = max(1, min(h_pixel, img_height - y1_pixel))
# ----------------------------
# 3.4 绘制检测框
# ----------------------------
# 在图像上绘制矩形框标记目标,线宽为2像素,颜色默认红色(RGB565格式下可自定义)
img.draw_rectangle((x1_pixel, y1_pixel, w_pixel, h_pixel), thickness=2)
# 可选:在框上方绘制类别和置信度文本(增强可视化效果)
# 文本内容:类别ID + 置信度(保留2位小数)
text = f"cls{label}: {scores:.2f}"
# 绘制文本:位置在框左上角上方,字体大小1(最小),颜色红色
img.draw_string(x1_pixel, y1_pixel - 10, text, color=(255, 0, 0), scale=1)
# ----------------------------
# 3.5 输出实时帧率
# ----------------------------
# 计算并打印当前帧率(FPS = 每秒处理的图像帧数)
# 嵌入式设备中,FPS越高说明实时性越好(通常需≥10FPS才流畅)
print(f"帧率:{clock.fps():.1f} FPS")
# 定期触发垃圾回收,释放循环中产生的临时内存(避免内存泄漏)
gc.collect()
步骤3:验证部署效果
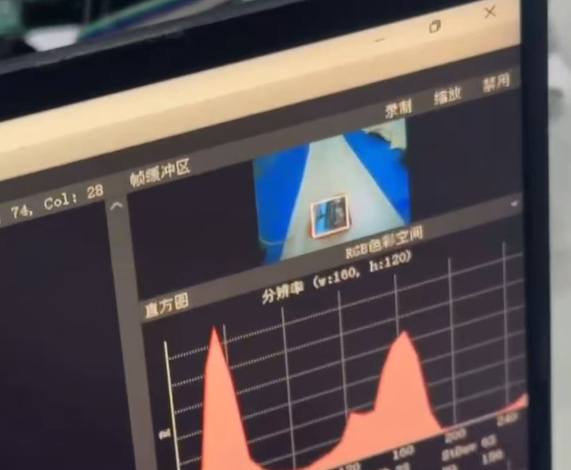
如果需要在PC上提前验证TFLite模型的效果,可运行项目提供的检测脚本:
脚本会读取图像并输出检测结果(目标位置和类别),效果如下(由于openart都给下一届学弟拿去学习了,现在手上没有openart 这还是从以前视频截的照片):
总结
通过本文,我们完成了从数据打标、模型训练到部署到OpenART的全流程。YOLO3 Nano的轻量级设计让它在openart设备上“跑得动”,而TensorFlow 2.x的生态则简化了训练和部署流程。
回顾整个过程,高质量的数据集是模型效果的基础,合理的锚框和训练参数是模型精度的保障,而TFLite格式则是连接训练与部署的桥梁。如果想进一步提升性能,可以尝试:
- 增加数据增强(如旋转、裁剪、亮度调整);
- 微调模型结构(如增加注意力机制);
- 量化模型(TFLite支持INT8量化,进一步降低推理耗时)。
機器視覺:智能車大賽視覺組技術文檔——用 YOLO3 Nano 實現目標檢測並部署到 OpenART
本篇屬智能車視覺組系列:介紹 TensorFlow 2.x 版 YOLO3 Nano 的 VOC 標註(LabelImg/官方標註包)、設定檔與 TFRecord 轉換、k-means 錨框、訓練與評估,以及將含後處理的 TFLite 部署至 OpenART(附註解採集迴圈)與在電腦端驗證的做法。
來源:https://blog.csdn.net/2403_87969572/article/details/153582736
抓取時間(ISO本地):2026-05-18 05:17:11
系列文章目錄
機器視覺:智能車大賽視覺組技術文檔——OpenArt結合OpenMV實現色塊檢測
機器視覺:智能車大賽視覺組技術文檔——用 YOLO3 Nano 實現目標檢測並部署到 OpenART
機器視覺:智能車大賽視覺組技術文檔——用eIQ工具高效訓練分類模型
機器視覺:智能車大賽視覺組技術文檔——第20屆智能車比賽視覺組視覺模塊多種思路分析
文章目錄
- 系列文章目錄
- 前言
- 一、YOLO3算法簡介
- 二、基於TensorFlow 2.x的輕量級YOLO3模型(YOLO3 Nano)簡介
- 三、需要文件的下載安裝
- 三、打標教程及技巧:為訓練準備高質量數據
- 三、訓練模型教程:從數據到可用模型
- 四、部署模型到OpenART
前言
上一篇博客 我們在講色塊檢測的時候有提到,很多情況下我們也會選擇yolo目標檢測作為一種更加穩定的方案,他不需要現場調節閾值,可以很穩定的實現對選定目標的框取定位。
而在比賽之外,在嵌入式設備上實現高效的目標檢測,一直是計算機視覺領域的熱門需求。無論是智能小車避障、無人機巡檢,還是便攜式安防設備,都需要輕量級、低功耗且精度足夠的模型。今天,我們就來聊聊如何利用YOLO3 Nano——一個基於TensorFlow 2.x的輕量級YOLO3實現,完成從數據打標、模型訓練到部署到OpenART硬件的全流程。
本文適合對目標檢測感興趣的初學者,無需深厚的深度學習理論基礎,跟著步驟操作就能上手。讓我們一步步把“目標檢測”搬進openart中吧
一、YOLO3算法簡介
在聊YOLO3 Nano之前,我們先簡單瞭解下它的“前輩”——YOLO3算法。
