爬虫专栏:基于Python实现历史天气数据爬取
爬取 datashareclub 24 小时历史天气:requests 抓取、正则解析 JS 变量、合并 CSV 保存,附完整可运行代码。
前言
由于树莓派巡检小车部分预测功能的需求,现在需要实现当地天气的python爬虫进行数据获取。需要的数据有温度、湿度、降雨量、光照强度、是否下雨等。(但实际爬取的数据取决于目标网站,我选取的网站远远不止这几个数据),接下来进入实现部分。
一、目标网址的选取与域名熟悉
1、网址选取
选取的目标网址为:全国历史天气查询平台
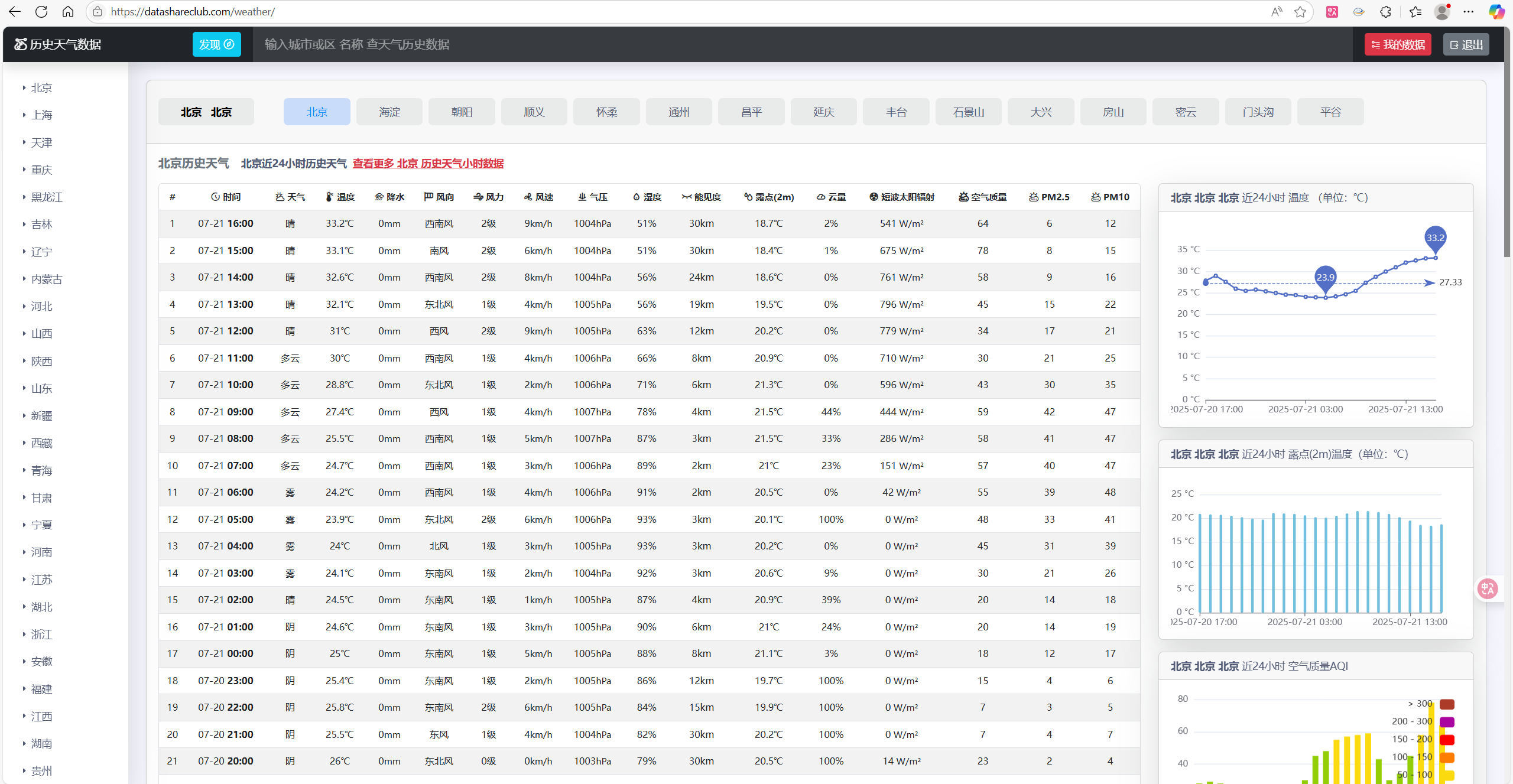
可以看到这边提供以小时为间隔的前24小时历史间隔数据,包括且不限于天气、温度、降水、风向 、风力 、风速、气压、湿度等,符合我们的要求。
2、分析界面
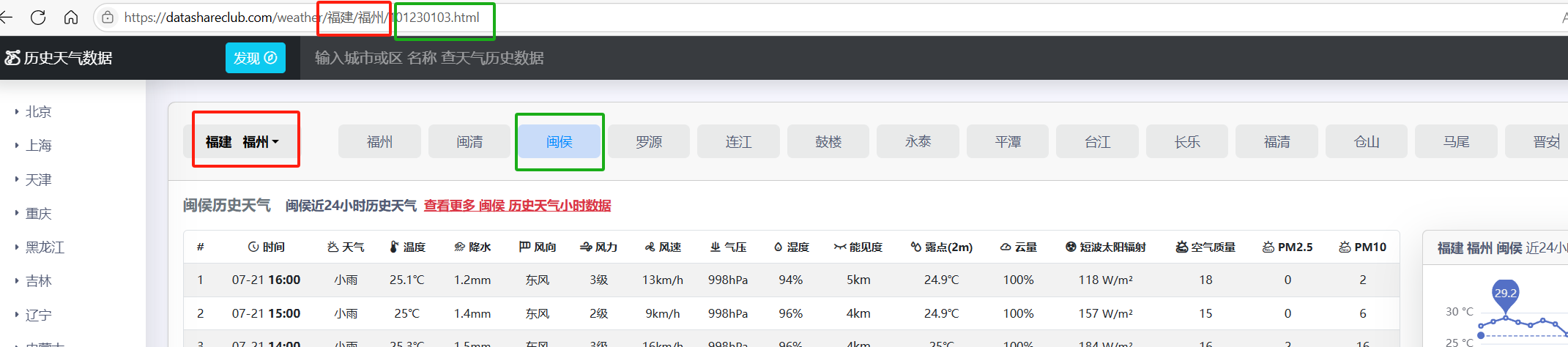
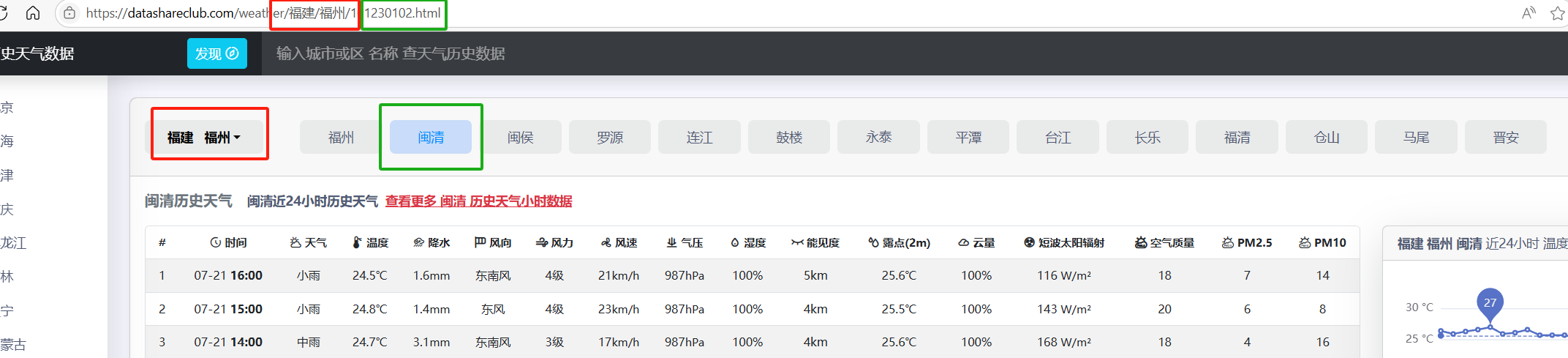
随便访问了两个地方的天气数据对应的子页面,可以看到相同的地方是前面的https://datashareclub.com/weather/以及福建/福州,不同的地方是之后的编码一个是01230103 一个是01230102,对应我们所选择的具体区县。
因此我们可以将这整个网址分为三部分

我们只需要修改绿色黄色相应的部分就可以访问到具体对应的24小时历史天气数据子页面,这有利于我们进行批量的天气数据爬取。但是本次我们只需要用到福建省福州市闽侯县的天气数据就好。
二、代码实践部分
1、初步查看响应
方法一:用Request进行请求后直接输出内容(适用于较为简单的网页界面)
首先构建一个进行请求的python函数fetch_url_content
import requests
from requests.exceptions import RequestException
target_url="https://datashareclub.com/weather/%E7%A6%8F%E5%BB%BA/%E7%A6%8F%E5%B7%9E/101230102.html"
def fetch_url_content(url, headers=None, timeout=10):
"""
使用requests访问目标URL并返回响应内容
参数:
url (str): 要访问的目标URL
headers (dict, 可选): 请求头,默认使用模拟浏览器的User-Agent
timeout (int, 可选): 请求超时时间(秒),默认10秒
返回:
str: 响应文本内容(成功时);None(失败时)
"""
# 默认请求头(模拟浏览器,避免被简单反爬拦截)
default_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
# 如果用户传入自定义headers,合并到默认headers中(用户传入的优先)
if headers:
default_headers.update(headers)
try:
# 发送GET请求
response = requests.get(
url=url,
headers=default_headers,
timeout=timeout # 超时保护
)
# 检查响应状态码(200表示成功)
response.raise_for_status()
# 打印成功信息(可选,可删除)
print(f"✅ 访问成功:{url}(状态码:{response.status_code})")
# 返回响应文本(如果需要二进制内容,可改为 return response.content)
return response.text
except RequestException as e:
# 捕获所有requests相关异常(网络错误、超时、404/500等状态码)
print(f"❌ 访问失败:{url},错误:{str(e)}")
return None
except Exception as e:
# 捕获其他未知异常
print(f"❌ 未知错误:{url},错误:{str(e)}")
return None
def crawler(url):
content = fetch_url_content(url)
if content:
print("\n--- 响应内容---")
print(content)
print('成功响应')
crwaler(target_url)
代码运行结果如下
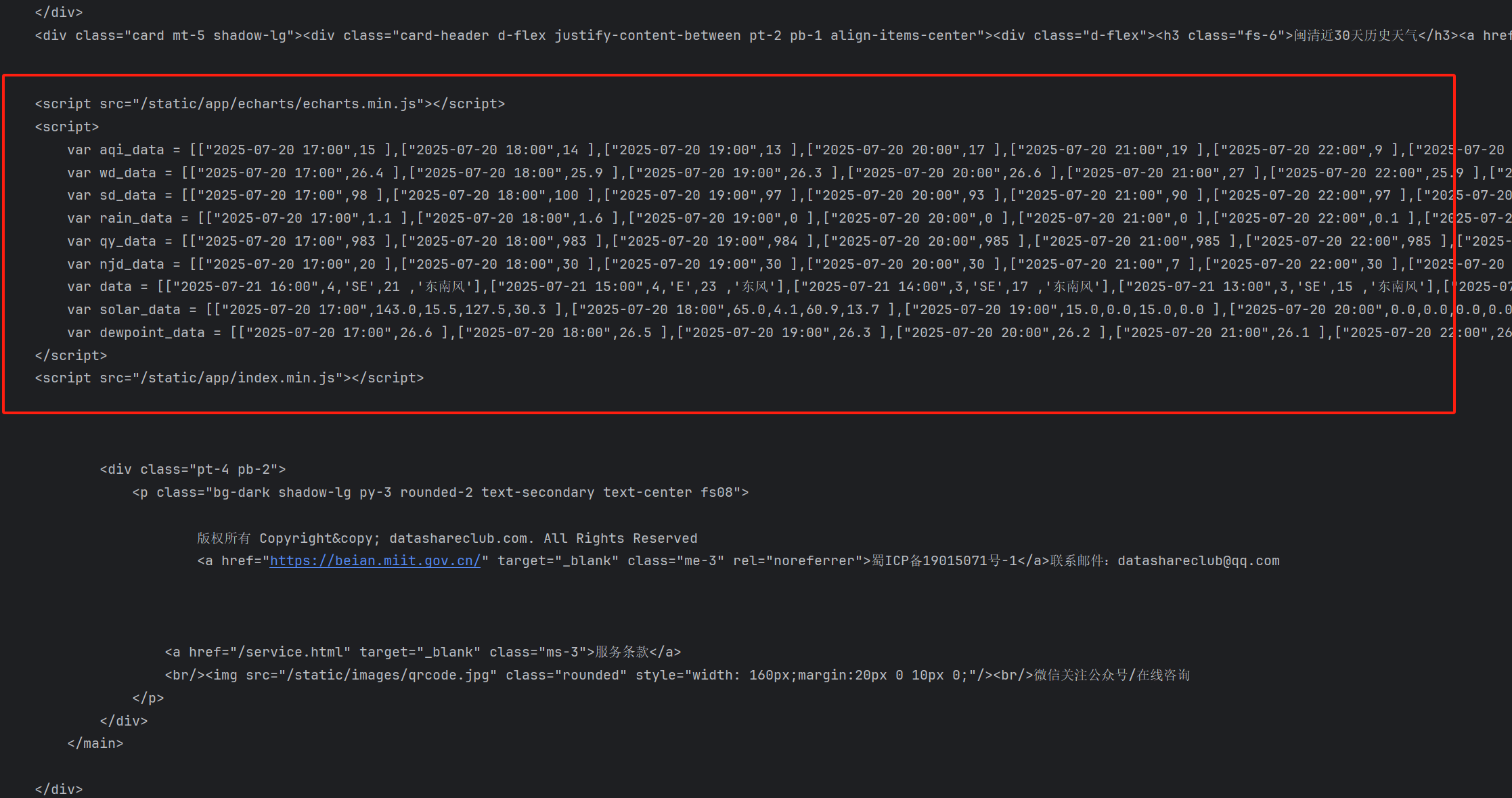
可以在控制台比较轻松的找到我们所需要的历史天气数据,接下来进行解析与提取既可
方法二:用开发者工具直接在浏览器进行查看(适用于较复杂的网页界面)
在浏览器中按F12进入开发者模式,然后进入“网络”或者“Network”,然后进行网页刷新
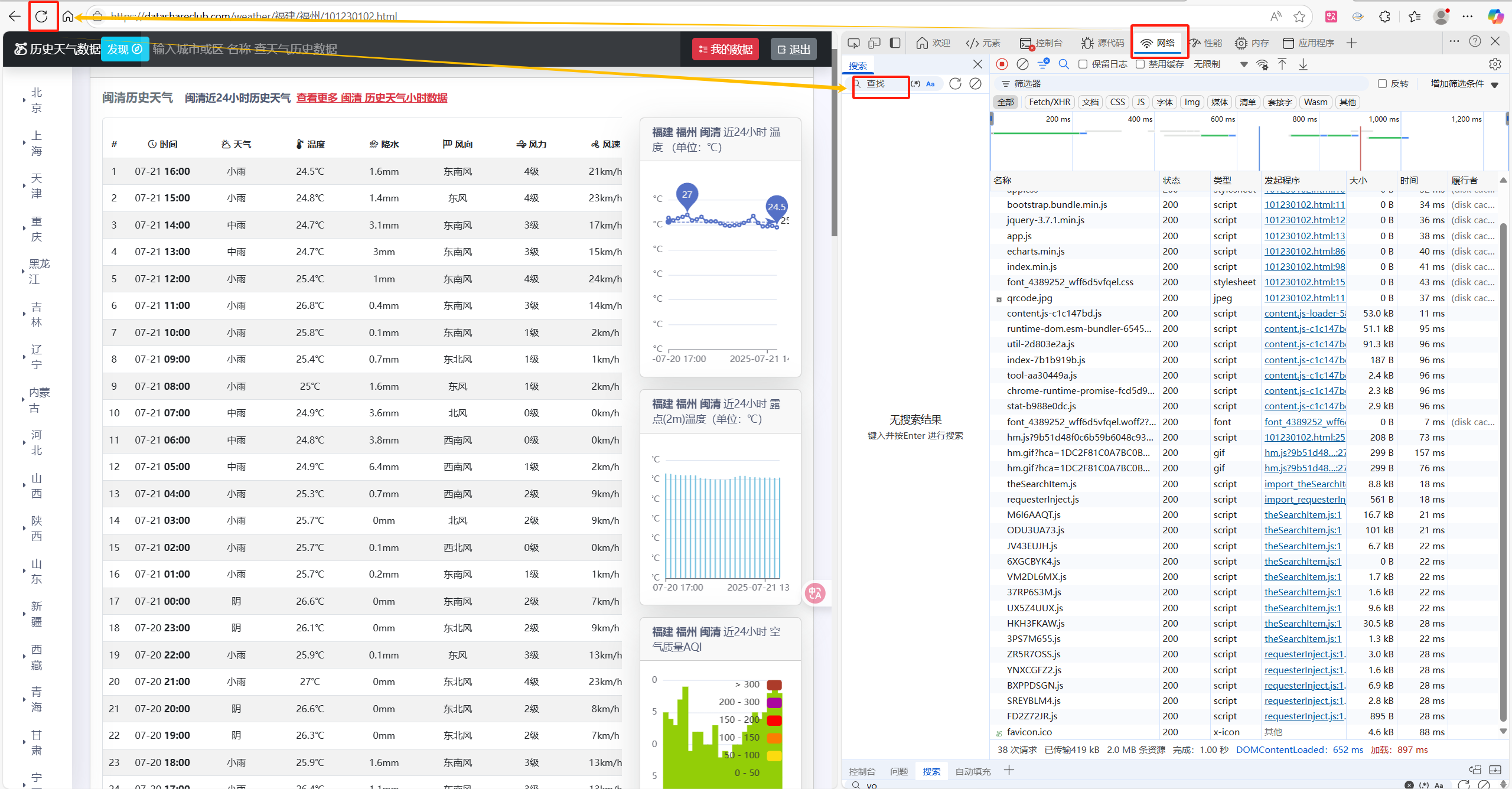
即可把浏览器的响应数据加载进去准备进行搜索,我们可以选取一个相对来说并不容易出现的数据和字符进行搜索,例如这边选择25.7度
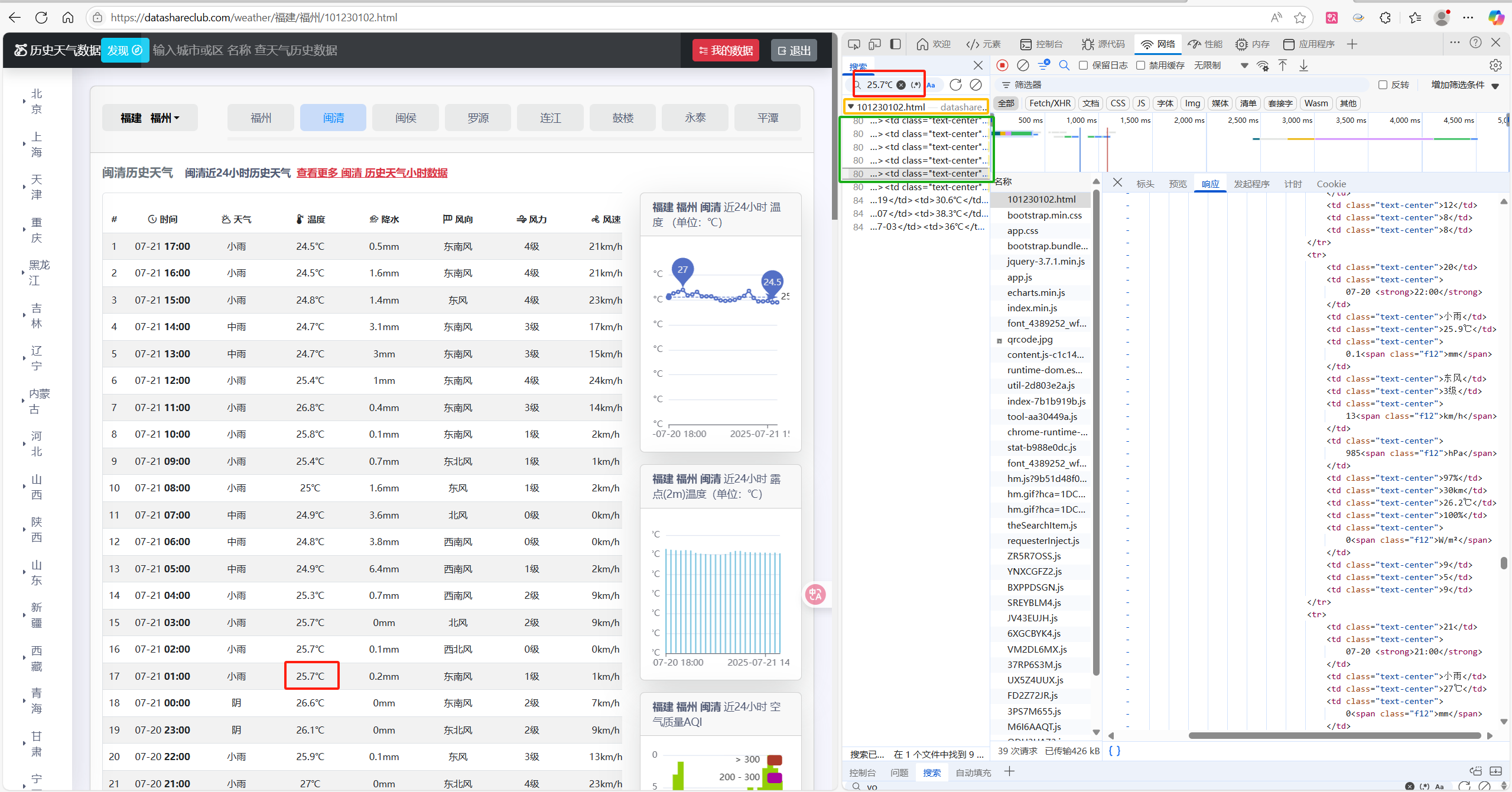
可以看到,黄色的部分表示这是101230102.html的响应数据,也就是我们需要用Request去访问的网址,绿色的这些地方就对应到该数据在响应数据中的具体位置,我们也可以通过这种方式来查找需要的数据在响应数据中的具体位置。
2、数据解析
解析函数如下:
import re
import ast
def extract_weather_data(html_content):
"""
从HTML内容中提取天气数据(针对提供的JS变量格式)
参数:
html_content (str): 包含天气数据的HTML/JS文本内容
返回:
dict: 结构化的天气数据字典,包含各类气象指标
"""
# 定义需要提取的JS变量及其对应的数据名称
data_vars = {
'aqi_data': '空气质量AQI',
'wd_data': '温度(℃)',
'sd_data': '湿度(%)',
'rain_data': '降水量(mm)',
'qy_data': '气压(hPa)',
'njd_data': '能见度(km)',
'data': '风向风力',
'solar_data': '太阳辐射(W/m²)',
'dewpoint_data': '露点温度(℃)'
}
# 存储提取后的所有数据
result = {}
# 遍历所有需要提取的变量
for var_name, desc in data_vars.items():
# 正则表达式:匹配 "var 变量名 = [数组内容];" 的结构
# 匹配规则:忽略空格,捕获数组部分
pattern = re.compile(
rf'var\s+{var_name}\s*=\s*(\[.*?\]);',
re.DOTALL # 让 .*? 可以匹配换行
)
# 查找匹配结果
match = pattern.search(html_content)
if not match:
result[desc] = []
continue
# 提取数组字符串并转换为Python列表
try:
# 去除可能的注释和多余字符,确保是标准数组格式
data_str = match.group(1).strip().rstrip(';')
# 使用ast.literal_eval安全转换字符串为Python对象(避免eval的安全问题)
data_list = ast.literal_eval(data_str)
result[desc] = data_list
except (SyntaxError, ValueError) as e:
print(f"提取 {desc} 失败:{str(e)}")
result[desc] = []
return result
解析函数需要根据具体的返回数据来定,这边对代码中的几个点进行解释
字典data_vars含义解释:
键:要提取的 JavaScript 变量名(如 ‘aqi_data’)
值:该变量对应的中文描述(如 ’ 空气质量 AQI’)
pattern = re.compile(
rf'var\s+{var_name}\s*=\s*(\[.*?\]);',
re.DOTALL # 让 .*? 可以匹配换行
)
这个地方是利用创造re正则表达式进行匹配
匹配类似 var aqi_data = [1,2,3]; 的 JS 变量定义
\s+和\s*:匹配任意数量的空格,使匹配更灵活
([.*?]): 捕获方括号及其中的内容(即数组数据)
re.DOTALL: 使.能匹配换行符,处理多行的数组定义
将解析之后的数据打印出来结果如下:

3、数据保存
这边写了两种数据保存为csv文件的函数,分别是不同指标保存到不同csv文件中和不同指标保存到同一个csv文件中,具体代码如下:
保存到不同csv文件中
import pandas as pd
import csv
def get_csv_row_count(file_path):
"""
读取CSV文件并返回行数(不包含标题行)
参数:
file_path (str): CSV文件路径
返回:
int: CSV文件的行数(不包含标题行)
异常:
FileNotFoundError: 如果文件不存在
pd.errors.ParserError: 如果文件格式错误
"""
try:
# 使用chunksize分块读取,避免加载整个文件到内存
chunk_size = 10000
