AI 十大论文精讲(三):RLHF 范式奠基 ——InstructGPT 如何让大模型 “听懂人话”
解读 OpenAI 2022 年《Training Language Models to Follow Instructions with Human Feedback》(InstructGPT):用 RLHF(监督微调、奖励建模、强化学习对齐)把大模型从「会说话」拉到更听指令、更少胡编有害输出。
系列文章前言
在人工智能技术从理论突破走向工程落地的进程中,一篇篇里程碑式的论文如同灯塔,照亮了技术演进的关键路径。为帮助大家吃透 AI 核心技术的底层逻辑、理清行业发展脉络,博主推出「AI 十大核心论文解读系列」,每篇聚焦一篇关键论文的问题背景、核心创新与行业影响。本篇博客解读AI领域十大论文的第二篇——《Training Language Models to Follow Instructions with Human Feedback》论文。
前言
2022 年,OpenAI 发表的《Training Language Models to Follow Instructions with Human Feedback》堪称大模型从 “能做事” 走向 “会做事” 的分水岭 —— 在此之前,即便像 GPT-3 这样参数规模达 175B 的 “巨无霸” 模型,也常因 “捏造事实、偏离指令、生成有害内容” 让用户头疼;这篇论文首次用 “人类反馈强化学习(RLHF)” 构建了一套可复现的技术框架,让模型真正对齐 “听懂指令、诚实输出” 的人类需求。本篇博客会给予论文详细拆解 RLHF 的技术细节、实验设计与学术逻辑,满足研究者与开发者对技术原理的需求。
一、研究背景与核心问题
大型语言模型(LMs)的预训练目标多为“预测互联网文本的下一个token”,这与用户核心需求“安全、诚实地遵循指令”存在本质错位。论文指出,即使是175B参数的GPT-3,也常出现捏造事实、生成有毒内容或偏离指令的行为。该研究的核心目标是通过“人类反馈强化学习(RLHF)”技术,实现模型与人类意图的对齐,定义对齐的三大标准:helpful(辅助用户完成任务)、honest(不编造信息)、harmless(不造成物理/心理/社会伤害)。
二、论文深度解读
1、核心方法:RLHF三步对齐法
论文提出的RLHF(Reinforcement Learning from Human Feedback)框架包含三个关键步骤,形成闭环优化:
- 有监督微调(SFT):收集13k条包含人类示范的prompt数据(含OpenAI API用户提交和标签员编写的prompt),对GPT-3进行有监督训练,让模型学习“符合人类期望的输出模式”。标签员需通过筛选测试(评估敏感内容识别能力和标注一致性),确保示范数据质量,训练采用余弦学习率衰减和0.2的残差dropout,迭代16个epoch。
- 奖励模型训练(RM):收集33k条prompt对应的模型输出排名数据(标签员对4-9个模型输出按偏好排序),基于对比学习训练6B参数的奖励模型。损失函数采用交叉熵损失,优化目标为预测人类偏好的输出对,即最大化
