机器视觉:Swin Transformer 深度解读
深度解读Swin Transformer:分层特征图、移位窗口自注意力(SW-MSA)、相对位置偏置,对比ViT缺陷,覆盖分类/检测/分割实验与消融分析。
1. 引言:视觉Backbone的演进与ViT的困境
在计算机视觉领域,卷积神经网络(CNN)长期占据统治地位——从AlexNet的横空出世,到ResNet、EfficientNet等架构的持续优化,CNN凭借局部感受野、权重共享等特性,在图像分类、检测、分割等任务中展现出强大的适配性。但随着自然语言处理(NLP)领域Transformer的爆发,研究者们开始探索将这种“注意力即一切”的架构迁移到视觉领域,核心代表便是Vision Transformer(ViT)。上一篇博客中详细介绍了Vision Transformer的提出以及原理,还不了解的可以看一下:机器视觉:Vision Transformer——打破CNN垄断的视觉革命先锋
ViT的核心思路是将图像分割为固定大小的补丁(Patch),视为“视觉token”后直接输入Transformer编码器,通过全局自注意力建模token间依赖。这一突破证明了Transformer在视觉任务中的潜力,但它存在两个致命缺陷,导致难以成为通用视觉Backbone:
- 单分辨率特征图:ViT仅输出单一低分辨率特征图,无法适配目标检测、语义分割等需要多尺度特征的密集预测任务(这类任务依赖FPN、U-Net等多尺度融合结构);
- 二次计算复杂度:全局自注意力的计算量与token数量(图像分辨率)的平方成正比,面对高分辨率图像(如512×512)时,计算开销会急剧膨胀,无法落地应用。
正是为了解决这两个核心问题,微软亚洲研究院提出了Swin Transformer——一种基于“移位窗口”的分层视觉Transformer,它既保留了Transformer的全局建模能力,又具备CNN的分层特征和高效计算特性,最终成为首个能无缝适配分类、检测、分割等全场景视觉任务的Transformer Backbone。
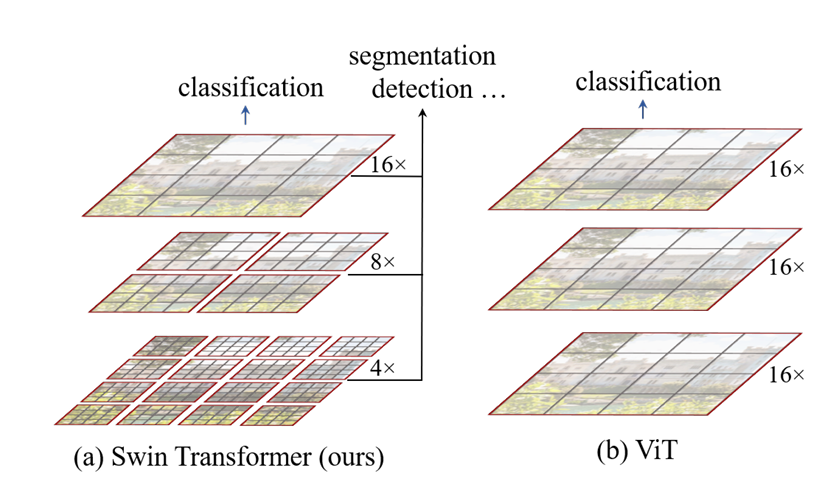
(a) 所提 Swin Transformer 通过在深层合并图像块(灰色所示)构建分层特征图,且因仅在各局部窗口(红色所示)内计算自注意力,其计算复杂度与输入图像尺寸呈线性关系,因此可作为适用于图像分类和密集型识别任务的通用骨干网络。(b) 相比之下,早期视觉 Transformer [20] 仅生成单一低分辨率特征图,且由于需计算全局自注意力,其计算复杂度与输入图像尺寸呈二次关系
2. 核心创新点总览
Swin Transformer的成功源于两个革命性设计,再加上细节优化,共同实现了“高效+通用”的目标:
- 分层特征表示(Hierarchical Feature Maps):模仿CNN的多尺度特征构建方式,通过“补丁合并”(Patch Merging)逐步减少token数量、提升特征维度,输出与CNN一致的多分辨率特征图(1/4、1/8、1/16、1/32下采样率),完美适配密集预测任务;
- 移位窗口自注意力(Shifted Window Self-Attention):将自注意力的计算限制在局部非重叠窗口内(降低复杂度),同时通过窗口移位建立跨窗口连接(保证建模能力),实现“线性复杂度+全局依赖建模”的平衡;
- 细节优化:相对位置偏置(提升空间建模精度)、循环移位+掩码(高效处理移位窗口)等,进一步强化性能与效率。
3. 原理详解:一步步拆解Swin Transformer
3.1 整体架构:分层特征的构建逻辑
Swin Transformer的整体架构与CNN类似,通过4个Stage逐步构建分层特征,每个Stage包含“补丁合并”(仅前3个Stage有)和“多个Swin Transformer Block”。以基础版Swin-T(Tiny)为例,架构流程如下:
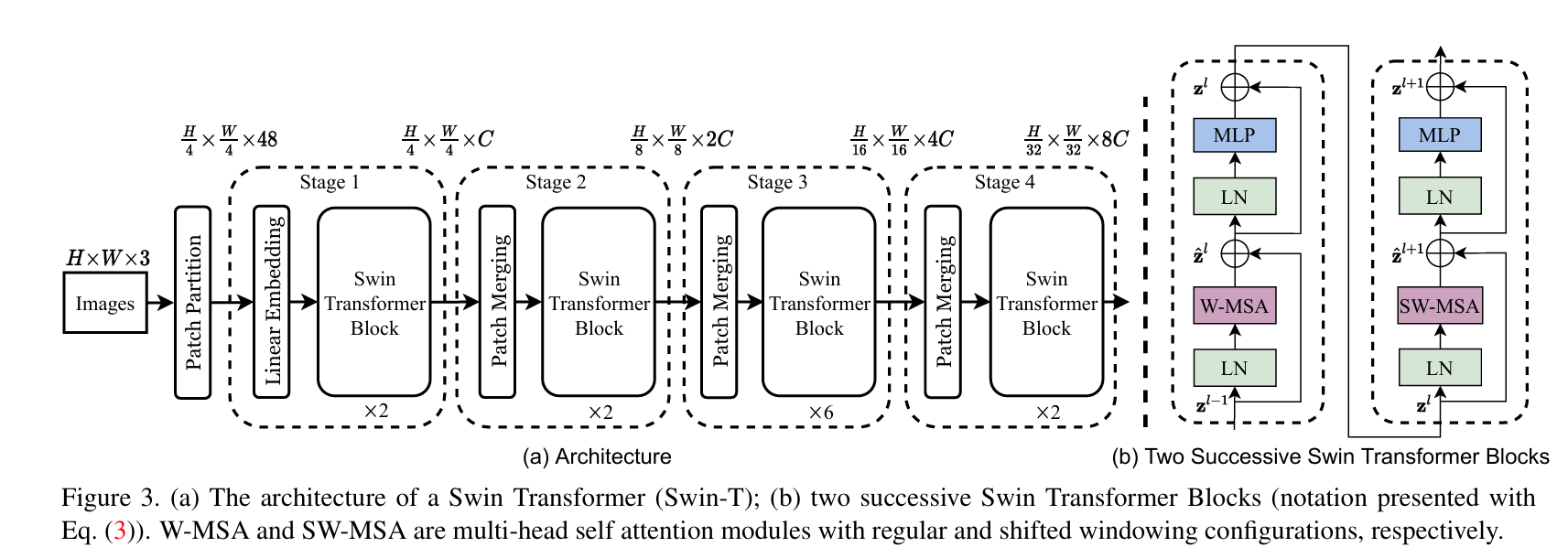
(a)展示从输入图像到4个Stage的特征演变;(b)展示W-MSA(常规窗口注意力)和SW-MSA(移位窗口注意力)的交替使用。
第一步:输入处理与Patch Embedding
- Patch Partition(补丁划分):将输入RGB图像(如224×224×3)划分为非重叠的4×4补丁(Patch)。每个补丁包含4×4×3=48个像素值,整个图像会被划分为(224/4)×(224/4)=56×56个补丁,即56×56个“视觉token”;
- Linear Embedding(线性嵌入):通过一个线性层将每个48维的补丁特征映射到指定维度C(Swin-T中C=96),最终得到56×56×96的特征图。这一步对应ViT的Patch Embedding,但Swin的补丁更小(4×4 vs ViT的16×16),为后续分层特征奠定基础。
第二步:Stage 1~4:分层特征的递进
Swin的4个Stage逐步降低特征图分辨率、提升特征维度,过程如下:
| Stage | 核心操作 | 输入特征 | 输出特征 | 作用 |
|---|---|---|---|---|
| 1 | 2个Swin Block | 56×56×96 | 56×56×96 | 初步特征提取,无下采样 |
| 2 | Patch Merging + 2个Swin Block | 56×56×96 | 28×28×192 | 下采样2倍,特征维度翻倍 |
| 3 | Patch Merging + 6个Swin Block | 28×28×192 | 14×14×384 | 下采样2倍,特征维度翻倍 |
| 4 | Patch Merging + 2个Swin Block | 14×14×384 | 7×7×768 | 下采样2倍,特征维度翻倍 |
关键模块解释:
- Patch Merging(补丁合并):实现下采样的核心操作。将2×2相邻的4个补丁的特征拼接(如56×56×96 → 28×28×(96×4)),再通过一个线性层将维度减半(96×4 → 192),最终得到28×28×192的特征图。这一步既减少了token数量(4倍减少),又提升了特征的感受野;
- Swin Transformer Block:每个Block是特征变换的核心,结构为“LN → 注意力模块 → 残差连接 → LN → MLP → 残差连接”。与标准Transformer Block的区别在于:注意力模块交替使用W-MSA(常规窗口注意力) 和SW-MSA(移位窗口注意力)(如上图(b)所示),通过这种交替建立跨窗口连接。
3.2 核心:移位窗口自注意力(SW-MSA)
