从零到一:五分钟快速部署轻量化 AI 知识库模型(GTE + SeqGPT)
五分钟部署 RAG 双模型:GTE-Chinese-Large 做语义检索、SeqGPT-560m 做生成;含依赖安装、aria2 加速下载、Transformers 加载避坑与示例脚本。
0. 前言
在 AI 应用开发中,最经典的组合莫过于 RAG(检索增强生成)。本文将带你实战部署两个核心模型:
- GTE-Chinese-Large:目前语义向量(Embedding)领域的顶级模型,负责让 AI “理解”文档。
- SeqGPT-560m:超轻量化生成模型,负责“总结”和“对话”。
环境要求: PyTorch 2.x、Python 3.10+、建议有 GPU(CPU 也可跑)。
1. 环境准备:扫清依赖障碍
ModelScope 的 NLP 模型依赖较多,我们先一次性补齐所有可能缺失的底层库,避免“打地鼠”式的报错。
# 进入你的虚拟环境 (例如 torch29)
pip install modelscope -U
# 解决版本冲突的关键:datasets 必须限制在 3.0 以下,transformers 使用稳定版
pip install "datasets<3.0.0" "transformers>=4.40.0" -U
# 补齐 ModelScope 的隐藏依赖
pip install simplejson sortedcontainers oss2 addict pyyaml accelerate sentencepiece
2. 暴力加速:使用 aria2 快速获取权重
模型文件通常几百 MB 到几 GB,默认下载速度极慢。我们使用 aria2 开启 16 线程下载,将 30 分钟的等待缩短至 1 分钟。
2.1 安装 aria2
sudo apt-get update && sudo apt-get install aria2 -y
2.2 下载 GTE 向量模型 (约 620MB)
mkdir -p /root/.cache/modelscope/hub/models/iic/nlp_gte_sentence-embedding_chinese-large
cd /root/.cache/modelscope/hub/models/iic/nlp_gte_sentence-embedding_chinese-large
aria2c -s 16 -x 16 -k 1M -o pytorch_model.bin "https://www.modelscope.cn/api/v1/models/iic/nlp_gte_sentence-embedding_chinese-large/repo?Revision=master&FilePath=pytorch_model.bin"
2.3 下载 SeqGPT 生成模型 (约 1.04GB)
mkdir -p /root/.cache/modelscope/hub/models/iic/nlp_seqgpt-560m
cd /root/.cache/modelscope/hub/models/iic/nlp_seqgpt-560m
aria2c -s 16 -x 16 -k 1M -o pytorch_model.bin "https://www.modelscope.cn/api/v1/models/iic/nlp_seqgpt-560m/repo?Revision=master&FilePath=pytorch_model.bin"