σ(rθ(x,yw) - rθ(x,yl))(yw为偏好输出,yl为非偏好输出),训练时将同一prompt的所有输出对作为单个batch元素,避免过拟合。 - 强化学习优化(PPO):以SFT模型为初始化,利用PPO算法最大化奖励模型的得分,同时引入KL惩罚(控制与SFT模型的输出差异)避免过度优化。为缓解“对齐税”(alignment tax,即对齐后公共NLP任务性能退化),提出PPO-ptx变体,在优化中融入预训练数据的梯度更新,目标函数为
objective(φ) = E[rθ(x,y) - βlog(πφ^RL/π^SFT)] + γE[logπφ^RL(x)]。
从通俗易懂的角度来讲,这三个流程可以类比于“教模型学做事”的完整流程
- 第一步:跟着老师学示范:找40个专业“人类老师”,让他们针对各种需求(写故事、改文案、答问题)做正确示范,比如用户问“怎么重拾工作热情”,老师就给出5个靠谱想法。模型像学生一样,照着13000多个示范案例反复学,先摸清“正确做法”的门道。
- 第二步:学会给作业评好坏:让老师给模型的“作业”打分——同一个问题让模型输出4-9个答案,老师排个名次(最好到最差)。模型从这些排名里学规律:比如“实事求是”的答案排前面,“胡编乱造”的排后面,慢慢练就“自我评判”的能力。
- 第三步:反复练习拿高分:让模型不断做题(处理新prompt),每次输出后对照自己的“评判标准”(奖励模型)改答案,争取拿更高分。同时还要注意:不能为了拿高分就忘了自己原来的知识(KL惩罚),也不能因为学了新技能就搞砸老任务(比如做阅读理解),所以还要偶尔复习“课本”(预训练数据),避免偏科。
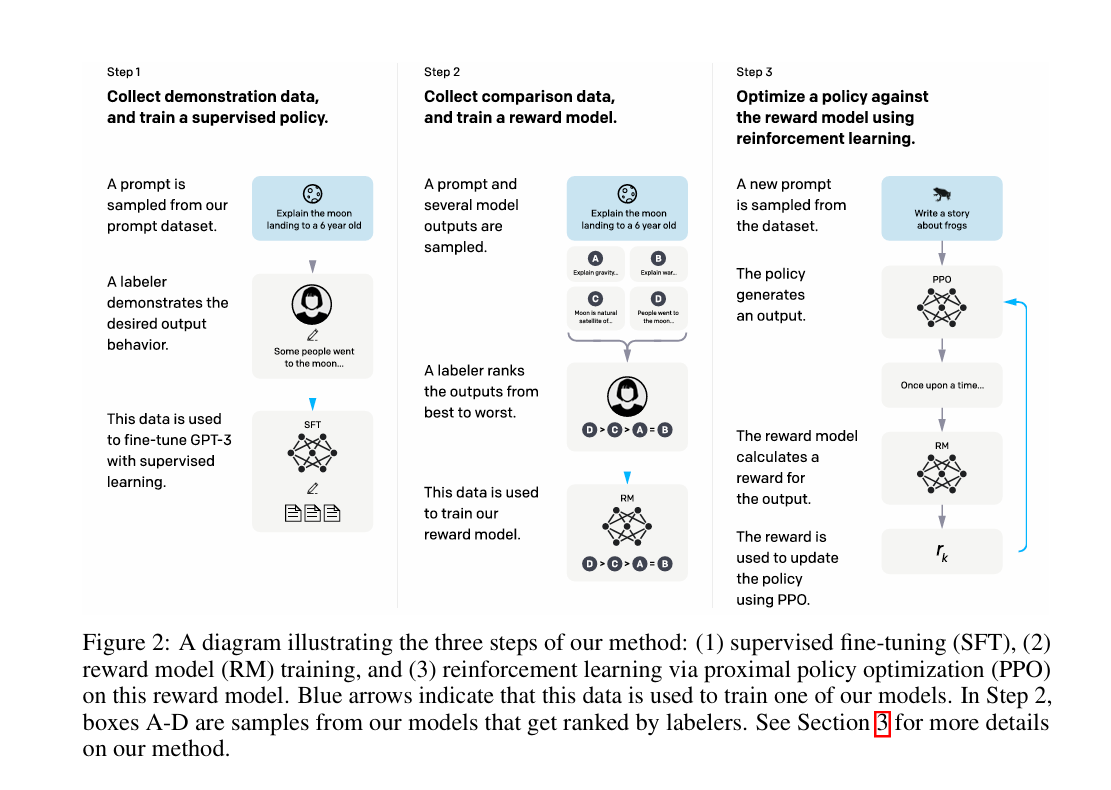
图 2:展示我们方法三个步骤的示意图:(1)监督微调(SFT)、(2)奖励模型(RM)训练、(3)基于该奖励模型的近端策略优化(PPO)强化学习。蓝色箭头表示该数据用于训练我们的某个模型。步骤 2 中,方框 A-D 是来自我们模型的样本,标注人员会对这些样本进行排序。关于我们方法的更多细节,请参见第 3 节。
2、关键实验结果与核心发现
- 模型偏好性优势:在人类评估中,1.3B参数的InstructGPT(PPO-ptx)输出被偏好的概率高于175B GPT-3,175B InstructGPT对175B GPT-3的胜率达85±3%,对少量提示(few-shot)的GPT-3胜率达71±4%,验证了“小规模对齐模型优于大规模未对齐模型”的核心假设。
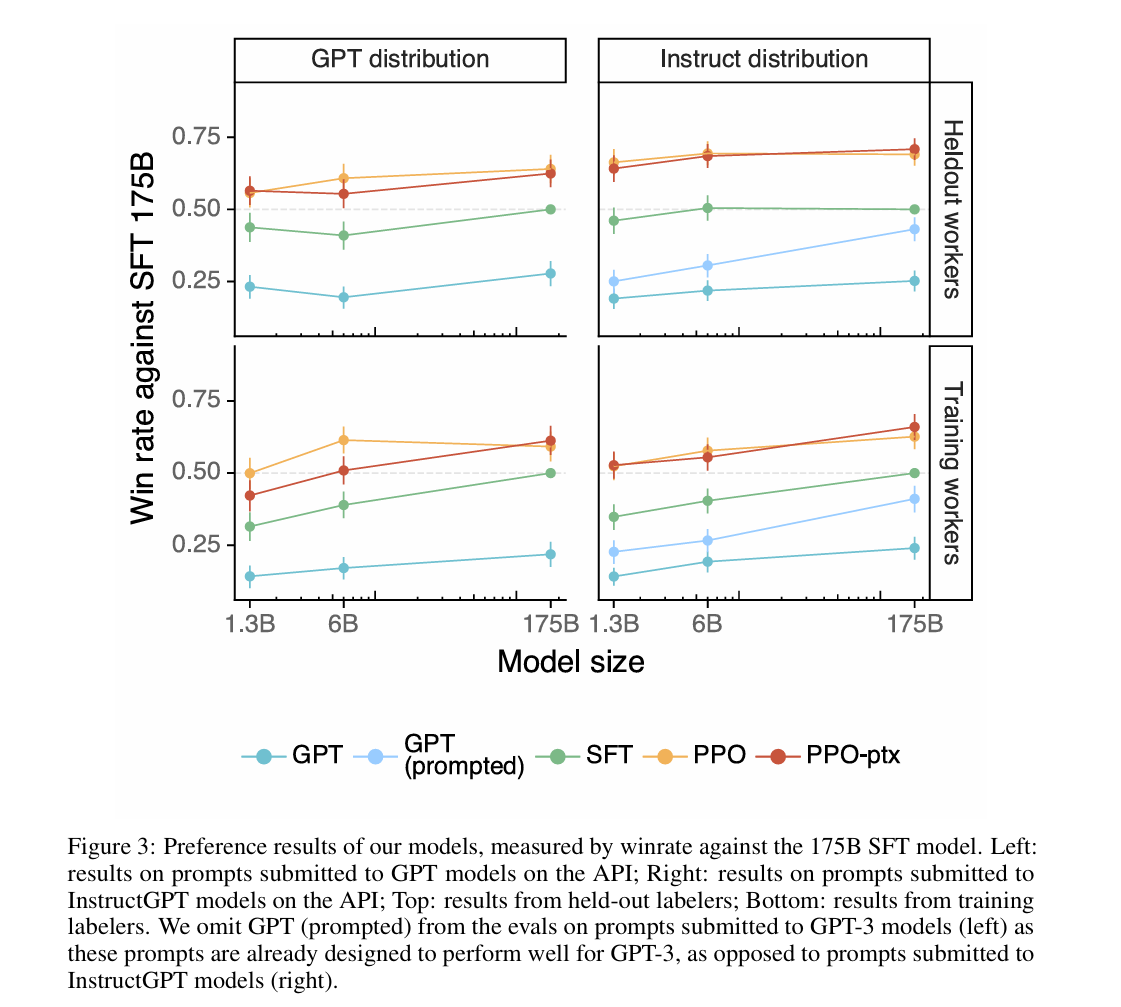
图 3:我们模型的偏好结果,以相对于 1750 亿参数 SFT 模型的胜率衡量。左图:提交至 API 上 GPT 模型的提示词的结果;右图:提交至 API 上 InstructGPT 模型的提示词的结果;上图:预留标注人员的结果;下图:训练标注人员的结果。在针对提交至 GPT-3 模型的提示词的评估中(左图),我们省略了 GPT(带提示词的),因为这些提示词原本就被设计为在 GPT-3 上表现良好,这与提交至 InstructGPT 模型的提示词(右图)不同。 - 对齐指标提升:在TruthfulQA基准中,InstructGPT生成真实且有信息量答案的概率是GPT-3的两倍;封闭域任务(如摘要、闭卷问答)中,幻觉率从GPT-3的41%降至21%;在RealToxicityPrompts数据集上,受“尊重指令”提示时,有毒输出减少25%。换句话说,就是模型变老实、变文明了:以前GPT-3爱编瞎话(比如没依据的事实),现在InstructGPT说真话的概率翻倍;以前可能冒出脏话,现在受提醒后脏话少了四分之一;写摘要时乱加信息的情况也少了一半。
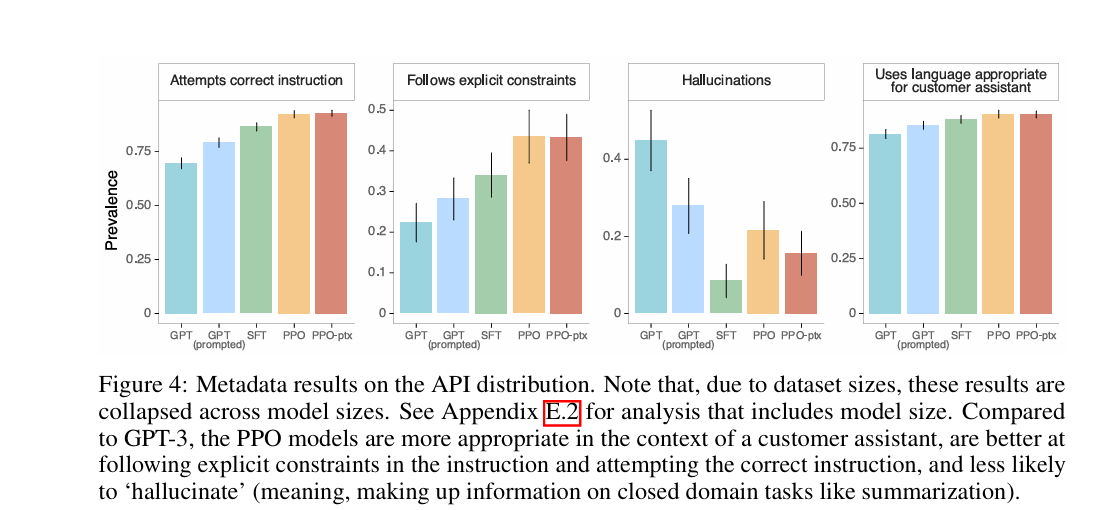
图 4:API 分布上的元数据结果。注意,由于数据集大小的原因,这些结果是跨模型大小合并的。有关包含模型大小的分析,请参见附录 E.2。与 GPT-3 相比,PPO 模型在客户助手场景中更合适,更擅长遵循指令中的明确约束并尝试执行正确的指令,且更少出现 “幻觉”(即,在总结等封闭域任务中编造信息)。
- 性能退化缓解:PPO-ptx模型通过融入预训练梯度,在SQuAD、DROP、HellaSwag等公共NLP数据集上的性能退化显著缓解,部分任务(如HellaSwag)甚至超过GPT-3。性能退化可以理解为遗忘自己的预训练数据,用通俗易懂的话来说就是,刚开始优化后,模型可能在做阅读理解、翻译等老任务时表现变差(就像学了新技能忘了老本事),但后来加了“复习课本”的步骤,不仅没忘老本事,有些任务还比以前做得好。
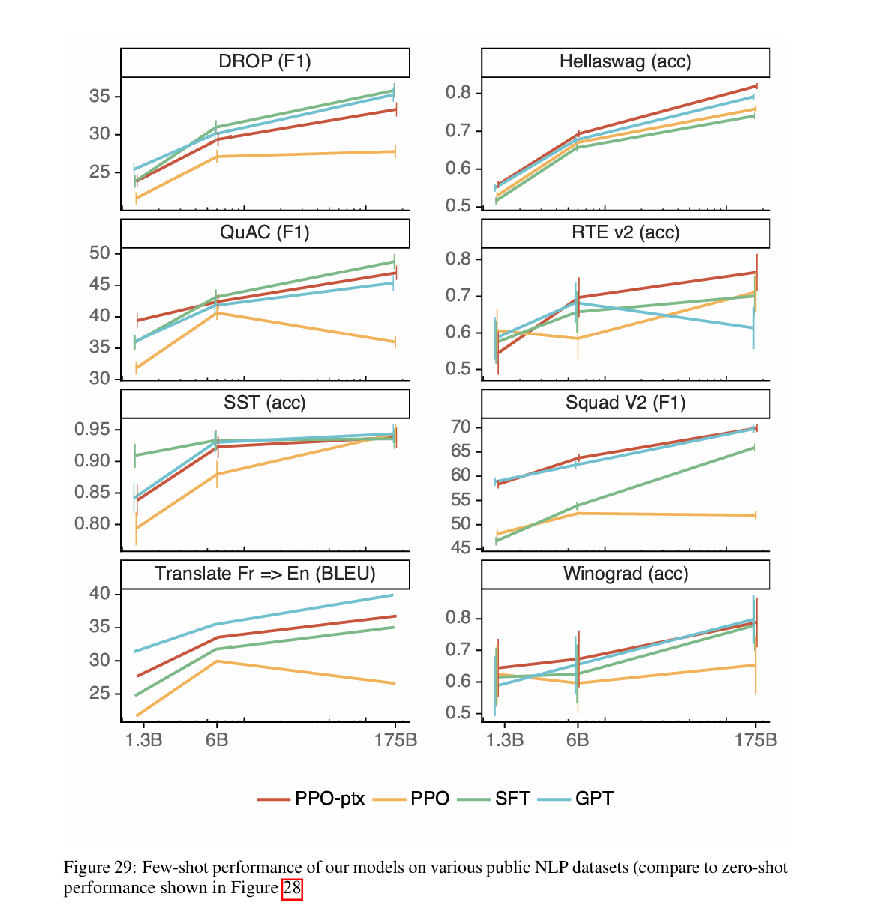
图 29:我们的模型在各种公开自然语言处理(NLP)数据集上的少样本性能(与图 28 所示的零样本性能相比)
- 泛化能力:未参与训练的“独立标签员”对InstructGPT的偏好率与训练标签员接近;模型能泛化到非英语指令、代码相关任务(尽管这些数据在训练集中占比极低)。
3、研究局限与后续进展
InstructGPT仍存在显著局限:对虚假前提的指令易盲从、简单问题过度犹豫(hedging)、多约束指令执行能力弱;在Winogender和CrowSPairs数据集上,偏见缓解效果不显著;对齐目标依赖标签员(以英语母语者为主)和API用户的偏好,缺乏更广泛人群的代表性。
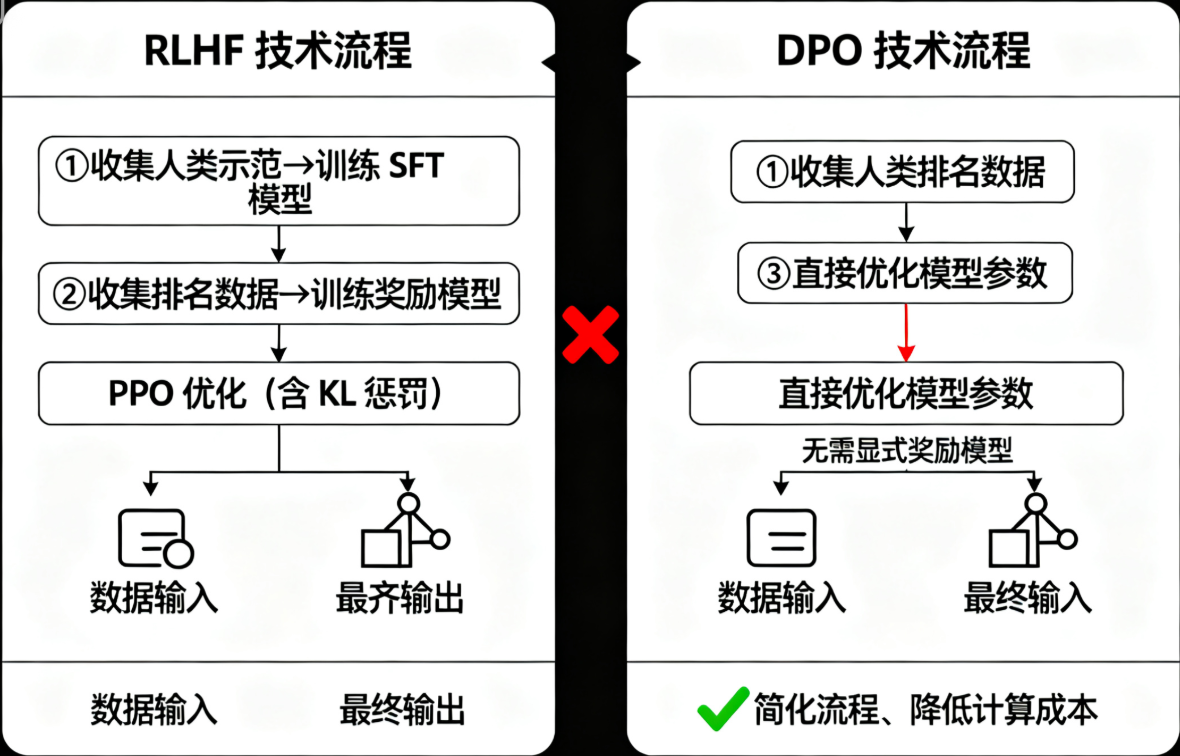
后续领域进展中,Direct Preference Optimization(DPO)技术成为关键突破:无需构建显式奖励模型,直接通过偏好数据(人类排名)优化模型参数,将RLHF的三步流程简化为两步,降低计算成本的同时保持对齐效果,其核心是通过极大似然估计直接建模偏好数据的概率分布,避免PPO的复杂优化过程。
4、研究意义与行业影响