这是Swin Transformer最具创新性的部分,直接解决了ViT的“复杂度高”和“无跨窗口连接”两大问题。我们分5步拆解其设计逻辑:
第一步:为什么要“局部窗口”?—— 复杂度的降维打击
全局自注意力的计算复杂度是ViT的致命伤,其公式为:
Ω ( M S A )
4
h
w
C
2
+
2
(
h
w
)
2
C
\Omega(MSA) = 4hwC^2 + 2(hw)^2C
Ω(MSA)=4hwC2+2(hw)2C
其中,
h
w
hw
hw是token数量(如56×56=3136),
C
C
C 是特征维度。可以看到,复杂度与 (hw) 的平方成正比(二次复杂度)——当图像分辨率提升到512×512时,(hw=128×128=16384),((hw)^2) 会达到2.68亿,计算量完全无法承受。
Swin的解决方案是局部窗口注意力(W-MSA):将特征图划分为非重叠的局部窗口,仅在每个窗口内计算自注意力。假设窗口大小为 M × M M×M M×M(默认M=7),则每个窗口包含 M 2 M^2 M2 个token,复杂度公式变为:
Ω ( W − M S A )
4
h
w
C
2
+
2
M
2
h
w
C
\Omega(W-MSA) = 4hwC^2 + 2M^2hwC
Ω(W−MSA)=4hwC2+2M2hwC
此时,复杂度与
h
w
hw
hw成正比(线性复杂度)——因为
M
M
M 是固定值(如7),
M
2
49 M^2=49 M2=49是常数。同样以512×512图像为例,计算量会从“亿级”降至“百万级”,效率提升显著。
第二步:常规窗口的问题——缺乏跨窗口连接
局部窗口虽然高效,但窗口间是孤立的——一个窗口内的token无法与其他窗口的token建立注意力连接,导致模型难以建模长距离依赖(比如图像中跨窗口的物体),建模能力受限。
第三步:移位窗口(SW-MSA)—— 建立跨窗口连接
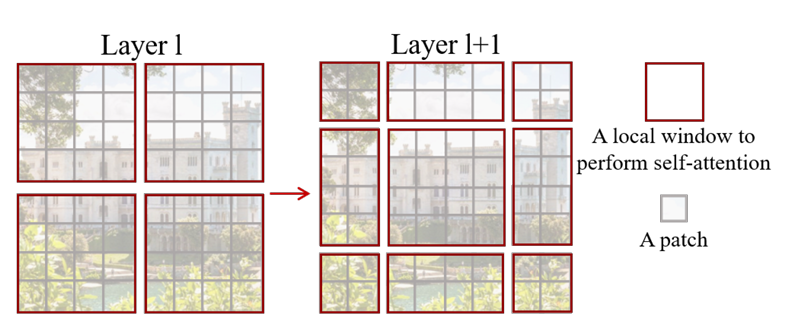
为了解决窗口孤立问题,Swin提出“移位窗口”策略:在连续的Swin Block中,交替使用“常规窗口”和“移位窗口”。具体操作是:
- 第l层Block使用常规窗口(W-MSA):窗口从特征图左上角开始,均匀划分;
- 第l+1层Block使用移位窗口(SW-MSA):将窗口沿x轴和y轴各移位 ⌊ M / 2 ⌋ \lfloor M/2 \rfloor ⌊M/2⌋个像素(如M=7时移位3个像素)。
移位后,新窗口会跨越原窗口的边界,自然建立起不同窗口间的token连接。例如,原窗口A和窗口B的边界token,在移位后的窗口中会被划入同一个窗口,从而实现注意力交互。
第四步:高效批量计算——循环移位+掩码
移位窗口虽然解决了连接问题,但会带来新的麻烦:移位后窗口数量会增加,且部分窗口会小于 M × M M×M M×M(比如特征图边缘的窗口)。以8×8特征图、M=4为例:
- 常规窗口:(8/4)×(8/4)=2×2=4个窗口(均为4×4);
- 移位窗口:(8/4 +1)×(8/4 +1)=3×3=9个窗口(边缘窗口为2×2)。
如果直接对9个窗口计算注意力,会产生大量小窗口,导致计算效率低、内存访问碎片化。Swin提出“循环移位(Cyclic Shift)+ 掩码(Masking)”的高效解决方案,步骤如下:
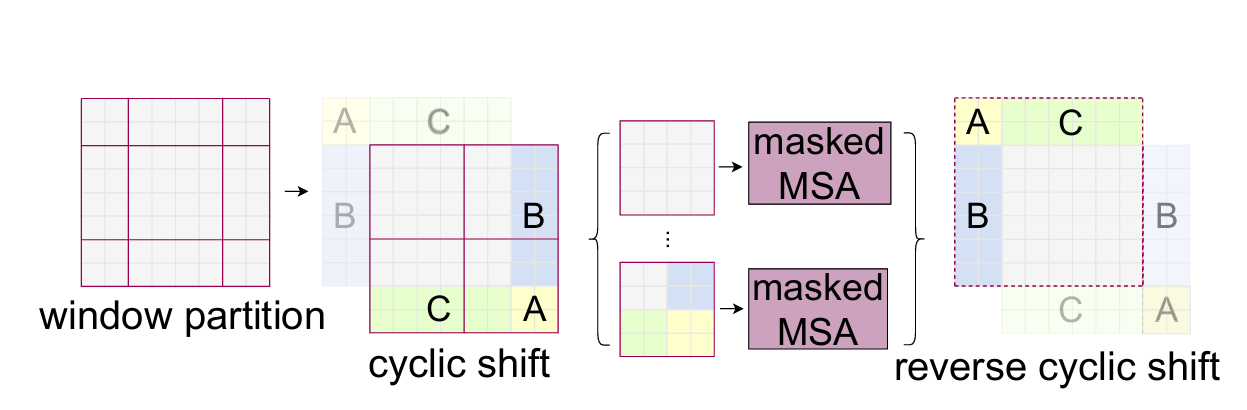
展示如何通过循环移位将小窗口拼接为完整窗口,再通过掩码屏蔽无效注意力。
- 循环移位:将特征图沿x轴和y轴循环移位 ⌊ M / 2 ⌋ \lfloor M/2 \rfloor ⌊M/2⌋ 个像素,原本分散在边缘的小窗口会被拼接成完整的 (M×M) 窗口;
- 合并窗口:拼接后,窗口数量恢复为常规窗口的数量(如2×2=4个),可批量计算注意力;
- 掩码屏蔽:由于循环移位后,部分窗口内的token来自原特征图的不同区域(并非真实相邻),需要用一个二进制掩码屏蔽这些“无效连接”——让这些token间的注意力权重为-∞(SoftMax后接近0),避免虚假依赖;
- 反向循环移位:注意力计算完成后,将特征图反向循环移位,恢复到原始位置。
通过这四步,既能保证跨窗口连接,又能维持与常规窗口相同的计算效率,完美解决了移位窗口的工程实现问题。
第五步:相对位置偏置——提升空间建模精度
自注意力机制本身是“位置无关”的——它只关注token间的内容相似性,不考虑空间位置关系。ViT通过添加“绝对位置嵌入”解决这一问题,但绝对位置嵌入存在两个缺陷:
- 缺乏平移不变性:训练时学到的“位置1”的嵌入,无法泛化到其他位置;
- 不适配不同窗口大小:如果微调时改变窗口大小,预训练的绝对位置嵌入会失效。
Swin提出相对位置偏置(Relative Position Bias),直接建模窗口内token的相对位置关系。具体设计如下:
-
在自注意力计算中加入偏置项 (B),公式为:
A t t e n t i o n ( Q , K , V )
S o f t M a x ( Q K T d + B ) V Attention(Q, K, V) = SoftMax\left( \frac{QK^T}{\sqrt{d}} + B \right) V Attention(Q,K,V)=SoftMax(d QKT+B)V
其中, B ∈ R M 2 × M 2 B \in \mathbb{R}^{M^2 \times M^2} B∈RM2×M2 是相对位置偏置矩阵, M 2 M^2 M2 是窗口内token的数量(如M=7时为49); -
参数高效化:由于token的相对位置范围是 [ − M + 1 , M − 1 ] [-M+1, M-1] [−M+1,M−1](如M=7时,x轴相对位置为-6~6),无需为 M 2 × M 2 M^2×M^2 M2×M2个位置对都分配参数,只需参数化一个更小的矩阵 B ^ ∈ R ( 2 M − 1 ) × ( 2 M − 1 ) \hat{B} \in \mathbb{R}^{(2M-1) \times (2M-1)} B^∈R(2M−1)×(2M−1)(如M=7时为13×13),再通过索引映射得到 (B);
-
泛化性:预训练的 B ^ \hat{B} B^可通过双三次插值适配不同窗口大小,无需重新训练。
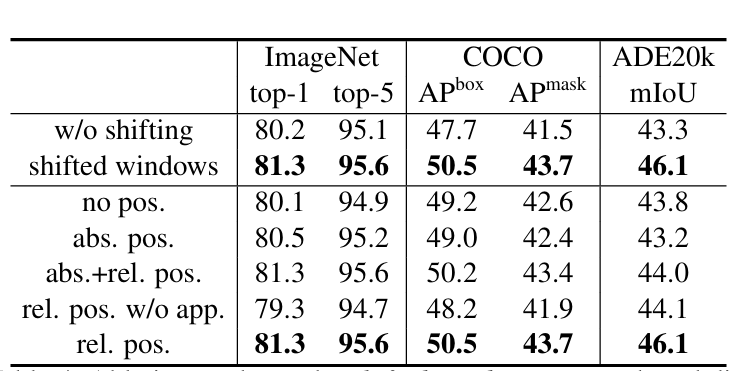
论文的消融实验证明,相对位置偏置能显著提升性能——在ADE20K分割任务中,相比无偏置的版本,mIoU提升2.3%。
3.3 架构变体:适配不同场景需求
Swin Transformer提供了4种架构变体,通过调整“初始特征维度C”和“各Stage的Block数量”,平衡性能与计算开销:
| 变体 | 初始维度C | 各Stage Block数量 | 参数量 | 适用场景 |
|---|---|---|---|---|
| Swin-T | 96 | [2, 2, 6, 2] | 29M | 轻量场景、边缘设备 |
| Swin-S | 96 | [2, 2, 18, 2] | 50M | 平衡性能与效率 |
| Swin-B | 128 | [2, 2, 18, 2] | 88M | 基准模型、大部分场景 |
| Swin-L | 192 | [2, 2, 18, 2] | 197M | 高精度场景、大模型需求 |
这些变体的复杂度与ResNet系列对应:Swin-T≈ResNet-50,Swin-S≈ResNet-101,方便开发者直接替换现有CNN Backbone。
4. 实验验证:Swin的性能碾压级表现
Swin Transformer在图像分类、目标检测、语义分割三大核心任务中均超越当时的SOTA模型,充分证明了其“通用Backbone”的能力。
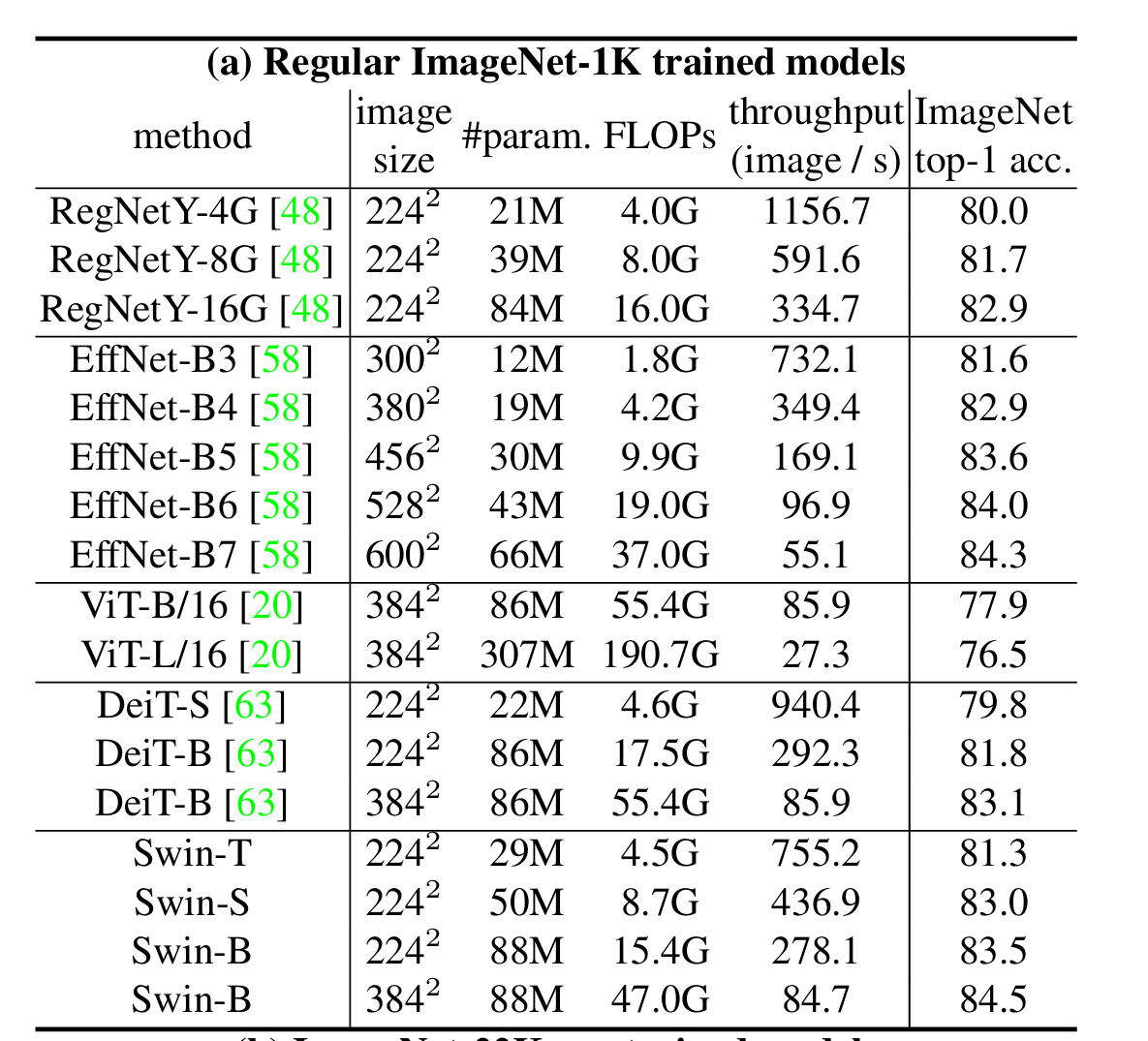
4.1 图像分类(ImageNet-1K)
- 最高性能:Swin-L(ImageNet-22K预训练)在384×384输入下达到87.3% top-1准确率,超越ViT-L(85.2%)和EfficientNet-B7(84.3%);
- 效率优势:相同复杂度下,Swin-T(81.3%)优于DeiT-S(79.8%),Swin-B(84.5%)优于DeiT-B(83.1%)。
- 常规训练结果;
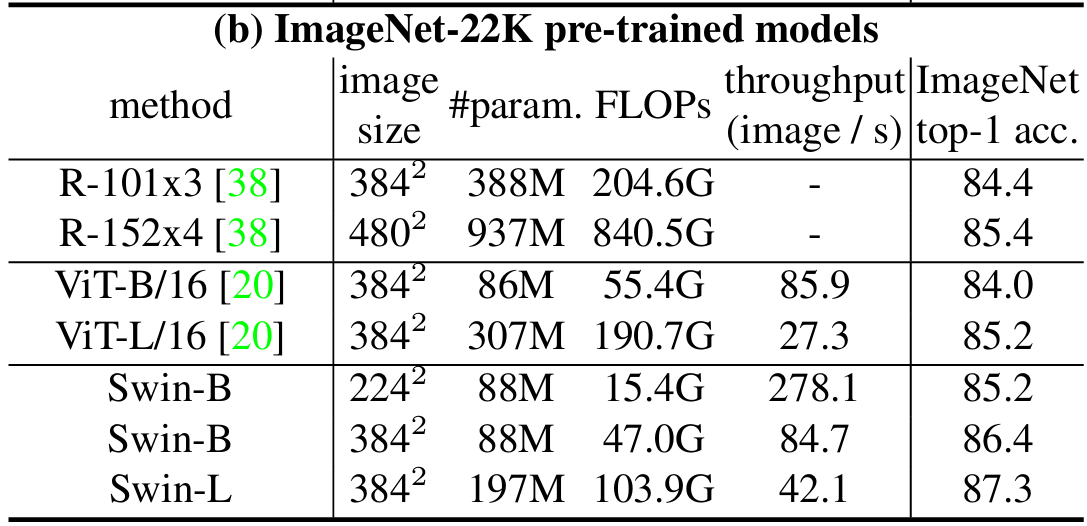
- ImageNet-22K预训练结果
4.2 目标检测与实例分割(COCO)
- 检测性能:Swin-L + HTC++框架在COCO test-dev集上达到58.7 box AP、51.1 mask AP,超越此前SOTA(Copy-paste的56.0 box AP、DetectoRS的48.5 mask AP);
- 对比ResNet:相同框架下,Swin-T(50.5 box AP)比ResNet-50(46.3 box AP)提升4.2 AP,且参数量相近。
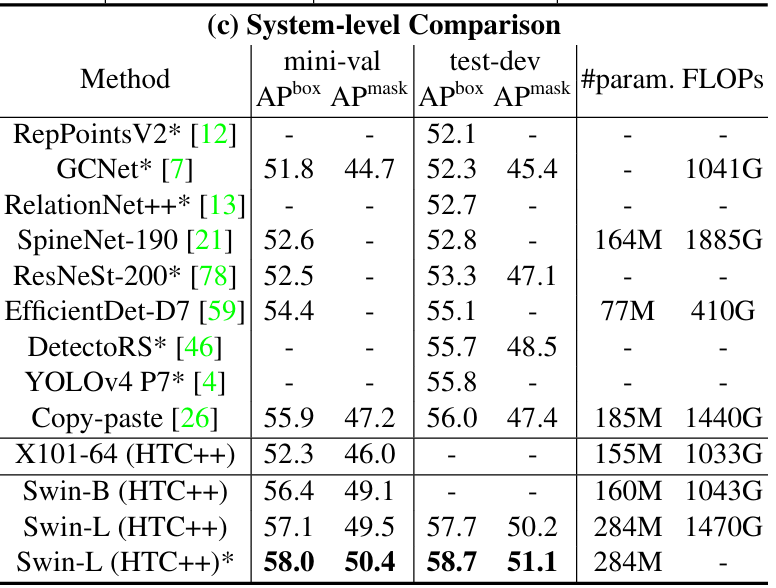
展示Swin在COCO检测任务上的SOTA表现
4.3 语义分割(ADE20K)
- 分割性能:Swin-L + UperNet在ADE20K val集上达到53.5 mIoU,超越SETR(50.3 mIoU)+3.2 mIoU;
- 对比DeiT:Swin-S(49.3 mIoU)比DeiT-S(44.0 mIoU)提升5.3 mIoU,计算开销相近。
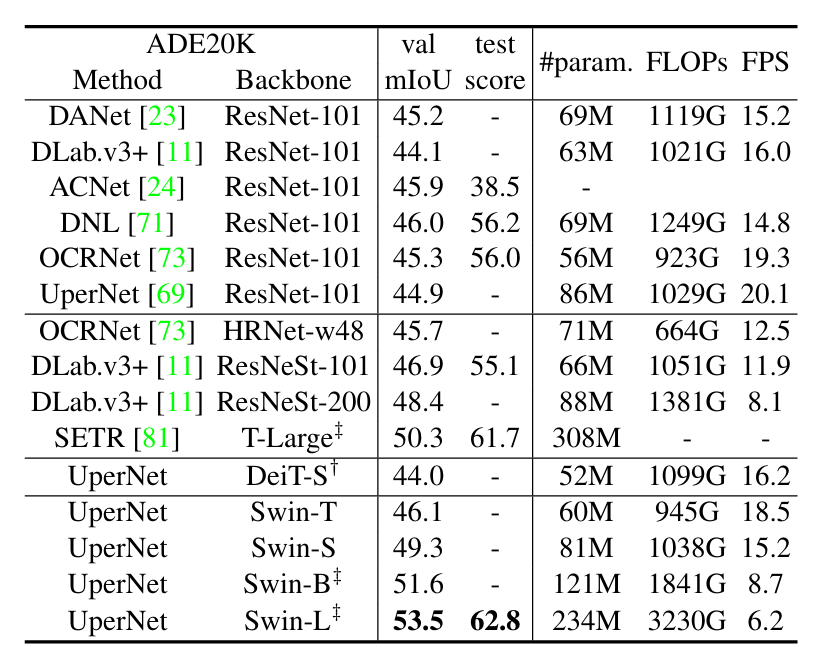
4.4 消融实验:核心设计的有效性验证
论文通过消融实验验证了关键设计的必要性(以Swin-T为例):
- 移位窗口:无移位时(仅用W-MSA),ImageNet top-1下降1.1%,COCO box AP下降2.8%,证明跨窗口连接的重要性;
- 相对位置偏置:无偏置时,ADE20K mIoU下降2.3%;使用绝对位置嵌入时,检测/分割性能反而下降,证明相对位置偏置更适配视觉任务;
- 循环移位优化:相比直接padding小窗口,循环移位+掩码使推理速度提升13%~18%,且性能无损。
5. 总结与展望
5.1 核心贡献
Swin Transformer的最大贡献是首次实现了Transformer在视觉任务中的“通用性”——它通过分层特征解决了密集预测适配问题,通过移位窗口解决了效率问题,最终让Transformer像CNN一样成为视觉任务的通用Backbone。具体贡献可概括为:
- 提出分层特征表示,适配分类、检测、分割等全场景视觉任务;
- 创新移位窗口自注意力,平衡线性计算复杂度与全局依赖建模能力;
- 设计相对位置偏置,提升空间建模精度与泛化性;
- 验证了Vision与NLP统一架构的可行性,为跨模态建模(如图文生成)奠定基础。
5.2 未来方向
Swin Transformer的设计思路已成为后续视觉Transformer的重要参考,未来可探索的方向包括:
- 窗口大小自适应:根据图像内容动态调整窗口大小(如前景区域用小窗口、背景区域用大窗口),进一步提升效率;
- 更高效的移位策略:简化循环移位+掩码的实现,降低硬件 latency;
- 轻量化优化:针对移动设备,设计更轻量的架构变体(如更小的C和窗口大小)。
6. 资源获取
- 官方代码:https://github.com/microsoft/Swin-Transformer(支持PyTorch,包含分类、检测、分割全场景实现);
- 预训练模型:提供ImageNet-1K/22K预训练权重,可直接用于下游任务微调;
- 配套工具:兼容MMDetection、MMSegmentation等主流视觉框架,替换Backbone即可使用。
Swin Transformer的出现,标志着视觉领域正式进入“CNN与Transformer并存”的时代。它不仅在性能上碾压传统CNN,更在架构上打通了视觉与NLP的壁垒——未来,我们可能会看到更多基于Transformer的统一架构,实现“一张网络搞定所有模态任务”的目标。
機器視覺:Swin Transformer 深度解讀
深度解讀Swin Transformer:分層特徵圖、移位視窗自注意力(SW-MSA)、相對位置偏置,對比ViT缺陷,涵蓋分類/檢測/分割實驗與消融分析。
來源:https://blog.csdn.net/2403_87969572/article/details/155241656
抓取時間(ISO本地):2026-05-18 05:17:22
文章目錄
1. 引言:視覺Backbone的演進與ViT的困境
在計算機視覺領域,卷積神經網路(CNN)長期佔據統治地位——從AlexNet的橫空出世,到ResNet、EfficientNet等架構的持續最佳化,CNN憑藉區域性感受野、權重共享等特性,在影象分類、檢測、分割等任務中展現出強大的適配性。但隨著自然語言處理(NLP)領域Transformer的爆發,研究者們開始探索將這種“注意力即一切”的架構遷移到視覺領域,核心代表便是Vision Transformer(ViT)。上一篇部落格中詳細介紹了Vision Transformer的提出以及原理,還不瞭解的可以看一下:機器視覺:Vision Transformer——打破CNN壟斷的視覺革命先鋒
