机器视觉:视觉大模型——从技术突破到产业革新的全面解析
系统梳理视觉大模型相对传统小模型的能力跃迁:数据与算力范式、代表性架构路线、在多模态与工业检测中的优劣,以及如何把它放进真实成本与 SLA 的工程评估。
前言
当我们用手机扫码支付时的人脸识别、自动驾驶汽车对路况的实时判断、医生借助AI辅助分析医学影像、设计师通过文本指令生成创意图像——这些看似无关的场景,背后都离不开同一类核心技术的支撑:视觉大模型。
在自然语言大模型掀起AI革命之后,视觉大模型正以同样迅猛的势头重塑计算机视觉领域。作为人工智能感知世界的”眼睛”,视觉大模型打破了传统视觉算法”一任务一模型”的局限,通过大规模数据训练和先进架构设计,实现了从图像识别到场景理解、从被动感知到主动决策的能力跃升。它不仅让机器具备了接近人类的视觉认知水平,更成为连接物理世界与数字世界的关键桥梁,推动千行百业的智能化转型。
本文将从定义、研究现状、技术分支、产业应用等维度,带您全面读懂视觉大模型的技术内核与发展脉络。
一、视觉大模型的核心定义
视觉大模型(Visual Large Model)本质上是一类基于基础模型(Foundational Models) 理念构建的人工智能系统,其核心定义可概括为:通过自监督或半监督学习方式,在海量视觉数据(图像、视频)及多模态数据(文本-图像、音频-视频等)上训练,具备大规模参数规模和强泛化能力,能够自适应解决多种下游视觉任务的通用型模型。
这一定义包含三个关键特征,区别于传统计算机视觉模型:
- 通用泛化性:无需针对特定任务重新训练,通过提示工程(Prompt Engineering)或少量微调即可适配目标检测、语义分割、图像生成等多种任务,实现零样本/少样本学习;
- 大规模基础:训练数据量通常达到数千万至数十亿级,模型参数规模从亿级到千亿级不等,通过数据与参数的双重规模效应实现能力涌现;
- 多模态融合:打破单一视觉模态局限,普遍集成文本、音频等信息,实现跨模态语义对齐与交互(如文本生成图像、图像描述生成)。
其技术根源可追溯至Transformer架构在视觉领域的应用(如ViT模型),通过将图像转化为序列数据进行处理,解决了传统CNN模型在长距离依赖建模上的不足,为大规模视觉模型的发展奠定了基础。
二、视觉大模型的研究现状
视觉大模型的研究已从早期的单模态建模,发展为多模态融合、细粒度感知与决策推理并重的新阶段,关键突破集中在以下三大方向:
1. 基础架构与训练范式成熟化
- Transformer主导架构:ViT(Vision Transformer)的提出开启了视觉大模型的新时代,后续衍生出Swin Transformer、MAE(掩码自编码器)等优化架构,在保持模型性能的同时提升计算效率。智源团队的EVA模型通过融合CLIP的语义学习与MIM的几何结构学习,仅用十亿参数便实现了领先的视觉表示能力;
- 训练目标多元化:对比式学习(如CLIP的图像-文本对比损失)解决了多模态对齐问题,生成式学习(如扩散模型、掩码语言建模)强化了内容生成能力,而强化学习(RLHF、GRPO)则通过人类反馈或可验证奖励提升模型决策的可靠性;
- 数据利用高效化:从依赖人工标注数据转向大规模弱监督/无监督数据,通过Web爬取的图像-文本对(如CLIP使用的WebImageText)、伪标签数据(如GLIP、SA-1B)构建训练集,降低数据标注成本。
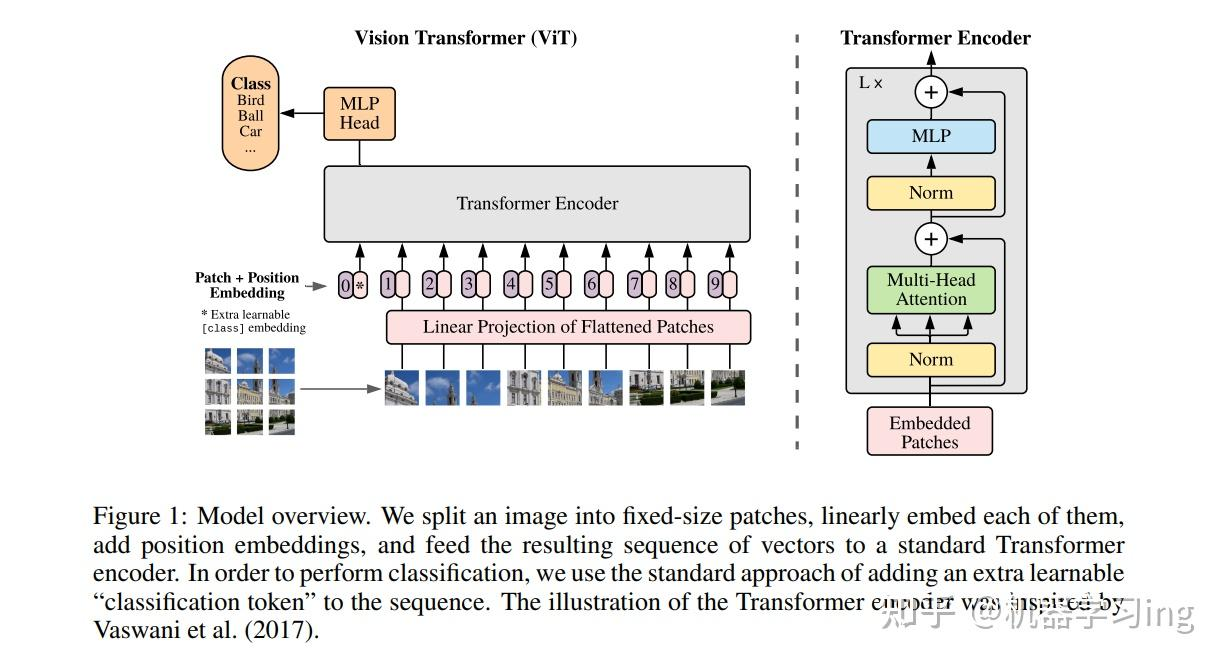
图 1:模型整体架构我们将图像分割为固定大小的补丁块(fixed-size patches),对每个补丁块进行线性嵌入(linearly embed),添加位置嵌入(position embeddings),并将得到的向量序列输入标准 Transformer 编码器。为实现分类功能,我们采用主流方案:在序列中额外添加一个可学习的 “分类令牌(classification token)”。Transformer 编码器的示意图设计灵感源自 Irwan Vaswani 等人(2017 年)的研究 [1]。
2. 关键模型与技术突破
近年来,一批具有里程碑意义的视觉大模型相继问世,推动技术边界持续拓展:
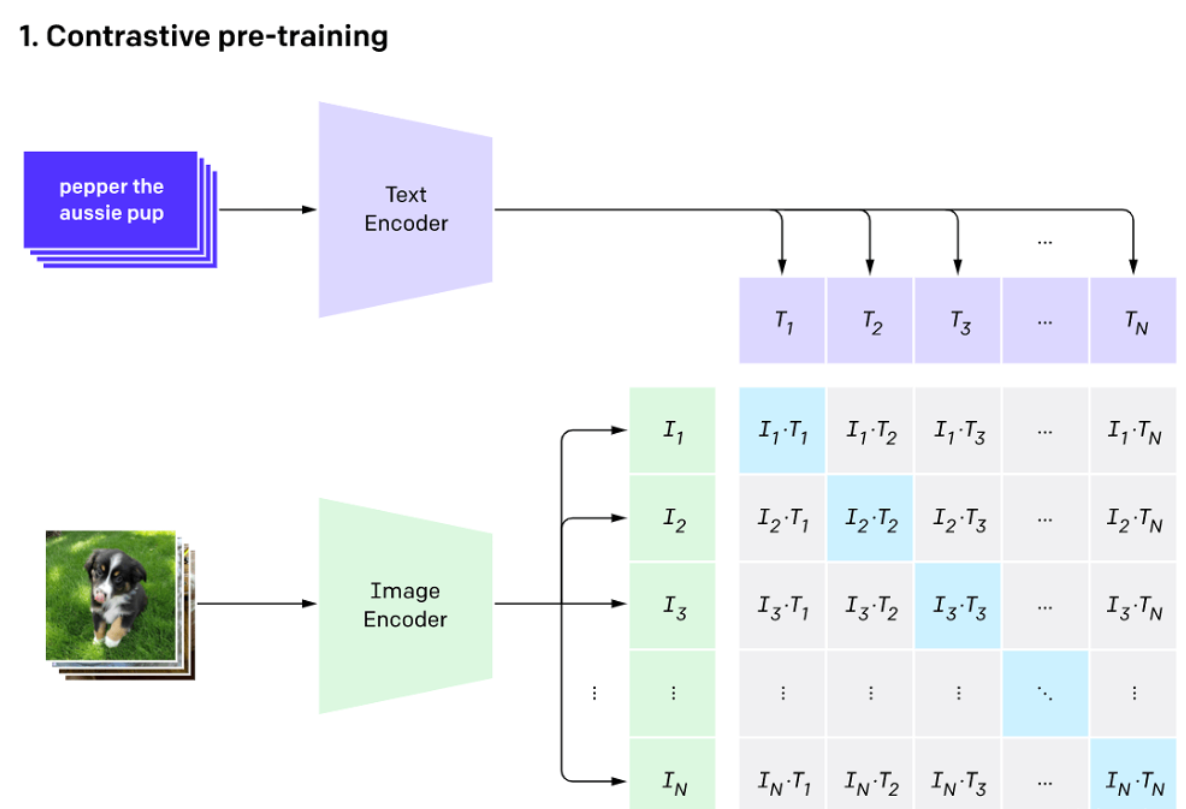
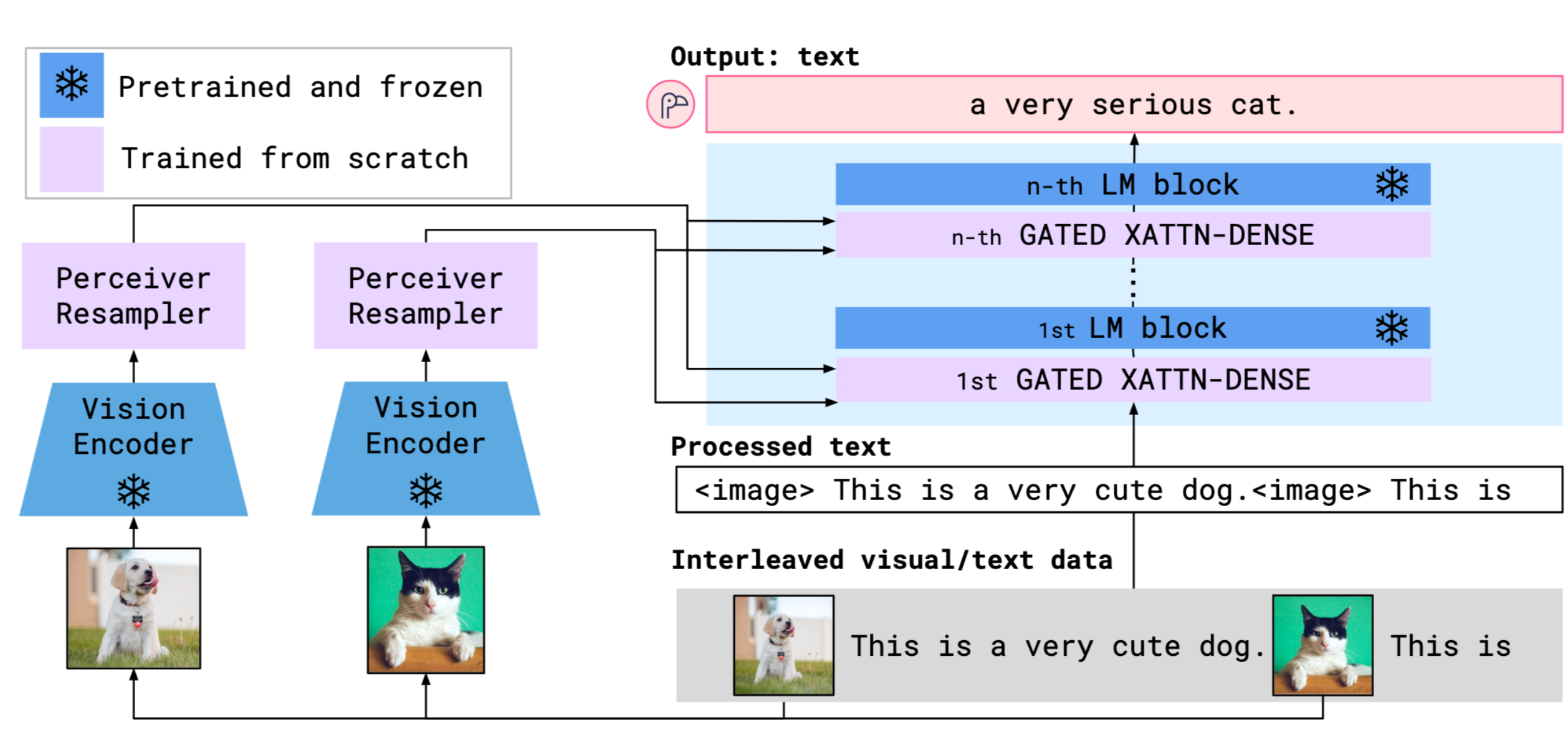
- 多模态对齐模型:OpenAI的CLIP首次实现了文本与图像的深度语义对齐,使模型能够通过自然语言提示完成零样本分类;Google的Flamingo通过Perceiver Resampler连接视觉与语言模型,提升了跨模态推理能力;
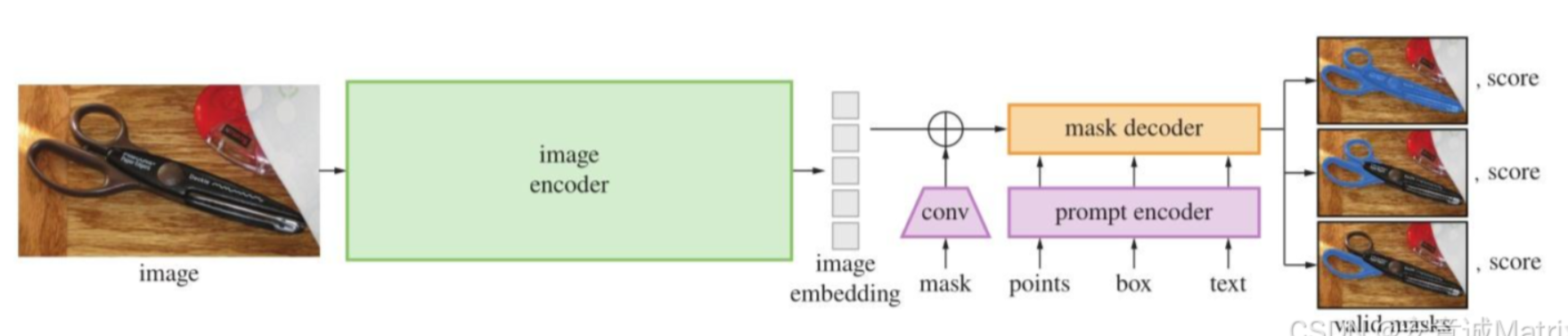
- 视觉提示模型:Meta的SAM(Segment Anything Model)开创了”分割一切”的先河,通过点、框等视觉提示即可实现通用目标分割,无需任务特定训练,已广泛应用于医学影像、遥感等领域;
