GLM-4V-9B 视觉多模态模型本地部署教程【保姆级教程】
教程在已具备 PyTorch/CUDA 的 Linux 上部署 GLM-4V-9B:列出依赖与 ModelScope 下载、给出与源码一致的 inference 推理脚本(含 BF16、apply_chat_template),并简述 4-bit 量化与 vLLM OpenAI 式服务。
1. 前言
GLM-4V-9B 是智谱 AI 推出的最新一代开源视觉多模态模型,具备强大的图像理解、对话及推理能力。相比于云端 API,本地部署能更好地保护数据隐私,并显著降低长期使用的成本。
本教程将指导你如何在已安装 PyTorch 的 Linux 服务器上,快速完成 GLM-4V-9B 的部署与推理。
2. 环境准备
在开始之前,请确保你的服务器满足以下基础条件:
- 操作系统: Ubuntu 20.04+ (推荐)
- 显存:
- FP16 模式:至少 24GB(如 RTX 3090/4090, A10/A100)
- Int4 量化模式:至少 12GB(如 RTX 3060/4070)
- 已安装: Python 3.10+, CUDA 11.8+, PyTorch 2.0+
2.1 安装必要依赖
如果你已经安装了 PyTorch,可以进入该步骤安装额外的库来处理图像和复杂的 Tokenizer:
pip install transformers>=4.45.0 accelerate tiktoken einops scipy pillow
# 强烈建议安装 flash-attn 以获得更快的推理速度(需支持 CUDA 11.6+)
pip install flash-attn --no-build-isolation
3. 模型下载
由于模型权重文件较大(约 18GB),国内用户推荐使用 ModelScope(魔搭社区),下载速度通常比 Hugging Face 快得多。
pip install modelscope
# 下载模型到当前目录下的 glm-4v-9b 文件夹
modelscope download --model ZhipuAI/glm-4v-9b --local_dir ./glm-4v-9b
推荐用多线程脚本加速
from modelscope import snapshot_download
model_id = 'ZhipuAI/glm-4v-9b'
# local_dir 为你想要存放模型的路径
local_dir = './glm-4v-9b'
# snapshot_download 默认支持多线程
# 增加 max_workers 参数(视你的服务器带宽而定,建议设置 4-8)
snapshot_download(
model_id,
local_dir=local_dir,
cache_dir='./cache', # 临时缓存目录
max_workers=16 # 开启8个线程同时下载
)
4. 核心部署代码
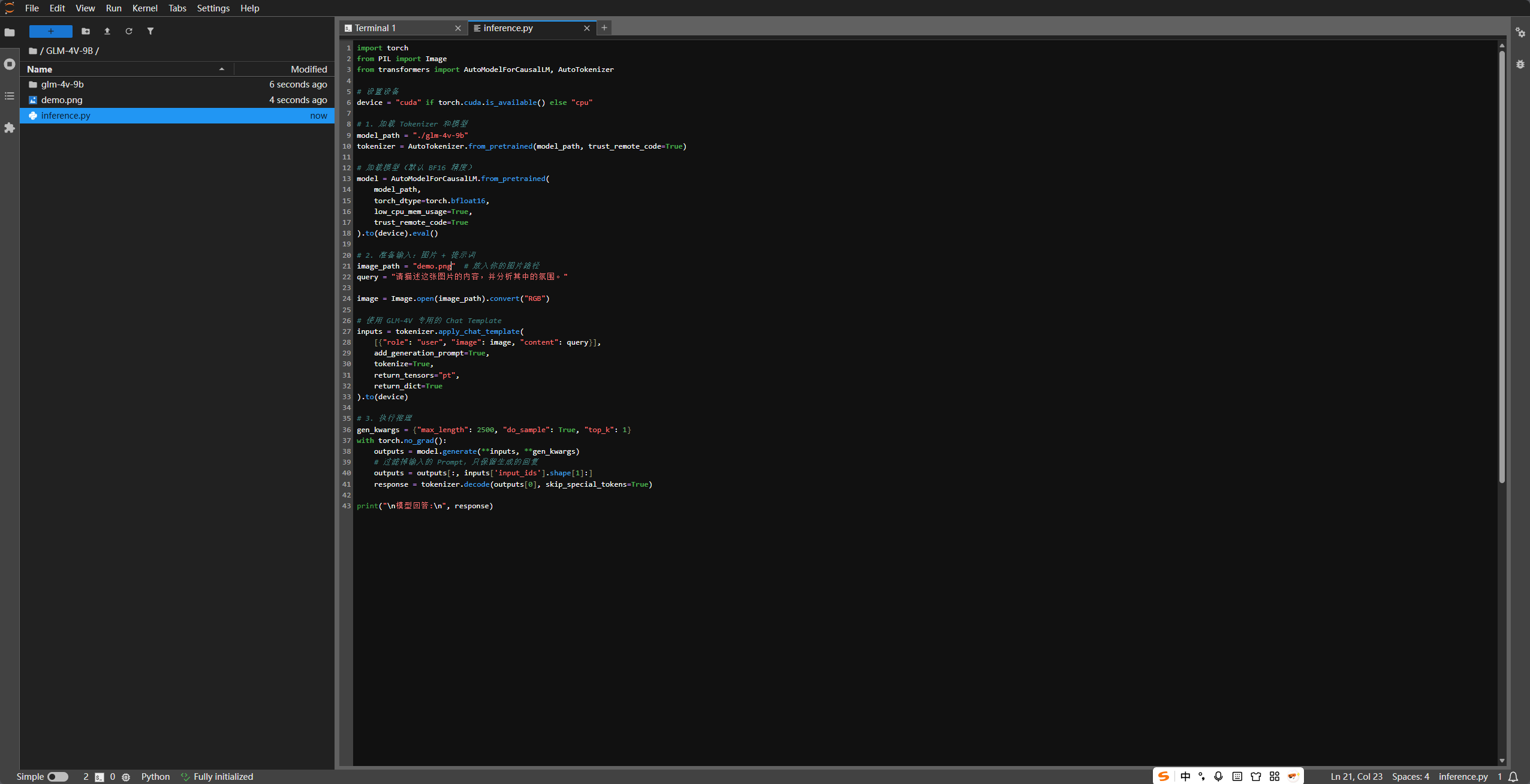
创建一个 inference.py 文件,填入以下代码。该脚本支持加载本地权重并进行一次图文对话。
import os