ViT的核心思路是將影象分割為固定大小的補丁(Patch),視為“視覺token”後直接輸入Transformer編碼器,透過全域性自注意力建模token間依賴。這一突破證明了Transformer在視覺任務中的潛力,但它存在兩個致命缺陷,導致難以成為通用視覺Backbone:
- 單解析度特徵圖:ViT僅輸出單一低解析度特徵圖,無法適配目標檢測、語義分割等需要多尺度特徵的密集預測任務(這類任務依賴FPN、U-Net等多尺度融合結構);
- 二次計算複雜度:全域性自注意力的計算量與token數量(影象解析度)的平方成正比,面對高解析度影象(如512×512)時,計算開銷會急劇膨脹,無法落地應用。
正是為了解決這兩個核心問題,微軟亞洲研究院提出了Swin Transformer——一種基於“移位視窗”的分層視覺Transformer,它既保留了Transformer的全域性建模能力,又具備CNN的分層特徵和高效計算特性,最終成為首個能無縫適配分類、檢測、分割等全場景視覺任務的Transformer Backbone。
(a) 所提 Swin Transformer 透過在深層合併影象塊(灰色所示)構建分層特徵圖,且因僅在各區域性視窗(紅色所示)內計算自注意力,其計算複雜度與輸入影象尺寸呈線性關係,因此可作為適用於影象分類和密集型識別任務的通用骨幹網路。(b) 相比之下,早期視覺 Transformer [20] 僅生成單一低解析度特徵圖,且由於需計算全域性自注意力,其計算複雜度與輸入影象尺寸呈二次關係
2. 核心創新點總覽
Swin Transformer的成功源於兩個革命性設計,再加上細節最佳化,共同實現了“高效+通用”的目標:
- 分層特徵表示(Hierarchical Feature Maps):模仿CNN的多尺度特徵構建方式,透過“補丁合併”(Patch Merging)逐步減少token數量、提升特徵維度,輸出與CNN一致的多解析度特徵圖(1/4、1/8、1/16、1/32下取樣率),完美適配密集預測任務;
- 移位視窗自注意力(Shifted Window Self-Attention):將自注意力的計算限制在區域性非重疊視窗內(降低複雜度),同時透過視窗移位建立跨視窗連線(保證建模能力),實現“線性複雜度+全域性依賴建模”的平衡;
- 細節最佳化:相對位置偏置(提升空間建模精度)、迴圈移位+掩碼(高效處理移位視窗)等,進一步強化效能與效率。
3. 原理詳解:一步步拆解Swin Transformer
3.1 整體架構:分層特徵的構建邏輯
Swin Transformer的整體架構與CNN類似,透過4個Stage逐步構建分層特徵,每個Stage包含“補丁合併”(僅前3個Stage有)和“多個Swin Transformer Block”。以基礎版Swin-T(Tiny)為例,架構流程如下:
(a)展示從輸入影象到4個Stage的特徵演變;(b)展示W-MSA(常規視窗注意力)和SW-MSA(移位視窗注意力)的交替使用。
第一步:輸入處理與Patch Embedding
- Patch Partition(補丁劃分):將輸入RGB影象(如224×224×3)劃分為非重疊的4×4補丁(Patch)。每個補丁包含4×4×3=48個畫素值,整個影象會被劃分為(224/4)×(224/4)=56×56個補丁,即56×56個“視覺token”;
- Linear Embedding(線性嵌入):透過一個線性層將每個48維的補丁特徵對映到指定維度C(Swin-T中C=96),最終得到56×56×96的特徵圖。這一步對應ViT的Patch Embedding,但Swin的補丁更小(4×4 vs ViT的16×16),為後續分層特徵奠定基礎。
第二步:Stage 1~4:分層特徵的遞進
Swin的4個Stage逐步降低特徵圖解析度、提升特徵維度,過程如下:
| Stage | 核心操作 | 輸入特徵 | 輸出特徵 | 作用 |
|---|---|---|---|---|
| 1 | 2個Swin Block | 56×56×96 | 56×56×96 | 初步特徵提取,無下采樣 |
| 2 | Patch Merging + 2個Swin Block | 56×56×96 | 28×28×192 | 下采樣2倍,特徵維度翻倍 |
| 3 | Patch Merging + 6個Swin Block | 28×28×192 | 14×14×384 | 下采樣2倍,特徵維度翻倍 |
| 4 | Patch Merging + 2個Swin Block | 14×14×384 | 7×7×768 | 下采樣2倍,特徵維度翻倍 |
關鍵模組解釋:
- Patch Merging(補丁合併):實現下采樣的核心操作。將2×2相鄰的4個補丁的特徵拼接(如56×56×96 → 28×28×(96×4)),再透過一個線性層將維度減半(96×4 → 192),最終得到28×28×192的特徵圖。這一步既減少了token數量(4倍減少),又提升了特徵的感受野;
- Swin Transformer Block:每個Block是特徵變換的核心,結構為“LN → 注意力模組 → 殘差連線 → LN → MLP → 殘差連線”。與標準Transformer Block的區別在於:注意力模組交替使用W-MSA(常規視窗注意力) 和SW-MSA(移位視窗注意力)(如上圖(b)所示),透過這種交替建立跨視窗連線。
3.2 核心:移位視窗自注意力(SW-MSA)
這是Swin Transformer最具創新性的部分,直接解決了ViT的“複雜度高”和“無跨視窗連線”兩大問題。我們分5步拆解其設計邏輯:
第一步:為什麼要“區域性視窗”?—— 複雜度的降維打擊
全域性自注意力的計算複雜度是ViT的致命傷,其公式為:
Ω ( M S A )
4
h
w
C
2
+
2
(
h
w
)
2
C
\Omega(MSA) = 4hwC^2 + 2(hw)^2C
Ω(MSA)=4hwC2+2(hw)2C
其中,
h
w
hw
hw是token數量(如56×56=3136),
C
C
C 是特徵維度。可以看到,複雜度與 (hw) 的平方成正比(二次複雜度)——當影象解析度提升到512×512時,(hw=128×128=16384),((hw)^2) 會達到2.68億,計算量完全無法承受。
Swin的解決方案是區域性視窗注意力(W-MSA):將特徵圖劃分為非重疊的區域性視窗,僅在每個視窗內計算自注意力。假設視窗大小為 M × M M×M M×M(預設M=7),則每個視窗包含 M 2 M^2 M2 個token,複雜度公式變為:
Ω ( W − M S A )
4
h
w
C
2
+
2
M
2
h
w
C
\Omega(W-MSA) = 4hwC^2 + 2M^2hwC
