具身智能:研究现状深度解析——从技术突破到产业落地
当人工智能从虚拟的数字世界迈向真实的物理空间,一场关乎“智能如何具象化”的革命正在悄然发生。2025年,“具身智能”首次被写入政府工作报告,成为国家重点培育的未来产业,全球领域融资超500亿元,中国产业规模更是达到4800亿元,同比增长67.8%。从工业车间的柔性生产到家庭场景的智能服务,从医疗辅助的精准操作到应急救援的危险作业,具身智能正以“物理实体+AI大脑”的形态,填补传统人工智能“只知不行”的能力鸿沟。人工智能的发展已历经感知智能(“看懂世界”)、认知智能(“理解语言”)两个阶段,如今正迈入具身智能的全新阶段——实现“在真实世界中行动”的关键跨越。
前言
当人工智能从虚拟的数字世界迈向真实的物理空间,一场关乎“智能如何具象化”的革命正在悄然发生。2025年,“具身智能”首次被写入政府工作报告,成为国家重点培育的未来产业,全球领域融资超500亿元,中国产业规模更是达到4800亿元,同比增长67.8%。从工业车间的柔性生产到家庭场景的智能服务,从医疗辅助的精准操作到应急救援的危险作业,具身智能正以“物理实体+AI大脑”的形态,填补传统人工智能“只知不行”的能力鸿沟。
人工智能的发展已历经感知智能(“看懂世界”)、认知智能(“理解语言”)两个阶段,如今正迈入具身智能的全新阶段——实现“在真实世界中行动”的关键跨越。清华大学张钹院士曾直言:“没有具身能力的人工智能是不完整的。” 随着多模态大模型与机器人技术的深度融合,具身智能正从实验室的理论探索走向规模化产业应用,开启人机共生的全新纪元。本文将系统解析具身智能的核心内涵、研究现状、前沿方向与头部玩家,带你全面把握这一万亿级赛道的发展脉络。
一、什么是具身智能?
定义与核心特征
2025年,国际人工智能学会(IAAI)联合IEEE、ACM等权威机构发布的《具身智能技术白皮书》首次确立了标准化定义:具身智能是指具有物理形态的智能体,通过“感知-决策-行动-反馈”闭环系统与物理环境进行持续交互,能够理解、适应并改造环境,具备在开放世界中完成复杂任务能力的智能系统。
与传统“离身智能”(如ChatGPT等纯软件AI)相比,具身智能的核心特征体现在四个维度:
- 具身性:拥有物理载体(机器人本体)、感官系统(多模态传感器)、行动能力(执行器)和社会角色,更强调对物理规律的内在理解(如重力、摩擦力),实现从“有身体”到“懂物理”的进阶;
- 交互性:与环境形成双向动态影响,通过感知指导行动,再以行动结果优化感知,而非被动接收数据;
- 适应性:能在动态变化的开放环境中调整行为策略,应对不确定性场景;
- 涌现性:通过简单规则与持续交互,产生复杂且不可预测的高级智能行为。
核心逻辑与概念边界
具身智能的核心理念源于认知科学的“具身假说”——智能并非孤立于大脑或算法,而是身体形态、运动能力与环境动态耦合的产物。这如同婴儿认识世界:并非单纯依靠大脑思考,而是通过眼睛看、耳朵听、双手触摸的交互过程积累认知。
需要明确的是,具身智能与相关概念存在本质区别:
- 与“智能体(Agent)”:智能体涵盖虚拟与物理形态,具身智能是智能体在物理世界的具体化;
- 与“通用人工智能(AGI)”:具身智能是AGI从数字世界走向物理现实的关键路径,而非终极目标;
- 与“具身机器人”:前者是核心能力(智能层面),后者是具体载体(硬件层面)。