row_count = 0
for chunk in pd.read_csv(file_path, chunksize=chunk_size):
row_count += len(chunk)
return row_count
except FileNotFoundError:
raise FileNotFoundError(f"文件不存在: {file_path}")
except pd.errors.ParserError as e:
raise ValueError(f"CSV解析错误: {str(e)}")
except Exception as e:
raise Exception(f"读取文件时发生未知错误: {str(e)}")
保存同一个csv文件中
def merge_to_single_csv(weather_data, output_file='2.csv'):
"""
将所有天气数据合并到一个CSV文件中
参数:
weather_data (dict): 提取的天气数据字典(由extract_weather_data函数返回)
output_file (str): 输出的CSV文件路径
返回:
str: 生成的CSV文件路径
"""
# 1. 收集所有时间点并去重、排序
all_timestamps = set()
for data_type, data_list in weather_data.items():
for item in data_list:
timestamp = item[0]
# 统一转换为datetime对象
dt = parse_time(timestamp)
# 转换回标准格式字符串
all_timestamps.add(format_time(dt))
# 排序时间点,使用智能解析函数
sorted_timestamps = sorted(all_timestamps, key=lambda x: parse_time(x))
# 2. 构建表头
headers = ['时间']
# 数据类型映射(用于简化表头)
data_type_mapping = {
'空气质量AQI': 'AQI',
'温度(℃)': '温度(℃)',
'湿度(%)': '湿度(%)',
'降水量(mm)': '降水量(mm)',
'气压(hPa)': '气压(hPa)',
'能见度(km)': '能见度(km)',
'风向风力': '风向风力',
'太阳辐射(W/m²)': '太阳辐射',
'露点温度(℃)': '露点温度(℃)'
}
# 为每种数据类型添加对应的列
for data_type in weather_data.keys():
if data_type == '风向风力':
headers.extend(['风力等级', '风向代码', '风速', '风向名称'])
elif data_type == '太阳辐射(W/m²)':
headers.extend(['短波辐射(W/m²)', '直接辐射(W/m²)', '散射辐射(W/m²)', '直接正常辐照度(W/m²)'])
else:
headers.append(data_type_mapping.get(data_type, data_type))
# 3. 构建数据行
rows = []
for timestamp in sorted_timestamps:
row = [timestamp]
# 为每个时间点收集所有数据
for data_type, data_list in weather_data.items():
# 查找该时间点对应的数据
data_point = None
for item in data_list:
item_timestamp = item[0]
# 统一格式后比较
if format_time(parse_time(item_timestamp)) == timestamp:
data_point = item
break
# 根据数据类型添加对应的值
if data_point:
if data_type == '风向风力':
row.extend(data_point[1:5]) # 风力等级、风向代码、风速、风向名称
elif data_type == '太阳辐射(W/m²)':
row.extend(data_point[1:5]) # 所有四个辐射指标
else:
row.append(data_point[1]) # 普通数据类型(只有一个值)
else:
# 无数据时填充空值
if data_type == '风向风力' or data_type == '太阳辐射(W/m²)':
row.extend([''] * 4) # 这两种数据类型各有4列
else:
row.append('') # 其他数据类型只有1列
rows.append(row)
# 4. 写入CSV文件
with open(output_file, 'w', newline='', encoding='utf-8-sig') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(headers)
writer.writerows(rows)
print(f"已生成综合CSV文件: {output_file} ({len(rows)} 条记录)")
return output_file
4、补充代码
这边补充两个对于时间进行解析的函数,分别对爬取到的时间数据进行预处理
def parse_time(time_str):
"""智能解析不同格式的时间字符串"""
if isinstance(time_str, datetime):
return time_str
try:
# 尝试解析带秒的格式
return datetime.strptime(time_str, '%Y-%m-%d %H:%M:%S')
except ValueError:
try:
# 尝试解析不带秒的格式
return datetime.strptime(time_str, '%Y-%m-%d %H:%M')
except ValueError:
# 如果是时间戳(整数或浮点数),转换为datetime
if isinstance(time_str, (int, float)):
timestamp = time_str / 1000.0 if time_str > 1000000000 else time_str
return datetime.fromtimestamp(timestamp)
# 无法解析的格式,返回原始值
print(f"警告: 无法解析时间格式: {time_str}")
return time_str
def format_time(dt):
"""将datetime对象格式化为标准字符串"""
if isinstance(dt, datetime):
return dt.strftime('%Y-%m-%d %H:%M:%S')
return str(dt)
parse_time用于智能解析不同格式的时间字符串
format_time用于将将datetime对象格式化为标准字符串
5、完整代码
完整代码如下:
import requests
from requests.exceptions import RequestException
import re
import ast
import csv
from datetime import datetime, timedelta
target_url="https://datashareclub.com/weather/%E7%A6%8F%E5%BB%BA/%E7%A6%8F%E5%B7%9E/101230102.html"
def parse_time(time_str):
"""智能解析不同格式的时间字符串"""
if isinstance(time_str, datetime):
return time_str
try:
# 尝试解析带秒的格式
return datetime.strptime(time_str, '%Y-%m-%d %H:%M:%S')
except ValueError:
try:
# 尝试解析不带秒的格式
return datetime.strptime(time_str, '%Y-%m-%d %H:%M')
except ValueError:
# 如果是时间戳(整数或浮点数),转换为datetime
if isinstance(time_str, (int, float)):
timestamp = time_str / 1000.0 if time_str > 1000000000 else time_str
return datetime.fromtimestamp(timestamp)
# 无法解析的格式,返回原始值
print(f"警告: 无法解析时间格式: {time_str}")
return time_str
def format_time(dt):
"""将datetime对象格式化为标准字符串"""
if isinstance(dt, datetime):
return dt.strftime('%Y-%m-%d %H:%M:%S')
return str(dt)
def fetch_url_content(url, headers=None, timeout=10):
"""
使用requests访问目标URL并返回响应内容
参数:
url (str): 要访问的目标URL
headers (dict, 可选): 请求头,默认使用模拟浏览器的User-Agent
