人工智能:Bert-Base-Chinese预训练模型部署手册
零基础部署 bert-base-chinese:安装 PyTorch/Transformers,运行完形填空、语义相似度与词向量三个示例,并总结客服、搜索、舆情等工业场景。
前言
这是一份针对 bert-base-chinese 模型的全流程部署教学文档。它将从环境准备、模型下载,到运行三个示例程序,带你完整走一遍 部署的全流程。

1. 准备工作 (Pre-requisites)
bert-base-chinese 是一个轻量级模型,不需要高端显卡。
- 硬件需求:最低 4GB 内存,普通笔记本 CPU 即可。
- 软件环境:Python 3.8 或更高版本。
第一步:安装核心依赖库
在你的终端(Command Prompt / Terminal)运行以下命令:
# 安装深度学习框架 PyTorch 和 模型库 Transformers
pip install torch transformers
# 如果下载慢,可以使用国内镜像源
pip install torch transformers -i https://pypi.tuna.tsinghua.edu.cn/simple
(如果是直接选择配置好Pytorch的镜像服务器 就可以直接跳过这一步)
2. 编写部署代码 (Core Scripts)
建议创建一个文件夹(如 bert_demo),在该文件夹下创建 main.py 并粘贴以下代码。
这份代码集成了三个功能:完型填空、语义相似度判断、特征维度观察。
import torch
from transformers import pipeline, BertTokenizer, BertModel
from torch.nn.functional import cosine_similarity
# --- 配置区 ---
MODEL_PATH = "google-bert/bert-base-chinese" # 会自动下载,若有离线包可改为路径
def demo_fill_mask():
"""示例 1:完型填空(展示语义理解)"""
print("\n--- [任务1: 完型填空] ---")
# 加载填空流水线
unmasker = pipeline('fill-mask', model=MODEL_PATH)
text = "中国境内最高的山峰是[MASK]。"
print(f"输入文本: {text}")
results = unmasker(text)
for i, res in enumerate(results[:3]):
print(f"候选词 {i+1}: {res['token_str']} (置信度: {res['score']:.4f})")
def demo_similarity():
"""示例 2:语义相似度(展示如何对比两个句子的意思)"""
print("\n--- [任务2: 语义相似度计算] ---")
tokenizer = BertTokenizer.from_pretrained(MODEL_PATH)
model = BertModel.from_pretrained(MODEL_PATH)
s1 = "我今天心情特别好"
s2 = "今天我感到很开心"
s3 = "明天下午要开会"
def get_vec(text):
inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True)
with torch.no_grad():
# 获取模型最后一层的输出,取第0个Token(CLS)作为全句特征
return model(**inputs).last_hidden_state[:, 0, :]
v1, v2, v3 = get_vec(s1), get_vec(s2), get_vec(s3)
sim_happy = cosine_similarity(v1, v2).item()
sim_unrelated = cosine_similarity(v1, v3).item()
print(f"句子A: '{s1}'")
print(f"句子B: '{s2}'")
print(f"句子C: '{s3}'")
print(f"A与B(意思相近)的相似度: {sim_happy:.4f}")
print(f"A与C(完全无关)的相似度: {sim_unrelated:.4f}")
def demo_features():
"""示例 3:特征提取(展示模型眼里的数学世界)"""
print("\n--- [任务3: 观察词向量特征] ---")
tokenizer = BertTokenizer.from_pretrained(MODEL_PATH)
model = BertModel.from_pretrained(MODEL_PATH)
word = "科技"
inputs = tokenizer(word, return_tensors="pt")
outputs = model(**inputs)
# BERT 默认将每个字转化为 768 维的浮点数组
vector = outputs.last_hidden_state[0][1] # 取“科”字的向量
print(f"词语: '{word}'")
print(f"向量长度: {len(vector)} 维")
print(f"前 5 位特征数值: {vector[:5].tolist()}")
if __name__ == "__main__":
print("正在启动 BERT 中文模型...")