其技术栈呈现三层架构:顶层为语义理解与任务规划(大模型+世界模型),中层为感知-决策融合(多模态统一表征),底层为物理交互与控制(运动规划+灵巧操作),形成“大脑+小脑+身体”的完整体系。
二、研究现状:从技术突破到场景落地
技术发展阶段
具身智能的研究已从早期的“行为主义探索”(1990s Brooks提出“行为主义智能”)、“数学模型构建”(2018年Ay等基于马尔可夫假设的抽象定义),进入“多模态大模型驱动”的爆发期。2023年ChatGPT问世后,相关研究呈指数级增长,仅2024年谷歌学术“embodied agent”关键词发文量就达1350篇,较往年实现翻倍增长。
当前技术突破主要集中在三大核心能力:
- 环境感知能力:基于多模态大模型(如GPT-4o、Gemini 1.5、Qwen-VL)实现跨模态理解,无需额外训练即可完成视觉定位、导航等任务,泛化能力显著提升;
- 长程任务规划:通过大模型的逻辑推理能力,将复杂指令分解为可执行子任务。例如“接杯水”可拆解为“找杯子-拿杯子-定位饮水机-接水-送水”等步骤,解决了传统具身智能“任务分解难”的痛点;
- 短程动作控制:从早期的API调用、代码生成,发展到具身大模型直接生成动作指令,ReKep算法通过关系关键点约束,大幅提升了操作精度和泛化能力。
应用场景落地进展
2025年被业界称为“具身智能产业化元年”,技术已从实验室走向多领域规模化应用:
- 工业制造:优必选Walker S1成为全球首个在工业场景落地的人形机器人,与无人物流车协同作业,应用于比亚迪等车厂,累计意向订单超500台;龙旗科技车间使用具身机器人后,产品合格率提升12%;
- 服务领域:腾讯“小五”机器人在养老院场景实现抱扶老人、取放物品等功能,双臂承重50千克,可应对楼梯、斜坡等复杂地形;酒店服务机器人云迹科技成功上市,成为“机器人服务智能体第一股”;
- 家庭场景:家庭服务机器人已能完成“准备一顿晚餐”等复杂任务,并且具有较高的完成率,但仍受限于成本与泛化能力,尚未大规模普及;
- 特种场景:在核电站巡检、应急救援等危险环境中,具身机器人替代人工操作,安全性大幅提升,成为高危场景的“刚需解决方案”。
当前瓶颈与挑战
尽管进展显著,具身智能仍面临多重技术与产业化挑战:
- Sim2Real落地鸿沟:在物料分拣等刚体任务中已实现突破,但流体物理模拟、柔性体接触等复杂场景仍需攻克,安全验证成为“最后一公里”难题;
- 硬件成本高企:高精度灵巧手、多模态传感器等核心部件价格昂贵,限制了民用场景的普及;
- 泛化能力不足:在结构化环境中表现优异,但面对开放世界的动态变化(如突发障碍物、任务变更),适应性仍需提升;
- 闭环学习效率低:真实世界数据采集成本高、周期长,难以形成“数据-模型-优化”的快速迭代飞轮。
三、研究方向:未来技术演进的核心赛道
1. 多模态大模型与世界模型协同
当前具身智能的核心趋势是“大脑升级”——将多模态大模型(MLLM)的语义理解能力与世界模型(WM)的物理预测能力相结合。世界模型能够推演物理环境的动态变化,为大模型提供“环境预判”支持,形成“感知-预测-决策”的全链路优化,这一组合被认为是具身智能实现“GPT式爆发”的关键。Fast-in-Slow推理范式已成为主流:大模型负责高层任务规划,专用模块处理底层实时执行,平衡了推理精度与响应速度。
2. 灵巧操作与高精度控制
