AI 十大论文精讲(一):不懂 Attention 不算懂 AI?一文读懂《Attention Is All You Need》
2、Transformer整体架构:编码器+解码器的“精密协作系统” 论文节详细描述了架构细节,核心是“6层堆叠+残差连接+层归一化”,每个组件都有明确的设计目标,下面结合参数和原理双向解读:
系列文章前言
在人工智能技术从理论突破走向工程落地的进程中,一篇篇里程碑式的论文如同灯塔,照亮了技术演进的关键路径。为帮助大家吃透 AI 核心技术的底层逻辑、理清行业发展脉络,博主推出「AI 十大核心论文解读系列」,每篇聚焦一篇关键论文的问题背景、核心创新与行业影响。本篇博客解读《Attention Is All You Need》论文。
前言:为何它能入选AI工程领域“十大必看论文”
在人工智能工程的发展史上,有一批论文如同“灯塔”,照亮了技术突破的方向。“AI工程领域十大核心论文”覆盖模型架构、微调技术、检索增强、智能体等关键方向,而2017年谷歌团队发表的《Attention Is All You Need》,无疑是其中最具“奠基性”的一篇——它彻底脱离前人的序列模型框架,以全新的“自注意力机制”重构了自然语言处理(NLP)乃至整个深度学习的技术路径。
如果说GPT、BERT、LLaMA等大模型是AI时代的“高楼大厦”,那《Attention Is All You Need》就是搭建这些大厦的“钢筋骨架”。如今几乎所有现代大型语言模型(LLM)的设计,都离不开这篇论文提出的Transformer架构。无论是AI工程师面试必问的“并行计算原理”,还是日常开发依赖的“上下文理解能力”,其技术根源都能追溯到这篇仅11页的论文。今天,我们就来深度拆解这篇改变AI格局的经典之作。
论文链接:https://arxiv.org/abs/1706.03762
一、技术背景:Transformer出现前的“三大困境”
2017年之前,NLP领域的主流技术方案是循环神经网络(RNN) 和卷积神经网络(CNN),但这两种模型存在难以突破的瓶颈,直接限制了AI处理复杂文本的能力。
1. 序列处理效率低下:串行计算拖慢训练节奏
RNN的核心逻辑是“逐句、逐词处理文本”——分析一句话时,模型必须先处理第一个词,再基于其结果处理第二个词,以此类推。这种串行模式如同人逐字读文章,无法同时处理多个词汇,导致训练速度极慢。对于长文本,RNN的训练时间会呈指数级增长,根本无法支撑大规模数据训练。
2. 长距离依赖难题:信息衰减导致语义断裂
RNN存在“短期记忆”缺陷。比如处理“小明昨天去超市买了苹果,他今天把____吃了”这句话时,RNN很难将“他”与前文的“小明”、“____”与前文的“苹果”关联起来。随着文本长度增加,早期词汇的信息会逐渐衰减,模型无法有效捕捉远距离词汇的语义联系。即便后续出现LSTM、GRU等改进模型,也只是缓解问题,并未从根本上解决。
3. 并行计算能力缺失:硬件资源无法充分利用
当时AI训练已开始依赖多GPU集群提升效率,但RNN和CNN几乎无法支持高效并行。RNN的串行逻辑决定了“下一个词的计算必须依赖上一个词”,无法拆分任务到多个GPU同时执行;CNN虽能并行处理局部特征,但对长文本的全局语义理解能力弱,且并行粒度有限。这种“并行困境”导致模型规模难以扩大——扩大参数规模只能依赖单GPU硬扛,成本和时间都难以承受。
正是在这样的技术瓶颈下,《Attention Is All You Need》的出现如同一场“技术革命”,用全新思路解决了上述所有问题。
二、论文深度解读:自注意力机制如何“颠覆”传统框架?
这篇论文的核心贡献只有一个:提出Transformer架构,用“自注意力机制”取代传统的序列处理逻辑。整个架构围绕“高效处理文本、支持并行计算、捕捉全局语义”三个目标设计,可从“核心机制”“架构细节”和“核心优势”三方面拆解。
1、自注意力机制——从“逐字读”到“全局扫”的范式革命
(1)自注意力的本质:不止是“找关联”,更是“动态加权语义融合”
专业定义:自注意力是将查询(Q)、键(K)、值(V)三组向量映射为输出的函数,输出是V的加权和,权重由Q与K的相似度计算得出。其核心是通过可学习的参数,为每个位置的token生成“全局依赖表征”,即每个token的最终向量都融合了所有其他token的语义信息。
通俗类比:把处理句子比作“班级自我介绍”——以前的RNN是“按座位顺序逐个发言,只能记住前一个人的名字”;自注意力是“所有人同时站起来,每个人手里举着自己的‘关键词牌’(K)和‘详细介绍’(V),你(当前token)拿着自己的‘需求牌’(Q),快速和所有人比对:和你需求越匹配的人,你越认真听他的介绍,最后把所有人的介绍按‘认真程度’加权整合,形成自己的最终印象”。
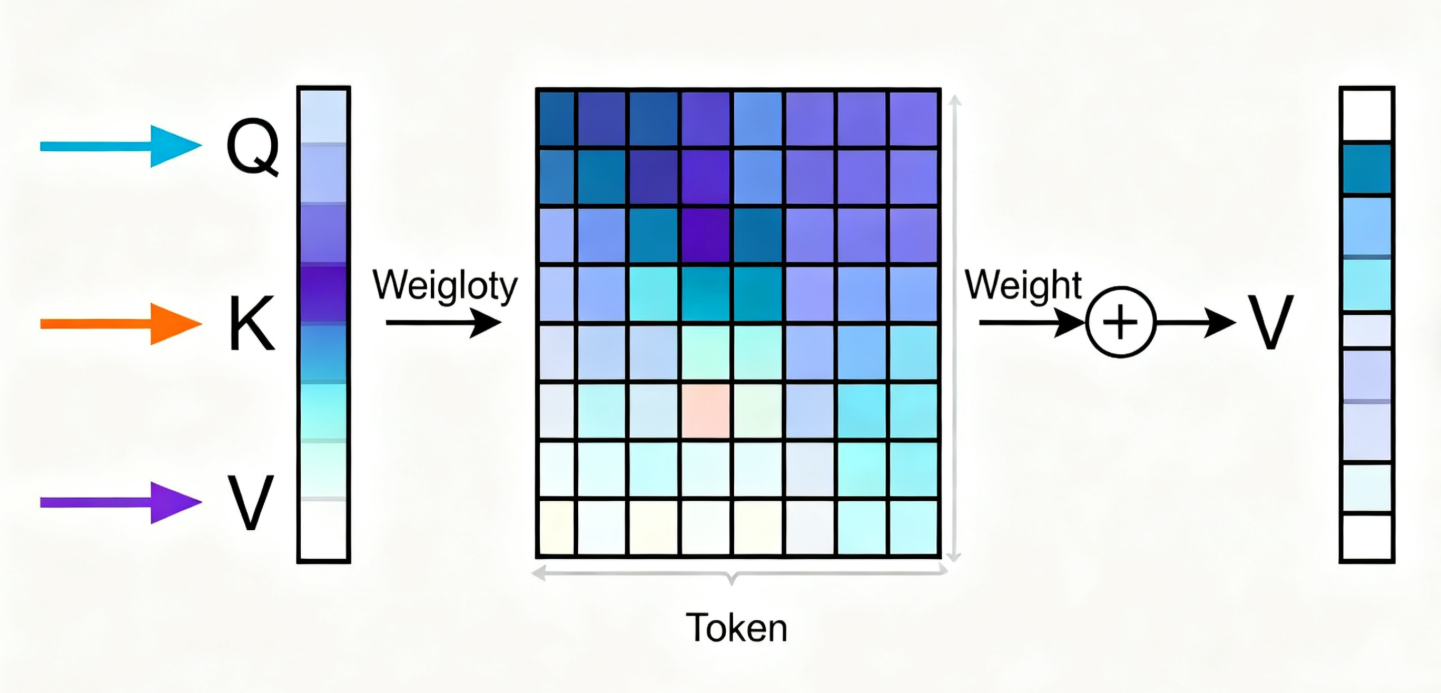
论文关键细节补充:
-
向量维度约束:论文中Q、K的维度 d k
64 d_k=64 dk=64,V的维度 d v
64 d_v=64 dv=64,整个模型的表征维度 d m o d e l
512 d_{model}=512 dmodel=512(所有子层输出维度统一,方便残差连接)。 - 计算流程(对应论文公式1):
- 计算Q与K的转置点积: Q K T QK^T QKT(得到 n × n n×n n×n的相似度矩阵,n是序列长度);
- 除以 d k \sqrt{d_k} dk (缩放步骤);
- 经过softmax得到归一化权重(权重和为1);
- 权重与V矩阵相乘,得到最终输出。
(2) 缩放点积注意力:解决“相似度分数爆炸”的关键
专业解释:为什么需要缩放?假设Q和K的每个元素都是均值为0、方差为1的独立随机变量,它们的点积 q ⋅ k
∑ i
1 d k q i k i q·k=\sum_{i=1}^{d_k}q_ik_i q⋅k=∑i=1dkqiki的均值为0、方差为 d k d_k dk。当 d k d_k dk较大(如 d k
512 d_k=512 dk=512)时,点积结果的数值会非常大,导致softmax函数的输入值落在“梯度接近0”的区域(softmax在输入值极大时,输出趋近于one-hot,导数几乎为0),模型无法更新参数。 缩放的作用:除以 d k \sqrt{d_k} dk 后,点积的方差被归一化为1,避免softmax陷入“梯度消失陷阱”。
通俗类比:比如 d k
64 d_k=64 dk=64时, d k
8 \sqrt{d_k}=8 dk =8。如果不缩放,Q和K的点积可能达到几十甚至上百,softmax会“偏爱”分数最高的那个token,其他token的权重几乎为0(相当于“只看一个词,忽略其他所有”);缩放后,分数被“压缩”到合理范围(比如原来100分变成12.5分),softmax能更均衡地分配权重,模型能关注到多个相关token。

