概念解析:机器视觉如何赋予机器“三维双眼”——3D重建技术全景指南
从2D影像恢复三维几何的全景科普:被动视觉(单目SfM、双目立体、NeRF、3D高斯泼溅)与主动视觉(结构光、ToF),涵盖原理、流程、适用场景与主要瓶颈,并附核心文献索引。
前言
在人工智能的浪潮中,如果说传统的2D图像识别是让机器“认出”物体,那么**3D重建(3D Reconstruction)**则是让机器真正“理解”物理世界。通过机器视觉实现3D重建,是赋予机器人、无人机和自动驾驶汽车空间感知能力的核心技术。
1. 什么是通过机器视觉实现3D重建?
定义
通过机器视觉实现的3D重建,是指利用光学传感器(如相机)获取的2D图像序列,结合计算机视觉算法,恢复物体的三维几何形状、空间位置以及表面纹理的过程。
核心本质:从2D到3D的逆向投影
在物理世界中,3D物体通过相机的透镜成像在2D感光元件上,这是一个降维的过程(丢失了深度信息 Z Z Z)。3D重建的目标就是通过数学模型和算法,将这些丢失的深度信息找回来,把像素点还原到三维坐标系( X , Y , Z X, Y, Z X,Y,Z)中。
关键概念
- 点云(Point Cloud): 重建的第一步通常是生成大量带有空间坐标的采样点。
- 三角剖分(Triangulation): 利用几何关系确定点在空间中的位置。
- 深度图(Depth Map): 每个像素点代表距离相机距离的图像。
2. 效果演示:3D重建的过程
我们可以通过以下三个阶段来想象重建的视觉效果:
- 稀疏重建阶段(Sparse Reconstruction):
屏幕上出现零散的特征点,看起来像是一群发光的萤火虫构成了物体的轮廓。此时可以看清相机的运动轨迹。 - 稠密重建阶段(Dense Reconstruction):
点云变得极其密集,物体的形状已经清晰可辨,像是由无数细小的沙粒堆砌而成的雕塑。 - 表面网格化与纹理贴图(Meshing & Texturing):
算法在点与点之间连线形成三角面片(Mesh),并把照片上的颜色“贴”上去。此时,物体在屏幕上看起来与真实照片无异,但你可以旋转、缩放它。
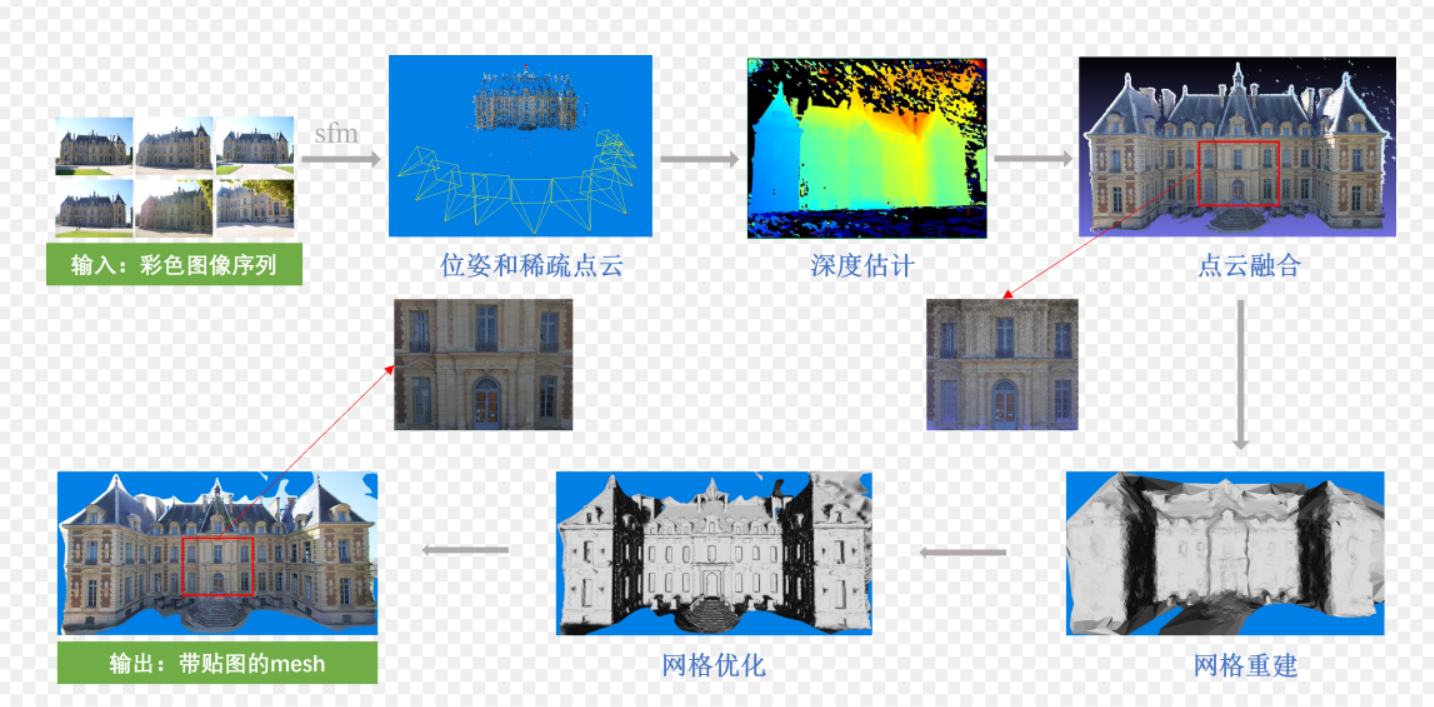
概念解读:
1. Mesh(网格 / 三角网格)
Mesh 是三维模型的 “几何骨架”,它由大量三角形(或多边形)面片拼接而成,只定义了物体的三维形状、轮廓和结构,就像建筑的钢筋框架,本身没有颜色和纹理。
2. 贴图(Texture Mapping)
贴图是一张包含颜色、纹理、细节信息的二维图像,比如墙面的砖石纹理、窗户的玻璃质感。它的作用是把这些表面细节 “贴” 到 Mesh 的几何框架上。
3. 目前的主流方法
3D重建的方法主要分为主动视觉和被动视觉两大类:
一、被动视觉(Passive Vision)—— 仅依赖环境光
这类方法不向物体发射能量,仅通过捕捉环境光成像。
A. 单目重建(Monocular Reconstruction):
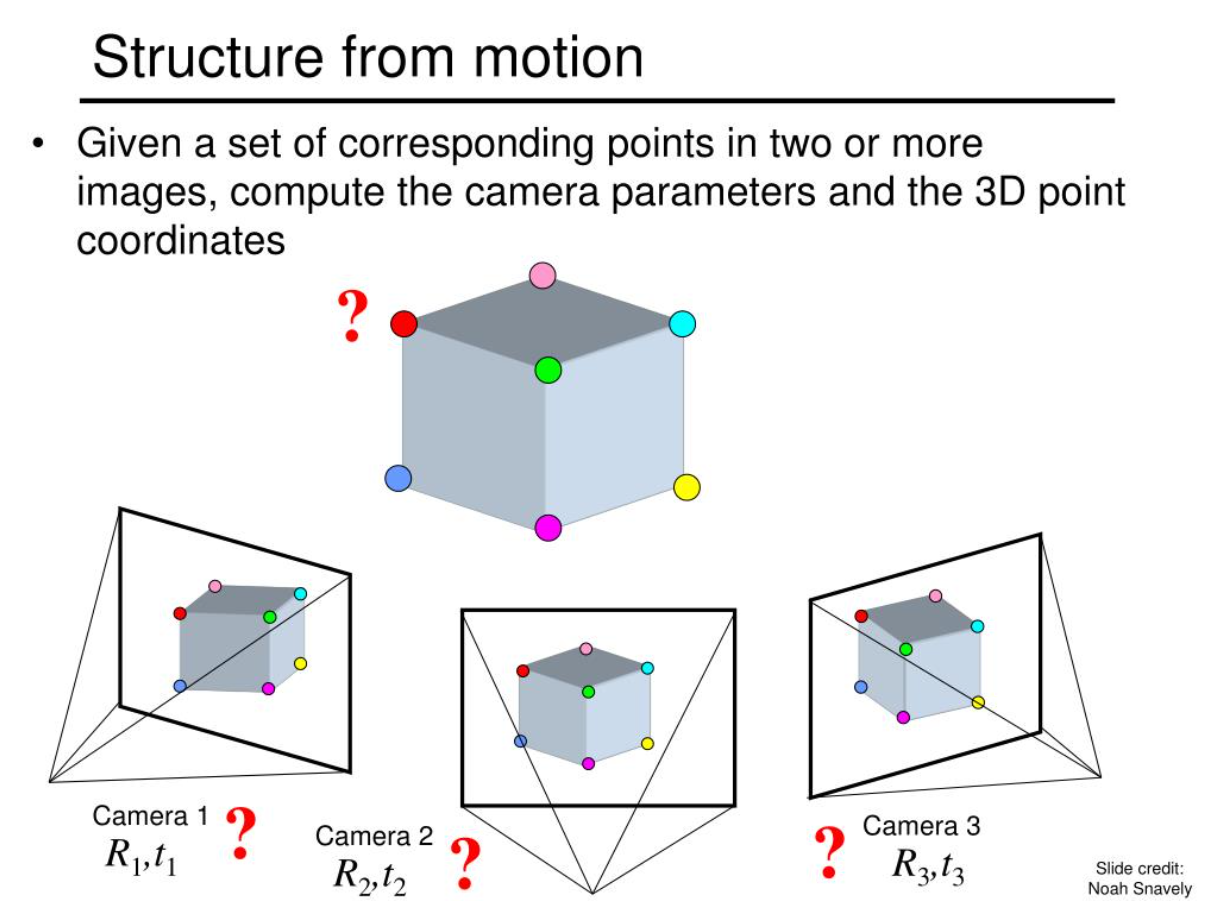
原理:利用运动恢复结构(SfM, Structure from Motion)。通过单台相机在不同位置拍摄的多张照片,计算相机位姿变化并重建场景。
难点: 存在尺度不确定性(不知道物体到底有多大)。
简单来说,SfM 就是通过移动的相机拍摄的一系列2D图像,来推算出物体的3D形状和相机的空间轨迹。
下面我将非常详细地为你拆解 SfM 的原理、步骤以及它背后的数学逻辑。
什么是 SfM(Structure from Motion)?
- Structure(结构): 指的是被拍摄物体的三维坐标(点云)。
- Motion(运动): 指的是相机在拍摄每一张照片时的位置(位姿,Pose)。
- From(通过…恢复): 强调了因果关系。
核心思想:
想象你围着一个雕像转圈拍照。虽然每张照片都是平面的(2D),但当你从左边移动到右边时,雕像上的特征点(比如鼻子尖)在照片里的位置会发生移动。SfM 算法就像你的大脑一样,通过分析这些点移动的幅度、方向和规律,反过来推算出:“哦,原来鼻子尖距离我这么远,而我刚才向右移动了 50 厘米。”
SfM 的全流程(极简步骤版)
一个标准的 SfM 系统通常包含以下五个核心步骤:
1. 特征提取与匹配 (Feature Extraction & Matching)
- 做什么: 算法会在每一张照片中寻找“地标”——那些无论光照怎么变、角度怎么变都能认出来的点(通常使用 SIFT 或 ORB 算法)。
- 目的: 确定第一张照片里的那个“点”和第二张照片里的哪个“点”是物理世界中的同一个位置。
- 结果: 得到一堆配对好的像素点坐标。
2. 计算几何关系 (Estimating Epipolar Geometry)
- 做什么: 利用对极几何(Epipolar Geometry)理论。通过匹配的点对,计算出两张照片之间的数学变换关系,即基础矩阵(Fundamental Matrix)或本质矩阵(Essential Matrix)。
- 原理: 即使不知道物体的形状,只要有足够的匹配点,我们就能算出相机从位置 A 到位置 B 到底旋转了多少度,平移了多少距离。
3. 三角测量 (Triangulation)
- 做什么: 有了相机的位姿,算法会从两个相机中心向同一个特征点发射两条射线。
- 原理: 这两条射线的交点,就是该特征点在三维空间中的真实坐标( X , Y , Z X, Y, Z X,Y,Z)。
- 结果: 生成了最初的稀疏点云。
4. 增量式重建 (Incremental Reconstruction)
- 做什么: 算法不会一次性处理几百张照片,而是先从两张开始,重建出一小部分,然后像拼图一样,不断加入第三张、第四张照片。
- 过程: 每加入一张新照片,就利用已有的 3D 点云来反推这张新照片的相机位置(这叫 PnP 算法),然后再把新看到的点加入点云。
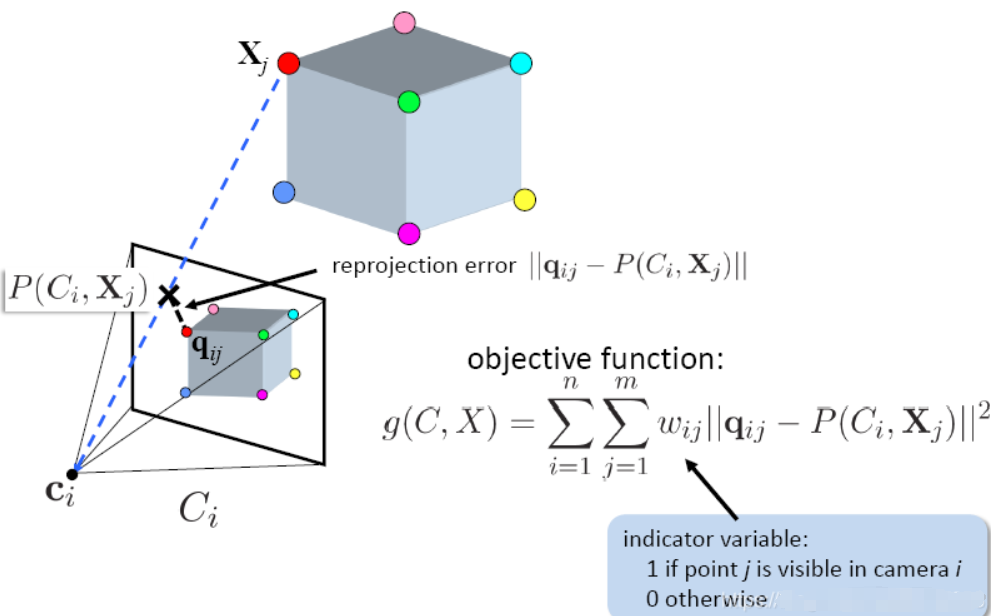
5. 全局优化:光束法平差 (Bundle Adjustment, BA)
- 这是 SfM 的灵魂: 随着照片越来越多,误差会累积,点云会“飘”掉或变形。
- 做什么: BA 是一项大型优化工程。它会同时调整所有相机的位姿和所有 3D 点的坐标,使得每一个 3D 点投影回照片上时,与照片里原始像素点的距离(重投影误差)最小。
为什么单目 SfM 无法感知“绝对尺度”?