InstructGPT论文奠定了“模型对齐”领域的技术范式,首次系统性验证了RLHF在大规模语言模型上的有效性,证明“对齐人类意图”可独立于模型规模成为核心优化目标。其提出的“helpful-honest-harmless”对齐框架,成为后续模型安全评估的核心标准;PPO-ptx缓解对齐税的思路,为平衡模型对齐性与任务性能提供了关键参考;而标签员筛选、数据收集的方法论,为后续偏好学习研究提供了可复现的实验范式。后来的ChatGPT、Claude等模型,都沿用了这种“让人类教、让人类评、让模型练”的思路;我们现在用AI写东西、查资料时,它能准确理解需求、不胡说八道,背后都有这篇论文的功劳——它开启了“大模型从‘博学’到‘好用’”的新时代。
总结
InstructGPT的核心贡献,是用严谨的RLHF框架证明了**“对齐优先于规模**”的核心逻辑,为大模型从“能力强大”走向“可靠可用”提供了可落地的技术路径。专业视角下,它是偏好学习与模型对齐的里程碑;通俗视角下,它是让AI“听懂人话、办对事”的关键一步。而后续DPO等技术的涌现,正是对这一核心思路的优化与延伸——模型对齐的终极目标,始终是让AI成为真正尊重人类意图、安全可靠的助手。\
AI 十大論文精講(三):RLHF 範式奠基 ——InstructGPT 如何讓大模型 “聽懂人話”
解讀 OpenAI 2022 年《Training Language Models to Follow Instructions with Human Feedback》(InstructGPT):以 RLHF(監督微調、獎勵模型、強化對齊)讓大模型更服從指令、減少捏造與有害輸出。
來源:https://blog.csdn.net/2403_87969572/article/details/154784144
抓取時間(ISO本地):2026-05-18 05:17:12
系列文章前言
在人工智能技術從理論突破走向工程落地的進程中,一篇篇里程碑式的論文如同燈塔,照亮了技術演進的關鍵路徑。為幫助大家吃透 AI 核心技術的底層邏輯、理清行業發展脈絡,博主推出「AI 十大核心論文解讀系列」,每篇聚焦一篇關鍵論文的問題背景、核心創新與行業影響。本篇博客解讀AI領域十大論文的第二篇——《Training Language Models to Follow Instructions with Human Feedback》論文。
文章目錄
前言
2022 年,OpenAI 發表的《Training Language Models to Follow Instructions with Human Feedback》堪稱大模型從 “能做事” 走向 “會做事” 的分水嶺 —— 在此之前,即便像 GPT-3 這樣參數規模達 175B 的 “巨無霸” 模型,也常因 “捏造事實、偏離指令、生成有害內容” 讓用戶頭疼;這篇論文首次用 “人類反饋強化學習(RLHF)” 構建了一套可復現的技術框架,讓模型真正對齊 “聽懂指令、誠實輸出” 的人類需求。本篇博客會給予論文詳細拆解 RLHF 的技術細節、實驗設計與學術邏輯,滿足研究者與開發者對技術原理的需求。
一、研究背景與核心問題
大型語言模型(LMs)的預訓練目標多為“預測互聯網文本的下一個token”,這與用戶核心需求“安全、誠實地遵循指令”存在本質錯位。論文指出,即使是175B參數的GPT-3,也常出現捏造事實、生成有毒內容或偏離指令的行為。該研究的核心目標是通過“人類反饋強化學習(RLHF)”技術,實現模型與人類意圖的對齊,定義對齊的三大標準:helpful(輔助用戶完成任務)、honest(不編造信息)、harmless(不造成物理/心理/社會傷害)。