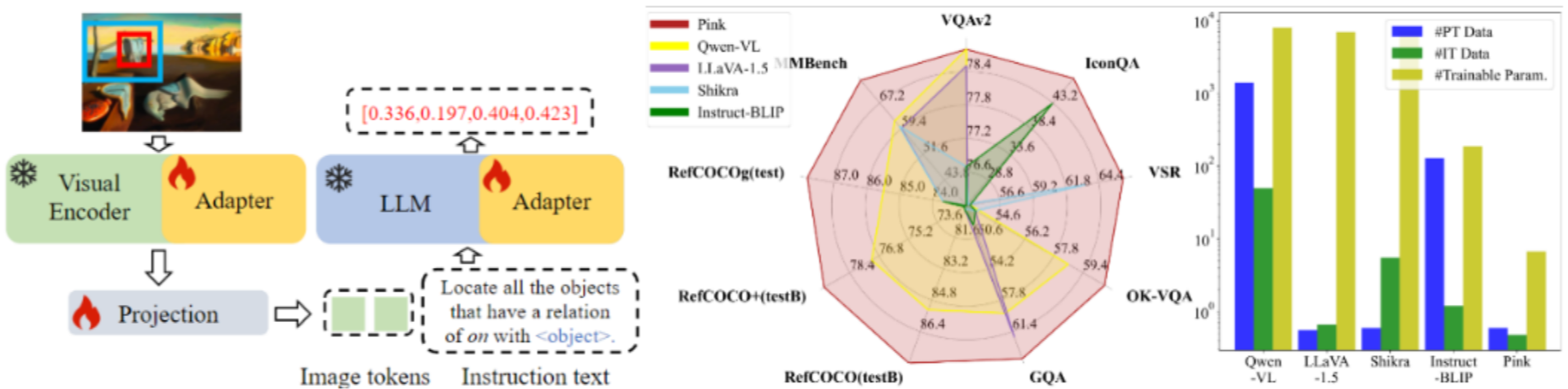
- 细粒度感知模型:北京大学的Pink模型通过坐标框文本化、适配器微调等创新,实现了图像中特定物体的细粒度指代分析,在GQA数据集上超越同类方法5.2%;LocLLM则将多模态大模型拓展至人体姿态感知,跨数据集泛化准确率领先传统方法11.0%;
- 强化学习融合模型:Gemini 2.5通过RL优化视觉-文本推理过程,VLM-R1采用GRPO算法提升零样本鲁棒性,使模型决策更贴合人类偏好与实际场景需求。
3. 性能与效率持续优化
当前视觉大模型在各项基准测试中表现亮眼:在多模态评测基准MMBench上,Pink模型以仅6.7M可微调参数量和477K指令微调数据,超越第二名5.6%;在目标检测、语义分割等传统任务上,通过预训练+微调的方式,模型性能已远超传统专用算法;同时,通过LoRA(低秩适配)、知识蒸馏等技术,模型微调成本显著降低,已可在消费级GPU上完成训练。
三、视觉大模型的研究方向分支
随着技术发展,视觉大模型的研究已形成多个明确分支,涵盖架构设计、能力拓展、落地优化等多个维度:
1. 基于提示方式的分类
- 文本提示模型(Textually Prompted Models):通过自然语言指令驱动模型完成任务,核心是视觉-文本语义对齐,代表模型有CLIP、BLIP、InstructBLIP等,支持零样本分类、图像描述、跨模态检索等任务;
- 视觉提示模型(Visually Prompted Models):以视觉信号(点、框、掩码)作为输入提示,实现精准目标定位与分割,代表模型有SAM、SegGPT、Grounding-DINO,在开放世界检测、像素级分割任务中表现突出;
- 多模态提示模型(Heterogeneous Modalities-based Models):融合文本、视觉、音频等多种提示信号,实现复杂场景理解,代表模型有ImageBind、Valley、Gemini,支持跨模态内容生成与交互。
2. 基于架构设计的分类
- 双编码器架构:独立处理视觉与文本模态,通过对比损失优化模态对齐,如CLIP、ALBEF,优势是训练高效、跨模态检索性能优异;
- 融合架构:引入额外融合编码器学习跨模态表示,如FLAVA、BLIP-2,擅长复杂语义理解与推理任务;
- 编码器-解码器架构:结合视觉编码器与语言解码器,支持生成式任务,如Flamingo、KOSMOS,可实现图像字幕生成、多模态对话;
- 自适应LLM架构:以大语言模型为核心,通过视觉编码器将图像转化为LLM兼容格式,如GPT-4V、Qwen-VL,具备强大的逻辑推理与多任务处理能力。
3. 基于核心能力的分类
- 细粒度感知:聚焦图像局部特征与复杂关系理解,如Pink的指代分析、LocLLM的人体关键点定位,突破传统模型”图像级”理解局限;
- 3D与视频理解:从2D图像扩展至3D场景重建、视频时序分析,如PointE的3D生成、VideoMAE的视频预训练,支撑自动驾驶、虚拟现实等场景;
- 视觉-语言-行动(VLA):融合感知、推理与执行能力,如李飞飞团队的语言指令机器人、VLA智能体,推动具身智能发展;
- 模型轻量化与边缘部署:通过压缩、蒸馏、量化等技术,适配边缘设备,如大小模型协同架构、联邦学习部署,解决云端依赖与隐私问题。
4. 基于训练目标的分类
- 对比式学习:通过最大化正样本对相似度、最小化负样本对相似度学习表示,如CLIP的ITC损失、FILIP Loss;
- 生成式学习:通过生成目标优化模型,如掩码语言建模(MLM)、字幕生成损失(Cap Loss)、扩散模型的生成损失;
- 强化学习:基于反馈信号优化策略,如RLHF(人类反馈强化学习)、GRPO(群体相对策略优化)、RLVR(可验证奖励强化学习),提升模型决策可靠性。
四、视觉大模型的产业应用现状
视觉大模型已从实验室走向产业落地,在多个行业形成规模化应用,展现出”技术工具”向”产业操作系统”进化的清晰路径:
1. 智慧城市与公共安全
- 城市治理:大华星汉大模型2.0实现对出店经营、流动摊贩等20类城市事件的精准识别,平均准确率较传统模型提升10%以上,场景覆盖从街道园区扩展至水域河岸、建筑工地;
- 交通管理:通过解析90余种交通场景信息,实现道路抛洒物、违规行驶等事件的自动检测与分级预警,抛洒物检测准确率提升50%,支持危险等级智能判断;
- 周界安防:基于SAM的动态分割技术,实现场景自动分类与异常行为识别(如翻越护栏、破坏设施),大幅缩短设备部署周期,降低运维成本。
2. 工业与能源领域
- 工业质检:在煤矿、制造业场景中,实现传送带20余种异常(锚杆、异物、水煤)实时识别,矿料质量分析(煤块大小、装载率)自动化,平均准确率提升10%以上,无需人工配置规则参数;
- 设备运维:通过分析设备运行视频与历史数据,实现故障预测性维护,如轴承磨损预警、管线泄漏检测,降低非计划停机风险;