这是单目重建最致命的弱点,也是面试或学术讨论中必问的问题。
原理:
在数学上,SfM 恢复出的空间结构具有尺度等比性。
- 如果你拍摄一张桌子上的水杯,重建出来的模型可能看起来很完美。
- 但是,算法无法分辨这是一个真实的高 10 厘米的水杯,还是一个高 10 米的巨型水杯模型。
原因:
在单目相机看来,一个很小的物体离相机很近,和一个巨大的物体离相机很远,在照片上的像素表现是一模一样的。除非你额外告诉算法一个参考值(比如:照片里那个硬币直径是 25mm,或者两个相机其实距离 10cm),否则它只能告诉你:“A 点到 B 点的距离是 C 点到 D 点距离的 2 倍”,而不能告诉你到底是多少米。
SfM 的两种主流流派
-
增量式 SfM (Incremental SfM):
- 代表作:COLMAP(目前学术界和工业界最常用的开源工具)。
- 优点:非常鲁棒,精度高。
- 缺点:慢,照片多了之后优化非常耗时。
-
全局式 SfM (Global SfM):
- 代表作:TheiaSfM。
- 优点:速度极快,适合大规模场景。
- 缺点:对异常匹配点非常敏感,容易崩溃。
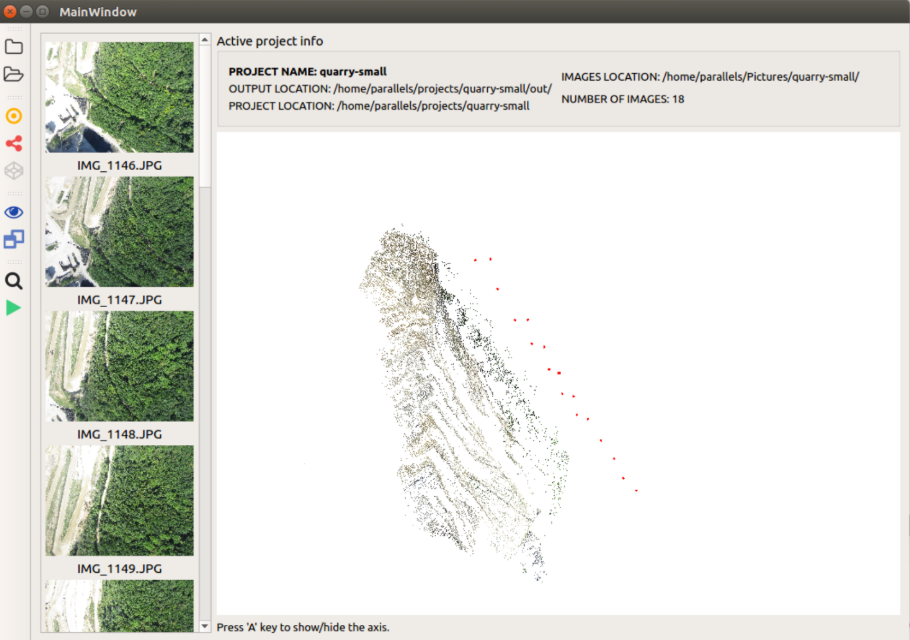
参考文件
若要深入研究 SfM 的底层数学,以下文献是必读的:
- Agarwal, S., et al. (2011). Building Rome in a Day. Communications of the ACM.
(这是 SfM 历史上的里程碑,证明了利用互联网上的成千上万张照片重建一座城市是可能的)。 - Schönberger, J. L., & Frahm, J. M. (2016). Structure-from-Motion Revisited. CVPR.
(这是 COLMAP 的核心论文,目前被公认为增量式 SfM 的最优实践)。 - Triggs, B., et al. (1999). Bundle Adjustment – A Modern Synthesis. Vision Algorithms: Theory and Practice.
(深入讲解了 SfM 中最关键的优化算法 BA)。 - Snavely, N., Seitz, S. M., & Szeliski, R. (2006). Photo Tourism: Exploring image collections in 3D. SIGGRAPH.
(首次向大众展示了如何通过非结构化照片集进行 3D 导航)。 - Longuet-Higgins, H. C. (1981). A computer algorithm for reconstructing a scene from two projections. Nature.
(提出了著名的八点算法,是 SfM 几何计算的基石)。
B. 双目/多目立体视觉(Stereo Vision):
原理: 模拟人类双眼。通过计算左右两个相机拍摄图像的视差(Disparity),利用三角测量原理计算深度。
如果说 SfM(运动恢复结构)是模仿人类“边走边看”来认知空间,那么双目立体视觉(Stereo Vision)则是直接模仿人类的双眼结构。
它是机器视觉中最经典、应用最广泛的深度感知技术之一。下面我们深度拆解双目立体视觉的原理、数学逻辑以及实现过程。
1. 核心定义
双目立体视觉是指使用两台成像特性相同(焦距、像素尺寸等一致)的相机,安装在同一平面上,保持一定的水平距离(基线,Baseline),通过计算左右图像中同一物体像素点的相对位姿差异,来获取物体三维信息的方法。
直观理解:
伸出你的一根手指放在眼前,先闭上左眼看,再闭上右眼看。你会发现手指相对于背景的位置发生了“跳动”。
- 手指离眼睛越近,跳动幅度(位姿差异)越大。
- 手指离眼睛越远,跳动幅度越小。
- 这种跳动的位移量,在计算机视觉中被称为视差(Disparity)。
2. 核心数学原理:三角测量(Triangulation)
双目视觉的精髓可以用一个极其简单的几何公式来概括。
假设两台相机完全平行,焦距为 f f f,两相机中心距离(基线)为 B B B。空间中一点 P P P 在左相机成像面上的横坐标是 x L x_L xL,在右相机成像面上的横坐标是 x R x_R xR。
-
视差(Disparity)定义: d
x L − x R d = x_L - x_R d=xL−xR
-
深度(Depth)计算公式:
Z
f ⋅ B d Z = \frac{f \cdot B}{d} Z=df⋅B
这个公式告诉我们两个关键信息:
- 反比关系: 深度 Z Z Z 与视差 d d d 成反比。视差越大,物体越近。
- 尺度确定性: 与单目 SfM 不同,由于基线 B B B 是提前测量好的物理常数(比如两相机间距 6 厘米),所以双目视觉可以直接计算出物体的真实物理距离(米或毫米),不存在尺度不确定性。
3. 标准算法流程(Stereo Pipeline)
实现高质量的双目重建通常需要经过以下四个严谨的步骤:
第一步:相机标定(Camera Calibration)
- 目的: 确定相机的内参(焦距、中心点)和外参(两相机之间的精确旋转和平移关系)。
- 意义: 如果相机镜头有畸变(比如鱼眼效果),或者两个相机没装正,后续计算全是错的。
第二步:立体校正(Stereo Rectification)—— 极关键
- 做什么: 通过数学变换,把拍摄时的两张照片对齐,使得左右图像的极线(Epipolar Line)处于同一水平线上。
- 意义: 校正后,左图中的一个点,在右图中一定能在同一行找到。这把一个 2D 的搜索问题降维成了 1D 搜索,极大地提高了运算速度。
第三步:立体匹配(Stereo Matching)—— 最核心、最难
- 做什么: 算法要在右图的同一行像素里,找到那个和左图点“长得最像”的点。
- 主流算法:
- BM (Block Matching): 快,但精度低,边缘粗糙。
- SGM (Semi-Global Matching): 工业界的主流,在速度和精度间取得了极佳平衡。
- 深度学习方法: 如 PSMNet,利用神经网络直接输出视差图,在处理无纹理区域表现更好。
第四步:视差转深度(Disparity to Depth)
-
做什么: 利用前面提到的公式 Z
( f ⋅ B ) / d Z = (f \cdot B) / d Z=(f⋅B)/d,将像素级的视差图转化为物理世界的深度图。
4. 双目视觉 vs. 单目 SfM 的区别
| 特性 | 双目立体视觉 (Stereo) | 单目 SfM |
|---|---|---|
| 相机数量 | 2台或多台 | 1台 |
| 拍摄状态 | 可以静态拍摄(瞬间成像) | 必须移动相机(动态拍摄) |
| 尺度感知 | 自动获得真实物理尺度 | 无法获得真实尺度(仅有比例) |
| 实时性 | 高(适合避障、机器人) | 低(计算量大,需运动序列) |
| 适用范围 | 适合近距离、高精度感知 | 适合大场景、远距离建模 |
5. 适用场景与局限性
适用场景:
- 车载辅助驾驶(ADAS): 识别前方障碍物距离。
- 工业抓取: 机械臂识别零件的 3D 位置。
- 无人机避障: 实时感知周围墙体距离。
局限性:
- 环境纹理依赖: 如果墙面是纯白色的,算法无法在右图中找到匹配的点(因为看起来都一样),会导致深度丢失。
- 基线限制: 测量距离受限于基线 B B B。如果要测 100 米外的物体,基线必须足够宽,否则视差 d d d 太小,会导致误差剧增。
- 遮挡问题: 左眼看得到的地方,右眼可能被挡住了(暗影区),导致无法计算。
6. 参考资料与经典文献
- Scharstein, D., & Szeliski, R. (2002). A taxonomy and evaluation of dense two-frame stereo correspondence algorithms. International Journal of Computer Vision.
(立体匹配领域的基石论文,定义了评估标准)。 - Hirschmuller, H. (2005). Accurate and efficient stereo processing by semi-global matching and mutual information. CVPR.
(提出了著名的 SGM 算法,至今仍是该领域的工业标准)。 - Marr, D., & Poggio, T. (1979). A computational theory of human stereo vision. Proceedings of the Royal Society of London.
(从生物学和计算视觉角度解释了人类双眼如何感知深度)。 - Konolige, K. (1998). Small Vision Systems: Hardware and Implementation. International Symposium on Robotics Research.
(讲解了实时双目视觉系统的早期硬件实现)。 - Zhang, Z. (2000). A flexible new technique for camera calibration. IEEE Transactions on Pattern Analysis and Machine Intelligence.
(著名的“张氏标定法”,双目相机标定的必备基础)。
C. 神经辐射场(NeRF, Neural Radiance Fields)
* **前沿:** 2020年后的爆发性技术。利用深度学习将场景表示为一个连续的体积场,通过体渲染技术生成极其逼真的3D视图。
如果说 SfM 是在做“几何题”,双目视觉是在做“物理题”,那么 NeRF(Neural Radiance Fields,神经辐射场) 就是在用“人工智能算法”进行一次革命性的艺术创作。
NeRF 是 2020 年计算机视觉领域最具颠覆性的技术之一。它彻底改变了我们存储和表现 3D 世界的方式。
1. 什么是 NeRF?
定义:
NeRF 是一种利用深度神经网络(通常是多层感知机 MLP)来隐式地表示 3D 场景的技术。它不存储点云,也不存储三角面片,而是将整个 3D 场景编码进一个神经网络的权重里。
核心直觉:
想象空间中充满了“带颜色的烟雾”。在每一个坐标点上,烟雾都有特定的颜色和浓度。NeRF 的目标是训练一个 AI 助手,当你问它:“在坐标
(
x
,
y
,
z
)
(x, y, z)
(x,y,z) 这个点,从
(
θ
,
ϕ
)
(\theta, \phi)
(θ,ϕ) 这个角度看过去是什么颜色?”它能立刻计算出结果。
2. NeRF 的核心原理:5D 函数
NeRF 将场景表示为一个连续的 5D 函数:
- 输入 (5个参数): 空间位置 ( x , y , z ) (x, y, z) (x,y,z) + 观察视角 ( θ , ϕ ) (\theta, \phi) (θ,ϕ)。
- 输出 (4个参数): 该点的颜色
R
G
B
RGB
RGB + 该点的体积密度
σ
\sigma
σ(即光线通过这里的阻力,代表物体是否存在)。
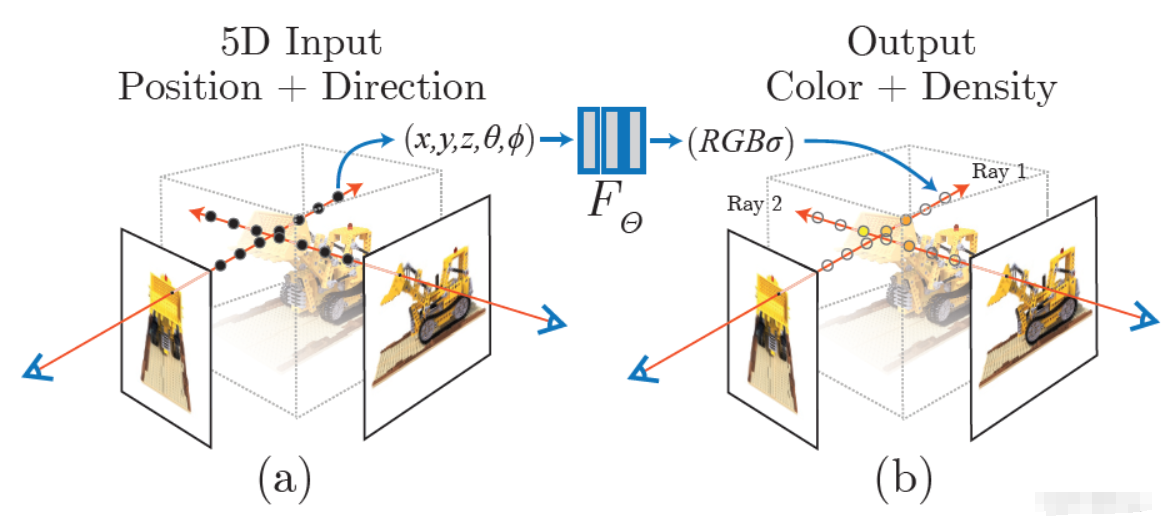
- 隐式表示(Implicit Representation):
传统的 3D 模型像“乐高积木”(体素)或“折纸”(网格)。NeRF 像“一段代码”,你给它坐标,它吐出颜色。这使得它能表现极其精细的细节,而不需要海量的存储空间。 - 位置编码(Positional Encoding):
这是 NeRF 能火的关键。神经网络天生倾向于学习“平滑”的东西,容易把图像变模糊。NeRF 通过把坐标转换成高频正弦/余弦波,强制网络记住细节(如物体的边缘、细小的纹理)。 - 可微体渲染(Differentiable Volume Rendering):
这是 NeRF 的“渲染引擎”。它沿着相机射出的一条光线进行采样,把路径上所有点的颜色和密度加权累加,最终得到一个像素的颜色。因为整个过程是数学可导的,所以可以通过对比生成的图像和真实照片的差异,利用反向传播来训练网络。
3. NeRF 的工作流程
- 准备数据: 拍摄几十张到上百张物体的照片,并利用 SfM (如 COLMAP) 算出每张照片拍摄时的精确相机位置。
- 光线投射: 对于图像上的每个像素,从相机中心射出一条穿过该像素的光线。
- 采样与查询: 在这条光线上采样成百上千个点,把这些点的坐标丢进神经网络里。
- 合成颜色: 神经网络输出这些点的颜色和密度,通过体渲染公式把它们“捏合”成一个像素颜色。
- 优化权重: 比较 AI 生成的像素和照片里的真实像素。如果不一样,就调整神经网络的参数。重复成千上万次,直到网络能完美预测出任何角度的画面。
4. 为什么 NeRF 效果这么震撼?