二、論文深度解讀
1、核心方法:RLHF三步對齊法
論文提出的RLHF(Reinforcement Learning from Human Feedback)框架包含三個關鍵步驟,形成閉環優化:
- 有監督微調(SFT):收集13k條包含人類示範的prompt數據(含OpenAI API用戶提交和標籤員編寫的prompt),對GPT-3進行有監督訓練,讓模型學習“符合人類期望的輸出模式”。標籤員需通過篩選測試(評估敏感內容識別能力和標註一致性),確保示範數據質量,訓練採用餘弦學習率衰減和0.2的殘差dropout,迭代16個epoch。
- 獎勵模型訓練(RM):收集33k條prompt對應的模型輸出排名數據(標籤員對4-9個模型輸出按偏好排序),基於對比學習訓練6B參數的獎勵模型。損失函數採用交叉熵損失,優化目標為預測人類偏好的輸出對,即最大化
σ(rθ(x,yw) - rθ(x,yl))(yw為偏好輸出,yl為非偏好輸出),訓練時將同一prompt的所有輸出對作為單個batch元素,避免過擬合。 - 強化學習優化(PPO):以SFT模型為初始化,利用PPO算法最大化獎勵模型的得分,同時引入KL懲罰(控制與SFT模型的輸出差異)避免過度優化。為緩解“對齊稅”(alignment tax,即對齊後公共NLP任務性能退化),提出PPO-ptx變體,在優化中融入預訓練數據的梯度更新,目標函數為
objective(φ) = E[rθ(x,y) - βlog(πφ^RL/π^SFT)] + γE[logπφ^RL(x)]。
從通俗易懂的角度來講,這三個流程可以類比於“教模型學做事”的完整流程
- 第一步:跟著老師學示範:找40個專業“人類老師”,讓他們針對各種需求(寫故事、改文案、答問題)做正確示範,比如用戶問“怎麼重拾工作熱情”,老師就給出5個靠譜想法。模型像學生一樣,照著13000多個示範案例反覆學,先摸清“正確做法”的門道。
- 第二步:學會給作業評好壞:讓老師給模型的“作業”打分——同一個問題讓模型輸出4-9個答案,老師排個名次(最好到最差)。模型從這些排名裡學規律:比如“實事求是”的答案排前面,“胡編亂造”的排後面,慢慢練就“自我評判”的能力。
- 第三步:反覆練習拿高分:讓模型不斷做題(處理新prompt),每次輸出後對照自己的“評判標準”(獎勵模型)改答案,爭取拿更高分。同時還要注意:不能為了拿高分就忘了自己原來的知識(KL懲罰),也不能因為學了新技能就搞砸老任務(比如做閱讀理解),所以還要偶爾複習“課本”(預訓練數據),避免偏科。
圖 2:展示我們方法三個步驟的示意圖:(1)監督微調(SFT)、(2)獎勵模型(RM)訓練、(3)基於該獎勵模型的近端策略優化(PPO)強化學習。藍色箭頭表示該數據用於訓練我們的某個模型。步驟 2 中,方框 A-D 是來自我們模型的樣本,標註人員會對這些樣本進行排序。關於我們方法的更多細節,請參見第 3 節。
2、關鍵實驗結果與核心發現