- 遥感监测:高分辨率遥感图像语义分割、多时相变化检测技术,应用于城市规划、灾害监测、农作物估产,支撑智能地球建设。
3. 医疗健康领域
- 医学影像分析:基于视觉大模型的病灶分割与检测技术,已应用于CT、MRI、X射线等多模态医学图像分析,实现肿瘤边界精准勾画、早期病灶筛查,提升诊断效率与准确性;
- 临床辅助决策:融合医学知识图谱与视觉模型,支持影像报告自动生成、疾病分期评估,辅助医生制定治疗方案;
- 远程医疗:通过边缘端小模型实现手术视频实时处理与关键区域提取,降低传输延迟,支撑远程手术指导。
4. 消费电子与内容创作
- 智能终端:手机、相机等设备集成视觉大模型,实现人像美化、场景识别、实时翻译等功能,提升用户体验;
- 内容生成:文本-图像生成(如Stable Diffusion)、图像编辑、视频剪辑辅助,赋能设计师、创作者提升生产效率;
- 多模态交互:数字人、智能音箱等产品通过视觉-语言融合技术,实现更自然的人机交互,如通过手势指令控制设备、图像内容问答。
五、总结与展望
视觉大模型的出现,标志着计算机视觉领域从”任务专用”向”通用智能”的跨越。通过大规模数据训练与先进架构设计,它打破了模态壁垒与任务边界,不仅在技术层面实现了感知、理解、生成、决策能力的全面提升,更在产业层面成为驱动数字化转型的核心引擎。
当前,视觉大模型的发展仍面临多重挑战:数据隐私与安全风险(训练数据泄露、模型投毒)、算法偏见与公平性问题、算力成本过高、可解释性不足,以及边缘部署的效率瓶颈。这些问题需要学界与业界协同解决,通过技术创新(如差分隐私、模型压缩)、制度建设(如伦理审查框架)、标准规范(如数据治理准则)共同推动行业健康发展。
展望未来,视觉大模型将呈现三大发展趋势:
- 多模态深度融合:从简单的视觉-文本对齐走向视觉、语言、音频、传感器数据的全域融合,实现更全面的场景理解与交互能力;
- 专用化与轻量化并行:一方面面向垂直行业打造专用模型(如医疗、工业定制版大模型),另一方面通过技术优化实现边缘端高效部署,满足实时性与隐私保护需求;
- 具身智能与自主进化:视觉大模型将与机器人技术、强化学习深度结合,形成具备感知-决策-执行闭环的智能体,应用于自动驾驶、服务机器人、工业自动化等领域,从”理解世界”走向”改造世界”。
从实验室的技术突破到产业界的规模化应用,视觉大模型正以惊人的速度重塑我们的生活与工作。随着技术的持续迭代与生态的不断完善,相信在不久的将来,视觉大模型将如同水电一样融入社会生产生活的各个角落,成为推动新质生产力发展的核心力量。
機器視覺:視覺大模型——從技術突破到產業革新的全面解析
統整視覺大模型對傳統小模型的能力躍昇:資料與算力敘事、代表架構、在製造檢測或多模態場景的定位,並提醒如何放回延遲、漂移與營運成本評估。
來源:https://blog.csdn.net/2403_87969572/article/details/154960178
抓取時間(ISO本地):2026-05-18 05:17:17
文章目錄
前言
當我們用手機掃碼支付時的人臉識別、自動駕駛汽車對路況的實時判斷、醫生藉助AI輔助分析醫學影像、設計師通過文本指令生成創意圖像——這些看似無關的場景,背後都離不開同一類核心技術的支撐:視覺大模型。
在自然語言大模型掀起AI革命之後,視覺大模型正以同樣迅猛的勢頭重塑計算機視覺領域。作為人工智能感知世界的”眼睛”,視覺大模型打破了傳統視覺算法”一任務一模型”的侷限,通過大規模數據訓練和先進架構設計,實現了從圖像識別到場景理解、從被動感知到主動決策的能力躍升。它不僅讓機器具備了接近人類的視覺認知水平,更成為連接物理世界與數字世界的關鍵橋樑,推動千行百業的智能化轉型。
本文將從定義、研究現狀、技術分支、產業應用等維度,帶您全面讀懂視覺大模型的技術內核與發展脈絡。
一、視覺大模型的核心定義
視覺大模型(Visual Large Model)本質上是一類基於基礎模型(Foundational Models) 理念構建的人工智能系統,其核心定義可概括為:通過自監督或半監督學習方式,在海量視覺數據(圖像、視頻)及多模態數據(文本-圖像、音頻-視頻等)上訓練,具備大規模參數規模和強泛化能力,能夠自適應解決多種下游視覺任務的通用型模型。
這一定義包含三個關鍵特徵,區別於傳統計算機視覺模型:
- 通用泛化性:無需針對特定任務重新訓練,通過提示工程(Prompt Engineering)或少量微調即可適配目標檢測、語義分割、圖像生成等多種任務,實現零樣本/少樣本學習;
- 大規模基礎:訓練數據量通常達到數千萬至數十億級,模型參數規模從億級到千億級不等,通過數據與參數的雙重規模效應實現能力湧現;
- 多模態融合:打破單一視覺模態侷限,普遍集成文本、音頻等信息,實現跨模態語義對齊與交互(如文本生成圖像、圖像描述生成)。
