PDF 转 Markdown 神器:MinerU 2.5 (1.2B) 部署全攻略
在 AI 时代,高质量的数据是模型训练的基石。而 PDF 文档由于其排版复杂(多栏、表格、公式、图片交叉),一直是数据清洗中的“硬骨头”。
前言
在 AI 时代,高质量的数据是模型训练的基石。而 PDF 文档由于其排版复杂(多栏、表格、公式、图片交叉),一直是数据清洗中的“硬骨头”。
MinerU 是由 OpenDataLab 推出的开源 PDF 提取工具,支持精准的布局分析、公式识别和表格提取。最近更新的 2.5-2509-1.2B 版本在性能和准确率上又有了显著提升。今天,我们就来手把手拆解如何在 Linux 环境下部署这套强大的系统。
1. 硬件要求
MinerU 2.5-1.2B 包含多个深度学习模型(Layout, OCR, Formula),建议配置如下:
- 操作系统: Ubuntu 22.04 或更高版本
- CPU: 8 核以上
- GPU: NVIDIA GPU (显存建议 8GB 以上,12GB/16GB 最佳)
- 存储: 至少 20GB 剩余空间(用于存放模型权重)
2. 环境搭建
2.1 创建虚拟环境
建议使用 Conda 来管理 Python 环境,避免依赖冲突。
# 创建 Python 3.10 环境
conda create -n mineru python=3.10 -y
conda activate mineru
2.2 安装 magic-pdf
magic-pdf 是 MinerU 的核心包。我们选择带 GPU 加速的全量安装包。
# 安装 magic-pdf [full]
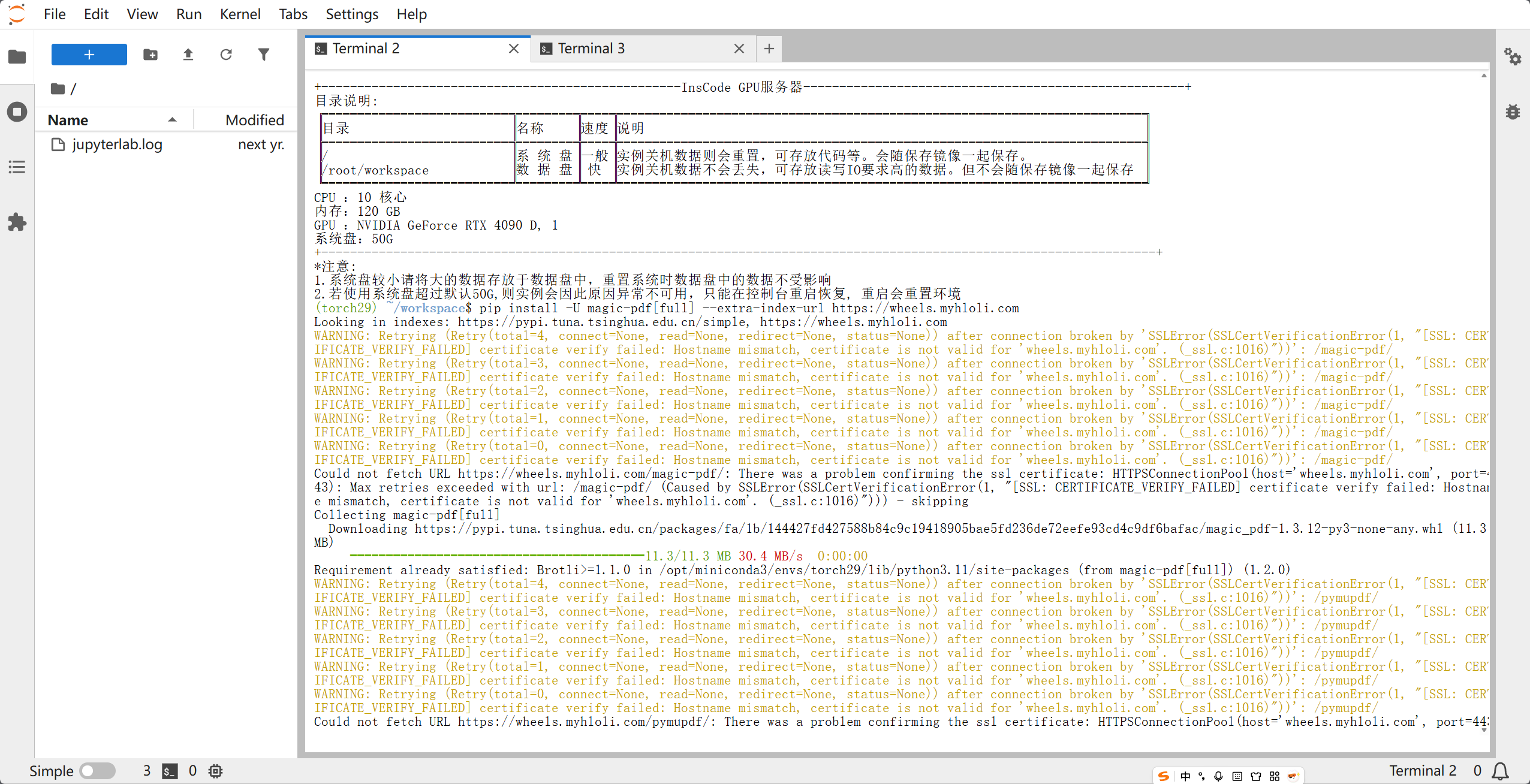
pip install -U magic-pdf[full] --extra-index-url https://wheels.myhloli.com
这个过程稍微耗时会有一点久,中间可能会有警告弹出(黄色字体)不用管让他下载就好了
2.3 安装系统依赖
PDF 解析涉及到图像处理,需要安装相关的系统动态库:
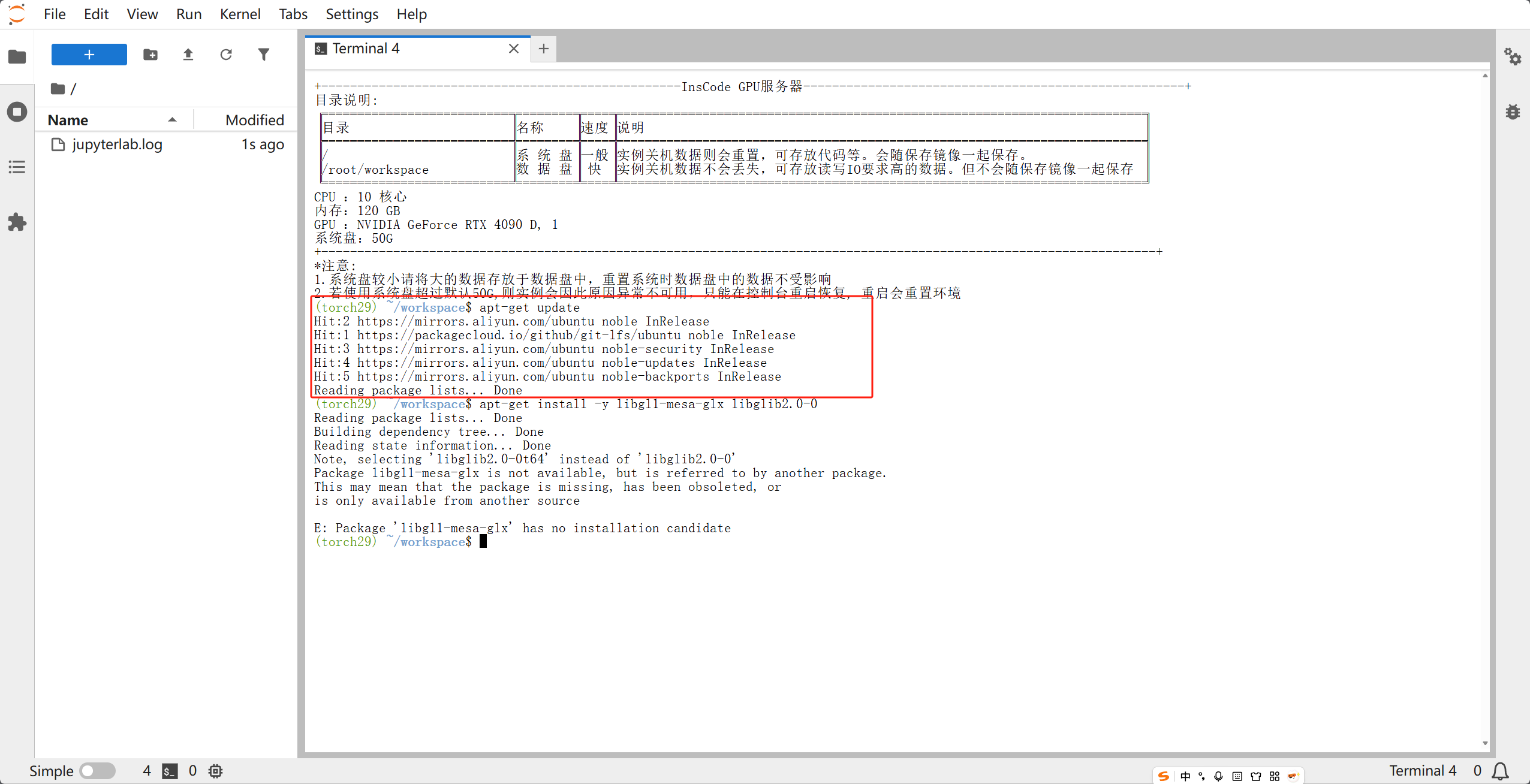
sudo apt-get update
sudo apt-get install -y libgl1-mesa-glx libglib2.0-0
如果是在Autodl等平台上面,就不需要赋予权限,可以按以下命令:
apt-get update
apt-get install -y libgl1 libglx-mesa0 libglib2.0-0
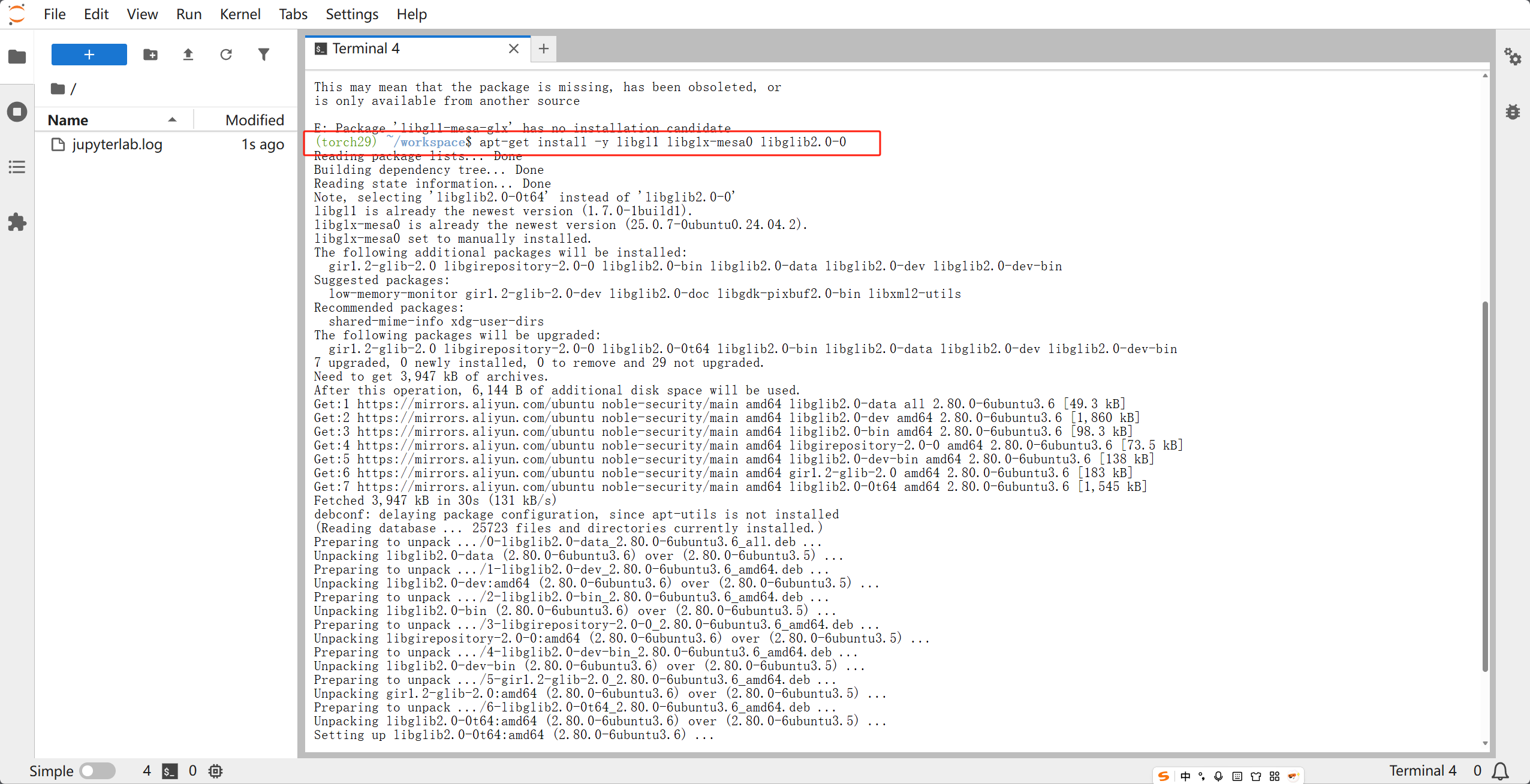