- 模型偏好性優勢:在人類評估中,1.3B參數的InstructGPT(PPO-ptx)輸出被偏好的概率高於175B GPT-3,175B InstructGPT對175B GPT-3的勝率達85±3%,對少量提示(few-shot)的GPT-3勝率達71±4%,驗證了“小規模對齊模型優於大規模未對齊模型”的核心假設。
圖 3:我們模型的偏好結果,以相對於 1750 億參數 SFT 模型的勝率衡量。左圖:提交至 API 上 GPT 模型的提示詞的結果;右圖:提交至 API 上 InstructGPT 模型的提示詞的結果;上圖:預留標註人員的結果;下圖:訓練標註人員的結果。在針對提交至 GPT-3 模型的提示詞的評估中(左圖),我們省略了 GPT(帶提示詞的),因為這些提示詞原本就被設計為在 GPT-3 上表現良好,這與提交至 InstructGPT 模型的提示詞(右圖)不同。 - 對齊指標提升:在TruthfulQA基準中,InstructGPT生成真實且有信息量答案的概率是GPT-3的兩倍;封閉域任務(如摘要、閉卷問答)中,幻覺率從GPT-3的41%降至21%;在RealToxicityPrompts數據集上,受“尊重指令”提示時,有毒輸出減少25%。換句話說,就是模型變老實、變文明瞭:以前GPT-3愛編瞎話(比如沒依據的事實),現在InstructGPT說真話的概率翻倍;以前可能冒出髒話,現在受提醒後髒話少了四分之一;寫摘要時亂加信息的情況也少了一半。
圖 4:API 分佈上的元數據結果。注意,由於數據集大小的原因,這些結果是跨模型大小合併的。有關包含模型大小的分析,請參見附錄 E.2。與 GPT-3 相比,PPO 模型在客戶助手場景中更合適,更擅長遵循指令中的明確約束並嘗試執行正確的指令,且更少出現 “幻覺”(即,在總結等封閉域任務中編造信息)。
- 性能退化緩解:PPO-ptx模型通過融入預訓練梯度,在SQuAD、DROP、HellaSwag等公共NLP數據集上的性能退化顯著緩解,部分任務(如HellaSwag)甚至超過GPT-3。性能退化可以理解為遺忘自己的預訓練數據,用通俗易懂的話來說就是,剛開始優化後,模型可能在做閱讀理解、翻譯等老任務時表現變差(就像學了新技能忘了老本事),但後來加了“複習課本”的步驟,不僅沒忘老本事,有些任務還比以前做得好。
圖 29:我們的模型在各種公開自然語言處理(NLP)數據集上的少樣本性能(與圖 28 所示的零樣本性能相比)
- 泛化能力:未參與訓練的“獨立標籤員”對InstructGPT的偏好率與訓練標籤員接近;模型能泛化到非英語指令、代碼相關任務(儘管這些數據在訓練集中佔比極低)。
3、研究侷限與後續進展
InstructGPT仍存在顯著侷限:對虛假前提的指令易盲從、簡單問題過度猶豫(hedging)、多約束指令執行能力弱;在Winogender和CrowSPairs數據集上,偏見緩解效果不顯著;對齊目標依賴標籤員(以英語母語者為主)和API用戶的偏好,缺乏更廣泛人群的代表性。