try:
demo_fill_mask()
demo_similarity()
demo_features()
except Exception as e:
print(f"部署出错: {e}")
print("提示:如果遇到网络问题无法下载模型,请配置 HF_ENDPOINT 环境变量或检查网络。")
3. 运行与验证 (Execution)
- 在终端进入代码目录。
- 执行命令:
python main.py。 - 初次运行注意:
-
程序会自动从 Hugging Face 官方服务器下载约 400MB 的模型权重。需要稍微等待下
 * 下载完成后,你会看到终端依次打印出填空结果、相似度百分比和那一串长长的数学向量。
* 下载完成后,你会看到终端依次打印出填空结果、相似度百分比和那一串长长的数学向量。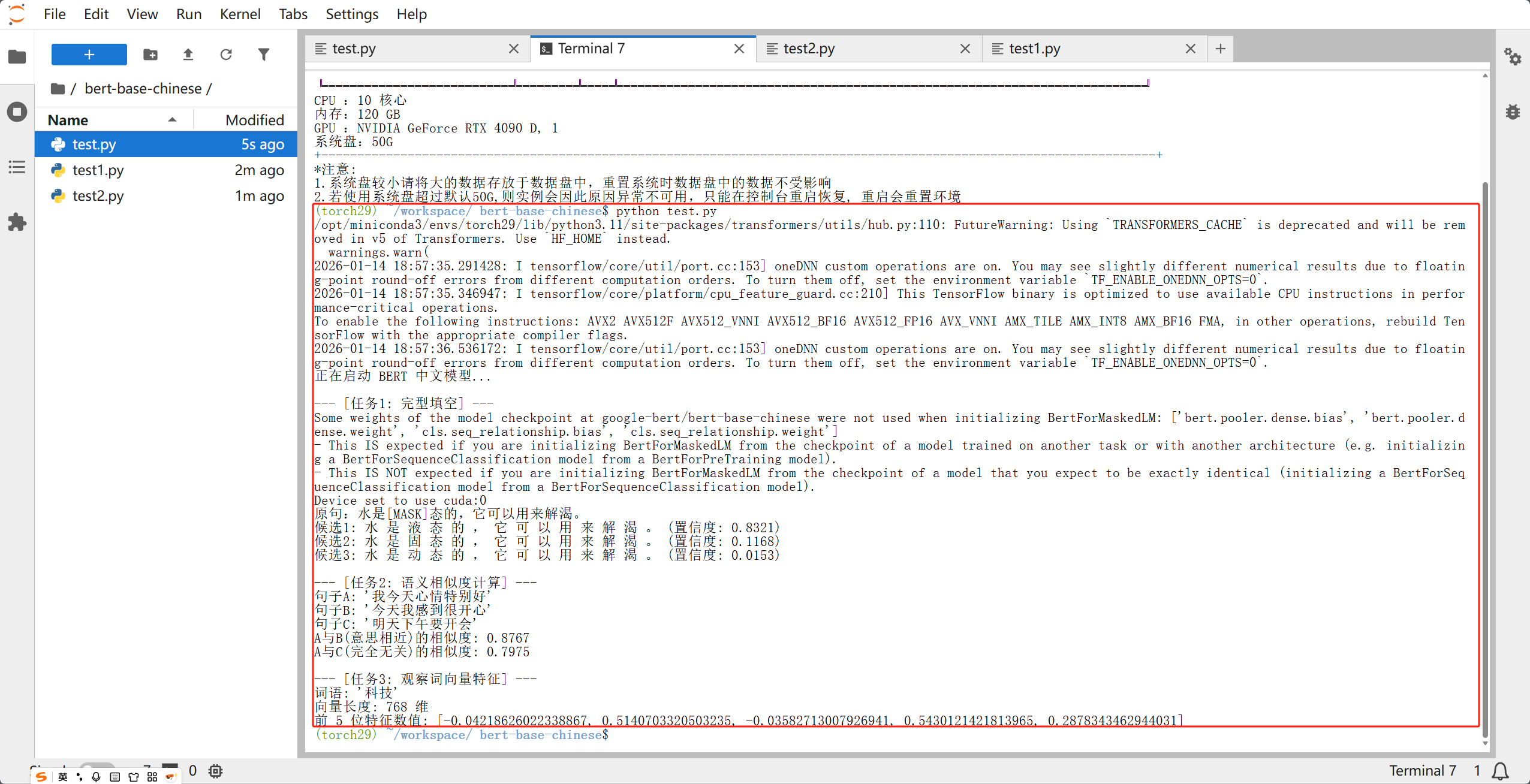
-
4. 常见问题排查 (Troubleshooting)
| 报错信息 | 原因 | 解决方法 |
|---|---|---|
Connection Error | 无法访问 Hugging Face 官网下载模型。 | 在运行前设置临时环境变量:export HF_ENDPOINT=https://hf-mirror.com (Windows 用 set) |
ModuleNotFoundError | 缺少必要的库。 | 重新运行 pip install transformers torch |
OutOfMemory (显存溢出) | 虽然 BERT 很小,但如果你的 GPU 太老。 | 在代码最开始强制使用 CPU:import os; os.environ["CUDA_VISIBLE_DEVICES"] = "-1" |
5. 模型应用:BERT 在行业中到底能做什么?