这个也需要下载
pip install -U mineru
3. 模型权重下载
MinerU 2.5 需要加载预训练权重。国内用户推荐使用 ModelScope(魔搭),速度极快。
3.1 使用脚本下载
创建一个 download_models.py 文件:
from modelscope import snapshot_download
# 注意:仓库名需包含版本号和参数量
model_dir = snapshot_download('OpenDataLab/MinerU2.5-2509-1.2B', local_dir='models')
print(f"模型下载成功,存放路径为: {model_dir}")
运行下载:
python download.py
3.2其他权重下载
这个是补充部分缺失的权重,主要用于OCR,如果不是很模糊的扫描件的话可以跳过这一步
运行命令
python -c "from modelscope import snapshot_download; snapshot_download('OpenDataLab/PDF-Extract-Kit-1.0', local_dir='/root/workspace/MinerU2.5', max_workers=16)"
这个过程可能会有点久,稍微等待等待
4. 核心配置(关键步骤)
MinerU 需要一个配置文件来指定模型路径。
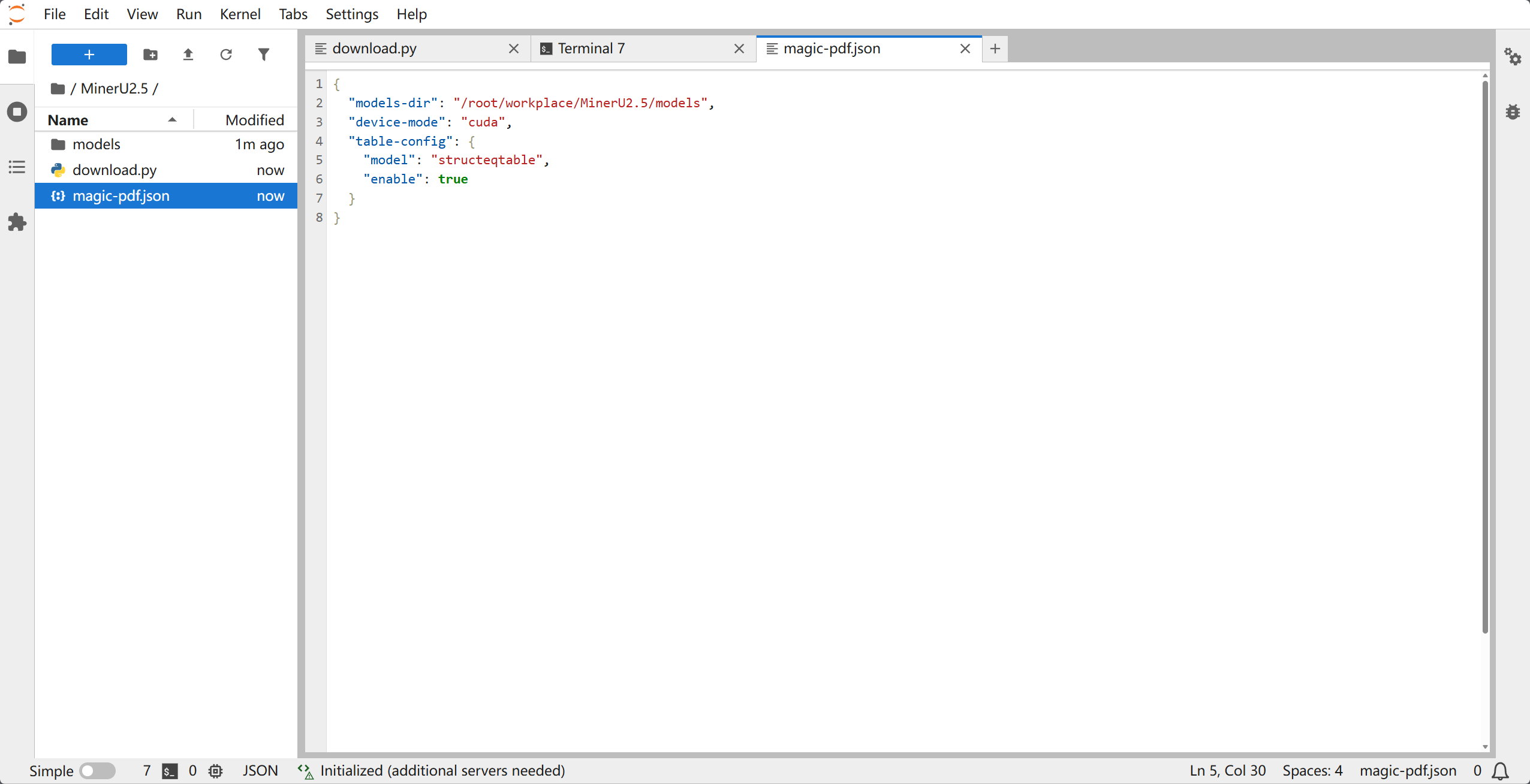
- 获取模板:在你的家目录下创建一个名为
magic-pdf.json的文件。(注意一定要家目录) - 填写路径:
{
"models-dir": "/root/workspace/MinerU2.5/models",
"device-mode": "cuda",
"layout-config": {
"model": "doclayout_yolo"
},
"ocr-config": {
"model": "native",
"enable": false
}
}
注意:
models-dir必须是绝对路径,且指向你刚才下载模型所在的那个文件夹。
5. 开始实战
5.1 命令行模式(CLI)
这是最快捷的测试方式,直接将一个 PDF 转换为 Markdown。
mineru -p test.pdf -o ./output --task doc
转换完成后,你会在 output 文件夹中看到:
5.2 启动 Web UI 界面
如果你更喜欢可视化操作,可以启动内置的 Gradio 演示界面:
# 先安装 gradio
pip install gradio
