深度学习如何重塑三维重建:从任务定义到工程落地全流程解析
三维重建工程化全景:从输入模态与场景定义、数据质控、标定位姿、深度多视图、稠密表示到语义增强与部署优化,梳理深度学习各阶段可落地切入点。
前言
三维重建正在从“可视化展示”走向“可交付、可运维、可闭环”的工程系统。过去,行业更多依赖传统几何方法解决位姿、深度和稠密建模问题;而在复杂场景、跨设备部署和长期稳定运行的要求下,仅靠单一算法已难以满足实际需求。深度学习的价值也因此发生转变:不再只是追求某个模块的离线精度极限,而是嵌入重建全链路,提升鲁棒性、泛化性和系统效率。
本文围绕三维重建Pipeline的关键环节展开,从任务入口定义、数据采集治理、几何前端增强,到深度与多视图几何、稠密表示生成、外观恢复、动态时序一致性、语义增强,以及后处理与部署优化,系统梳理深度学习在各阶段的可落地切入点。核心目标是给出一套面向工程实践的方法框架:先明确场景与目标约束,再用“学习增强 + 几何约束 + 质量闭环”的组合范式,构建可持续演进的三维重建系统。
0. 任务入口与场景定义(决定后续技术路线)
三维重建项目中,深度学习方法是否有效,往往不取决于“模型是否先进”,而取决于任务定义是否准确。入口阶段需要先明确输入模态、场景属性和业务目标,这三者会直接决定后续在位姿估计、深度估计、表示学习和部署优化上的方法选择。
0.1 输入模态:决定可利用信息上限
1) 单目图像(Monocular RGB)
- 优势:采集门槛低、数据来源广、硬件成本最低。
- 局限:天然缺乏绝对尺度与深度约束,易受纹理缺失和光照变化影响。
- 深度学习典型作用:
- 单目深度估计提供伪几何先验;
- 语义分割辅助结构恢复(墙、地、天等布局);
- 学习型特征匹配提高SfM鲁棒性。
- 适用场景:互联网图像重建、轻量级移动采集、低成本原型验证。

2) 多视图图像(Multi-view RGB)
- 优势:有视差约束,可形成稳定几何恢复基础。
- 局限:依赖视角覆盖质量,采集组织成本较高。
- 深度学习典型作用:
- 学习型MVS网络替代传统匹配代价;
- 基于置信度的深度融合和异常剔除;
- 在弱纹理区域引入先验提升重建完整性。
- 适用场景:文物数字化、工业零件逆向、室内外高保真重建。
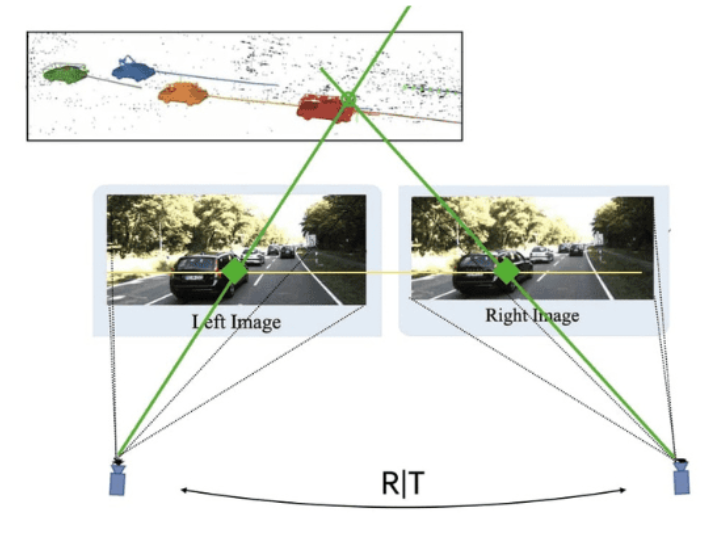
3) 视频序列(Video)
- 优势:天然具备时序连续性,利于位姿估计和稠密跟踪。
- 局限:动态物体、运动模糊和滚动快门会引入误差积累。
- 深度学习典型作用:
- 关键帧选择和动态区域分割;
- 时序一致性约束的深度估计;
- 联合VO/SLAM的漂移抑制。
- 适用场景:机器人巡检、手机扫描、自动驾驶场景建图。

4) RGB-D / 深度相机
- 优势:直接获得深度,几何恢复稳定,工程落地快。
- 局限:深度噪声、空洞、量程受限;户外强光环境表现不稳定。
- 深度学习典型作用:
- 深度补全与去噪;
- RGB引导的边缘细节修复;
- 多帧融合中的不确定性建模。
- 适用场景:室内扫描、机械臂抓取、近距重建任务。

5) LiDAR 点云(可与视觉融合)
- 优势:几何精度高、远距离测量稳定。
- 局限:点云稀疏、语义信息弱、设备成本高。
- 深度学习典型作用:
- 点云补全和上采样;
- LiDAR-视觉融合提升稠密重建质量;
- 学习型配准与跨传感器标定。
- 适用场景:自动驾驶、高精地图、室外大尺度重建。
0.2 场景属性:决定方法的可行边界
1) 室内 vs 室外
- 室内:结构规则、尺度较小、遮挡密集,适合语义先验与RGB-D融合。
- 室外:光照变化剧烈、尺度大、动态目标多,需更强鲁棒配准与分块重建策略。
2) 静态 vs 动态
- 静态场景:可采用传统SfM/MVS与NeRF类方法获得高质量结果。
- 动态场景:必须引入动态分割、时序建模与4D表示,否则容易出现重影、几何撕裂和位姿漂移。
3) 小物体 vs 大场景
- 小物体重建:强调局部细节、边界和纹理保真,常用高分辨率多视图与隐式表示。
- 大场景重建:强调全局一致性与效率,需分区建图、层级表示和内存优化。
4) 材质复杂度
- 反光、透明、弱纹理区域是传统几何方法难点。
- 深度学习可通过先验补偿和可微渲染提升稳定性,但仍需多模态或物理约束辅助。
0.3 目标定义:决定最优解而非最强模型
实际项目通常不是“精度越高越好”,而是多目标折中。建议在立项时先定义主目标优先级:
1) 几何精度优先
- 关注绝对/相对误差、边缘细节、拓扑正确性。
- 方法倾向:学习型MVS + 高质量融合 + 后处理修复。
- 代价:算力和处理时长较高。
2) 视觉观感优先
- 关注纹理清晰度、材质真实感和新视角渲染质量。
- 方法倾向:NeRF/3DGS及其高保真外观建模分支。
- 风险:几何可编辑性和工程部署复杂度上升。
3) 实时性优先
- 关注端侧推理延迟、吞吐和功耗。
- 方法倾向:轻量网络、稀疏表示、模型压缩与增量更新。
- 折中:在复杂场景下可能牺牲精度与完整性。
4) 成本与可部署性优先
- 关注数据采集成本、训练成本、维护成本与稳定性。
- 方法倾向:混合式方案(传统几何 + 深度学习关键模块增强),逐步迭代替换。
0.4 深度学习切入点选型矩阵(入口阶段建议)
| 约束条件 | 优先切入环节 | 推荐策略 |
|---|---|---|
| 数据少、标注少 | 位姿/匹配、深度补全 | 使用预训练模型 + 几何一致性自监督 |
| 设备算力弱 | 前端特征与轻量深度网络 | 模型蒸馏、量化、关键帧推理 |
| 场景动态多 | 动态分割与时序建模 | 静动态解耦 + 4D一致性约束 |
| 需要高保真渲染 | 外观建模与神经表示 | NeRF/3DGS + 几何先验融合 |
| 工业高精度需求 | 深度估计与融合优化 | 学习MVS + 不确定性过滤 + 网格修复 |
1. 数据采集与质量控制
在三维重建项目中,采集质量通常决定结果上限。深度学习在这一环节的核心价值,不是“直接生成三维”,而是提前识别和抑制会在后续SfM/MVS/NeRF阶段被放大的误差源,包括模糊、曝光异常、视角覆盖不足、动态干扰和域偏移。
工程上可以把本章理解为:用学习方法做数据入口治理,把坏数据尽量挡在Pipeline前端。
1.1 本环节在重建Pipeline中的定位
数据采集与质量控制是重建流程的“前端门控层”,对后续模块有连锁影响:
深度学习在该阶段应聚焦两类任务:
- 采集前规划:视角策略、路径建议、采集规范。
- 采集中筛选:质量评估、关键帧选择、异常检测与自动回采。
1.2 深度学习可落地的关键能力
1.2.1 图像质量评估(IQA)
目标是自动识别“不适合进入重建”的帧,常见检测维度:
- 清晰度:运动模糊、失焦、压缩伪影。
- 曝光质量:过曝、欠曝、强反差区域。
- 纹理可用性:大面积纯色或弱纹理导致匹配困难。
- 反光/透明区域占比:玻璃、镜面会干扰几何一致性。
落地方式:
- 使用无参考IQA网络(NR-IQA)打分,并按阈值过滤。
- 将IQA分数接入采集App实时提示(“请减速”“请补拍该区域”)。
- 对边缘可用帧不直接丢弃,可降权进入后续融合。
工程收益:
- 降低匹配失败率与重建噪声。
- 减少后处理修复成本。
- 缩短“采完才发现不能用”的返工周期。
1.2.2 关键帧筛选与视角覆盖评估
重建不是帧越多越好,而是视角覆盖越完整越好。深度学习可用于关键帧抽取和覆盖度评估:
- 相邻帧冗余检测:避免近重复帧堆积。
- 视角多样性评分:优先保留基线充分、信息增益高的帧。
- 覆盖空洞检测:识别尚未拍摄到的区域。
可采用策略:
- 学习型帧表示 + 聚类筛选关键帧。
- 结合几何启发(视差、重叠率)进行混合筛选。
- 针对视频采集,做“在线关键帧决策”,边采边控。
工程收益:
- 在相近精度下减少数据量、降低算力消耗。
- 提高场景完整性,降低“某一面缺失”的概率。
1.2.3 动态干扰与异常内容检测
动态目标(行人、车辆、摆动物体)会破坏静态场景假设。深度学习可前置识别并隔离这类区域:
- 语义分割/实例分割:识别潜在动态类别。
- 光流一致性检测:发现运动区域与遮挡边界。
- 时序异常检测:跳帧、剧烈抖动、滚动快门异常。
落地建议:
- 静态重建任务中,对动态区域打掩码,降低其在匹配与融合中的权重。
- 对高动态片段触发“重采建议”。
- 记录动态占比,作为场景难度标签输入后续模块。
1.2.4 域适配与数据增强(提升泛化)
同一重建模型常在不同设备、不同光照和不同环境下退化。采集阶段可通过学习策略做“分布对齐”:
- 风格迁移增强:模拟目标域光照/色彩。
- 几何一致增强:旋转、缩放、裁剪时保持标注几何关系。
- 真实-仿真混合训练:降低真实数据稀缺带来的偏差。
目标是让后续位姿估计和深度网络在跨场景时更稳定,而不是仅在单一数据集上最优。
1.2.5 主动采集(Active Reconstruction)
主动采集强调“系统告诉采集者下一步拍哪里最有价值”,是高性价比提质方向:
- 预测当前重建不确定性热区。
- 推荐下一视角以最大化信息增益。
- 在移动端或机器人端实时给出路径建议。
该能力可显著减少盲拍和重复拍摄,特别适用于大场景和复杂结构物体。
1.3 典型实现架构(工程可直接套用)
一个常见的数据采集质量控制流水线如下:
- 输入帧流:相机/视频实时输入。
- 质量评分模块:IQA + 纹理可用性 + 曝光评估。
- 动态检测模块:语义分割 + 光流异常检测。
- 关键帧决策模块:冗余抑制 + 覆盖度优化。
- 反馈模块:实时提示用户补拍/调整角度。
- 数据缓存与打标:记录质量分、动态比例、覆盖指标。
该结构本质是“在线数据治理层”,建议作为所有重建任务的通用前端。

1.4 指标体系:如何衡量这一环节是否有效
建议将本章节效果量化为“前端质量指标 + 后端收益指标”两类。
1.4.1 前端质量指标
- 可用帧率(可进入重建的帧占比)。
- 平均质量分与低质量帧占比。
- 关键帧压缩率(在保留信息前提下的数据减量)。
- 场景覆盖度(视角覆盖与盲区比例)。
- 动态区域占比与剔除准确率。
1.4.2 后端收益指标
- SfM匹配内点率与位姿求解成功率。
- 深度图完整性与噪声水平。
- 最终点云/网格完整度(如F-score、Completeness)。
- 端到端处理时长与返工率。
若前端质量控制有效,通常会看到:后端精度提高 + 总时长下降 + 人工干预减少。
1.5 成本与代价(必须提前评估)
深度学习前置提质虽有效,但也引入成本:
- 额外推理开销:实时评分与分割会占用边端算力。
- 阈值调参成本:不同场景需不同质量门限。
- 错杀风险:过严筛选可能丢失关键视角帧。
- 系统复杂度提升:多模块联动增加工程维护负担。
优化建议:
- 采用分级策略:轻量模型在线筛选,重模型离线复检。
- 关键模块做可回退设计(保留原始帧索引,支持重跑)。
- 按场景维护参数模板(室内、室外、夜间、强反光)。
1.6 本节结论
数据采集与质量控制是三维重建中最容易被低估、但投入产出比最高的深度学习应用点。
其核心不是追求复杂模型,而是建立一套稳定的前端治理机制:先确保输入可重建,再讨论后端高精度。
在工程实践中,建议优先落地以下三项能力:
- 在线图像质量评估(清晰度/曝光/纹理可用性)。
- 关键帧与覆盖度联合优化(去冗余但不丢信息)。
- 动态干扰检测与掩码化处理(保障静态重建假设)。
做到这三点,通常即可显著提升整条Pipeline的稳定性与最终重建质量。
2. 相机标定、位姿估计与配准
在三维重建Pipeline中,相机标定、位姿估计与多源配准构成几何前端。该阶段的误差会被后续深度估计、融合和网格化持续放大,因此这是深度学习“最值得投入”的增强点之一。
从工程角度看,本章节目标是回答三个问题:相机是否被正确建模、位姿是否稳定可解、跨帧/跨传感器是否能精确对齐。
2.1 本环节在Pipeline中的作用边界
该环节向后续模块提供“统一坐标系下的几何基础”,主要输出包括:
- 内参/畸变参数:焦距、主点、径向与切向畸变。
- 外参与轨迹:相机在世界坐标中的位姿序列。
- 跨源对齐关系:视觉、IMU、LiDAR、深度相机等传感器外参。
若该环节不稳定,常见连锁问题包括:
- 特征匹配多但可用内点少,RANSAC难收敛。
- 局部轨迹可解但全局漂移明显,闭环后仍不一致。
- 多传感器融合出现“重影”或系统性偏移。
- 后续稠密重建出现拉伸、错层、重复结构。
因此,深度学习在此阶段的价值不是替代几何约束,而是增强其鲁棒性:几何方法负责可解释性,学习方法负责抗噪与泛化。
2.2 深度学习在标定中的应用
2.2.1 学习型畸变与内参估计
传统标定依赖标定板和离线流程,工业环境下维护成本高。学习方法可用于在线校正与快速重估:
- 基于图像线结构的畸变回归(直线应保持直线)。
- 基于重投影一致性的弱监督内参优化。
- 多设备迁移学习,减少每台设备单独标定成本。
输入:是图像(单帧或多帧)以及可选的线特征/匹配点/初始参数等约束信息。
输出:是相机内参和畸变参数(常带置信度或重投影误差),用于去畸变和后续位姿求解
2.2.2 自标定与在线重标定
在长期运行系统中,相机参数可能随时间漂移。可用深度学习做漂移监测与触发式重标定:
- 监测重投影误差分布是否异常。
- 在特定阈值触发时启动在线微调。
- 对高风险设备分配更频繁重标定周期。
该策略可降低停机标定次数,提高系统可维护性。
输入:是运行中的多帧图像/轨迹与实时重投影误差统计。
输出:是“是否漂移”的告警与触发重标定后的更新参数(并给出设备重标定频率建议)。
2.3 深度学习在位姿估计中的应用
2.3.1 学习型特征点与描述子
在弱纹理、重复纹理、光照变化场景中,传统手工特征稳定性不足。学习型特征可显著提升匹配质量:
- 更强的光照与尺度鲁棒性。
- 更稳定的重复定位能力。
- 更高内点率,降低RANSAC试错成本。
典型做法是“学习特征 + 几何验证”:
- 网络提取关键点与描述子。
- 学习匹配器给出候选对应关系。
- 几何模型(E/F矩阵、PnP)筛内点并解位姿。
这种混合方案在工程上可解释性高,且便于定位错误来源。
输入:是两帧/多帧图像(可含时序)。
输出:是高质量匹配点对与置信度、筛选后的内点集合,以及最终位姿估计结果(E/F/PnP)。

2.3.2 学习型匹配与外点抑制
匹配环节是位姿稳定性的第一道关。深度学习可用于对匹配对进行上下文建模与置信度打分:
- 基于注意力机制建模全局一致性。
- 对重复结构和纹理混淆区域进行外点抑制。
- 输出匹配置信度,用于后续加权求解。
实际收益通常体现在:
- 同等帧数下更高可解率。
- 大基线或视角变化下更稳健。
- 低光和动态干扰条件下退化更慢。
输入:是候选匹配点对(及其局部特征/上下文信息)。
输出:是去外点后的高置信匹配与每对匹配权重,供后续加权位姿求解使用。