- 照片级的真实感: 它能完美处理光泽表面(如金属的反光)、透明物体(如玻璃杯)以及极其复杂的几何结构(如头发、树叶),这些都是传统点云或 Mesh 的噩梦。
- 无限的分辨率: 因为是连续函数,理论上你可以无限放大场景。
- 视角插值: 你只拍了 20 张照片,但 NeRF 可以生成相机从未经过的位置的平滑视频,效果就像在好莱坞电影里穿梭一样。
5. 局限性与目前的瓶颈
尽管效果惊艳,但原生 NeRF 存在以下问题:
- 训练极慢: 2020 年刚出来时,训练一个场景需要几小时甚至几天。
- 渲染(推理)极慢: 生成一张图需要几秒钟,无法做到实时互动。
- 场景是死板的: 原生 NeRF 只能重建静态场景,如果画面里有东西在动,或者光线变了,模型就会崩溃。
- 需要相机位姿: 它极其依赖 SfM 提供的精确坐标,如果照片位姿算错了,NeRF 出来的结果会是一团浆糊。
6. 进化之路(NeRF 的子孙们)
为了解决上述问题,诞生了一系列变体:
- Instant-NGP (NVIDIA): 将训练时间从小时级缩短到了秒级。
- Mip-NeRF: 解决了物体在远近切换时的锯齿问题。
- D-NeRF / NSVF: 尝试处理会动的物体(动态场景)。
- 3D Gaussian Splatting (2023): 虽然不完全是 NeRF,但它吸取了 NeRF 的思想,实现了真正实时的高质量渲染,是目前最火的替代方案。
7. 参考文献
- Mildenhall, B., Srinivasan, P. P., Tancik, M., Barron, J. T., Ramamoorthi, R., & Ng, R. (2020). NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis.
ECCV. (NeRF 的开山之作)。 - Müller, T., Evans, A., Schied, C., & Keller, A. (2022). Instant Neural Graphics Primitives with a Multiresolution Hash Encoding. ACM Transactions on Graphics.
(NVIDIA 提出的 Instant-NGP,让 NeRF 走向实用化)。 - Barron, J. T., et al. (2021). Mip-NeRF: A Multiscale Representation for Anti-Aliasing Neural Radiance Fields. ICCV.
(解决了抗锯齿和多尺度问题)。 - Tancik, M., et al. (2022). Block-NeRF: Scalable Large Scene Neural View Synthesis. CVPR.
(证明了 NeRF 可以用来重建整个城市街道)。 - Martin-Brualla, R., et al. (2021). NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections. CVPR.
(解决了利用互联网乱七八糟的照片进行重建的问题)。
D. 3D Gaussian Splatting (3DGS):
最新: 2023年出现的技术,通过大量3D高斯椭球体拟合场景,实现了比NeRF更快的渲染速度和极高的重建质量。
如果说 NeRF 是 3D 重建领域的“数字幻觉”,那么 3D Gaussian Splatting (3DGS) 就是在 2023 年横空出世的“数字画笔”。
3DGS 的出现直接解决了 NeRF 渲染慢、训练久的核心痛点,将 3D 重建推向了实时、高画质、可交互的新纪元。
1. 什么是 3D Gaussian Splatting (3DGS)?
定义:
3DGS 是一种基于显式辐射场(Explicit Radiance Field)的场景表示技术。它不使用神经网络来“猜”颜色,而是直接在空间中抛洒数百万个带有颜色、形状和透明度的3D 高斯椭球体(Gaussian Kernels),通过这些椭球体的叠加来拼凑出整个世界。
形象比喻:
- NeRF 像是一个记忆力超强的画师:你问他画里某个坐标是什么颜色,他想一下告诉你。
- 3DGS 像是一个贴纸大师:他直接在透明的空间里贴了数百万张半透明的彩色贴纸(椭球体),你从任何角度看过去,这些贴纸叠加在一起就是一张完美的照片。
2. 核心原理:3D 高斯椭球体的“基因”
每一个 3D 高斯椭球体都包含了一组极其精简的数学参数(基因):
- 中心位置 (Position, X , Y , Z X, Y, Z X,Y,Z): 椭球体在哪。
- 协方差矩阵 (Covariance,
Σ
\Sigma
Σ): 决定椭球体的形状和方向。为了方便计算,它被分解为:
- 缩放 (Scaling): 它是长的、圆的还是扁的。
- 旋转 (Rotation): 它是横着的还是斜着的。
- 不透明度 (Opacity, α \alpha α): 这个椭球体有多透明。
- 球谐函数颜色 (Spherical Harmonics, SH): 这是一种特殊的颜色表示法。它不只是一个单一颜色,而是记录了从不同方向看这个点时颜色的变化(比如金属的高光)。
3. 工作流程:从点云到精美建模
第一步:初始化 (Initialization)
3DGS 通常以 SfM (如 COLMAP) 产生的稀疏点云作为起点。每个点被初始化为一个小的 3D 高斯球。
第二步:可微投影与渲染 (Splatting & Rasterization)
这是 3DGS 速度极快的秘诀。
- 算法将 3D 的椭球体平扁化(投影)到 2D 屏幕上,变成一个个 2D 椭圆。
- 采用基于分块(Tile-based)的快速光栅化渲染器。它将屏幕分成许多小格子(Tiles),只渲染对这个格子有贡献的椭球体。这与现代显卡(GPU)的处理逻辑完全匹配。
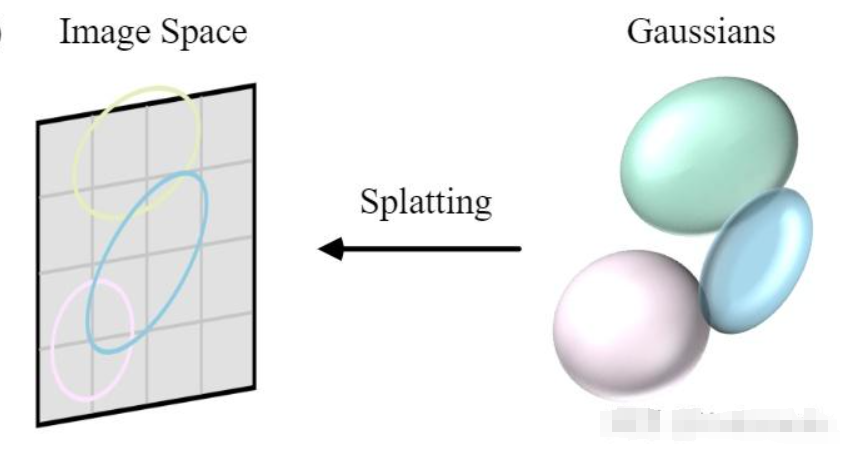
第三步:自适应密度控制 (Adaptive Density Control)
这是 3DGS 的“进化”过程。在优化过程中,算法会观察:
- 克隆 (Clone): 如果某个地方太平滑,点不够用,就在那复制一个点。
- 分裂 (Split): 如果某个椭球体太大、太模糊,就把它拆成两个小的。
- 修剪 (Culling): 如果某个椭球体不透明度极低,基本看不见,就把它删掉。
为什么 3DGS 能在 2023 年引爆技术圈?
- 渲染速度起飞: NeRF 渲染一张图需要几秒钟,而 3DGS 可以在普通的 GPU 上实现 100+ FPS(每秒帧数)的实时渲染。
- 训练时间极短: 一个中等复杂的场景,NeRF 可能要训练几小时,3DGS 只需要 5-10 分钟。
- 显式存储: 因为它是数百万个点,你可以直接在 3D 软件里看到这些点,甚至可以手动删除、移动或缩放其中的一部分,这在 NeRF 的神经网络权重里是几乎做不到的。
- 视觉效果惊艳: 3DGS 捕捉精细细节(如树叶、毛发、薄雾)的能力极强,画面边缘比 NeRF 更加锐利。
5. 目前的瓶颈与挑战
- 显存压力大 (VRAM Intensive): 渲染虽然快,但要在显存里存储数百万个高斯参数,非常吃显存(通常需要 8GB 以上的显存才能流畅运行大型场景)。
- 存储空间巨大: 一个高质量场景的模型文件可能高达 数百 MB 甚至几个 GB,而 NeRF 只需要几 MB 的神经网络权重。
- 依赖初始化: 如果 SfM 出来的初始点云太差(比如在光滑平面上没取到点),3DGS 很难凭空生成高质量的椭球体,会出现明显的“破洞”。
- 伪影 (Artifacts): 在视角变化剧烈时,有时会看到椭球体像“彩色雪花”一样漂浮。
6. 参考文献
- Kerbl, B., Kopanas, G., Leimkühler, T., & Drettakis, G. (2023). 3D Gaussian Splatting for Real-Time Radiance Field Rendering. ACM Transactions on Graphics (SIGGRAPH).
(3DGS 的开山鼻祖,目前该领域引用量最高的论文)。 - Zwicker, M., Pfister, H., van Baar, J., & Gross, M. (2001). Surface Splatting. SIGGRAPH.
(3DGS 核心思想“Splatting”的早期理论来源)。 - Luan, F., et al. (2024). GPS-Gaussian: Generalizable Pixel-wise 3D Gaussian Splatting for Real-time Human Novel View Synthesis.
(将 3DGS 应用于人体动态建模的前沿工作)。 - Niedermayr, S., et al. (2023). Compressed 3D Gaussian Splatting for Highly Accessible Novel View Synthesis.
(针对 3DGS 存储体积过大问题的早期优化研究)。 - Chen, Z., et al. (2023). MCMC-GS: Multi-Scale 3D Gaussian Splatting for Large-Scale Scene Reconstruction.
(针对大规模城市场景的 3DGS 改进算法)。
二. 主动视觉(Active Vision)—— 自带光源
这类方法通过向物体发射特定光线来辅助测量。
- 结构光(Structured Light):
- 原理: 投影仪向物体投射特定的光栅图案,相机拍摄被物体表面畸变后的图案,通过数学计算得出深度。
- 代表: iPhone的前置FaceID。
如果说 SfM 和双目视觉是利用“自然的眼睛”去观察世界,那么**结构光(Structured Light)**则是给机器装上了一台“主动测量尺”。
它是目前高精度 3D 扫描、人脸识别(如 iPhone FaceID)和工业精密检测领域最核心的技术。
A. 结构光技术
####定义:
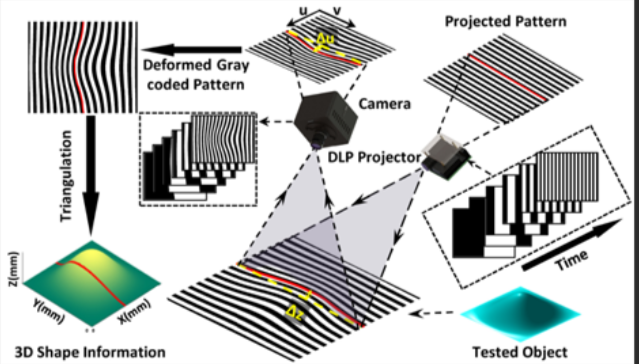
结构光是一种主动视觉测量技术。它通过投影仪向物体表面投射特定的已知图案(如格点、条纹、编码图),再由相机捕捉这些图案在物体表面发生的几何畸变,通过三角测量原理计算出物体的三维空间坐标。
形象比喻:
想象你在黑暗中面对一面凹凸不平的墙。你打开一支手电筒,手电筒的光罩上画着整齐的方格。
- 如果墙是平的,你在墙上看到的方格也是整齐的。
- 如果墙上有个坑或者凸起,方格线就会变得弯曲。
- 通过观察方格线“弯了多少”,你就能推算出墙面的起伏。这就是结构光。
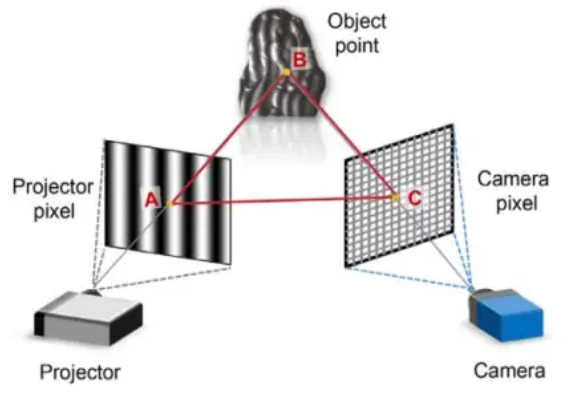
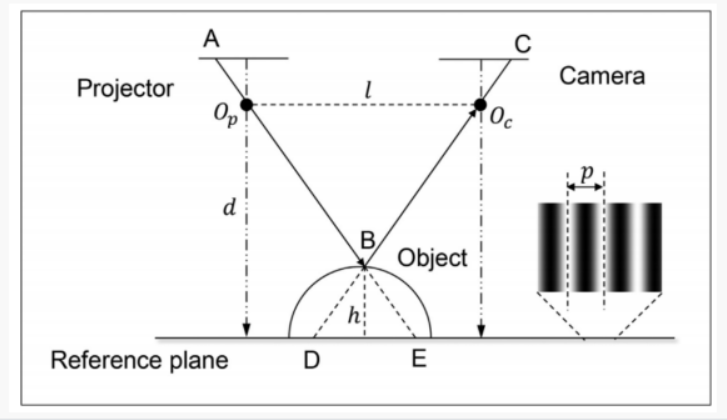
2. 核心数学原理:变形的三角测量
结构光本质上是双目视觉的变种。
- 在双目视觉中,我们需要两个相机从不同角度看同一个点。
- 在结构光中,我们用一个投影仪替代了其中一个相机。
数学逻辑:
- 已知条件: 投影仪投射出的光束角度是已知的,相机与投影仪之间的距离(基线 B B B)是固定的。
- 寻找匹配: 投影仪投出的每一个光点(或线条)都有一个唯一的“编码”。相机拍到这个点后,立刻就能知道它是从投影仪的哪个角度射出来的。
- 几何求解: 投影仪发出的射线与相机接收到的射线在空间中相交。根据正弦定理或简单的三角函数,即可解算出该交点的三维坐标 ( X , Y , Z ) (X, Y, Z) (X,Y,Z)。
3. 编码方式:结构光的“语言”
结构光最核心的竞争力在于如何设计投射的“图案”。目前主流有三种:
A. 空间编码 (Spatial Coding) —— 代表:iPhone FaceID
- 做法: 一次性投射一个复杂的散斑图案(类似满天星)。
- 特点: 只需拍摄一张图片即可完成重建,速度极快,适合动态物体(如人脸)。
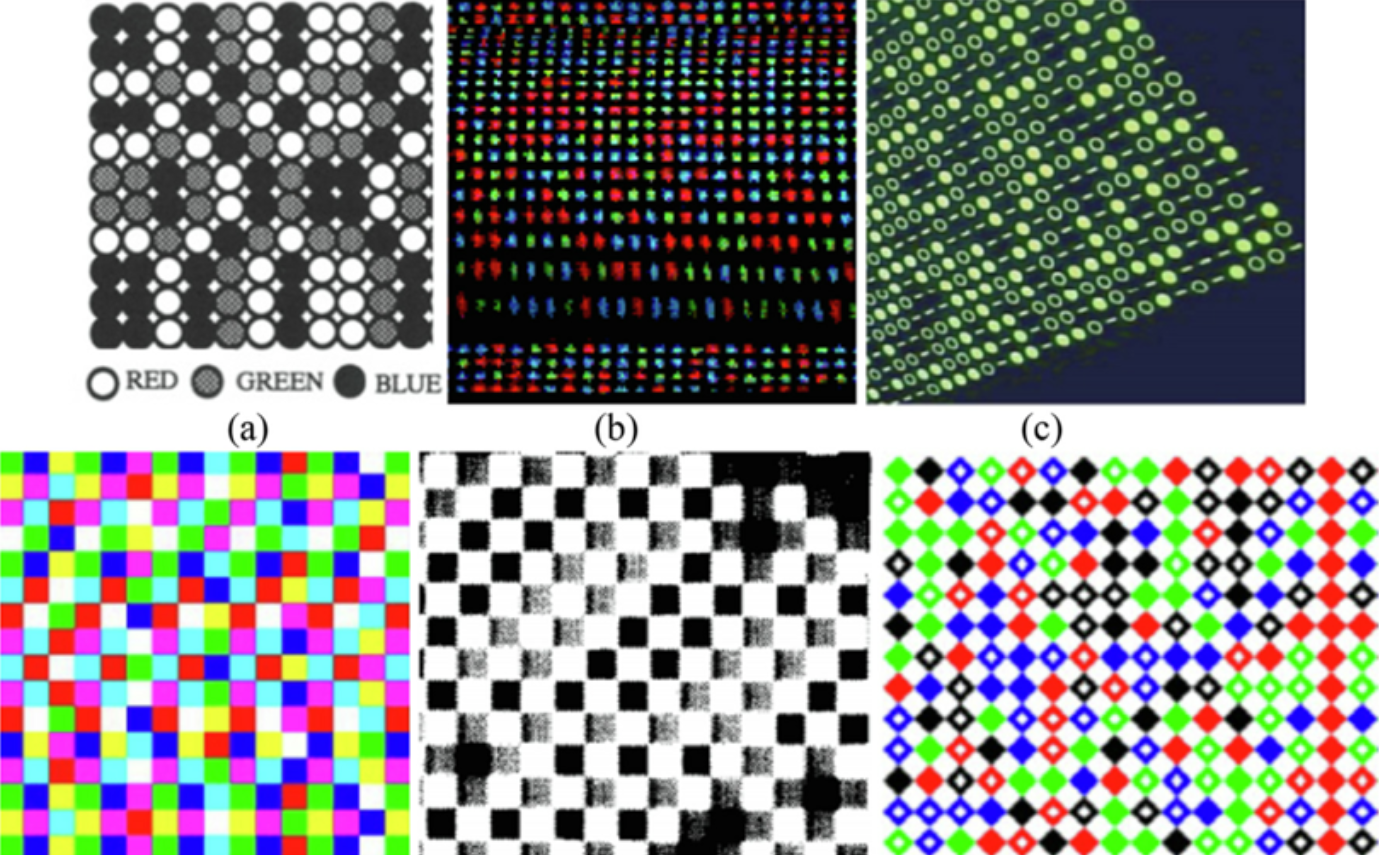
B. 时间编码 (Temporal Coding) —— 代表:工业 3D 扫描仪
- 做法: 连续投射多张不同频率的黑白条纹(如格雷码 + 正弦条纹)。
- 特点: 精度极高(可达微米级),但物体必须保持静止,因为需要拍摄多张照片。
C. 相移法 (Phase Shifting)
- 做法: 投射周期性的正弦光栅,通过分析光波相位的偏移来提取高度信息。
4. 深度解析:iPhone FaceID 是如何工作的?