(3) 多头注意力:让模型“多角度看问题”
专业解释:核心操作是将Q、K、V通过8组独立的线性投影( W i Q ∈ R d m o d e l × d k W_i^Q∈\mathbb{R}^{d_{model}×d_k} WiQ∈Rdmodel×dk, W i K ∈ R d m o d e l × d k W_i^K∈\mathbb{R}^{d_{model}×d_k} WiK∈Rdmodel×dk, W i V ∈ R d m o d e l × d v W_i^V∈\mathbb{R}^{d_{model}×d_v} WiV∈Rdmodel×dv)拆分为8个“子空间”(h=8,论文固定设置),每个子空间独立执行缩放点积注意力,得到8个 d v d_v dv维的输出( d v
64 d_v=64 dv=64),最后将8个输出拼接,通过一个线性投影 W O ∈ R h d v × d m o d e l W^O∈\mathbb{R}^{h d_v×d_{model}} WO∈Rhdv×dmodel得到最终结果。参数约束: h × d k
d m o d e l
512 h×d_k=d_{model}=512 h×dk=dmodel=512,确保总计算量与“单头注意力( d k
512 d_k=512 dk=512)”相当( O ( n 2 d m o d e l ) O(n^2 d_{model}) O(n2dmodel)),不增加额外计算负担。
通俗类比:多头注意力就像“8个不同的专家同时分析一句话”——有的专家专门关注“语法依赖”(比如“它”指代哪个名词),有的关注“语义关联”(比如“making”和“difficult”的因果关系),有的关注“逻辑连接”(比如“but”前后的转折)。最后把8个专家的分析结果整合,得到比单个专家更全面的理解。
论文实证支持:论文附录的注意力可视化(图3-5)显示,不同头确实学习到了不同依赖:比如某个头专门捕捉“making”与“more difficult”的长距离关联(完成“making…more difficult”短语),另两个头负责指代消解(“its”指向“Law”),验证了多头设计的有效性。
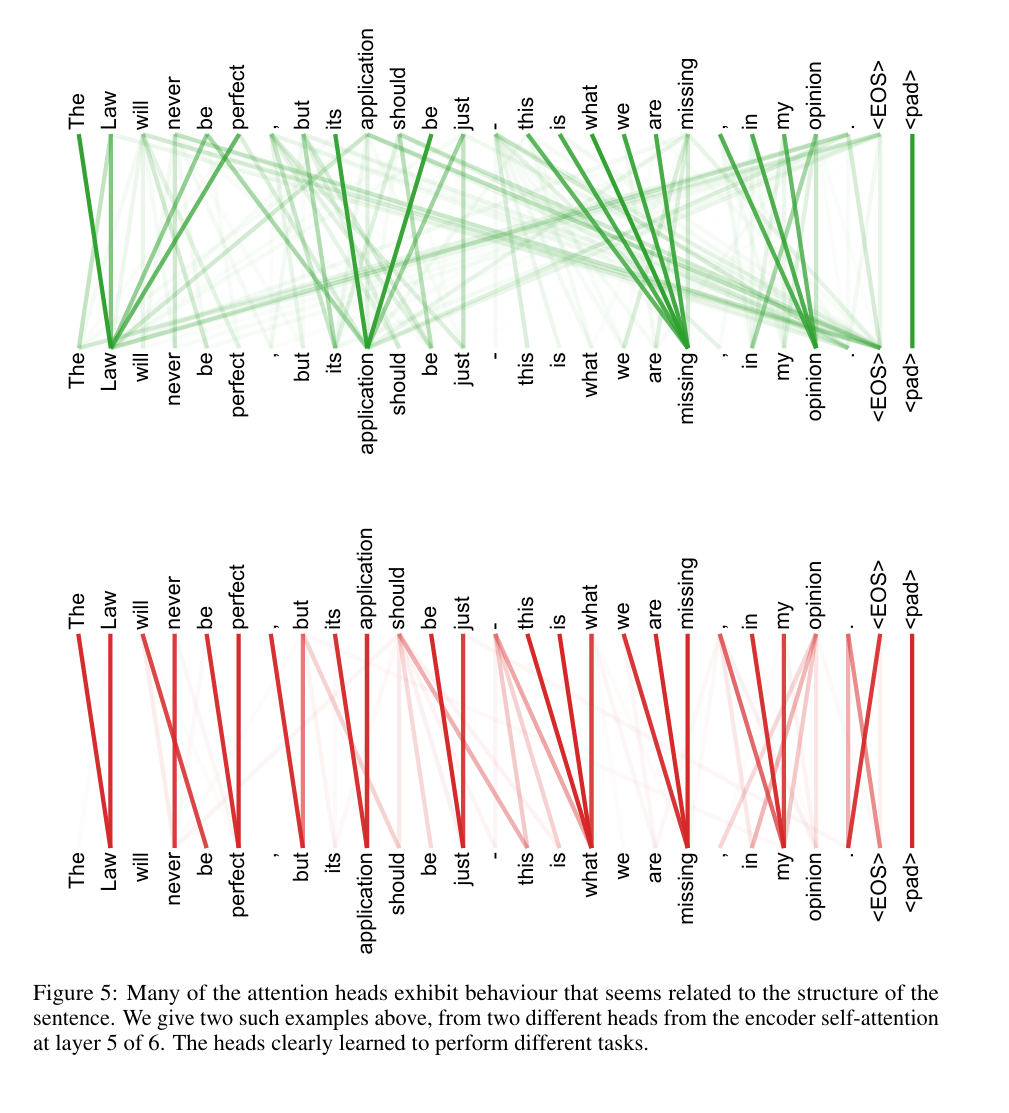
“许多注意力头表现出与句子结构相关的行为。我们在上面给出了两个这样的例子,它们来自 6 层编码器自注意力机制中第 5 层的两个不同注意力头。这些注意力头显然学会了执行不同的任务。”
2、Transformer整体架构:编码器+解码器的“精密协作系统”
论文节详细描述了架构细节,核心是“6层堆叠+残差连接+层归一化”,每个组件都有明确的设计目标,下面结合参数和原理双向解读:
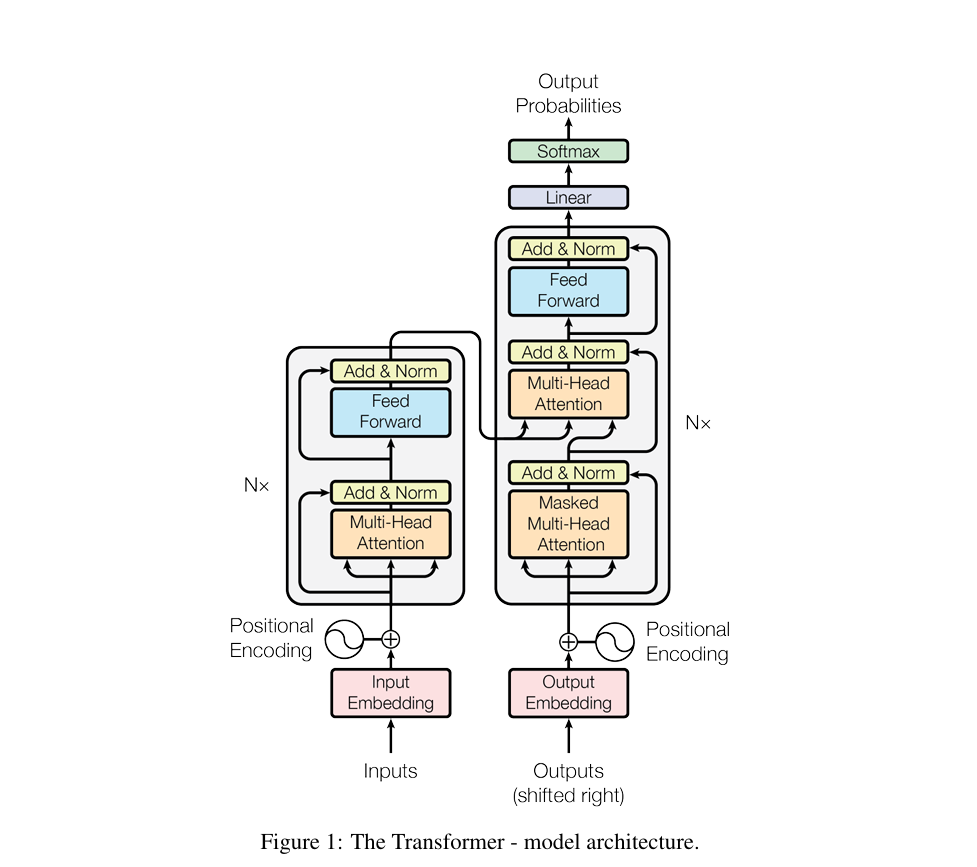
(1) 编码器(Encoder):文本“理解器”(6层堆叠)
专业结构拆解:
- 每层包含2个子层,且都包裹残差连接(Residual Connection)和层归一化(Layer Normalization):
- 子层1:多头自注意力(Multi-Head Self-Attention)——所有Q、K、V都来自上一层输出,捕捉输入序列内部的全局依赖(比如“猫坐在垫子上”中“猫”与“垫子”的位置关系)。
-
子层2:位置wise前馈网络(Position-wise Feed-Forward Network)——对每个token的表征独立进行非线性变换,公式为 F F N ( x )
m a x ( 0 , x W 1 + b 1 ) W 2 + b 2 FFN(x)=max(0, xW_1+b_1)W_2+b_2 FFN(x)=max(0,xW1+b1)W2+b2(论文公式3),其中 d f f
2048 d_{ff}=2048 dff=2048(中间层维度), d m o d e l
512 d_{model}=512 dmodel=512(输入输出维度)。
-
关键约束:所有子层(包括嵌入层)的输出维度必须为 d m o d e l
512 d_{model}=512 dmodel=512,否则残差连接无法进行( x x x与Sublayer(x)维度需一致)。 - 残差连接的作用:缓解深层网络的梯度消失——通过直接将输入 x x x加到子层输出,确保梯度能“直接回传”到浅层,避免因多层变换导致梯度衰减。
通俗类比:编码器就像“阅读理解做题步骤”——
- 多头自注意力:先通读全文,划出所有关键词的关联(比如“原因-结果”“主体-动作”);
- 前馈网络:针对每个关键词,单独深化其语义(比如“猫”不仅是“动物”,还是“动作‘坐’的执行者”);
- 残差连接:确保深化语义时不忘记原文信息(比如不会因为关注“猫”的动作,而忘记“猫”的位置)。
(2) 解码器(Decoder):文本“生成器”(6层堆叠)
专业结构拆解:
- 每层包含3个子层(比编码器多1个子层),同样带残差连接和层归一化:
- 子层1:掩码多头自注意力(Masked Multi-Head Self-Attention)——限制当前位置只能关注“之前的位置”(比如生成第3个词时,只能看第1、2个词),避免“偷看未来信息”。实现方式是在 Q K T QK^T QKT后,将未来位置的相似度分数设为 − ∞ -∞ −∞,softmax后权重为0。
- 子层2:编码器-解码器注意力(Encoder-Decoder Attention)——Q来自解码器上一层输出,K、V来自编码器最终输出,让生成的每个词都能关注输入序列的相关位置(比如翻译“它很舒服”时,“它”关注输入的“猫”)。
- 子层3:与编码器相同的位置wise前馈网络。
-
输出处理:解码器最后一层输出通过线性投影(维度从 d m o d e l
512 d_{model}=512 dmodel=512映射到词汇表大小,如37000)和softmax,得到下一个词的概率分布。
通俗类比:解码器就像“写作文”——
- 掩码自注意力:写每一句话时,只能参考前面已经写的内容,不能提前看后面的草稿(保证逻辑连贯);
- 编码器-解码器注意力:写的时候不断回头看“阅读理解的笔记”(输入文本的语义表征),确保不偏离原文意思;
- 前馈网络:把每个词的表达打磨得更准确(比如把“它舒服”改成“它显得很舒服”)。
(3) 位置编码(Positional Encoding):给词汇“贴位置标签”
专业解释:
-
设计原因:Transformer无递归/卷积,无法自动捕捉序列顺序,必须手动注入位置信息。
-
编码公式(论文核心公式):
P E ( p o s , 2 i )
s i n ( p o s / 1000 0 2 i / d m o d e l ) PE_{(pos, 2i)}=sin(pos/10000^{2i/d_{model}}) PE(pos,2i)=sin(pos/100002i/dmodel)