Ω(W−MSA)=4hwC2+2M2hwC
此時,複雜度與
h
w
hw
hw成正比(線性複雜度)——因為
M
M
M 是固定值(如7),
M
2
49 M^2=49 M2=49是常數。同樣以512×512影象為例,計算量會從“億級”降至“百萬級”,效率提升顯著。
第二步:常規視窗的問題——缺乏跨視窗連線
區域性視窗雖然高效,但視窗間是孤立的——一個視窗內的token無法與其他視窗的token建立注意力連線,導致模型難以建模長距離依賴(比如影象中跨視窗的物體),建模能力受限。
第三步:移位視窗(SW-MSA)—— 建立跨視窗連線
為了解決視窗孤立問題,Swin提出“移位視窗”策略:在連續的Swin Block中,交替使用“常規視窗”和“移位視窗”。具體操作是:
- 第l層Block使用常規視窗(W-MSA):視窗從特徵圖左上角開始,均勻劃分;
- 第l+1層Block使用移位視窗(SW-MSA):將視窗沿x軸和y軸各移位 ⌊ M / 2 ⌋ \lfloor M/2 \rfloor ⌊M/2⌋個畫素(如M=7時移位3個畫素)。
移位後,新視窗會跨越原視窗的邊界,自然建立起不同視窗間的token連線。例如,原視窗A和視窗B的邊界token,在移位後的視窗中會被劃入同一個視窗,從而實現注意力互動。
第四步:高效批次計算——迴圈移位+掩碼
移位視窗雖然解決了連線問題,但會帶來新的麻煩:移位後視窗數量會增加,且部分視窗會小於 M × M M×M M×M(比如特徵圖邊緣的視窗)。以8×8特徵圖、M=4為例:
- 常規視窗:(8/4)×(8/4)=2×2=4個視窗(均為4×4);
- 移位視窗:(8/4 +1)×(8/4 +1)=3×3=9個視窗(邊緣視窗為2×2)。
如果直接對9個視窗計算注意力,會產生大量小視窗,導致計算效率低、記憶體訪問碎片化。Swin提出“迴圈移位(Cyclic Shift)+ 掩碼(Masking)”的高效解決方案,步驟如下:
展示如何透過迴圈移位將小視窗拼接為完整視窗,再透過掩碼遮蔽無效注意力。
- 迴圈移位:將特徵圖沿x軸和y軸迴圈移位 ⌊ M / 2 ⌋ \lfloor M/2 \rfloor ⌊M/2⌋ 個畫素,原本分散在邊緣的小視窗會被拼接成完整的 (M×M) 視窗;
- 合併視窗:拼接後,視窗數量恢復為常規視窗的數量(如2×2=4個),可批次計算注意力;
- 掩碼遮蔽:由於迴圈移位後,部分視窗內的token來自原特徵圖的不同區域(並非真實相鄰),需要用一個二進位制掩碼遮蔽這些“無效連線”——讓這些token間的注意力權重為-∞(SoftMax後接近0),避免虛假依賴;
- 反向迴圈移位:注意力計算完成後,將特徵圖反向迴圈移位,恢復到原始位置。
透過這四步,既能保證跨視窗連線,又能維持與常規視窗相同的計算效率,完美解決了移位視窗的工程實現問題。
第五步:相對位置偏置——提升空間建模精度
自注意力機制本身是“位置無關”的——它只關注token間的內容相似性,不考慮空間位置關係。ViT透過新增“絕對位置嵌入”解決這一問題,但絕對位置嵌入存在兩個缺陷:
- 缺乏平移不變性:訓練時學到的“位置1”的嵌入,無法泛化到其他位置;
- 不適配不同視窗大小:如果微調時改變視窗大小,預訓練的絕對位置嵌入會失效。
Swin提出相對位置偏置(Relative Position Bias),直接建模視窗內token的相對位置關係。具體設計如下:
-
在自注意力計算中加入偏置項 (B),公式為:
A t t e n t i o n ( Q , K , V )
S o f t M a x ( Q K T d + B ) V Attention(Q, K, V) = SoftMax\left( \frac{QK^T}{\sqrt{d}} + B \right) V Attention(Q,K,V)=SoftMax(d QKT+B)V
其中, B ∈ R M 2 × M 2 B \in \mathbb{R}^{M^2 \times M^2} B∈RM2×M2 是相對位置偏置矩陣, M 2 M^2 M2 是視窗內token的數量(如M=7時為49); -
引數高效化:由於token的相對位置範圍是 [ − M + 1 , M − 1 ] [-M+1, M-1] [−M+1,M−1](如M=7時,x軸相對位置為-6~6),無需為 M 2 × M 2 M^2×M^2 M2×M2個位置對都分配引數,只需引數化一個更小的矩陣 B ^ ∈ R ( 2 M − 1 ) × ( 2 M − 1 ) \hat{B} \in \mathbb{R}^{(2M-1) \times (2M-1)} B^∈R(2M−1)×(2M−1)(如M=7時為13×13),再透過索引對映得到 (B);
-
泛化性:預訓練的 B ^ \hat{B} B^可透過雙三次插值適配不同視窗大小,無需重新訓練。
論文的消融實驗證明,相對位置偏置能顯著提升效能——在ADE20K分割任務中,相比無偏置的版本,mIoU提升2.3%。
3.3 架構變體:適配不同場景需求
Swin Transformer提供了4種架構變體,透過調整“初始特徵維度C”和“各Stage的Block數量”,平衡效能與計算開銷:
| 變體 | 初始維度C | 各Stage Block數量 | 引數量 | 適用場景 |
|---|---|---|---|---|
| Swin-T | 96 | [2, 2, 6, 2] | 29M | 輕量場景、邊緣裝置 |
| Swin-S | 96 | [2, 2, 18, 2] | 50M | 平衡效能與效率 |
| Swin-B | 128 | [2, 2, 18, 2] | 88M | 基準模型、大部分場景 |
| Swin-L | 192 | [2, 2, 18, 2] | 197M | 高精度場景、大模型需求 |
這些變體的複雜度與ResNet系列對應:Swin-T≈ResNet-50,Swin-S≈ResNet-101,方便開發者直接替換現有CNN Backbone。
4. 實驗驗證:Swin的效能碾壓級表現
Swin Transformer在影象分類、目標檢測、語義分割三大核心任務中均超越當時的SOTA模型,充分證明了其“通用Backbone”的能力。
4.1 影象分類(ImageNet-1K)
- 最高效能:Swin-L(ImageNet-22K預訓練)在384×384輸入下達到87.3% top-1準確率,超越ViT-L(85.2%)和EfficientNet-B7(84.3%);
- 效率優勢:相同複雜度下,Swin-T(81.3%)優於DeiT-S(79.8%),Swin-B(84.5%)優於DeiT-B(83.1%)。
- 常規訓練結果;
- ImageNet-22K預訓練結果