timeout (int, 可选): 请求超时时间(秒),默认10秒
返回:
str: 响应文本内容(成功时);None(失败时)
"""
# 默认请求头(模拟浏览器,避免被简单反爬拦截)
default_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
# 如果用户传入自定义headers,合并到默认headers中(用户传入的优先)
if headers:
default_headers.update(headers)
try:
# 发送GET请求
response = requests.get(
url=url,
headers=default_headers,
timeout=timeout # 超时保护
)
# 检查响应状态码(200表示成功)
response.raise_for_status()
# 打印成功信息(可选,可删除)
print(f"✅ 访问成功:{url}(状态码:{response.status_code})")
# 返回响应文本(如果需要二进制内容,可改为 return response.content)
return response.text
except RequestException as e:
# 捕获所有requests相关异常(网络错误、超时、404/500等状态码)
print(f"❌ 访问失败:{url},错误:{str(e)}")
return None
except Exception as e:
# 捕获其他未知异常
print(f"❌ 未知错误:{url},错误:{str(e)}")
return None
def extract_weather_data(html_content):
"""
从HTML内容中提取天气数据(针对提供的JS变量格式)
参数:
html_content (str): 包含天气数据的HTML/JS文本内容
返回:
dict: 结构化的天气数据字典,包含各类气象指标
"""
# 定义需要提取的JS变量及其对应的数据名称
data_vars = {
'aqi_data': '空气质量AQI',
'wd_data': '温度(℃)',
'sd_data': '湿度(%)',
'rain_data': '降水量(mm)',
'qy_data': '气压(hPa)',
'njd_data': '能见度(km)',
'data': '风向风力',
'solar_data': '太阳辐射(W/m²)',
'dewpoint_data': '露点温度(℃)'
}
# 存储提取后的所有数据
result = {}
# 遍历所有需要提取的变量
for var_name, desc in data_vars.items():
# 正则表达式:匹配 "var 变量名 = [数组内容];" 的结构
# 匹配规则:忽略空格,捕获数组部分
pattern = re.compile(
rf'var\s+{var_name}\s*=\s*(\[.*?\]);',
re.DOTALL # 让 .*? 可以匹配换行
)
# 查找匹配结果
match = pattern.search(html_content)
if not match:
result[desc] = []
continue
# 提取数组字符串并转换为Python列表
try:
# 去除可能的注释和多余字符,确保是标准数组格式
data_str = match.group(1).strip().rstrip(';')
# 使用ast.literal_eval安全转换字符串为Python对象(避免eval的安全问题)
data_list = ast.literal_eval(data_str)
result[desc] = data_list
except (SyntaxError, ValueError) as e:
print(f"提取 {desc} 失败:{str(e)}")
result[desc] = []
return result
def merge_to_single_csv(weather_data, output_file='2.csv'):
"""
将所有天气数据合并到一个CSV文件中
参数:
weather_data (dict): 提取的天气数据字典(由extract_weather_data函数返回)
output_file (str): 输出的CSV文件路径
返回:
str: 生成的CSV文件路径
"""
# 1. 收集所有时间点并去重、排序
all_timestamps = set()
for data_type, data_list in weather_data.items():
for item in data_list:
timestamp = item[0]
# 统一转换为datetime对象
dt = parse_time(timestamp)
# 转换回标准格式字符串
all_timestamps.add(format_time(dt))
# 排序时间点,使用智能解析函数
sorted_timestamps = sorted(all_timestamps, key=lambda x: parse_time(x))
# 2. 构建表头
headers = ['时间']
# 数据类型映射(用于简化表头)
data_type_mapping = {
'空气质量AQI': 'AQI',
'温度(℃)': '温度(℃)',
'湿度(%)': '湿度(%)',
'降水量(mm)': '降水量(mm)',
'气压(hPa)': '气压(hPa)',
'能见度(km)': '能见度(km)',
'风向风力': '风向风力',
'太阳辐射(W/m²)': '太阳辐射',
'露点温度(℃)': '露点温度(℃)'
}
# 为每种数据类型添加对应的列
for data_type in weather_data.keys():
if data_type == '风向风力':
headers.extend(['风力等级', '风向代码', '风速', '风向名称'])
elif data_type == '太阳辐射(W/m²)':
headers.extend(['短波辐射(W/m²)', '直接辐射(W/m²)', '散射辐射(W/m²)', '直接正常辐照度(W/m²)'])
else:
headers.append(data_type_mapping.get(data_type, data_type))
# 3. 构建数据行
rows = []
for timestamp in sorted_timestamps:
row = [timestamp]
# 为每个时间点收集所有数据
for data_type, data_list in weather_data.items():
# 查找该时间点对应的数据
data_point = None
for item in data_list:
item_timestamp = item[0]
# 统一格式后比较
if format_time(parse_time(item_timestamp)) == timestamp:
data_point = item
break
# 根据数据类型添加对应的值
if data_point:
if data_type == '风向风力':
row.extend(data_point[1:5]) # 风力等级、风向代码、风速、风向名称
elif data_type == '太阳辐射(W/m²)':
row.extend(data_point[1:5]) # 所有四个辐射指标
else:
row.append(data_point[1]) # 普通数据类型(只有一个值)
else:
# 无数据时填充空值
if data_type == '风向风力' or data_type == '太阳辐射(W/m²)':
row.extend([''] * 4) # 这两种数据类型各有4列
else:
row.append('') # 其他数据类型只有1列
rows.append(row)
# 4. 写入CSV文件
with open(output_file, 'w', newline='', encoding='utf-8-sig') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(headers)
writer.writerows(rows)
print(f"已生成综合CSV文件: {output_file} ({len(rows)} 条记录)")
return output_file
def crawler(url):
content = fetch_url_content(url)
if content:
print("\n--- 响应内容---")
print(content)
print('成功响应')
merge_to_single_csv(extract_weather_data(content),'10.csv')
crawler(target_url)
三、总结
在不涉及到较为复杂的反爬加密的情况下,爬虫基本都是一个固定的思路,即参照本文的目录来就可以,根据自己的需求选择目标网址并进行分析,编写代码进行数据的访问以及解析保存等操作。各个网站主要的不同点都是在于数据解析的部分,因为其数据存储结构各不相同,基本上只需要修改这一部分的代码即可,并且很多时候如果把响应数据直接发给ai,让其帮忙写一份解析函数出来再稍加修改,基本也能实现这个功能。