P E ( p o s , 2 i + 1 )
c o s ( p o s / 1000 0 2 i / d m o d e l ) PE_{(pos, 2i+1)}=cos(pos/10000^{2i/d_{model}}) PE(pos,2i+1)=cos(pos/100002i/dmodel)
其中pos是token在序列中的位置(从0开始),i是维度索引(0到 d m o d e l / 2 − 1 d_{model}/2-1 dmodel/2−1)。 -
核心优势:
- 相对位置可表示:对于任意固定偏移k, P E p o s + k PE_{pos+k} PEpos+k可通过 P E p o s PE_{pos} PEpos的正弦和余弦函数线性组合得到(利用三角恒等式),模型能学习到“相对位置关系”(比如“第2个词和第5个词相差3个位置”)。
- 泛化性强:正弦余弦函数是周期性的,可生成任意长度序列的位置编码,即使测试时序列长度超过训练时的最大值(比如训练时最长512词,测试时600词),也能直接计算编码,无需额外训练。
-
对比实验:论文表3(E行)显示,正弦余弦编码与“学习型位置嵌入”(随机初始化后训练)性能几乎一致(BLEU分别为25.7和25.8),但前者更节省参数且泛化性更好。
通俗类比:位置编码就像“给排队的人贴编号”——每个token都有一个唯一的“位置标签”,标签的设计很巧妙:不仅能看出“谁在第1位、谁在第10位”(绝对位置),还能通过标签计算“两人之间差几个位置”(相对位置),而且不管队伍多长(序列多长),都能快速生成新的编号。
三、核心优势:基于论文数据的“碾压式突破”
论文通过理论分析(表1)和实验结果(表2-4),论证了Transformer的三大优势,下面结合“专业数据+通俗解读”展开:
1. 并行计算效率:从“串行排队”到“并行开工”

“表 1:不同层类型的最大路径长度、每层复杂度及最小顺序操作数注:n 为序列长度,d 为表示维度,k 为卷积核大小,r 为受限自注意力中的邻域大小”
专业分析(论文表1):
- 计算复杂度对比:
- 自注意力: O ( n 2 d ) O(n^2 d) O(n2d)(n=序列长度,d=表征维度)——主要开销是计算 Q K T QK^T QKT( n × n n×n n×n矩阵)。
- RNN: O ( n d 2 ) O(nd^2) O(nd2)——每个token都要依赖前一个token的隐藏状态,无法并行,且复杂度随d增长更快。
- CNN: O ( k n d 2 ) O(kn d^2) O(knd2)(k=卷积核大小)——虽支持并行,但捕捉长距离依赖需堆叠多层(比如k=3时,捕捉n=100词的依赖需~30层)。
- 关键结论:当 n < d n < d n<d时(这是NLP任务的常见情况,比如word-piece表征中n=100,d=512),自注意力的复杂度低于RNN,且并行度极高(所有token的 Q K T QK^T QKT计算可同时进行)。
论文实验数据:Transformer(big)在8个P100 GPU上训练3.5天(300,000步),而之前的SOTA模型GNMT训练需1.1×10²¹ FLOPs(是Transformer的~48倍),却只达到41.16 BLEU,Transformer则达到41.8 BLEU。
通俗解读:
- RNN处理句子像“工厂流水线”:只有前一个token处理完,才能处理下一个,100个token要按顺序来,效率低。
- Transformer像“建筑工地”:所有token同时“开工”,各自计算与其他所有token的关联,8个GPU就是8个施工队,同时推进,效率呈指数级提升。
- 举个例子:处理100词的句子,RNN需要100个“时间步”,Transformer只需1个“时间步”就能完成所有关联计算,后续只需要处理前馈网络和归一化,并行优势一目了然。
2. 长距离依赖捕捉:从“隔山喊话”到“当面交流”
专业分析(论文表1“最大路径长度”):
- 最大路径长度:指输入序列中任意两个token的依赖关系,在网络中需要经过的“层数量”(路径越短,依赖越容易学习)。
- 自注意力: O ( 1 ) O(1) O(1)——任意两个token直接通过注意力权重关联,无需经过中间层传递。
- RNN: O ( n ) O(n) O(n)——第1个token和第n个token的依赖,需要经过n-1个时间步的传递,梯度容易衰减。
- CNN: O ( l o g k n ) O(log_k n) O(logkn)——需通过 dilated convolution(空洞卷积)堆叠,路径长度随n增长而增加。
论文实证支持:注意力可视化图3显示,编码器第5层的多个头能直接捕捉“making”(第8个token)与“difficult”(第14个token)的长距离关联,形成“making the registration process more difficult”的完整短语,而RNN需要逐次传递才能建立这种关联,容易丢失信息。
通俗解读:
- RNN处理长文本像“传话游戏”:第1个词的信息要经过第2、3、…、n-1个词才能传到第n个词,中间容易“传错话”(梯度消失),长距离依赖的信息会严重衰减。
- Transformer像“微信群聊”:不管两个词相距多远(比如第1个词和第1000个词),都能直接“@对方”,建立直接关联,信息传递无损耗,长距离依赖的捕捉准确率几乎不受距离影响。
- 比如处理“虽然他三年前离开了公司,但他的贡献至今仍被同事们铭记”这句话,Transformer能直接将“他”与“他的贡献”“同事们”关联,而RNN可能在传递“他”的指代信息时出现偏差。
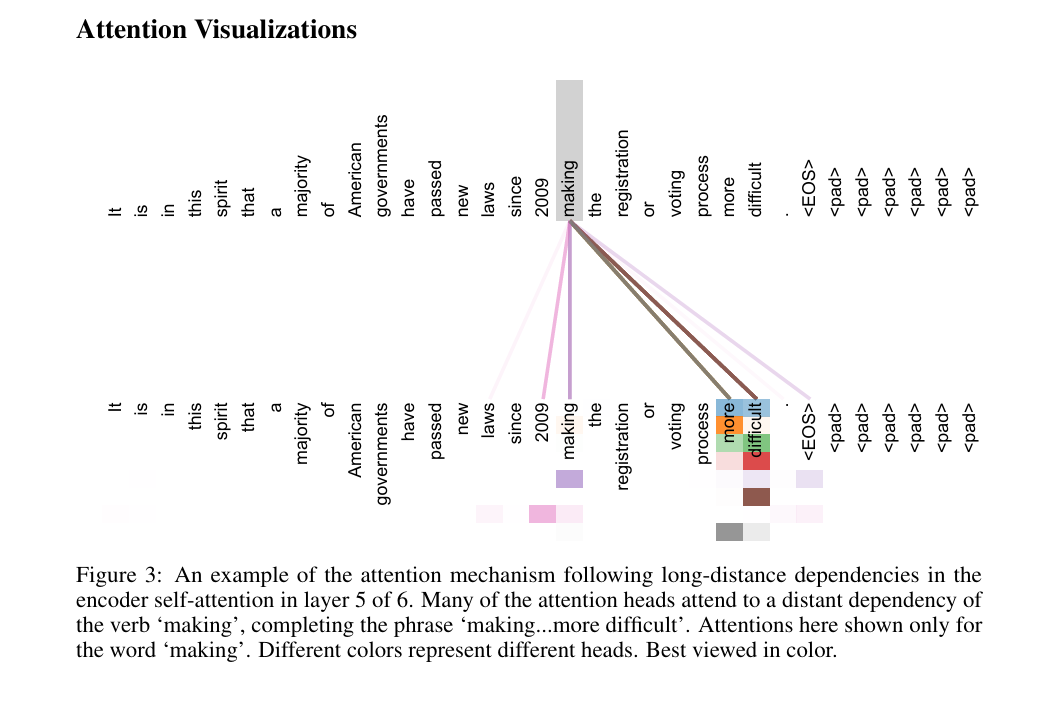
“图 3:6 层编码器自注意力中第 5 层的注意力机制捕捉长距离依赖的示例。许多注意力头会关注动词 “making” 的远距离依赖,以补全短语 “making…more difficult”。此处仅展示针对单词 “making” 的注意力情况。不同颜色代表不同的注意力头。建议以彩色查看。”
3. 规模扩展性价比:从“添砖加瓦”到“搭积木”
专业分析:
-
传统模型(RNN/CNN)扩展规模时,计算量呈“线性增长”甚至“超线性增长”:比如RNN的隐藏层维度从512提升到1024,复杂度从 n d 2 nd^2 nd2变成 n ( 2 d ) 2