4.2 目標檢測與例項分割(COCO)
- 檢測效能:Swin-L + HTC++框架在COCO test-dev集上達到58.7 box AP、51.1 mask AP,超越此前SOTA(Copy-paste的56.0 box AP、DetectoRS的48.5 mask AP);
- 對比ResNet:相同框架下,Swin-T(50.5 box AP)比ResNet-50(46.3 box AP)提升4.2 AP,且引數量相近。
展示Swin在COCO檢測任務上的SOTA表現
4.3 語義分割(ADE20K)
- 分割效能:Swin-L + UperNet在ADE20K val集上達到53.5 mIoU,超越SETR(50.3 mIoU)+3.2 mIoU;
- 對比DeiT:Swin-S(49.3 mIoU)比DeiT-S(44.0 mIoU)提升5.3 mIoU,計算開銷相近。
4.4 消融實驗:核心設計的有效性驗證
論文透過消融實驗驗證了關鍵設計的必要性(以Swin-T為例):
- 移位視窗:無移位時(僅用W-MSA),ImageNet top-1下降1.1%,COCO box AP下降2.8%,證明跨視窗連線的重要性;
- 相對位置偏置:無偏置時,ADE20K mIoU下降2.3%;使用絕對位置嵌入時,檢測/分割效能反而下降,證明相對位置偏置更適配視覺任務;
- 迴圈移位最佳化:相比直接padding小視窗,迴圈移位+掩碼使推理速度提升13%~18%,且效能無損。
5. 總結與展望
5.1 核心貢獻
Swin Transformer的最大貢獻是首次實現了Transformer在視覺任務中的“通用性”——它透過分層特徵解決了密集預測適配問題,透過移位視窗解決了效率問題,最終讓Transformer像CNN一樣成為視覺任務的通用Backbone。具體貢獻可概括為:
- 提出分層特徵表示,適配分類、檢測、分割等全場景視覺任務;
- 創新移位視窗自注意力,平衡線性計算複雜度與全域性依賴建模能力;
- 設計相對位置偏置,提升空間建模精度與泛化性;
- 驗證了Vision與NLP統一架構的可行性,為跨模態建模(如圖文生成)奠定基礎。
5.2 未來方向
Swin Transformer的設計思路已成為後續視覺Transformer的重要參考,未來可探索的方向包括:
- 視窗大小自適應:根據影象內容動態調整視窗大小(如前景區域用小視窗、背景區域用大視窗),進一步提升效率;
- 更高效的移位策略:簡化迴圈移位+掩碼的實現,降低硬體 latency;
- 輕量化最佳化:針對移動裝置,設計更輕量的架構變體(如更小的C和視窗大小)。
6. 資源獲取
- 官方程式碼:https://github.com/microsoft/Swin-Transformer(支援PyTorch,包含分類、檢測、分割全場景實現);
- 預訓練模型:提供ImageNet-1K/22K預訓練權重,可直接用於下游任務微調;
- 配套工具:相容MMDetection、MMSegmentation等主流視覺框架,替換Backbone即可使用。
Swin Transformer的出現,標誌著視覺領域正式進入“CNN與Transformer並存”的時代。它不僅在效能上碾壓傳統CNN,更在架構上打通了視覺與NLP的壁壘——未來,我們可能會看到更多基於Transformer的統一架構,實現“一張網路搞定所有模態任務”的目標。
Computer Vision: An In-Depth Discussion of Swin Transformer
Deep dive into Swin Transformer: hierarchical maps, shifted-window attention, vs ViT limits, with classification/detection/segmentation benchmarks.
Captured at (ISO local): 2026-05-18 05:17:22
1. Introduction: Evolution of Vision Backbones and ViT’s Limitations
Convolutional neural networks (CNNs) long dominated practical computer vision—from AlexNet to ResNet, EfficientNet—exploiting local receptive fields plus weight-sharing to flourish across classification, detection, segmentation, etc. When Transformers matured in NLP, researchers began porting attention-first paradigms to vision, culminating in Vision Transformer (ViT). The previous instalment unpacked ViT genesis & mechanics—for background see:
Computer Vision: Vision Transformer—trailblazing Transformer vision.
ViT flattens the image into fixed-size patches interpreted as tokens, stacking standard Transformer encoder blocks with global self-attention bridging every patch pair. Demonstrating feasibility unlocked huge potential—but two structural weaknesses prevent ViT replacing CNNs universally:
- Single-resolution feature map: ViT emits one comparatively low-resolution latent grid, ill-suited to dense localization tasks demanding multi-scale pyramid features (think FPN/U-Net scaffolding).