# 从 GitHub 克隆源码以运行 demo (或者直接运行包内的 demo)
git clone https://github.com/opendatalab/MinerU.git
cd MinerU
python web_demo.py
6. 常见坑点与解决
-
显存溢出 (OOM):
- 如果显存小于 8G,建议在配置文件中将
device-mode设置为cpu(速度会变慢)。 - 或者处理 PDF 时减少并发。
- 如果显存小于 8G,建议在配置文件中将
-
PaddlePaddle 报错:
- MinerU 的 OCR 默认依赖 Paddle。如果报错
libpaddle.so相关问题,请检查 CUDA 版本是否与 Paddle 匹配。 - 尝试重新安装:
pip install paddlepaddle-gpu -i https://pypi.tuna.tsinghua.edu.cn/simple
- MinerU 的 OCR 默认依赖 Paddle。如果报错
-
公式识别乱码:
- 确保
magic-pdf.json中的路径正确,且完整下载了LaTeX_OCR相关模型。
- 确保
7. 总结
MinerU 2.5-1.2B 是目前开源界处理 PDF 效果最出色的工具之一。通过合理的配置,它可以极大地提升我们处理非结构化文档的效率。
如果你觉得有用,请点个赞并关注吧!有任何部署问题欢迎在评论区留言讨论。
PDF 轉 Markdown 神器:MinerU 2.5 (1.2B) 部署全攻略
在 AI 時代,高質量的數據是模型訓練的基石。而 PDF 文檔由於其排版複雜(多欄、表格、公式、圖片交叉),一直是數據清洗中的“硬骨頭”。
來源:https://blog.csdn.net/2403_87969572/article/details/156801958
抓取時間(ISO本地):2026-05-18 05:17:25
前言
在 AI 時代,高質量的資料是模型訓練的基石。而 PDF 文件由於其排版複雜(多欄、表格、公式、圖片交叉),一直是資料清洗中的“硬骨頭”。
MinerU 是由 OpenDataLab 推出的開源 PDF 提取工具,支援精準的佈局分析、公式識別和表格提取。最近更新的 2.5-2509-1.2B 版本在效能和準確率上又有了顯著提升。今天,我們就來手把手拆解如何在 Linux 環境下部署這套強大的系統。
1. 硬體要求
MinerU 2.5-1.2B 包含多個深度學習模型(Layout, OCR, Formula),建議配置如下:
- 作業系統: Ubuntu 22.04 或更高版本
- CPU: 8 核以上