4 n d 2 n(2d)^2=4nd^2 n(2d)2=4nd2,计算量翻4倍,但性能提升有限。 - Transformer的并行特性让规模扩展的“边际成本降低”:论文中“big model”将 d m o d e l d_{model} dmodel从512提升到1024, d f f d_{ff} dff从2048提升到4096,h从8提升到16,参数从6500万增加到2.13亿(3.3倍),但训练时间仅从12小时(base model)增加到3.5天(big model),而BLEU从27.3提升到28.4(EN-DE任务【BLEU全称 Bilingual Evaluation Understudy(双语评估替补),核心是衡量模型生成文本与人工标注参考文本的相似度】),提升幅度显著。
论文实验数据:表3显示,当 d m o d e l
1024 d_{model}=1024 dmodel=1024、 d f f
4096 d_{ff}=4096 dff=4096时,模型的困惑度(PPL)从4.92降至4.33,BLEU从25.8提升到26.4,验证了规模扩展的有效性。
通俗解读:
- 传统模型扩展像“盖平房”:要想盖更高(性能更好),必须把地基、墙体都重新加固(计算量大幅增加),付出的成本很高,但高度提升有限。
- Transformer扩展像“搭乐高”:并行结构就是“标准化积木”,要想搭更高(更大规模),只需增加积木数量(参数),无需重新设计结构,付出的成本远低于传统模型,但高度(性能)能持续提升。
- 这也是为什么后续GPT-3(1750亿参数)、PaLM(5400亿参数)能基于Transformer架构实现,而无法基于RNN——RNN的串行结构根本支撑不了如此大规模的参数训练。
四、补充:训练细节与泛化能力
1. 训练关键策略
-
优化器:Adam(论文5.3节),参数 β 1
0.9 \beta_1=0.9 β1=0.9, β 2
0.98 \beta_2=0.98 β2=0.98, ϵ
1 e − 9 \epsilon=1e-9 ϵ=1e−9
β 2 \beta_2 β2接近1,说明对历史梯度平方的衰减较慢,适合稀疏梯度场景;“模型学习时既重视近期的梯度(当前数据的规律),也不忽视远期的梯度(之前数据的规律),避免学了新的忘了旧的”。
-
学习率调度: l r a t e
d m o d e l − 0.5 ⋅ m i n ( s t e p _ n u m − 0.5 , s t e p _ n u m ⋅ w a r m u p _ s t e p s − 1.5 ) lrate=d_{model}^{-0.5}·min(step\_num^{-0.5}, step\_num·warmup\_steps^{-1.5}) lrate=dmodel−0.5⋅min(step_num−0.5,step_num⋅warmup_steps−1.5)(论文公式3)
前4000步线性升温(warmup),避免初始学习率过大导致模型震荡;之后按步长的-0.5次方衰减,确保后期稳定收敛
- 正则化(论文5.4节):
-
残差dropout: P d r o p
0.1 P_{drop}=0.1 Pdrop=0.1——对每个子层输出和嵌入+位置编码的总和进行dropout,防止过拟合; -
标签平滑: ϵ l s
0.1 \epsilon_{ls}=0.1 ϵls=0.1——将真实标签的概率从1.0调整为0.9,其他标签共享0.1的概率
-
降低模型对“正确标签”的过度自信,提升泛化性。
2. 泛化能力:不止于翻译
- 任务:英语 constituency parsing( constituency 句法分析,即分析句子的短语结构,如“主语短语-谓语短语”)。
-
实验设置:4层Transformer, d m o d e l
1024 d_{model}=1024 dmodel=1024,训练数据分两种:仅WSJ(4万句)、半监督(1700万句)。 - 结果:仅WSJ训练时F1=91.3,超过多数传统模型;半监督训练时F1=92.7,接近SOTA(RNN Grammar的93.3)。
句法分析要求模型捕捉严格的结构依赖(如“定语从句修饰哪个名词”),且输出长度远大于输入(短语结构树的节点数是token数的2-3倍),Transformer能在该任务上取得好成绩,证明其注意力机制的“结构建模能力”,而非仅适用于翻译。Transformer不仅能“做好翻译”,还能“学好语法分析”,说明它掌握的是“语言的通用规律”,而非“翻译的专属技巧”,为后续迁移到文本生成、摘要、问答等任务奠定了基础。
五、总结:一篇论文,开启AI的“大模型时代”
《Attention Is All You Need》之所以成为AI工程领域的“里程碑”,不仅在于它解决了当时的技术瓶颈,更在于它为后续十年的AI发展奠定了基础:
- 技术层面:让“大规模并行训练”成为可能,直接推动模型参数从“百万级”跃升到“万亿级”(如GPT-4的万亿参数规模);
- 应用层面:基于Transformer的模型攻克了机器翻译、文本生成、问答系统等核心任务,让AI从“实验室”走进日常生活(如ChatGPT、智能客服、AI写作工具);
- 工程师视角:理解Transformer的自注意力机制、并行逻辑和架构设计,是掌握大模型开发、优化、部署的“必修课”
如果说AI的发展是一条漫长的道路,那《Attention Is All You Need》就是这条路上的“关键路标”——它不仅回答了“如何高效处理文本”的问题,更开启了“用注意力机制构建智能系统”的全新思路。直到今天,这篇论文的思想仍在影响AI前沿研究(如视觉Transformer(ViT)、多模态Transformer),足以证明其不朽的价值。
对于想要深入AI领域的朋友,建议直接阅读论文原文(篇幅仅11页,逻辑清晰、公式简洁)——理解它,你就理解了现代大模型的“技术原点”。 论文链接如下 https://arxiv.org/abs/1706.03762

AI 十大論文精講(一):不懂 Attention 不算懂 AI?一文讀懂《Attention Is All You Need》
2、Transformer整體架構:編碼器+解碼器的“精密協作系統” 論文節詳細描述了架構細節,核心是“6層堆疊+殘差連接+層歸一化”,每個組件都有明確的設計目標,下面結合參數和原理雙向解讀:
來源:https://blog.csdn.net/2403_87969572/article/details/154720197
抓取時間(ISO本地):2026-05-18 05:17:09
系列文章前言
在人工智能技術從理論突破走向工程落地的進程中,一篇篇里程碑式的論文如同燈塔,照亮了技術演進的關鍵路徑。為幫助大家吃透 AI 核心技術的底層邏輯、理清行業發展脈絡,博主推出「AI 十大核心論文解讀系列」,每篇聚焦一篇關鍵論文的問題背景、核心創新與行業影響。本篇博客解讀《Attention Is All You Need》論文。
文章目錄
- 系列文章前言
- 前言:為何它能入選AI工程領域“十大必看論文”
- 一、技術背景:Transformer出現前的“三大困境”
- 二、論文深度解讀:自注意力機制如何“顛覆”傳統框架?