灵巧操作是具身智能“手眼协调”的核心体现,成为2025年IROS大会的热点主题。当前研究聚焦于高自由度灵巧手的硬件研发与算法优化:Sharpa推出首款视触觉集成的22自由度灵巧手,实现荷官发牌等精细操作;舞肌科技展示高自由度灵巧手实机,突破了电机小型化、低发热等技术瓶颈。算法层面,**模仿学习(Learning from Demonstration)**成为主流路径,通过人类演示数据快速提升机器人操作熟练度。
3. 闭环学习与数据效率优化
针对真实世界数据稀缺的问题,闭环学习机制成为研究重点:智能体通过环境反馈持续优化模型参数,减少对人工标注数据的依赖。同时,低成本机械臂、开源仿真平台(如BEHAVIOR-1K基准测试)的发展,降低了数据采集与训练门槛,推动“真机训练+仿真迭代”的混合训练模式普及。
4. 多智能体协同与集群智能
单一具身智能体的能力有限,多具身智能体协同成为复杂场景的解决方案。研究方向包括:工业场景中“人形机器人+移动机器人”的任务分工,应急救援中的多机器人协作勘探,以及集群智能的分布式决策算法。通过机器人之间的通信与协同,实现“1+1>2”的任务执行效率提升。
5. 场景适配与商业化路径优化
学术界与产业界已形成共识:具身智能将遵循“工业先于家庭”的落地路径。工业场景任务明确、成本可控,已形成成熟商业模式;家庭服务场景则需等待成本下降与泛化能力提升,将先在医院、酒店等垂直场景渗透,再逐步进入普通家庭。
四、头部公司:全球玩家的技术布局与竞争格局
国外核心企业
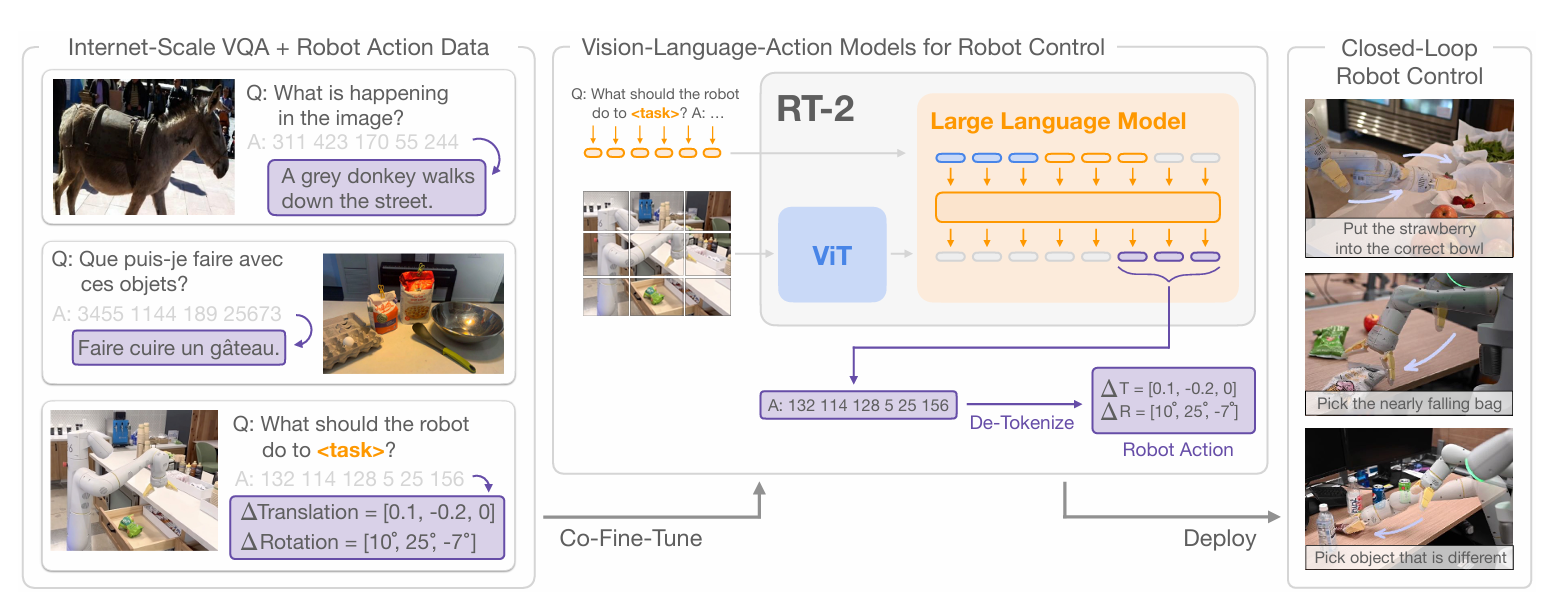
- 谷歌DeepMind:技术引领者,推出视觉-语言-动作(VLA)模型RT-2,将网络数据与机器人数据融合训练,使未见过场景的任务成功率从32%提升至62%,奠定了具身大模型的技术基础;
- 特斯拉:聚焦人形机器人Optimus,计划2025年底实现量产,凭借在自动驾驶、电机控制等领域的技术积累,主打“低成本+高可靠性”,目标成为民用场景的普及者;

- Meta:深耕多模态融合与仿真训练平台,通过虚拟环境生成海量训练数据,降低真机训练成本,其研究成果在社交机器人、工业协作场景具有潜在应用;
- 亚马逊:以Astro家庭服务机器人为载体,结合Alexa语音助手的语义理解能力,打造“家居场景一体化解决方案”,侧重实用性与用户体验。
国内标杆企业
- 优必选:国内人形机器人龙头,Walker S1率先实现工业场景落地,搭载自主研发的ROSA2.0操作系统和第三代仿人灵巧手,累计意向订单超500台,2023年登陆港股成为“人形机器人第一股”;

- 腾讯Robotics X实验室:发布人居环境机器人“小五”,采用四腿轮足复合设计,覆盖180个检测点的触觉皮肤,在养老院场景展现出强大的地形适应与人机交互能力;
- 智元机器人:2024年初推出首个具身大模型,实现语言、视觉与动作的统一表示,通过21亿元收购上纬新材引发借壳上市猜想,聚焦高端具身智能解决方案;
- 宇树科技:以人形机器人登上春晚为契机,加速IPO筹备,计划2025年底递交上市申请,有望成为A股“人形机器人第一股”,主打消费级与工业级双赛道;
- Sharpa/舞肌科技:在灵巧手领域实现突破,Sharpa的视触觉集成灵巧手、舞肌科技的高自由度机械臂,代表了国内硬件研发的顶尖水平,成为产业链核心零部件供应商。
此外,斯坦德机器人、仙工智能、云迹科技等企业纷纷冲刺IPO,形成“整机厂+核心零部件+场景应用”的完整产业生态,2025年上半年国内具身智能产业链融资事件达144次,融资金额195亿元。
总结