2.3.3 深度辅助位姿求解(Depth-aided Pose)
当仅靠2D匹配不稳定时,可引入学习深度先验提升位姿可观测性:
- 单目深度作为PnP中的3D锚点来源。
- 深度置信图用于剔除不可靠区域。
- 与光度一致性联合优化抑制尺度漂移。
适合场景:
- 纹理稀少、低重复结构环境。
- 长走廊、隧道、室内白墙等几何退化区域。
输入:是图像匹配结果 + 预测深度图/深度置信图(可再加光度误差)。
输出:是更稳定的相机位姿与尺度估计(同时剔除低置信深度区域)。

2.4 SLAM/SfM中的深度学习增强点
2.4.1 视觉里程计(VO)前端增强
可在跟踪前端引入学习模块:
- 关键点质量预测,优先使用高稳定性观测。
- 关键帧选择网络,降低冗余和漂移积累。
- 动态区域掩码,减少运动目标干扰。
输入:是连续图像帧(可含光流/语义信息)。
输出:是筛选后的高质量关键点、关键帧集合和动态掩码,用于更稳的前端跟踪
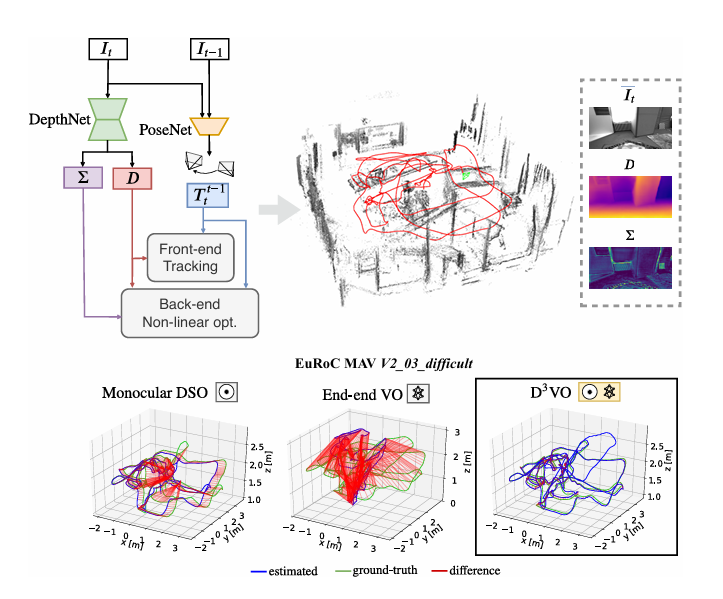
2.4.2 回环检测与重定位
学习型全局描述子可显著提升回环召回率:
- 在视角变化和光照变化下保持场景可识别性。
- 缩短重定位时间,增强长序列鲁棒性。
- 与图优化结合,改善全局一致性。
输入:是当前帧/关键帧图像及历史地图库(关键帧数据库)。
输出:是回环候选与重定位位姿(含相似度分数),并将约束送入图优化。
2.4.3 BA与图优化中的学习辅助
深度学习不直接替代优化器,而是提供更好的输入权重:
- 匹配边权重学习。
- 观测置信度建模。
- 不确定性估计用于鲁棒核自适应。
结果是优化过程更稳定、局部极值更少、收敛更快。
输入:是匹配边、观测残差和初始位姿/地图状态。
输出:是学习得到的边权重与不确定性(鲁棒核参数),供BA/图优化器加权求解并提升收敛稳定性
2.5 多传感器配准中的深度学习应用
当系统包含视觉、IMU、LiDAR或RGB-D时,跨模态配准成为关键难点。
2.5.1 视觉-IMU联合标定与对齐
- 学习时间同步偏差与噪声模型。
- 在高速运动中利用惯导稳定短时姿态。
- 通过联合优化抑制纯视觉漂移。
输入:相机图像序列 + IMU 时序数据(角速度/加速度)+ 时间戳(可含初始外参)
输出:相机-IMU 外参、时间偏移、噪声/偏置模型,以及融合后的稳定短时位姿
2.5.2 视觉-LiDAR配准
- 学习跨模态特征对齐(2D纹理与3D几何)。
- 对稀疏点云和遮挡场景增强配准鲁棒性。
- 提供初始变换供ICP/NDT精修。
输入:图像(2D)+ 点云(3D)+ 初始对应/先验变换(可选)
输出:跨模态对齐关系与初始变换 T_cam_lidar(R,t),供 ICP/NDT 精修
2.5.3 RGB-D与多相机系统对齐
- 深度置信度估计用于融合加权。
- 相机间外参偏移在线监测与修正。
- 大规模多相机阵列的自动一致性检查。
输入:RGB 图、深度图、多相机同步帧(可含历史外参与质量统计)
输出:融合权重(深度置信度)、更新后的相机间外参、阵列一致性检查结果/告警
2.6 常见错误模式与规避策略
问题1:把学习模型当作纯黑盒位姿解算器
- 表现:离线效果好,跨场景后位姿崩溃且难诊断。
- 规避:采用“学习匹配 + 几何求解”混合架构,保留可解释中间量。
问题2:忽略不确定性,所有匹配一视同仁
- 表现:少量错误匹配导致全局轨迹漂移。
- 规避:输出置信度并在PnP/BA中做加权优化。
问题3:动态区域未隔离
- 表现:车辆/行人主导特征,静态结构估计失真。
- 规避:前端加入动态分割与运动一致性过滤。
问题4:跨传感器初值差,后端难收敛
- 表现:ICP反复陷入局部最优。
- 规避:先用学习模型提供跨模态粗配准,再做几何精配准。
2.7 指标与评估建议
建议将评估分为“局部可解性、全局一致性、跨域鲁棒性”三类。
2.7.1 局部位姿质量
- 匹配内点率、重投影误差、PnP成功率。
- 短窗轨迹误差(RPE)。
- 跟踪中断频次与重定位时延。
2.7.2 全局一致性
- 绝对轨迹误差(ATE)。
- 回环后全局漂移残差。
- 稠密重建几何一致性(错层/重影比例)。
2.7.3 跨域鲁棒性
- 不同设备、光照、天气条件下性能波动。
- 动态干扰场景中的退化曲线。
- 长序列稳定性(公里级/小时级)表现。
若该环节优化有效,通常能在后端看到:重建完整度提升、几何噪声下降、失败率明显降低。
2.8 本节结论
相机标定、位姿估计与配准不是单点算法问题,而是整个重建Pipeline的几何底座。
深度学习在该环节最有效的用法是“增强鲁棒性和可解率”,而非完全取代几何约束。
实践中,推荐长期采用以下组合范式:
- 学习型特征与匹配提升前端观测质量;
- 几何求解与图优化保证物理一致性与可解释性;
- 不确定性建模贯穿匹配、求解和融合全流程。
当这三者协同,系统通常能同时获得更高精度、更强泛化和更低失败率,为后续深度估计与稠密重建提供稳定基础。
3. 深度估计与多视图几何
这一部分聚焦三维重建Pipeline里最核心的几何中层:把多视角图像转换为稳定、可融合的深度与几何关系。
写作上采用“用途驱动”方式:每个用途都给出你要求的 输入 / 输出,并附配图链接,便于快速理解与汇报展示。
3.1 用途A:单目深度先验生成(给位姿与MVS提供初始几何)
- 输入:RGB图(单帧或短时序)、可选历史外参、可选质量统计(清晰度/曝光评分)。
- 输出:初始深度图、深度置信度图(可转成融合权重)、尺度一致性评分。
说明
单目深度本身存在尺度歧义,但在工程中非常有价值:可作为后续多视图深度求解的初值,也可在弱纹理区域提供“可观测性补偿”。
常见做法是使用自监督深度网络产出 depth + confidence,并把低置信区域交给后续多视图几何再修正。
3.2 用途B:多视图深度推断(MVS主干)
- 输入:多相机同步帧(含内外参初值)、参考帧RGB图、候选源视图集合、可选历史外参与质量统计。
- 输出:参考帧深度图、像素级概率/置信度图(融合权重)、可见性掩码。
说明
这是学习型MVS的核心环节:通过可微单应变换构造代价体(Cost Volume),再做3D正则化,得到深度与概率图。
概率图可以直接转为融合阶段的权重,低概率区域会被抑制,减少伪深度污染。
3.3 用途C:多视图几何一致性校验(剔除伪匹配与伪深度)
- 输入:参考帧深度图、源视图深度图、相机位姿(当前估计)、重投影误差统计。
- 输出:几何一致性分数、点级/像素级有效性掩码、更新后的融合权重。
说明
深度估计并不等于“可直接融合”。必须通过前后向重投影、视角一致性、遮挡一致性做过滤。
这一步是控制“毛刺点云、悬浮面片、边缘错层”的关键,通常会对后续网格质量产生决定性影响。
3.4 用途D:深度置信度建模与融合权重预测
- 输入:RGB图、深度图、法线/梯度信息、历史帧稳定性统计(可选)。
- 输出:融合权重(深度置信度)、不确定性热力图、可选“拒绝融合”掩码。
说明
工程里最常见问题是“平均融合把错误也平均进去了”。
正确做法是先预测深度不确定性,再以学习权重进行加权融合;高置信区域主导表面,低置信区域延后决策或交由更多视角补证。
3.5 用途E:相机间外参在线微调(阵列长期运行必需)
- 输入:多相机同步帧(可含历史外参与质量统计)、跨视角匹配对、重投影残差序列。
- 输出:更新后的相机间外参、外参漂移趋势、校正可信度。
说明
多相机系统在长期运行中会出现轻微机械漂移或热漂移。
可用学习匹配 + 几何优化做在线微调:学习模块提供更稳健对应关系,几何优化保证参数物理合理。
3.6 用途F:阵列一致性检查与告警(运维与质量闭环)
- 输入:多相机同步帧、当前外参、深度置信度统计、历史告警日志。
- 输出:阵列一致性检查结果/告警、异常相机列表、建议处理动作(重标定/降权/剔除)。
说明
这一用途直接对应场景化表达:不仅要“算出来”,还要“可监控、可报警、可运维”。
常见告警规则包括:重投影误差突增、跨相机深度断层、某路相机长期低置信度等。

3.7 用途G:时序深度稳定化(视频重建去抖与抗闪烁)
- 输入:连续RGB帧、历史深度图、历史外参、帧质量统计(模糊/曝光/动态比例)。
- 输出:时序平滑后的深度序列、帧间一致性分数、时序融合权重。
说明
视频场景中,单帧深度“看起来正确”不代表时序稳定。
深度学习可结合时序先验(光流、时序Transformer、循环状态)抑制闪烁与局部跳变,提升最终重建的连续表面质量。
3.8 用途H:神经表示中的深度几何约束(NeRF/3DGS阶段)
- 输入:多视角RGB图、相机位姿、可选深度先验图/深度置信度图。
- 输出:几何一致的辐射场参数、可渲染深度图、可用于融合的置信信息。
说明
NeRF/3DGS强调新视角合成,但如果缺少深度几何约束,容易出现漂浮结构与几何歧义。
将深度图及其置信度纳入训练损失,可显著提升收敛速度与几何真实性。
3.10 小结(第3章结论)
“深度估计与多视图几何”不是单个算法点,而是连接前端位姿与后端融合的关键枢纽层。
在实际项目中,建议优先建设三项能力:
深度 + 置信度联合输出(不要只要深度值)。- 几何一致性过滤与加权融合(不要直接平均)。
- 外参在线微调 + 阵列一致性告警(保证长期稳定运行)。
做到这三点,通常可以同时提升重建精度、系统稳定性和可运维性。
4. 稠密重建与三维表示生成
这一部分关注三维重建Pipeline中“落地成形”的环节:把多视图深度、位姿和置信信息,转化为可使用的三维表示(点云、网格、隐式场、神经表示等)。
4.1 用途A:深度图融合为稠密点云(Dense Fusion)
- 输入:多视图RGB图、深度图、相机位姿、深度置信度(融合权重)、可见性掩码。
- 输出:融合点云(含点置信度)、异常点剔除结果、局部完整性统计。
说明
这是从“每帧深度”走向“统一三维几何”的第一步。
关键在于:不是简单叠加,而是利用深度置信度做加权融合,并通过重投影一致性过滤掉漂浮点与外点。

4.2 用途B:点云去噪、补全与上采样(Point-level Enhancement)
- 输入:原始融合点云、点置信度、RGB颜色/法线信息、可选历史重建结果。
- 输出:去噪点云、补全点云、上采样点云、点级质量评分。
说明
融合点云常见问题是“噪声多、孔洞多、边缘破碎”。
深度学习可通过点云补全网络与局部几何先验提升完整性,特别适合弱纹理区域和遮挡区域恢复。
4.3 用途C:点云到网格重建(Surface Meshing)
- 输入:增强后点云、法线估计、点置信度、可选语义边界信息。
- 输出:三角网格(Mesh)、孔洞填补结果、拓扑一致性检查报告。
说明
网格是最常见的工程交付形式(CAD、仿真、渲染、打印都依赖网格)。
深度学习可辅助边界恢复和孔洞修复,但最终通常仍结合传统几何算法(Poisson、Delaunay、Marching Cubes)保证拓扑可控。

4.4 用途D:TSDF/体素融合(可实时增量建图)
- 输入:RGB-D帧流或多视图深度、相机位姿、体素网格配置、深度置信度。
- 输出:TSDF体(或体素场)、增量网格结果、体素置信度地图。
说明
TSDF融合是工业和机器人中非常实用的“稳健方案”:可增量更新、可实时、抗噪能力强。
深度学习常用于预测每帧深度置信度、优化融合权重、补洞与边界锐化。

4.5 用途E:隐式表示生成(Occupancy / SDF)
- 输入:多视图RGB图、深度先验、相机位姿、采样点坐标、可选法线约束。
- 输出:隐式场参数(Occupancy或SDF)、可提取网格、几何误差统计。
说明
隐式表示适合高质量连续表面建模,能表达复杂拓扑并减少离散网格伪影。
常见流程是先学习场函数,再通过Marching Cubes提取可用网格。
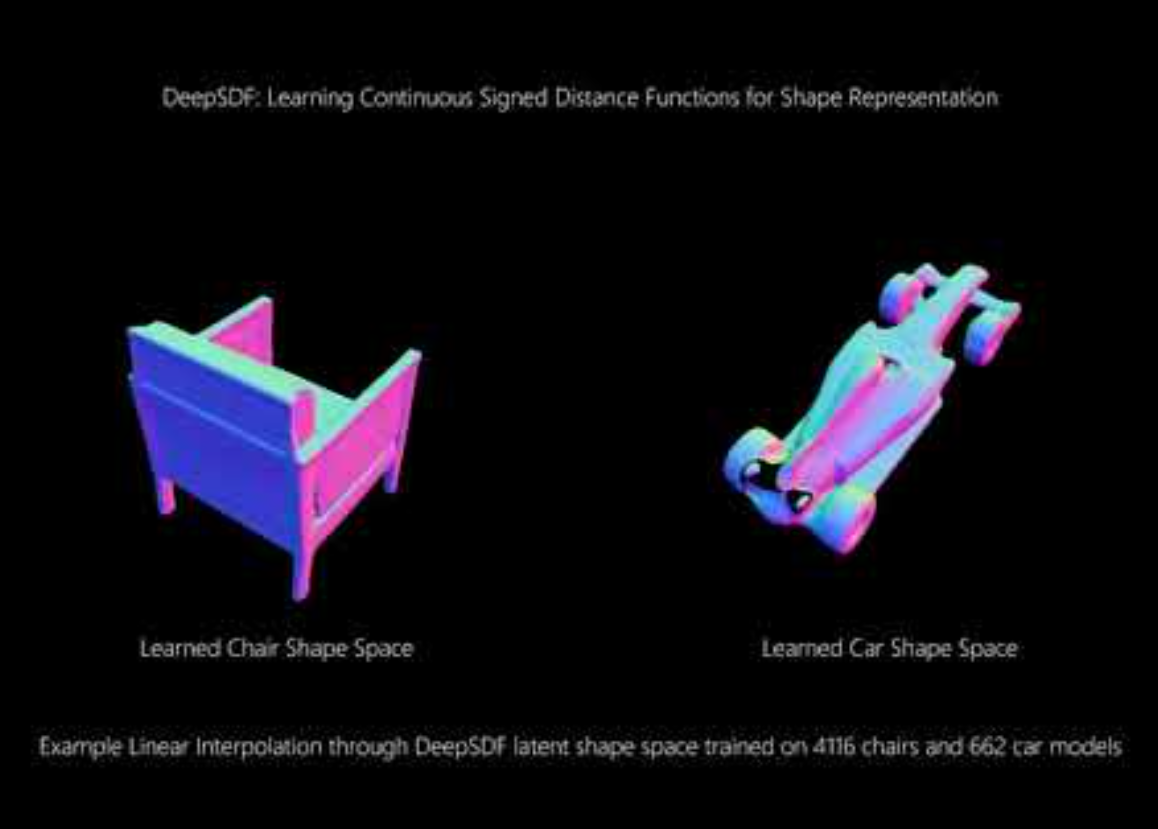
4.6 用途F:神经辐射场与3DGS表示生成(NeRF/GS)
- 输入:多视图RGB图、相机位姿、可选深度图与深度置信度、可选语义先验。
- 输出:NeRF或3D Gaussian Splatting参数、可渲染新视角、可导出几何(深度/点云/网格)。
说明
这类表示在“视觉真实感”上表现突出,适合数字内容生产和新视角渲染。
若要用于工程几何任务,通常需要引入深度监督与几何一致性约束,避免外观好但几何漂移。
4.7 用途G:多表示协同转换(Point ↔ Mesh ↔ Implicit ↔ Neural)
- 输入:已有三维表示(点云/网格/隐式场/神经表示)、质量评分、目标应用约束(渲染/仿真/检测)。
- 输出:目标表示格式、转换误差报告、应用适配版本(轻量/高保真)。
说明
工程中没有“唯一最佳表示”,而是“按任务切换表示”:
- 视觉渲染偏NeRF/3DGS;
- 工业测量偏网格/点云;
- 优化学习偏隐式场。
深度学习可在表示转换时补偿细节与抑制信息损失。
4.8 用途H:阵列级一致性重建与在线告警
- 输入:多相机同步帧、历史外参与质量统计、深度置信度图、跨相机重投影误差。
- 输出:融合权重(深度置信度)更新、更新后的相机间外参、阵列一致性检查结果/告警。
说明
这一步把第3章的几何中层能力,真正落到第4章的“最终表示质量”上:
当某路相机偏移或质量下降时,系统自动降权、触发外参微调并告警,避免错误几何进入最终模型。
4.9 小结
稠密重建与三维表示生成的关键,不在于“选哪个表示最先进”,而在于“是否构建了稳定的表示生产链路”:
- 深度与置信度联合驱动融合(先控制错误传播)。
- 按任务选择最合适表示(点云/网格/隐式/神经场)。
- 阵列一致性和在线告警贯穿全流程(保证长期可用)。
当这三点同时满足时,系统才能从“能重建”走向“能交付、能维护、能规模化部署”。
5. 纹理/材质/外观恢复
几何重建解决的是“形状对不对”,而纹理/材质/外观恢复解决的是“看起来像不像、渲染是否真实、下游能否直接用”。
5.1 用途A:多视图纹理融合(Texture Blending)
- 输入:三维网格或点云、多视图RGB图、相机位姿、可见性与遮挡信息、图像质量统计。
- 输出:纹理贴图(UV纹理或点颜色)、视角加权融合结果、纹理接缝质量报告。
说明
多视图纹理融合的关键是“选对来源视角并平滑拼接”。
深度学习可用于预测每个视角的纹理可信度(清晰度、反光、曝光一致性),在融合时动态赋权,减少缝合痕迹与颜色跳变。