- 三、核心優勢:基於論文數據的“碾壓式突破”
- 四、補充:訓練細節與泛化能力
- 五、總結:一篇論文,開啟AI的“大模型時代”
前言:為何它能入選AI工程領域“十大必看論文”
在人工智能工程的發展史上,有一批論文如同“燈塔”,照亮了技術突破的方向。“AI工程領域十大核心論文”覆蓋模型架構、微調技術、檢索增強、智能體等關鍵方向,而2017年穀歌團隊發表的《Attention Is All You Need》,無疑是其中最具“奠基性”的一篇——它徹底脫離前人的序列模型框架,以全新的“自注意力機制”重構了自然語言處理(NLP)乃至整個深度學習的技術路徑。
如果說GPT、BERT、LLaMA等大模型是AI時代的“高樓大廈”,那《Attention Is All You Need》就是搭建這些大廈的“鋼筋骨架”。如今幾乎所有現代大型語言模型(LLM)的設計,都離不開這篇論文提出的Transformer架構。無論是AI工程師面試必問的“並行計算原理”,還是日常開發依賴的“上下文理解能力”,其技術根源都能追溯到這篇僅11頁的論文。今天,我們就來深度拆解這篇改變AI格局的經典之作。
論文鏈接:https://arxiv.org/abs/1706.03762
一、技術背景:Transformer出現前的“三大困境”
2017年之前,NLP領域的主流技術方案是循環神經網絡(RNN) 和卷積神經網絡(CNN),但這兩種模型存在難以突破的瓶頸,直接限制了AI處理複雜文本的能力。
1. 序列處理效率低下:串行計算拖慢訓練節奏
RNN的核心邏輯是“逐句、逐詞處理文本”——分析一句話時,模型必須先處理第一個詞,再基於其結果處理第二個詞,以此類推。這種串行模式如同人逐字讀文章,無法同時處理多個詞彙,導致訓練速度極慢。對於長文本,RNN的訓練時間會呈指數級增長,根本無法支撐大規模數據訓練。
2. 長距離依賴難題:信息衰減導致語義斷裂
RNN存在“短期記憶”缺陷。比如處理“小明昨天去超市買了蘋果,他今天把____吃了”這句話時,RNN很難將“他”與前文的“小明”、“____”與前文的“蘋果”關聯起來。隨著文本長度增加,早期詞彙的信息會逐漸衰減,模型無法有效捕捉遠距離詞彙的語義聯繫。即便後續出現LSTM、GRU等改進模型,也只是緩解問題,並未從根本上解決。
3. 並行計算能力缺失:硬件資源無法充分利用
當時AI訓練已開始依賴多GPU集群提升效率,但RNN和CNN幾乎無法支持高效並行。RNN的串行邏輯決定了“下一個詞的計算必須依賴上一個詞”,無法拆分任務到多個GPU同時執行;CNN雖能並行處理局部特徵,但對長文本的全局語義理解能力弱,且並行粒度有限。這種“並行困境”導致模型規模難以擴大——擴大參數規模只能依賴單GPU硬扛,成本和時間都難以承受。
正是在這樣的技術瓶頸下,《Attention Is All You Need》的出現如同一場“技術革命”,用全新思路解決了上述所有問題。
二、論文深度解讀:自注意力機制如何“顛覆”傳統框架?
這篇論文的核心貢獻只有一個:提出Transformer架構,用“自注意力機制”取代傳統的序列處理邏輯。整個架構圍繞“高效處理文本、支持並行計算、捕捉全局語義”三個目標設計,可從“核心機制”“架構細節”和“核心優勢”三方面拆解。
1、自注意力機制——從“逐字讀”到“全局掃”的範式革命
(1)自注意力的本質:不止是“找關聯”,更是“動態加權語義融合”
專業定義:自注意力是將查詢(Q)、鍵(K)、值(V)三組向量映射為輸出的函數,輸出是V的加權和,權重由Q與K的相似度計算得出。其核心是通過可學習的參數,為每個位置的token生成“全局依賴表徵”,即每個token的最終向量都融合了所有其他token的語義信息。
通俗類比:把處理句子比作“班級自我介紹”——以前的RNN是“按座位順序逐個發言,只能記住前一個人的名字”;自注意力是“所有人同時站起來,每個人手裡舉著自己的‘關鍵詞牌’(K)和‘詳細介紹’(V),你(當前token)拿著自己的‘需求牌’(Q),快速和所有人比對:和你需求越匹配的人,你越認真聽他的介紹,最後把所有人的介紹按‘認真程度’加權整合,形成自己的最終印象”。
論文關鍵細節補充:
-
向量維度約束:論文中Q、K的維度 d k
64 d_k=64 dk=64,V的維度 d v
64 d_v=64 dv=64,整個模型的表徵維度 d m o d e l
512 d_{model}=512 dmodel=512(所有子層輸出維度統一,方便殘差連接)。 - 計算流程(對應論文公式1):
- 計算Q與K的轉置點積: Q K T QK^T QKT(得到 n × n n×n n×n的相似度矩陣,n是序列長度);
- 除以 d k \sqrt{d_k} dk (縮放步驟);
- 經過softmax得到歸一化權重(權重和為1);
- 權重與V矩陣相乘,得到最終輸出。
(2) 縮放點積注意力:解決“相似度分數爆炸”的關鍵
專業解釋:為什麼需要縮放?假設Q和K的每個元素都是均值為0、方差為1的獨立隨機變量,它們的點積 q ⋅ k
∑ i
1 d k q i k i q·k=\sum_{i=1}^{d_k}q_ik_i q⋅k=∑i=1dkqiki的均值為0、方差為 d k d_k dk。當 d k d_k dk較大(如 d k
512 d_k=512 dk=512)時,點積結果的數值會非常大,導致softmax函數的輸入值落在“梯度接近0”的區域(softmax在輸入值極大時,輸出趨近於one-hot,導數幾乎為0),模型無法更新參數。 縮放的作用:除以 d k \sqrt{d_k} dk 後,點積的方差被歸一化為1,避免softmax陷入“梯度消失陷阱”。
通俗類比:比如 d k
64 d_k=64 dk=64時, d k
8 \sqrt{d_k}=8 dk =8。如果不縮放,Q和K的點積可能達到幾十甚至上百,softmax會“偏愛”分數最高的那個token,其他token的權重幾乎為0(相當於“只看一個詞,忽略其他所有”);縮放後,分數被“壓縮”到合理範圍(比如原來100分變成12.5分),softmax能更均衡地分配權重,模型能關注到多個相關token。
(3) 多頭注意力:讓模型“多角度看問題”
專業解釋:核心操作是將Q、K、V通過8組獨立的線性投影( W i Q ∈ R d m o d e l × d k W_i^Q∈\mathbb{R}^{d_{model}×d_k} WiQ∈Rdmodel×dk, W i K ∈ R d m o d e l × d k W_i^K∈\mathbb{R}^{d_{model}×d_k} WiK∈Rdmodel×dk, W i V ∈ R d m o d e l × d v W_i^V∈\mathbb{R}^{d_{model}×d_v} WiV∈Rdmodel×dv)拆分為8個“子空間”(h=8,論文固定設置),每個子空間獨立執行縮放點積注意力,得到8個 d v d_v dv維的輸出( d v
64 d_v=64 dv=64),最後將8個輸出拼接,通過一個線性投影 W O ∈ R h d v × d m o d e l W^O∈\mathbb{R}^{h d_v×d_{model}} WO∈Rhdv×dmodel得到最終結果。參數約束: h × d k
d m o d e l
512 h×d_k=d_{model}=512 h×dk=dmodel=512,確保總計算量與“單頭注意力( d k
512 d_k=512 dk=512)”相當( O ( n 2 d m o d e l ) O(n^2 d_{model}) O(n2dmodel)),不增加額外計算負擔。
通俗類比:多頭注意力就像“8個不同的專家同時分析一句話”——有的專家專門關注“語法依賴”(比如“它”指代哪個名詞),有的關注“語義關聯”(比如“making”和“difficult”的因果關係),有的關注“邏輯連接”(比如“but”前後的轉折)。最後把8個專家的分析結果整合,得到比單個專家更全面的理解。
論文實證支持:論文附錄的注意力可視化(圖3-5)顯示,不同頭確實學習到了不同依賴:比如某個頭專門捕捉“making”與“more difficult”的長距離關聯(完成“making…more difficult”短語),另兩個頭負責指代消解(“its”指向“Law”),驗證了多頭設計的有效性。
“許多注意力頭表現出與句子結構相關的行為。我們在上面給出了兩個這樣的例子,它們來自 6 層編碼器自注意力機制中第 5 層的兩個不同注意力頭。這些注意力頭顯然學會了執行不同的任務。”
2、Transformer整體架構:編碼器+解碼器的“精密協作系統”
論文節詳細描述了架構細節,核心是“6層堆疊+殘差連接+層歸一化”,每個組件都有明確的設計目標,下面結合參數和原理雙向解讀:
(1) 編碼器(Encoder):文本“理解器”(6層堆疊)
專業結構拆解:
- 每層包含2個子層,且都包裹殘差連接(Residual Connection)和層歸一化(Layer Normalization):
- 子層1:多頭自注意力(Multi-Head Self-Attention)——所有Q、K、V都來自上一層輸出,捕捉輸入序列內部的全局依賴(比如“貓坐在墊子上”中“貓”與“墊子”的位置關係)。
-
子層2:位置wise前饋網絡(Position-wise Feed-Forward Network)——對每個token的表徵獨立進行非線性變換,公式為 F F N ( x )
m a x ( 0 , x W 1 + b 1 ) W 2 + b 2 FFN(x)=max(0, xW_1+b_1)W_2+b_2 FFN(x)=max(0,xW1+b1)W2+b2(論文公式3),其中 d f f
2048 d_{ff}=2048 dff=2048(中間層維度), d m o d e l