FaceID 是结构光技术小型化、消费级应用的巅峰。它包含三个核心组件:
- 点阵投影器 (Dot Projector): 向你的脸部投射超过 30,000 个肉眼不可见的红外散斑点。
- 红外摄像头 (Infrared Camera): 读取这些散斑在脸部起伏下形成的畸变图像。
- 泛光感应元件 (Flood Illuminator): 确保在全黑环境下也能照亮脸部,供红外相机识别。
为什么它安全?
因为它不是在对比“照片”,而是在对比你脸部的三维地形图。照片是平面的,无法产生结构光的畸变效果,因此无法欺骗 FaceID。
5. 结构光的优缺点
优点:
- 无需环境纹理: 即使是纯白色的墙,结构光也能重建(因为它自己投射了纹理),这弥补了双目视觉的短板。
- 精度极高: 在近距离(1米以内),结构光的精度可以轻松达到毫米甚至微米级。
- 主动补光: 在全黑的环境下依然能工作。
缺点:
- 怕强光: 在室外强光(如阳光)下,投影仪的光会被阳光淹没,导致失效。
- 距离限制: 投影仪功率有限,通常只适用于近距离(如手机解锁、桌面扫描)。
- 材质敏感: 面对镜面反光物体或全黑吸光物体,投射的光会消失或乱射,导致无法成像。
6. 参考文献
- Geng, J. (2011). Structured-light 3D surface imaging: a tutorial. Advances in Optics and Photonics.
(最经典的结构光综述性教程)。 - Scharstein, D., & Szeliski, R. (2003). High-accuracy stereo depth maps using structured light. CVPR.
(探讨了如何利用结构光获取极高精度的深度图)。 - Salvi, J., et al. (2004). Pattern codification strategies in structured light systems. Pattern Recognition.
(详细对比了各种编码图案的优劣)。 - Apple Inc. About Face ID advanced technology. Support Documentation.
(虽然不是学术论文,但揭示了消费级结构光系统的硬件架构)。 - Zuo, C., et al. (2016). Micro-structured-light 3D surface profiling: A review. Measurement.
(聚焦于微观领域高精度结构光测量的综述)。
飞行时间法(ToF, Time of Flight)
原理: 发射红外脉冲,测量光线反射回来的时间。
代表: 激光雷达(LiDAR)、Kinect 2.0。
如果说结构光是利用“几何畸变”来测量,那么**飞行时间法(ToF, Time of Flight)**就是利用“绝对速度”来测量。
ToF 是目前 3D 感知领域中速度最快、延迟最低的技术。它广泛应用于自动驾驶的激光雷达(LiDAR)、手机后置深度摄像头(如 iPhone 的 LiDAR 扫描仪)以及早期的体感游戏设备。
1. 什么是 ToF (飞行时间法)?
定义:
ToF 是一种通过测量光波在传感器与目标物体之间“飞行”的时间,来计算目标距离的技术。因为光的传播速度
c
c
c 是已知的常数,只要知道了时间
t
t
t,距离
d
d
d 也就迎刃而解。
形象比喻:
想象你对着一口深井大喊一声,然后开始计时。当你听到回声时,停止计时。
- 声纳/雷达: 利用声波或无线电波的反射。
- ToF: 利用光波(通常是 850nm-940nm 的近红外光)。由于光速极快(每秒 30 万公里),ToF 芯片需要具备“皮秒级”(万亿分之一秒)的计时精度。
2. 核心数学原理:极速公式
ToF 的基本原理非常直观,但实现方法分为两种主要流派:dToF 和 iToF。
A. dToF (Direct ToF,直接测量) —— 代表:激光雷达 (LiDAR)
这是最硬核的方式。传感器直接发射一个极短的光脉冲,并启动一个超高精度的“秒表”,记录光子飞出去并跳回来的确切时间
Δ
t
\Delta t
Δt。
-
公式: d
c ⋅ Δ t 2 d = \frac{c \cdot \Delta t}{2} d=2c⋅Δt - 难点: 光速太快,光走 1 厘米只需要约 33 皮秒。这就要求传感器(通常是 SPAD,单光子雪崩二极管)具有极其恐怖的响应速度。
B. iToF (Indirect ToF,间接测量) —— 代表:Kinect 2.0
由于精确计时太难且贵,iToF 采用了“曲线救国”的方法:它发射的是连续的正弦调制光波,通过测量发射波与反射波之间的**相位差(Phase Shift)**来推算时间。
- 逻辑: 相位偏移了多少度,就代表时间过去了多久。
- 优点: 硬件成本较低,像素分辨率可以做得很高(类似手机摄像头)。
3. ToF 的工作流程
- 发射单元 (Emitter): 发出经过调制的红外激光或脉冲。
- 反射 (Reflection): 光线触碰物体表面后发生弥散反射。
- 接收单元 (Sensor): 一个特殊的 CMOS 图像传感器捕捉返回的光信号。
- 处理单元 (Processor):
- 对于 dToF:统计光子到达的直方图,确定峰值时间。
- 对于 iToF:计算每个像素点的电荷差异,转换成相位,再换算成深度值。
- 输出: 生成一张深度图(Depth Map),每个像素代表该点的物理距离。
4. ToF vs. 结构光:有什么区别?
| 特性 | ToF (飞行时间法) | 结构光 (Structured Light) |
|---|---|---|
| 计算量 | 极低(硬件直接输出结果) | 高(需要复杂的图像对比分析) |
| 工作距离 | 远(激光雷达可达数百米) | 短(通常 1 米以内) |
| 抗干扰性 | 较强(尤其 dToF 适合室外) | 较弱(强光下图案会被淹没) |
| 分辨率 | 较低(通常是 QVGA 级) | 较高(可以达到百万像素) |
| 应用场景 | 扫地机器人、自动驾驶、AR 建模 | 手机面部解锁、精密扫描、活体检测 |
5. 目前的瓶颈与挑战
- 多径干扰 (Multi-path Interference):
如果光线在墙角经过多次反射才回到传感器,ToF 会误以为物体比实际更远,产生“深度重影”。 - 飞点效应 (Flying Pixels):
在物体的边缘,一个像素可能同时接收到物体表面和背景墙的反射信号,导致边缘出现一圈莫须有的“飞点”。 - 环境光干扰:
虽然 iToF 在室内表现优异,但在太阳光下,红外光噪声巨大,会导致精度大幅下降(dToF 通过单光子技术缓解了这一问题)。 - 功耗问题:
因为要不断地主动发射光,ToF 传感器通常比普通摄像头更耗电。
6. 参考文献
- Hansard, M., Lee, S., Choi, O., & Horaud, R. P. (2012). Time-of-Flight Cameras: Principles, Methods and Applications. Springer Briefs in Computer Science.
(最系统讲解 ToF 原理的经典书籍)。 - Li, L. (2014). Time-of-flight camera – An introduction. Technical report, Texas Instruments.
(TI 发布的官方技术报告,深入讲解了 iToF 的电子学实现)。 - Horaud, R., et al. (2016). An overview of gradient-based 3D reconstruction methods for Time-of-Flight RGB-D cameras. Journal of Mathematical Imaging and Vision.
(探讨了如何优化 ToF 的深度图质量)。 - Bamji, C. S., et al. (2015). A 0.13μm CMOS System-on-Chip for a 512×424 Time-of-Flight Image Sensor with Multi-Frequency Photo-Demodulation. ISSCC.
(Kinect 2.0 背后芯片的技术细节论文)。 - Niclass, C., et al. (2005). A CMOS single photon avalanche diode array for 3D imaging. IEEE International Solid-State Circuits Conference.
(dToF 核心组件 SPAD 传感器的奠基性研究)。
4. 适用场景
3D重建技术已经深入到各行各业:
- 工业自动化: 高精度零件的尺寸检测、缺陷扫描、机器人抓取引导。
- 自动驾驶与机器人: 避障、环境建模(SLAM)、高精地图制作。
- 文化遗产保护: 对古建筑物、文物进行数字化建模,实现永恒保存。
- 医疗成像: 牙科扫描建模、手术前3D模拟。
- 数字孪生与元宇宙: 将现实世界的物体快速建模并导入游戏或虚拟空间。
- 电子商务: 手机扫描商品实现3D预览(如宜家家具试摆)。
5. 目前的瓶颈与问题
尽管技术发展迅速,但3D重建仍面临以下严峻挑战:
- 弱纹理与重复纹理:
面对洁白的墙壁、纯色桌面或玻璃表面,算法很难找到可靠的特征匹配点,导致重建失败或出现“破洞”。 - 反光与透明物体:
金属表面的高光和玻璃的折射会误导相机,使算法计算出错误的深度。 - 计算复杂度与实时性:
高精度的稠密重建需要巨大的算力,在移动设备或嵌入式平台上难以实现超高精度的实时重建。 - 遮挡问题:
当物体的一部分被挡住时,算法需要通过先验知识(AI猜想)来补全,这往往会导致精度下降。 - 光照敏感性:
过强或过暗的光线都会严重影响被动视觉方法的特征提取质量。
总结
通过机器视觉实现3D重建是计算机视觉领域的“圣杯”之一。从经典的三角几何到现代的深度学习(NeRF/3DGS),我们正处于从“拍出好看的照片”向“构建完美的数字世界”跨越的时代。随着算力的提升和算法的优化,未来的3D重建将变得像拍照一样简单且精准。
参考文献
为了保证信息的真实性与学术严谨性,以下是本博客参考的核心文献与经典教材:
- Hartley, R., & Zisserman, A. (2004). Multiple View Geometry in Computer Vision. Cambridge University Press.
(计算机视觉领域的圣经,详细讲解了多视图几何和相机模型)。 - Mildenhall, B., et al. (2020). NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. ECCV.
(神经辐射场奠基之作)。 - Kerbl, B., et al. (2023). 3D Gaussian Splatting for Real-Time Radiance Field Rendering. ACM Transactions on Graphics.
(当前最前沿的实时3D重建算法)。 - Schonberger, J. L., & Frahm, J. M. (2016). Structure-from-Motion Revisited. CVPR.
(COLMAP算法的理论基础)。 - Newcombe, R. A., et al. (2011). KinectFusion: Real-time 3D reconstruction and interaction using a moving depth camera. ISMAR.
(结构光与ToF实时重建的经典文献)。
作者提示: 如果你对具体的某个算法(如如何配置COLMAP或如何训练NeRF)感兴趣,欢迎在评论区留言,我将在下一期详细讲解!
概念解析:機器視覺如何賦予機器“三維雙眼”——3D重建技術全景指南
在人工智慧的浪潮中,如果說傳統的2D影象識別是讓機器“認出”物體,那麼3D重建(3D Reconstruction)則是讓機器真正“理解”物理世界。透過機器視覺實現3D重建,是賦予機器人、無人機和自動駕駛汽車空間感知能力的核心技術。
來源:https://blog.csdn.net/2403_87969572/article/details/157725993
抓取時間(ISO本地):2026-05-18 05:17:34
文章目錄
- 前言
- 1. 什麼是透過機器視覺實現3D重建?
- 2. 效果演示:3D重建的過程
- 3. 目前的主流方法
- 4. 適用場景
- 5. 目前的瓶頸與問題
- 總結
- 參考文獻
前言
在人工智慧的浪潮中,如果說傳統的2D影象識別是讓機器“認出”物體,那麼**3D重建(3D Reconstruction)**則是讓機器真正“理解”物理世界。透過機器視覺實現3D重建,是賦予機器人、無人機和自動駕駛汽車空間感知能力的核心技術。
1. 什麼是透過機器視覺實現3D重建?