5.2 用途B:纹理超分与细节增强(Super-Resolution for Texture)
- 输入:低分辨率纹理图、原始多视图RGB图、几何边界信息(法线/深度边缘)。
- 输出:高分辨率纹理图、细节增强结果、边缘保真度评分。
说明
在移动端采集或远距离采集中,纹理分辨率经常不足。
可用超分网络恢复高频细节,同时结合几何边界约束,避免“看起来更清晰但结构错位”的伪细节。
5.3 用途C:光照分解与重光照一致性(Intrinsic Decomposition)
- 输入:RGB图、多视图位姿、几何先验(法线/深度)、可选环境光信息。
- 输出:反照率(Albedo)、阴影/光照分量、重光照后外观一致性结果。
说明
同一物体在不同视角可能受光照影响明显,直接纹理融合会产生颜色不一致。
通过分解“材质本色”和“光照影响”,可获得跨视角一致的外观,后续在渲染和编辑中更稳定。
5.4 用途D:反光/透明材质恢复(Specular & Transparent Handling)
- 输入:多视图RGB图、深度图、偏振或多曝光信息(可选)、历史质量统计。
- 输出:反光区域修正纹理、透明区域外观估计、高风险区域告警图。
说明
反光与透明材质是外观恢复难点:镜面高光会被误当作纹理,玻璃区域常导致纹理错贴。
深度学习可先检测材质类型,再采用材质感知融合策略,降低伪纹理与“漂浮反光”现象。
5.5 用途E:材质参数估计(PBR参数恢复)
- 输入:RGB图、几何模型(法线/粗糙几何)、多视角观测、可选光照先验。
- 输出:PBR材质贴图(Albedo、Roughness、Metallic、Normal)、材质置信度图。
说明
对游戏、数字孪生和工业仿真来说,仅有“颜色纹理”不够,还需要可物理渲染的材质参数。
深度学习可以从多视角外观反推材质属性,输出可直接用于现代渲染引擎的PBR贴图。
配图链接

5.6 用途F:视角相关外观建模(View-dependent Appearance)
- 输入:多视图RGB图、相机位姿、可选深度先验与法线。
- 输出:视角相关外观函数、新视角渲染结果、外观一致性评分。
说明
某些材质(如金属、车漆)会随观察角度变化。
如果只用“静态纹理贴图”表达,渲染会失真。神经渲染方法(NeRF家族)可学习视角相关外观,在真实感上优势明显。
5.7 小结
纹理/材质/外观恢复的核心不是“加一层贴图”,而是建立一套可解释、可评估、可运维的外观生产链:
- 多视图纹理融合要以质量权重驱动,避免接缝和色偏。
- 材质恢复要从“颜色贴图”升级到“可渲染参数贴图(PBR)”。
当几何质量与外观质量同时达标,三维重建结果才真正具备产品化价值。
6. 动态场景与时序一致性
静态场景重建的核心是空间一致性,而动态场景重建的核心是“空间一致性 + 时间一致性”。
在真实应用中(自动驾驶、机器人巡检、移动端扫描、人体重建),动态目标与时间漂移是导致重建失败的主要原因之一。
6.1 用途A:动态区域检测与静动态解耦
- 输入:连续RGB帧、可选深度图/光流、历史外参与质量统计。
- 输出:动态区域掩码、静态背景掩码、动态目标列表与置信度。
说明
动态目标(人、车、摆动物体)会破坏静态几何假设,导致位姿漂移和重影。
先做静动态解耦,再分别处理,是动态场景重建的基础动作。
6.2 用途B:时序位姿稳定与漂移抑制(Temporal Pose Stabilization)
- 输入:多帧特征匹配结果、IMU/里程计信息(可选)、历史外参、动态掩码。
- 输出:时序平滑位姿轨迹、漂移估计曲线、异常跳变告警。
说明
动态场景下,逐帧位姿常出现“短时抖动 + 长期漂移”。
深度学习可学习轨迹先验与不确定性,配合图优化提升全局一致性。
6.3 用途C:时序深度一致性约束(Depth Temporal Consistency)
- 输入:连续RGB图、单帧/多视图深度图、历史深度图、历史外参与质量统计。
- 输出:时序一致深度图、深度置信度更新(融合权重)、深度闪烁告警图。
说明
视频重建常见问题不是“某一帧错”,而是“帧间忽高忽低的深度闪烁”。
通过时序一致性损失、光流引导和短时记忆模型,可显著提升深度稳定性。
6.4 用途D:动态目标的4D重建(3D + Time)
- 输入:目标相关多视图视频帧、相机位姿、可选人体/物体先验模型。
- 输出:时变几何序列(4D表示)、动态轨迹、逐时刻外观结果。
说明
对人体动作、工业机械臂、交通参与体等,需要重建“随时间变化的形状”。
4D重建不仅要还原几何,还要保证时间连续与拓扑稳定。

6.6 用途F:时序融合权重与关键帧调度
- 输入:连续RGB/深度帧、每帧质量评分、历史外参与误差统计、动态占比。
- 输出:时序融合权重(深度置信度)、关键帧更新策略、帧级保留/丢弃决策。
说明
在线重建系统中,不是每帧都应等权参与融合。
应根据质量、动态程度、几何增益动态分配权重,保证“少而有效”的时序融合。
6.7 小结(第6章结论)
动态场景重建的难点从来不只是“几何精度”,而是“几何 + 时间 + 系统稳定性”的联合约束。
工程上建议优先落地以下三项能力:
- 静动态解耦 + 时序深度一致性(先控制误差扩散)。
- 位姿漂移抑制 + 融合权重调度(保证长期稳定)。
当这三项能力建立后,系统才能在真实动态环境中持续输出可用的三维结果。
7. 语义增强重建
传统三维重建通常只关注几何与外观,但在工程应用中,还需要模型具备“语义可理解性”:哪里是墙、哪里是路、哪里是设备、哪里是可交互对象。
语义增强重建的目标,是让重建结果不仅可视化,还能被检索、分析、编辑、决策系统直接使用。
7.1 用途A:2D语义分割引导3D重建
- 输入:多视图RGB图、2D语义分割结果、相机位姿、深度图(可选)。
- 输出:带语义标签的3D点云/网格、类别置信度图、语义覆盖率统计。
说明
先在2D做语义分割,再通过重投影映射到3D,是最常见、最稳健的语义增强路径。
其优势是可复用成熟2D模型,快速获得场景级语义结构。

7.2 用途B:实例级重建(对象分离与对象级建模)
- 输入:多视图RGB图、实例分割结果、相机位姿、深度图、历史外参与质量统计(可选)。
- 输出:对象级3D实例(每个物体独立ID)、实例边界与置信度、对象级告警(遮挡/缺失)。
说明
语义类别(如“车”)不足以支持下游任务,很多应用需要实例粒度(“第3辆车”)。
实例级重建可支持对象追踪、资产管理、机器人抓取和工业盘点。

7.3 用途C:语义约束的深度与几何优化
- 输入:RGB图、深度图、语义标签、相机位姿、重投影误差统计。
- 输出:语义一致深度图、融合权重(深度置信度)更新、几何异常区域标记。
说明
语义可以作为几何先验:
- “墙面/地面”应具备连续和平面倾向;
- “天空/玻璃反射”深度可信度应降低。
通过语义-几何联合优化,可减少重建噪声并提高结构可解释性。
7.4 用途D:语义地图与几何地图联合构建
- 输入:多相机同步帧、位姿轨迹、语义分割结果、深度图、历史外参与质量统计。
- 输出:语义地图(类别/实例)、几何地图(点云/网格/体素)、联合一致性检查结果/告警。
说明
在机器人和自动驾驶系统中,真正有价值的是“语义+几何”联合地图,而非纯几何模型。
联合地图可同时服务导航、避障、巡检、目标检索和路径规划。

7.5 用途E:语义驱动的可编辑重建
- 输入:带语义标签的3D模型、对象实例ID、材质/纹理信息、用户编辑指令。
- 输出:可编辑语义3D资产(按类别/实例操作)、编辑日志、区域一致性告警。
说明
语义增强的最大工程价值之一是“可编辑”:
例如只替换墙体材质、只删除某类障碍物、只导出某类设备。
这使三维重建从“展示结果”转向“生产工具”。
7.6 用途F:开放词汇语义增强(Open-vocabulary 3D)
- 输入:多视图RGB图、文本类别提示(prompt)、相机位姿、可选深度图。
- 输出:开放词汇语义标签、语义检索结果、未知类别告警。
说明
封闭类别语义模型在新场景会失效。
开放词汇方案(视觉-语言模型)允许用自然语言扩展类别,提升跨域泛化和部署灵活性。
7.7 用途G:语义时序一致性与跨帧ID维护
- 输入:连续多帧语义分割结果、实例跟踪结果、历史外参与质量统计。
- 输出:时序一致语义标签、稳定实例ID轨迹、语义漂移告警。
说明
视频重建中经常出现“同一对象跨帧标签跳变”。
语义时序一致性模块可通过时序关联和轨迹约束稳定标签,减少后续对象级分析误差。
7.8 用途H:语义质量评估与系统告警闭环
- 输入:语义3D模型、融合权重历史、更新后的相机间外参、阵列一致性日志。
- 输出:语义完整率/准确率指标、类别级异常告警、重采与重建建议。
说明
语义增强落地后必须建立质量闭环:
- 哪些类别稳定;
- 哪些类别易误检;
- 哪些相机位置导致语义盲区。
该模块直接支持数据回流与模型迭代。
7.9 小结
语义增强重建的本质,是让三维模型从“几何资产”升级为“可理解、可操作、可决策的数据资产”。
工程上建议优先建设三项核心能力:
- 2D语义到3D映射(快速建立语义底座)。
- 语义-几何联合优化(提升稳定性与可解释性)。
- 语义质量告警与数据回流(保障长期演进)。
当语义能力融入重建Pipeline后,系统价值会从“可视化展示”扩展到“自动化分析与业务闭环”。
8. 后处理与模型优化
前面章节解决的是“如何得到三维结果”,本章解决的是“如何把结果变成稳定、轻量、可运行的产品资产”。
后处理与模型优化在工程里往往决定最终交付质量:没有这一层,常见问题是模型很重、噪声多、实时性差、跨设备表现不稳定。
8.1 用途A:几何去噪与离群点清理(Geometry Cleanup)
- 输入:原始点云/网格、点级置信度、深度融合权重、可选历史重建结果。
- 输出:去噪后的点云/网格、离群点报告、局部质量热力图。
说明
重建结果常带有漂浮点、边缘毛刺、局部噪声。
可结合统计滤波、法线一致性约束和学习型去噪网络做清理,减少后续网格修复压力。