- GPU: NVIDIA GPU (視訊記憶體建議 8GB 以上,12GB/16GB 最佳)
- 儲存: 至少 20GB 剩餘空間(用於存放模型權重)
2. 環境搭建
2.1 建立虛擬環境
建議使用 Conda 來管理 Python 環境,避免依賴衝突。
# 建立 Python 3.10 環境
conda create -n mineru python=3.10 -y
conda activate mineru
2.2 安裝 magic-pdf
magic-pdf 是 MinerU 的核心包。我們選擇帶 GPU 加速的全量安裝包。
# 安裝 magic-pdf [full]
pip install -U magic-pdf[full] --extra-index-url https://wheels.myhloli.com
這個過程稍微耗時會有一點久,中間可能會有警告彈出(黃色字型)不用管讓他下載就好了
2.3 安裝系統依賴
PDF 解析涉及到影象處理,需要安裝相關的系統動態庫:
sudo apt-get update
sudo apt-get install -y libgl1-mesa-glx libglib2.0-0
如果是在Autodl等平臺上面,就不需要賦予許可權,可以按以下命令:
apt-get update
apt-get install -y libgl1 libglx-mesa0 libglib2.0-0
這個也需要下載
pip install -U mineru
3. 模型權重下載
MinerU 2.5 需要載入預訓練權重。國內使用者推薦使用 ModelScope(魔搭),速度極快。
3.1 使用指令碼下載
建立一個 download_models.py 檔案:
from modelscope import snapshot_download
# 注意:倉庫名需包含版本號和引數量
model_dir = snapshot_download('OpenDataLab/MinerU2.5-2509-1.2B', local_dir='models')
print(f"模型下載成功,存放路徑為: {model_dir}")
執行下載:
python download.py
3.2其他權重下載
這個是補充部分缺失的權重,主要用於OCR,如果不是很模糊的掃描件的話可以跳過這一步
執行命令
python -c "from modelscope import snapshot_download; snapshot_download('OpenDataLab/PDF-Extract-Kit-1.0', local_dir='/root/workspace/MinerU2.5', max_workers=16)"