YOLO(You Only Look Once)是經典的單階段目標檢測算法,核心優勢是“快”。與兩階段算法(如Faster R-CNN)相比,YOLO將目標檢測視為一個端到端的迴歸問題,直接從圖像中預測目標的邊界框和類別,省去了複雜的區域提案(Region Proposal)步驟,因此推理速度極快,適合實時場景。
YOLO3在YOLOv1、v2的基礎上做了多項改進:
- 多尺度檢測:通過3個不同尺度的特徵圖(13×13、26×26、52×52),分別檢測大、中、小目標,提升了對小目標的識別能力;
- 特徵融合:使用跳躍連接(Skip Connection)融合不同層級的特徵(淺層特徵含細節,深層特徵含語義),讓檢測更精準;
- 骨幹網絡升級:採用Darknet-53作為特徵提取網絡,兼顧精度和速度;
- 錨框機制:預設9種不同尺寸的錨框(Anchors),通過聚類數據集目標尺寸生成,提升邊界框預測效率。
不過,YOLO3的Darknet-53網絡仍有較多參數,在嵌入式設備上(比如說本次智能車大賽指定的openmv視覺模塊或者是算力稍微好一點樹莓派、Nano)運行時會面臨算力和內存限制。因此,輕量級版本——YOLO3 Nano應運而生。
二、基於TensorFlow 2.x的輕量級YOLO3模型(YOLO3 Nano)簡介
YOLO3 Nano是針對資源受限設備設計的輕量化YOLO3實現,核心特點是“輕量”和“易用”:
- 輕量級設計:簡化了YOLO3的骨幹網絡,減少卷積層數量和通道數,大幅降低模型參數(通常只有原YOLO3的1/10左右),適合在嵌入式設備(如OpenART)上運行;
- TensorFlow 2.x支持:基於TensorFlow 2.x框架實現,兼容Keras高階API,訓練和部署更靈活,且支持導出為TFLite格式(輕量級推理格式);
- 完整工具鏈:配套提供了數據集轉換、錨框生成、訓練、評估、推理的全套腳本,無需從零搭建流程;
- OpenART適配:針對嵌入式硬件優化,可直接部署到OpenART設備(一種面向邊緣計算的智能硬件),滿足實時檢測需求。
三、需要文件的下載安裝
鏈接:https://pan.baidu.com/s/1EaHbtiiy0zJTN2bIdIjWpw
提取碼:ciwu
下載解壓之後是包含著四個文件或文件夾的,其具體作用在下面會詳細介紹
三、打標教程及技巧:為訓練準備高質量數據
模型訓練的效果,很大程度上取決於數據集的質量。YOLO3 Nano支持VOC格式數據集,因此我們需要用工具標註圖像,並生成VOC格式的標註文件。 打標的意思就是為數據添加標籤,簡單來說就是告訴模型這個圖片裡面的哪些區域是我要檢測的東西,其屬於哪個類別(不過在這邊我們用的只有一個類別,因為我們暫時只需要進行目標檢測)
工具準備:LabelImg
LabelImg是一款開源的圖像標註工具,支持生成VOC格式(XML文件)的標註結果,操作簡單,適合初學者。
安裝命令(Windows/Mac/Linux通用):
pip install labelimg
安裝完成後,在終端輸入labelimg即可啟動。
或者是這個壓縮文件裡面其實是提供了完整的打標工具的,進入label_img目錄下直接運行mainUI.exe這個可執行文件既可進行打標
打標步驟
-
準備圖像:
收集需要檢測的目標圖像,建議至少收集500張以上(數量越多,模型泛化能力越強)注意不可以直接用比賽官方提供的數據集進行標註,一定要把數據集全部打印出來用攝像頭一張一張的拍下在真實環境中的真實圖片(不過去年逐飛官方有提到一個p圖的方法,也可以參考參考),在目標檢測的時候倒是不需要拍下所有類別的所有照片,大概拍一部分500張以上就可以了,實測數據集在5000張以上的時候定位效果是非常穩定的。這個數據集也可以按拍照圖片的類別保存後,後期經過yolo模型處理之後可以作為訓練分類模型的數據集,就可以少拍一些之後的分類模型數據集了(這個才是最折磨人的) -
啟動標註環境 導入圖片(以逐飛官方提供的labe_img為例):
按上述步驟進入mainUI.exe之後界面如下,需要按圖片步驟導入拍攝的圖片路徑:
點開導入之後有一個打開圖片文件夾的選項,選中你存放拍攝的圖片的路徑下就可以了,效果如下:
-
新建工程
點擊左上角的文件——然後選擇新建工程——在彈出的界面中選擇User Define Objects——在Input Types裡面輸入object(注意一定要是object 不可以是別的否則在訓練的時候會報錯,除非你的代碼基礎比較好可以直接嘗試修改備註文件或者標註工程文件) -
標註目標:
這裡面的標註框選工具是默認喚醒的,直接進行框選就好,框選之後會出現類別的選擇項,由於這邊使用的是單目標檢測,所以直接選擇object_0就可以了
打完這張圖的標記之後可以按Next進入下一張的標註
-
導出數據集:
按導出數據集——保存voc文件既可進行打標結果的保存,這個保存的數據集是直接適配於文件中的yolo3Nano的訓練代碼的,不需要再進行格式調整什麼的。