注意: 下载完成后,记得回到你的工作目录
cd ~/workspace/your_project。
3. 模型部署:避开 is_decoder 报错
由于 ModelScope 内部代码与新版 Transformers 存在兼容性问题(常报 is_decoder 错误),我们推荐使用 Transformers 原生加载方式。
3.1 部署 GTE 语义搜索
完整代码
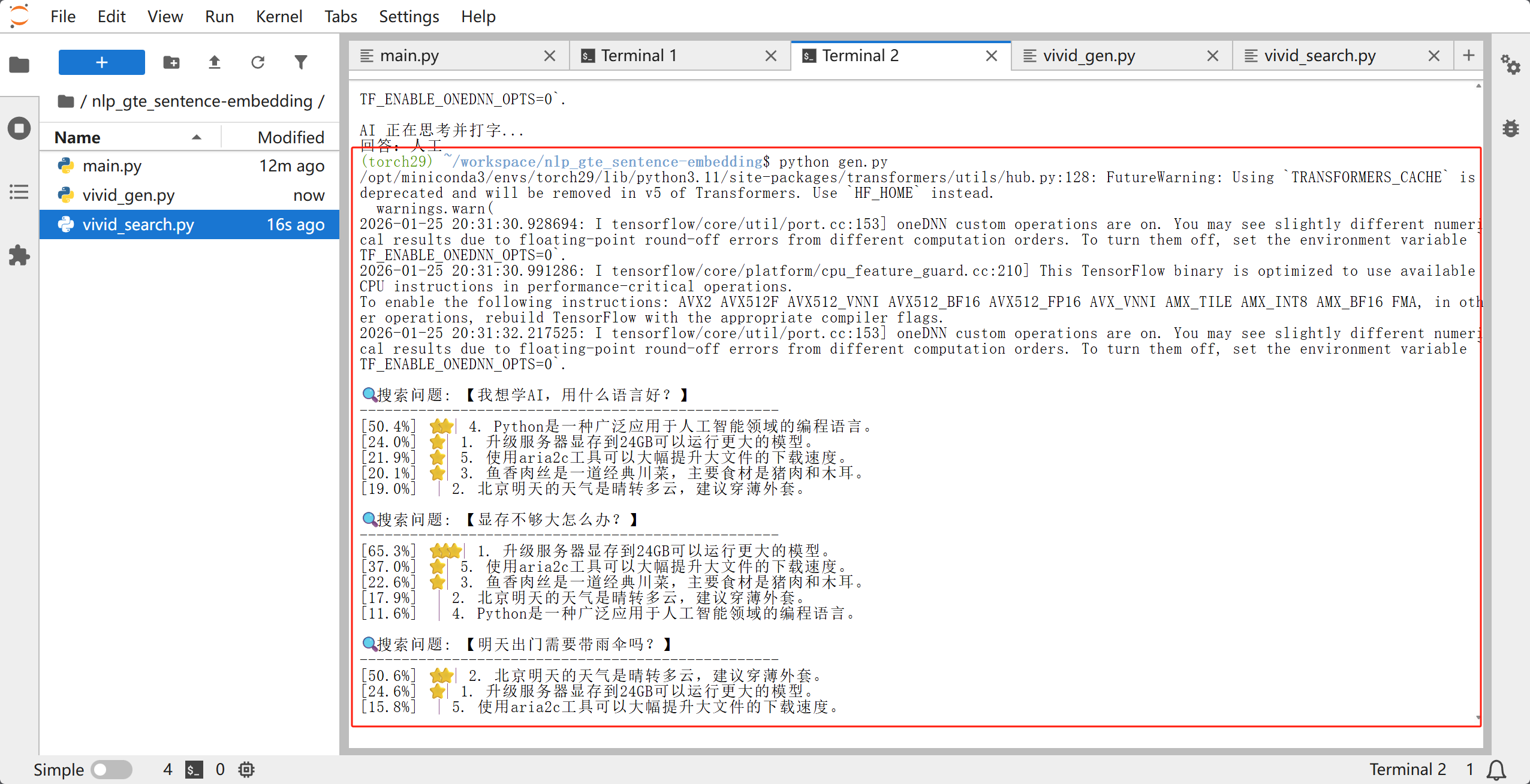
新建 search.py,这个脚本能实现“模糊语义搜索”,即问“显存不够”,它能找到“升级硬件”的资料。
import torch
import torch.nn.functional as F
from transformers import AutoTokenizer, AutoModel
model_path = "/root/.cache/modelscope/hub/models/iic/nlp_gte_sentence-embedding_chinese-large"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModel.from_pretrained(model_path)
def get_emb(text):
inputs = tokenizer(text, padding=True, truncation=True, return_tensors='pt', max_length=512)
with torch.no_grad():
out = model(**inputs)
return F.normalize(out.last_hidden_state[:, 0], p=2, dim=1)
# --- 模拟你的知识库 ---
knowledge_base = [
"1. 升级服务器显存到24GB可以运行更大的模型。",
"2. 北京明天的天气是晴转多云,建议穿薄外套。",
"3. 鱼香肉丝是一道经典川菜,主要食材是猪肉和木耳。",
"4. Python是一种广泛应用于人工智能领域的编程语言。",
"5. 使用aria2c工具可以大幅提升大文件的下载速度。"
]
# 计算库里所有资料的坐标(向量)
kb_embs = get_emb(knowledge_base)
def smart_search(user_query):
query_emb = get_emb([user_query])
# 计算相似度百分比
scores = (query_emb @ kb_embs.T) * 100
print(f"\n🔍 搜索问题: 【{user_query}】")
print("-" * 50)
# 将结果排序输出
results = sorted(zip(scores[0].tolist(), knowledge_base), reverse=True)
for score, text in results:
# 只显示相关度较高的
star = "⭐" * int(score/20) # 满分5颗星
print(f"[{score:.1f}%] {star} | {text}")
# --- 进行几次有趣的测试 ---
smart_search("我想学AI,用什么语言好?")