- Quadratic cost: Complexity scales with (\mathcal{O}((HW)^2)) token interactions—moving from 224² to 512² blows memory & FLOPs untenably because token count climbs quadratically in area.
Against that backdrop MSR Asia introduced Swin Transformer—“Shifted window Transformer”—layering hierarchies like ConvNets while retaining Transformers’ expressive affinity modeling. Alternate window / shifted-window attention restrains pairwise computation inside local (M×M) windows yet periodically re-wires coupling across windows, marrying near-linear cost vs. resolution with global reasoning depth. Consequently Swin emerged as arguably the earliest general-purpose Transformer backbone smoothly plug-replacing CNNs across classification and detection and semantic segmentation workloads.
(a) The proposed Swin hierarchy progressively merges patch tokens (gray) deepening layers; because self-attention is localized within red windows complexity tracks linearly with spatial size—usable backbone for classification and dense prediction.
(b) Early ViT produced a single low-resolution map incurring quadratic global-attention dependence on resolution.
2. Core Innovations Overview
Swin owes success synergistically to two headline ideas complemented by nuanced engineering polish:
- Hierarchical feature maps: Mirrors CNN pyramid construction—patch merging sequentially halves spatial resolution while doubling channel width yielding multi-scale (\tfrac14,\tfrac18,\tfrac1{16},\tfrac1{32}) stride maps analogous to canonical ResNet stage geometry—plug-friendly for detectors/segmenters.
- Shifted window self-attention: Restrict attention within non-overlapping local windows (W-MSA) for linear-ish scaling versus area, insert SW-MSA blocks staggering window grids so tokens originally separated reconcile inside shared windows—balancing efficiency & receptive mixing.
- Details matter: Relative positional bias strengthens spatial inductive biases; cyclic shift plus attention masking implements SW-MSA batch-efficiently.
3. Principle Walkthrough—Decomposing Swin Transformer
3.1 Overall architecture—the mechanics of hierarchies
Swin parallels CNN funnel geometry—four successive Stages each combining optional patch merging (first three stages) then stacked Swin Transformer blocks. Focusing on vanilla Swin-T (Tiny):
(a) Spatial resolution/channel depth evolution Stage1→Stage4
(b) Alternation between conventional window (W-MSA) versus shifted grids (SW-MSA) inside residual blocks
Stage 1—Patch embedding & partitioning
- Patch partition: Divide RGB (224×224×3) into non-overlapping (4×4) patches ⇒ each patch gathers (4×4×3 = 48) raw intensities ⇒ (56×56) grid of tokens analogous to latent “pixels.”
- Linear embedding: A linear layer lifts 48-D raw vectors to embedding width (C) (Swin-T uses (C=96)) producing tensor shaped (56×56×96). Mirrors ViT patch projection yet uses smaller native patch size enriching fine-scale early detail.