其技術根源可追溯至Transformer架構在視覺領域的應用(如ViT模型),通過將圖像轉化為序列數據進行處理,解決了傳統CNN模型在長距離依賴建模上的不足,為大規模視覺模型的發展奠定了基礎。
二、視覺大模型的研究現狀
視覺大模型的研究已從早期的單模態建模,發展為多模態融合、細粒度感知與決策推理並重的新階段,關鍵突破集中在以下三大方向:
1. 基礎架構與訓練範式成熟化
- Transformer主導架構:ViT(Vision Transformer)的提出開啟了視覺大模型的新時代,後續衍生出Swin Transformer、MAE(掩碼自編碼器)等優化架構,在保持模型性能的同時提升計算效率。智源團隊的EVA模型通過融合CLIP的語義學習與MIM的幾何結構學習,僅用十億參數便實現了領先的視覺表示能力;
- 訓練目標多元化:對比式學習(如CLIP的圖像-文本對比損失)解決了多模態對齊問題,生成式學習(如擴散模型、掩碼語言建模)強化了內容生成能力,而強化學習(RLHF、GRPO)則通過人類反饋或可驗證獎勵提升模型決策的可靠性;
- 數據利用高效化:從依賴人工標註數據轉向大規模弱監督/無監督數據,通過Web爬取的圖像-文本對(如CLIP使用的WebImageText)、偽標籤數據(如GLIP、SA-1B)構建訓練集,降低數據標註成本。
圖 1:模型整體架構我們將圖像分割為固定大小的補丁塊(fixed-size patches),對每個補丁塊進行線性嵌入(linearly embed),添加位置嵌入(position embeddings),並將得到的向量序列輸入標準 Transformer 編碼器。為實現分類功能,我們採用主流方案:在序列中額外添加一個可學習的 “分類令牌(classification token)”。Transformer 編碼器的示意圖設計靈感源自 Irwan Vaswani 等人(2017 年)的研究 [1]。
2. 關鍵模型與技術突破
近年來,一批具有里程碑意義的視覺大模型相繼問世,推動技術邊界持續拓展:
- 多模態對齊模型:OpenAI的CLIP首次實現了文本與圖像的深度語義對齊,使模型能夠通過自然語言提示完成零樣本分類;Google的Flamingo通過Perceiver Resampler連接視覺與語言模型,提升了跨模態推理能力;
- 視覺提示模型:Meta的SAM(Segment Anything Model)開創了”分割一切”的先河,通過點、框等視覺提示即可實現通用目標分割,無需任務特定訓練,已廣泛應用於醫學影像、遙感等領域;
- 細粒度感知模型:北京大學的Pink模型通過座標框文本化、適配器微調等創新,實現了圖像中特定物體的細粒度指代分析,在GQA數據集上超越同類方法5.2%;LocLLM則將多模態大模型拓展至人體姿態感知,跨數據集泛化準確率領先傳統方法11.0%;
- 強化學習融合模型:Gemini 2.5通過RL優化視覺-文本推理過程,VLM-R1採用GRPO算法提升零樣本魯棒性,使模型決策更貼合人類偏好與實際場景需求。
3. 性能與效率持續優化
當前視覺大模型在各項基準測試中表現亮眼:在多模態評測基準MMBench上,Pink模型以僅6.7M可微調參數量和477K指令微調數據,超越第二名5.6%;在目標檢測、語義分割等傳統任務上,通過預訓練+微調的方式,模型性能已遠超傳統專用算法;同時,通過LoRA(低秩適配)、知識蒸餾等技術,模型微調成本顯著降低,已可在消費級GPU上完成訓練。
三、視覺大模型的研究方向分支
隨著技術發展,視覺大模型的研究已形成多個明確分支,涵蓋架構設計、能力拓展、落地優化等多個維度:
1. 基於提示方式的分類
- 文本提示模型(Textually Prompted Models):通過自然語言指令驅動模型完成任務,核心是視覺-文本語義對齊,代表模型有CLIP、BLIP、InstructBLIP等,支持零樣本分類、圖像描述、跨模態檢索等任務;
- 視覺提示模型(Visually Prompted Models):以視覺信號(點、框、掩碼)作為輸入提示,實現精準目標定位與分割,代表模型有SAM、SegGPT、Grounding-DINO,在開放世界檢測、像素級分割任務中表現突出;
- 多模態提示模型(Heterogeneous Modalities-based Models):融合文本、視覺、音頻等多種提示信號,實現複雜場景理解,代表模型有ImageBind、Valley、Gemini,支持跨模態內容生成與交互。
2. 基於架構設計的分類
- 雙編碼器架構:獨立處理視覺與文本模態,通過對比損失優化模態對齊,如CLIP、ALBEF,優勢是訓練高效、跨模態檢索性能優異;
- 融合架構:引入額外融合編碼器學習跨模態表示,如FLAVA、BLIP-2,擅長複雜語義理解與推理任務;
- 編碼器-解碼器架構:結合視覺編碼器與語言解碼器,支持生成式任務,如Flamingo、KOSMOS,可實現圖像字幕生成、多模態對話;