保存之後的是一個tar壓縮包,解壓之後數據集格式如下:
JPEGImage就是原始的圖片數據
Annotations文件夾是與圖片一一對應的打標數據(文件名相同,猴嘴不同為xml文件)
<annotation> <folder>data</folder> <filename>000716.jpg</filename> <path>C:\Users\Z\Downloads\data\000716.jpg</path> <source> <database>Unknown</database> </source> <size> <width>640</width> <height>480</height> <depth>3</depth> </size> <segmented>0</segmented> <object> <name>object</name> <pose>Unspecified</pose> <truncated>0</truncated> <difficult>0</difficult> <bndbox> <xmin>191</xmin> <ymin>135</ymin> <xmax>449</xmax> <ymax>428</ymax> </bndbox> </object> </annotation>標註文件為 Pascal VOC 格式(常用於 YOLO 等模型訓練),主要信息如下:
標註圖像:位於 “data” 文件夾,文件名為 “000716.jpg”,路徑為 “C:\Users\Z\Downloads\data\000716.jpg”;
圖像尺寸:寬 640、高 480、深度 3(RGB 格式),無分割標註(segmented=0);
標註物體:1 個類別為 “object” 的物體,姿態未指定,未截斷(truncated=0),不難識別(difficult=0),邊界框座標為 xmin=191、ymin=135、xmax=449、ymax=428。
打標技巧
1、進入下一張的時候可以直接按空格復刻上一次的按鈕操作(Prev 或者 Next) 就不需要數據在框選和Next那邊來回點擊了
2、建議打一部分就按一次導出數據集——保存voc文件,不然萬一這個程序抽風崩潰或者卡死前面的標就全部白打了
三、訓練模型教程:從數據到可用模型
有了標註好的數據集,接下來我們用YOLO3 Nano的工具鏈訓練模型。
環境準備
首先安裝依賴庫(建議用虛擬環境隔離):
pip install tensorflow==2.11.0 numpy==1.23.4 pillow opencv-python configparser argparse matplotlib
步驟1:配置數據集路徑
- 打開剛才下載的文件夾裡面yolo3_smartcar路徑,找到項目根目錄下的
config.cfg文件,用記事本或VS Code打開。 - 找到
[dataset]部分的voc_folder參數,填寫VOC格式數據集的根目錄路徑:
修改為剛才標註導出的tar文件的解壓之後的路徑
數據集目錄結構需符合VOC格式(如下),其中JPEGImages放圖像,Annotations放XML標註文件,ImageSets/Main下放train.txt和val.txt(記錄訓練/驗證圖像的文件名):VOC2007/ ├─ JPEGImages/ # 圖像文件(.jpg) ├─ Annotations/ # 標註文件(.xml) └─ ImageSets/ └─ Main/ ├─ train.txt # 訓練集圖像文件名(無後綴) └─ val.txt # 驗證集圖像文件名(無後綴)
步驟2:轉換數據集
YOLO3 Nano需要將VOC格式的XML文件轉換為模型可直接讀取的TFRecord格式(高效存儲數據)。運行以下命令:
python voc_convertor.py
腳本會自動讀取config.cfg中的數據集路徑,生成train.tfrecord和val.tfrecord文件(保存在項目根目錄)。
步驟3:生成錨框(Anchors)
錨框(Anchor Box) 是一種預先設定的、具有固定寬高比例的邊界框,用於輔助模型更高效地預測圖像中目標的位置和大小。它的核心作用是 “降低預測難度”—— 通過預設的 “模板框”,讓模型只需學習 “如何調整模板”,而不是從零開始預測目標的邊界框。
YOLO算法依賴錨框預測目標邊界框,錨框的尺寸需要根據數據集的目標尺寸通過K-means聚類生成(更貼合數據分佈)。運行:
python kmeans.py
腳本會輸出9個錨框的尺寸(如[[10,13], [16,30], ...]),並自動更新到config.cfg的anchors參數中。
輸出結果解析:
1、發現了 2 個無效標註框(需檢查並修正,避免影響模型訓練);
2、聚類得到 3 個錨框(9×4、13×7、24×14),這些錨框會被用於 YOLO3 Nano 模型的邊界框預測;
3、錨框與真實目標的平均匹配度為 74.98%,聚類效果合格,可用於後續訓練