8.2 用途B:孔洞填补与表面修复(Hole Filling & Surface Repair)
- 输入:不完整网格/点云、法线信息、纹理边界信息、语义标签(可选)。
- 输出:补洞后的网格、边界连续性评分、修复区域标注。
说明
遮挡、弱纹理和反光会造成几何缺失。
后处理阶段应优先修复“结构关键区域”(边缘、连接面、接触面),避免拓扑断裂影响下游应用。
8.3 用途C:网格简化与LOD生成(面向实时渲染)
- 输入:高精网格、目标平台约束(帧率/显存/带宽)、可选语义重要性权重。
- 输出:多级LOD网格、简化误差报告、关键区域保真度评估。
说明
原始高精网格通常无法直接部署到实时系统。
应基于应用目标生成多级细节(LOD),并保证语义关键区域(如设备边缘、可交互区域)优先保留精度。
8.4 小结(第8章结论)
后处理与模型优化是三维重建从研究原型走向产品交付的关键一跳。
工程上建议优先建立三条能力链:
- 几何清理与修复链(去噪、补洞、LOD)。
- 模型轻量与部署链(蒸馏、量化)。
总结
深度学习在三维重建中的作用,已经从“单点提精度”发展为“全链路增强”。在任务入口阶段,它用于模态适配与方案选型(单目、多视图、视频、RGB-D、LiDAR)以确定可观测性上限;在数据采集阶段,用于图像质量评估、关键帧筛选、动态干扰检测和主动采集,提升输入数据可用性。进入几何前端后,深度学习主要增强标定、特征匹配、外点抑制、位姿估计与跨传感器配准,并通过置信度建模提高SfM/SLAM可解率与鲁棒性。
在深度估计与多视图几何阶段,其核心贡献是学习型MVS、深度不确定性预测与几何一致性校验,使“深度+置信度”成为融合前的标准输出。到稠密重建与表示生成阶段,深度学习用于点云融合加权、去噪补全、网格修复、隐式场建模及NeRF/3DGS表示学习,支撑从几何重建到高保真渲染的多目标需求。外观恢复阶段则聚焦纹理融合、超分增强、光照分解、反光透明材质处理与PBR参数估计,实现“形状正确”向“观感真实”升级。面对动态场景,深度学习通过静动态解耦、时序深度一致性、漂移抑制与4D建模保障时空连续。结合语义增强后,系统可实现2D到3D语义映射、实例级重建、语义-几何联合优化与开放词汇检索,使重建结果可检索、可编辑、可决策。最后在后处理与部署优化中,深度学习用于几何清理、补洞、LOD生成及模型压缩加速,推动成果走向可部署、可维护、可规模化落地。
深度學習如何重塑三維重建:從任務定義到工程落地全流程解析
三維重建工程化全景:從輸入模態與場景定義、資料質控、標定位姿、深度多視圖、稠密表示到語義增強與部署優化,梳理深度學習各階段可落地切入點。
來源:https://blog.csdn.net/2403_87969572/article/details/160624697
抓取時間(ISO本地):2026-05-18 05:17:42
前言
三維重建正在從“視覺化展示”走向“可交付、可運維、可閉環”的工程系統。過去,行業更多依賴傳統幾何方法解決位姿、深度和稠密建模問題;而在複雜場景、跨裝置部署和長期穩定執行的要求下,僅靠單一演算法已難以滿足實際需求。深度學習的價值也因此發生轉變:不再只是追求某個模組的離線精度極限,而是嵌入重建全鏈路,提升魯棒性、泛化性和系統效率。
本文圍繞三維重建Pipeline的關鍵環節展開,從任務入口定義、資料採集治理、幾何前端增強,到深度與多檢視幾何、稠密表示生成、外觀恢復、動態時序一致性、語義增強,以及後處理與部署最佳化,系統梳理深度學習在各階段的可落地切入點。核心目標是給出一套面向工程實踐的方法框架:先明確場景與目標約束,再用“學習增強 + 幾何約束 + 質量閉環”的組合正規化,構建可持續演進的三維重建系統。
文章目錄
0. 任務入口與場景定義(決定後續技術路線)
三維重建專案中,深度學習方法是否有效,往往不取決於“模型是否先進”,而取決於任務定義是否準確。入口階段需要先明確輸入模態、場景屬性和業務目標,這三者會直接決定後續在位姿估計、深度估計、表示學習和部署最佳化上的方法選擇。
0.1 輸入模態:決定可利用資訊上限
1) 單目影象(Monocular RGB)
- 優勢:採集門檻低、資料來源廣、硬體成本最低。
- 侷限:天然缺乏絕對尺度與深度約束,易受紋理缺失和光照變化影響。
- 深度學習典型作用:
- 單目深度估計提供偽幾何先驗;
- 語義分割輔助結構恢復(牆、地、天等佈局);
- 學習型特徵匹配提高SfM魯棒性。
- 適用場景:網際網路影象重建、輕量級移動採集、低成本原型驗證。
2) 多檢視影象(Multi-view RGB)
- 優勢:有視差約束,可形成穩定幾何恢復基礎。
- 侷限:依賴視角覆蓋質量,採集組織成本較高。
- 深度學習典型作用:
- 學習型MVS網路替代傳統匹配代價;
- 基於置信度的深度融合和異常剔除;
- 在弱紋理區域引入先驗提升重建完整性。
- 適用場景:文物數字化、工業零件逆向、室內外高保真重建。
3) 影片序列(Video)
- 優勢:天然具備時序連續性,利於位姿估計和稠密跟蹤。
- 侷限:動態物體、運動模糊和滾動快門會引入誤差積累。
- 深度學習典型作用:
- 關鍵幀選擇和動態區域分割;
- 時序一致性約束的深度估計;
- 聯合VO/SLAM的漂移抑制。
- 適用場景:機器人巡檢、手機掃描、自動駕駛場景建圖。
4) RGB-D / 深度相機
- 優勢:直接獲得深度,幾何恢復穩定,工程落地快。
- 侷限:深度噪聲、空洞、量程受限;戶外強光環境表現不穩定。
- 深度學習典型作用:
- 深度補全與去噪;
- RGB引導的邊緣細節修復;
- 多幀融合中的不確定性建模。
- 適用場景:室內掃描、機械臂抓取、近距重建任務。
5) LiDAR 點雲(可與視覺融合)
- 優勢:幾何精度高、遠距離測量穩定。
- 侷限:點雲稀疏、語義資訊弱、裝置成本高。
- 深度學習典型作用:
- 點雲補全和上取樣;
- LiDAR-視覺融合提升稠密重建質量;
- 學習型配準與跨感測器標定。
- 適用場景:自動駕駛、高精地圖、室外大尺度重建。
0.2 場景屬性:決定方法的可行邊界
1) 室內 vs 室外
- 室內:結構規則、尺度較小、遮擋密集,適合語義先驗與RGB-D融合。
- 室外:光照變化劇烈、尺度大、動態目標多,需更強魯棒配準與分塊重建策略。
2) 靜態 vs 動態
- 靜態場景:可採用傳統SfM/MVS與NeRF類方法獲得高質量結果。
- 動態場景:必須引入動態分割、時序建模與4D表示,否則容易出現重影、幾何撕裂和位姿漂移。
3) 小物體 vs 大場景
- 小物體重建:強調區域性細節、邊界和紋理保真,常用高解析度多檢視與隱式表示。
- 大場景重建:強調全域性一致性與效率,需分割槽建圖、層級表示和記憶體最佳化。
4) 材質複雜度
- 反光、透明、弱紋理區域是傳統幾何方法難點。
- 深度學習可透過先驗補償和可微渲染提升穩定性,但仍需多模態或物理約束輔助。
0.3 目標定義:決定最優解而非最強模型
實際專案通常不是“精度越高越好”,而是多目標折中。建議在立項時先定義主目標優先順序:
1) 幾何精度優先
- 關注絕對/相對誤差、邊緣細節、拓撲正確性。
- 方法傾向:學習型MVS + 高質量融合 + 後處理修復。
- 代價:算力和處理時長較高。
2) 視覺觀感優先
- 關注紋理清晰度、材質真實感和新視角渲染質量。
- 方法傾向:NeRF/3DGS及其高保真外觀建模分支。
- 風險:幾何可編輯性和工程部署複雜度上升。
3) 實時性優先
- 關注端側推理延遲、吞吐和功耗。
- 方法傾向:輕量網路、稀疏表示、模型壓縮與增量更新。
- 折中:在複雜場景下可能犧牲精度與完整性。
4) 成本與可部署性優先
- 關注資料採整合本、訓練成本、維護成本與穩定性。
- 方法傾向:混合式方案(傳統幾何 + 深度學習關鍵模組增強),逐步迭代替換。
0.4 深度學習切入點選型矩陣(入口階段建議)
| 約束條件 | 優先切入環節 | 推薦策略 |
|---|---|---|
| 資料少、標註少 | 位姿/匹配、深度補全 | 使用預訓練模型 + 幾何一致性自監督 |
| 裝置算力弱 | 前端特徵與輕量深度網路 | 模型蒸餾、量化、關鍵幀推理 |
| 場景動態多 | 動態分割與時序建模 | 靜動態解耦 + 4D一致性約束 |
| 需要高保真渲染 | 外觀建模與神經表示 | NeRF/3DGS + 幾何先驗融合 |
| 工業高精度需求 | 深度估計與融合最佳化 | 學習MVS + 不確定性過濾 + 網格修復 |
1. 資料採集與質量控制
在三維重建專案中,採集質量通常決定結果上限。深度學習在這一環節的核心價值,不是“直接生成三維”,而是提前識別和抑制會在後續SfM/MVS/NeRF階段被放大的誤差源,包括模糊、曝光異常、視角覆蓋不足、動態干擾和域偏移。
工程上可以把本章理解為:用學習方法做資料入口治理,把壞資料儘量擋在Pipeline前端。
1.1 本環節在重建Pipeline中的定位
資料採集與質量控制是重建流程的“前端門控層”,對後續模組有連鎖影響:
深度學習在該階段應聚焦兩類任務:
- 採集前規劃:視角策略、路徑建議、採集規範。
- 採集中篩選:質量評估、關鍵幀選擇、異常檢測與自動回採。
1.2 深度學習可落地的關鍵能力
1.2.1 影象質量評估(IQA)
目標是自動識別“不適合進入重建”的幀,常見檢測維度:
- 清晰度:運動模糊、失焦、壓縮偽影。
- 曝光質量:過曝、欠曝、強反差區域。
- 紋理可用性:大面積純色或弱紋理導致匹配困難。
- 反光/透明區域佔比:玻璃、鏡面會干擾幾何一致性。
落地方式:
- 使用無參考IQA網路(NR-IQA)打分,並按閾值過濾。
- 將IQA分數接入採集App實時提示(“請減速”“請補拍該區域”)。
- 對邊緣可用幀不直接丟棄,可降權進入後續融合。
工程收益:
- 降低匹配失敗率與重建噪聲。
- 減少後處理修復成本。
- 縮短“採完才發現不能用”的返工週期。
1.2.2 關鍵幀篩選與視角覆蓋評估
重建不是幀越多越好,而是視角覆蓋越完整越好。深度學習可用於關鍵幀抽取和覆蓋度評估:
- 相鄰幀冗餘檢測:避免近重複幀堆積。
- 視角多樣性評分:優先保留基線充分、資訊增益高的幀。
- 覆蓋空洞檢測:識別尚未拍攝到的區域。
可採用策略:
- 學習型幀表示 + 聚類篩選關鍵幀。
- 結合幾何啟發(視差、重疊率)進行混合篩選。
- 針對影片採集,做“線上關鍵幀決策”,邊採邊控。
工程收益:
- 在相近精度下減少資料量、降低算力消耗。
- 提高場景完整性,降低“某一面缺失”的機率。
1.2.3 動態干擾與異常內容檢測
動態目標(行人、車輛、擺動物體)會破壞靜態場景假設。深度學習可前置識別並隔離這類區域:
- 語義分割/例項分割:識別潛在動態類別。
- 光流一致性檢測:發現運動區域與遮擋邊界。
- 時序異常檢測:跳幀、劇烈抖動、滾動快門異常。
落地建議:
- 靜態重建任務中,對動態區域打掩碼,降低其在匹配與融合中的權重。
- 對高動態片段觸發“重採建議”。
- 記錄動態佔比,作為場景難度標籤輸入後續模組。
1.2.4 域適配與資料增強(提升泛化)
同一重建模型常在不同裝置、不同光照和不同環境下退化。採集階段可透過學習策略做“分佈對齊”:
- 風格遷移增強:模擬目標域光照/色彩。
- 幾何一致增強:旋轉、縮放、裁剪時保持標註幾何關係。
- 真實-模擬混合訓練:降低真實資料稀缺帶來的偏差。
目標是讓後續位姿估計和深度網路在跨場景時更穩定,而不是僅在單一資料集上最優。
1.2.5 主動採集(Active Reconstruction)
主動採集強調“系統告訴採集者下一步拍哪裡最有價值”,是高價效比提質方向:
- 預測當前重建不確定性熱區。
- 推薦下一視角以最大化資訊增益。
- 在移動端或機器人端實時給出路徑建議。
該能力可顯著減少盲拍和重複拍攝,特別適用於大場景和複雜結構物體。
1.3 典型實現架構(工程可直接套用)
一個常見的資料採集質量控制流水線如下:
- 輸入幀流:相機/影片實時輸入。
- 質量評分模組:IQA + 紋理可用性 + 曝光評估。
- 動態檢測模組:語義分割 + 光流異常檢測。
- 關鍵幀決策模組:冗餘抑制 + 覆蓋度最佳化。
- 反饋模組:實時提示使用者補拍/調整角度。
- 資料快取與打標:記錄質量分、動態比例、覆蓋指標。
該結構本質是“線上資料治理層”,建議作為所有重建任務的通用前端。
1.4 指標體系:如何衡量這一環節是否有效
建議將本章節效果量化為“前端質量指標 + 後端收益指標”兩類。
1.4.1 前端質量指標
- 可用幀率(可進入重建的幀佔比)。
- 平均質量分與低質量幀佔比。
- 關鍵幀壓縮率(在保留資訊前提下的資料減量)。
- 場景覆蓋度(視角覆蓋與盲區比例)。
- 動態區域佔比與剔除準確率。
1.4.2 後端收益指標
- SfM匹配內點率與位姿求解成功率。
- 深度圖完整性與噪聲水平。
- 最終點雲/網格完整度(如F-score、Completeness)。
- 端到端處理時長與返工率。
若前端質量控制有效,通常會看到:後端精度提高 + 總時長下降 + 人工干預減少。
1.5 成本與代價(必須提前評估)
深度學習前置提質雖有效,但也引入成本:
- 額外推理開銷:實時評分與分割會佔用邊端算力。
- 閾值調參成本:不同場景需不同質量門限。
- 錯殺風險:過嚴篩選可能丟失關鍵視角幀。
- 系統複雜度提升:多模組聯動增加工程維護負擔。
最佳化建議:
- 採用分級策略:輕量模型線上篩選,重模型離線複檢。
- 關鍵模組做可回退設計(保留原始幀索引,支援重跑)。
- 按場景維護引數模板(室內、室外、夜間、強反光)。
1.6 本節結論
資料採集與質量控制是三維重建中最容易被低估、但投入產出比最高的深度學習應用點。
其核心不是追求複雜模型,而是建立一套穩定的前端治理機制:先確保輸入可重建,再討論後端高精度。
在工程實踐中,建議優先落地以下三項能力:
- 線上影象質量評估(清晰度/曝光/紋理可用性)。
- 關鍵幀與覆蓋度聯合最佳化(去冗餘但不丟資訊)。
- 動態干擾檢測與掩碼化處理(保障靜態重建假設)。
做到這三點,通常即可顯著提升整條Pipeline的穩定性與最終重建質量。
2. 相機標定、位姿估計與配準
在三維重建Pipeline中,相機標定、位姿估計與多源配準構成幾何前端。該階段的誤差會被後續深度估計、融合和網格化持續放大,因此這是深度學習“最值得投入”的增強點之一。
從工程角度看,本章節目標是回答三個問題:相機是否被正確建模、位姿是否穩定可解、跨幀/跨感測器是否能精確對齊。
2.1 本環節在Pipeline中的作用邊界
該環節向後續模組提供“統一座標系下的幾何基礎”,主要輸出包括:
- 內參/畸變引數:焦距、主點、徑向與切向畸變。
- 外參與軌跡:相機在世界座標中的位姿序列。
- 跨源對齊關係:視覺、IMU、LiDAR、深度相機等感測器外參。
若該環節不穩定,常見連鎖問題包括:
- 特徵匹配多但可用內點少,RANSAC難收斂。
- 區域性軌跡可解但全域性漂移明顯,閉環後仍不一致。
- 多感測器融合出現“重影”或系統性偏移。
- 後續稠密重建出現拉伸、錯層、重複結構。
因此,深度學習在此階段的價值不是替代幾何約束,而是增強其魯棒性:幾何方法負責可解釋性,學習方法負責抗噪與泛化。
2.2 深度學習在標定中的應用
2.2.1 學習型畸變與內參估計
傳統標定依賴標定板和離線流程,工業環境下維護成本高。學習方法可用於線上校正與快速重估:
- 基於影象線結構的畸變回歸(直線應保持直線)。
- 基於重投影一致性的弱監督內參最佳化。
- 多裝置遷移學習,減少每臺裝置單獨標定成本。
輸入:是影象(單幀或多幀)以及可選的線特徵/匹配點/初始引數等約束資訊。
輸出:是相機內參和畸變引數(常帶置信度或重投影誤差),用於去畸變和後續位姿求解
2.2.2 自標定與線上重標定
在長期執行系統中,相機引數可能隨時間漂移。可用深度學習做漂移監測與觸發式重標定:
- 監測重投影誤差分佈是否異常。
- 在特定閾值觸發時啟動線上微調。
- 對高風險裝置分配更頻繁重標定週期。
該策略可降低停機標定次數,提高系統可維護性。
輸入:是執行中的多幀影象/軌跡與實時重投影誤差統計。
輸出:是“是否漂移”的告警與觸發重標定後的更新引數(並給出裝置重標定頻率建議)。
2.3 深度學習在位姿估計中的應用
2.3.1 學習型特徵點與描述子
在弱紋理、重複紋理、光照變化場景中,傳統手工特徵穩定性不足。學習型特徵可顯著提升匹配質量:
- 更強的光照與尺度魯棒性。
- 更穩定的重複定位能力。
- 更高內點率,降低RANSAC試錯成本。
典型做法是“學習特徵 + 幾何驗證”:
- 網路提取關鍵點與描述子。
- 學習匹配器給出候選對應關係。
- 幾何模型(E/F矩陣、PnP)篩內點並解位姿。
這種混合方案在工程上可解釋性高,且便於定位錯誤來源。
輸入:是兩幀/多幀影象(可含時序)。
輸出:是高質量匹配點對與置信度、篩選後的內點集合,以及最終位姿估計結果(E/F/PnP)。
2.3.2 學習型匹配與外點抑制
匹配環節是位姿穩定性的第一道關。深度學習可用於對匹配對進行上下文建模與置信度打分:
- 基於注意力機制建模全域性一致性。
- 對重複結構和紋理混淆區域進行外點抑制。
- 輸出匹配置信度,用於後續加權求解。
實際收益通常體現在:
- 同等幀數下更高可解率。
- 大基線或視角變化下更穩健。
- 低光和動態干擾條件下退化更慢。
輸入:是候選匹配點對(及其區域性特徵/上下文資訊)。
輸出:是去外點後的高置信匹配與每對匹配權重,供後續加權位姿求解使用。
2.3.3 深度輔助位姿求解(Depth-aided Pose)
當僅靠2D匹配不穩定時,可引入學習深度先驗提升位姿可觀測性:
- 單目深度作為PnP中的3D錨點來源。
- 深度置信圖用於剔除不可靠區域。
- 與光度一致性聯合最佳化抑制尺度漂移。
適合場景:
- 紋理稀少、低重複結構環境。
- 長走廊、隧道、室內白牆等幾何退化區域。