import warnings
import torch
# 1. 屏蔽环境变量日志 (必须在 import transformers 之前执行)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # 屏蔽 TensorFlow 日志
os.environ['TRANSFORMERS_VERBOSITY'] = 'error' # 屏蔽 Transformers 自带的大部分警告
os.environ['HF_HUB_DISABLE_SYMLINKS_WARNING'] = '1' # 屏蔽 HF 软连接警告
# 2. 屏蔽 Python 警告
warnings.filterwarnings("ignore", category=FutureWarning)
warnings.filterwarnings("ignore", category=UserWarning)
# 3. 此时再导入剩下的库
from PIL import Image
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
# 4. 屏蔽 transformers 内部库的输出
transformers.logging.set_verbosity_error()
def run_inference():
model_path = "./glm-4v-9b"
# 1. 加载分词器
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
# 2. 加载模型
print("[1/3] 正在加载模型至显存 (BF16)...")
model = AutoModelForCausalLM.from_pretrained(
model_path,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto"
).eval()
# 兼容性小补丁
if not hasattr(model.config, "num_hidden_layers"):
model.config.num_hidden_layers = model.config.num_layers
# 3. 准备输入
image_path = "demo.jpg"
query = "请详细描述这张图片。"
try:
image = Image.open(image_path).convert("RGB")
except Exception:
print(f"错误:无法找到图片 {image_path}")
return
inputs = tokenizer.apply_chat_template(
[{"role": "user", "image": image, "content": query}],
add_generation_prompt=True,
tokenize=True,
return_tensors="pt",
return_dict=True
).to("cuda")
# 4. 执行推理
print("[2/3] 模型正在思考...")