smart_search("显存不够大怎么办?")
smart_search("明天出门需要带雨伞吗?")
效果演示
3.2 部署 SeqGPT 文案助手
对于 560M 这样的小模型,Prompt(提示词)格式至关重要。
新建 gen.py:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_path = "/root/.cache/modelscope/hub/models/iic/nlp_seqgpt-560m"
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True).to('cpu')
def ask_ai(task, content):
# 强制使用【任务-输入-输出】结构
prompt = f"任务:{task}\n输入:{content}\n输出:"
inputs = tokenizer(prompt, return_tensors="pt")
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=64,
do_sample=True,
temperature=0.8,
repetition_penalty=1.2
)
full_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
return full_text.split("输出:")[-1].strip()
print(f"AI 回复:{ask_ai('给这段话写一个标题', '今天我们成功在服务器上部署了两个AI模型')}")
4. 常见坑点总结
- ModuleNotFoundError:
- 缺少
simplejson或sortedcontainers?直接pip install。 - 报错
cannot import name 'ALL_ALLOWED_EXTENSIONS'?是因为datasets版本太新,执行pip install "datasets<3.0.0"即可解决。
- 缺少
- 下载到一半卡住:
- 这是服务器单线程限速。立刻切换到
aria2c多线程下载,或者设置环境变量export MODELSCOPE_PARALLEL_DOWNLOAD_COUNT=16。
- 这是服务器单线程限速。立刻切换到
- 输出结果为空或重复:
- 检查
max_new_tokens是否设置。 - 检查 Prompt 格式,SeqGPT 这类小模型非常依赖特定的触发词(如“输出:”)。
- 检查
5. 结语
恭喜!你已经成功部署了语义搜索和文本生成两个基础模型。有了这两个“乐高积木”,你可以开始构建自己的企业级私有知识库客服了。
本文记录于 2026年1月25日 部署实战,环境 PyTorch 2.9,ModelScope 1.20+。
從零到一:五分鐘快速部署輕量化 AI 知識庫模型(GTE + SeqGPT)
五分鐘部署 RAG 雙模型:GTE-Chinese-Large 做語義檢索、SeqGPT-560m 做生成;含依賴安裝、aria2 加速下載、Transformers 加載避坑與示例腳本。
來源:https://blog.csdn.net/2403_87969572/article/details/157363741
抓取時間(ISO本地):2026-05-18 05:17:31
0. 前言
在 AI 應用開發中,最經典的組合莫過於 RAG(檢索增強生成)。本文將帶你實戰部署兩個核心模型:
- GTE-Chinese-Large:目前語義向量(Embedding)領域的頂級模型,負責讓 AI “理解”文件。
- SeqGPT-560m:超輕量化生成模型,負責“總結”和“對話”。
環境要求: PyTorch 2.x、Python 3.10+、建議有 GPU(CPU 也可跑)。
1. 環境準備:掃清依賴障礙
ModelScope 的 NLP 模型依賴較多,我們先一次性補齊所有可能缺失的底層庫,避免“打地鼠”式的報錯。
# 進入你的虛擬環境 (例如 torch29)
pip install modelscope -U
# 解決版本衝突的關鍵:datasets 必須限制在 3.0 以下,transformers 使用穩定版
pip install "datasets<3.0.0" "transformers>=4.40.0" -U
# 補齊 ModelScope 的隱藏依賴
pip install simplejson sortedcontainers oss2 addict pyyaml accelerate sentencepiece
2. 暴力加速:使用 aria2 快速獲取權重
模型檔案通常幾百 MB 到幾 GB,預設下載速度極慢。我們使用 aria2 開啟 16 執行緒下載,將 30 分鐘的等待縮短至 1 分鐘。
2.1 安裝 aria2
sudo apt-get update && sudo apt-get install aria2 -y