bert-base-chinese 不仅仅是一个“填空工具”,它在工业界扮演着**“中文语义理解引擎”**的角色。它是许多高级 AI 应用的底层核心(Backbone),具体应用场景包括:
① 智能客服与意图识别 (Intent Classification)
- 场景:当你在银行 App 询问“我的卡怎么刷不了了?”
- 作用:BERT 能理解这句话背后的意图是“信用卡异常”,而不是“刷子”或“卡片”的物理动作。它能将非规范的用户语言精准匹配到对应的业务功能。
② 搜索增强与推荐系统 (Semantic Search)
- 场景:在电商或内容平台搜索“适合冬天的运动鞋”。
- 作用:传统的搜索是“关键词匹配”。BERT 则是“语义匹配”,它能理解“保暖”、“防滑”与“冬天”的关联,即便标题里没有“冬天”两个字,也能把相关的商品排在前面。
③ 舆情分析与情感监测 (Sentiment Analysis)
- 场景:品牌方监控微博、小红书上的用户评价。
- 作用:BERT 可以自动识别评论是“好评”、“差评”还是“反讽”。由于它能理解上下文,对于“这就是你们的服务啊?”这种带讽刺意味的句子,其识别准确率远高于传统算法。
④ 金融与法律文档合规审查 (NER)
- 场景:从几千份合同中提取“公司名”、“金额”、“到期时间”。
- 作用:通过命名实体识别(NER)技术,BERT 能像人一样读懂合同文本,自动提取关键信息,极大地减少人工审核的工作量。
⑤ 文本内容风控 (Content Moderation)
- 场景:社交平台自动拦截违规言论。
- 作用:识别变体字、谐音梗或隐晦的违规信息。BERT 对长句子的双向理解能力,使其在识别“有毒”内容时比关键词过滤更加智能、难以规避。
总结:为什么它是“必学”模型?
在 NLP 行业中,bert-base-chinese 相当于数学里的“九九乘法表”。
- 高性价比:它虽然不如 GPT-4 那么“全能”,但在特定的分类任务上,经过微调(Fine-tuning)后的效果往往能媲美大模型,且推理成本仅为后者的千分之一。
- 易于部署:如你所见,单 CPU 即可运行,这使得它非常适合部署在手机端、边缘计算设备或高并发的生产环境后台。
人工智慧:Bert-Base-Chinese預訓練模型部署手冊
零基礎部署 bert-base-chinese:安裝 PyTorch/Transformers,執行完形填空、語義相似度與詞向量三個範例,並總結客服、搜尋、輿情等工業場景。
來源:https://blog.csdn.net/2403_87969572/article/details/156951218
抓取時間(ISO本地):2026-05-18 05:17:32
前言
這是一份針對 bert-base-chinese 模型的全流程部署教學文件。它將從環境準備、模型下載,到執行三個示例程式,帶你完整走一遍 部署的全流程。
1. 準備工作 (Pre-requisites)
bert-base-chinese 是一個輕量級模型,不需要高階顯示卡。
- 硬體需求:最低 4GB 記憶體,普通筆記本 CPU 即可。
- 軟體環境:Python 3.8 或更高版本。
第一步:安裝核心依賴庫
在你的終端(Command Prompt / Terminal)執行以下命令:
# 安裝深度學習框架 PyTorch 和 模型庫 Transformers
pip install torch transformers
# 如果下載慢,可以使用國內映象源
pip install torch transformers -i https://pypi.tuna.tsinghua.edu.cn/simple
(如果是直接選擇配置好Pytorch的映象伺服器 就可以直接跳過這一步)
2. 編寫部署程式碼 (Core Scripts)
建議建立一個資料夾(如 bert_demo),在該資料夾下建立 main.py 並貼上以下程式碼。
這份程式碼整合了三個功能:完型填空、語義相似度判斷、特徵維度觀察。
import torch
from transformers import pipeline, BertTokenizer, BertModel
from torch.nn.functional import cosine_similarity
# --- 配置區 ---
MODEL_PATH = "google-bert/bert-base-chinese" # 會自動下載,若有離線包可改為路徑
def demo_fill_mask():
"""示例 1:完型填空(展示語義理解)"""
print("\n--- [任務1: 完型填空] ---")
# 載入填空流水線
unmasker = pipeline('fill-mask', model=MODEL_PATH)
text = "中國境內最高的山峰是[MASK]。"
print(f"輸入文字: {text}")
results = unmasker(text)
for i, res in enumerate(results[:3]):