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=512,
do_sample=False,
use_cache=True,
eos_token_id=tokenizer.eos_token_id
)
response_ids = outputs[0][len(inputs['input_ids'][0]):]
response = tokenizer.decode(response_ids, skip_special_tokens=True)
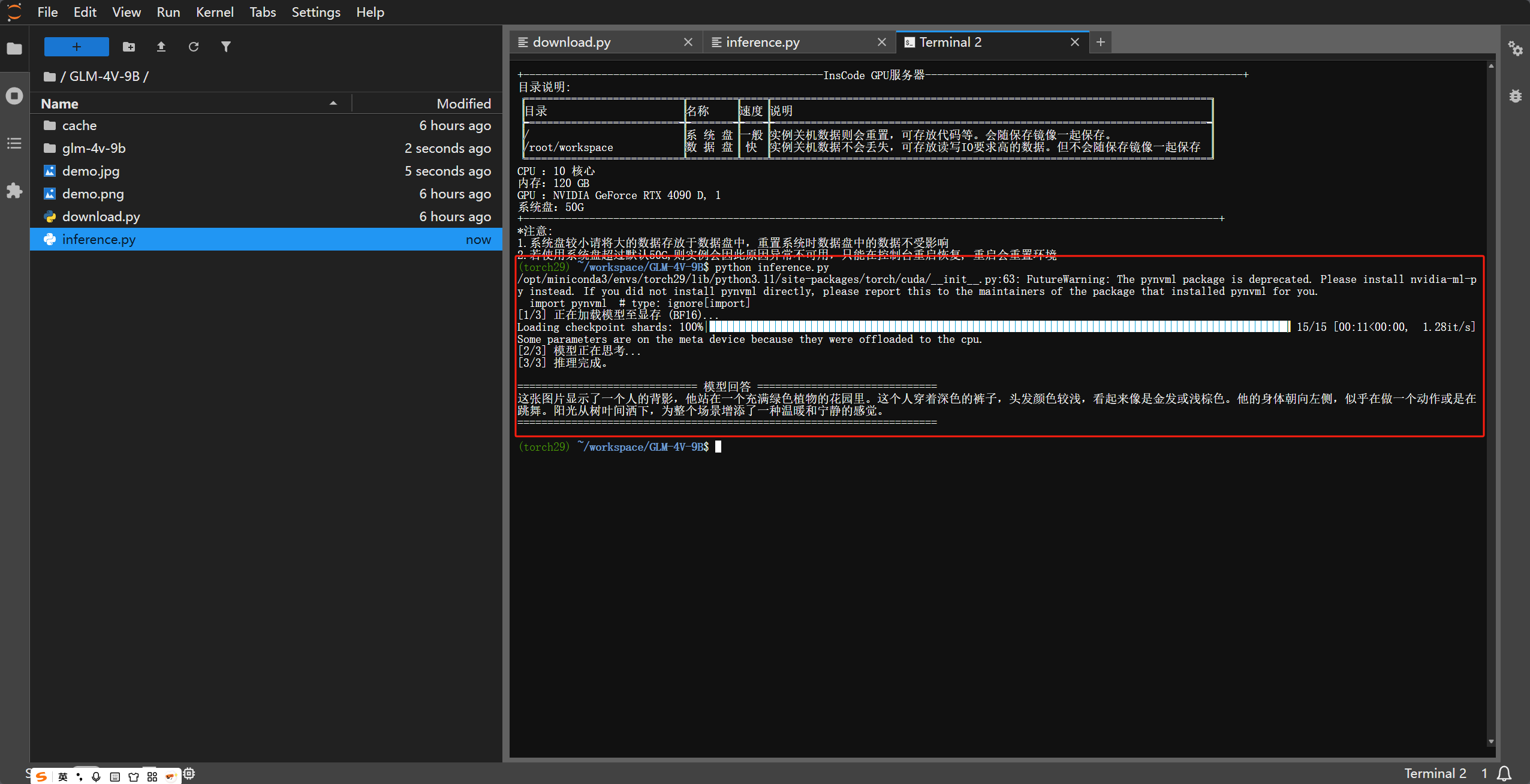
print("[3/3] 推理完成。")
print("\n" + "="*30 + " 模型回答 " + "="*30)
print(response)
print("="*70 + "\n")
if __name__ == "__main__":
run_inference()
5. 效果演示
6. 进阶配置:针对不同场景的优化
方案 A:显存不足?使用 4-bit 量化
如果你的显存小于 20GB,可以通过 bitsandbytes 开启 4-bit 量化加载,显存占用将降至约 9-11GB。
首先安装:pip install bitsandbytes
修改模型加载部分:
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
load_in_4bit=True, # 开启 4bit 量化
device_map="auto" # 自动分配显存
)
方案 B:高并发推理?使用 vLLM 部署
如果你希望将模型作为 API 服务提供给前端使用,推荐使用 vLLM 框架,它的吞吐量比原生 Transformers 高出数倍。
pip install vllm
# 启动兼容 OpenAI 接口的服务
python -m vllm.entrypoints.openai.api_server \
--model ./glm-4v-9b \
--trust-remote-code \
--gpu-memory-utilization 0.9 \
--max-model-len 4096 \
--port 8000
部署后,你可以直接使用 OpenAI 的 SDK 调用它。
7. 常见坑点排查(FAQ)
- 报错
AttributeError: 'ChatGLMTokenizer' object has no attribute 'apply_chat_template'- 解决: 请确保
transformers版本大于 4.44.0。如果版本正确仍报错,检查tokenizer_config.json是否在模型目录中。
- 解决: 请确保
- 显存溢出 (OOM)
- 解决: 减小
max_length;或者使用上文提到的 4-bit 量化方案。
- 解决: 减小
- 图片识别效果差
- 解决: 检查图片读取时是否转换为了
.convert("RGB"),GLM-4V 对灰度图或带 Alpha 通道的图可能不兼容。
- 解决: 检查图片读取时是否转换为了
8. 结语
GLM-4V-9B 展现了极强的图文理解能力,通过本地部署,你可以将其集成到自动化办公、智能安检、医疗影像辅助等多种私有化场景中。如果你在部署过程中遇到问题,欢迎在评论区交流!