爬蟲專欄:基於Python實現歷史天氣數據爬取
爬取 datashareclub 24 小時歷史天氣:requests 抓取、正則解析 JS 變數、合併 CSV 保存,附完整可執行程式碼。
來源:https://blog.csdn.net/2403_87969572/article/details/149509113
抓取時間(ISO本地):2026-05-18 05:16:58
文章目錄
前言
由於樹莓派巡檢小車部分預測功能的需求,現在需要實現當地天氣的python爬蟲進行數據獲取。需要的數據有溫度、溼度、降雨量、光照強度、是否下雨等。(但實際爬取的數據取決於目標網站,我選取的網站遠遠不止這幾個數據),接下來進入實現部分。
一、目標網址的選取與域名熟悉
1、網址選取
選取的目標網址為:全國曆史天氣查詢平臺
可以看到這邊提供以小時為間隔的前24小時歷史間隔數據,包括且不限於天氣、溫度、降水、風向 、風力 、風速、氣壓、溼度等,符合我們的要求。
2、分析界面
隨便訪問了兩個地方的天氣數據對應的子頁面,可以看到相同的地方是前面的https://datashareclub.com/weather/以及福建/福州,不同的地方是之後的編碼一個是01230103 一個是01230102,對應我們所選擇的具體區縣。
因此我們可以將這整個網址分為三部分
我們只需要修改綠色黃色相應的部分就可以訪問到具體對應的24小時歷史天氣數據子頁面,這有利於我們進行批量的天氣數據爬取。但是本次我們只需要用到福建省福州市閩侯縣的天氣數據就好。
二、代碼實踐部分
1、初步查看響應
方法一:用Request進行請求後直接輸出內容(適用於較為簡單的網頁界面)
首先構建一個進行請求的python函數fetch_url_content
import requests
from requests.exceptions import RequestException
target_url="https://datashareclub.com/weather/%E7%A6%8F%E5%BB%BA/%E7%A6%8F%E5%B7%9E/101230102.html"
def fetch_url_content(url, headers=None, timeout=10):
"""
使用requests訪問目標URL並返回響應內容
參數:
url (str): 要訪問的目標URL
headers (dict, 可選): 請求頭,默認使用模擬瀏覽器的User-Agent
timeout (int, 可選): 請求超時時間(秒),默認10秒
返回:
str: 響應文本內容(成功時);None(失敗時)
"""
# 默認請求頭(模擬瀏覽器,避免被簡單反爬攔截)
default_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
# 如果用戶傳入自定義headers,合併到默認headers中(用戶傳入的優先)
if headers:
default_headers.update(headers)
try:
# 發送GET請求
response = requests.get(
url=url,
headers=default_headers,
timeout=timeout # 超時保護
)
# 檢查響應狀態碼(200表示成功)
response.raise_for_status()
# 打印成功信息(可選,可刪除)
print(f"✅ 訪問成功:{url}(狀態碼:{response.status_code})")
# 返回響應文本(如果需要二進制內容,可改為 return response.content)
return response.text
except RequestException as e:
# 捕獲所有requests相關異常(網絡錯誤、超時、404/500等狀態碼)
print(f"❌ 訪問失敗:{url},錯誤:{str(e)}")
return None
except Exception as e:
# 捕獲其他未知異常
print(f"❌ 未知錯誤:{url},錯誤:{str(e)}")
return None
def crawler(url):
content = fetch_url_content(url)
if content:
print("\n--- 響應內容---")
print(content)
print('成功響應')
crwaler(target_url)
代碼運行結果如下
可以在控制檯比較輕鬆的找到我們所需要的歷史天氣數據,接下來進行解析與提取既可
方法二:用開發者工具直接在瀏覽器進行查看(適用於較複雜的網頁界面)
在瀏覽器中按F12進入開發者模式,然後進入“網絡”或者“Network”,然後進行網頁刷新
即可把瀏覽器的響應數據加載進去準備進行搜索,我們可以選取一個相對來說並不容易出現的數據和字符進行搜索,例如這邊選擇25.7度
可以看到,黃色的部分表示這是101230102.html的響應數據,也就是我們需要用Request去訪問的網址,綠色的這些地方就對應到該數據在響應數據中的具體位置,我們也可以通過這種方式來查找需要的數據在響應數據中的具體位置。
2、數據解析
解析函數如下:
import re
import ast
def extract_weather_data(html_content):
"""
從HTML內容中提取天氣數據(針對提供的JS變量格式)
參數:
html_content (str): 包含天氣數據的HTML/JS文本內容
返回:
dict: 結構化的天氣數據字典,包含各類氣象指標
"""
# 定義需要提取的JS變量及其對應的數據名稱
data_vars = {
'aqi_data': '空氣質量AQI',
'wd_data': '溫度(℃)',
'sd_data': '溼度(%)',
'rain_data': '降水量(mm)',
'qy_data': '氣壓(hPa)',
'njd_data': '能見度(km)',
'data': '風向風力',
'solar_data': '太陽輻射(W/m²)',
'dewpoint_data': '露點溫度(℃)'
}
# 存儲提取後的所有數據
result = {}
# 遍歷所有需要提取的變量
for var_name, desc in data_vars.items():
# 正則表達式:匹配 "var 變量名 = [數組內容];" 的結構
# 匹配規則:忽略空格,捕獲數組部分
pattern = re.compile(
rf'var\s+{var_name}\s*=\s*(\[.*?\]);',
re.DOTALL # 讓 .*? 可以匹配換行
)
# 查找匹配結果
match = pattern.search(html_content)
if not match:
result[desc] = []
continue
# 提取數組字符串並轉換為Python列表
try:
# 去除可能的註釋和多餘字符,確保是標準數組格式
data_str = match.group(1).strip().rstrip(';')
# 使用ast.literal_eval安全轉換字符串為Python對象(避免eval的安全問題)
data_list = ast.literal_eval(data_str)
result[desc] = data_list
except (SyntaxError, ValueError) as e:
print(f"提取 {desc} 失敗:{str(e)}")
result[desc] = []
return result
解析函數需要根據具體的返回數據來定,這邊對代碼中的幾個點進行解釋
字典data_vars含義解釋:
鍵:要提取的 JavaScript 變量名(如 ‘aqi_data’)
值:該變量對應的中文描述(如 ’ 空氣質量 AQI’)
pattern = re.compile(
rf'var\s+{var_name}\s*=\s*(\[.*?\]);',
re.DOTALL # 讓 .*? 可以匹配換行
)
這個地方是利用創造re正則表達式進行匹配
匹配類似 var aqi_data = [1,2,3]; 的 JS 變量定義
\s+和\s*:匹配任意數量的空格,使匹配更靈活
([.*?]): 捕獲方括號及其中的內容(即數組數據)
re.DOTALL: 使.能匹配換行符,處理多行的數組定義
將解析之後的數據打印出來結果如下:
3、數據保存
這邊寫了兩種數據保存為csv文件的函數,分別是不同指標保存到不同csv文件中和不同指標保存到同一個csv文件中,具體代碼如下:
保存到不同csv文件中
import pandas as pd
import csv
def get_csv_row_count(file_path):
"""
讀取CSV文件並返回行數(不包含標題行)
參數:
file_path (str): CSV文件路徑
返回:
int: CSV文件的行數(不包含標題行)
異常:
FileNotFoundError: 如果文件不存在
pd.errors.ParserError: 如果文件格式錯誤
"""
try:
# 使用chunksize分塊讀取,避免加載整個文件到內存
chunk_size = 10000
row_count = 0
for chunk in pd.read_csv(file_path, chunksize=chunk_size):
row_count += len(chunk)
return row_count
except FileNotFoundError:
raise FileNotFoundError(f"文件不存在: {file_path}")
except pd.errors.ParserError as e:
raise ValueError(f"CSV解析錯誤: {str(e)}")
except Exception as e:
raise Exception(f"讀取文件時發生未知錯誤: {str(e)}")
保存同一個csv文件中
def merge_to_single_csv(weather_data, output_file='2.csv'):
"""
將所有天氣數據合併到一個CSV文件中
參數:
weather_data (dict): 提取的天氣數據字典(由extract_weather_data函數返回)
output_file (str): 輸出的CSV文件路徑
返回:
str: 生成的CSV文件路徑
"""
# 1. 收集所有時間點並去重、排序
all_timestamps = set()
for data_type, data_list in weather_data.items():
for item in data_list:
timestamp = item[0]
# 統一轉換為datetime對象
dt = parse_time(timestamp)
# 轉換回標準格式字符串
all_timestamps.add(format_time(dt))
# 排序時間點,使用智能解析函數
sorted_timestamps = sorted(all_timestamps, key=lambda x: parse_time(x))
# 2. 構建表頭
headers = ['時間']
# 數據類型映射(用於簡化表頭)
data_type_mapping = {
'空氣質量AQI': 'AQI',
'溫度(℃)': '溫度(℃)',
'溼度(%)': '溼度(%)',
'降水量(mm)': '降水量(mm)',
'氣壓(hPa)': '氣壓(hPa)',
'能見度(km)': '能見度(km)',
'風向風力': '風向風力',
'太陽輻射(W/m²)': '太陽輻射',
'露點溫度(℃)': '露點溫度(℃)'
}
# 為每種數據類型添加對應的列
for data_type in weather_data.keys():
if data_type == '風向風力':
headers.extend(['風力等級', '風向代碼', '風速', '風向名稱'])
elif data_type == '太陽輻射(W/m²)':
headers.extend(['短波輻射(W/m²)', '直接輻射(W/m²)', '散射輻射(W/m²)', '直接正常輻照度(W/m²)'])
else:
headers.append(data_type_mapping.get(data_type, data_type))
# 3. 構建數據行
rows = []
for timestamp in sorted_timestamps:
row = [timestamp]
# 為每個時間點收集所有數據
for data_type, data_list in weather_data.items():
# 查找該時間點對應的數據
data_point = None
for item in data_list:
item_timestamp = item[0]
# 統一格式後比較
if format_time(parse_time(item_timestamp)) == timestamp:
data_point = item
break
# 根據數據類型添加對應的值
if data_point:
if data_type == '風向風力':
row.extend(data_point[1:5]) # 風力等級、風向代碼、風速、風向名稱
elif data_type == '太陽輻射(W/m²)':
row.extend(data_point[1:5]) # 所有四個輻射指標
else:
row.append(data_point[1]) # 普通數據類型(只有一個值)
else:
# 無數據時填充空值
if data_type == '風向風力' or data_type == '太陽輻射(W/m²)':
row.extend([''] * 4) # 這兩種數據類型各有4列
else:
row.append('') # 其他數據類型只有1列
rows.append(row)
# 4. 寫入CSV文件
with open(output_file, 'w', newline='', encoding='utf-8-sig') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(headers)
writer.writerows(rows)
print(f"已生成綜合CSV文件: {output_file} ({len(rows)} 條記錄)")
return output_file
4、補充代碼
這邊補充兩個對於時間進行解析的函數,分別對爬取到的時間數據進行預處理
def parse_time(time_str):
"""智能解析不同格式的時間字符串"""
if isinstance(time_str, datetime):
return time_str
try:
# 嘗試解析帶秒的格式
return datetime.strptime(time_str, '%Y-%m-%d %H:%M:%S')
except ValueError:
try:
# 嘗試解析不帶秒的格式
return datetime.strptime(time_str, '%Y-%m-%d %H:%M')
except ValueError:
# 如果是時間戳(整數或浮點數),轉換為datetime
if isinstance(time_str, (int, float)):
timestamp = time_str / 1000.0 if time_str > 1000000000 else time_str
return datetime.fromtimestamp(timestamp)
# 無法解析的格式,返回原始值
print(f"警告: 無法解析時間格式: {time_str}")
return time_str
def format_time(dt):
"""將datetime對象格式化為標準字符串"""
if isinstance(dt, datetime):
return dt.strftime('%Y-%m-%d %H:%M:%S')
return str(dt)
parse_time用於智能解析不同格式的時間字符串
format_time用於將將datetime對象格式化為標準字符串
5、完整代碼
完整代碼如下:
import requests
from requests.exceptions import RequestException
import re
import ast
import csv
from datetime import datetime, timedelta
target_url="https://datashareclub.com/weather/%E7%A6%8F%E5%BB%BA/%E7%A6%8F%E5%B7%9E/101230102.html"
def parse_time(time_str):
"""智能解析不同格式的時間字符串"""
if isinstance(time_str, datetime):
return time_str
try:
# 嘗試解析帶秒的格式
return datetime.strptime(time_str, '%Y-%m-%d %H:%M:%S')
except ValueError:
try:
# 嘗試解析不帶秒的格式
return datetime.strptime(time_str, '%Y-%m-%d %H:%M')
except ValueError:
# 如果是時間戳(整數或浮點數),轉換為datetime
if isinstance(time_str, (int, float)):
timestamp = time_str / 1000.0 if time_str > 1000000000 else time_str
return datetime.fromtimestamp(timestamp)
# 無法解析的格式,返回原始值
print(f"警告: 無法解析時間格式: {time_str}")
return time_str
def format_time(dt):
"""將datetime對象格式化為標準字符串"""
if isinstance(dt, datetime):
return dt.strftime('%Y-%m-%d %H:%M:%S')
return str(dt)
def fetch_url_content(url, headers=None, timeout=10):
"""
使用requests訪問目標URL並返回響應內容
參數:
url (str): 要訪問的目標URL
headers (dict, 可選): 請求頭,默認使用模擬瀏覽器的User-Agent
timeout (int, 可選): 請求超時時間(秒),默認10秒
返回:
str: 響應文本內容(成功時);None(失敗時)
"""
# 默認請求頭(模擬瀏覽器,避免被簡單反爬攔截)
default_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