這個過程可能會有點久,稍微等待等待
4. 核心配置(關鍵步驟)
MinerU 需要一個配置檔案來指定模型路徑。
- 獲取模板:在你的家目錄下建立一個名為
magic-pdf.json的檔案。(注意一定要家目錄) - 填寫路徑:
{
"models-dir": "/root/workspace/MinerU2.5/models",
"device-mode": "cuda",
"layout-config": {
"model": "doclayout_yolo"
},
"ocr-config": {
"model": "native",
"enable": false
}
}
注意:
models-dir必須是絕對路徑,且指向你剛才下載模型所在的那個資料夾。
5. 開始實戰
5.1 命令列模式(CLI)
這是最快捷的測試方式,直接將一個 PDF 轉換為 Markdown。
mineru -p test.pdf -o ./output --task doc
轉換完成後,你會在 output 資料夾中看到:
5.2 啟動 Web UI 介面
如果你更喜歡視覺化操作,可以啟動內建的 Gradio 演示介面:
# 先安裝 gradio
pip install gradio
# 從 GitHub 克隆原始碼以執行 demo (或者直接執行包內的 demo)
git clone https://github.com/opendatalab/MinerU.git
cd MinerU
python web_demo.py
6. 常見坑點與解決
-
視訊記憶體溢位 (OOM):
- 如果視訊記憶體小於 8G,建議在配置檔案中將
device-mode設定為cpu(速度會變慢)。 - 或者處理 PDF 時減少併發。
- 如果視訊記憶體小於 8G,建議在配置檔案中將
-
PaddlePaddle 報錯:
- MinerU 的 OCR 預設依賴 Paddle。如果報錯
libpaddle.so相關問題,請檢查 CUDA 版本是否與 Paddle 匹配。 - 嘗試重新安裝:
pip install paddlepaddle-gpu -i https://pypi.tuna.tsinghua.edu.cn/simple
- MinerU 的 OCR 預設依賴 Paddle。如果報錯
-
公式識別亂碼:
- 確保
magic-pdf.json中的路徑正確,且完整下載了LaTeX_OCR相關模型。
- 確保
7. 總結
MinerU 2.5-1.2B 是目前開源界處理 PDF 效果最出色的工具之一。透過合理的配置,它可以極大地提升我們處理非結構化文件的效率。