GLM-4V-9B 視覺多模態模型本地部署教程【保姆級教程】
教程在已具備 PyTorch/CUDA 的 Linux 上部署 GLM-4V-9B:列出依賴與 ModelScope 下載、給出與源碼一致的 inference 推理腳本(含 BF16、apply_chat_template),並簡述 4-bit 量化與 vLLM OpenAI 式服務。
來源:https://blog.csdn.net/2403_87969572/article/details/156802580
抓取時間(ISO本地):2026-05-18 05:17:26
文章目錄
1. 前言
GLM-4V-9B 是智譜 AI 推出的最新一代開源視覺多模態模型,具備強大的影象理解、對話及推理能力。相比於雲端 API,本地部署能更好地保護資料隱私,並顯著降低長期使用的成本。
本教程將指導你如何在已安裝 PyTorch 的 Linux 伺服器上,快速完成 GLM-4V-9B 的部署與推理。
2. 環境準備
在開始之前,請確保你的伺服器滿足以下基礎條件:
- 作業系統: Ubuntu 20.04+ (推薦)
- 視訊記憶體:
- FP16 模式:至少 24GB(如 RTX 3090/4090, A10/A100)
- Int4 量化模式:至少 12GB(如 RTX 3060/4070)
- 已安裝: Python 3.10+, CUDA 11.8+, PyTorch 2.0+
2.1 安裝必要依賴
如果你已經安裝了 PyTorch,可以進入該步驟安裝額外的庫來處理影象和複雜的 Tokenizer:
pip install transformers>=4.45.0 accelerate tiktoken einops scipy pillow
# 強烈建議安裝 flash-attn 以獲得更快的推理速度(需支援 CUDA 11.6+)
pip install flash-attn --no-build-isolation
3. 模型下載
由於模型權重檔案較大(約 18GB),國內使用者推薦使用 ModelScope(魔搭社群),下載速度通常比 Hugging Face 快得多。
pip install modelscope
# 下載模型到當前目錄下的 glm-4v-9b 資料夾
modelscope download --model ZhipuAI/glm-4v-9b --local_dir ./glm-4v-9b
推薦用多執行緒指令碼加速
from modelscope import snapshot_download
model_id = 'ZhipuAI/glm-4v-9b'
# local_dir 為你想要存放模型的路徑
local_dir = './glm-4v-9b'
# snapshot_download 預設支援多執行緒
# 增加 max_workers 引數(視你的伺服器頻寬而定,建議設定 4-8)
snapshot_download(
model_id,
local_dir=local_dir,
cache_dir='./cache', # 臨時快取目錄
max_workers=16 # 開啟8個執行緒同時下載
)
4. 核心部署程式碼