後續領域進展中,Direct Preference Optimization(DPO)技術成為關鍵突破:無需構建顯式獎勵模型,直接通過偏好數據(人類排名)優化模型參數,將RLHF的三步流程簡化為兩步,降低計算成本的同時保持對齊效果,其核心是通過極大似然估計直接建模偏好數據的概率分佈,避免PPO的複雜優化過程。
4、研究意義與行業影響
InstructGPT論文奠定了“模型對齊”領域的技術範式,首次系統性驗證了RLHF在大規模語言模型上的有效性,證明“對齊人類意圖”可獨立於模型規模成為核心優化目標。其提出的“helpful-honest-harmless”對齊框架,成為後續模型安全評估的核心標準;PPO-ptx緩解對齊稅的思路,為平衡模型對齊性與任務性能提供了關鍵參考;而標籤員篩選、數據收集的方法論,為後續偏好學習研究提供了可復現的實驗範式。後來的ChatGPT、Claude等模型,都沿用了這種“讓人類教、讓人類評、讓模型練”的思路;我們現在用AI寫東西、查資料時,它能準確理解需求、不胡說八道,背後都有這篇論文的功勞——它開啟了“大模型從‘博學’到‘好用’”的新時代。
總結
InstructGPT的核心貢獻,是用嚴謹的RLHF框架證明了**“對齊優先於規模**”的核心邏輯,為大模型從“能力強大”走向“可靠可用”提供了可落地的技術路徑。專業視角下,它是偏好學習與模型對齊的里程碑;通俗視角下,它是讓AI“聽懂人話、辦對事”的關鍵一步。而後續DPO等技術的湧現,正是對這一核心思路的優化與延伸——模型對齊的終極目標,始終是讓AI成為真正尊重人類意圖、安全可靠的助手。\
AI Top 10 Papers Deep Dive (3): RLHF Foundations — How InstructGPT Taught LLMs to “Understand People”
A concise walkthrough of OpenAI’s 2022 InstructGPT paper: RLHF — SFT plus a preference-trained reward model and PPO refinement — aligns large language models to follow instructions and curb toxic or fabricated answers.
Captured at (local ISO): 2026-05-18 05:17:12
Series Preface
As AI moves from theory to production, landmark papers act as lighthouses on the path of progress. This “AI Top 10 Core Papers” series unpacks the problem background, core innovations, and industry impact of each pivotal work. This post covers paper #3 in the series — Training Language Models to Follow Instructions with Human Feedback.