print(f"候選詞 {i+1}: {res['token_str']} (置信度: {res['score']:.4f})")
def demo_similarity():
"""示例 2:語義相似度(展示如何對比兩個句子的意思)"""
print("\n--- [任務2: 語義相似度計算] ---")
tokenizer = BertTokenizer.from_pretrained(MODEL_PATH)
model = BertModel.from_pretrained(MODEL_PATH)
s1 = "我今天心情特別好"
s2 = "今天我感到很開心"
s3 = "明天下午要開會"
def get_vec(text):
inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True)
with torch.no_grad():
# 獲取模型最後一層的輸出,取第0個Token(CLS)作為全句特徵
return model(**inputs).last_hidden_state[:, 0, :]
v1, v2, v3 = get_vec(s1), get_vec(s2), get_vec(s3)
sim_happy = cosine_similarity(v1, v2).item()
sim_unrelated = cosine_similarity(v1, v3).item()
print(f"句子A: '{s1}'")
print(f"句子B: '{s2}'")
print(f"句子C: '{s3}'")
print(f"A與B(意思相近)的相似度: {sim_happy:.4f}")
print(f"A與C(完全無關)的相似度: {sim_unrelated:.4f}")
def demo_features():
"""示例 3:特徵提取(展示模型眼裡的數學世界)"""
print("\n--- [任務3: 觀察詞向量特徵] ---")
tokenizer = BertTokenizer.from_pretrained(MODEL_PATH)
model = BertModel.from_pretrained(MODEL_PATH)
word = "科技"
inputs = tokenizer(word, return_tensors="pt")
outputs = model(**inputs)
# BERT 預設將每個字轉化為 768 維的浮點陣列
vector = outputs.last_hidden_state[0][1] # 取“科”字的向量
print(f"詞語: '{word}'")
print(f"向量長度: {len(vector)} 維")
print(f"前 5 位特徵數值: {vector[:5].tolist()}")
if __name__ == "__main__":
print("正在啟動 BERT 中文模型...")
try:
demo_fill_mask()
demo_similarity()
demo_features()
except Exception as e:
print(f"部署出錯: {e}")
print("提示:如果遇到網路問題無法下載模型,請配置 HF_ENDPOINT 環境變數或檢查網路。")
3. 執行與驗證 (Execution)
- 在終端進入程式碼目錄。
- 執行命令:
python main.py。 - 初次執行注意:
-
程式會自動從 Hugging Face 官方伺服器下載約 400MB 的模型權重。需要稍微等待下
* 下載完成後,你會看到終端依次列印出填空結果、相似度百分比和那一串長長的數學向量。
-
4. 常見問題排查 (Troubleshooting)
| 報錯資訊 | 原因 | 解決方法 |
|---|---|---|
Connection Error | 無法訪問 Hugging Face 官網下載模型。 | 在執行前設定臨時環境變數:export HF_ENDPOINT=https://hf-mirror.com (Windows 用 set) |
ModuleNotFoundError | 缺少必要的庫。 | 重新執行 pip install transformers torch |
OutOfMemory (視訊記憶體溢位) | 雖然 BERT 很小,但如果你的 GPU 太老。 | 在程式碼最開始強制使用 CPU:import os; os.environ["CUDA_VISIBLE_DEVICES"] = "-1" |
5. 模型應用:BERT 在行業中到底能做什麼?
bert-base-chinese 不僅僅是一個“填空工具”,它在工業界扮演著**“中文語義理解引擎”**的角色。它是許多高階 AI 應用的底層核心(Backbone),具體應用場景包括:
① 智慧客服與意圖識別 (Intent Classification)
- 場景:當你在銀行 App 詢問“我的卡怎麼刷不了了?”