- 自適應LLM架構:以大語言模型為核心,通過視覺編碼器將圖像轉化為LLM兼容格式,如GPT-4V、Qwen-VL,具備強大的邏輯推理與多任務處理能力。
3. 基於核心能力的分類
- 細粒度感知:聚焦圖像局部特徵與複雜關係理解,如Pink的指代分析、LocLLM的人體關鍵點定位,突破傳統模型”圖像級”理解侷限;
- 3D與視頻理解:從2D圖像擴展至3D場景重建、視頻時序分析,如PointE的3D生成、VideoMAE的視頻預訓練,支撐自動駕駛、虛擬現實等場景;
- 視覺-語言-行動(VLA):融合感知、推理與執行能力,如李飛飛團隊的語言指令機器人、VLA智能體,推動具身智能發展;
- 模型輕量化與邊緣部署:通過壓縮、蒸餾、量化等技術,適配邊緣設備,如大小模型協同架構、聯邦學習部署,解決雲端依賴與隱私問題。
4. 基於訓練目標的分類
- 對比式學習:通過最大化正樣本對相似度、最小化負樣本對相似度學習表示,如CLIP的ITC損失、FILIP Loss;
- 生成式學習:通過生成目標優化模型,如掩碼語言建模(MLM)、字幕生成損失(Cap Loss)、擴散模型的生成損失;
- 強化學習:基於反饋信號優化策略,如RLHF(人類反饋強化學習)、GRPO(群體相對策略優化)、RLVR(可驗證獎勵強化學習),提升模型決策可靠性。
四、視覺大模型的產業應用現狀
視覺大模型已從實驗室走向產業落地,在多個行業形成規模化應用,展現出”技術工具”向”產業操作系統”進化的清晰路徑:
1. 智慧城市與公共安全
- 城市治理:大華星漢大模型2.0實現對出店經營、流動攤販等20類城市事件的精準識別,平均準確率較傳統模型提升10%以上,場景覆蓋從街道園區擴展至水域河岸、建築工地;
- 交通管理:通過解析90餘種交通場景信息,實現道路拋灑物、違規行駛等事件的自動檢測與分級預警,拋灑物檢測準確率提升50%,支持危險等級智能判斷;
- 周界安防:基於SAM的動態分割技術,實現場景自動分類與異常行為識別(如翻越護欄、破壞設施),大幅縮短設備部署週期,降低運維成本。
2. 工業與能源領域
- 工業質檢:在煤礦、製造業場景中,實現傳送帶20餘種異常(錨杆、異物、水煤)實時識別,礦料質量分析(煤塊大小、裝載率)自動化,平均準確率提升10%以上,無需人工配置規則參數;
- 設備運維:通過分析設備運行視頻與歷史數據,實現故障預測性維護,如軸承磨損預警、管線洩漏檢測,降低非計劃停機風險;
- 遙感監測:高分辨率遙感圖像語義分割、多時相變化檢測技術,應用於城市規劃、災害監測、農作物估產,支撐智能地球建設。
3. 醫療健康領域
- 醫學影像分析:基於視覺大模型的病灶分割與檢測技術,已應用於CT、MRI、X射線等多模態醫學圖像分析,實現腫瘤邊界精準勾畫、早期病灶篩查,提升診斷效率與準確性;
- 臨床輔助決策:融合醫學知識圖譜與視覺模型,支持影像報告自動生成、疾病分期評估,輔助醫生制定治療方案;
- 遠程醫療:通過邊緣端小模型實現手術視頻實時處理與關鍵區域提取,降低傳輸延遲,支撐遠程手術指導。
4. 消費電子與內容創作
- 智能終端:手機、相機等設備集成視覺大模型,實現人像美化、場景識別、實時翻譯等功能,提升用戶體驗;
- 內容生成:文本-圖像生成(如Stable Diffusion)、圖像編輯、視頻剪輯輔助,賦能設計師、創作者提升生產效率;
- 多模態交互:數字人、智能音箱等產品通過視覺-語言融合技術,實現更自然的人機交互,如通過手勢指令控制設備、圖像內容問答。
五、總結與展望
視覺大模型的出現,標誌著計算機視覺領域從”任務專用”向”通用智能”的跨越。通過大規模數據訓練與先進架構設計,它打破了模態壁壘與任務邊界,不僅在技術層面實現了感知、理解、生成、決策能力的全面提升,更在產業層面成為驅動數字化轉型的核心引擎。
當前,視覺大模型的發展仍面臨多重挑戰:數據隱私與安全風險(訓練數據洩露、模型投毒)、算法偏見與公平性問題、算力成本過高、可解釋性不足,以及邊緣部署的效率瓶頸。這些問題需要學界與業界協同解決,通過技術創新(如差分隱私、模型壓縮)、制度建設(如倫理審查框架)、標準規範(如數據治理準則)共同推動行業健康發展。
展望未來,視覺大模型將呈現三大發展趨勢:
- 多模態深度融合:從簡單的視覺-文本對齊走向視覺、語言、音頻、傳感器數據的全域融合,實現更全面的場景理解與交互能力;
- 專用化與輕量化並行:一方面面向垂直行業打造專用模型(如醫療、工業定製版大模型),另一方面通過技術優化實現邊緣端高效部署,滿足實時性與隱私保護需求;
- 具身智能與自主進化:視覺大模型將與機器人技術、強化學習深度結合,形成具備感知-決策-執行閉環的智能體,應用於自動駕駛、服務機器人、工業自動化等領域,從”理解世界”走向”改造世界”。
從實驗室的技術突破到產業界的規模化應用,視覺大模型正以驚人的速度重塑我們的生活與工作。隨著技術的持續迭代與生態的不斷完善,相信在不久的將來,視覺大模型將如同水電一樣融入社會生產生活的各個角落,成為推動新質生產力發展的核心力量。