輸入:是影象匹配結果 + 預測深度圖/深度置信圖(可再加光度誤差)。
輸出:是更穩定的相機位姿與尺度估計(同時剔除低置信深度區域)。
2.4 SLAM/SfM中的深度學習增強點
2.4.1 視覺里程計(VO)前端增強
可在跟蹤前端引入學習模組:
- 關鍵點質量預測,優先使用高穩定性觀測。
- 關鍵幀選擇網路,降低冗餘和漂移積累。
- 動態區域掩碼,減少運動目標干擾。
輸入:是連續影象幀(可含光流/語義資訊)。
輸出:是篩選後的高質量關鍵點、關鍵幀集合和動態掩碼,用於更穩的前端跟蹤
2.4.2 迴環檢測與重定位
學習型全域性描述子可顯著提升迴環召回率:
- 在視角變化和光照變化下保持場景可識別性。
- 縮短重定位時間,增強長序列魯棒性。
- 與圖最佳化結合,改善全域性一致性。
輸入:是當前幀/關鍵幀影象及歷史地相簿(關鍵幀資料庫)。
輸出:是迴環候選與重定位位姿(含相似度分數),並將約束送入圖最佳化。
2.4.3 BA與圖最佳化中的學習輔助
深度學習不直接替代最佳化器,而是提供更好的輸入權重:
- 匹配邊權重學習。
- 觀測置信度建模。
- 不確定性估計用於魯棒核自適應。
結果是最佳化過程更穩定、區域性極值更少、收斂更快。
輸入:是匹配邊、觀測殘差和初始位姿/地圖狀態。
輸出:是學習得到的邊權重與不確定性(魯棒核引數),供BA/圖最佳化器加權求解並提升收斂穩定性
2.5 多感測器配準中的深度學習應用
當系統包含視覺、IMU、LiDAR或RGB-D時,跨模態配準成為關鍵難點。
2.5.1 視覺-IMU聯合標定與對齊
- 學習時間同步偏差與噪聲模型。
- 在高速運動中利用慣導穩定短時姿態。
- 透過聯合最佳化抑制純視覺漂移。
輸入:相機影象序列 + IMU 時序資料(角速度/加速度)+ 時間戳(可含初始外參)
輸出:相機-IMU 外參、時間偏移、噪聲/偏置模型,以及融合後的穩定短時位姿
2.5.2 視覺-LiDAR配準
- 學習跨模態特徵對齊(2D紋理與3D幾何)。
- 對稀疏點雲和遮擋場景增強配準魯棒性。
- 提供初始變換供ICP/NDT精修。
輸入:影象(2D)+ 點雲(3D)+ 初始對應/先驗變換(可選)
輸出:跨模態對齊關係與初始變換 T_cam_lidar(R,t),供 ICP/NDT 精修
2.5.3 RGB-D與多相機系統對齊
- 深度置信度估計用於融合加權。
- 相機間外參偏移線上監測與修正。
- 大規模多相機陣列的自動一致性檢查。
輸入:RGB 圖、深度圖、多相機同步幀(可含歷史外參與質量統計)
輸出:融合權重(深度置信度)、更新後的相機間外參、陣列一致性檢查結果/告警
2.6 常見錯誤模式與規避策略
問題1:把學習模型當作純黑盒位姿解算器
- 表現:離線效果好,跨場景後位姿崩潰且難診斷。
- 規避:採用“學習匹配 + 幾何求解”混合架構,保留可解釋中間量。
問題2:忽略不確定性,所有匹配一視同仁
- 表現:少量錯誤匹配導致全域性軌跡漂移。
- 規避:輸出置信度並在PnP/BA中做加權最佳化。
問題3:動態區域未隔離
- 表現:車輛/行人主導特徵,靜態結構估計失真。
- 規避:前端加入動態分割與運動一致性過濾。
問題4:跨感測器初值差,後端難收斂
- 表現:ICP反覆陷入區域性最優。
- 規避:先用學習模型提供跨模態粗配準,再做幾何精配準。
2.7 指標與評估建議
建議將評估分為“區域性可解性、全域性一致性、跨域魯棒性”三類。
2.7.1 區域性位姿質量
- 匹配內點率、重投影誤差、PnP成功率。
- 短窗軌跡誤差(RPE)。
- 跟蹤中斷頻次與重定位時延。
2.7.2 全域性一致性
- 絕對軌跡誤差(ATE)。
- 迴環後全域性漂移殘差。
- 稠密重建幾何一致性(錯層/重影比例)。
2.7.3 跨域魯棒性
- 不同裝置、光照、天氣條件下效能波動。
- 動態干擾場景中的退化曲線。
- 長序列穩定性(公里級/小時級)表現。
若該環節最佳化有效,通常能在後端看到:重建完整度提升、幾何噪聲下降、失敗率明顯降低。
2.8 本節結論
相機標定、位姿估計與配準不是單點演算法問題,而是整個重建Pipeline的幾何底座。
深度學習在該環節最有效的用法是“增強魯棒性和可解率”,而非完全取代幾何約束。
實踐中,推薦長期採用以下組合正規化:
- 學習型特徵與匹配提升前端觀測質量;
- 幾何求解與圖最佳化保證物理一致性與可解釋性;
- 不確定性建模貫穿匹配、求解和融合全流程。
當這三者協同,系統通常能同時獲得更高精度、更強泛化和更低失敗率,為後續深度估計與稠密重建提供穩定基礎。
3. 深度估計與多檢視幾何
這一部分聚焦三維重建Pipeline裡最核心的幾何中層:把多視角影象轉換為穩定、可融合的深度與幾何關係。
寫作上採用“用途驅動”方式:每個用途都給出你要求的 輸入 / 輸出,並附配圖連結,便於快速理解與彙報展示。
3.1 用途A:單目深度先驗生成(給位姿與MVS提供初始幾何)
- 輸入:RGB圖(單幀或短時序)、可選歷史外參、可選質量統計(清晰度/曝光評分)。
- 輸出:初始深度圖、深度置信度圖(可轉成融合權重)、尺度一致性評分。
說明
單目深度本身存在尺度歧義,但在工程中非常有價值:可作為後續多檢視深度求解的初值,也可在弱紋理區域提供“可觀測性補償”。
常見做法是使用自監督深度網路產出 depth + confidence,並把低置信區域交給後續多檢視幾何再修正。
3.2 用途B:多檢視深度推斷(MVS主幹)
- 輸入:多相機同步幀(含內外參初值)、參考幀RGB圖、候選源檢視集合、可選歷史外參與質量統計。
- 輸出:參考幀深度圖、畫素級機率/置信度圖(融合權重)、可見性掩碼。
說明
這是學習型MVS的核心環節:透過可微單應變換構造代價體(Cost Volume),再做3D正則化,得到深度與機率圖。
機率圖可以直接轉為融合階段的權重,低機率區域會被抑制,減少偽深度汙染。
3.3 用途C:多檢視幾何一致性校驗(剔除偽匹配與偽深度)
- 輸入:參考幀深度圖、源檢視深度圖、相機位姿(當前估計)、重投影誤差統計。
- 輸出:幾何一致性分數、點級/畫素級有效性掩碼、更新後的融合權重。
說明
深度估計並不等於“可直接融合”。必須透過前後向重投影、視角一致性、遮擋一致性做過濾。
這一步是控制“毛刺點雲、懸浮面片、邊緣錯層”的關鍵,通常會對後續網格質量產生決定性影響。
3.4 用途D:深度置信度建模與融合權重預測
- 輸入:RGB圖、深度圖、法線/梯度資訊、歷史幀穩定性統計(可選)。
- 輸出:融合權重(深度置信度)、不確定性熱力圖、可選“拒絕融合”掩碼。
說明
工程裡最常見問題是“平均融合把錯誤也平均進去了”。
正確做法是先預測深度不確定性,再以學習權重進行加權融合;高置信區域主導表面,低置信區域延後決策或交由更多視角補證。
3.5 用途E:相機間外參線上微調(陣列長期執行必需)
- 輸入:多相機同步幀(可含歷史外參與質量統計)、跨視角匹配對、重投影殘差序列。
- 輸出:更新後的相機間外參、外參漂移趨勢、校正可信度。
說明
多相機系統在長期執行中會出現輕微機械漂移或熱漂移。
可用學習匹配 + 幾何最佳化做線上微調:學習模組提供更穩健對應關係,幾何最佳化保證引數物理合理。
3.6 用途F:陣列一致性檢查與告警(運維與質量閉環)
- 輸入:多相機同步幀、當前外參、深度置信度統計、歷史告警日誌。
- 輸出:陣列一致性檢查結果/告警、異常相機列表、建議處理動作(重標定/降權/剔除)。
說明
這一用途直接對應場景化表達:不僅要“算出來”,還要“可監控、可報警、可運維”。
常見告警規則包括:重投影誤差突增、跨相機深度斷層、某路相機長期低置信度等。
3.7 用途G:時序深度穩定化(影片重建去抖與抗閃爍)
- 輸入:連續RGB幀、歷史深度圖、歷史外參、幀質量統計(模糊/曝光/動態比例)。
- 輸出:時序平滑後的深度序列、幀間一致性分數、時序融合權重。
說明
影片場景中,單幀深度“看起來正確”不代表時序穩定。
深度學習可結合時序先驗(光流、時序Transformer、迴圈狀態)抑制閃爍與區域性跳變,提升最終重建的連續表面質量。
3.8 用途H:神經表示中的深度幾何約束(NeRF/3DGS階段)
- 輸入:多視角RGB圖、相機位姿、可選深度先驗圖/深度置信度圖。
- 輸出:幾何一致的輻射場引數、可渲染深度圖、可用於融合的置信資訊。
說明
NeRF/3DGS強調新視角合成,但如果缺少深度幾何約束,容易出現漂浮結構與幾何歧義。
將深度圖及其置信度納入訓練損失,可顯著提升收斂速度與幾何真實性。
3.10 小結(第3章結論)
“深度估計與多檢視幾何”不是單個演算法點,而是連線前端位姿與後端融合的關鍵樞紐層。
在實際專案中,建議優先建設三項能力:
深度 + 置信度聯合輸出(不要只要深度值)。- 幾何一致性過濾與加權融合(不要直接平均)。
- 外參線上微調 + 陣列一致性告警(保證長期穩定執行)。
做到這三點,通常可以同時提升重建精度、系統穩定性和可運維性。
4. 稠密重建與三維表示生成
這一部分關注三維重建Pipeline中“落地成形”的環節:把多檢視深度、位姿和置信資訊,轉化為可使用的三維表示(點雲、網格、隱式場、神經表示等)。
4.1 用途A:深度圖融合為稠密點雲(Dense Fusion)
- 輸入:多檢視RGB圖、深度圖、相機位姿、深度置信度(融合權重)、可見性掩碼。
- 輸出:融合點雲(含點置信度)、異常點剔除結果、區域性完整性統計。
說明
這是從“每幀深度”走向“統一三維幾何”的第一步。
關鍵在於:不是簡單疊加,而是利用深度置信度做加權融合,並透過重投影一致性過濾掉漂浮點與外點。
4.2 用途B:點雲去噪、補全與上取樣(Point-level Enhancement)
- 輸入:原始融合點雲、點置信度、RGB顏色/法線資訊、可選歷史重建結果。
- 輸出:去噪點雲、補全點雲、上取樣點雲、點級質量評分。
說明
融合點雲常見問題是“噪聲多、孔洞多、邊緣破碎”。
深度學習可透過點雲補全網路與區域性幾何先驗提升完整性,特別適合弱紋理區域和遮擋區域恢復。
4.3 用途C:點雲到網格重建(Surface Meshing)
- 輸入:增強後點雲、法線估計、點置信度、可選語義邊界資訊。
- 輸出:三角網格(Mesh)、孔洞填補結果、拓撲一致性檢查報告。
說明
網格是最常見的工程交付形式(CAD、模擬、渲染、列印都依賴網格)。
深度學習可輔助邊界恢復和孔洞修復,但最終通常仍結合傳統幾何演算法(Poisson、Delaunay、Marching Cubes)保證拓撲可控。
4.4 用途D:TSDF/體素融合(可實時增量建圖)
- 輸入:RGB-D幀流或多檢視深度、相機位姿、體素網格配置、深度置信度。
- 輸出:TSDF體(或體素場)、增量網格結果、體素置信度地圖。
說明
TSDF融合是工業和機器人中非常實用的“穩健方案”:可增量更新、可實時、抗噪能力強。
深度學習常用於預測每幀深度置信度、最佳化融合權重、補洞與邊界銳化。
4.5 用途E:隱式表示生成(Occupancy / SDF)
- 輸入:多檢視RGB圖、深度先驗、相機位姿、取樣點座標、可選法線約束。
- 輸出:隱式場引數(Occupancy或SDF)、可提取網格、幾何誤差統計。
說明
隱式表示適合高質量連續表面建模,能表達複雜拓撲並減少離散網格偽影。
常見流程是先學習場函式,再透過Marching Cubes提取可用網格。
4.6 用途F:神經輻射場與3DGS表示生成(NeRF/GS)
- 輸入:多檢視RGB圖、相機位姿、可選深度圖與深度置信度、可選語義先驗。
- 輸出:NeRF或3D Gaussian Splatting引數、可渲染新視角、可匯出幾何(深度/點雲/網格)。
說明
這類表示在“視覺真實感”上表現突出,適合數字內容生產和新視角渲染。
若要用於工程幾何任務,通常需要引入深度監督與幾何一致性約束,避免外觀好但幾何漂移。
4.7 用途G:多表示協同轉換(Point ↔ Mesh ↔ Implicit ↔ Neural)
- 輸入:已有三維表示(點雲/網格/隱式場/神經表示)、質量評分、目標應用約束(渲染/模擬/檢測)。
- 輸出:目標表示格式、轉換誤差報告、應用適配版本(輕量/高保真)。
說明
工程中沒有“唯一最佳表示”,而是“按任務切換表示”:
- 視覺渲染偏NeRF/3DGS;
- 工業測量偏網格/點雲;
- 最佳化學習偏隱式場。
深度學習可在表示轉換時補償細節與抑制資訊損失。
4.8 用途H:陣列級一致性重建與線上告警
- 輸入:多相機同步幀、歷史外參與質量統計、深度置信度圖、跨相機重投影誤差。
- 輸出:融合權重(深度置信度)更新、更新後的相機間外參、陣列一致性檢查結果/告警。
說明
這一步把第3章的幾何中層能力,真正落到第4章的“最終表示質量”上:
當某路相機偏移或質量下降時,系統自動降權、觸發外參微調並告警,避免錯誤幾何進入最終模型。
4.9 小結
稠密重建與三維表示生成的關鍵,不在於“選哪個表示最先進”,而在於“是否構建了穩定的表示生產鏈路”:
- 深度與置信度聯合驅動融合(先控制錯誤傳播)。
- 按任務選擇最合適表示(點雲/網格/隱式/神經場)。
- 陣列一致性和線上告警貫穿全流程(保證長期可用)。
當這三點同時滿足時,系統才能從“能重建”走向“能交付、能維護、能規模化部署”。
5. 紋理/材質/外觀恢復
幾何重建解決的是“形狀對不對”,而紋理/材質/外觀恢復解決的是“看起來像不像、渲染是否真實、下游能否直接用”。
5.1 用途A:多檢視紋理融合(Texture Blending)
- 輸入:三維網格或點雲、多檢視RGB圖、相機位姿、可見性與遮擋資訊、影象質量統計。
- 輸出:紋理貼圖(UV紋理或點顏色)、視角加權融合結果、紋理接縫質量報告。
說明
多檢視紋理融合的關鍵是“選對來源視角並平滑拼接”。
深度學習可用於預測每個視角的紋理可信度(清晰度、反光、曝光一致性),在融合時動態賦權,減少縫合痕跡與顏色跳變。
5.2 用途B:紋理超分與細節增強(Super-Resolution for Texture)
- 輸入:低解析度紋理圖、原始多檢視RGB圖、幾何邊界資訊(法線/深度邊緣)。
- 輸出:高解析度紋理圖、細節增強結果、邊緣保真度評分。
說明
在移動端採集或遠距離採集中,紋理解析度經常不足。
可用超分網路恢復高頻細節,同時結合幾何邊界約束,避免“看起來更清晰但結構錯位”的偽細節。
5.3 用途C:光照分解與重光照一致性(Intrinsic Decomposition)
- 輸入:RGB圖、多檢視位姿、幾何先驗(法線/深度)、可選環境光資訊。
- 輸出:反照率(Albedo)、陰影/光照分量、重光照後外觀一致性結果。
說明
同一物體在不同視角可能受光照影響明顯,直接紋理融合會產生顏色不一致。
透過分解“材質本色”和“光照影響”,可獲得跨視角一致的外觀,後續在渲染和編輯中更穩定。
5.4 用途D:反光/透明材質恢復(Specular & Transparent Handling)
- 輸入:多檢視RGB圖、深度圖、偏振或多曝光資訊(可選)、歷史質量統計。
- 輸出:反光區域修正紋理、透明區域外觀估計、高風險區域告警圖。
說明
反光與透明材質是外觀恢復難點:鏡面高光會被誤當作紋理,玻璃區域常導致紋理錯貼。
深度學習可先檢測材質型別,再採用材質感知融合策略,降低偽紋理與“漂浮反光”現象。
5.5 用途E:材質引數估計(PBR引數恢復)
- 輸入:RGB圖、幾何模型(法線/粗糙幾何)、多視角觀測、可選光照先驗。
- 輸出:PBR材質貼圖(Albedo、Roughness、Metallic、Normal)、材質置信度圖。
說明
對遊戲、數字孿生和工業模擬來說,僅有“顏色紋理”不夠,還需要可物理渲染的材質引數。
深度學習可以從多視角外觀反推材質屬性,輸出可直接用於現代渲染引擎的PBR貼圖。
配圖連結
5.6 用途F:視角相關外觀建模(View-dependent Appearance)
- 輸入:多檢視RGB圖、相機位姿、可選深度先驗與法線。
- 輸出:視角相關外觀函式、新視角渲染結果、外觀一致性評分。
說明
某些材質(如金屬、車漆)會隨觀察角度變化。
如果只用“靜態紋理貼圖”表達,渲染會失真。神經渲染方法(NeRF家族)可學習視角相關外觀,在真實感上優勢明顯。
5.7 小結
紋理/材質/外觀恢復的核心不是“加一層貼圖”,而是建立一套可解釋、可評估、可運維的外觀生產鏈:
- 多檢視紋理融合要以質量權重驅動,避免接縫和色偏。
- 材質恢復要從“顏色貼圖”升級到“可渲染引數貼圖(PBR)”。
當幾何質量與外觀質量同時達標,三維重建結果才真正具備產品化價值。
6. 動態場景與時序一致性
靜態場景重建的核心是空間一致性,而動態場景重建的核心是“空間一致性 + 時間一致性”。
在真實應用中(自動駕駛、機器人巡檢、移動端掃描、人體重建),動態目標與時間漂移是導致重建失敗的主要原因之一。
6.1 用途A:動態區域檢測與靜動態解耦
- 輸入:連續RGB幀、可選深度圖/光流、歷史外參與質量統計。
- 輸出:動態區域掩碼、靜態背景掩碼、動態目標列表與置信度。
說明
動態目標(人、車、擺動物體)會破壞靜態幾何假設,導致位姿漂移和重影。
先做靜動態解耦,再分別處理,是動態場景重建的基礎動作。
6.2 用途B:時序位姿穩定與漂移抑制(Temporal Pose Stabilization)
- 輸入:多幀特徵匹配結果、IMU/里程計資訊(可選)、歷史外參、動態掩碼。
- 輸出:時序平滑位姿軌跡、漂移估計曲線、異常跳變告警。
說明
動態場景下,逐幀位姿常出現“短時抖動 + 長期漂移”。
深度學習可學習軌跡先驗與不確定性,配合圖最佳化提升全域性一致性。
6.3 用途C:時序深度一致性約束(Depth Temporal Consistency)
- 輸入:連續RGB圖、單幀/多檢視深度圖、歷史深度圖、歷史外參與質量統計。
- 輸出:時序一致深度圖、深度置信度更新(融合權重)、深度閃爍告警圖。
說明