2.2 下載 GTE 向量模型 (約 620MB)
mkdir -p /root/.cache/modelscope/hub/models/iic/nlp_gte_sentence-embedding_chinese-large
cd /root/.cache/modelscope/hub/models/iic/nlp_gte_sentence-embedding_chinese-large
aria2c -s 16 -x 16 -k 1M -o pytorch_model.bin "https://www.modelscope.cn/api/v1/models/iic/nlp_gte_sentence-embedding_chinese-large/repo?Revision=master&FilePath=pytorch_model.bin"
2.3 下載 SeqGPT 生成模型 (約 1.04GB)
mkdir -p /root/.cache/modelscope/hub/models/iic/nlp_seqgpt-560m
cd /root/.cache/modelscope/hub/models/iic/nlp_seqgpt-560m
aria2c -s 16 -x 16 -k 1M -o pytorch_model.bin "https://www.modelscope.cn/api/v1/models/iic/nlp_seqgpt-560m/repo?Revision=master&FilePath=pytorch_model.bin"
注意: 下載完成後,記得回到你的工作目錄
cd ~/workspace/your_project。
3. 模型部署:避開 is_decoder 報錯
由於 ModelScope 內部程式碼與新版 Transformers 存在相容性問題(常報 is_decoder 錯誤),我們推薦使用 Transformers 原生載入方式。
3.1 部署 GTE 語義搜尋
完整程式碼
新建 search.py,這個指令碼能實現“模糊語義搜尋”,即問“視訊記憶體不夠”,它能找到“升級硬體”的資料。
import torch
import torch.nn.functional as F
from transformers import AutoTokenizer, AutoModel
model_path = "/root/.cache/modelscope/hub/models/iic/nlp_gte_sentence-embedding_chinese-large"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModel.from_pretrained(model_path)
def get_emb(text):
inputs = tokenizer(text, padding=True, truncation=True, return_tensors='pt', max_length=512)
with torch.no_grad():
out = model(**inputs)
return F.normalize(out.last_hidden_state[:, 0], p=2, dim=1)
# --- 模擬你的知識庫 ---
knowledge_base = [
"1. 升級伺服器視訊記憶體到24GB可以執行更大的模型。",
"2. 北京明天的天氣是晴轉多雲,建議穿薄外套。",
"3. 魚香肉絲是一道經典川菜,主要食材是豬肉和木耳。",
"4. Python是一種廣泛應用於人工智慧領域的程式語言。",
"5. 使用aria2c工具可以大幅提升大檔案的下載速度。"
]
# 計算庫裡所有資料的座標(向量)
kb_embs = get_emb(knowledge_base)
def smart_search(user_query):
query_emb = get_emb([user_query])
# 計算相似度百分比
scores = (query_emb @ kb_embs.T) * 100
print(f"\n🔍 搜尋問題: 【{user_query}】")
print("-" * 50)
# 將結果排序輸出
results = sorted(zip(scores[0].tolist(), knowledge_base), reverse=True)
for score, text in results:
# 只顯示相關度較高的
star = "⭐" * int(score/20) # 滿分5顆星
print(f"[{score:.1f}%] {star} | {text}")
# --- 進行幾次有趣的測試 ---
smart_search("我想學AI,用什麼語言好?")
smart_search("視訊記憶體不夠大怎麼辦?")
smart_search("明天出門需要帶雨傘嗎?")