- 作用:BERT 能理解這句話背後的意圖是“信用卡異常”,而不是“刷子”或“卡片”的物理動作。它能將非規範的使用者語言精準匹配到對應的業務功能。
② 搜尋增強與推薦系統 (Semantic Search)
- 場景:在電商或內容平臺搜尋“適合冬天的運動鞋”。
- 作用:傳統的搜尋是“關鍵詞匹配”。BERT 則是“語義匹配”,它能理解“保暖”、“防滑”與“冬天”的關聯,即便標題裡沒有“冬天”兩個字,也能把相關的商品排在前面。
③ 輿情分析與情感監測 (Sentiment Analysis)
- 場景:品牌方監控微博、小紅書上的使用者評價。
- 作用:BERT 可以自動識別評論是“好評”、“差評”還是“反諷”。由於它能理解上下文,對於“這就是你們的服務啊?”這種帶諷刺意味的句子,其識別準確率遠高於傳統演算法。
④ 金融與法律文件合規審查 (NER)
- 場景:從幾千份合同中提取“公司名”、“金額”、“到期時間”。
- 作用:透過命名實體識別(NER)技術,BERT 能像人一樣讀懂合同文字,自動提取關鍵資訊,極大地減少人工稽核的工作量。
⑤ 文字內容風控 (Content Moderation)
- 場景:社交平臺自動攔截違規言論。
- 作用:識別變體字、諧音梗或隱晦的違規資訊。BERT 對長句子的雙向理解能力,使其在識別“有毒”內容時比關鍵詞過濾更加智慧、難以規避。
總結:為什麼它是“必學”模型?
在 NLP 行業中,bert-base-chinese 相當於數學裡的“九九乘法表”。
- 高價效比:它雖然不如 GPT-4 那麼“全能”,但在特定的分類任務上,經過微調(Fine-tuning)後的效果往往能媲美大模型,且推理成本僅為後者的千分之一。
- 易於部署:如你所見,單 CPU 即可執行,這使得它非常適合部署在手機端、邊緣計算裝置或高併發的生產環境後臺。
AI: Bert-Base-Chinese Pretrained Model Deployment Handbook
Deploy bert-base-chinese with PyTorch/Transformers: fill-mask, similarity, and embedding demos plus industry use cases from search to moderation.
Captured at (local ISO): 2026-05-18 05:17:32
Preface
This is an end-to-end deployment guide for bert-base-chinese: environment setup, model download, and three runnable demos walk you through the full pipeline.
1. Prerequisites
bert-base-chinese is light—no high-end GPU required.
- Hardware: ≥ 4 GB RAM; a normal laptop CPU is fine.
- Software: Python 3.8+.
Step 1: Install core libraries
In your terminal (CMD / Terminal):
# 安装深度学习框架 PyTorch 和 模型库 Transformers
pip install torch transformers
# 如果下载慢,可以使用国内镜像源
pip install torch transformers -i https://pypi.tuna.tsinghua.edu.cn/simple
(如果是直接选择配置好Pytorch的镜像服务器 就可以直接跳过这一步)
2. Core deployment code (main.py)
Create a folder (e.g., bert_demo), add main.py, and paste:
This script bundles three demos: fill-mask, semantic similarity, and feature inspection.