具身智能正站在“技术爆发+产业落地”的双重拐点,成为人工智能从“数字虚拟”走向“物理现实”的核心载体。从认知科学的理论假说,到多模态大模型驱动的技术突破;从实验室的Demo演示,到工业车间的规模化应用,具身智能用短短几年时间完成了“从0到1”的跨越,2025年的产业化元年标志着其正式进入“从1到N”的快速发展期。
当前,技术层面正朝着“大模型+世界模型”的协同方向演进,硬件层面聚焦灵巧操作与成本优化,应用层面遵循“工业先于家庭”的落地路径,政策与资本的双重加持则为行业发展提供了强劲动力。但同时,Sim2Real鸿沟、泛化能力不足、成本高企等挑战仍需长期攻坚,具身智能的“GPT时刻”尚未到来——正如专家预测,当世界模型实现通用物理推演,当机器人集群生成海量真实数据,才会迎来真正的突破性爆发。
展望未来,具身智能不仅是实现通用人工智能的关键路径,更是推动产业升级、重构人机关系的核心力量。它将让机器人从“程序化工具”转变为“自主化代理”,从工业生产到家庭服务,从医疗辅助到应急救援,深度融入千行百业,推动人类社会迈入“人机共创”的全新阶段。对于研究者而言,这是充满挑战的学术前沿;对于企业而言,这是万亿级的市场蓝海;对于普通人而言,这是即将改变生活的科技革命。
正如DeepMind首席科学家David Silver所言:“没有具身的AGI就像没有身体的幽灵,无法真正理解人类世界。” 具身智能的征途是星辰大海,而我们正处在这场革命的起点。
具身智能:研究現狀深度解析——從技術突破到產業落地
當人工智能從虛擬的數字世界邁向真實的物理空間,一場關乎“智能如何具象化”的革命正在悄然發生。2025年,“具身智能”首次被寫入政府工作報告,成為國家重點培育的未來產業,全球領域融資超500億元,中國產業規模更是達到4800億元,同比增長67.8%。從工業車間的柔性生產到家庭場景的智能服務,從醫療輔助的精準操作到應急救援的危險作業,具身智能正以“物理實體+AI大腦”的形態,填補傳統人工智能“只知不行”的能力鴻溝。人工智能的發展已歷經感知智能(“看懂世界”)、認知智能(“理解語言”)兩個階段,如今正邁入具身智能的全新階段——實現“在真實世界中行動”的關鍵跨越。
來源:https://blog.csdn.net/2403_87969572/article/details/154909044
抓取時間(ISO本地):2026-05-18 05:17:12
前言
當人工智能從虛擬的數字世界邁向真實的物理空間,一場關乎“智能如何具象化”的革命正在悄然發生。2025年,“具身智能”首次被寫入政府工作報告,成為國家重點培育的未來產業,全球領域融資超500億元,中國產業規模更是達到4800億元,同比增長67.8%。從工業車間的柔性生產到家庭場景的智能服務,從醫療輔助的精準操作到應急救援的危險作業,具身智能正以“物理實體+AI大腦”的形態,填補傳統人工智能“只知不行”的能力鴻溝。
人工智能的發展已歷經感知智能(“看懂世界”)、認知智能(“理解語言”)兩個階段,如今正邁入具身智能的全新階段——實現“在真實世界中行動”的關鍵跨越。清華大學張鈸院士曾直言:“沒有具身能力的人工智能是不完整的。” 隨著多模態大模型與機器人技術的深度融合,具身智能正從實驗室的理論探索走向規模化產業應用,開啟人機共生的全新紀元。本文將系統解析具身智能的核心內涵、研究現狀、前沿方向與頭部玩家,帶你全面把握這一萬億級賽道的發展脈絡。
文章目錄
一、什麼是具身智能?