影片重建常見問題不是“某一幀錯”,而是“幀間忽高忽低的深度閃爍”。
透過時序一致性損失、光流引導和短時記憶模型,可顯著提升深度穩定性。
6.4 用途D:動態目標的4D重建(3D + Time)
- 輸入:目標相關多檢視影片幀、相機位姿、可選人體/物體先驗模型。
- 輸出:時變幾何序列(4D表示)、動態軌跡、逐時刻外觀結果。
說明
對人體動作、工業機械臂、交通參與體等,需要重建“隨時間變化的形狀”。
4D重建不僅要還原幾何,還要保證時間連續與拓撲穩定。
6.6 用途F:時序融合權重與關鍵幀排程
- 輸入:連續RGB/深度幀、每幀質量評分、歷史外參與誤差統計、動態佔比。
- 輸出:時序融合權重(深度置信度)、關鍵幀更新策略、幀級保留/丟棄決策。
說明
線上重建系統中,不是每幀都應等權參與融合。
應根據質量、動態程度、幾何增益動態分配權重,保證“少而有效”的時序融合。
6.7 小結(第6章結論)
動態場景重建的難點從來不只是“幾何精度”,而是“幾何 + 時間 + 系統穩定性”的聯合約束。
工程上建議優先落地以下三項能力:
- 靜動態解耦 + 時序深度一致性(先控制誤差擴散)。
- 位姿漂移抑制 + 融合權重排程(保證長期穩定)。
當這三項能力建立後,系統才能在真實動態環境中持續輸出可用的三維結果。
7. 語義增強重建
傳統三維重建通常只關注幾何與外觀,但在工程應用中,還需要模型具備“語義可理解性”:哪裡是牆、哪裡是路、哪裡是裝置、哪裡是可互動物件。
語義增強重建的目標,是讓重建結果不僅視覺化,還能被檢索、分析、編輯、決策系統直接使用。
7.1 用途A:2D語義分割引導3D重建
- 輸入:多檢視RGB圖、2D語義分割結果、相機位姿、深度圖(可選)。
- 輸出:帶語義標籤的3D點雲/網格、類別置信度圖、語義覆蓋率統計。
說明
先在2D做語義分割,再透過重投影對映到3D,是最常見、最穩健的語義增強路徑。
其優勢是可複用成熟2D模型,快速獲得場景級語義結構。
7.2 用途B:例項級重建(物件分離與物件級建模)
- 輸入:多檢視RGB圖、例項分割結果、相機位姿、深度圖、歷史外參與質量統計(可選)。
- 輸出:物件級3D例項(每個物體獨立ID)、例項邊界與置信度、物件級告警(遮擋/缺失)。
說明
語義類別(如“車”)不足以支援下游任務,很多應用需要例項粒度(“第3輛車”)。
例項級重建可支援物件追蹤、資產管理、機器人抓取和工業盤點。
7.3 用途C:語義約束的深度與幾何最佳化
- 輸入:RGB圖、深度圖、語義標籤、相機位姿、重投影誤差統計。
- 輸出:語義一致深度圖、融合權重(深度置信度)更新、幾何異常區域標記。
說明
語義可以作為幾何先驗:
- “牆面/地面”應具備連續和平面傾向;
- “天空/玻璃反射”深度可信度應降低。
透過語義-幾何聯合最佳化,可減少重建噪聲並提高結構可解釋性。
7.4 用途D:語義地圖與幾何地圖聯合構建
- 輸入:多相機同步幀、位姿軌跡、語義分割結果、深度圖、歷史外參與質量統計。
- 輸出:語義地圖(類別/例項)、幾何地圖(點雲/網格/體素)、聯合一致性檢查結果/告警。
說明
在機器人和自動駕駛系統中,真正有價值的是“語義+幾何”聯合地圖,而非純幾何模型。
聯合地圖可同時服務導航、避障、巡檢、目標檢索和路徑規劃。
7.5 用途E:語義驅動的可編輯重建
- 輸入:帶語義標籤的3D模型、物件例項ID、材質/紋理資訊、使用者編輯指令。
- 輸出:可編輯語義3D資產(按類別/例項操作)、編輯日誌、區域一致性告警。
說明
語義增強的最大工程價值之一是“可編輯”:
例如只替換牆體材質、只刪除某類障礙物、只匯出某類裝置。
這使三維重建從“展示結果”轉向“生產工具”。
7.6 用途F:開放詞彙語義增強(Open-vocabulary 3D)
- 輸入:多檢視RGB圖、文字類別提示(prompt)、相機位姿、可選深度圖。
- 輸出:開放詞彙語義標籤、語義檢索結果、未知類別告警。
說明
封閉類別語義模型在新場景會失效。
開放詞彙方案(視覺-語言模型)允許用自然語言擴充套件類別,提升跨域泛化和部署靈活性。
7.7 用途G:語義時序一致性與跨幀ID維護
- 輸入:連續多幀語義分割結果、例項跟蹤結果、歷史外參與質量統計。
- 輸出:時序一致語義標籤、穩定例項ID軌跡、語義漂移告警。
說明
影片重建中經常出現“同一物件跨幀標籤跳變”。
語義時序一致性模組可透過時序關聯和軌跡約束穩定標籤,減少後續物件級分析誤差。
7.8 用途H:語義質量評估與系統告警閉環
- 輸入:語義3D模型、融合權重歷史、更新後的相機間外參、陣列一致性日誌。
- 輸出:語義完整率/準確率指標、類別級異常告警、重採與重建建議。
說明
語義增強落地後必須建立質量閉環:
- 哪些類別穩定;
- 哪些類別易誤檢;
- 哪些相機位置導致語義盲區。
該模組直接支援資料迴流與模型迭代。
7.9 小結
語義增強重建的本質,是讓三維模型從“幾何資產”升級為“可理解、可操作、可決策的資料資產”。
工程上建議優先建設三項核心能力:
- 2D語義到3D對映(快速建立語義底座)。
- 語義-幾何聯合最佳化(提升穩定性與可解釋性)。
- 語義質量告警與資料迴流(保障長期演進)。
當語義能力融入重建Pipeline後,系統價值會從“視覺化展示”擴充套件到“自動化分析與業務閉環”。
8. 後處理與模型最佳化
前面章節解決的是“如何得到三維結果”,本章解決的是“如何把結果變成穩定、輕量、可執行的產品資產”。
後處理與模型最佳化在工程裡往往決定最終交付質量:沒有這一層,常見問題是模型很重、噪聲多、實時性差、跨裝置表現不穩定。
8.1 用途A:幾何去噪與離群點清理(Geometry Cleanup)
- 輸入:原始點雲/網格、點級置信度、深度融合權重、可選歷史重建結果。
- 輸出:去噪後的點雲/網格、離群點報告、區域性質量熱力圖。
說明
重建結果常帶有漂浮點、邊緣毛刺、區域性噪聲。
可結合統計濾波、法線一致性約束和學習型去噪網路做清理,減少後續網格修復壓力。
8.2 用途B:孔洞填補與表面修復(Hole Filling & Surface Repair)
- 輸入:不完整網格/點雲、法線資訊、紋理邊界資訊、語義標籤(可選)。
- 輸出:補洞後的網格、邊界連續性評分、修復區域標註。
說明
遮擋、弱紋理和反光會造成幾何缺失。
後處理階段應優先修復“結構關鍵區域”(邊緣、連線面、接觸面),避免拓撲斷裂影響下游應用。
8.3 用途C:網格簡化與LOD生成(面向實時渲染)
- 輸入:高精網格、目標平臺約束(幀率/視訊記憶體/頻寬)、可選語義重要性權重。
- 輸出:多級LOD網格、簡化誤差報告、關鍵區域保真度評估。
說明
原始高精網格通常無法直接部署到實時系統。
應基於應用目標生成多級細節(LOD),並保證語義關鍵區域(如裝置邊緣、可互動區域)優先保留精度。
8.4 小結(第8章結論)
後處理與模型最佳化是三維重建從研究原型走向產品交付的關鍵一跳。
工程上建議優先建立三條能力鏈:
- 幾何清理與修復鏈(去噪、補洞、LOD)。
- 模型輕量與部署鏈(蒸餾、量化)。
總結
深度學習在三維重建中的作用,已經從“單點提精度”發展為“全鏈路增強”。在任務入口階段,它用於模態適配與方案選型(單目、多檢視、影片、RGB-D、LiDAR)以確定可觀測性上限;在資料採集階段,用於影象質量評估、關鍵幀篩選、動態干擾檢測和主動採集,提升輸入資料可用性。進入幾何前端後,深度學習主要增強標定、特徵匹配、外點抑制、位姿估計與跨感測器配準,並透過置信度建模提高SfM/SLAM可解率與魯棒性。
在深度估計與多檢視幾何階段,其核心貢獻是學習型MVS、深度不確定性預測與幾何一致性校驗,使“深度+置信度”成為融合前的標準輸出。到稠密重建與表示生成階段,深度學習用於點雲融合加權、去噪補全、網格修復、隱式場建模及NeRF/3DGS表示學習,支撐從幾何重建到高保真渲染的多目標需求。外觀恢復階段則聚焦紋理融合、超分增強、光照分解、反光透明材質處理與PBR引數估計,實現“形狀正確”向“觀感真實”升級。面對動態場景,深度學習透過靜動態解耦、時序深度一致性、漂移抑制與4D建模保障時空連續。結合語義增強後,系統可實現2D到3D語義對映、例項級重建、語義-幾何聯合最佳化與開放詞彙檢索,使重建結果可檢索、可編輯、可決策。最後在後處理與部署最佳化中,深度學習用於幾何清理、補洞、LOD生成及模型壓縮加速,推動成果走向可部署、可維護、可規模化落地。
How Deep Learning Reshapes 3D Reconstruction: From Task Definition to Production
Engineering-oriented 3D reconstruction pipeline: task definition, data QC, pose/calibration, depth, dense models, semantics, and deployment—with DL touchpoints.
Captured at (local ISO): 2026-05-18 05:17:42
Preface
3D reconstruction is moving from “visualization demos” to deliverable, operable, closed-loop engineering systems. The industry long relied on classical geometry for pose, depth, and dense modeling; under complex scenes, cross-device deployment, and long-run stability, a single algorithm stack is no longer enough. Deep learning’s role has shifted: not only chasing offline SOTA on one module, but embedding across the pipeline to improve robustness, generalization, and system efficiency.
This article walks the reconstruction pipeline—task definition, data acquisition, geometric front end, depth and multi-view geometry, dense representations, appearance, dynamic/temporal consistency, semantics, post-processing, and deployment—and maps practical DL entry points at each stage. The goal is an engineering playbook: clarify scenario constraints first, then build evolving systems with learning enhancement + geometric constraints + quality loops.
0. Task entry and scenario definition (sets the technical route)
三维重建项目中,深度学习方法是否有效,往往不取决于“模型是否先进”,而取决于任务定义是否准确。入口阶段需要先明确输入模态、场景属性和业务目标,这三者会直接决定后续在位姿估计、深度估计、表示学习和部署优化上的方法选择。
0.1 输入模态:决定可利用信息上限
1) 单目图像(Monocular RGB)
- Pros:采集门槛低、数据来源广、硬件成本最低。
- Cons:天然缺乏绝对尺度与深度约束,易受纹理缺失和光照变化影响。
- 深度学习典型作用:
- 单目深度估计提供伪几何先验;
- 语义分割辅助结构恢复(墙、地、天等布局);
- 学习型特征匹配提高SfM鲁棒性。
- 适用场景:互联网图像重建、轻量级移动采集、低成本原型验证。
2) 多视图图像(Multi-view RGB)
- Pros:有视差约束,可形成稳定几何恢复基础。
- Cons:依赖视角覆盖质量,采集组织成本较高。
- 深度学习典型作用:
- 学习型MVS网络替代传统匹配代价;
- 基于置信度的深度融合和异常剔除;
- 在弱纹理区域引入先验提升重建完整性。
- 适用场景:文物数字化、工业零件逆向、室内外高保真重建。
3) 视频序列(Video)
- Pros:天然具备时序连续性,利于位姿估计和稠密跟踪。
- Cons:动态物体、运动模糊和滚动快门会引入误差积累。
- 深度学习典型作用:
- 关键帧选择和动态区域分割;
- 时序一致性约束的深度估计;
- 联合VO/SLAM的漂移抑制。
- 适用场景:机器人巡检、手机扫描、自动驾驶场景建图。
4) RGB-D / 深度相机
- Pros:直接获得深度,几何恢复稳定,工程落地快。
- Cons:深度噪声、空洞、量程受限;户外强光环境表现不稳定。
- 深度学习典型作用:
- 深度补全与去噪;
- RGB引导的边缘细节修复;
- 多帧融合中的不确定性建模。
- 适用场景:室内扫描、机械臂抓取、近距重建任务。
5) LiDAR 点云(可与视觉融合)
- Pros:几何精度高、远距离测量稳定。
- Cons:点云稀疏、语义信息弱、设备成本高。
- 深度学习典型作用:
- 点云补全和上采样;
- LiDAR-视觉融合提升稠密重建质量;
- 学习型配准与跨传感器标定。
- 适用场景:自动驾驶、高精地图、室外大尺度重建。
0.2 场景属性:决定方法的可行边界
1) 室内 vs 室外
- 室内:结构规则、尺度较小、遮挡密集,适合语义先验与RGB-D融合。
- 室外:光照变化剧烈、尺度大、动态目标多,需更强鲁棒配准与分块重建策略。
2) 静态 vs 动态
- 静态场景:可采用传统SfM/MVS与NeRF类方法获得高质量结果。
- 动态场景:必须引入动态分割、时序建模与4D表示,否则容易出现重影、几何撕裂和位姿漂移。
3) 小物体 vs 大场景
- 小物体重建:强调局部细节、边界和纹理保真,常用高分辨率多视图与隐式表示。
- 大场景重建:强调全局一致性与效率,需分区建图、层级表示和内存优化。
4) 材质复杂度
- 反光、透明、弱纹理区域是传统几何方法难点。
- 深度学习可通过先验补偿和可微渲染提升稳定性,但仍需多模态或物理约束辅助。
0.3 目标定义:决定最优解而非最强模型
实际项目通常不是“精度越高越好”,而是多目标折中。建议在立项时先定义主目标优先级:
1) 几何精度优先
- 关注绝对/相对误差、边缘细节、拓扑正确性。
- 方法倾向:学习型MVS + 高质量融合 + 后处理修复。
- 代价:算力和处理时长较高。
2) 视觉观感优先
- 关注纹理清晰度、材质真实感和新视角渲染质量。
- 方法倾向:NeRF/3DGS及其高保真外观建模分支。
- 风险:几何可编辑性和工程部署复杂度上升。
3) 实时性优先
- 关注端侧推理延迟、吞吐和功耗。
- 方法倾向:轻量网络、稀疏表示、模型压缩与增量更新。
- 折中:在复杂场景下可能牺牲精度与完整性。
4) 成本与可部署性优先
- 关注数据采集成本、训练成本、维护成本与稳定性。
- 方法倾向:混合式方案(传统几何 + 深度学习关键模块增强),逐步迭代替换。
0.4 深度学习切入点选型矩阵(入口阶段建议)
| Constraints | Best entry point | Recommended strategy |
|---|---|---|
| Little data / labels | 位姿/匹配、深度补全 | Pretrained models + geometry-consistent self-supervision |
| Weak compute | 前端特征与轻量深度网络 | Distillation, quantization, key-frame inference |
| Highly dynamic scenes | 动态分割与时序建模 | Static/dynamic decoupling + 4D consistency |
| Photoreal rendering | 外观建模与神经表示 | NeRF/3DGS + geometric priors |
| Industrial precision | 深度估计与融合优化 | Learned MVS + uncertainty filtering + mesh repair |
1. Data acquisition and quality control
在三维重建项目中,采集质量通常决定结果上限。深度学习在这一环节的核心价值,不是“直接生成三维”,而是提前识别和抑制会在后续SfM/MVS/NeRF阶段被放大的误差源,包括模糊、曝光异常、视角覆盖不足、动态干扰和域偏移。
工程上可以把本章理解为:用学习方法做数据入口治理,把坏数据尽量挡在Pipeline前端。
1.1 本环节在重建Pipeline中的定位
数据采集与质量控制是重建流程的“前端门控层”,对后续模块有连锁影响:
深度学习在该阶段应聚焦两类任务:
- 采集前规划:视角策略、路径建议、采集规范。
- 采集中筛选:质量评估、关键帧选择、异常检测与自动回采。
1.2 深度学习可落地的关键能力
1.2.1 图像质量评估(IQA)
目标是自动识别“不适合进入重建”的帧,常见检测维度:
- 清晰度:运动模糊、失焦、压缩伪影。
- 曝光质量:过曝、欠曝、强反差区域。
- 纹理可用性:大面积纯色或弱纹理导致匹配困难。
- 反光/透明区域占比:玻璃、镜面会干扰几何一致性。
落地方式:
- 使用无参考IQA网络(NR-IQA)打分,并按阈值过滤。