定義
透過機器視覺實現的3D重建,是指利用光學感測器(如相機)獲取的2D影象序列,結合計算機視覺演算法,恢復物體的三維幾何形狀、空間位置以及表面紋理的過程。
核心本質:從2D到3D的逆向投影
在物理世界中,3D物體透過相機的透鏡成像在2D感光元件上,這是一個降維的過程(丟失了深度資訊 Z Z Z)。3D重建的目標就是透過數學模型和演算法,將這些丟失的深度資訊找回來,把畫素點還原到三維座標系( X , Y , Z X, Y, Z X,Y,Z)中。
關鍵概念
- 點雲(Point Cloud): 重建的第一步通常是生成大量帶有空間座標的取樣點。
- 三角剖分(Triangulation): 利用幾何關係確定點在空間中的位置。
- 深度圖(Depth Map): 每個畫素點代表距離相機距離的影象。
2. 效果演示:3D重建的過程
我們可以透過以下三個階段來想象重建的視覺效果:
- 稀疏重建階段(Sparse Reconstruction):
螢幕上出現零散的特徵點,看起來像是一群發光的螢火蟲構成了物體的輪廓。此時可以看清相機的運動軌跡。 - 稠密重建階段(Dense Reconstruction):
點雲變得極其密集,物體的形狀已經清晰可辨,像是由無數細小的沙粒堆砌而成的雕塑。 - 表面網格化與紋理貼圖(Meshing & Texturing):
演算法在點與點之間連線形成三角面片(Mesh),並把照片上的顏色“貼”上去。此時,物體在螢幕上看起來與真實照片無異,但你可以旋轉、縮放它。
概念解讀:
1. Mesh(網格 / 三角網格)
Mesh 是三維模型的 “幾何骨架”,它由大量三角形(或多邊形)面片拼接而成,只定義了物體的三維形狀、輪廓和結構,就像建築的鋼筋框架,本身沒有顏色和紋理。
2. 貼圖(Texture Mapping)
貼圖是一張包含顏色、紋理、細節資訊的二維影象,比如牆面的磚石紋理、窗戶的玻璃質感。它的作用是把這些表面細節 “貼” 到 Mesh 的幾何框架上。
3. 目前的主流方法
3D重建的方法主要分為主動視覺和被動視覺兩大類:
一、被動視覺(Passive Vision)—— 僅依賴環境光
這類方法不向物體發射能量,僅透過捕捉環境光成像。
A. 單目重建(Monocular Reconstruction):
原理:利用運動恢復結構(SfM, Structure from Motion)。透過單臺相機在不同位置拍攝的多張照片,計算相機位姿變化並重建場景。
難點: 存在尺度不確定性(不知道物體到底有多大)。
簡單來說,SfM 就是透過移動的相機拍攝的一系列2D影象,來推算出物體的3D形狀和相機的空間軌跡。
下面我將非常詳細地為你拆解 SfM 的原理、步驟以及它背後的數學邏輯。
什麼是 SfM(Structure from Motion)?
- Structure(結構): 指的是被拍攝物體的三維座標(點雲)。
- Motion(運動): 指的是相機在拍攝每一張照片時的位置(位姿,Pose)。
- From(透過…恢復): 強調了因果關係。
核心思想:
想象你圍著一個雕像轉圈拍照。雖然每張照片都是平面的(2D),但當你從左邊移動到右邊時,雕像上的特徵點(比如鼻子尖)在照片裡的位置會發生移動。SfM 演算法就像你的大腦一樣,透過分析這些點移動的幅度、方向和規律,反過來推算出:“哦,原來鼻子尖距離我這麼遠,而我剛才向右移動了 50 釐米。”
SfM 的全流程(極簡步驟版)
一個標準的 SfM 系統通常包含以下五個核心步驟:
1. 特徵提取與匹配 (Feature Extraction & Matching)
- 做什麼: 演算法會在每一張照片中尋找“地標”——那些無論光照怎麼變、角度怎麼變都能認出來的點(通常使用 SIFT 或 ORB 演算法)。
- 目的: 確定第一張照片裡的那個“點”和第二張照片裡的哪個“點”是物理世界中的同一個位置。
- 結果: 得到一堆配對好的畫素點座標。
2. 計算幾何關係 (Estimating Epipolar Geometry)
- 做什麼: 利用對極幾何(Epipolar Geometry)理論。透過匹配的點對,計算出兩張照片之間的數學變換關係,即基礎矩陣(Fundamental Matrix)或本質矩陣(Essential Matrix)。
- 原理: 即使不知道物體的形狀,只要有足夠的匹配點,我們就能算出相機從位置 A 到位置 B 到底旋轉了多少度,平移了多少距離。
3. 三角測量 (Triangulation)
- 做什麼: 有了相機的位姿,演算法會從兩個相機中心向同一個特徵點發射兩條射線。
- 原理: 這兩條射線的交點,就是該特徵點在三維空間中的真實座標( X , Y , Z X, Y, Z X,Y,Z)。
- 結果: 生成了最初的稀疏點雲。
4. 增量式重建 (Incremental Reconstruction)
- 做什麼: 演算法不會一次性處理幾百張照片,而是先從兩張開始,重建出一小部分,然後像拼圖一樣,不斷加入第三張、第四張照片。
- 過程: 每加入一張新照片,就利用已有的 3D 點雲來反推這張新照片的相機位置(這叫 PnP 演算法),然後再把新看到的點加入點雲。
5. 全域性最佳化:光束法平差 (Bundle Adjustment, BA)
- 這是 SfM 的靈魂: 隨著照片越來越多,誤差會累積,點雲會“飄”掉或變形。
- 做什麼: BA 是一項大型最佳化工程。它會同時調整所有相機的位姿和所有 3D 點的座標,使得每一個 3D 點投影回照片上時,與照片裡原始畫素點的距離(重投影誤差)最小。
為什麼單目 SfM 無法感知“絕對尺度”?
這是單目重建最致命的弱點,也是面試或學術討論中必問的問題。
原理:
在數學上,SfM 恢復出的空間結構具有尺度等比性。
- 如果你拍攝一張桌子上的水杯,重建出來的模型可能看起來很完美。
- 但是,演算法無法分辨這是一個真實的高 10 釐米的水杯,還是一個高 10 米的巨型水杯模型。
原因:
在單目相機看來,一個很小的物體離相機很近,和一個巨大的物體離相機很遠,在照片上的畫素表現是一模一樣的。除非你額外告訴演算法一個參考值(比如:照片裡那個硬幣直徑是 25mm,或者兩個相機其實距離 10cm),否則它只能告訴你:“A 點到 B 點的距離是 C 點到 D 點距離的 2 倍”,而不能告訴你到底是多少米。
SfM 的兩種主流流派
-
增量式 SfM (Incremental SfM):
- 代表作:COLMAP(目前學術界和工業界最常用的開源工具)。
- 優點:非常魯棒,精度高。
- 缺點:慢,照片多了之後最佳化非常耗時。
-
全域性式 SfM (Global SfM):
- 代表作:TheiaSfM。
- 優點:速度極快,適合大規模場景。
- 缺點:對異常匹配點非常敏感,容易崩潰。
參考檔案
若要深入研究 SfM 的底層數學,以下文獻是必讀的:
- Agarwal, S., et al. (2011). Building Rome in a Day. Communications of the ACM.
(這是 SfM 歷史上的里程碑,證明了利用網際網路上的成千上萬張照片重建一座城市是可能的)。 - Schönberger, J. L., & Frahm, J. M. (2016). Structure-from-Motion Revisited. CVPR.
(這是 COLMAP 的核心論文,目前被公認為增量式 SfM 的最優實踐)。 - Triggs, B., et al. (1999). Bundle Adjustment – A Modern Synthesis. Vision Algorithms: Theory and Practice.
(深入講解了 SfM 中最關鍵的最佳化演算法 BA)。 - Snavely, N., Seitz, S. M., & Szeliski, R. (2006). Photo Tourism: Exploring image collections in 3D. SIGGRAPH.
(首次向大眾展示瞭如何透過非結構化照片集進行 3D 導航)。 - Longuet-Higgins, H. C. (1981). A computer algorithm for reconstructing a scene from two projections. Nature.
(提出了著名的八點演算法,是 SfM 幾何計算的基石)。
B. 雙目/多目立體視覺(Stereo Vision):
原理: 模擬人類雙眼。透過計算左右兩個相機拍攝影象的視差(Disparity),利用三角測量原理計算深度。
如果說 SfM(運動恢復結構)是模仿人類“邊走邊看”來認知空間,那麼雙目立體視覺(Stereo Vision)則是直接模仿人類的雙眼結構。
它是機器視覺中最經典、應用最廣泛的深度感知技術之一。下面我們深度拆解雙目立體視覺的原理、數學邏輯以及實現過程。
1. 核心定義
雙目立體視覺是指使用兩臺成像特性相同(焦距、畫素尺寸等一致)的相機,安裝在同一平面上,保持一定的水平距離(基線,Baseline),透過計算左右影象中同一物體畫素點的相對位姿差異,來獲取物體三維資訊的方法。
直觀理解:
伸出你的一根手指放在眼前,先閉上左眼看,再閉上右眼看。你會發現手指相對於背景的位置發生了“跳動”。
- 手指離眼睛越近,跳動幅度(位姿差異)越大。
- 手指離眼睛越遠,跳動幅度越小。
- 這種跳動的位移量,在計算機視覺中被稱為視差(Disparity)。
2. 核心數學原理:三角測量(Triangulation)
雙目視覺的精髓可以用一個極其簡單的幾何公式來概括。
假設兩臺相機完全平行,焦距為 f f f,兩相機中心距離(基線)為 B B B。空間中一點 P P P 在左相機成像面上的橫座標是 x L x_L xL,在右相機成像面上的橫座標是 x R x_R xR。
-
視差(Disparity)定義: d
x L − x R d = x_L - x_R d=xL−xR
-
深度(Depth)計算公式:
Z
f ⋅ B d Z = \frac{f \cdot B}{d} Z=df⋅B
這個公式告訴我們兩個關鍵資訊:
- 反比關係: 深度 Z Z Z 與視差 d d d 成反比。視差越大,物體越近。
- 尺度確定性: 與單目 SfM 不同,由於基線 B B B 是提前測量好的物理常數(比如兩相機間距 6 釐米),所以雙目視覺可以直接計算出物體的真實物理距離(米或毫米),不存在尺度不確定性。
3. 標準演算法流程(Stereo Pipeline)
實現高質量的雙目重建通常需要經過以下四個嚴謹的步驟:
第一步:相機標定(Camera Calibration)
- 目的: 確定相機的內參(焦距、中心點)和外參(兩相機之間的精確旋轉和平移關係)。
- 意義: 如果相機鏡頭有畸變(比如魚眼效果),或者兩個相機沒裝正,後續計算全是錯的。
第二步:立體校正(Stereo Rectification)—— 極關鍵
- 做什麼: 透過數學變換,把拍攝時的兩張照片對齊,使得左右影象的極線(Epipolar Line)處於同一水平線上。
- 意義: 校正後,左圖中的一個點,在右圖中一定能在同一行找到。這把一個 2D 的搜尋問題降維成了 1D 搜尋,極大地提高了運算速度。
第三步:立體匹配(Stereo Matching)—— 最核心、最難
- 做什麼: 演算法要在右圖的同一行畫素裡,找到那個和左圖點“長得最像”的點。
- 主流演算法:
- BM (Block Matching): 快,但精度低,邊緣粗糙。
- SGM (Semi-Global Matching): 工業界的主流,在速度和精度間取得了極佳平衡。
- 深度學習方法: 如 PSMNet,利用神經網路直接輸出視差圖,在處理無紋理區域表現更好。
第四步:視差轉深度(Disparity to Depth)
-
做什麼: 利用前面提到的公式 Z
( f ⋅ B ) / d Z = (f \cdot B) / d Z=(f⋅B)/d,將畫素級的視差圖轉化為物理世界的深度圖。
4. 雙目視覺 vs. 單目 SfM 的區別
| 特性 | 雙目立體視覺 (Stereo) | 單目 SfM |
|---|---|---|
| 相機數量 | 2臺或多臺 | 1臺 |
| 拍攝狀態 | 可以靜態拍攝(瞬間成像) | 必須移動相機(動態拍攝) |
| 尺度感知 | 自動獲得真實物理尺度 | 無法獲得真實尺度(僅有比例) |
| 實時性 | 高(適合避障、機器人) | 低(計算量大,需運動序列) |
| 適用範圍 | 適合近距離、高精度感知 | 適合大場景、遠距離建模 |
5. 適用場景與侷限性
適用場景:
- 車載輔助駕駛(ADAS): 識別前方障礙物距離。
- 工業抓取: 機械臂識別零件的 3D 位置。
- 無人機避障: 實時感知周圍牆體距離。
侷限性:
- 環境紋理依賴: 如果牆面是純白色的,演算法無法在右圖中找到匹配的點(因為看起來都一樣),會導致深度丟失。
- 基線限制: 測量距離受限於基線 B B B。如果要測 100 米外的物體,基線必須足夠寬,否則視差 d d d 太小,會導致誤差劇增。
- 遮擋問題: 左眼看得到的地方,右眼可能被擋住了(暗影區),導致無法計算。
6. 參考資料與經典文獻
- Scharstein, D., & Szeliski, R. (2002). A taxonomy and evaluation of dense two-frame stereo correspondence algorithms. International Journal of Computer Vision.
(立體匹配領域的基石論文,定義了評估標準)。 - Hirschmuller, H. (2005). Accurate and efficient stereo processing by semi-global matching and mutual information. CVPR.
(提出了著名的 SGM 演算法,至今仍是該領域的工業標準)。 - Marr, D., & Poggio, T. (1979). A computational theory of human stereo vision. Proceedings of the Royal Society of London.
(從生物學和計算視覺角度解釋了人類雙眼如何感知深度)。 - Konolige, K. (1998). Small Vision Systems: Hardware and Implementation. International Symposium on Robotics Research.
(講解了實時雙目視覺系統的早期硬體實現)。 - Zhang, Z. (2000). A flexible new technique for camera calibration. IEEE Transactions on Pattern Analysis and Machine Intelligence.
(著名的“張氏標定法”,雙目相機標定的必備基礎)。
C. 神經輻射場(NeRF, Neural Radiance Fields)
* **前沿:** 2020年後的爆發性技術。利用深度學習將場景表示為一個連續的體積場,透過體渲染技術生成極其逼真的3D檢視。
如果說 SfM 是在做“幾何題”,雙目視覺是在做“物理題”,那麼 NeRF(Neural Radiance Fields,神經輻射場) 就是在用“人工智慧演算法”進行一次革命性的藝術創作。
NeRF 是 2020 年計算機視覺領域最具顛覆性的技術之一。它徹底改變了我們儲存和表現 3D 世界的方式。
1. 什麼是 NeRF?
定義:
NeRF 是一種利用深度神經網路(通常是多層感知機 MLP)來隱式地表示 3D 場景的技術。它不儲存點雲,也不儲存三角面片,而是將整個 3D 場景編碼進一個神經網路的權重裡。
核心直覺:
想象空間中充滿了“帶顏色的煙霧”。在每一個座標點上,煙霧都有特定的顏色和濃度。NeRF 的目標是訓練一個 AI 助手,當你問它:“在座標
(
x
,
y
,
z
)
(x, y, z)
(x,y,z) 這個點,從
(
θ
,
ϕ
)
(\theta, \phi)
(θ,ϕ) 這個角度看過去是什麼顏色?”它能立刻計算出結果。
2. NeRF 的核心原理:5D 函式
NeRF 將場景表示為一個連續的 5D 函式:
- 輸入 (5個引數): 空間位置 ( x , y , z ) (x, y, z) (x,y,z) + 觀察視角 ( θ , ϕ ) (\theta, \phi) (θ,ϕ)。
- 輸出 (4個引數): 該點的顏色
R
G
B
RGB
RGB + 該點的體積密度
σ
\sigma
σ(即光線透過這裡的阻力,代表物體是否存在)。
- 隱式表示(Implicit Representation):
傳統的 3D 模型像“樂高積木”(體素)或“摺紙”(網格)。NeRF 像“一段程式碼”,你給它座標,它吐出顏色。這使得它能表現極其精細的細節,而不需要海量的儲存空間。 - 位置編碼(Positional Encoding):
這是 NeRF 能火的關鍵。神經網路天生傾向於學習“平滑”的東西,容易把影象變模糊。NeRF 透過把座標轉換成高頻正弦/餘弦波,強制網路記住細節(如物體的邊緣、細小的紋理)。 - 可微體渲染(Differentiable Volume Rendering):
這是 NeRF 的“渲染引擎”。它沿著相機射出的一條光線進行取樣,把路徑上所有點的顏色和密度加權累加,最終得到一個畫素的顏色。因為整個過程是數學可導的,所以可以透過對比生成的影象和真實照片的差異,利用反向傳播來訓練網路。
3. NeRF 的工作流程
- 準備資料: 拍攝幾十張到上百張物體的照片,並利用 SfM (如 COLMAP) 算出每張照片拍攝時的精確相機位置。
- 光線投射: 對於影象上的每個畫素,從相機中心射出一條穿過該畫素的光線。
- 取樣與查詢: 在這條光線上取樣成百上千個點,把這些點的座標丟進神經網路裡。
- 合成顏色: 神經網路輸出這些點的顏色和密度,透過體渲染公式把它們“捏合”成一個畫素顏色。
- 最佳化權重: 比較 AI 生成的畫素和照片裡的真實畫素。如果不一樣,就調整神經網路的引數。重複成千上萬次,直到網路能完美預測出任何角度的畫面。
4. 為什麼 NeRF 效果這麼震撼?