定義與核心特徵
2025年,國際人工智能學會(IAAI)聯合IEEE、ACM等權威機構發佈的《具身智能技術白皮書》首次確立了標準化定義:具身智能是指具有物理形態的智能體,通過“感知-決策-行動-反饋”閉環系統與物理環境進行持續交互,能夠理解、適應並改造環境,具備在開放世界中完成複雜任務能力的智能系統。
與傳統“離身智能”(如ChatGPT等純軟件AI)相比,具身智能的核心特徵體現在四個維度:
- 具身性:擁有物理載體(機器人本體)、感官系統(多模態傳感器)、行動能力(執行器)和社會角色,更強調對物理規律的內在理解(如重力、摩擦力),實現從“有身體”到“懂物理”的進階;
- 交互性:與環境形成雙向動態影響,通過感知指導行動,再以行動結果優化感知,而非被動接收數據;
- 適應性:能在動態變化的開放環境中調整行為策略,應對不確定性場景;
- 湧現性:通過簡單規則與持續交互,產生複雜且不可預測的高級智能行為。
核心邏輯與概念邊界
具身智能的核心理念源於認知科學的“具身假說”——智能並非孤立於大腦或算法,而是身體形態、運動能力與環境動態耦合的產物。這如同嬰兒認識世界:並非單純依靠大腦思考,而是通過眼睛看、耳朵聽、雙手觸摸的交互過程積累認知。
需要明確的是,具身智能與相關概念存在本質區別:
- 與“智能體(Agent)”:智能體涵蓋虛擬與物理形態,具身智能是智能體在物理世界的具體化;
- 與“通用人工智能(AGI)”:具身智能是AGI從數字世界走向物理現實的關鍵路徑,而非終極目標;
- 與“具身機器人”:前者是核心能力(智能層面),後者是具體載體(硬件層面)。
其技術棧呈現三層架構:頂層為語義理解與任務規劃(大模型+世界模型),中層為感知-決策融合(多模態統一表徵),底層為物理交互與控制(運動規劃+靈巧操作),形成“大腦+小腦+身體”的完整體系。
二、研究現狀:從技術突破到場景落地
技術發展階段
具身智能的研究已從早期的“行為主義探索”(1990s Brooks提出“行為主義智能”)、“數學模型構建”(2018年Ay等基於馬爾可夫假設的抽象定義),進入“多模態大模型驅動”的爆發期。2023年ChatGPT問世後,相關研究呈指數級增長,僅2024年穀歌學術“embodied agent”關鍵詞發文量就達1350篇,較往年實現翻倍增長。
當前技術突破主要集中在三大核心能力:
- 環境感知能力:基於多模態大模型(如GPT-4o、Gemini 1.5、Qwen-VL)實現跨模態理解,無需額外訓練即可完成視覺定位、導航等任務,泛化能力顯著提升;
- 長程任務規劃:通過大模型的邏輯推理能力,將複雜指令分解為可執行子任務。例如“接杯水”可拆解為“找杯子-拿杯子-定位飲水機-接水-送水”等步驟,解決了傳統具身智能“任務分解難”的痛點;
- 短程動作控制:從早期的API調用、代碼生成,發展到具身大模型直接生成動作指令,ReKep算法通過關係關鍵點約束,大幅提升了操作精度和泛化能力。
應用場景落地進展
2025年被業界稱為“具身智能產業化元年”,技術已從實驗室走向多領域規模化應用:
- 工業製造:優必選Walker S1成為全球首個在工業場景落地的人形機器人,與無人物流車協同作業,應用於比亞迪等車廠,累計意向訂單超500臺;龍旗科技車間使用具身機器人後,產品合格率提升12%;
- 服務領域:騰訊“小五”機器人在養老院場景實現抱扶老人、取放物品等功能,雙臂承重50千克,可應對樓梯、斜坡等複雜地形;酒店服務機器人云跡科技成功上市,成為“機器人服務智能體第一股”;
- 家庭場景:家庭服務機器人已能完成“準備一頓晚餐”等複雜任務,並且具有較高的完成率,但仍受限於成本與泛化能力,尚未大規模普及;
- 特種場景:在核電站巡檢、應急救援等危險環境中,具身機器人替代人工操作,安全性大幅提升,成為高危場景的“剛需解決方案”。
當前瓶頸與挑戰
儘管進展顯著,具身智能仍面臨多重技術與產業化挑戰:
- Sim2Real落地鴻溝:在物料分揀等剛體任務中已實現突破,但流體物理模擬、柔性體接觸等複雜場景仍需攻克,安全驗證成為“最後一公里”難題;
- 硬件成本高企:高精度靈巧手、多模態傳感器等核心部件價格昂貴,限制了民用場景的普及;
- 泛化能力不足:在結構化環境中表現優異,但面對開放世界的動態變化(如突發障礙物、任務變更),適應性仍需提升;
- 閉環學習效率低:真實世界數據採集成本高、週期長,難以形成“數據-模型-優化”的快速迭代飛輪。
三、研究方向:未來技術演進的核心賽道
1. 多模態大模型與世界模型協同
當前具身智能的核心趨勢是“大腦升級”——將多模態大模型(MLLM)的語義理解能力與世界模型(WM)的物理預測能力相結合。世界模型能夠推演物理環境的動態變化,為大模型提供“環境預判”支持,形成“感知-預測-決策”的全鏈路優化,這一組合被認為是具身智能實現“GPT式爆發”的關鍵。Fast-in-Slow推理範式已成為主流:大模型負責高層任務規劃,專用模塊處理底層實時執行,平衡了推理精度與響應速度。
2. 靈巧操作與高精度控制
靈巧操作是具身智能“手眼協調”的核心體現,成為2025年IROS大會的熱點主題。當前研究聚焦於高自由度靈巧手的硬件研發與算法優化:Sharpa推出首款視觸覺集成的22自由度靈巧手,實現荷官發牌等精細操作;舞肌科技展示高自由度靈巧手實機,突破了電機小型化、低發熱等技術瓶頸。算法層面,**模仿學習(Learning from Demonstration)**成為主流路徑,通過人類演示數據快速提升機器人操作熟練度。
3. 閉環學習與數據效率優化
針對真實世界數據稀缺的問題,閉環學習機制成為研究重點:智能體通過環境反饋持續優化模型參數,減少對人工標註數據的依賴。同時,低成本機械臂、開源仿真平臺(如BEHAVIOR-1K基準測試)的發展,降低了數據採集與訓練門檻,推動“真機訓練+仿真迭代”的混合訓練模式普及。
4. 多智能體協同與集群智能
單一具身智能體的能力有限,多具身智能體協同成為複雜場景的解決方案。研究方向包括:工業場景中“人形機器人+移動機器人”的任務分工,應急救援中的多機器人協作勘探,以及集群智能的分佈式決策算法。通過機器人之間的通信與協同,實現“1+1>2”的任務執行效率提升。
5. 場景適配與商業化路徑優化