步驟4:訓練模型
運行訓練腳本,開始模型訓練:
python train.py
訓練過程中,腳本會自動加載數據集、初始化模型、計算損失並更新參數。關鍵參數可在config.cfg中調整:
batch_size:批次大小(根據顯卡顯存調整,建議8-32);epochs:訓練輪數(建議100-300輪,根據驗證集精度調整);learning_rate:學習率(初始建議0.001,後期可衰減)。
訓練過程中,模型會定期保存到checkpoints目錄,同時在logs目錄生成TensorBoard日誌(可通過tensorboard --logdir=logs查看損失和精度曲線)。
這樣就是正確開始訓練了,耗時不會很長,具體根據你的batch_size和epochs等決定
步驟5:評估模型
訓練完成後,用驗證集評估模型性能(主要看mAP:平均精度均值):
python evaluate.py
輸出結果中,mAP值越高(接近1),模型性能越好。如果精度較低,可增加數據集數量、調整訓練參數或優化標註質量。
四、部署模型到OpenART
訓練好的模型需要轉換為嵌入式設備支持的格式,才能部署到OpenART。YOLO3 Nano已支持導出TFLite格式(輕量級推理格式),並附帶後處理邏輯(簡化部署流程)。
步驟1:導出TFLite模型
訓練完成後,項目會自動生成包含後處理的TFLite模型(yolo3_iou_smartcar_final_with_post_processing.tflite),無需額外轉換。
步驟2:部署到OpenART
OpenART是一款支持TFLite推理的嵌入式硬件,部署步驟超簡單:
- 將
yolo3_iou_smartcar_final_with_post_processing.tflite複製到SD卡中; - 將SD卡插入OpenART硬件的SD卡槽;
- 啟動OpenART,運行以下官方提供的代碼(我已加上詳細註釋很好理解)。硬件會自動加載TFLite模型並運行目標檢測:
# 導入必要的庫
# seekfree/pyb:OpenART硬件專用庫,用於控制底層硬件(如攝像頭、IO口)
# sensor:攝像頭傳感器控制庫,負責圖像採集
# image:圖像處理庫,用於繪製檢測框、圖像預處理等
# time:時間工具庫,用於計時和幀率計算
# tf:TensorFlow Lite推理庫,用於加載模型並執行目標檢測
# gc:垃圾回收庫,嵌入式設備內存有限,用於主動釋放內存避免溢出
import seekfree, pyb
import sensor, image, time, tf, gc
# ----------------------------
# 1. 攝像頭傳感器初始化配置
# ----------------------------
# 重置攝像頭傳感器(類似重啟,確保初始狀態正確)
sensor.reset()
# 設置像素格式:RGB565(每個像素佔2字節,兼顧色彩顯示和內存佔用)
# 可選格式:GRAYSCALE(灰度圖,1字節/像素,更省內存但無色彩)
sensor.set_pixformat(sensor.RGB565)
# 設置圖像分辨率:QVGA(320x240)
# 選擇原因:嵌入式設備算力有限,低分辨率可提升幀率(實時性更優);若需更高精度,可嘗試VGA(640x480)但幀率會下降
sensor.set_framesize(sensor.QVGA)
# 跳過初始2000ms的圖像幀
# 原因:攝像頭剛啟動時,曝光、白平衡等參數未穩定,前幾幀圖像可能偏暗/偏色,跳過可保證後續檢測穩定性
sensor.skip_frames(time=2000)
# 創建時鐘對象,用於計算實時幀率(FPS)
clock = time.clock()
# ----------------------------
# 2. 加載YOLO3 Nano模型
# ----------------------------
# 模型路徑:TFLite模型存儲在SD卡中(OpenART通常通過SD卡讀取外部文件)
# 此處路徑對應之前部署的"帶後處理的模型"(已集成NMS等後處理邏輯,直接輸出最終檢測結果)
model_path = '/sd/yolo3_iou_smartcar_final_with_post_processing.tflite'
# 加載模型:通過tf.load()方法將模型從SD卡加載到內存
# 注意:若模型加載失敗,可能是路徑錯誤或模型文件損壞,需檢查SD卡中的文件
net = tf.load(model_path)
# 主動觸發一次垃圾回收,釋放模型加載過程中可能產生的臨時內存佔用
gc.collect()
# ----------------------------
# 3. 實時目標檢測主循環
# ----------------------------
while True:
# 記錄當前時間(用於後續計算幀率)
clock.tick()
# 從攝像頭獲取一幀圖像(snapshot()返回image對象,可直接用於檢測和繪製)
img = sensor.snapshot()
# ----------------------------
# 3.1 執行目標檢測
# ----------------------------
# 使用加載的模型檢測圖像中的目標
# tf.detect(net, img)返回檢測結果列表:每個元素是一個目標的信息(座標、類別、置信度)
# 注:模型輸出的座標是"歸一化座標"(範圍0~1),需後續轉換為實際像素座標
detect_results = tf.detect(net, img)
# ----------------------------
# 3.2 處理檢測結果
# ----------------------------
for obj in detect_results:
# 解析單個目標的信息:
# x1, y1:目標左上角座標(歸一化,0~1)
# x2, y2:目標右下角座標(歸一化,0~1)
# label:目標類別ID(對應訓練時的類別,如0代表"車")
# scores:目標置信度(0~1,值越高,模型對該目標的判斷越可靠)
x1, y1, x2, y2, label, scores = obj
# 過濾低置信度目標:只保留置信度>70%的結果
# 目的:減少誤檢(模型可能把背景誤判為目標),提升檢測可靠性
if scores > 0.7:
# 打印目標信息(調試用,可查看檢測到的目標細節)
print(f"檢測到目標:類別={label},置信度={scores:.2f},座標=({x1:.2f},{y1:.2f})-({x2:.2f},{y2:.2f})")
# ----------------------------
# 3.3 座標轉換:歸一化座標 → 實際像素座標
# ----------------------------
# 模型輸出的x1,y1,x2,y2是相對於圖像寬高的比例(0~1),需轉換為實際像素值
# 圖像實際寬高:img.width()=320,img.height()=240(對應QVGA分辨率)
img_width = img.width() # 圖像寬度(像素)
img_height = img.height() # 圖像高度(像素)
# 計算目標寬度和高度(歸一化)
w_norm = x2 - x1 # 歸一化寬度
h_norm = y2 - y1 # 歸一化高度
# 轉換為實際像素座標(x1_offset是可選的校準參數,若檢測框整體偏右,可減偏移量)
x1_pixel = int((x1 - 0.05) * img_width) # 左上角x像素(-0.05為示例校準值,可根據實際偏移調整)
y1_pixel = int(y1 * img_height) # 左上角y像素
w_pixel = int(w_norm * img_width) # 寬度像素
h_pixel = int(h_norm * img_height) # 高度像素
# 確保座標在圖像範圍內(避免超出圖像邊界導致繪製錯誤)
x1_pixel = max(0, min(x1_pixel, img_width))
y1_pixel = max(0, min(y1_pixel, img_height))
w_pixel = max(1, min(w_pixel, img_width - x1_pixel)) # 寬度至少為1,避免無效框
h_pixel = max(1, min(h_pixel, img_height - y1_pixel))
# ----------------------------
# 3.4 繪製檢測框
# ----------------------------
# 在圖像上繪製矩形框標記目標,線寬為2像素,顏色默認紅色(RGB565格式下可自定義)
img.draw_rectangle((x1_pixel, y1_pixel, w_pixel, h_pixel), thickness=2)
# 可選:在框上方繪製類別和置信度文本(增強可視化效果)
# 文本內容:類別ID + 置信度(保留2位小數)
text = f"cls{label}: {scores:.2f}"
# 繪製文本:位置在框左上角上方,字體大小1(最小),顏色紅色
img.draw_string(x1_pixel, y1_pixel - 10, text, color=(255, 0, 0), scale=1)
# ----------------------------
# 3.5 輸出實時幀率
# ----------------------------
# 計算並打印當前幀率(FPS = 每秒處理的圖像幀數)
# 嵌入式設備中,FPS越高說明實時性越好(通常需≥10FPS才流暢)
print(f"幀率:{clock.fps():.1f} FPS")