512 d_{model}=512 dmodel=512(輸入輸出維度)。
-
關鍵約束:所有子層(包括嵌入層)的輸出維度必須為 d m o d e l
512 d_{model}=512 dmodel=512,否則殘差連接無法進行( x x x與Sublayer(x)維度需一致)。 - 殘差連接的作用:緩解深層網絡的梯度消失——通過直接將輸入 x x x加到子層輸出,確保梯度能“直接回傳”到淺層,避免因多層變換導致梯度衰減。
通俗類比:編碼器就像“閱讀理解做題步驟”——
- 多頭自注意力:先通讀全文,劃出所有關鍵詞的關聯(比如“原因-結果”“主體-動作”);
- 前饋網絡:針對每個關鍵詞,單獨深化其語義(比如“貓”不僅是“動物”,還是“動作‘坐’的執行者”);
- 殘差連接:確保深化語義時不忘記原文信息(比如不會因為關注“貓”的動作,而忘記“貓”的位置)。
(2) 解碼器(Decoder):文本“生成器”(6層堆疊)
專業結構拆解:
- 每層包含3個子層(比編碼器多1個子層),同樣帶殘差連接和層歸一化:
- 子層1:掩碼多頭自注意力(Masked Multi-Head Self-Attention)——限制當前位置只能關注“之前的位置”(比如生成第3個詞時,只能看第1、2個詞),避免“偷看未來信息”。實現方式是在 Q K T QK^T QKT後,將未來位置的相似度分數設為 − ∞ -∞ −∞,softmax後權重為0。
- 子層2:編碼器-解碼器注意力(Encoder-Decoder Attention)——Q來自解碼器上一層輸出,K、V來自編碼器最終輸出,讓生成的每個詞都能關注輸入序列的相關位置(比如翻譯“它很舒服”時,“它”關注輸入的“貓”)。
- 子層3:與編碼器相同的位置wise前饋網絡。
-
輸出處理:解碼器最後一層輸出通過線性投影(維度從 d m o d e l
512 d_{model}=512 dmodel=512映射到詞彙表大小,如37000)和softmax,得到下一個詞的概率分佈。
通俗類比:解碼器就像“寫作文”——
- 掩碼自注意力:寫每一句話時,只能參考前面已經寫的內容,不能提前看後面的草稿(保證邏輯連貫);
- 編碼器-解碼器注意力:寫的時候不斷回頭看“閱讀理解的筆記”(輸入文本的語義表徵),確保不偏離原文意思;
- 前饋網絡:把每個詞的表達打磨得更準確(比如把“它舒服”改成“它顯得很舒服”)。
(3) 位置編碼(Positional Encoding):給詞彙“貼位置標籤”
專業解釋:
-
設計原因:Transformer無遞歸/卷積,無法自動捕捉序列順序,必須手動注入位置信息。
-
編碼公式(論文核心公式):
P E ( p o s , 2 i )
s i n ( p o s / 1000 0 2 i / d m o d e l ) PE_{(pos, 2i)}=sin(pos/10000^{2i/d_{model}}) PE(pos,2i)=sin(pos/100002i/dmodel)
P E ( p o s , 2 i + 1 )
c o s ( p o s / 1000 0 2 i / d m o d e l ) PE_{(pos, 2i+1)}=cos(pos/10000^{2i/d_{model}}) PE(pos,2i+1)=cos(pos/100002i/dmodel)
其中pos是token在序列中的位置(從0開始),i是維度索引(0到 d m o d e l / 2 − 1 d_{model}/2-1 dmodel/2−1)。 -
核心優勢:
- 相對位置可表示:對於任意固定偏移k, P E p o s + k PE_{pos+k} PEpos+k可通過 P E p o s PE_{pos} PEpos的正弦和餘弦函數線性組合得到(利用三角恆等式),模型能學習到“相對位置關係”(比如“第2個詞和第5個詞相差3個位置”)。
- 泛化性強:正弦餘弦函數是週期性的,可生成任意長度序列的位置編碼,即使測試時序列長度超過訓練時的最大值(比如訓練時最長512詞,測試時600詞),也能直接計算編碼,無需額外訓練。
-
對比實驗:論文表3(E行)顯示,正弦餘弦編碼與“學習型位置嵌入”(隨機初始化後訓練)性能幾乎一致(BLEU分別為25.7和25.8),但前者更節省參數且泛化性更好。
通俗類比:位置編碼就像“給排隊的人貼編號”——每個token都有一個唯一的“位置標籤”,標籤的設計很巧妙:不僅能看出“誰在第1位、誰在第10位”(絕對位置),還能通過標籤計算“兩人之間差幾個位置”(相對位置),而且不管隊伍多長(序列多長),都能快速生成新的編號。
三、核心優勢:基於論文數據的“碾壓式突破”
論文通過理論分析(表1)和實驗結果(表2-4),論證了Transformer的三大優勢,下面結合“專業數據+通俗解讀”展開:
1. 並行計算效率:從“串行排隊”到“並行開工”
“表 1:不同層類型的最大路徑長度、每層複雜度及最小順序操作數注:n 為序列長度,d 為表示維度,k 為卷積核大小,r 為受限自注意力中的鄰域大小”
專業分析(論文表1):
- 計算複雜度對比:
- 自注意力: O ( n 2 d ) O(n^2 d) O(n2d)(n=序列長度,d=表徵維度)——主要開銷是計算 Q K T QK^T QKT( n × n n×n n×n矩陣)。
- RNN: O ( n d 2 ) O(nd^2) O(nd2)——每個token都要依賴前一個token的隱藏狀態,無法並行,且複雜度隨d增長更快。
- CNN: O ( k n d 2 ) O(kn d^2) O(knd2)(k=卷積核大小)——雖支持並行,但捕捉長距離依賴需堆疊多層(比如k=3時,捕捉n=100詞的依賴需~30層)。
- 關鍵結論:當 n < d n < d n<d時(這是NLP任務的常見情況,比如word-piece表徵中n=100,d=512),自注意力的複雜度低於RNN,且並行度極高(所有token的 Q K T QK^T QKT計算可同時進行)。
論文實驗數據:Transformer(big)在8個P100 GPU上訓練3.5天(300,000步),而之前的SOTA模型GNMT訓練需1.1×10²¹ FLOPs(是Transformer的~48倍),卻只達到41.16 BLEU,Transformer則達到41.8 BLEU。
通俗解讀:
- RNN處理句子像“工廠流水線”:只有前一個token處理完,才能處理下一個,100個token要按順序來,效率低。
- Transformer像“建築工地”:所有token同時“開工”,各自計算與其他所有token的關聯,8個GPU就是8個施工隊,同時推進,效率呈指數級提升。
- 舉個例子:處理100詞的句子,RNN需要100個“時間步”,Transformer只需1個“時間步”就能完成所有關聯計算,後續只需要處理前饋網絡和歸一化,並行優勢一目瞭然。
2. 長距離依賴捕捉:從“隔山喊話”到“當面交流”
專業分析(論文表1“最大路徑長度”):
- 最大路徑長度:指輸入序列中任意兩個token的依賴關係,在網絡中需要經過的“層數量”(路徑越短,依賴越容易學習)。
- 自注意力: O ( 1 ) O(1) O(1)——任意兩個token直接通過注意力權重關聯,無需經過中間層傳遞。
- RNN: O ( n ) O(n) O(n)——第1個token和第n個token的依賴,需要經過n-1個時間步的傳遞,梯度容易衰減。
- CNN: O ( l o g k n ) O(log_k n) O(logkn)——需通過 dilated convolution(空洞卷積)堆疊,路徑長度隨n增長而增加。
論文實證支持:注意力可視化圖3顯示,編碼器第5層的多個頭能直接捕捉“making”(第8個token)與“difficult”(第14個token)的長距離關聯,形成“making the registration process more difficult”的完整短語,而RNN需要逐次傳遞才能建立這種關聯,容易丟失信息。
通俗解讀:
- RNN處理長文本像“傳話遊戲”:第1個詞的信息要經過第2、3、…、n-1個詞才能傳到第n個詞,中間容易“傳錯話”(梯度消失),長距離依賴的信息會嚴重衰減。
- Transformer像“微信群聊”:不管兩個詞相距多遠(比如第1個詞和第1000個詞),都能直接“@對方”,建立直接關聯,信息傳遞無損耗,長距離依賴的捕捉準確率幾乎不受距離影響。
- 比如處理“雖然他三年前離開了公司,但他的貢獻至今仍被同事們銘記”這句話,Transformer能直接將“他”與“他的貢獻”“同事們”關聯,而RNN可能在傳遞“他”的指代信息時出現偏差。
“圖 3:6 層編碼器自注意力中第 5 層的注意力機制捕捉長距離依賴的示例。許多注意力頭會關注動詞 “making” 的遠距離依賴,以補全短語 “making…more difficult”。此處僅展示針對單詞 “making” 的注意力情況。不同顏色代表不同的注意力頭。建議以彩色查看。”
3. 規模擴展性價比:從“添磚加瓦”到“搭積木”
專業分析:
-
傳統模型(RNN/CNN)擴展規模時,計算量呈“線性增長”甚至“超線性增長”:比如RNN的隱藏層維度從512提升到1024,複雜度從 n d 2 nd^2 nd2變成 n ( 2 d ) 2