學術界與產業界已形成共識:具身智能將遵循“工業先於家庭”的落地路徑。工業場景任務明確、成本可控,已形成成熟商業模式;家庭服務場景則需等待成本下降與泛化能力提升,將先在醫院、酒店等垂直場景滲透,再逐步進入普通家庭。
四、頭部公司:全球玩家的技術佈局與競爭格局
國外核心企業
- 谷歌DeepMind:技術引領者,推出視覺-語言-動作(VLA)模型RT-2,將網絡數據與機器人數據融合訓練,使未見過場景的任務成功率從32%提升至62%,奠定了具身大模型的技術基礎;
- 特斯拉:聚焦人形機器人Optimus,計劃2025年底實現量產,憑藉在自動駕駛、電機控制等領域的技術積累,主打“低成本+高可靠性”,目標成為民用場景的普及者;
- Meta:深耕多模態融合與仿真訓練平臺,通過虛擬環境生成海量訓練數據,降低真機訓練成本,其研究成果在社交機器人、工業協作場景具有潛在應用;
- 亞馬遜:以Astro家庭服務機器人為載體,結合Alexa語音助手的語義理解能力,打造“家居場景一體化解決方案”,側重實用性與用戶體驗。
國內標杆企業
- 優必選:國內人形機器人龍頭,Walker S1率先實現工業場景落地,搭載自主研發的ROSA2.0操作系統和第三代仿人靈巧手,累計意向訂單超500臺,2023年登陸港股成為“人形機器人第一股”;
- 騰訊Robotics X實驗室:發佈人居環境機器人“小五”,採用四腿輪足複合設計,覆蓋180個檢測點的觸覺皮膚,在養老院場景展現出強大的地形適應與人機交互能力;
- 智元機器人:2024年初推出首個具身大模型,實現語言、視覺與動作的統一表示,通過21億元收購上緯新材引發借殼上市猜想,聚焦高端具身智能解決方案;
- 宇樹科技:以人形機器人登上春晚為契機,加速IPO籌備,計劃2025年底遞交上市申請,有望成為A股“人形機器人第一股”,主打消費級與工業級雙賽道;
- Sharpa/舞肌科技:在靈巧手領域實現突破,Sharpa的視觸覺集成靈巧手、舞肌科技的高自由度機械臂,代表了國內硬件研發的頂尖水平,成為產業鏈核心零部件供應商。
此外,斯坦德機器人、仙工智能、雲跡科技等企業紛紛衝刺IPO,形成“整機廠+核心零部件+場景應用”的完整產業生態,2025年上半年國內具身智能產業鏈融資事件達144次,融資金額195億元。
總結
具身智能正站在“技術爆發+產業落地”的雙重拐點,成為人工智能從“數字虛擬”走向“物理現實”的核心載體。從認知科學的理論假說,到多模態大模型驅動的技術突破;從實驗室的Demo演示,到工業車間的規模化應用,具身智能用短短几年時間完成了“從0到1”的跨越,2025年的產業化元年標誌著其正式進入“從1到N”的快速發展期。
當前,技術層面正朝著“大模型+世界模型”的協同方向演進,硬件層面聚焦靈巧操作與成本優化,應用層面遵循“工業先於家庭”的落地路徑,政策與資本的雙重加持則為行業發展提供了強勁動力。但同時,Sim2Real鴻溝、泛化能力不足、成本高企等挑戰仍需長期攻堅,具身智能的“GPT時刻”尚未到來——正如專家預測,當世界模型實現通用物理推演,當機器人集群生成海量真實數據,才會迎來真正的突破性爆發。
展望未來,具身智能不僅是實現通用人工智能的關鍵路徑,更是推動產業升級、重構人機關係的核心力量。它將讓機器人從“程序化工具”轉變為“自主化代理”,從工業生產到家庭服務,從醫療輔助到應急救援,深度融入千行百業,推動人類社會邁入“人機共創”的全新階段。對於研究者而言,這是充滿挑戰的學術前沿;對於企業而言,這是萬億級的市場藍海;對於普通人而言,這是即將改變生活的科技革命。
正如DeepMind首席科學家David Silver所言:“沒有具身的AGI就像沒有身體的幽靈,無法真正理解人類世界。” 具身智能的征途是星辰大海,而我們正處在這場革命的起點。
Embodied AI: a deep look at research—technology breakthroughs to industrial scale
As AI steps from bits into atoms, a revolution asks how intelligence becomes physical. In 2025, “embodied intelligence” entered China’s Government Work Report as a future industry priority; global financing topped ¥50B+, China’s industry ¥480B+, +67.8% YoY. From flexible factories to home assistance, precise medical work to hazardous rescue, embodied systems—“physical bodies + AI minds”—bridge the classic gap where models “know but cannot do.” After perception (“see”) and cognition (“understand language”), we enter embodied AI—the leap to act in the real world.
Captured at (local ISO): 2026-05-18 05:17:12
Preface
As AI steps from bits into atoms, a revolution asks how intelligence becomes physical. In 2025, “embodied intelligence” entered China’s Government Work Report as a future industry priority; global financing topped ¥50B+, China’s industry ¥480B+, +67.8% YoY. From flexible factories to home assistance, precise medical work to hazardous rescue, embodied systems—“physical bodies + AI minds”—bridge the classic gap where models “know but cannot do.”