# 定期觸發垃圾回收,釋放循環中產生的臨時內存(避免內存洩漏)
gc.collect()
步驟3:驗證部署效果
如果需要在PC上提前驗證TFLite模型的效果,可運行項目提供的檢測腳本:
腳本會讀取圖像並輸出檢測結果(目標位置和類別),效果如下(由於openart都給下一屆學弟拿去學習了,現在手上沒有openart 這還是從以前視頻截的照片):
總結
通過本文,我們完成了從數據打標、模型訓練到部署到OpenART的全流程。YOLO3 Nano的輕量級設計讓它在openart設備上“跑得動”,而TensorFlow 2.x的生態則簡化了訓練和部署流程。
回顧整個過程,高質量的數據集是模型效果的基礎,合理的錨框和訓練參數是模型精度的保障,而TFLite格式則是連接訓練與部署的橋樑。如果想進一步提升性能,可以嘗試:
- 增加數據增強(如旋轉、裁剪、亮度調整);
- 微調模型結構(如增加注意力機制);
- 量化模型(TFLite支持INT8量化,進一步降低推理耗時)。
Machine Vision: Smart-Car Contest Vision Stack—YOLO3 Nano Object Detection Deployed on OpenART
This installment of the smart-car vision series covers YOLO3 Nano on TensorFlow 2.x: VOC labeling, config.cfg paths, TFRecord conversion, k-means anchors, training/eval, deploying the post-processed TFLite to OpenART with a commented capture loop, and optional PC-side checks.
Captured at (local ISO): 2026-05-18 05:17:11
Series index
Machine vision: Smart-car vision—OpenART + OpenMV color blob detection
Machine vision: Smart-car vision—YOLO3 Nano detection on OpenART
Machine vision: Smart-car vision—training classifiers efficiently with eIQ
Machine vision: Smart-car vision—analysis of multiple module strategies (20th contest)
Foreword
In the color-blob post we noted that YOLO-style detection is often more stable: no fiddly thresholds on site, reliable boxes around chosen targets.
Off the track, efficient detection on embedded kits is a perennial CV topic—smart cars, drones, portable security—all want small, low‑power models that are still accurate enough. This article walks through YOLO3 Nano, a TensorFlow 2.x–friendly lightweight YOLO3, from labeling → training → OpenART deployment.
It targets beginners curious about detection; you don’t need heavy theory—follow the steps. Let’s put real-time detection on OpenART.
I. YOLO3 in brief
Before Nano, a minute on YOLO3.
YOLO (You Only Look Once) is a classic one-stage detector. Its headline feature is speed. Compared with two-stage R-CNN families, YOLO frames detection as dense regression—boxes and classes straight from the image—skipping region proposals, so it’s fast enough for real time.