# 如果用戶傳入自定義headers,合併到默認headers中(用戶傳入的優先)
if headers:
default_headers.update(headers)
try:
# 發送GET請求
response = requests.get(
url=url,
headers=default_headers,
timeout=timeout # 超時保護
)
# 檢查響應狀態碼(200表示成功)
response.raise_for_status()
# 打印成功信息(可選,可刪除)
print(f"✅ 訪問成功:{url}(狀態碼:{response.status_code})")
# 返回響應文本(如果需要二進制內容,可改為 return response.content)
return response.text
except RequestException as e:
# 捕獲所有requests相關異常(網絡錯誤、超時、404/500等狀態碼)
print(f"❌ 訪問失敗:{url},錯誤:{str(e)}")
return None
except Exception as e:
# 捕獲其他未知異常
print(f"❌ 未知錯誤:{url},錯誤:{str(e)}")
return None
def extract_weather_data(html_content):
"""
從HTML內容中提取天氣數據(針對提供的JS變量格式)
參數:
html_content (str): 包含天氣數據的HTML/JS文本內容
返回:
dict: 結構化的天氣數據字典,包含各類氣象指標
"""
# 定義需要提取的JS變量及其對應的數據名稱
data_vars = {
'aqi_data': '空氣質量AQI',
'wd_data': '溫度(℃)',
'sd_data': '溼度(%)',
'rain_data': '降水量(mm)',
'qy_data': '氣壓(hPa)',
'njd_data': '能見度(km)',
'data': '風向風力',
'solar_data': '太陽輻射(W/m²)',
'dewpoint_data': '露點溫度(℃)'
}
# 存儲提取後的所有數據
result = {}
# 遍歷所有需要提取的變量
for var_name, desc in data_vars.items():
# 正則表達式:匹配 "var 變量名 = [數組內容];" 的結構
# 匹配規則:忽略空格,捕獲數組部分
pattern = re.compile(
rf'var\s+{var_name}\s*=\s*(\[.*?\]);',
re.DOTALL # 讓 .*? 可以匹配換行
)
# 查找匹配結果
match = pattern.search(html_content)
if not match:
result[desc] = []
continue
# 提取數組字符串並轉換為Python列表
try:
# 去除可能的註釋和多餘字符,確保是標準數組格式
data_str = match.group(1).strip().rstrip(';')
# 使用ast.literal_eval安全轉換字符串為Python對象(避免eval的安全問題)
data_list = ast.literal_eval(data_str)
result[desc] = data_list
except (SyntaxError, ValueError) as e:
print(f"提取 {desc} 失敗:{str(e)}")
result[desc] = []
return result
def merge_to_single_csv(weather_data, output_file='2.csv'):
"""
將所有天氣數據合併到一個CSV文件中
參數:
weather_data (dict): 提取的天氣數據字典(由extract_weather_data函數返回)
output_file (str): 輸出的CSV文件路徑
返回:
str: 生成的CSV文件路徑
"""
# 1. 收集所有時間點並去重、排序
all_timestamps = set()
for data_type, data_list in weather_data.items():
for item in data_list:
timestamp = item[0]
# 統一轉換為datetime對象
dt = parse_time(timestamp)
# 轉換回標準格式字符串
all_timestamps.add(format_time(dt))
# 排序時間點,使用智能解析函數
sorted_timestamps = sorted(all_timestamps, key=lambda x: parse_time(x))
# 2. 構建表頭
headers = ['時間']
# 數據類型映射(用於簡化表頭)
data_type_mapping = {
'空氣質量AQI': 'AQI',
'溫度(℃)': '溫度(℃)',
'溼度(%)': '溼度(%)',
'降水量(mm)': '降水量(mm)',
'氣壓(hPa)': '氣壓(hPa)',
'能見度(km)': '能見度(km)',
'風向風力': '風向風力',
'太陽輻射(W/m²)': '太陽輻射',
'露點溫度(℃)': '露點溫度(℃)'
}
# 為每種數據類型添加對應的列
for data_type in weather_data.keys():
if data_type == '風向風力':
headers.extend(['風力等級', '風向代碼', '風速', '風向名稱'])
elif data_type == '太陽輻射(W/m²)':
headers.extend(['短波輻射(W/m²)', '直接輻射(W/m²)', '散射輻射(W/m²)', '直接正常輻照度(W/m²)'])
else:
headers.append(data_type_mapping.get(data_type, data_type))
# 3. 構建數據行
rows = []
for timestamp in sorted_timestamps:
row = [timestamp]
# 為每個時間點收集所有數據
for data_type, data_list in weather_data.items():
# 查找該時間點對應的數據
data_point = None
for item in data_list:
item_timestamp = item[0]
# 統一格式後比較
if format_time(parse_time(item_timestamp)) == timestamp:
data_point = item
break
# 根據數據類型添加對應的值
if data_point:
if data_type == '風向風力':
row.extend(data_point[1:5]) # 風力等級、風向代碼、風速、風向名稱
elif data_type == '太陽輻射(W/m²)':
row.extend(data_point[1:5]) # 所有四個輻射指標
else:
row.append(data_point[1]) # 普通數據類型(只有一個值)
else:
# 無數據時填充空值
if data_type == '風向風力' or data_type == '太陽輻射(W/m²)':
row.extend([''] * 4) # 這兩種數據類型各有4列
else:
row.append('') # 其他數據類型只有1列
rows.append(row)
# 4. 寫入CSV文件
with open(output_file, 'w', newline='', encoding='utf-8-sig') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(headers)
writer.writerows(rows)
print(f"已生成綜合CSV文件: {output_file} ({len(rows)} 條記錄)")
return output_file
def crawler(url):
content = fetch_url_content(url)
if content:
print("\n--- 響應內容---")
print(content)
print('成功響應')
merge_to_single_csv(extract_weather_data(content),'10.csv')
crawler(target_url)
三、總結
在不涉及到較為複雜的反爬加密的情況下,爬蟲基本都是一個固定的思路,即參照本文的目錄來就可以,根據自己的需求選擇目標網址並進行分析,編寫代碼進行數據的訪問以及解析保存等操作。各個網站主要的不同點都是在於數據解析的部分,因為其數據存儲結構各不相同,基本上只需要修改這一部分的代碼即可,並且很多時候如果把響應數據直接發給ai,讓其幫忙寫一份解析函數出來再稍加修改,基本也能實現這個功能。
Crawler Column: Historical Weather in Python
Scrape datashareclub hourly weather via requests, regex on JS vars, and merged CSV export with full runnable code.