After perception (“see”) and cognition (“understand language”), we enter embodied AI—the leap to act in the real world. Academician Zhang Bo (Tsinghua) noted intelligence without embodiment is incomplete. As multimodal LLMs fuse with robotics, embodied AI shifts from lab curiosity toward industrial scale—a new chapter of human–machine coexistence. This article covers definitions, state of play, frontiers, and key players.
1. What is embodied AI?
Definition and hallmarks
In 2025, IAAI with IEEE/ACM issued an Embodied AI Technology White Paper with a standard definition: embodied intelligence is a physically instantiated agent that continuously interacts with the environment through a perceive–decide–act–feedback loop—understanding, adapting to, and reshaping surroundings—able to complete complex tasks in open worlds.
Versus disembodied software AI (e.g., pure chat models), four traits stand out:
- Embodiment: physical platform, multimodal sensors, actuators, social role—internalizes physics (gravity, friction) from “having a body” to “understanding physics.”
- Interactivity: bidirectional coupling—perception guides action; action reshapes perception—not passive log ingestion.
- Adaptability: policy shifts under open‑world dynamics and uncertainty.
- Emergence: simple rules + interaction yield complex, hard‑to‑forecast behavior.
Core logic and boundaries
Roots lie in embodied cognition—intelligence is not just an algorithm in a head; it couples body morphology, motor skill, and environment.
Distinctions:
- vs. Agent (software): agents may be virtual or physical; embodied AI stresses physical grounding.
- vs. AGI: embodied capability is a path from digital to physical, not the final milestone.
- vs. embodied robot: the former is capability; the latter is hardware.
Stack: top semantics/planning (LLM + world model); middle perception–decision fusion (multimodal representation); bottom physical interaction (motion + dexterity)—“brain + cerebellum + body.”
2. Research landscape: breakthroughs to deployment
Technology stages
From 1990s behaviorism (Brooks) and 2018 formal models (Ay et al.) to today’s multimodal LLM era—post‑ChatGPT papers exploded; “embodied agent” hits on Scholar cited at 1,350 in 2024, about double prior norms.
Three capability fronts:
- Perception: MLLMs (GPT‑4o, Gemini 1.5, Qwen‑VL) zero‑shot localize/navigate with broader generalization.
- Long‑horizon planning: LLM reasoning decomposes commands—“pour water” → find cup, fetch, locate dispenser, fill, deliver—easing classic task decomposition pain.