Computer Vision: Visual Foundation Models — A Full Picture from Technical Breakthroughs to Industrial Transformation
A strategic tour of foundation-scale vision models: training signals vs classical CV, strength/limit checklist for inspection or multimodal apps, and how teams should budget latency, drift and tooling.
Captured at (local ISO): 2026-05-18 05:17:17
Preface
When you pay with your phone using face recognition, when a self-driving car judges the road in real time, when a doctor uses AI to help read medical images, or when a designer generates concepts from a text prompt—seemingly unrelated scenarios— they all rely on the same kind of core technology: visual foundation models.
After large language models kicked off an AI revolution, visual foundation models are reshaping computer vision just as fast. As the “eyes” through which AI perceives the world, they break the old pattern of one task, one model. Through training at scale and advanced architectures, they leap from image recognition to scene understanding, and from passive sensing to active decision-making. They bring machine vision closer to human-level perception and form a key bridge between the physical and digital worlds, accelerating intelligent transformation across industries.
This article walks through definitions, the state of research, technical branches, and industrial applications so you can grasp both the technical core and the trajectory of visual foundation models.
I. Core definition of visual foundation models
A visual foundation model is a class of AI systems built on the foundation-model idea. In short: trained with self- or semi-supervised learning on massive visual data (images, videos) and often multimodal data (text–image, audio–video, etc.), with large parameter counts and strong generalization, such a model can adapt to many downstream vision tasks without being rebuilt from scratch for each one.
Three traits distinguish this from traditional CV models:
- Generalization across tasks: Without full retraining for every use case, prompt engineering or light fine-tuning can adapt the same model to detection, segmentation, generation, and more—supporting zero- or few-shot setups.