import torch
from transformers import pipeline, BertTokenizer, BertModel
from torch.nn.functional import cosine_similarity
# --- 配置区 ---
MODEL_PATH = "google-bert/bert-base-chinese" # 会自动下载,若有离线包可改为路径
def demo_fill_mask():
"""示例 1:完型填空(展示语义理解)"""
print("\n--- [任务1: 完型填空] ---")
# 加载填空流水线
unmasker = pipeline('fill-mask', model=MODEL_PATH)
text = "中国境内最高的山峰是[MASK]。"
print(f"输入文本: {text}")
results = unmasker(text)
for i, res in enumerate(results[:3]):
print(f"候选词 {i+1}: {res['token_str']} (置信度: {res['score']:.4f})")
def demo_similarity():
"""示例 2:语义相似度(展示如何对比两个句子的意思)"""
print("\n--- [任务2: 语义相似度计算] ---")
tokenizer = BertTokenizer.from_pretrained(MODEL_PATH)
model = BertModel.from_pretrained(MODEL_PATH)
s1 = "我今天心情特别好"
s2 = "今天我感到很开心"
s3 = "明天下午要开会"
def get_vec(text):
inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True)
with torch.no_grad():
# 获取模型最后一层的输出,取第0个Token(CLS)作为全句特征
return model(**inputs).last_hidden_state[:, 0, :]
v1, v2, v3 = get_vec(s1), get_vec(s2), get_vec(s3)
sim_happy = cosine_similarity(v1, v2).item()
sim_unrelated = cosine_similarity(v1, v3).item()
print(f"句子A: '{s1}'")
print(f"句子B: '{s2}'")
print(f"句子C: '{s3}'")
print(f"A与B(意思相近)的相似度: {sim_happy:.4f}")
print(f"A与C(完全无关)的相似度: {sim_unrelated:.4f}")
def demo_features():
"""示例 3:特征提取(展示模型眼里的数学世界)"""
print("\n--- [任务3: 观察词向量特征] ---")
tokenizer = BertTokenizer.from_pretrained(MODEL_PATH)
model = BertModel.from_pretrained(MODEL_PATH)
word = "科技"
inputs = tokenizer(word, return_tensors="pt")
outputs = model(**inputs)
# BERT 默认将每个字转化为 768 维的浮点数组
vector = outputs.last_hidden_state[0][1] # 取“科”字的向量
print(f"词语: '{word}'")
print(f"向量长度: {len(vector)} 维")
print(f"前 5 位特征数值: {vector[:5].tolist()}")
if __name__ == "__main__":
print("正在启动 BERT 中文模型...")
try:
demo_fill_mask()
demo_similarity()
demo_features()
except Exception as e:
print(f"部署出错: {e}")
print("提示:如果遇到网络问题无法下载模型,请配置 HF_ENDPOINT 环境变量或检查网络。")
3. Run and verify
-
cdinto the project folder. -
Run:
python main.py. -
First run: weights (~400 MB) download from Hugging Face—wait a bit.
* After download you should see fill-mask candidates, similarity scores, and a long numeric vector.
4. Troubleshooting
| Symptom | Cause | Fix |
|---|---|---|
Connection Error | Cannot reach Hugging Face. | Set HF_ENDPOINT=https://hf-mirror.com before run (export on Unix, set on Windows). |
ModuleNotFoundError | Missing deps. | pip install transformers torch |
OutOfMemory | Rare on CPU/GPU combo issues. | Force CPU: import os; os.environ["CUDA_VISIBLE_DEVICES"] = "-1" at the top. |
5. Where BERT is used in industry
bert-base-chinese is not just a “cloze toy”—it often acts as a Chinese semantic backbone for higher-level apps:
① Customer support & intent
- Scenario: “My card won’t swipe anymore” in a banking app.
- Role: Maps messy user language to card/transaction issues, not literal “brushes” or physical cards.
② Search & recommendations
- Scenario: Query “winter running shoes.”
- Role: Goes beyond keyword overlap to semantics—“warm,” “grip,” and “winter” align even if “winter” is missing in titles.
③ Sentiment & public opinion
- Scenario: Brand monitoring on Weibo / Xiaohongshu.
- Role: Spots praise, complaint, irony—“This is your service?” reads differently with context.
④ Finance / legal NER
- Scenario: Thousands of contracts—company names, amounts, maturity dates.
- Role: Named-entity extraction to cut manual review.
⑤ Content moderation
- Scenario: Block policy-violating posts.
- Role: Homoglyphs, puns, implicit toxicity—harder to game than keyword filters.
Why learn this model?
In NLP, bert-base-chinese is like multiplication tables in math.
- Cost/perf: Not “GPT-4 general,” but after fine-tuning it often matches big models on classification—at ~1/1000 inference cost.
- Deployability: Runs on CPU—fits phones, edge, and high-QPS backends.