- 将IQA分数接入采集App实时提示(“请减速”“请补拍该区域”)。
- 对边缘可用帧不直接丢弃,可降权进入后续融合。
工程收益:
- 降低匹配失败率与重建噪声。
- 减少后处理修复成本。
- 缩短“采完才发现不能用”的返工周期。
1.2.2 关键帧筛选与视角覆盖评估
重建不是帧越多越好,而是视角覆盖越完整越好。深度学习可用于关键帧抽取和覆盖度评估:
- 相邻帧冗余检测:避免近重复帧堆积。
- 视角多样性评分:优先保留基线充分、信息增益高的帧。
- 覆盖空洞检测:识别尚未拍摄到的区域。
可采用策略:
- 学习型帧表示 + 聚类筛选关键帧。
- 结合几何启发(视差、重叠率)进行混合筛选。
- 针对视频采集,做“在线关键帧决策”,边采边控。
工程收益:
- 在相近精度下减少数据量、降低算力消耗。
- 提高场景完整性,降低“某一面缺失”的概率。
1.2.3 动态干扰与异常内容检测
动态目标(行人、车辆、摆动物体)会破坏静态场景假设。深度学习可前置识别并隔离这类区域:
- 语义分割/实例分割:识别潜在动态类别。
- 光流一致性检测:发现运动区域与遮挡边界。
- 时序异常检测:跳帧、剧烈抖动、滚动快门异常。
落地建议:
- 静态重建任务中,对动态区域打掩码,降低其在匹配与融合中的权重。
- 对高动态片段触发“重采建议”。
- 记录动态占比,作为场景难度标签输入后续模块。
1.2.4 域适配与数据增强(提升泛化)
同一重建模型常在不同设备、不同光照和不同环境下退化。采集阶段可通过学习策略做“分布对齐”:
- 风格迁移增强:模拟目标域光照/色彩。
- 几何一致增强:旋转、缩放、裁剪时保持标注几何关系。
- 真实-仿真混合训练:降低真实数据稀缺带来的偏差。
目标是让后续位姿估计和深度网络在跨场景时更稳定,而不是仅在单一数据集上最优。
1.2.5 主动采集(Active Reconstruction)
主动采集强调“系统告诉采集者下一步拍哪里最有价值”,是高性价比提质方向:
- 预测当前重建不确定性热区。
- 推荐下一视角以最大化信息增益。
- 在移动端或机器人端实时给出路径建议。
该能力可显著减少盲拍和重复拍摄,特别适用于大场景和复杂结构物体。
1.3 典型实现架构(工程可直接套用)
一个常见的数据采集质量控制流水线如下:
- 输入帧流:相机/视频实时输入。
- 质量评分模块:IQA + 纹理可用性 + 曝光评估。
- 动态检测模块:语义分割 + 光流异常检测。
- 关键帧决策模块:冗余抑制 + 覆盖度优化。
- 反馈模块:实时提示用户补拍/调整角度。
- 数据缓存与打标:记录质量分、动态比例、覆盖指标。
该结构本质是“在线数据治理层”,建议作为所有重建任务的通用前端。
1.4 指标体系:如何衡量这一环节是否有效
建议将本章节效果量化为“前端质量指标 + 后端收益指标”两类。
1.4.1 前端质量指标
- 可用帧率(可进入重建的帧占比)。
- 平均质量分与低质量帧占比。
- 关键帧压缩率(在保留信息前提下的数据减量)。
- 场景覆盖度(视角覆盖与盲区比例)。
- 动态区域占比与剔除准确率。
1.4.2 后端收益指标
- SfM匹配内点率与位姿求解成功率。
- 深度图完整性与噪声水平。
- 最终点云/网格完整度(如F-score、Completeness)。
- 端到端处理时长与返工率。
若前端质量控制有效,通常会看到:后端精度提高 + 总时长下降 + 人工干预减少。
1.5 成本与代价(必须提前评估)
深度学习前置提质虽有效,但也引入成本:
- 额外推理开销:实时评分与分割会占用边端算力。
- 阈值调参成本:不同场景需不同质量门限。
- 错杀风险:过严筛选可能丢失关键视角帧。
- 系统复杂度提升:多模块联动增加工程维护负担。
优化建议:
- 采用分级策略:轻量模型在线筛选,重模型离线复检。
- 关键模块做可回退设计(保留原始帧索引,支持重跑)。
- 按场景维护参数模板(室内、室外、夜间、强反光)。
1.6 本节结论
数据采集与质量控制是三维重建中最容易被低估、但投入产出比最高的深度学习应用点。
其核心不是追求复杂模型,而是建立一套稳定的前端治理机制:先确保输入可重建,再讨论后端高精度。
在工程实践中,建议优先落地以下三项能力:
- 在线图像质量评估(清晰度/曝光/纹理可用性)。
- 关键帧与覆盖度联合优化(去冗余但不丢信息)。
- 动态干扰检测与掩码化处理(保障静态重建假设)。
做到这三点,通常即可显著提升整条Pipeline的稳定性与最终重建质量。
2. Calibration, pose estimation, and registration
在三维重建Pipeline中,相机标定、位姿估计与多源配准构成几何前端。该阶段的误差会被后续深度估计、融合和网格化持续放大,因此这是深度学习“最值得投入”的增强点之一。
从工程角度看,本章节目标是回答三个问题:相机是否被正确建模、位姿是否稳定可解、跨帧/跨传感器是否能精确对齐。
2.1 本环节在Pipeline中的作用边界
该环节向后续模块提供“统一坐标系下的几何基础”,主要输出包括:
- 内参/畸变参数:焦距、主点、径向与切向畸变。
- 外参与轨迹:相机在世界坐标中的位姿序列。
- 跨源对齐关系:视觉、IMU、LiDAR、深度相机等传感器外参。
若该环节不稳定,常见连锁问题包括:
- 特征匹配多但可用内点少,RANSAC难收敛。
- 局部轨迹可解但全局漂移明显,闭环后仍不一致。
- 多传感器融合出现“重影”或系统性偏移。
- 后续稠密重建出现拉伸、错层、重复结构。
因此,深度学习在此阶段的价值不是替代几何约束,而是增强其鲁棒性:几何方法负责可解释性,学习方法负责抗噪与泛化。
2.2 深度学习在标定中的应用
2.2.1 学习型畸变与内参估计
传统标定依赖标定板和离线流程,工业环境下维护成本高。学习方法可用于在线校正与快速重估:
- 基于图像线结构的畸变回归(直线应保持直线)。
- 基于重投影一致性的弱监督内参优化。
- 多设备迁移学习,减少每台设备单独标定成本。
输入:是图像(单帧或多帧)以及可选的线特征/匹配点/初始参数等约束信息。
输出:是相机内参和畸变参数(常带置信度或重投影误差),用于去畸变和后续位姿求解
2.2.2 自标定与在线重标定
在长期运行系统中,相机参数可能随时间漂移。可用深度学习做漂移监测与触发式重标定:
- 监测重投影误差分布是否异常。
- 在特定阈值触发时启动在线微调。
- 对高风险设备分配更频繁重标定周期。
该策略可降低停机标定次数,提高系统可维护性。
输入:是运行中的多帧图像/轨迹与实时重投影误差统计。
输出:是“是否漂移”的告警与触发重标定后的更新参数(并给出设备重标定频率建议)。
2.3 深度学习在位姿估计中的应用
2.3.1 学习型特征点与描述子
在弱纹理、重复纹理、光照变化场景中,传统手工特征稳定性不足。学习型特征可显著提升匹配质量:
- 更强的光照与尺度鲁棒性。
- 更稳定的重复定位能力。
- 更高内点率,降低RANSAC试错成本。
典型做法是“学习特征 + 几何验证”:
- 网络提取关键点与描述子。
- 学习匹配器给出候选对应关系。
- 几何模型(E/F矩阵、PnP)筛内点并解位姿。
这种混合方案在工程上可解释性高,且便于定位错误来源。
输入:是两帧/多帧图像(可含时序)。
输出:是高质量匹配点对与置信度、筛选后的内点集合,以及最终位姿估计结果(E/F/PnP)。
2.3.2 学习型匹配与外点抑制
匹配环节是位姿稳定性的第一道关。深度学习可用于对匹配对进行上下文建模与置信度打分:
- 基于注意力机制建模全局一致性。
- 对重复结构和纹理混淆区域进行外点抑制。
- 输出匹配置信度,用于后续加权求解。
实际收益通常体现在:
- 同等帧数下更高可解率。
- 大基线或视角变化下更稳健。
- 低光和动态干扰条件下退化更慢。
输入:是候选匹配点对(及其局部特征/上下文信息)。
输出:是去外点后的高置信匹配与每对匹配权重,供后续加权位姿求解使用。
2.3.3 深度辅助位姿求解(Depth-aided Pose)
当仅靠2D匹配不稳定时,可引入学习深度先验提升位姿可观测性:
- 单目深度作为PnP中的3D锚点来源。
- 深度置信图用于剔除不可靠区域。
- 与光度一致性联合优化抑制尺度漂移。
适合场景:
- 纹理稀少、低重复结构环境。
- 长走廊、隧道、室内白墙等几何退化区域。
输入:是图像匹配结果 + 预测深度图/深度置信图(可再加光度误差)。
输出:是更稳定的相机位姿与尺度估计(同时剔除低置信深度区域)。
2.4 SLAM/SfM中的深度学习增强点
2.4.1 视觉里程计(VO)前端增强
可在跟踪前端引入学习模块:
- 关键点质量预测,优先使用高稳定性观测。
- 关键帧选择网络,降低冗余和漂移积累。
- 动态区域掩码,减少运动目标干扰。
输入:是连续图像帧(可含光流/语义信息)。
输出:是筛选后的高质量关键点、关键帧集合和动态掩码,用于更稳的前端跟踪
2.4.2 回环检测与重定位
学习型全局描述子可显著提升回环召回率:
- 在视角变化和光照变化下保持场景可识别性。
- 缩短重定位时间,增强长序列鲁棒性。
- 与图优化结合,改善全局一致性。
输入:是当前帧/关键帧图像及历史地图库(关键帧数据库)。
输出:是回环候选与重定位位姿(含相似度分数),并将约束送入图优化。
2.4.3 BA与图优化中的学习辅助
深度学习不直接替代优化器,而是提供更好的输入权重:
- 匹配边权重学习。
- 观测置信度建模。
- 不确定性估计用于鲁棒核自适应。
结果是优化过程更稳定、局部极值更少、收敛更快。
输入:是匹配边、观测残差和初始位姿/地图状态。
输出:是学习得到的边权重与不确定性(鲁棒核参数),供BA/图优化器加权求解并提升收敛稳定性
2.5 多传感器配准中的深度学习应用
当系统包含视觉、IMU、LiDAR或RGB-D时,跨模态配准成为关键难点。
2.5.1 视觉-IMU联合标定与对齐
- 学习时间同步偏差与噪声模型。
- 在高速运动中利用惯导稳定短时姿态。
- 通过联合优化抑制纯视觉漂移。
输入:相机图像序列 + IMU 时序数据(角速度/加速度)+ 时间戳(可含初始外参)
输出:相机-IMU 外参、时间偏移、噪声/偏置模型,以及融合后的稳定短时位姿
2.5.2 视觉-LiDAR配准
- 学习跨模态特征对齐(2D纹理与3D几何)。
- 对稀疏点云和遮挡场景增强配准鲁棒性。
- 提供初始变换供ICP/NDT精修。
输入:图像(2D)+ 点云(3D)+ 初始对应/先验变换(可选)
输出:跨模态对齐关系与初始变换 T_cam_lidar(R,t),供 ICP/NDT 精修
2.5.3 RGB-D与多相机系统对齐
- 深度置信度估计用于融合加权。
- 相机间外参偏移在线监测与修正。
- 大规模多相机阵列的自动一致性检查。
输入:RGB 图、深度图、多相机同步帧(可含历史外参与质量统计)
输出:融合权重(深度置信度)、更新后的相机间外参、阵列一致性检查结果/告警
2.6 常见错误模式与规避策略
问题1:把学习模型当作纯黑盒位姿解算器
- 表现:离线效果好,跨场景后位姿崩溃且难诊断。
- 规避:采用“学习匹配 + 几何求解”混合架构,保留可解释中间量。
问题2:忽略不确定性,所有匹配一视同仁
- 表现:少量错误匹配导致全局轨迹漂移。
- 规避:输出置信度并在PnP/BA中做加权优化。
问题3:动态区域未隔离
- 表现:车辆/行人主导特征,静态结构估计失真。
- 规避:前端加入动态分割与运动一致性过滤。
问题4:跨传感器初值差,后端难收敛
- 表现:ICP反复陷入局部最优。
- 规避:先用学习模型提供跨模态粗配准,再做几何精配准。
2.7 指标与评估建议
建议将评估分为“局部可解性、全局一致性、跨域鲁棒性”三类。
2.7.1 局部位姿质量
- 匹配内点率、重投影误差、PnP成功率。
- 短窗轨迹误差(RPE)。
- 跟踪中断频次与重定位时延。
2.7.2 全局一致性
- 绝对轨迹误差(ATE)。
- 回环后全局漂移残差。
- 稠密重建几何一致性(错层/重影比例)。
2.7.3 跨域鲁棒性
- 不同设备、光照、天气条件下性能波动。
- 动态干扰场景中的退化曲线。
- 长序列稳定性(公里级/小时级)表现。
若该环节优化有效,通常能在后端看到:重建完整度提升、几何噪声下降、失败率明显降低。
2.8 本节结论
相机标定、位姿估计与配准不是单点算法问题,而是整个重建Pipeline的几何底座。
深度学习在该环节最有效的用法是“增强鲁棒性和可解率”,而非完全取代几何约束。
实践中,推荐长期采用以下组合范式:
- 学习型特征与匹配提升前端观测质量;
- 几何求解与图优化保证物理一致性与可解释性;
- 不确定性建模贯穿匹配、求解和融合全流程。
当这三者协同,系统通常能同时获得更高精度、更强泛化和更低失败率,为后续深度估计与稠密重建提供稳定基础。
3. Depth estimation and multi-view geometry
这一部分聚焦三维重建Pipeline里最核心的几何中层:把多视角图像转换为稳定、可融合的深度与几何关系。
写作上采用“用途驱动”方式:每个用途都给出你要求的 输入 / 输出,并附配图链接,便于快速理解与汇报展示。
3.1 用途A:单目深度先验生成(给位姿与MVS提供初始几何)
- Input:RGB图(单帧或短时序)、可选历史外参、可选质量统计(清晰度/曝光评分)。
- Output:初始深度图、深度置信度图(可转成融合权重)、尺度一致性评分。
Notes
单目深度本身存在尺度歧义,但在工程中非常有价值:可作为后续多视图深度求解的初值,也可在弱纹理区域提供“可观测性补偿”。
常见做法是使用自监督深度网络产出 depth + confidence,并把低置信区域交给后续多视图几何再修正。
3.2 用途B:多视图深度推断(MVS主干)
- Input:多相机同步帧(含内外参初值)、参考帧RGB图、候选源视图集合、可选历史外参与质量统计。
- Output:参考帧深度图、像素级概率/置信度图(融合权重)、可见性掩码。
Notes
这是学习型MVS的核心环节:通过可微单应变换构造代价体(Cost Volume),再做3D正则化,得到深度与概率图。
概率图可以直接转为融合阶段的权重,低概率区域会被抑制,减少伪深度污染。
3.3 用途C:多视图几何一致性校验(剔除伪匹配与伪深度)
- Input:参考帧深度图、源视图深度图、相机位姿(当前估计)、重投影误差统计。
- Output:几何一致性分数、点级/像素级有效性掩码、更新后的融合权重。
Notes
深度估计并不等于“可直接融合”。必须通过前后向重投影、视角一致性、遮挡一致性做过滤。
这一步是控制“毛刺点云、悬浮面片、边缘错层”的关键,通常会对后续网格质量产生决定性影响。
3.4 用途D:深度置信度建模与融合权重预测
- Input:RGB图、深度图、法线/梯度信息、历史帧稳定性统计(可选)。
- Output:融合权重(深度置信度)、不确定性热力图、可选“拒绝融合”掩码。
Notes
工程里最常见问题是“平均融合把错误也平均进去了”。
正确做法是先预测深度不确定性,再以学习权重进行加权融合;高置信区域主导表面,低置信区域延后决策或交由更多视角补证。
3.5 用途E:相机间外参在线微调(阵列长期运行必需)
- Input:多相机同步帧(可含历史外参与质量统计)、跨视角匹配对、重投影残差序列。
- Output:更新后的相机间外参、外参漂移趋势、校正可信度。
Notes
多相机系统在长期运行中会出现轻微机械漂移或热漂移。
可用学习匹配 + 几何优化做在线微调:学习模块提供更稳健对应关系,几何优化保证参数物理合理。
3.6 用途F:阵列一致性检查与告警(运维与质量闭环)
- Input:多相机同步帧、当前外参、深度置信度统计、历史告警日志。
- Output:阵列一致性检查结果/告警、异常相机列表、建议处理动作(重标定/降权/剔除)。
Notes
这一用途直接对应场景化表达:不仅要“算出来”,还要“可监控、可报警、可运维”。
常见告警规则包括:重投影误差突增、跨相机深度断层、某路相机长期低置信度等。
3.7 用途G:时序深度稳定化(视频重建去抖与抗闪烁)
- Input:连续RGB帧、历史深度图、历史外参、帧质量统计(模糊/曝光/动态比例)。
- Output:时序平滑后的深度序列、帧间一致性分数、时序融合权重。
Notes
视频场景中,单帧深度“看起来正确”不代表时序稳定。
深度学习可结合时序先验(光流、时序Transformer、循环状态)抑制闪烁与局部跳变,提升最终重建的连续表面质量。
3.8 用途H:神经表示中的深度几何约束(NeRF/3DGS阶段)
- Input:多视角RGB图、相机位姿、可选深度先验图/深度置信度图。
- Output:几何一致的辐射场参数、可渲染深度图、可用于融合的置信信息。
Notes
NeRF/3DGS强调新视角合成,但如果缺少深度几何约束,容易出现漂浮结构与几何歧义。
将深度图及其置信度纳入训练损失,可显著提升收敛速度与几何真实性。
3.10 小结(第3章结论)
“深度估计与多视图几何”不是单个算法点,而是连接前端位姿与后端融合的关键枢纽层。
在实际项目中,建议优先建设三项能力:
深度 + 置信度联合输出(不要只要深度值)。- 几何一致性过滤与加权融合(不要直接平均)。
- 外参在线微调 + 阵列一致性告警(保证长期稳定运行)。
做到这三点,通常可以同时提升重建精度、系统稳定性和可运维性。
4. Dense reconstruction and 3D representations
这一部分关注三维重建Pipeline中“落地成形”的环节:把多视图深度、位姿和置信信息,转化为可使用的三维表示(点云、网格、隐式场、神经表示等)。
4.1 用途A:深度图融合为稠密点云(Dense Fusion)
- Input:多视图RGB图、深度图、相机位姿、深度置信度(融合权重)、可见性掩码。