- 照片級的真實感: 它能完美處理光澤表面(如金屬的反光)、透明物體(如玻璃杯)以及極其複雜的幾何結構(如頭髮、樹葉),這些都是傳統點雲或 Mesh 的噩夢。
- 無限的解析度: 因為是連續函式,理論上你可以無限放大場景。
- 視角插值: 你只拍了 20 張照片,但 NeRF 可以生成相機從未經過的位置的平滑影片,效果就像在好萊塢電影裡穿梭一樣。
5. 侷限性與目前的瓶頸
儘管效果驚豔,但原生 NeRF 存在以下問題:
- 訓練極慢: 2020 年剛出來時,訓練一個場景需要幾小時甚至幾天。
- 渲染(推理)極慢: 生成一張圖需要幾秒鐘,無法做到實時互動。
- 場景是死板的: 原生 NeRF 只能重建靜態場景,如果畫面裡有東西在動,或者光線變了,模型就會崩潰。
- 需要相機位姿: 它極其依賴 SfM 提供的精確座標,如果照片位姿算錯了,NeRF 出來的結果會是一團漿糊。
6. 進化之路(NeRF 的子孫們)
為了解決上述問題,誕生了一系列變體:
- Instant-NGP (NVIDIA): 將訓練時間從小時級縮短到了秒級。
- Mip-NeRF: 解決了物體在遠近切換時的鋸齒問題。
- D-NeRF / NSVF: 嘗試處理會動的物體(動態場景)。
- 3D Gaussian Splatting (2023): 雖然不完全是 NeRF,但它吸取了 NeRF 的思想,實現了真正實時的高質量渲染,是目前最火的替代方案。
7. 參考文獻
- Mildenhall, B., Srinivasan, P. P., Tancik, M., Barron, J. T., Ramamoorthi, R., & Ng, R. (2020). NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis.
ECCV. (NeRF 的開山之作)。 - Müller, T., Evans, A., Schied, C., & Keller, A. (2022). Instant Neural Graphics Primitives with a Multiresolution Hash Encoding. ACM Transactions on Graphics.
(NVIDIA 提出的 Instant-NGP,讓 NeRF 走向實用化)。 - Barron, J. T., et al. (2021). Mip-NeRF: A Multiscale Representation for Anti-Aliasing Neural Radiance Fields. ICCV.
(解決了抗鋸齒和多尺度問題)。 - Tancik, M., et al. (2022). Block-NeRF: Scalable Large Scene Neural View Synthesis. CVPR.
(證明了 NeRF 可以用來重建整個城市街道)。 - Martin-Brualla, R., et al. (2021). NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections. CVPR.
(解決了利用網際網路亂七八糟的照片進行重建的問題)。
D. 3D Gaussian Splatting (3DGS):
最新: 2023年出現的技術,透過大量3D高斯橢球體擬合場景,實現了比NeRF更快的渲染速度和極高的重建質量。
如果說 NeRF 是 3D 重建領域的“數字幻覺”,那麼 3D Gaussian Splatting (3DGS) 就是在 2023 年橫空出世的“數字畫筆”。
3DGS 的出現直接解決了 NeRF 渲染慢、訓練久的核心痛點,將 3D 重建推向了實時、高畫質、可互動的新紀元。
1. 什麼是 3D Gaussian Splatting (3DGS)?
定義:
3DGS 是一種基於顯式輻射場(Explicit Radiance Field)的場景表示技術。它不使用神經網路來“猜”顏色,而是直接在空間中拋灑數百萬個帶有顏色、形狀和透明度的3D 高斯橢球體(Gaussian Kernels),透過這些橢球體的疊加來拼湊出整個世界。
形象比喻:
- NeRF 像是一個記憶力超強的畫師:你問他畫裡某個座標是什麼顏色,他想一下告訴你。
- 3DGS 像是一個貼紙大師:他直接在透明的空間裡貼了數百萬張半透明的彩色貼紙(橢球體),你從任何角度看過去,這些貼紙疊加在一起就是一張完美的照片。
2. 核心原理:3D 高斯橢球體的“基因”
每一個 3D 高斯橢球體都包含了一組極其精簡的數學引數(基因):
- 中心位置 (Position, X , Y , Z X, Y, Z X,Y,Z): 橢球體在哪。
- 協方差矩陣 (Covariance,
Σ
\Sigma
Σ): 決定橢球體的形狀和方向。為了方便計算,它被分解為:
- 縮放 (Scaling): 它是長的、圓的還是扁的。
- 旋轉 (Rotation): 它是橫著的還是斜著的。
- 不透明度 (Opacity, α \alpha α): 這個橢球體有多透明。
- 球諧函式顏色 (Spherical Harmonics, SH): 這是一種特殊的顏色表示法。它不只是一個單一顏色,而是記錄了從不同方向看這個點時顏色的變化(比如金屬的高光)。
3. 工作流程:從點雲到精美建模
第一步:初始化 (Initialization)
3DGS 通常以 SfM (如 COLMAP) 產生的稀疏點雲作為起點。每個點被初始化為一個小的 3D 高斯球。
第二步:可微投影與渲染 (Splatting & Rasterization)
這是 3DGS 速度極快的秘訣。
- 演算法將 3D 的橢球體平扁化(投影)到 2D 螢幕上,變成一個個 2D 橢圓。
- 採用基於分塊(Tile-based)的快速光柵化渲染器。它將螢幕分成許多小格子(Tiles),只渲染對這個格子有貢獻的橢球體。這與現代顯示卡(GPU)的處理邏輯完全匹配。
第三步:自適應密度控制 (Adaptive Density Control)
這是 3DGS 的“進化”過程。在最佳化過程中,演算法會觀察:
- 克隆 (Clone): 如果某個地方太平滑,點不夠用,就在那複製一個點。
- 分裂 (Split): 如果某個橢球體太大、太模糊,就把它拆成兩個小的。
- 修剪 (Culling): 如果某個橢球體不透明度極低,基本看不見,就把它刪掉。
為什麼 3DGS 能在 2023 年引爆技術圈?
- 渲染速度起飛: NeRF 渲染一張圖需要幾秒鐘,而 3DGS 可以在普通的 GPU 上實現 100+ FPS(每秒幀數)的實時渲染。
- 訓練時間極短: 一箇中等複雜的場景,NeRF 可能要訓練幾小時,3DGS 只需要 5-10 分鐘。
- 顯式儲存: 因為它是數百萬個點,你可以直接在 3D 軟體裡看到這些點,甚至可以手動刪除、移動或縮放其中的一部分,這在 NeRF 的神經網路權重裡是幾乎做不到的。
- 視覺效果驚豔: 3DGS 捕捉精細細節(如樹葉、毛髮、薄霧)的能力極強,畫面邊緣比 NeRF 更加銳利。
5. 目前的瓶頸與挑戰
- 視訊記憶體壓力大 (VRAM Intensive): 渲染雖然快,但要在視訊記憶體裡儲存數百萬個高斯引數,非常吃視訊記憶體(通常需要 8GB 以上的視訊記憶體才能流暢執行大型場景)。
- 儲存空間巨大: 一個高質量場景的模型檔案可能高達 數百 MB 甚至幾個 GB,而 NeRF 只需要幾 MB 的神經網路權重。
- 依賴初始化: 如果 SfM 出來的初始點雲太差(比如在光滑平面上沒取到點),3DGS 很難憑空生成高質量的橢球體,會出現明顯的“破洞”。
- 偽影 (Artifacts): 在視角變化劇烈時,有時會看到橢球體像“彩色雪花”一樣漂浮。
6. 參考文獻
- Kerbl, B., Kopanas, G., Leimkühler, T., & Drettakis, G. (2023). 3D Gaussian Splatting for Real-Time Radiance Field Rendering. ACM Transactions on Graphics (SIGGRAPH).
(3DGS 的開山鼻祖,目前該領域引用量最高的論文)。 - Zwicker, M., Pfister, H., van Baar, J., & Gross, M. (2001). Surface Splatting. SIGGRAPH.
(3DGS 核心思想“Splatting”的早期理論來源)。 - Luan, F., et al. (2024). GPS-Gaussian: Generalizable Pixel-wise 3D Gaussian Splatting for Real-time Human Novel View Synthesis.
(將 3DGS 應用於人體動態建模的前沿工作)。 - Niedermayr, S., et al. (2023). Compressed 3D Gaussian Splatting for Highly Accessible Novel View Synthesis.
(針對 3DGS 儲存體積過大問題的早期最佳化研究)。 - Chen, Z., et al. (2023). MCMC-GS: Multi-Scale 3D Gaussian Splatting for Large-Scale Scene Reconstruction.
(針對大規模城市場景的 3DGS 改進演算法)。
二. 主動視覺(Active Vision)—— 自帶光源
這類方法透過向物體發射特定光線來輔助測量。
- 結構光(Structured Light):
- 原理: 投影儀向物體投射特定的光柵圖案,相機拍攝被物體表面畸變後的圖案,透過數學計算得出深度。
- 代表: iPhone的前置FaceID。
如果說 SfM 和雙目視覺是利用“自然的眼睛”去觀察世界,那麼**結構光(Structured Light)**則是給機器裝上了一臺“主動測量尺”。
它是目前高精度 3D 掃描、人臉識別(如 iPhone FaceID)和工業精密檢測領域最核心的技術。
A. 結構光技術
####定義:
結構光是一種主動視覺測量技術。它透過投影儀向物體表面投射特定的已知圖案(如格點、條紋、編碼圖),再由相機捕捉這些圖案在物體表面發生的幾何畸變,透過三角測量原理計算出物體的三維空間座標。
形象比喻:
想象你在黑暗中面對一面凹凸不平的牆。你開啟一支手電筒,手電筒的光罩上畫著整齊的方格。
- 如果牆是平的,你在牆上看到的方格也是整齊的。
- 如果牆上有個坑或者凸起,方格線就會變得彎曲。
- 透過觀察方格線“彎了多少”,你就能推算出牆面的起伏。這就是結構光。
2. 核心數學原理:變形的三角測量
結構光本質上是雙目視覺的變種。
- 在雙目視覺中,我們需要兩個相機從不同角度看同一個點。
- 在結構光中,我們用一個投影儀替代了其中一個相機。
數學邏輯:
- 已知條件: 投影儀投射出的光束角度是已知的,相機與投影儀之間的距離(基線 B B B)是固定的。
- 尋找匹配: 投影儀投出的每一個光點(或線條)都有一個唯一的“編碼”。相機拍到這個點後,立刻就能知道它是從投影儀的哪個角度射出來的。
- 幾何求解: 投影儀發出的射線與相機接收到的射線在空間中相交。根據正弦定理或簡單的三角函式,即可解算出該交點的三維座標 ( X , Y , Z ) (X, Y, Z) (X,Y,Z)。
3. 編碼方式:結構光的“語言”
結構光最核心的競爭力在於如何設計投射的“圖案”。目前主流有三種:
A. 空間編碼 (Spatial Coding) —— 代表:iPhone FaceID
- 做法: 一次性投射一個複雜的散斑圖案(類似滿天星)。
- 特點: 只需拍攝一張圖片即可完成重建,速度極快,適合動態物體(如人臉)。
B. 時間編碼 (Temporal Coding) —— 代表:工業 3D 掃描器
- 做法: 連續投射多張不同頻率的黑白條紋(如格雷碼 + 正弦條紋)。
- 特點: 精度極高(可達微米級),但物體必須保持靜止,因為需要拍攝多張照片。
C. 相移法 (Phase Shifting)
- 做法: 投射週期性的正弦光柵,透過分析光波相位的偏移來提取高度資訊。
4. 深度解析:iPhone FaceID 是如何工作的?
FaceID 是結構光技術小型化、消費級應用的巔峰。它包含三個核心元件:
- 點陣投影器 (Dot Projector): 向你的臉部投射超過 30,000 個肉眼不可見的紅外散斑點。
- 紅外攝像頭 (Infrared Camera): 讀取這些散斑在臉部起伏下形成的畸變影象。
- 泛光感應元件 (Flood Illuminator): 確保在全黑環境下也能照亮臉部,供紅外相機識別。
為什麼它安全?
因為它不是在對比“照片”,而是在對比你臉部的三維地形圖。照片是平面的,無法產生結構光的畸變效果,因此無法欺騙 FaceID。
5. 結構光的優缺點
優點:
- 無需環境紋理: 即使是純白色的牆,結構光也能重建(因為它自己投射了紋理),這彌補了雙目視覺的短板。
- 精度極高: 在近距離(1米以內),結構光的精度可以輕鬆達到毫米甚至微米級。
- 主動補光: 在全黑的環境下依然能工作。
缺點:
- 怕強光: 在室外強光(如陽光)下,投影儀的光會被陽光淹沒,導致失效。
- 距離限制: 投影儀功率有限,通常只適用於近距離(如手機解鎖、桌面掃描)。
- 材質敏感: 面對鏡面反光物體或全黑吸光物體,投射的光會消失或亂射,導致無法成像。
6. 參考文獻
- Geng, J. (2011). Structured-light 3D surface imaging: a tutorial. Advances in Optics and Photonics.
(最經典的結構光綜述性教程)。 - Scharstein, D., & Szeliski, R. (2003). High-accuracy stereo depth maps using structured light. CVPR.
(探討了如何利用結構光獲取極高精度的深度圖)。 - Salvi, J., et al. (2004). Pattern codification strategies in structured light systems. Pattern Recognition.
(詳細對比了各種編碼圖案的優劣)。 - Apple Inc. About Face ID advanced technology. Support Documentation.
(雖然不是學術論文,但揭示了消費級結構光系統的硬體架構)。 - Zuo, C., et al. (2016). Micro-structured-light 3D surface profiling: A review. Measurement.