如果你覺得有用,請點個贊並關注吧!有任何部署問題歡迎在評論區留言討論。
MinerU 2.5 (1.2B) Full Deploy Guide: PDF to Markdown
OS: Ubuntu 22.04+ GPU: NVIDIA, 8 GB+ VRAM (12–16 GB ideal) Disk: 20 GB+ for weights
Captured at (local ISO): 2026-05-18 05:17:25
Introduction
High-quality data matters for AI. PDFs—with multi-column layout, tables, formulas, and figures—are hard to parse. MinerU from OpenDataLab extracts layout, formulas, and tables accurately. This guide deploys MinerU2.5-2509-1.2B on Linux.
1. Hardware
- OS: Ubuntu 22.04+
- CPU: 8+ cores
- GPU: NVIDIA, 8 GB+ VRAM (12–16 GB ideal)
- Disk: 20 GB+ for weights
2. Environment
2.1 Conda env
conda create -n mineru python=3.10 -y
conda activate mineru
2.2 Install magic-pdf
pip install -U magic-pdf[full] --extra-index-url https://wheels.myhloli.com
Yellow warnings during install are usually fine.
2.3 System libraries
sudo apt-get update
sudo apt-get install -y libgl1-mesa-glx libglib2.0-0
On AutoDL without sudo:
apt-get update
apt-get install -y libgl1 libglx-mesa0 libglib2.0-0
Also:
pip install -U mineru
3. Download weights
Use ModelScope in China.
3.1 Script
from modelscope import snapshot_download