Preface
OpenAI’s 2022 paper Training Language Models to Follow Instructions with Human Feedback marked the shift from models that “can do things” to models that “do the right things.” Even 175B GPT-3 often hallucinated, drifted off instructions, or produced harmful text. This work introduced a reproducible Reinforcement Learning from Human Feedback (RLHF) pipeline so models align with human goals: follow instructions and answer honestly. This post walks through RLHF mechanics, experiments, and why it matters for researchers and builders.
I. Research Background and Core Problem
Large language models (LMs) are mostly pretrained to predict the next token on internet text, which misaligns with user needs: safe, honest instruction following. Even 175B GPT-3 often fabricates facts, generates toxic content, or ignores prompts. The paper’s goal is alignment via RLHF, with three criteria: helpful (complete the user’s task), honest (no fabrication), and harmless (no physical, psychological, or social harm).
II. In-Depth Paper Analysis
1. Core Method: Three-Step RLHF Alignment
RLHF forms a closed optimization loop:
- Supervised Fine-Tuning (SFT): ~13k prompts with human demonstrations (OpenAI API submissions plus labeler-written prompts). Labelers pass screening (sensitive-content judgment and consistency). Training uses cosine LR decay, 0.2 residual dropout, 16 epochs.
- Reward Model (RM): ~33k prompts with ranked model outputs (4–9 candidates per prompt). A 6B RM is trained with contrastive loss maximizing
σ(rθ(x,yw) - rθ(x,yl))(preferred vs. dispreferred). All pairs for one prompt share a batch element to reduce overfitting. - PPO Reinforcement Learning: Initialize from SFT; PPO maximizes RM score with a KL penalty vs. SFT to limit “alignment tax” (NLP benchmark regression). PPO-ptx mixes pretraining gradients:
objective(φ) = E[rθ(x,y) - βlog(πφ^RL/π^SFT)] + γE[logπφ^RL(x)].
Intuitive analogy — teaching a student:
- Follow the teacher: ~40 expert labelers demonstrate good answers on diverse prompts; the model learns from ~13k examples.
- Learn to grade: Labelers rank 4–9 outputs per prompt; the RM learns what humans prefer.
- Practice for high scores: The policy iterates on new prompts, improves against the RM, but KL + pretraining replay prevent forgetting old skills.
Figure 2: Three steps — (1) SFT, (2) RM training, (3) PPO on the RM. Blue arrows show training data flow. In step 2, boxes A–D are model samples ranked by labelers. See Section 3 for details.
2. Key Experimental Results and Findings
-
Human preference wins: 1.3B InstructGPT (PPO-ptx) is preferred over 175B GPT-3; 175B InstructGPT beats 175B GPT-3 ~85±3% and few-shot GPT-3 ~71±4% — smaller aligned models can beat larger unaligned ones.
Figure 3: Win rates vs. 175B SFT. Left: GPT API prompts; right: InstructGPT API prompts; top: held-out labelers; bottom: training labelers. -
Alignment metrics: On TruthfulQA, InstructGPT is ~2× more likely to give truthful, informative answers; closed-domain tasks (summarization, closed-book QA) see hallucination drop from 41% to 21%; on RealToxicityPrompts, toxicity drops ~25% with “respectful” prompting — models become more honest and civil.
Figure 4: Metadata on the API distribution (pooled across sizes; see Appendix E.2 for per-size). PPO models are more suitable in customer-assistant settings, better at explicit constraints, and hallucinate less on closed-domain tasks.
- Mitigating regression: PPO-ptx recovers performance on SQuAD, DROP, HellaSwag, etc.; some tasks even beat GPT-3.
Figure 29: Few-shot performance on public NLP benchmarks (vs. zero-shot in Figure 28).
- Generalization: Held-out labelers prefer InstructGPT similarly; the model generalizes to non-English and code-like prompts despite low training share.
3. Limitations and Follow-Up Work
InstructGPT still fails on false premises, over-hedges on easy questions, and struggles with many simultaneous constraints; bias gains on Winogender/CrowSPairs are weak; alignment reflects English-speaking labelers and API users.
Direct Preference Optimization (DPO) later simplified RLHF: optimize directly on preference rankings without an explicit RM, cutting cost while preserving alignment.
4. Significance and Industry Impact
This paper established the alignment paradigm: RLHF works at scale; intent alignment can matter more than raw size. The helpful–honest–harmless framework became a safety benchmark; PPO-ptx inspired balancing alignment vs. capability; labeler and data protocols influenced preference learning. ChatGPT, Claude, and similar products follow teach → judge → practice — the bridge from “knowledgeable” to usable LLMs.
Summary
InstructGPT proved with a rigorous RLHF pipeline that alignment can trump scale, giving a practical path from “powerful” to reliable. It is a milestone in preference learning; in plain terms, it is why modern AI follows instructions and avoids nonsense. DPO and successors refine the same goal: AI that respects human intent safely and reliably.