- Short horizons / control: from API/code to direct action tokens; ReKep‑style relational keypoints boost precision and generalization.
Scenario progress
2025 is often called industrialization year one:
- Manufacturing: UBTECH Walker S1 claimed first humanoid at industrial scale with AGVs, at BYD‑class plants—500+ LOI units; Longcheer lines cite +12% yield with embodied robots.
- Services: Tencent “Xiaowu” supports elders—lift/transfer, fetch—50 kg bicom arms, stairs/slopes; Yunji hotel robots IPO’d as “robot service agent #1 share.”
- Homes: systems can attempt “make dinner” with nontrivial success—cost + generalization still cap mass adoption.
- Special risk: nuclear patrol, emergency response—tele‑op / autonomous arms replace people where safety dominates.
Current bottlenecks
- Sim2Real: rigid bin pick improves; fluids, deformables lag—safety certification is the last mile.
- Hardware cost: dexterous hands, rich sensors stay expensive—limits consumer scale.
- Generalization: great in structured worlds; open‑world dynamics still challenging.
- Closed‑loop data: real‑world logs are costly/slow—hard to spin the data → model → improve flywheel.
3. Research directions: core race tracks
3.1 Multimodal LLMs × world models
Trend: upgrade the brain—pair MLLM semantics with world models predicting physical dynamics for lookahead. Fast‑in‑slow paradigms split slow planning (LLM) from fast reflexes (modules), balancing accuracy and latency.
3.2 Dexterous manipulation and precision control
Dexterity dominated IROS 2025 buzz: 22‑DoF hands with vision‑tactile fusion (e.g., Sharpa dealing cards); muscle‑tech demos push motor miniaturization and thermal limits. Algorithms: learning from demonstration scales skills quickly from human traces.
3.3 Closed‑loop learning and data efficiency
Closed‑loop updates from environment reward cut label needs. Cheap arms, open sims (BEHAVIOR‑1K), and hybrid real+sim training widen access.
3.4 Multi‑agent coordination and swarms
Complex sites need teams—humanoids + AMRs in plants; search‑and‑rescue swarms; distributed decisions. Coordination aims for 1+1>2 throughput.
3.5 Scenario fit and commercial paths
Consensus: industry before home—clear tasks and ROI in factories; homes wait on cost and generalization—vertical venues (hospitals, hotels) bridge first.
4. Leading companies: global posture
Foreign anchors
- Google DeepMind: VLA model RT‑2 fuses web + robot data—novel task success 32% → 62% in cited work—helped define embodied foundation models.
- Tesla: Optimus humanoid—2025 mass‑prod goal; leverages autopilot motor/control stack for cost + reliability.
- Meta: multimodal + sim data factories cut real‑robot hours—social/industrial collaboration angles.
- Amazon: Astro home robot × Alexa semantics for integrated home UX.
Domestic benchmarks
- UBTECH: Walker S1 industrial humanoid—ROSA2.0 OS, Gen‑3 hands—500+ LOI cited; 2023 HK IPO “humanoid first share.”
- Tencent Robotics X: “Xiaowu” for human environments—quad‑wheel‑leg hybrid, 180‑point tactile skin—nursing‑home terrain/interaction demos.
- AgiBot (Zhiyuan): 2024 embodied foundation model unifying language, vision, action; ¥2.1B deal sparked backdoor listing chatter—premium solutions positioning.
- Unitree: Spring Festival humanoids sped IPO prep—2025 filing rumored for A‑share “humanoid first share”—consumer + industrial lanes.
- Sharpa / muscle‑tech: vision‑tactile hands, high‑DoF arms—component leadership in the supply chain.
Also Standard Robots, SEER, Yunji pursuing IPO—OEM + parts + scenarios—144 funding events in H1 2025, ¥19.5B in China’s chain.
Summary
Embodied AI sits at tech lift‑off and industrial launch—the bridge from digital to physical. From cognitive theory to MLLM‑driven methods, from demos to shop floors, years of 0→1 work hits 2025 as 1→N acceleration.
Brain: LLM + world model synergy. Body: dexterity and cost curves. Markets: factories first, homes later. Policy + capital add tailwinds. Still, Sim2Real, generalization, and cost need long campaigns—the field’s “ChatGPT moment” is not here yet: breakthroughs may await general physics world models and planet‑scale real robot data.
Looking ahead, embodied AI is both an AGI path and an industrial transformer—from programmed tools to autonomous agents across plants, clinics, homes, and hazards—for researchers (hard frontier), enterprises (trillion‑class potential), and society (life changes).
As DeepMind’s David Silver put it: “AGI without embodiment is a ghost that cannot truly know our world.” The journey is wide open—and we are still near the start.