model_dir = snapshot_download('OpenDataLab/MinerU2.5-2509-1.2B', local_dir='models')
print(f"模型下载成功,存放路径为: {model_dir}")
python download.py
3.2 Optional OCR kit
For blurry scans:
python -c "from modelscope import snapshot_download; snapshot_download('OpenDataLab/PDF-Extract-Kit-1.0', local_dir='/root/workspace/MinerU2.5', max_workers=16)"
4. Configuration
Create magic-pdf.json in your home directory:
{
"models-dir": "/root/workspace/MinerU2.5/models",
"device-mode": "cuda",
"layout-config": {
"model": "doclayout_yolo"
},
"ocr-config": {
"model": "native",
"enable": false
}
}
models-dir must be an absolute path to downloaded weights.
5. Run
5.1 CLI
mineru -p test.pdf -o ./output --task doc
Output under output/:
5.2 Gradio UI
pip install gradio
git clone https://github.com/opendatalab/MinerU.git
cd MinerU
python web_demo.py
6. Pitfalls
- OOM: Use
"device-mode": "cpu"or reduce concurrency on <8 GB VRAM. - Paddle errors: Match CUDA to
paddlepaddle-gpuor reinstall from Tsinghua mirror. - Garbled formulas: Verify
models-dirand full LaTeX OCR weights.
7. Summary
MinerU 2.5-1.2B is among the best open PDF parsers available. Proper config saves hours on unstructured documents.