- Scale: Training sets often reach tens of millions to billions of examples; parameters range from hundreds of millions to hundreds of billions, unlocking emergent behavior from data and model size together.
- Multimodality: Beyond pure vision, models commonly fuse text, audio, and other signals for cross-modal alignment and interaction (e.g., text-to-image, image captioning).
Technically, much traces back to Transformer in vision (e.g., ViT): by turning images into token sequences, long-range dependencies are modeled better than with classic CNNs alone, laying groundwork for large-scale visual models.
II. Research landscape of visual foundation models
Work has moved from early single-modal modeling toward multimodal fusion, fine-grained perception, and decision-oriented reasoning. Major progress clusters in three directions:
1. Maturing base architectures and training paradigms
- Transformer-centric design: ViT opened the modern era; successors like Swin Transformer and MAE (masked autoencoder) improved efficiency while holding accuracy. The EVA family from BAAI combines CLIP-style semantics with MIM-style geometry at ~1B parameters for leading representations.
- Diverse training objectives: Contrastive learning (e.g., CLIP’s image–text loss) improves alignment; generative objectives (diffusion, masked modeling) strengthen creation; RLHF/GRPO-style training aligns decisions with human or verifiable feedback.
- Better use of data: Less reliance on hand-labeled sets; large weakly supervised or unpaired web data (e.g., CLIP’s web image–text pairs; pseudo-labeled sets in GLIP, SA-1B) cut labeling cost.
Figure 1: Overall model architecture. We split the image into fixed-size patches, linearly embed each patch, add position embeddings, and feed the resulting sequence to a standard Transformer encoder. For classification we follow the common recipe of prepending a learnable “classification token.” The encoder schematic follows the spirit of Vaswani et al. (2017) [1].