Progressive stages 1–4
Stages shrink spatial extents while deepening channels:
| Stage | Composition | Spatial extant | Remarks |
|---|---|---|---|
| 1 | 2× Swin blocks | 56×56×96 | No downsampling—light feature mixing |
| 2 | Patch merge + 2 blocks | 28×28×192 | Spatial ÷2, channels ×2 |
| 3 | Patch merge + 6 blocks | 14×14×384 | Further pooling depth |
| 4 | Patch merge + 2 blocks | 7×7×768 | Deepest bottleneck tokens |
Interpretation:
- Patch merging: Groups each (2×2) neighbourhood of spatial tokens concatenating (4) channel vectors ⇒ linear projection halves aggregate width ⇒ reduces tokens 4× while enlarging receptive context analogously stride-2 convolution.
- Swin Transformer block: Standard pre-norm residuals
LN → Attention → LN → MLPbut attention submodule alternates W-MSA then SW-MSA, achieving cross-window information flow across depth (panel (b) above).
3.2 Core—Shifted-window self-attention (SW-MSA)
Innovation epicenter bridging ViT critiques—five explanatory beats:
Step A—why local windows? Complexity relief
Global Multihead Self Attention (MSA) complexity roughly:
$$ \Omega(\mathrm{MSA}) = 4hwC^{2} + 2(hw)^2 C $$
(hw) token count (e.g. (56×56=3136)), embedding (C). Quadratic ( (hw)^2 ) dominates at moderate resolutions—for (128×128) tokens ((hw=16384)) pairwise term explodes (\approx \mathcal{O}(2.7×10^{8})) MAC-like interactions—problematic training/inference budgets.
W-MSA partitions map into disjoint (M×M) windows (default (M=7 ⇒ 49) tokens/window):
$$ \Omega(\text{W-MSA}) = 4hwC^{2} + 2 M^{2} hw C $$
Now linear in (hw) holding (M) fixed—bringing million-scale rather than hundred-million brute interactions realistic @ high resolution.
Step B—plain windows isolation hazard
Pure W-MSA prohibits attention across window borders—tokens cannot associate objects spanning seams— crippling relational modeling albeit cheap.
Step C—shift reconnects neighbourhoods
Adjacent Swin blocks alternate:
- Layer (\ell) W-MSA: windows anchored grid-aligned from top-left uniform tiling.
- Layer (\ell+1) SW-MSA: shift window partitioning by (\lfloor M/2 \rfloor) along x & y (e.g., +3 offsets when (M=7)).
Misaligned tiling causes previously disjoint neighbouring windows to jointly appear inside relocated windows yielding cross-boundary pairwise attention without abandoning locality benefits.
Step D—efficient batches via cyclic shifts & masking
Naïve shifting sprouts irregular partial windows—count explosion & padding waste. Canonical trick:
- Cyclic translation along axes by (\lfloor M/2 \rfloor).
- Regroup tiles reconstructing canonical window count—all windows square (M×M) again for batched matmul GEMM efficiency.
- Attention mask: Suppress pairwise scores crossing artificial stitched seams (set offending logits ( -\infty ⇒ ) softmax ≈ 0 ).
- Inverse cyclic translation restores original coordinate ordering post-attention.
Thus SW-MSA shares computational envelope with W-MSA while preserving correctness.
Step E—relative positional bias sharpening geometry
Attention default permutation invariant—spatial structure must be injected. Absolute sinusoidal / learned absolute embeddings (ViT baseline) hamper translation generalization / dynamic window resizing.
Swin relative bias augments logits:
$$ \mathrm{Attention}(Q,K,V)=\mathrm{softmax}\left(\frac{QK^\top}{\sqrt{d}} + B\right)V $$
Learned (\hat{B} \in \mathbb{R}^{(2M-1)\times (2M-1)}) parameterized compactly indexing pairwise relative axial offsets (\in{-(M-1),\dots,M-1}) yielding dense (M^2×M^2) effective bias lookup table without storing full tensor blindly.
Upsampling (\hat{B}) via bicubic interpolation accommodates fine-tuned alternate window extents—strong transfer story.
Paper ablations: Removing bias degraded ADE20K mIoU about ** −2.3 pts** emphasizing necessity.
3.3 Variants aligning compute budgets
Families trade width & depth balancing accuracy vs throughput:
| Model | Emb. (C) | Blocks / stage [S1,S2,S3,S4] | Params | Commentary |
|---|---|---|---|---|
| Swin-T | 96 | [2, 2, 6, 2] | 29 M | Mobile / constrained |
| Swin-S | 96 | [2, 2, 18, 2] | 50 M | Sweet spot prototyping |
| Swin-B | 128 | [2, 2, 18, 2] | 88 M | Baseline heavyweight |
| Swin-L | 192 | [2, 2, 18, 2] | 197 M | Accuracy maximal |
Operational FLOPs often compared against ResNet-50 / 101 analogues simplifying backbone swaps historically CNN pipelines.
4. Experiments—state-of-art breadth
Demonstrated dominance across cardinal vision tasks simultaneously—true general-purpose backbone.
4.1 Image classification (ImageNet-1K)
- Peak: Swin-L (init from IN-22k) (384) crop hits 87.3 % top‑1 edging ViT‑L (85.2 %) & EfficientNet‑B7 (84.3 %).
- Like-for-like budget: Swin‑T (81.3 %) tops DeiT‑S (79.8 %); Swin‑B (84.5 %) tops DeiT‑B (83.1 %).
Routine training leaderboard
IN-22K pretrain fine-tuned snapshot
4.2 Object detection & instance segmentation (COCO)
- Swin‑L backbone + HTC++ attains 58.7 bbox AP, 51.1 mask AP on
test-devsurpassing predecessors (Copy‑Paste ensemble / DetectoRS). - Same detector head swapping ResNet‑50→Swin‑T ⇒ +4.2 bbox AP (≈ ResNet‑50 param parity).
Performance curve
4.3 Semantic segmentation (ADE20K val)
- Swin‑L + UPerNet ⇒ 53.5 mIoU versus SETR (50.3).
- Swin‑S (49.3) surpasses comparable DeiT‑S (44.0) with similar throughput.
Visualization
4.4 Ablations (Swin‑T surrogate)
Removing shifts (only W‑MSA) drops ** −1.1 % ImageNet**, ** −2.8 bbox AP**, underscoring cross-window wiring importance; stripping positional bias slashes ADE20K ** −2.3 mIoU** whereas absolute embeddings hurt detection/segmentation—endorsing relative parametrization; cyclic shift masking accelerates inference ≈ 13‑18 % without accuracy penalty vs naive padded windows.
Ablative chart
5. Conclusions & Outlook
5.1 Principal contributions distilled
Transformers matured into general visual encoders:
- Hierarchical latent pyramids unify dense prediction + global classification ergonomics historically splintered.
- Shifted-window attention couples linear-ish scaling vs resolution with deepening effective receptive breadth.
- Relative positional bias injects critical spatial inductive structure surpassing naive absolute embeddings in downstream geometry-sensitive tasks.
Cross-pollinates NLP+Vison architectural unification groundwork—multimodal modeling tailwinds.
5.2 Forward-looking motifs
Potential research vectors:
- Adaptive window geometries responsive to semantics (small windows on foreground clutter, coarse background windows).
- Hardware-friendlier shift policies trimming latency vs batched GEMM quirks.
- Mobile-first narrow-width / small-window distilled variants bridging edge deployment constraints.
6. Resources
- Official repository: https://github.com/microsoft/Swin-Transformer (PyTorch reference training recipes classification/detection/segmentation).
- Checkpoints pretrained IN‑1K & IN‑22k seed downstream finetuning.
- Integrates with MMDetection / MMSegmentation—swap backbone constructors quickly.
Emergence of Swin marks era where CNNs & Transformers coexist competitively—beyond raw accuracy the architectural dialogue dissolves modality silos anticipating unified multimodal foundational models bridging vision+NLP horizons.