YOLO3 improved on v1/v2 with:
- Multi-scale heads: three maps (13×13, 26×26, 52×52) for large/medium/small objects—better small-object recall;
- Feature fusion: skip connections blend shallow detail with deep semantics;
- Backbone: Darknet‑53 trades off accuracy vs. speed;
- Anchors: nine preset boxes (usually k-means from your data) make box regression easier.
Darknet‑53 is still heavy for microcontrollers and small SBCs like the contest OpenMV module or a Raspberry Pi. YOLO3 Nano trims the stack for those constraints.
II. YOLO3 Nano on TensorFlow 2.x
YOLO3 Nano is a slim YOLO3 aimed at tight hardware:
- Lightweight: fewer conv layers/channels—often ~1/10 the params of stock YOLO3—so OpenART-class boards can keep up;
- TF 2.x: Keras‑friendly training and easy TFLite export;
- Tooling: convert VOC → TFRecords, k-means anchors, train/eval/infer scripts included;
- OpenART‑ready: fits edge boards that run TFLite with real-time budgets.
III. Downloads and setup
Link: https://pan.baidu.com/s/1EaHbtiiy0zJTN2bIdIjWpw
Extraction code: ciwu
After unzip you get four items—their roles appear below.
III. Labeling tutorial & tips: build a clean dataset
Quality labels dominate model quality. YOLO3 Nano expects VOC XML, so we draw boxes with a labeling tool. Labeling means telling the network where objects are and which class they are (here we use a single class because we only need generic object detection for now).
Tooling: LabelImg
LabelImg is an open-source annotator that emits VOC XML.
Install (Windows/macOS/Linux):
pip install labelimg
Run labelimg in a terminal after install.
The contest bundle also ships a full labeling kit: under label_img, run mainUI.exe directly.
Labeling steps
-
Collect images
Capture your own scenes with the onboard camera—do not just relabel the official contest JPEG bundle. Print or display targets and film them in the real course lighting. You don’t need every permutation; 500+ images is a workable floor; 5,000+ made localization very stable in our tests. Organize shots by category—you can later mine classification crops from YOLO outputs to reduce how many classification photos you need (that part is the real grind). -
Launch the UI and import (using the vendor
label_imgbuild):
OpenmainUI.exe; import your photo folder as shown:
After Import, pick Open image folder and select the directory of captured frames:
-
Create a project
Menu File → New project → choose User Define Objects → in Input Types typeobject(must be exactlyobjector training may break unless you know how to edit project metadata). -
Draw boxes
The rectangle tool is on by default; drag a box, pickobject_0for our single-class setup.
Use Next to advance.
-
Export the dataset
Export dataset → Save VOC writes a bundle already compatible with the bundled YOLO3 Nano trainer—no manual format tweaks.
You get a.tar; extracted layout:
JPEGImagesholds raw photos.
Annotationsholds one XML per image (same basename, .xml extension).
<annotation> <folder>data</folder> <filename>000716.jpg</filename> <path>C:\Users\Z\Downloads\data\000716.jpg</path> <source> <database>Unknown</database> </source> <size> <width>640</width> <height>480</height> <depth>3</depth> </size> <segmented>0</segmented> <object> <name>object</name> <pose>Unspecified</pose> <truncated>0</truncated> <difficult>0</difficult> <bndbox> <xmin>191</xmin> <ymin>135</ymin> <xmax>449</xmax> <ymax>428</ymax> </bndbox> </object> </annotation>This is Pascal VOC XML (common for YOLO trainers):
Image lives underdata, file000716.jpg, pathC:\Users\Z\Downloads\data\000716.jpg;
Size 640×480 RGB, no segmentation (segmented=0);
Oneobjectnamedobject,truncated=0,difficult=0, bbox (191,135)–(449,428).
Labeling tips
- Space bar repeats the last navigation (Prev/Next) so you aren’t constantly clicking between boxing and navigation.
- Export intermittently—if the tool crashes you don’t lose hours of work.
III. Training: from labels to a deployable model
Environment
Create a venv and install:
pip install tensorflow==2.11.0 numpy==1.23.4 pillow opencv-python configparser argparse matplotlib
Step 1: dataset path
- Open
yolo3_smartcarfrom the download and edit rootconfig.cfg. - Under
[dataset], setvoc_folderto your VOC root:
Point it at the folder produced by Save VOC.