(聚焦於微觀領域高精度結構光測量的綜述)。
飛行時間法(ToF, Time of Flight)
原理: 發射紅外脈衝,測量光線反射回來的時間。
代表: 鐳射雷達(LiDAR)、Kinect 2.0。
如果說結構光是利用“幾何畸變”來測量,那麼**飛行時間法(ToF, Time of Flight)**就是利用“絕對速度”來測量。
ToF 是目前 3D 感知領域中速度最快、延遲最低的技術。它廣泛應用於自動駕駛的鐳射雷達(LiDAR)、手機後置深度攝像頭(如 iPhone 的 LiDAR 掃描器)以及早期的體感遊戲裝置。
1. 什麼是 ToF (飛行時間法)?
定義:
ToF 是一種透過測量光波在感測器與目標物體之間“飛行”的時間,來計算目標距離的技術。因為光的傳播速度
c
c
c 是已知的常數,只要知道了時間
t
t
t,距離
d
d
d 也就迎刃而解。
形象比喻:
想象你對著一口深井大喊一聲,然後開始計時。當你聽到回聲時,停止計時。
- 聲納/雷達: 利用聲波或無線電波的反射。
- ToF: 利用光波(通常是 850nm-940nm 的近紅外光)。由於光速極快(每秒 30 萬公里),ToF 晶片需要具備“皮秒級”(萬億分之一秒)的計時精度。
2. 核心數學原理:極速公式
ToF 的基本原理非常直觀,但實現方法分為兩種主要流派:dToF 和 iToF。
A. dToF (Direct ToF,直接測量) —— 代表:鐳射雷達 (LiDAR)
這是最硬核的方式。感測器直接發射一個極短的光脈衝,並啟動一個超高精度的“秒錶”,記錄光子飛出去並跳回來的確切時間
Δ
t
\Delta t
Δt。
-
公式: d
c ⋅ Δ t 2 d = \frac{c \cdot \Delta t}{2} d=2c⋅Δt - 難點: 光速太快,光走 1 釐米只需要約 33 皮秒。這就要求感測器(通常是 SPAD,單光子雪崩二極體)具有極其恐怖的響應速度。
B. iToF (Indirect ToF,間接測量) —— 代表:Kinect 2.0
由於精確計時太難且貴,iToF 採用了“曲線救國”的方法:它發射的是連續的正弦調製光波,透過測量發射波與反射波之間的**相位差(Phase Shift)**來推算時間。
- 邏輯: 相位偏移了多少度,就代表時間過去了多久。
- 優點: 硬體成本較低,畫素解析度可以做得很高(類似手機攝像頭)。
3. ToF 的工作流程
- 發射單元 (Emitter): 發出經過調製的紅外鐳射或脈衝。
- 反射 (Reflection): 光線觸碰物體表面後發生彌散反射。
- 接收單元 (Sensor): 一個特殊的 CMOS 影象感測器捕捉返回的光訊號。
- 處理單元 (Processor):
- 對於 dToF:統計光子到達的直方圖,確定峰值時間。
- 對於 iToF:計算每個畫素點的電荷差異,轉換成相位,再換算成深度值。
- 輸出: 生成一張深度圖(Depth Map),每個畫素代表該點的物理距離。
4. ToF vs. 結構光:有什麼區別?
| 特性 | ToF (飛行時間法) | 結構光 (Structured Light) |
|---|---|---|
| 計算量 | 極低(硬體直接輸出結果) | 高(需要複雜的影象對比分析) |
| 工作距離 | 遠(鐳射雷達可達數百米) | 短(通常 1 米以內) |
| 抗干擾性 | 較強(尤其 dToF 適合室外) | 較弱(強光下圖案會被淹沒) |
| 解析度 | 較低(通常是 QVGA 級) | 較高(可以達到百萬畫素) |
| 應用場景 | 掃地機器人、自動駕駛、AR 建模 | 手機面部解鎖、精密掃描、活體檢測 |
5. 目前的瓶頸與挑戰
- 多徑干擾 (Multi-path Interference):
如果光線在牆角經過多次反射才回到感測器,ToF 會誤以為物體比實際更遠,產生“深度重影”。 - 飛點效應 (Flying Pixels):
在物體的邊緣,一個畫素可能同時接收到物體表面和背景牆的反射訊號,導致邊緣出現一圈莫須有的“飛點”。 - 環境光干擾:
雖然 iToF 在室內表現優異,但在太陽光下,紅外光噪聲巨大,會導致精度大幅下降(dToF 透過單光子技術緩解了這一問題)。 - 功耗問題:
因為要不斷地主動發射光,ToF 感測器通常比普通攝像頭更耗電。
6. 參考文獻
- Hansard, M., Lee, S., Choi, O., & Horaud, R. P. (2012). Time-of-Flight Cameras: Principles, Methods and Applications. Springer Briefs in Computer Science.
(最系統講解 ToF 原理的經典書籍)。 - Li, L. (2014). Time-of-flight camera – An introduction. Technical report, Texas Instruments.
(TI 釋出的官方技術報告,深入講解了 iToF 的電子學實現)。 - Horaud, R., et al. (2016). An overview of gradient-based 3D reconstruction methods for Time-of-Flight RGB-D cameras. Journal of Mathematical Imaging and Vision.
(探討了如何最佳化 ToF 的深度圖質量)。 - Bamji, C. S., et al. (2015). A 0.13μm CMOS System-on-Chip for a 512×424 Time-of-Flight Image Sensor with Multi-Frequency Photo-Demodulation. ISSCC.
(Kinect 2.0 背後晶片的技術細節論文)。 - Niclass, C., et al. (2005). A CMOS single photon avalanche diode array for 3D imaging. IEEE International Solid-State Circuits Conference.
(dToF 核心元件 SPAD 感測器的奠基性研究)。
4. 適用場景
3D重建技術已經深入到各行各業:
- 工業自動化: 高精度零件的尺寸檢測、缺陷掃描、機器人抓取引導。
- 自動駕駛與機器人: 避障、環境建模(SLAM)、高精地圖製作。
- 文化遺產保護: 對古建築物、文物進行數字化建模,實現永恆儲存。
- 醫療成像: 牙科掃描建模、手術前3D模擬。
- 數字孿生與元宇宙: 將現實世界的物體快速建模並匯入遊戲或虛擬空間。
- 電子商務: 手機掃描商品實現3D預覽(如宜家傢俱試擺)。
5. 目前的瓶頸與問題
儘管技術發展迅速,但3D重建仍面臨以下嚴峻挑戰:
- 弱紋理與重複紋理:
面對潔白的牆壁、純色桌面或玻璃表面,演算法很難找到可靠的特徵匹配點,導致重建失敗或出現“破洞”。 - 反光與透明物體:
金屬表面的高光和玻璃的折射會誤導相機,使演算法計算出錯誤的深度。 - 計算複雜度與實時性:
高精度的稠密重建需要巨大的算力,在移動裝置或嵌入式平臺上難以實現超高精度的實時重建。 - 遮擋問題:
當物體的一部分被擋住時,演算法需要透過先驗知識(AI猜想)來補全,這往往會導致精度下降。 - 光照敏感性:
過強或過暗的光線都會嚴重影響被動視覺方法的特徵提取質量。
總結
透過機器視覺實現3D重建是計算機視覺領域的“聖盃”之一。從經典的三角幾何到現代的深度學習(NeRF/3DGS),我們正處於從“拍出好看的照片”向“構建完美的數字世界”跨越的時代。隨著算力的提升和演算法的最佳化,未來的3D重建將變得像拍照一樣簡單且精準。
參考文獻
為了保證資訊的真實性與學術嚴謹性,以下是本部落格參考的核心文獻與經典教材:
- Hartley, R., & Zisserman, A. (2004). Multiple View Geometry in Computer Vision. Cambridge University Press.
(計算機視覺領域的聖經,詳細講解了多檢視幾何和相機模型)。 - Mildenhall, B., et al. (2020). NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. ECCV.
(神經輻射場奠基之作)。 - Kerbl, B., et al. (2023). 3D Gaussian Splatting for Real-Time Radiance Field Rendering. ACM Transactions on Graphics.
(當前最前沿的實時3D重建演算法)。 - Schonberger, J. L., & Frahm, J. M. (2016). Structure-from-Motion Revisited. CVPR.
(COLMAP演算法的理論基礎)。 - Newcombe, R. A., et al. (2011). KinectFusion: Real-time 3D reconstruction and interaction using a moving depth camera. ISMAR.
(結構光與ToF實時重建的經典文獻)。
作者提示: 如果你對具體的某個演算法(如如何配置COLMAP或如何訓練NeRF)感興趣,歡迎在評論區留言,我將在下一期詳細講解!
Concept Deep Dive: How Machine Vision Gives Machines “3D Eyes”—A Panoramic Guide to 3D Reconstruction
A panoramic, practitioner-friendly survey of 3D reconstruction from images: passive methods (monocular SfM, stereo/disparity, NeRF, 3D Gaussian Splatting) vs. active sensing (structured light, ToF), with pipelines, trade-offs, real-world uses, open challenges, and key references.
Captured at (ISO local): 2026-05-18 05:17:34
Foreword
In the AI era, if classical 2D recognition lets a machine “name” objects, 3D reconstruction is what lets it truly “understand” the physical world. Reconstructing 3D structure from machine vision is foundational to spatial perception for robots, drones, and autonomous vehicles.
1. What Is 3D Reconstruction via Machine Vision?
Definition
3D reconstruction via machine vision is the process of recovering an object’s 3D geometry, spatial layout, and surface appearance from 2D image sequences captured by optical sensors (e.g., cameras), using computer vision algorithms.
Core idea: inverse projection from 2D to 3D
In the real world, a 3D scene projects through a camera lens onto a 2D sensor—a dimension-reducing mapping that discards depth (Z). Reconstruction aims to infer that lost depth and lift pixels back into a 3D coordinate system ((X,Y,Z)).
Key concepts
- Point cloud: reconstruction often begins with many samples carrying 3D coordinates.
- Triangulation: geometric reasoning that fixes a point’s 3D location.
- Depth map: an image where each pixel stores distance from the camera.
2. Demo: How 3D reconstruction unfolds
Think of three visual stages:
- Sparse reconstruction: scattered landmarks glow like fireflies along silhouettes; camera motion becomes visible.
- Dense reconstruction: the cloud thickens until shape emerges, like sand packed into a sculpture.
- Meshing & texturing: points are connected into triangle meshes and photos are “wrapped” onto them—rotate and zoom a model that looks like the real thing.
How to read this:
1. Mesh (triangle mesh)
The mesh is the geometric skeleton: many triangles (or polygons) define 3D shape only—like rebar in a building, with no intrinsic color/texture.
2. Texture mapping
A texture is a 2D image of color and fine detail (brick, glass, etc.) pasted onto the mesh to finish the look.
3. Mainstream methods today
Methods split broadly into active and passive vision.
I. Passive vision—ambient light only
No deliberate illumination is projected; the system relies on ambient light.
A. Monocular reconstruction
Idea: Structure from Motion (SfM)—multiple images from one moving camera to estimate poses and reconstruct the scene.
Difficulty: scale ambiguity (absolute size is unknown).
SfM uses a moving camera and a 2D image sequence to recover 3D structure and the camera trajectory.
Below is a detailed breakdown of SfM’s principles, steps, and math.
What is SfM (Structure from Motion)?
- Structure: 3D coordinates of the scene (point cloud).
- Motion: camera pose for each frame.
- From emphasizes the causal chain.
Intuition: walk around a statue with one camera. Each frame is 2D, but feature motion encodes depth and your path. SfM infers: “the nose tip is this far away, and I moved this much to the right.”
SfM end-to-end (minimal step list)
A standard SfM system has five core stages:
1. Feature extraction & matching
- What: find stable landmarks—points robust to lighting/viewpoint (often SIFT or ORB).
- Why: link the same physical point across images.
- Output: paired pixel coordinates.
2. Estimating epipolar geometry
- What: from matches, estimate the two-view relation—the fundamental or essential matrix.
- Why: even without a 3D model, enough correspondences reveal relative rotation and translation.
3. Triangulation
- What: with poses known, cast rays from both camera centers through a matched feature.
- Why: the 3D point lies at the intersection—coordinates ((X,Y,Z)).
- Output: an initial sparse cloud.
4. Incremental reconstruction
- What: grow the model image-by-image (not all at once).
- How: add a new view, use existing 3D points with PnP to localize the new camera, then extend the cloud.
5. Global refinement: bundle adjustment (BA)
- The heart of SfM: error drifts as more frames arrive; geometry can warp.
- What BA does: jointly optimize all camera poses and all 3D points to minimize reprojection error—distance between projected 3D points and observed pixels.
Why monocular SfM lacks absolute scale?
A classic interview topic.
Principle: the recovered structure is correct only up to a similarity transform (scale free).
- A cup on a desk may reconstruct perfectly—yet the system cannot tell a 10 cm cup from a 10 m prop.
Reason: a small nearby object and a large distant one can produce identical images. Without an external datum (e.g., a 25 mm coin, or a 10 cm baseline between rig cameras), you only get ratios—“AB is twice CD”—not meters.
Two mainstream SfM families
- Incremental SfM
- Flagship: COLMAP (widely used in research and industry).
- Pros: robust, accurate.
- Cons: slow; large image sets make optimization heavy.
- Global SfM
- Example: TheiaSfM.
- Pros: fast for large scenes.
- Cons: sensitive to bad matches; can fail.
Further reading
For SfM math in depth:
- Agarwal, S., et al. (2011). Building Rome in a Day. Communications of the ACM.
(Landmark: city-scale reconstruction from Internet photos.) - Schönberger, J. L., & Frahm, J. M. (2016). Structure-from-Motion Revisited. CVPR.
(COLMAP’s backbone—reference incremental SfM practice.) - Triggs, B., et al. (1999). Bundle Adjustment – A Modern Synthesis. Vision Algorithms: Theory and Practice.
(Deep dive on BA—the key optimizer.) - Snavely, N., Seitz, S. M., & Szeliski, R. (2006). Photo Tourism: Exploring image collections in 3D. SIGGRAPH.
(Popularized navigating photo collections in 3D.) - Longuet-Higgins, H. C. (1981). A computer algorithm for reconstructing a scene from two projections. Nature.
(Eight-point algorithm—geometric cornerstone.)
B. Stereo / multi-view stereo
Idea: mimic human binocular vision—measure disparity between rectified views and recover depth by triangulation.
If SfM is “walk and observe,” stereo is “two fixed eyes.” It is among the most classical and widely deployed depth technologies. Below: principles, math, and pipeline.
1. Core definition
Stereo uses two (or more) cameras with matched intrinsics, aligned on a common plane, separated by a horizontal baseline (B). Depth comes from disparity—the horizontal shift of corresponding pixels.
Intuition: hold a finger near your face, alternately close left/right eyes—the finger “jumps” against the background.
- Nearer objects: larger jump (disparity).
- Farther objects: smaller jump.
2. Core math: triangulation
With parallel cameras, focal length (f), baseline (B), a 3D point (P) projects to (x_L) in the left image and (x_R) in the right.
- Disparity: (d = x_L - x_R).
- Depth:
[ Z = \frac{f \cdot B}{d} ]
What this says:
- Depth inversely tracks disparity—large disparity means near.
- Unlike monocular SfM, (B) is a measured physical constant (e.g., 6 cm), so stereo recovers metric depth.
3. Standard pipeline
Step 1: Camera calibration
- Goal: intrinsics (focal length, principal point) and extrinsics (relative pose).
- Why: lens distortion or misalignment breaks geometry downstream.
Step 2: Stereo rectification (critical)
- Goal: warp images so epipolar lines are horizontal rows.
- Why: reduces correspondence search from 2D to 1D.