2. Landmark models and technical breakthroughs
Several milestone models have pushed the frontier:
- Multimodal alignment: CLIP aligns text and images semantically and enables zero-shot classification from natural-language prompts; Flamingo’s Perceiver Resampler links vision and language for stronger cross-modal reasoning.
- Visual prompting: SAM (“Segment Anything”) popularizes segmentation from points, boxes, and similar prompts without task-specific training—now common in medical imaging, remote sensing, and more.
- Fine-grained perception: Peking University’s Pink model improves referring and grounding with box-to-text tricks and adapters, beating peers by 5.2% on GQA; LocLLM extends VLMs to human pose with cross-dataset gains around 11.0% over classical pipelines.
- RL-enhanced VLMs: Gemini 2.5 refines vision–text reasoning with RL; VLM-R1 uses GRPO to improve zero-shot robustness so behavior better matches human preferences and real scenes.
3. Continuous gains in performance and efficiency
On benchmarks such as MMBench, Pink with only 6.7M tunable parameters and 477K instruction examples leads the runner-up by 5.6%. On classic detection and segmentation, pre-train + fine-tune beats many bespoke pipelines. Techniques like LoRA, distillation, and quantization bring fine-tuning within reach of consumer GPUs.
III. Research branches and directions
Several clear branches have formed—architecture, capabilities, and deployment all included:
1. Taxonomy by prompting modality
- Textually prompted models: Natural-language instructions drive the task; core is vision–text alignment. Examples: CLIP, BLIP, InstructBLIP—zero-shot classification, captioning, retrieval.
- Visually prompted models: Points, boxes, or masks steer the model toward precise localization and segmentation. Examples: SAM, SegGPT, Grounding DINO—open-world detection and pixel-level tasks.
- Heterogeneous multimodal prompts: Fuse text, vision, audio, etc. Examples: ImageBind, Valley, Gemini—for cross-modal generation and interaction.
2. Taxonomy by architecture design
- Dual encoders: Separate vision and text towers with contrastive alignment (CLIP, ALBEF)—fast training, strong retrieval.
- Fusion encoders: Extra fusion modules for joint representations (FLAVA, BLIP-2)—better for complex semantics and reasoning.
- Encoder–decoder: Vision encoder + language decoder for generation (Flamingo, KOSMOS)—captioning, dialogue.
- LLM-centric VLMs: Image tokens fed into a large language model (GPT-4V, Qwen-VL)—strong reasoning and multi-task behavior.
3. Taxonomy by core capabilities
- Fine-grained perception: Local structure and relations (Pink-style referring, LocLLM-style keypoints)—beyond image-level pooling.
- 3D and video: From 2D stills to 3D reconstruction and temporal modeling (e.g., Point-E, VideoMAE)—supporting autonomy, XR, etc.
- Vision–language–action (VLA): Perception, reasoning, and actuation together (e.g., language-conditioned robotics)—toward embodied AI.
- Efficiency and edge: Compression, distillation, quantization, small–large collaboration, federated setups—reducing cloud dependence and privacy risk.
4. Taxonomy by training objectives
- Contrastive: Maximize similarity of positive pairs, minimize negatives—CLIP ITC, FILIP, etc.
- Generative: MLM, caption loss, diffusion losses.
- Reinforcement: RLHF, GRPO, RLVR with verifiable rewards—more reliable decisions.
IV. Industrial adoption today
Visual foundation models are graduating from labs to production, evolving from “tool” toward something like an industrial operating layer:
1. Smart cities and public safety
- Urban operations: Dahua’s Xinghan 2.0 model targets 20+ event types (e.g., sidewalk vending), with average accuracy ~10%+ above classical baselines across streets, waterfronts, and construction sites.
- Traffic: Parses 90+ scene cues; detects road debris and violations with tiered alerts; debris detection accuracy up ~50% with severity classification.
- Perimeter security: SAM-style dynamic segmentation for scene typing and anomaly cues (climbing, sabotage)—shorter deploy cycles and lower OPEX.
2. Industry and energy
- Quality inspection: In mining and manufacturing, real-time detection of 20+ belt anomalies; coal sizing and loading analytics—often 10%+ accuracy gains without hand-tuned rule thresholds.
- Asset health: Video plus history for predictive maintenance—bearing wear, line leaks, fewer unplanned outages.
- Remote sensing: HR segmentation and change detection for planning, disaster response, and crop estimation—supporting “digital earth” initiatives.
3. Healthcare
- Imaging: Lesion segmentation and detection on CT, MRI, X-ray—sharper contours, earlier screening, faster reads.
- Clinical decision support: Fusion with knowledge graphs—auto reports, staging, treatment hints.
- Telemedicine: Edge models on surgical video for key-region extraction—lower latency for remote guidance.
4. Consumer electronics and content creation
- Devices: Phones and cameras—portrait enhancement, scene understanding, live translation.
- Creation: Text-to-image (e.g., Stable Diffusion), editing, assisted editing—higher creative throughput.
- Multimodal products: Digital humans and smart speakers with fused vision–language—gesture control, visual Q&A.
V. Summary and outlook
Visual foundation models mark a shift from task-specific CV toward general visual intelligence. Scale and architecture break modality and task silos—lifting perception, understanding, generation, and decision-making—while industry increasingly treats them as infrastructure for digital transformation.
Challenges remain: privacy and security (data leakage, poisoning), bias and fairness, compute cost, interpretability, and edge efficiency. Progress needs joint effort—technical tools (e.g., differential privacy, compression), governance (ethics review), and standards (data policies).
Looking ahead, three trends stand out:
- Deeper multimodality: From vision–text pairing toward fusing vision, language, audio, and sensors for richer scene models and interfaces.
- Specialization and lightweighting in parallel: Vertical industry models alongside hardware-aware deployment for latency and privacy.
- Embodied agents and self-improvement: Tighter coupling with robotics and RL—closed loops of sense, plan, and act—in autonomy, service robots, and automation—moving from understanding the world to changing it.
From lab breakthroughs to industrial scale, visual foundation models are reshaping how we live and work. As the stack matures, they may become as ubiquitous as utilities—core drivers of productivity in the years ahead.