Expected tree:VOC2007/ ├─ JPEGImages/ # .jpg frames ├─ Annotations/ # .xml labels └─ ImageSets/ └─ Main/ ├─ train.txt # training IDs (no extension) └─ val.txt # val IDs
Step 2: convert dataset
YOLO3 Nano ingests TFRecord for IO efficiency:
python voc_convertor.py
Reads voc_folder from config.cfg, emits train.tfrecord / val.tfrecord beside the project.
Step 3: k-means anchors
Anchor boxes are fixed aspect-ratio priors so the net predicts offsets instead of boxes from scratch.
Run clustering on your bbox sizes:
python kmeans.py
Writes nine [w,h] pairs into config.cfg under anchors.
How to read the log:
- Two invalid boxes were skipped—clean those XMLs;
- Nine anchors (examples: 9×4, 13×7, 24×14) will feed the YOLO heads;
- ~75% mean IoU to GT—acceptable for training.
Step 4: train
python train.py
Key knobs in config.cfg:
batch_size: tune to VRAM (8–32 typical);epochs: 100–300 depending on val mAP;learning_rate: start ~1e‑3, decay later.
Checkpoints land in checkpoints; TensorBoard logs in logs (tensorboard --logdir=logs).
When loss prints steadily you’re training; wall time depends on batch/epoch settings.
Step 5: evaluate
python evaluate.py
Watch mAP—closer to 1.0 is better. If it’s weak, add data, fix labels, or retune hyperparameters.
IV. Deploy on OpenART
Export to the format OpenART ingests—this repo already ships post-processed TFLite.
Step 1: TFLite artifact
After training you should see yolo3_iou_smartcar_final_with_post_processing.tflite (NMS baked in). Copy that file.
Step 2: OpenART bring-up
OpenART runs TFLite on-device:
- Copy
yolo3_iou_smartcar_final_with_post_processing.tfliteto the SD card; - Insert the card;
- Boot and run the vendor script below (comments expanded). The board loads the model and loops detection:
# seekfree/pyb: board HAL
# sensor: camera capture
# image: drawing / light preprocessing
# time: timing / FPS
# tf: TFLite runtime
# gc: memory hygiene on small SRAM
import seekfree, pyb
import sensor, image, time, tf, gc
# ----------------------------
# 1. Camera setup
# ----------------------------
sensor.reset()
sensor.set_pixformat(sensor.RGB565)
sensor.set_framesize(sensor.QVGA)
sensor.skip_frames(time=2000)
clock = time.clock()
# ----------------------------
# 2. Load YOLO3 Nano TFLite
# ----------------------------
model_path = '/sd/yolo3_iou_smartcar_final_with_post_processing.tflite'
net = tf.load(model_path)
gc.collect()
# ----------------------------
# 3. Real-time loop
# ----------------------------
while True:
clock.tick()
img = sensor.snapshot()
detect_results = tf.detect(net, img)
for obj in detect_results:
x1, y1, x2, y2, label, scores = obj
if scores > 0.7:
print(f"det cls={label} score={scores:.2f} box=({x1:.2f},{y1:.2f})-({x2:.2f},{y2:.2f})")
img_width = img.width()
img_height = img.height()
w_norm = x2 - x1
h_norm = y2 - y1
x1_pixel = int((x1 - 0.05) * img_width) # tweak -0.05 if boxes drift
y1_pixel = int(y1 * img_height)
w_pixel = int(w_norm * img_width)
h_pixel = int(h_norm * img_height)
x1_pixel = max(0, min(x1_pixel, img_width))
y1_pixel = max(0, min(y1_pixel, img_height))
w_pixel = max(1, min(w_pixel, img_width - x1_pixel))
h_pixel = max(1, min(h_pixel, img_height - y1_pixel))
img.draw_rectangle((x1_pixel, y1_pixel, w_pixel, h_pixel), thickness=2)
text = f"cls{label}: {scores:.2f}"
img.draw_string(x1_pixel, y1_pixel - 10, text, color=(255, 0, 0), scale=1)
print(f"FPS: {clock.fps():.1f}")
gc.collect()
Step 3: sanity-check on PC
The project also includes a desktop smoke test that reads still images (screenshot from an old OpenART capture—the board was passed to juniors):
Wrap-up
We covered labeling, training, and OpenART deployment. Nano stays within OpenART’s budget; TensorFlow 2.x keeps the path from training to TFLite short.
Clean data, sensible anchors & training, and TFLite + built-in NMS are the spine of the pipeline. Next steps if you need more: heavier augmentation, light architecture tweaks, or INT8 quantization for extra FPS.