Captured at (local ISO): 2026-05-18 05:16:58
Preface
A Raspberry Pi inspection rover needed local weather features—temperature, humidity, rain, light, “is it raining,” etc. (what you actually get depends on the provider; the site I picked exposes far more fields.) Below is the build-out.
I. Picking a site and URL pattern
1. Site choice
Target: 全国历史天气查询平台
Hourly last-24-hours history: weather code, temp, precip, wind dir/speed, pressure, humidity, and more—fits the bill.
2. Page anatomy
Two county pages share the prefix https://datashareclub.com/weather/ plus 福建/福州/, but the trailing code differs (01230103 vs 01230102)—that tail is the district key.
Split the URL into three parts:
Swap the green and yellow segments to bulk-scrape other districts. For this note we only need 闽侯 under Fuzhou, Fujian.
II. Implementation
1. Inspect the response
Method A: print HTML from requests (simple pages)
Start with a small fetch helper fetch_url_content:
import requests
from requests.exceptions import RequestException
target_url="https://datashareclub.com/weather/%E7%A6%8F%E5%BB%BA/%E7%A6%8F%E5%B7%9E/101230102.html"
def fetch_url_content(url, headers=None, timeout=10):
"""
使用requests访问目标URL并返回响应内容
参数:
url (str): 要访问的目标URL
headers (dict, 可选): 请求头,默认使用模拟浏览器的User-Agent
timeout (int, 可选): 请求超时时间(秒),默认10秒
返回:
str: 响应文本内容(成功时);None(失败时)
"""
# 默认请求头(模拟浏览器,避免被简单反爬拦截)
default_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
# 如果用户传入自定义headers,合并到默认headers中(用户传入的优先)
if headers:
default_headers.update(headers)
try:
# 发送GET请求
response = requests.get(
url=url,
headers=default_headers,
timeout=timeout # 超时保护
)
# 检查响应状态码(200表示成功)
response.raise_for_status()
# 打印成功信息(可选,可删除)
print(f"✅ 访问成功:{url}(状态码:{response.status_code})")
# 返回响应文本(如果需要二进制内容,可改为 return response.content)
return response.text
except RequestException as e:
# 捕获所有requests相关异常(网络错误、超时、404/500等状态码)
print(f"❌ 访问失败:{url},错误:{str(e)}")
return None
except Exception as e:
# 捕获其他未知异常
print(f"❌ 未知错误:{url},错误:{str(e)}")
return None
def crawler(url):
content = fetch_url_content(url)
if content:
print("\n--- 响应内容---")
print(content)
print('成功响应')
crwaler(target_url)
Run output:
Once you eyeball where the series live in HTML/JS, move on to structured parsing.
Method B: DevTools Network tab (messy pages)
F12 → Network → reload—inspect the document for 101230102.html.
Search for a distinctive value like 25.7°C:
Yellow: response belongs to 101230102.html; Green: substring positions—guides regex/string extraction.
2. Parsing
import re
import ast
def extract_weather_data(html_content):
"""
从HTML内容中提取天气数据(针对提供的JS变量格式)
参数:
html_content (str): 包含天气数据的HTML/JS文本内容
返回:
dict: 结构化的天气数据字典,包含各类气象指标
"""
# 定义需要提取的JS变量及其对应的数据名称
data_vars = {
'aqi_data': '空气质量AQI',
'wd_data': '温度(℃)',
'sd_data': '湿度(%)',
'rain_data': '降水量(mm)',
'qy_data': '气压(hPa)',
'njd_data': '能见度(km)',
'data': '风向风力',
'solar_data': '太阳辐射(W/m²)',
'dewpoint_data': '露点温度(℃)'
}
# 存储提取后的所有数据
result = {}
# 遍历所有需要提取的变量
for var_name, desc in data_vars.items():
# 正则表达式:匹配 "var 变量名 = [数组内容];" 的结构
# 匹配规则:忽略空格,捕获数组部分
pattern = re.compile(
rf'var\s+{var_name}\s*=\s*(\[.*?\]);',
re.DOTALL # 让 .*? 可以匹配换行
)
# 查找匹配结果
match = pattern.search(html_content)
if not match:
result[desc] = []
continue
# 提取数组字符串并转换为Python列表
try:
# 去除可能的注释和多余字符,确保是标准数组格式
data_str = match.group(1).strip().rstrip(';')
# 使用ast.literal_eval安全转换字符串为Python对象(避免eval的安全问题)
data_list = ast.literal_eval(data_str)
result[desc] = data_list
except (SyntaxError, ValueError) as e:
print(f"提取 {desc} 失败:{str(e)}")
result[desc] = []
return result
Parser is site-specific—notes on data_vars and the regex:
data_vars: keys are JS identifiers (aqi_data, …); values are human labels.
pattern = re.compile(
rf'var\s+{var_name}\s*=\s*(\[.*?\]);',
re.DOTALL # 让 .*? 可以匹配换行
)
Matches var name = [...];, re.DOTALL lets . cross lines.
Parsed dump:
3. Saving CSV
Two helpers: per-series files vs one wide CSV. Snippets:
get_csv_row_count (per-file row count helper):
import pandas as pd
import csv
def get_csv_row_count(file_path):
"""
读取CSV文件并返回行数(不包含标题行)
参数:
file_path (str): CSV文件路径
返回:
int: CSV文件的行数(不包含标题行)
异常:
FileNotFoundError: 如果文件不存在
pd.errors.ParserError: 如果文件格式错误
"""
try:
# 使用chunksize分块读取,避免加载整个文件到内存
chunk_size = 10000
row_count = 0
for chunk in pd.read_csv(file_path, chunksize=chunk_size):
row_count += len(chunk)
return row_count
except FileNotFoundError:
raise FileNotFoundError(f"文件不存在: {file_path}")
except pd.errors.ParserError as e:
raise ValueError(f"CSV解析错误: {str(e)}")
except Exception as e:
raise Exception(f"读取文件时发生未知错误: {str(e)}")
Wide merge:
def merge_to_single_csv(weather_data, output_file='2.csv'):
"""
将所有天气数据合并到一个CSV文件中
参数:
weather_data (dict): 提取的天气数据字典(由extract_weather_data函数返回)
output_file (str): 输出的CSV文件路径
返回:
str: 生成的CSV文件路径
"""
# 1. 收集所有时间点并去重、排序
all_timestamps = set()
for data_type, data_list in weather_data.items():
for item in data_list:
timestamp = item[0]
# 统一转换为datetime对象
dt = parse_time(timestamp)
# 转换回标准格式字符串
all_timestamps.add(format_time(dt))
# 排序时间点,使用智能解析函数
sorted_timestamps = sorted(all_timestamps, key=lambda x: parse_time(x))
# 2. 构建表头
headers = ['时间']
# 数据类型映射(用于简化表头)
data_type_mapping = {
'空气质量AQI': 'AQI',
'温度(℃)': '温度(℃)',
'湿度(%)': '湿度(%)',
'降水量(mm)': '降水量(mm)',
'气压(hPa)': '气压(hPa)',
'能见度(km)': '能见度(km)',
'风向风力': '风向风力',
'太阳辐射(W/m²)': '太阳辐射',
'露点温度(℃)': '露点温度(℃)'
}
# 为每种数据类型添加对应的列
for data_type in weather_data.keys():
if data_type == '风向风力':
headers.extend(['风力等级', '风向代码', '风速', '风向名称'])
elif data_type == '太阳辐射(W/m²)':
headers.extend(['短波辐射(W/m²)', '直接辐射(W/m²)', '散射辐射(W/m²)', '直接正常辐照度(W/m²)'])
else:
headers.append(data_type_mapping.get(data_type, data_type))
# 3. 构建数据行
rows = []
for timestamp in sorted_timestamps:
row = [timestamp]
# 为每个时间点收集所有数据
for data_type, data_list in weather_data.items():
# 查找该时间点对应的数据
data_point = None
for item in data_list:
item_timestamp = item[0]
# 统一格式后比较
if format_time(parse_time(item_timestamp)) == timestamp:
data_point = item
break
# 根据数据类型添加对应的值
if data_point:
if data_type == '风向风力':
row.extend(data_point[1:5]) # 风力等级、风向代码、风速、风向名称
elif data_type == '太阳辐射(W/m²)':
row.extend(data_point[1:5]) # 所有四个辐射指标
else:
row.append(data_point[1]) # 普通数据类型(只有一个值)
else:
# 无数据时填充空值
if data_type == '风向风力' or data_type == '太阳辐射(W/m²)':
row.extend([''] * 4) # 这两种数据类型各有4列
else:
row.append('') # 其他数据类型只有1列
rows.append(row)
# 4. 写入CSV文件
with open(output_file, 'w', newline='', encoding='utf-8-sig') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(headers)
writer.writerows(rows)
print(f"已生成综合CSV文件: {output_file} ({len(rows)} 条记录)")
return output_file
4. Helper utilities
Time normalizers:
def parse_time(time_str):
"""智能解析不同格式的时间字符串"""
if isinstance(time_str, datetime):
return time_str
try:
# 尝试解析带秒的格式
return datetime.strptime(time_str, '%Y-%m-%d %H:%M:%S')
except ValueError:
try:
# 尝试解析不带秒的格式
return datetime.strptime(time_str, '%Y-%m-%d %H:%M')
except ValueError:
# 如果是时间戳(整数或浮点数),转换为datetime
if isinstance(time_str, (int, float)):
timestamp = time_str / 1000.0 if time_str > 1000000000 else time_str
return datetime.fromtimestamp(timestamp)
# 无法解析的格式,返回原始值
print(f"警告: 无法解析时间格式: {time_str}")
return time_str
def format_time(dt):
"""将datetime对象格式化为标准字符串"""
if isinstance(dt, datetime):
return dt.strftime('%Y-%m-%d %H:%M:%S')
return str(dt)
parse_time handles heterogeneous stamps; format_time canonicalizes to a string key.