建立一個 inference.py 檔案,填入以下程式碼。該指令碼支援載入本地權重並進行一次圖文對話。
import os
import warnings
import torch
# 1. 遮蔽環境變數日誌 (必須在 import transformers 之前執行)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # 遮蔽 TensorFlow 日誌
os.environ['TRANSFORMERS_VERBOSITY'] = 'error' # 遮蔽 Transformers 自帶的大部分警告
os.environ['HF_HUB_DISABLE_SYMLINKS_WARNING'] = '1' # 遮蔽 HF 軟連線警告
# 2. 遮蔽 Python 警告
warnings.filterwarnings("ignore", category=FutureWarning)
warnings.filterwarnings("ignore", category=UserWarning)
# 3. 此時再匯入剩下的庫
from PIL import Image
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
# 4. 遮蔽 transformers 內部庫的輸出
transformers.logging.set_verbosity_error()
def run_inference():
model_path = "./glm-4v-9b"
# 1. 載入分詞器
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
# 2. 載入模型
print("[1/3] 正在載入模型至視訊記憶體 (BF16)...")
model = AutoModelForCausalLM.from_pretrained(
model_path,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto"
).eval()
# 相容性小補丁
if not hasattr(model.config, "num_hidden_layers"):
model.config.num_hidden_layers = model.config.num_layers
# 3. 準備輸入
image_path = "demo.jpg"
query = "請詳細描述這張圖片。"
try:
image = Image.open(image_path).convert("RGB")
except Exception:
print(f"錯誤:無法找到圖片 {image_path}")
return
inputs = tokenizer.apply_chat_template(
[{"role": "user", "image": image, "content": query}],
add_generation_prompt=True,
tokenize=True,
return_tensors="pt",
return_dict=True
).to("cuda")
# 4. 執行推理
print("[2/3] 模型正在思考...")