4 n d 2 n(2d)^2=4nd^2 n(2d)2=4nd2,計算量翻4倍,但性能提升有限。 - Transformer的並行特性讓規模擴展的“邊際成本降低”:論文中“big model”將 d m o d e l d_{model} dmodel從512提升到1024, d f f d_{ff} dff從2048提升到4096,h從8提升到16,參數從6500萬增加到2.13億(3.3倍),但訓練時間僅從12小時(base model)增加到3.5天(big model),而BLEU從27.3提升到28.4(EN-DE任務【BLEU全稱 Bilingual Evaluation Understudy(雙語評估替補),核心是衡量模型生成文本與人工標註參考文本的相似度】),提升幅度顯著。
論文實驗數據:表3顯示,當 d m o d e l
1024 d_{model}=1024 dmodel=1024、 d f f
4096 d_{ff}=4096 dff=4096時,模型的困惑度(PPL)從4.92降至4.33,BLEU從25.8提升到26.4,驗證了規模擴展的有效性。
通俗解讀:
- 傳統模型擴展像“蓋平房”:要想蓋更高(性能更好),必須把地基、牆體都重新加固(計算量大幅增加),付出的成本很高,但高度提升有限。
- Transformer擴展像“搭樂高”:並行結構就是“標準化積木”,要想搭更高(更大規模),只需增加積木數量(參數),無需重新設計結構,付出的成本遠低於傳統模型,但高度(性能)能持續提升。
- 這也是為什麼後續GPT-3(1750億參數)、PaLM(5400億參數)能基於Transformer架構實現,而無法基於RNN——RNN的串行結構根本支撐不了如此大規模的參數訓練。
四、補充:訓練細節與泛化能力
1. 訓練關鍵策略
-
優化器:Adam(論文5.3節),參數 β 1
0.9 \beta_1=0.9 β1=0.9, β 2
0.98 \beta_2=0.98 β2=0.98, ϵ
1 e − 9 \epsilon=1e-9 ϵ=1e−9
β 2 \beta_2 β2接近1,說明對歷史梯度平方的衰減較慢,適合稀疏梯度場景;“模型學習時既重視近期的梯度(當前數據的規律),也不忽視遠期的梯度(之前數據的規律),避免學了新的忘了舊的”。
-
學習率調度: l r a t e
d m o d e l − 0.5 ⋅ m i n ( s t e p _ n u m − 0.5 , s t e p _ n u m ⋅ w a r m u p _ s t e p s − 1.5 ) lrate=d_{model}^{-0.5}·min(step\_num^{-0.5}, step\_num·warmup\_steps^{-1.5}) lrate=dmodel−0.5⋅min(step_num−0.5,step_num⋅warmup_steps−1.5)(論文公式3)
前4000步線性升溫(warmup),避免初始學習率過大導致模型震盪;之後按步長的-0.5次方衰減,確保後期穩定收斂
- 正則化(論文5.4節):
-
殘差dropout: P d r o p
0.1 P_{drop}=0.1 Pdrop=0.1——對每個子層輸出和嵌入+位置編碼的總和進行dropout,防止過擬合; -
標籤平滑: ϵ l s
0.1 \epsilon_{ls}=0.1 ϵls=0.1——將真實標籤的概率從1.0調整為0.9,其他標籤共享0.1的概率
-
降低模型對“正確標籤”的過度自信,提升泛化性。
2. 泛化能力:不止於翻譯
- 任務:英語 constituency parsing( constituency 句法分析,即分析句子的短語結構,如“主語短語-謂語短語”)。
-
實驗設置:4層Transformer, d m o d e l
1024 d_{model}=1024 dmodel=1024,訓練數據分兩種:僅WSJ(4萬句)、半監督(1700萬句)。 - 結果:僅WSJ訓練時F1=91.3,超過多數傳統模型;半監督訓練時F1=92.7,接近SOTA(RNN Grammar的93.3)。
句法分析要求模型捕捉嚴格的結構依賴(如“定語從句修飾哪個名詞”),且輸出長度遠大於輸入(短語結構樹的節點數是token數的2-3倍),Transformer能在該任務上取得好成績,證明其注意力機制的“結構建模能力”,而非僅適用於翻譯。Transformer不僅能“做好翻譯”,還能“學好語法分析”,說明它掌握的是“語言的通用規律”,而非“翻譯的專屬技巧”,為後續遷移到文本生成、摘要、問答等任務奠定了基礎。
五、總結:一篇論文,開啟AI的“大模型時代”
《Attention Is All You Need》之所以成為AI工程領域的“里程碑”,不僅在於它解決了當時的技術瓶頸,更在於它為後續十年的AI發展奠定了基礎:
- 技術層面:讓“大規模並行訓練”成為可能,直接推動模型參數從“百萬級”躍升到“萬億級”(如GPT-4的萬億參數規模);
- 應用層面:基於Transformer的模型攻克了機器翻譯、文本生成、問答系統等核心任務,讓AI從“實驗室”走進日常生活(如ChatGPT、智能客服、AI寫作工具);
- 工程師視角:理解Transformer的自注意力機制、並行邏輯和架構設計,是掌握大模型開發、優化、部署的“必修課”
如果說AI的發展是一條漫長的道路,那《Attention Is All You Need》就是這條路上的“關鍵路標”——它不僅回答了“如何高效處理文本”的問題,更開啟了“用注意力機制構建智能系統”的全新思路。直到今天,這篇論文的思想仍在影響AI前沿研究(如視覺Transformer(ViT)、多模態Transformer),足以證明其不朽的價值。
對於想要深入AI領域的朋友,建議直接閱讀論文原文(篇幅僅11頁,邏輯清晰、公式簡潔)——理解它,你就理解了現代大模型的“技術原點”。 論文鏈接如下 https://arxiv.org/abs/1706.03762
AI 十大论文精讲(一):不懂 Attention 不算懂 AI?一文读懂《Attention Is All You Need》
2. Transformer overall architecture: The "Precision Collaboration System" paper section of the encoder + decoder details the architecture. The core is "6-layer stacking + residual connection + layer normalization". Each component has a clear design goal. The following is a two-way interpretation combined with parameters and principles:
系列文章前言
在人工智能技术从理论突破走向工程落地的进程中,一篇篇里程碑式的论文如同灯塔,照亮了技术演进的关键路径。为帮助大家吃透 AI 核心技术的底层逻辑、理清行业发展脉络,博主推出「AI 十大核心论文解读系列」,每篇聚焦一篇关键论文的问题背景、核心创新与行业影响。本篇博客解读《Attention Is All You Need》论文。
前言:为何它能入选AI工程领域“十大必看论文”
在人工智能工程的发展史上,有一批论文如同“灯塔”,照亮了技术突破的方向。“AI工程领域十大核心论文”覆盖模型架构、微调技术、检索增强、智能体等关键方向,而2017年谷歌团队发表的《Attention Is All You Need》,无疑是其中最具“奠基性”的一篇——它彻底脱离前人的序列模型框架,以全新的“自注意力机制”重构了自然语言处理(NLP)乃至整个深度学习的技术路径。
如果说GPT、BERT、LLaMA等大模型是AI时代的“高楼大厦”,那《Attention Is All You Need》就是搭建这些大厦的“钢筋骨架”。如今几乎所有现代大型语言模型(LLM)的设计,都离不开这篇论文提出的Transformer架构。无论是AI工程师面试必问的“并行计算原理”,还是日常开发依赖的“上下文理解能力”,其技术根源都能追溯到这篇仅11页的论文。今天,我们就来深度拆解这篇改变AI格局的经典之作。
论文链接:https://arxiv.org/abs/1706.03762
一、技术背景:Transformer出现前的“三大困境”
2017年之前,NLP领域的主流技术方案是循环神经网络(RNN) 和卷积神经网络(CNN),但这两种模型存在难以突破的瓶颈,直接限制了AI处理复杂文本的能力。
1. 序列处理效率低下:串行计算拖慢训练节奏
RNN的核心逻辑是“逐句、逐词处理文本”——分析一句话时,模型必须先处理第一个词,再基于其结果处理第二个词,以此类推。这种串行模式如同人逐字读文章,无法同时处理多个词汇,导致训练速度极慢。对于长文本,RNN的训练时间会呈指数级增长,根本无法支撑大规模数据训练。
2. 长距离依赖难题:信息衰减导致语义断裂
RNN存在“短期记忆”缺陷。比如处理“小明昨天去超市买了苹果,他今天把____吃了”这句话时,RNN很难将“他”与前文的“小明”、“____”与前文的“苹果”关联起来。随着文本长度增加,早期词汇的信息会逐渐衰减,模型无法有效捕捉远距离词汇的语义联系。即便后续出现LSTM、GRU等改进模型,也只是缓解问题,并未从根本上解决。
3. 并行计算能力缺失:硬件资源无法充分利用
当时AI训练已开始依赖多GPU集群提升效率,但RNN和CNN几乎无法支持高效并行。RNN的串行逻辑决定了“下一个词的计算必须依赖上一个词”,无法拆分任务到多个GPU同时执行;CNN虽能并行处理局部特征,但对长文本的全局语义理解能力弱,且并行粒度有限。这种“并行困境”导致模型规模难以扩大——扩大参数规模只能依赖单GPU硬扛,成本和时间都难以承受。
正是在这样的技术瓶颈下,《Attention Is All You Need》的出现如同一场“技术革命”,用全新思路解决了上述所有问题。
二、论文深度解读:自注意力机制如何“颠覆”传统框架?