- Output:融合点云(含点置信度)、异常点剔除结果、局部完整性统计。
Notes
这是从“每帧深度”走向“统一三维几何”的第一步。
关键在于:不是简单叠加,而是利用深度置信度做加权融合,并通过重投影一致性过滤掉漂浮点与外点。
4.2 用途B:点云去噪、补全与上采样(Point-level Enhancement)
- Input:原始融合点云、点置信度、RGB颜色/法线信息、可选历史重建结果。
- Output:去噪点云、补全点云、上采样点云、点级质量评分。
Notes
融合点云常见问题是“噪声多、孔洞多、边缘破碎”。
深度学习可通过点云补全网络与局部几何先验提升完整性,特别适合弱纹理区域和遮挡区域恢复。
4.3 用途C:点云到网格重建(Surface Meshing)
- Input:增强后点云、法线估计、点置信度、可选语义边界信息。
- Output:三角网格(Mesh)、孔洞填补结果、拓扑一致性检查报告。
Notes
网格是最常见的工程交付形式(CAD、仿真、渲染、打印都依赖网格)。
深度学习可辅助边界恢复和孔洞修复,但最终通常仍结合传统几何算法(Poisson、Delaunay、Marching Cubes)保证拓扑可控。
4.4 用途D:TSDF/体素融合(可实时增量建图)
- Input:RGB-D帧流或多视图深度、相机位姿、体素网格配置、深度置信度。
- Output:TSDF体(或体素场)、增量网格结果、体素置信度地图。
Notes
TSDF融合是工业和机器人中非常实用的“稳健方案”:可增量更新、可实时、抗噪能力强。
深度学习常用于预测每帧深度置信度、优化融合权重、补洞与边界锐化。
4.5 用途E:隐式表示生成(Occupancy / SDF)
- Input:多视图RGB图、深度先验、相机位姿、采样点坐标、可选法线约束。
- Output:隐式场参数(Occupancy或SDF)、可提取网格、几何误差统计。
Notes
隐式表示适合高质量连续表面建模,能表达复杂拓扑并减少离散网格伪影。
常见流程是先学习场函数,再通过Marching Cubes提取可用网格。
4.6 用途F:神经辐射场与3DGS表示生成(NeRF/GS)
- Input:多视图RGB图、相机位姿、可选深度图与深度置信度、可选语义先验。
- Output:NeRF或3D Gaussian Splatting参数、可渲染新视角、可导出几何(深度/点云/网格)。
Notes
这类表示在“视觉真实感”上表现突出,适合数字内容生产和新视角渲染。
若要用于工程几何任务,通常需要引入深度监督与几何一致性约束,避免外观好但几何漂移。
4.7 用途G:多表示协同转换(Point ↔ Mesh ↔ Implicit ↔ Neural)
- Input:已有三维表示(点云/网格/隐式场/神经表示)、质量评分、目标应用约束(渲染/仿真/检测)。
- Output:目标表示格式、转换误差报告、应用适配版本(轻量/高保真)。
Notes
工程中没有“唯一最佳表示”,而是“按任务切换表示”:
- 视觉渲染偏NeRF/3DGS;
- 工业测量偏网格/点云;
- 优化学习偏隐式场。
深度学习可在表示转换时补偿细节与抑制信息损失。
4.8 用途H:阵列级一致性重建与在线告警
- Input:多相机同步帧、历史外参与质量统计、深度置信度图、跨相机重投影误差。
- Output:融合权重(深度置信度)更新、更新后的相机间外参、阵列一致性检查结果/告警。
Notes
这一步把第3章的几何中层能力,真正落到第4章的“最终表示质量”上:
当某路相机偏移或质量下降时,系统自动降权、触发外参微调并告警,避免错误几何进入最终模型。
4.9 小结
稠密重建与三维表示生成的关键,不在于“选哪个表示最先进”,而在于“是否构建了稳定的表示生产链路”:
- 深度与置信度联合驱动融合(先控制错误传播)。
- 按任务选择最合适表示(点云/网格/隐式/神经场)。
- 阵列一致性和在线告警贯穿全流程(保证长期可用)。
当这三点同时满足时,系统才能从“能重建”走向“能交付、能维护、能规模化部署”。
5. Texture, material, and appearance
几何重建解决的是“形状对不对”,而纹理/材质/外观恢复解决的是“看起来像不像、渲染是否真实、下游能否直接用”。
5.1 用途A:多视图纹理融合(Texture Blending)
- Input:三维网格或点云、多视图RGB图、相机位姿、可见性与遮挡信息、图像质量统计。
- Output:纹理贴图(UV纹理或点颜色)、视角加权融合结果、纹理接缝质量报告。
Notes
多视图纹理融合的关键是“选对来源视角并平滑拼接”。
深度学习可用于预测每个视角的纹理可信度(清晰度、反光、曝光一致性),在融合时动态赋权,减少缝合痕迹与颜色跳变。
5.2 用途B:纹理超分与细节增强(Super-Resolution for Texture)
- Input:低分辨率纹理图、原始多视图RGB图、几何边界信息(法线/深度边缘)。
- Output:高分辨率纹理图、细节增强结果、边缘保真度评分。
Notes
在移动端采集或远距离采集中,纹理分辨率经常不足。
可用超分网络恢复高频细节,同时结合几何边界约束,避免“看起来更清晰但结构错位”的伪细节。
5.3 用途C:光照分解与重光照一致性(Intrinsic Decomposition)
- Input:RGB图、多视图位姿、几何先验(法线/深度)、可选环境光信息。
- Output:反照率(Albedo)、阴影/光照分量、重光照后外观一致性结果。
Notes
同一物体在不同视角可能受光照影响明显,直接纹理融合会产生颜色不一致。
通过分解“材质本色”和“光照影响”,可获得跨视角一致的外观,后续在渲染和编辑中更稳定。
5.4 用途D:反光/透明材质恢复(Specular & Transparent Handling)
- Input:多视图RGB图、深度图、偏振或多曝光信息(可选)、历史质量统计。
- Output:反光区域修正纹理、透明区域外观估计、高风险区域告警图。
Notes
反光与透明材质是外观恢复难点:镜面高光会被误当作纹理,玻璃区域常导致纹理错贴。
深度学习可先检测材质类型,再采用材质感知融合策略,降低伪纹理与“漂浮反光”现象。
5.5 用途E:材质参数估计(PBR参数恢复)
- Input:RGB图、几何模型(法线/粗糙几何)、多视角观测、可选光照先验。
- Output:PBR材质贴图(Albedo、Roughness、Metallic、Normal)、材质置信度图。
Notes
对游戏、数字孪生和工业仿真来说,仅有“颜色纹理”不够,还需要可物理渲染的材质参数。
深度学习可以从多视角外观反推材质属性,输出可直接用于现代渲染引擎的PBR贴图。
配图链接
5.6 用途F:视角相关外观建模(View-dependent Appearance)
- Input:多视图RGB图、相机位姿、可选深度先验与法线。
- Output:视角相关外观函数、新视角渲染结果、外观一致性评分。
Notes
某些材质(如金属、车漆)会随观察角度变化。
如果只用“静态纹理贴图”表达,渲染会失真。神经渲染方法(NeRF家族)可学习视角相关外观,在真实感上优势明显。
5.7 小结
纹理/材质/外观恢复的核心不是“加一层贴图”,而是建立一套可解释、可评估、可运维的外观生产链:
- 多视图纹理融合要以质量权重驱动,避免接缝和色偏。
- 材质恢复要从“颜色贴图”升级到“可渲染参数贴图(PBR)”。
当几何质量与外观质量同时达标,三维重建结果才真正具备产品化价值。
6. Dynamic scenes and temporal consistency
静态场景重建的核心是空间一致性,而动态场景重建的核心是“空间一致性 + 时间一致性”。
在真实应用中(自动驾驶、机器人巡检、移动端扫描、人体重建),动态目标与时间漂移是导致重建失败的主要原因之一。
6.1 用途A:动态区域检测与静动态解耦
- Input:连续RGB帧、可选深度图/光流、历史外参与质量统计。
- Output:动态区域掩码、静态背景掩码、动态目标列表与置信度。
Notes
动态目标(人、车、摆动物体)会破坏静态几何假设,导致位姿漂移和重影。
先做静动态解耦,再分别处理,是动态场景重建的基础动作。
6.2 用途B:时序位姿稳定与漂移抑制(Temporal Pose Stabilization)
- Input:多帧特征匹配结果、IMU/里程计信息(可选)、历史外参、动态掩码。
- Output:时序平滑位姿轨迹、漂移估计曲线、异常跳变告警。
Notes
动态场景下,逐帧位姿常出现“短时抖动 + 长期漂移”。
深度学习可学习轨迹先验与不确定性,配合图优化提升全局一致性。
6.3 用途C:时序深度一致性约束(Depth Temporal Consistency)
- Input:连续RGB图、单帧/多视图深度图、历史深度图、历史外参与质量统计。
- Output:时序一致深度图、深度置信度更新(融合权重)、深度闪烁告警图。
Notes
视频重建常见问题不是“某一帧错”,而是“帧间忽高忽低的深度闪烁”。
通过时序一致性损失、光流引导和短时记忆模型,可显著提升深度稳定性。
6.4 用途D:动态目标的4D重建(3D + Time)
- Input:目标相关多视图视频帧、相机位姿、可选人体/物体先验模型。
- Output:时变几何序列(4D表示)、动态轨迹、逐时刻外观结果。
Notes
对人体动作、工业机械臂、交通参与体等,需要重建“随时间变化的形状”。
4D重建不仅要还原几何,还要保证时间连续与拓扑稳定。
6.6 用途F:时序融合权重与关键帧调度
- Input:连续RGB/深度帧、每帧质量评分、历史外参与误差统计、动态占比。
- Output:时序融合权重(深度置信度)、关键帧更新策略、帧级保留/丢弃决策。
Notes
在线重建系统中,不是每帧都应等权参与融合。
应根据质量、动态程度、几何增益动态分配权重,保证“少而有效”的时序融合。
6.7 小结(第6章结论)
动态场景重建的难点从来不只是“几何精度”,而是“几何 + 时间 + 系统稳定性”的联合约束。
工程上建议优先落地以下三项能力:
- 静动态解耦 + 时序深度一致性(先控制误差扩散)。
- 位姿漂移抑制 + 融合权重调度(保证长期稳定)。
当这三项能力建立后,系统才能在真实动态环境中持续输出可用的三维结果。
7. Semantics-enhanced reconstruction
传统三维重建通常只关注几何与外观,但在工程应用中,还需要模型具备“语义可理解性”:哪里是墙、哪里是路、哪里是设备、哪里是可交互对象。
语义增强重建的目标,是让重建结果不仅可视化,还能被检索、分析、编辑、决策系统直接使用。
7.1 用途A:2D语义分割引导3D重建
- Input:多视图RGB图、2D语义分割结果、相机位姿、深度图(可选)。
- Output:带语义标签的3D点云/网格、类别置信度图、语义覆盖率统计。
Notes
先在2D做语义分割,再通过重投影映射到3D,是最常见、最稳健的语义增强路径。
其优势是可复用成熟2D模型,快速获得场景级语义结构。
7.2 用途B:实例级重建(对象分离与对象级建模)
- Input:多视图RGB图、实例分割结果、相机位姿、深度图、历史外参与质量统计(可选)。
- Output:对象级3D实例(每个物体独立ID)、实例边界与置信度、对象级告警(遮挡/缺失)。
Notes
语义类别(如“车”)不足以支持下游任务,很多应用需要实例粒度(“第3辆车”)。
实例级重建可支持对象追踪、资产管理、机器人抓取和工业盘点。
7.3 用途C:语义约束的深度与几何优化
- Input:RGB图、深度图、语义标签、相机位姿、重投影误差统计。
- Output:语义一致深度图、融合权重(深度置信度)更新、几何异常区域标记。
Notes
语义可以作为几何先验:
- “墙面/地面”应具备连续和平面倾向;
- “天空/玻璃反射”深度可信度应降低。
通过语义-几何联合优化,可减少重建噪声并提高结构可解释性。
7.4 用途D:语义地图与几何地图联合构建
- Input:多相机同步帧、位姿轨迹、语义分割结果、深度图、历史外参与质量统计。
- Output:语义地图(类别/实例)、几何地图(点云/网格/体素)、联合一致性检查结果/告警。
Notes
在机器人和自动驾驶系统中,真正有价值的是“语义+几何”联合地图,而非纯几何模型。
联合地图可同时服务导航、避障、巡检、目标检索和路径规划。
7.5 用途E:语义驱动的可编辑重建
- Input:带语义标签的3D模型、对象实例ID、材质/纹理信息、用户编辑指令。
- Output:可编辑语义3D资产(按类别/实例操作)、编辑日志、区域一致性告警。
Notes
语义增强的最大工程价值之一是“可编辑”:
例如只替换墙体材质、只删除某类障碍物、只导出某类设备。
这使三维重建从“展示结果”转向“生产工具”。
7.6 用途F:开放词汇语义增强(Open-vocabulary 3D)
- Input:多视图RGB图、文本类别提示(prompt)、相机位姿、可选深度图。
- Output:开放词汇语义标签、语义检索结果、未知类别告警。
Notes
封闭类别语义模型在新场景会失效。
开放词汇方案(视觉-语言模型)允许用自然语言扩展类别,提升跨域泛化和部署灵活性。
7.7 用途G:语义时序一致性与跨帧ID维护
- Input:连续多帧语义分割结果、实例跟踪结果、历史外参与质量统计。
- Output:时序一致语义标签、稳定实例ID轨迹、语义漂移告警。
Notes
视频重建中经常出现“同一对象跨帧标签跳变”。
语义时序一致性模块可通过时序关联和轨迹约束稳定标签,减少后续对象级分析误差。
7.8 用途H:语义质量评估与系统告警闭环
- Input:语义3D模型、融合权重历史、更新后的相机间外参、阵列一致性日志。
- Output:语义完整率/准确率指标、类别级异常告警、重采与重建建议。
Notes
语义增强落地后必须建立质量闭环:
- 哪些类别稳定;
- 哪些类别易误检;
- 哪些相机位置导致语义盲区。
该模块直接支持数据回流与模型迭代。
7.9 小结
语义增强重建的本质,是让三维模型从“几何资产”升级为“可理解、可操作、可决策的数据资产”。
工程上建议优先建设三项核心能力:
- 2D语义到3D映射(快速建立语义底座)。
- 语义-几何联合优化(提升稳定性与可解释性)。
- 语义质量告警与数据回流(保障长期演进)。
当语义能力融入重建Pipeline后,系统价值会从“可视化展示”扩展到“自动化分析与业务闭环”。
8. Post-processing and model optimization
前面章节解决的是“如何得到三维结果”,本章解决的是“如何把结果变成稳定、轻量、可运行的产品资产”。
后处理与模型优化在工程里往往决定最终交付质量:没有这一层,常见问题是模型很重、噪声多、实时性差、跨设备表现不稳定。
8.1 用途A:几何去噪与离群点清理(Geometry Cleanup)
- Input:原始点云/网格、点级置信度、深度融合权重、可选历史重建结果。
- Output:去噪后的点云/网格、离群点报告、局部质量热力图。
Notes
重建结果常带有漂浮点、边缘毛刺、局部噪声。
可结合统计滤波、法线一致性约束和学习型去噪网络做清理,减少后续网格修复压力。
8.2 用途B:孔洞填补与表面修复(Hole Filling & Surface Repair)
- Input:不完整网格/点云、法线信息、纹理边界信息、语义标签(可选)。
- Output:补洞后的网格、边界连续性评分、修复区域标注。
Notes
遮挡、弱纹理和反光会造成几何缺失。
后处理阶段应优先修复“结构关键区域”(边缘、连接面、接触面),避免拓扑断裂影响下游应用。
8.3 用途C:网格简化与LOD生成(面向实时渲染)
- Input:高精网格、目标平台约束(帧率/显存/带宽)、可选语义重要性权重。
- Output:多级LOD网格、简化误差报告、关键区域保真度评估。
Notes
原始高精网格通常无法直接部署到实时系统。
应基于应用目标生成多级细节(LOD),并保证语义关键区域(如设备边缘、可交互区域)优先保留精度。
8.4 小结(第8章结论)
后处理与模型优化是三维重建从研究原型走向产品交付的关键一跳。
工程上建议优先建立三条能力链:
- 几何清理与修复链(去噪、补洞、LOD)。
- 模型轻量与部署链(蒸馏、量化)。
Summary
深度学习在三维重建中的作用,已经从“单点提精度”发展为“全链路增强”。在任务入口阶段,它用于模态适配与方案选型(单目、多视图、视频、RGB-D、LiDAR)以确定可观测性上限;在数据采集阶段,用于图像质量评估、关键帧筛选、动态干扰检测和主动采集,提升输入数据可用性。进入几何前端后,深度学习主要增强标定、特征匹配、外点抑制、位姿估计与跨传感器配准,并通过置信度建模提高SfM/SLAM可解率与鲁棒性。
在深度估计与多视图几何阶段,其核心贡献是学习型MVS、深度不确定性预测与几何一致性校验,使“深度+置信度”成为融合前的标准输出。到稠密重建与表示生成阶段,深度学习用于点云融合加权、去噪补全、网格修复、隐式场建模及NeRF/3DGS表示学习,支撑从几何重建到高保真渲染的多目标需求。外观恢复阶段则聚焦纹理融合、超分增强、光照分解、反光透明材质处理与PBR参数估计,实现“形状正确”向“观感真实”升级。面对动态场景,深度学习通过静动态解耦、时序深度一致性、漂移抑制与4D建模保障时空连续。结合语义增强后,系统可实现2D到3D语义映射、实例级重建、语义-几何联合优化与开放词汇检索,使重建结果可检索、可编辑、可决策。最后在后处理与部署优化中,深度学习用于几何清理、补洞、LOD生成及模型压缩加速,推动成果走向可部署、可维护、可规模化落地。