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=512,
do_sample=False,
use_cache=True,
eos_token_id=tokenizer.eos_token_id
)
response_ids = outputs[0][len(inputs['input_ids'][0]):]
response = tokenizer.decode(response_ids, skip_special_tokens=True)
print("[3/3] 推理完成。")
print("\n" + "="*30 + " 模型回答 " + "="*30)
print(response)
print("="*70 + "\n")
if __name__ == "__main__":
run_inference()
5. 效果演示
6. 進階配置:針對不同場景的最佳化
方案 A:視訊記憶體不足?使用 4-bit 量化
如果你的視訊記憶體小於 20GB,可以透過 bitsandbytes 開啟 4-bit 量化載入,視訊記憶體佔用將降至約 9-11GB。
首先安裝:pip install bitsandbytes
修改模型載入部分:
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
load_in_4bit=True, # 開啟 4bit 量化
device_map="auto" # 自動分配視訊記憶體
)
方案 B:高併發推理?使用 vLLM 部署
如果你希望將模型作為 API 服務提供給前端使用,推薦使用 vLLM 框架,它的吞吐量比原生 Transformers 高出數倍。
pip install vllm
# 啟動相容 OpenAI 介面的服務
python -m vllm.entrypoints.openai.api_server \
--model ./glm-4v-9b \
--trust-remote-code \
--gpu-memory-utilization 0.9 \
--max-model-len 4096 \
--port 8000
部署後,你可以直接使用 OpenAI 的 SDK 呼叫它。
7. 常見坑點排查(FAQ)
- 報錯
AttributeError: 'ChatGLMTokenizer' object has no attribute 'apply_chat_template'- 解決: 請確保
transformers版本大於 4.44.0。如果版本正確仍報錯,檢查tokenizer_config.json是否在模型目錄中。
- 解決: 請確保
- 視訊記憶體溢位 (OOM)
- 解決: 減小
max_length;或者使用上文提到的 4-bit 量化方案。
- 解決: 減小
- 圖片識別效果差
- 解決: 檢查圖片讀取時是否轉換為了
.convert("RGB"),GLM-4V 對灰度圖或帶 Alpha 通道的圖可能不相容。
- 解決: 檢查圖片讀取時是否轉換為了
8. 結語
GLM-4V-9B 展現了極強的圖文理解能力,透過本地部署,你可以將其整合到自動化辦公、智慧安檢、醫療影像輔助等多種私有化場景中。如果你在部署過程中遇到問題,歡迎在評論區交流!
GLM-4V-9B Vision-Language Multimodal Model Local Deployment (Step-by-step)
GLM-4V-9B from Zhipu AI is a recent open vision-language model emphasizing image understanding + dialogue + reasoning. Self-hosting keeps data on-prem and slashes long‑term API invoices versus cloud SKUs. This guide targets Linux boxes that already satisfy PyTorch + CUDA prerequisites and demonstrates end-to-end local inference. ---
Captured at (local ISO): 2026-05-18 05:17:26
1. Introduction
GLM-4V-9B from Zhipu AI is a recent open vision-language model emphasizing image understanding + dialogue + reasoning. Self-hosting keeps data on-prem and slashes long‑term API invoices versus cloud SKUs.
This guide targets Linux boxes that already satisfy PyTorch + CUDA prerequisites and demonstrates end-to-end local inference.
2. Environment setup
Minimal checklist:
- OS: Ubuntu 20.04+ (recommended baseline)
- VRAM:
- FP16 / BF16 path: aim for ≥ 24 GB (3090/4090, A10, A100 class)
- Int4 quantized path: roughly ≥12 GB (3060/4070 tiers)
- Toolchain: Python 3.10+, CUDA 11.8+, PyTorch 2.x
2.1 Install dependencies
Assuming Torch is wired, pull media handling + tokenizer stacks:
pip install transformers>=4.45.0 accelerate tiktoken einops scipy pillow
# 强烈建议安装 flash-attn 以获得更快的推理速度(需支持 CUDA 11.6+)
pip install flash-attn --no-build-isolation
3. Download weights
Approx 18 GB on disk — ModelScope mirrors often saturate faster domestically versus raw Hugging Face pulls.