Step 3: Stereo matching (hardest)
- Goal: for each left pixel, find the best match on the same row in the right image.
- Classics:
- BM (block matching): fast, coarse edges.
- SGM: industry sweet spot—speed vs. accuracy.
- Deep nets (e.g., PSMNet): better on weak texture.
Step 4: Disparity to depth
- Apply (Z = (f \cdot B) / d) pixel-wise to get a metric depth map.
4. Stereo vs. monocular SfM
| Aspect | Stereo | Monocular SfM |
|---|---|---|
| Cameras | Two or more | One |
| Capture | Can be static snapshots | Needs camera motion |
| Metric scale | Yes (known baseline) | No (up to scale) |
| Real time | High (robotics, ADAS) | Lower (long sequences, heavy BA) |
| Best for | Short-range, precise sensing | Large scenes, far objects |
5. Use cases and limits
Uses:
- ADAS: forward obstacle range.
- Bin picking: 6-DoF part localization.
- Drone obstacle: wall distances in real time.
Limits:
- Texture dependence: blank walls yield no matches—depth holes.
- Baseline vs. range: very far objects shrink disparity; tiny errors explode without a wide baseline.
- Occlusion: the left camera may see surfaces the right cannot.
6. References
- Scharstein, D., & Szeliski, R. (2002). A taxonomy and evaluation of dense two-frame stereo correspondence algorithms. IJCV.
- Hirschmuller, H. (2005). Accurate and efficient stereo processing by semi-global matching and mutual information. CVPR. (SGM.)
- Marr, D., & Poggio, T. (1979). A computational theory of human stereo vision. Proc. Royal Society.
- Konolige, K. (1998). Small Vision Systems: Hardware and Implementation. ISRR.
- Zhang, Z. (2000). A flexible new technique for camera calibration. PAMI. (Zhang’s method—stereo calibration staple.)
C. NeRF (Neural Radiance Fields)
* **Cutting edge (post-2020):** explosive progress. Deep learning represents the scene as a continuous volumetric field; differentiable rendering produces photoreal novel views.
If SfM solves geometry homework and stereo solves physics homework, NeRF is generative artistry with neural nets—a paradigm shift in how we store and render 3D worlds.
NeRF (2020) was among the most disruptive ideas in vision: implicit scenes encoded by network weights rather than explicit meshes or point clouds.
1. What is NeRF?
Definition: use a deep MLP to represent a scene implicitly. No point cloud or mesh—geometry and appearance live in network parameters.
Intuition: space is filled with colored “smoke.” At ((x,y,z)), density and color depend on viewing direction ((\theta,\phi)). NeRF trains a function that answers: “What would I see from this viewpoint?”
2. Core idea: a 5D function
NeRF models a continuous mapping:
- Inputs (5D): position ((x,y,z)) + view direction ((\theta,\phi)).
- Outputs (4D): RGB color + volume density (\sigma) (how much the ray is occluded).
- Implicit representation: voxels are bricks; meshes are origami; NeRF is executable code—query coordinates, get radiance—enabling fine detail without huge storage.
- Positional encoding: MLPs bias toward overly smooth solutions; NeRF wraps coordinates in high-frequency sines/cosines so edges and texture survive.
- ** Differentiable volume rendering:** march along a camera ray, accumulate color weighted by transmittance; the pipeline is differentiable, so photometric loss backpropagates into weights.
3. NeRF workflow
- Data: tens to hundreds of images + SfM (e.g., COLMAP) for accurate poses.
- Ray casting: one ray per pixel from the camera center.
- Sampling & queries: many 3D samples along each ray → network forward.
- Composite color: integrate radiance and density into a pixel color.
- Optimize: minimize difference to real photos until novel views match.
4. Why NeRF looks so good
- Photorealism: shiny metal, glass, hair, foliage—pain points for mesh/point clouds.
- Resolution: continuous field ⇒ zoom in without voxel grid limits.
- View interpolation: smooth paths between sparse captures—cinematic flythroughs.
5. Limitations
- Slow training: hours to days per scene (early work).
- Slow rendering: seconds per frame—no interactive rates natively.
- Static scenes: moving objects or lighting changes break vanilla NeRF.
- Pose sensitivity: bad SfM → blurry or collapsed reconstructions.
6. Evolution (NeRF descendants)
- Instant-NGP (NVIDIA): training in seconds.
- Mip-NeRF: anti-aliased multiscale reconstruction.
- D-NeRF / NSVF: steps toward dynamics / efficient structures.
- 3D Gaussian Splatting (2023): not purely NeRF, but borrows radiance-field ideas for real-time quality.
7. References
- Mildenhall, B., Srinivasan, P. P., Tancik, M., Barron, J. T., Ramamoorthi, R., & Ng, R. (2020). NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. ECCV.
- Müller, T., Evans, A., Schied, C., & Keller, A. (2022). Instant Neural Graphics Primitives with a Multiresolution Hash Encoding. ACM TOG.
- Barron, J. T., et al. (2021). Mip-NeRF: A Multiscale Representation for Anti-Aliasing Neural Radiance Fields. ICCV.
- Tancik, M., et al. (2022). Block-NeRF: Scalable Large Scene Neural View Synthesis. CVPR.
- Martin-Brualla, R., et al. (2021). NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections. CVPR.
D. 3D Gaussian Splatting (3DGS)
Recent: since 2023, millions of 3D Gaussians fit a scene—faster rendering than NeRF with very high fidelity.
If NeRF is a “digital illusionist,” 3DGS is the “digital brush” of 2023—addressing NeRF’s training and rendering cost while pushing reconstruction toward real-time, high quality, interactive use.
1. What is 3DGS?
Definition: an explicit radiance field: no neural “oracle,” but millions of 3D Gaussian kernels with color, shape, and opacity—splat together to reproduce views.
Metaphor:
- NeRF: ask the network the color at ((x,y,z,\theta,\phi)).
- 3DGS: paste semi-transparent colored ellipsoids in space; their sum is the image.
2. Core idea: Gaussian “genes”
Each Gaussian stores compact parameters:
- Position ((X,Y,Z)).
- Covariance (\Sigma) (shape/orientation), often factored into scale and rotation.
- Opacity (\alpha).
- Spherical-harmonics color (SH): view-dependent appearance (specular highlights).
3. Pipeline: from point cloud to polished model
Step 1: Initialization
Start from SfM (e.g., COLMAP) sparse points; initialize tiny 3D Gaussians.
Step 2: Differentiable splatting / rasterization
Project 3D ellipsoids to 2D ellipses; tile-based rasterizers cull work per screen tile—GPU friendly.
Step 3: Adaptive density control
During optimization:
- Clone where under-sampled.
- Split oversized blobs into finer Gaussians.
- Cull nearly invisible Gaussians.
Why 3DGS made waves in 2023
- Rendering speed: NeRF seconds/frame → 100+ FPS on mid-range GPUs for many scenes.
- Training: hours of NeRF → often 5–10 minutes for moderate scenes.
- Explicit editability: you can inspect, delete, move, or scale primitives—nearly impossible with NeRF weights alone.
- Crisp details: foliage, hair, thin structures—often sharper than NeRF.
5. Current bottlenecks
- VRAM hungry—millions of Gaussians on GPU (large scenes often want 8 GB+).
- Big files—hundreds of MB to multi-GB vs. a few MB of NeRF weights.
- Initialization sensitivity—weak SfM (e.g., textureless planes) yields holes.
- Artifacts—fast viewpoint changes can show “stained-glass snow.”
6. References
- Kerbl, B., Kopanas, G., Leimkühler, T., & Drettakis, G. (2023). 3D Gaussian Splatting for Real-Time Radiance Field Rendering. ACM TOG (SIGGRAPH).
- Zwicker, M., Pfister, H., van Baar, J., & Gross, M. (2001). Surface Splatting. SIGGRAPH.
- Luan, F., et al. (2024). GPS-Gaussian: Generalizable Pixel-wise 3D Gaussian Splatting for Real-time Human Novel View Synthesis.
- Niedermayr, S., et al. (2023). Compressed 3D Gaussian Splatting for Highly Accessible Novel View Synthesis.
- Chen, Z., et al. (2023). MCMC-GS: Multi-Scale 3D Gaussian Splatting for Large-Scale Scene Reconstruction.
II. Active vision—self-illumination
These methods project controlled illumination to aid measurement.
- Structured light
- Idea: project known patterns; measure warp on surfaces; infer depth.
- Icon: iPhone Face ID.
If SfM/stereo are “natural eyes,” structured light gives the system an active ruler—the core of high-precision 3D scanning, face auth, and industrial metrology.
A. Structured light
Definition: an active technique—project known patterns (dots, fringes, codewords) and observe geometric distortion on surfaces, then triangulate 3D coordinates.
Metaphor: shine a flashlight stencil on a bumpy wall at night—grids bend over bumps; the bend encodes height.
2. Core math: triangulation with deformation
Structured light is stereo with a projector instead of a second camera.
- Stereo: two rays to the same 3D point.
- Structured light: one projector ray + one camera ray.
Logic:
- Knowns: projector ray angles are calibrated; projector–camera baseline (B) is fixed.
- Matching: each projected feature has a unique code; the camera decodes which projector ray produced it.
- Solve: intersect projector and camera rays—law of sines / simple trig yields ((X,Y,Z)).
3. Encoding patterns
A. Spatial coding (Face ID class)
- One shot with dense speckle—fast, works on moving faces.
B. Temporal coding (industrial scanners)
- Many patterns (Gray codes + sinusoids)—µm class accuracy; subject must stay still.
C. Phase shifting
- Project sinusoidal gratings; recover height from phase shifts.
4. Deep dive: how iPhone Face ID works
Face ID is structured light miniaturized for consumers:
- Dot projector: > 30,000 IR dots on the face.
- IR camera: captures speckle warping over facial relief.
- Flood illuminator: aids IR imaging in the dark.
Why it resists photos: it compares 3D relief, not flat prints—prints don’t reproduce structured-light distortion faithfully.
5. Pros and cons
Pros:
- No scene texture needed—the projector supplies texture (beats stereo on white walls).
- High accuracy near-range—mm to µm indoors.
- Works in the dark with IR illumination.
Cons:
- Outdoor washout—sunlight swamps the pattern.
- Short range—limited projector power (phones, desktop scans).
- Material sensitivity—mirrors and deep blacks disrupt returns.
6. References
- Geng, J. (2011). Structured-light 3D surface imaging: a tutorial. Advances in Optics and Photonics.
- Scharstein, D., & Szeliski, R. (2003). High-accuracy stereo depth maps using structured light. CVPR.
- Salvi, J., et al. (2004). Pattern codification strategies in structured light systems. Pattern Recognition.
- Apple Inc. About Face ID advanced technology. Support Documentation.
- Zuo, C., et al. (2016). Micro-structured-light 3D surface profiling: A review. Measurement.
Time of flight (ToF)
Idea: emit IR pulses (or modulated light) and time the return.
Examples: automotive LiDAR, Kinect v2, rear depth sensors on phones.
If structured light uses geometric warp, ToF uses the speed of light—among the fastest, lowest-latency depth families for ADAS and mobile depth.
1. What is ToF?
Definition: measure round-trip time of light; with speed (c) known, range follows.
Metaphor: shout into a well and time the echo—sonar/radar use sound/radio; ToF uses NIR (~850–940 nm). At (c \approx 3\times10^8,\mathrm{m/s}), picosecond timing matters.
2. Core math: the speed-of-light formula
Two families: dToF and iToF.
A. dToF (direct ToF)—typical automotive LiDAR
Emit a short pulse; time-of-flight (\Delta t) directly.
- Range: (d = \dfrac{c \cdot \Delta t}{2})
- Hard part: 1 cm path ≈ 33 ps—SPAD arrays are common.
B. iToF (indirect)—Kinect v2 class
Continuous sinusoidal modulation; infer distance from phase shift between outgoing and incoming light.
- Cheaper, high-resolution sensors possible.
- Phase wraps and multipath need handling.
3. ToF workflow
- Emitter: modulated IR laser / pulse train.
- Reflection: diffuse return from scene.
- Sensor: specialized CMOS captures the signal.
- Processing:
- dToF: histogram peak time per pixel.
- iToF: demodulate to phase → depth.
- Output: depth map in metric units.
4. ToF vs. structured light
| Aspect | ToF | Structured light |
|---|---|---|
| Compute | Very low (hardware depth) | High (decode patterns) |
| Range | Far (LiDAR to hundreds of m) | Usually short (<~1 m phone class) |
| Robustness | Strong outdoors (esp. dToF) | Weak in bright sunlight |
| Resolution | Often modest (QVGA-class) | Can reach megapixels |
| Typical uses | Vacuums, AV, coarse AR geometry | Face unlock, metrology, liveness |
5. Bottlenecks
- Multipath: bounces confuse range—ghost depths.
- Flying pixels: mixed foreground/background at edges.
- Ambient light: sunlight raises noise (dToF mitigates with SPAD).
- Power: active illumination draws more than passive RGB.
6. References
- Hansard, M., Lee, S., Choi, O., & Horaud, R. P. (2012). Time-of-Flight Cameras: Principles, Methods and Applications. Springer Briefs.
- Li, L. (2014). Time-of-flight camera – An introduction. TI technical report.
- Horaud, R., et al. (2016). An overview of gradient-based 3D reconstruction methods for Time-of-Flight RGB-D cameras. JMIV.
- Bamji, C. S., et al. (2015). A 0.13μm CMOS SoC for a 512×424 ToF image sensor… ISSCC. (Kinect v2 hardware.)
- Niclass, C., et al. (2005). A CMOS single photon avalanche diode array for 3D imaging. ISSCC.
4. Application scenarios
3D reconstruction is everywhere:
- Industrial automation: dimensional inspection, defect scans, grasp planning.
- Autonomous systems & robotics: obstacle avoidance, SLAM mapping, HD maps.
- Cultural heritage: digitize buildings and artifacts.
- Medical: dental scans, surgical planning.
- Digital twins / metaverse: assets for games and VR.
- E-commerce: AR placement (e.g., furniture preview).
5. Open challenges
- Weak / repetitive texture: blank walls, glass—feature matching fails → holes.
- Specularity & transparency: metals and glass break assumptions.
- Compute vs. realtime: dense fusion is heavy for mobile/embedded targets.
- Occlusion: hidden regions need priors—often approximate.
- Lighting: too bright or too dark hurts passive feature pipelines.
Summary
3D reconstruction from machine vision is a “holy grail” problem: from classical multi-view geometry to deep implicit fields (NeRF) and explicit Gaussians (3DGS), we are moving from “pretty pictures” to faithful digital worlds. As compute grows and algorithms mature, capture may feel as effortless as pressing the shutter—yet remain precise.
References
Authoritative texts and papers cited at a glance:
- Hartley, R., & Zisserman, A. (2004). Multiple View Geometry in Computer Vision. CUP.
- Mildenhall, B., et al. (2020). NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. ECCV.
- Kerbl, B., et al. (2023). 3D Gaussian Splatting for Real-Time Radiance Field Rendering. ACM TOG.
- Schönberger, J. L., & Frahm, J. M. (2016). Structure-from-Motion Revisited. CVPR.
- Newcombe, R. A., et al. (2011). KinectFusion: Real-time 3D reconstruction and interaction using a moving depth camera. ISMAR.
Author note: If you want implementation detail (e.g., COLMAP setup or NeRF training), leave a comment—future posts can drill down!