5. Full script
import requests
from requests.exceptions import RequestException
import re
import ast
import csv
from datetime import datetime, timedelta
target_url="https://datashareclub.com/weather/%E7%A6%8F%E5%BB%BA/%E7%A6%8F%E5%B7%9E/101230102.html"
def parse_time(time_str):
"""智能解析不同格式的时间字符串"""
if isinstance(time_str, datetime):
return time_str
try:
# 尝试解析带秒的格式
return datetime.strptime(time_str, '%Y-%m-%d %H:%M:%S')
except ValueError:
try:
# 尝试解析不带秒的格式
return datetime.strptime(time_str, '%Y-%m-%d %H:%M')
except ValueError:
# 如果是时间戳(整数或浮点数),转换为datetime
if isinstance(time_str, (int, float)):
timestamp = time_str / 1000.0 if time_str > 1000000000 else time_str
return datetime.fromtimestamp(timestamp)
# 无法解析的格式,返回原始值
print(f"警告: 无法解析时间格式: {time_str}")
return time_str
def format_time(dt):
"""将datetime对象格式化为标准字符串"""
if isinstance(dt, datetime):
return dt.strftime('%Y-%m-%d %H:%M:%S')
return str(dt)
def fetch_url_content(url, headers=None, timeout=10):
"""
使用requests访问目标URL并返回响应内容
参数:
url (str): 要访问的目标URL
headers (dict, 可选): 请求头,默认使用模拟浏览器的User-Agent
timeout (int, 可选): 请求超时时间(秒),默认10秒
返回:
str: 响应文本内容(成功时);None(失败时)
"""
# 默认请求头(模拟浏览器,避免被简单反爬拦截)
default_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
# 如果用户传入自定义headers,合并到默认headers中(用户传入的优先)
if headers:
default_headers.update(headers)
try:
# 发送GET请求
response = requests.get(
url=url,
headers=default_headers,
timeout=timeout # 超时保护
)
# 检查响应状态码(200表示成功)
response.raise_for_status()
# 打印成功信息(可选,可删除)
print(f"✅ 访问成功:{url}(状态码:{response.status_code})")
# 返回响应文本(如果需要二进制内容,可改为 return response.content)
return response.text
except RequestException as e:
# 捕获所有requests相关异常(网络错误、超时、404/500等状态码)
print(f"❌ 访问失败:{url},错误:{str(e)}")
return None
except Exception as e:
# 捕获其他未知异常
print(f"❌ 未知错误:{url},错误:{str(e)}")
return None
def extract_weather_data(html_content):
"""
从HTML内容中提取天气数据(针对提供的JS变量格式)
参数:
html_content (str): 包含天气数据的HTML/JS文本内容
返回:
dict: 结构化的天气数据字典,包含各类气象指标
"""
# 定义需要提取的JS变量及其对应的数据名称
data_vars = {
'aqi_data': '空气质量AQI',
'wd_data': '温度(℃)',
'sd_data': '湿度(%)',
'rain_data': '降水量(mm)',
'qy_data': '气压(hPa)',
'njd_data': '能见度(km)',
'data': '风向风力',
'solar_data': '太阳辐射(W/m²)',
'dewpoint_data': '露点温度(℃)'
}
# 存储提取后的所有数据
result = {}
# 遍历所有需要提取的变量
for var_name, desc in data_vars.items():
# 正则表达式:匹配 "var 变量名 = [数组内容];" 的结构
# 匹配规则:忽略空格,捕获数组部分
pattern = re.compile(
rf'var\s+{var_name}\s*=\s*(\[.*?\]);',
re.DOTALL # 让 .*? 可以匹配换行
)
# 查找匹配结果
match = pattern.search(html_content)
if not match:
result[desc] = []
continue
# 提取数组字符串并转换为Python列表
try:
# 去除可能的注释和多余字符,确保是标准数组格式
data_str = match.group(1).strip().rstrip(';')
# 使用ast.literal_eval安全转换字符串为Python对象(避免eval的安全问题)
data_list = ast.literal_eval(data_str)
result[desc] = data_list
except (SyntaxError, ValueError) as e:
print(f"提取 {desc} 失败:{str(e)}")
result[desc] = []
return result
def merge_to_single_csv(weather_data, output_file='2.csv'):
"""
将所有天气数据合并到一个CSV文件中
参数:
weather_data (dict): 提取的天气数据字典(由extract_weather_data函数返回)
output_file (str): 输出的CSV文件路径
返回:
str: 生成的CSV文件路径
"""
# 1. 收集所有时间点并去重、排序
all_timestamps = set()
for data_type, data_list in weather_data.items():
for item in data_list:
timestamp = item[0]
# 统一转换为datetime对象
dt = parse_time(timestamp)
# 转换回标准格式字符串
all_timestamps.add(format_time(dt))
# 排序时间点,使用智能解析函数
sorted_timestamps = sorted(all_timestamps, key=lambda x: parse_time(x))
# 2. 构建表头
headers = ['时间']
# 数据类型映射(用于简化表头)
data_type_mapping = {
'空气质量AQI': 'AQI',
'温度(℃)': '温度(℃)',
'湿度(%)': '湿度(%)',
'降水量(mm)': '降水量(mm)',
'气压(hPa)': '气压(hPa)',
'能见度(km)': '能见度(km)',
'风向风力': '风向风力',
'太阳辐射(W/m²)': '太阳辐射',
'露点温度(℃)': '露点温度(℃)'
}
# 为每种数据类型添加对应的列
for data_type in weather_data.keys():
if data_type == '风向风力':
headers.extend(['风力等级', '风向代码', '风速', '风向名称'])
elif data_type == '太阳辐射(W/m²)':
headers.extend(['短波辐射(W/m²)', '直接辐射(W/m²)', '散射辐射(W/m²)', '直接正常辐照度(W/m²)'])
else:
headers.append(data_type_mapping.get(data_type, data_type))
# 3. 构建数据行
rows = []
for timestamp in sorted_timestamps:
row = [timestamp]
# 为每个时间点收集所有数据
for data_type, data_list in weather_data.items():
# 查找该时间点对应的数据
data_point = None
for item in data_list:
item_timestamp = item[0]
# 统一格式后比较
if format_time(parse_time(item_timestamp)) == timestamp:
data_point = item
break
# 根据数据类型添加对应的值
if data_point:
if data_type == '风向风力':
row.extend(data_point[1:5]) # 风力等级、风向代码、风速、风向名称
elif data_type == '太阳辐射(W/m²)':
row.extend(data_point[1:5]) # 所有四个辐射指标
else:
row.append(data_point[1]) # 普通数据类型(只有一个值)
else:
# 无数据时填充空值
if data_type == '风向风力' or data_type == '太阳辐射(W/m²)':
row.extend([''] * 4) # 这两种数据类型各有4列
else:
row.append('') # 其他数据类型只有1列
rows.append(row)
# 4. 写入CSV文件
with open(output_file, 'w', newline='', encoding='utf-8-sig') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(headers)
writer.writerows(rows)
print(f"已生成综合CSV文件: {output_file} ({len(rows)} 条记录)")
return output_file
def crawler(url):
content = fetch_url_content(url)
if content:
print("\n--- 响应内容---")
print(content)
print('成功响应')
merge_to_single_csv(extract_weather_data(content),'10.csv')
crawler(target_url)
III. Summary
Without heavy anti-bot crypto, scrapers follow a steady recipe—like this outline: pick a site, study the HTML/JS, fetch, parse, store. The piece that always changes is parsing, because each backend shapes data differently—usually tweak that function only. Often you can paste the raw response into an LLM, ask for a first-pass parser, then hand-edit—good enough for many jobs.