pip install modelscope
modelscope download --model ZhipuAI/glm-4v-9b --local_dir ./glm-4v-9b
Parallel downloader helper:
from modelscope import snapshot_download
model_id = 'ZhipuAI/glm-4v-9b'
local_dir = './glm-4v-9b'
# 增加 max_workers 参数(视你的服务器带宽而定,建议设置 4-8)
snapshot_download(
model_id,
local_dir=local_dir,
cache_dir='./cache', # 临时缓存目录
max_workers=16 # 开启8个线程同时下载
)
4. Core inference script
Save as inference.py adjacent to ./glm-4v-9b:
import os
import warnings
import torch
# 1. 屏蔽环境变量日志 (必须在 import transformers 之前执行)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # 屏蔽 TensorFlow 日志
os.environ['TRANSFORMERS_VERBOSITY'] = 'error' # 屏蔽 Transformers 自带的大部分警告
os.environ['HF_HUB_DISABLE_SYMLINKS_WARNING'] = '1' # 屏蔽 HF 软连接警告
# 2. 屏蔽 Python 警告
warnings.filterwarnings("ignore", category=FutureWarning)
warnings.filterwarnings("ignore", category=UserWarning)
# 3. 此时再导入剩下的库
from PIL import Image
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
# 4. 屏蔽 transformers 内部库的输出
transformers.logging.set_verbosity_error()
def run_inference():
model_path = "./glm-4v-9b"
# 1. 加载分词器
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
# 2. 加载模型
print("[1/3] 正在加载模型至显存 (BF16)...")
model = AutoModelForCausalLM.from_pretrained(
model_path,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto"
).eval()
# 兼容性小补丁
if not hasattr(model.config, "num_hidden_layers"):
model.config.num_hidden_layers = model.config.num_layers
# 3. 准备输入
image_path = "demo.jpg"
query = "请详细描述这张图片。"
try:
image = Image.open(image_path).convert("RGB")
except Exception:
print(f"错误:无法找到图片 {image_path}")
return
inputs = tokenizer.apply_chat_template(
[{"role": "user", "image": image, "content": query}],
add_generation_prompt=True,
tokenize=True,
return_tensors="pt",
return_dict=True
).to("cuda")
# 4. 执行推理
print("[2/3] 模型正在思考...")
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=512,
do_sample=False,
use_cache=True,
eos_token_id=tokenizer.eos_token_id
)
response_ids = outputs[0][len(inputs['input_ids'][0]):]
response = tokenizer.decode(response_ids, skip_special_tokens=True)
print("[3/3] 推理完成。")
print("\n" + "="*30 + " 模型回答 " + "="*30)
print(response)
print("="*70 + "\n")
if __name__ == "__main__":
run_inference()
5. Sample output
6. Advanced tuning
Plan A — VRAM constrained? Enable 4-bit
Sub‑20 GB boards benefit from BitsAndBytes 4‑bit quantization (~9–11 GB residency).
Install once: pip install bitsandbytes
Swap loader stanza:
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
load_in_4bit=True,
device_map="auto"
)
Plan B — High throughput APIs with vLLM
Serve OpenAI-compatible HTTP for frontends/backends needing batching throughput:
pip install vllm
python -m vllm.entrypoints.openai.api_server \
--model ./glm-4v-9b \
--trust-remote-code \
--gpu-memory-utilization 0.9 \
--max-model-len 4096 \
--port 8000
7. FAQ troubleshooting
AttributeError: 'ChatGLMTokenizer' object has no attribute 'apply_chat_template'
Bumptransformers≥ 4.44; confirmtokenizer_config.jsonlanded beside weights.- CUDA OOM
Shorten contexts, enable 4‑bit loader, reducegpu_memory_utilizationif using vLLM. - Weak visual answers
EnsureImage.open(...).convert("RGB"); transparent / single‑channel PNGs degrade alignment.
8. Closing thoughts
GLM-4V-9B punches above its parameter class for multimodal workloads. Wired locally it slots into offline document QA, CV inspection benches, biomedical imaging tooling, etc. Ping the comment thread when you stall—community notes accumulate fast on fresh checkpoints.