效果演示
3.2 部署 SeqGPT 文案助手
對於 560M 這樣的小模型,Prompt(提示詞)格式至關重要。
新建 gen.py:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_path = "/root/.cache/modelscope/hub/models/iic/nlp_seqgpt-560m"
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True).to('cpu')
def ask_ai(task, content):
# 強制使用【任務-輸入-輸出】結構
prompt = f"任務:{task}\n輸入:{content}\n輸出:"
inputs = tokenizer(prompt, return_tensors="pt")
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=64,
do_sample=True,
temperature=0.8,
repetition_penalty=1.2
)
full_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
return full_text.split("輸出:")[-1].strip()
print(f"AI 回覆:{ask_ai('給這段話寫一個標題', '今天我們成功在伺服器上部署了兩個AI模型')}")
4. 常見坑點總結
- ModuleNotFoundError:
- 缺少
simplejson或sortedcontainers?直接pip install。 - 報錯
cannot import name 'ALL_ALLOWED_EXTENSIONS'?是因為datasets版本太新,執行pip install "datasets<3.0.0"即可解決。
- 缺少
- 下載到一半卡住:
- 這是伺服器單執行緒限速。立刻切換到
aria2c多執行緒下載,或者設定環境變數export MODELSCOPE_PARALLEL_DOWNLOAD_COUNT=16。
- 這是伺服器單執行緒限速。立刻切換到
- 輸出結果為空或重複:
- 檢查
max_new_tokens是否設定。 - 檢查 Prompt 格式,SeqGPT 這類小模型非常依賴特定的觸發詞(如“輸出:”)。
- 檢查
5. 結語
恭喜!你已經成功部署了語義搜尋和文字生成兩個基礎模型。有了這兩個“樂高積木”,你可以開始構建自己的企業級私有知識庫客服了。
本文記錄於 2026年1月25日 部署實戰,環境 PyTorch 2.9,ModelScope 1.20+。
From Zero to One: Deploy a Lightweight AI Knowledge-Base Stack in Five Minutes (GTE + SeqGPT)
ModelScope NLP models need many deps. Install once to avoid whack-a-mole errors: pip install modelscope -U
Captured at (local ISO): 2026-05-18 05:17:31
0. Preface
In AI app development, the classic combo is RAG (retrieval-augmented generation). This post walks through deploying two core models:
- GTE-Chinese-Large: A top-tier semantic embedding model—helps AI “understand” documents.
- SeqGPT-560m: An ultra-light generative model—for summarization and dialogue.
Requirements: PyTorch 2.x, Python 3.10+, GPU recommended (CPU works).
1. Environment: Clear Dependency Landmines
ModelScope NLP models need many deps. Install once to avoid whack-a-mole errors:
# Enter your venv (e.g. torch29)
pip install modelscope -U
# Key pin: datasets < 3.0, stable transformers
pip install "datasets<3.0.0" "transformers>=4.40.0" -U
# Hidden ModelScope deps
pip install simplejson sortedcontainers oss2 addict pyyaml accelerate sentencepiece
2. Fast Weights: aria2 Multi-Thread Download
Weights are hundreds of MB to GB; default downloads are slow. Use aria2 with 16 threads to cut ~30 minutes to ~1 minute.
2.1 Install aria2
sudo apt-get update && sudo apt-get install aria2 -y
2.2 Download GTE embedding model (~620 MB)
mkdir -p /root/.cache/modelscope/hub/models/iic/nlp_gte_sentence-embedding_chinese-large
cd /root/.cache/modelscope/hub/models/iic/nlp_gte_sentence-embedding_chinese-large
aria2c -s 16 -x 16 -k 1M -o pytorch_model.bin "https://www.modelscope.cn/api/v1/models/iic/nlp_gte_sentence-embedding_chinese-large/repo?Revision=master&FilePath=pytorch_model.bin"
2.3 Download SeqGPT generative model (~1.04 GB)
mkdir -p /root/.cache/modelscope/hub/models/iic/nlp_seqgpt-560m
cd /root/.cache/modelscope/hub/models/iic/nlp_seqgpt-560m
aria2c -s 16 -x 16 -k 1M -o pytorch_model.bin "https://www.modelscope.cn/api/v1/models/iic/nlp_seqgpt-560m/repo?Revision=master&FilePath=pytorch_model.bin"
Note: After download, return to your project dir:
cd ~/workspace/your_project.
3. Deployment: Avoid the is_decoder Error
ModelScope + newer Transformers often clash (is_decoder). Prefer native Transformers loading.
3.1 Deploy GTE semantic search
Full code
Create search.py for fuzzy semantic search—e.g. query “not enough VRAM” can match “upgrade hardware”.
import torch
import torch.nn.functional as F
from transformers import AutoTokenizer, AutoModel
model_path = "/root/.cache/modelscope/hub/models/iic/nlp_gte_sentence-embedding_chinese-large"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModel.from_pretrained(model_path)
def get_emb(text):
inputs = tokenizer(text, padding=True, truncation=True, return_tensors='pt', max_length=512)
with torch.no_grad():
out = model(**inputs)
return F.normalize(out.last_hidden_state[:, 0], p=2, dim=1)
# --- Mock knowledge base ---
knowledge_base = [
"1. Upgrading server VRAM to 24GB can run larger models.",
"2. Beijing tomorrow: sunny to cloudy; bring a light jacket.",
"3. Fish-flavored shredded pork is a classic Sichuan dish with pork and wood ear.",
"4. Python is widely used in AI.",
"5. aria2c can greatly speed up large file downloads."
]
# Embed all entries
kb_embs = get_emb(knowledge_base)
def smart_search(user_query):
query_emb = get_emb([user_query])
scores = (query_emb @ kb_embs.T) * 100
print(f"\n🔍 Query: 【{user_query}】")
print("-" * 50)
results = sorted(zip(scores[0].tolist(), knowledge_base), reverse=True)
for score, text in results:
star = "⭐" * int(score/20)
print(f"[{score:.1f}%] {star} | {text}")
smart_search("I want to learn AI, which language?")
smart_search("VRAM is too small, what to do?")
smart_search("Do I need an umbrella tomorrow?")
Demo
3.2 Deploy SeqGPT copy assistant
For a 560M model, prompt format matters.
Create gen.py:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_path = "/root/.cache/modelscope/hub/models/iic/nlp_seqgpt-560m"
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True).to('cpu')
def ask_ai(task, content):
prompt = f"任务:{task}\n输入:{content}\n输出:"
inputs = tokenizer(prompt, return_tensors="pt")
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=64,
do_sample=True,
temperature=0.8,
repetition_penalty=1.2
)
full_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
return full_text.split("输出:")[-1].strip()
print(f"AI reply: {ask_ai('给这段话写一个标题', '今天我们成功在服务器上部署了两个AI模型')}")
4. Common pitfalls
- ModuleNotFoundError:
- Missing
simplejsonorsortedcontainers?pip installthem. cannot import name 'ALL_ALLOWED_EXTENSIONS'?datasetstoo new—pip install "datasets<3.0.0".
- Missing
- Download stalls:
- Server throttling—switch to
aria2corexport MODELSCOPE_PARALLEL_DOWNLOAD_COUNT=16.
- Server throttling—switch to
- Empty or repetitive output:
- Set
max_new_tokens. - Match SeqGPT prompt pattern (e.g. ending with “输出:”).
- Set
5. Closing
You now have semantic search and text generation—two LEGO bricks for a private enterprise knowledge-base assistant.
Logged 2026-01-25, PyTorch 2.9, ModelScope 1.20+.