这篇论文的核心贡献只有一个:提出Transformer架构,用“自注意力机制”取代传统的序列处理逻辑。整个架构围绕“高效处理文本、支持并行计算、捕捉全局语义”三个目标设计,可从“核心机制”“架构细节”和“核心优势”三方面拆解。
1、自注意力机制——从“逐字读”到“全局扫”的范式革命
(1)自注意力的本质:不止是“找关联”,更是“动态加权语义融合”
专业定义:自注意力是将查询(Q)、键(K)、值(V)三组向量映射为输出的函数,输出是V的加权和,权重由Q与K的相似度计算得出。其核心是通过可学习的参数,为每个位置的token生成“全局依赖表征”,即每个token的最终向量都融合了所有其他token的语义信息。
通俗类比:把处理句子比作“班级自我介绍”——以前的RNN是“按座位顺序逐个发言,只能记住前一个人的名字”;自注意力是“所有人同时站起来,每个人手里举着自己的‘关键词牌’(K)和‘详细介绍’(V),你(当前token)拿着自己的‘需求牌’(Q),快速和所有人比对:和你需求越匹配的人,你越认真听他的介绍,最后把所有人的介绍按‘认真程度’加权整合,形成自己的最终印象”。
论文关键细节补充:
-
向量维度约束:论文中Q、K的维度 d k
64 d_k=64 dk=64,V的维度 d v
64 d_v=64 dv=64,整个模型的表征维度 d m o d e l
512 d_{model}=512 dmodel=512(所有子层输出维度统一,方便残差连接)。 - 计算流程(对应论文公式1):
- 计算Q与K的转置点积: Q K T QK^T QKT(得到 n × n n×n n×n的相似度矩阵,n是序列长度);
- 除以 d k \sqrt{d_k} dk (缩放步骤);
- 经过softmax得到归一化权重(权重和为1);
- 权重与V矩阵相乘,得到最终输出。
(2) 缩放点积注意力:解决“相似度分数爆炸”的关键
专业解释:为什么需要缩放?假设Q和K的每个元素都是均值为0、方差为1的独立随机变量,它们的点积 q ⋅ k
∑ i
1 d k q i k i q·k=\sum_{i=1}^{d_k}q_ik_i q⋅k=∑i=1dkqiki的均值为0、方差为 d k d_k dk。当 d k d_k dk较大(如 d k
512 d_k=512 dk=512)时,点积结果的数值会非常大,导致softmax函数的输入值落在“梯度接近0”的区域(softmax在输入值极大时,输出趋近于one-hot,导数几乎为0),模型无法更新参数。 缩放的作用:除以 d k \sqrt{d_k} dk 后,点积的方差被归一化为1,避免softmax陷入“梯度消失陷阱”。
通俗类比:比如 d k
64 d_k=64 dk=64时, d k
8 \sqrt{d_k}=8 dk =8。如果不缩放,Q和K的点积可能达到几十甚至上百,softmax会“偏爱”分数最高的那个token,其他token的权重几乎为0(相当于“只看一个词,忽略其他所有”);缩放后,分数被“压缩”到合理范围(比如原来100分变成12.5分),softmax能更均衡地分配权重,模型能关注到多个相关token。
(3) 多头注意力:让模型“多角度看问题”
专业解释:核心操作是将Q、K、V通过8组独立的线性投影( W i Q ∈ R d m o d e l × d k W_i^Q∈\mathbb{R}^{d_{model}×d_k} WiQ∈Rdmodel×dk, W i K ∈ R d m o d e l × d k W_i^K∈\mathbb{R}^{d_{model}×d_k} WiK∈Rdmodel×dk, W i V ∈ R d m o d e l × d v W_i^V∈\mathbb{R}^{d_{model}×d_v} WiV∈Rdmodel×dv)拆分为8个“子空间”(h=8,论文固定设置),每个子空间独立执行缩放点积注意力,得到8个 d v d_v dv维的输出( d v
64 d_v=64 dv=64),最后将8个输出拼接,通过一个线性投影 W O ∈ R h d v × d m o d e l W^O∈\mathbb{R}^{h d_v×d_{model}} WO∈Rhdv×dmodel得到最终结果。参数约束: h × d k
d m o d e l
512 h×d_k=d_{model}=512 h×dk=dmodel=512,确保总计算量与“单头注意力( d k
512 d_k=512 dk=512)”相当( O ( n 2 d m o d e l ) O(n^2 d_{model}) O(n2dmodel)),不增加额外计算负担。
通俗类比:多头注意力就像“8个不同的专家同时分析一句话”——有的专家专门关注“语法依赖”(比如“它”指代哪个名词),有的关注“语义关联”(比如“making”和“difficult”的因果关系),有的关注“逻辑连接”(比如“but”前后的转折)。最后把8个专家的分析结果整合,得到比单个专家更全面的理解。
论文实证支持:论文附录的注意力可视化(图3-5)显示,不同头确实学习到了不同依赖:比如某个头专门捕捉“making”与“more difficult”的长距离关联(完成“making…more difficult”短语),另两个头负责指代消解(“its”指向“Law”),验证了多头设计的有效性。
“许多注意力头表现出与句子结构相关的行为。我们在上面给出了两个这样的例子,它们来自 6 层编码器自注意力机制中第 5 层的两个不同注意力头。这些注意力头显然学会了执行不同的任务。”
2、Transformer整体架构:编码器+解码器的“精密协作系统”
论文节详细描述了架构细节,核心是“6层堆叠+残差连接+层归一化”,每个组件都有明确的设计目标,下面结合参数和原理双向解读:
(1) 编码器(Encoder):文本“理解器”(6层堆叠)
专业结构拆解:
- 每层包含2个子层,且都包裹残差连接(Residual Connection)和层归一化(Layer Normalization):
- 子层1:多头自注意力(Multi-Head Self-Attention)——所有Q、K、V都来自上一层输出,捕捉输入序列内部的全局依赖(比如“猫坐在垫子上”中“猫”与“垫子”的位置关系)。
-
子层2:位置wise前馈网络(Position-wise Feed-Forward Network)——对每个token的表征独立进行非线性变换,公式为 F F N ( x )
m a x ( 0 , x W 1 + b 1 ) W 2 + b 2 FFN(x)=max(0, xW_1+b_1)W_2+b_2 FFN(x)=max(0,xW1+b1)W2+b2(论文公式3),其中 d f f
2048 d_{ff}=2048 dff=2048(中间层维度), d m o d e l
512 d_{model}=512 dmodel=512(输入输出维度)。
-
关键约束:所有子层(包括嵌入层)的输出维度必须为 d m o d e l
512 d_{model}=512 dmodel=512,否则残差连接无法进行( x x x与Sublayer(x)维度需一致)。 - 残差连接的作用:缓解深层网络的梯度消失——通过直接将输入 x x x加到子层输出,确保梯度能“直接回传”到浅层,避免因多层变换导致梯度衰减。
通俗类比:编码器就像“阅读理解做题步骤”——
- 多头自注意力:先通读全文,划出所有关键词的关联(比如“原因-结果”“主体-动作”);
- 前馈网络:针对每个关键词,单独深化其语义(比如“猫”不仅是“动物”,还是“动作‘坐’的执行者”);
- 残差连接:确保深化语义时不忘记原文信息(比如不会因为关注“猫”的动作,而忘记“猫”的位置)。
(2) 解码器(Decoder):文本“生成器”(6层堆叠)
专业结构拆解:
- 每层包含3个子层(比编码器多1个子层),同样带残差连接和层归一化:
- 子层1:掩码多头自注意力(Masked Multi-Head Self-Attention)——限制当前位置只能关注“之前的位置”(比如生成第3个词时,只能看第1、2个词),避免“偷看未来信息”。实现方式是在 Q K T QK^T QKT后,将未来位置的相似度分数设为 − ∞ -∞ −∞,softmax后权重为0。
- 子层2:编码器-解码器注意力(Encoder-Decoder Attention)——Q来自解码器上一层输出,K、V来自编码器最终输出,让生成的每个词都能关注输入序列的相关位置(比如翻译“它很舒服”时,“它”关注输入的“猫”)。
- 子层3:与编码器相同的位置wise前馈网络。
-
输出处理:解码器最后一层输出通过线性投影(维度从 d m o d e l
512 d_{model}=512 dmodel=512映射到词汇表大小,如37000)和softmax,得到下一个词的概率分布。
通俗类比:解码器就像“写作文”——
- 掩码自注意力:写每一句话时,只能参考前面已经写的内容,不能提前看后面的草稿(保证逻辑连贯);
- 编码器-解码器注意力:写的时候不断回头看“阅读理解的笔记”(输入文本的语义表征),确保不偏离原文意思;
- 前馈网络:把每个词的表达打磨得更准确(比如把“它舒服”改成“它显得很舒服”)。
(3) 位置编码(Positional Encoding):给词汇“贴位置标签”
专业解释:
-
设计原因:Transformer无递归/卷积,无法自动捕捉序列顺序,必须手动注入位置信息。
-
编码公式(论文核心公式):
P E ( p o s , 2 i )
s i n ( p o s / 1000 0 2 i / d m o d e l ) PE_{(pos, 2i)}=sin(pos/10000^{2i/d_{model}}) PE(pos,2i)=sin(pos/100002i/dmodel)
P E ( p o s , 2 i + 1 )
c o s ( p o s / 1000 0 2 i / d m o d e l ) PE_{(pos, 2i+1)}=cos(pos/10000^{2i/d_{model}}) PE(pos,2i+1)=cos(pos/100002i/dmodel)
其中pos是token在序列中的位置(从0开始),i是维度索引(0到 d m o d e l / 2 − 1 d_{model}/2-1 dmodel/2−1)。 -
核心优势:
- 相对位置可表示:对于任意固定偏移k, P E p o s + k PE_{pos+k} PEpos+k可通过 P E p o s PE_{pos} PEpos的正弦和余弦函数线性组合得到(利用三角恒等式),模型能学习到“相对位置关系”(比如“第2个词和第5个词相差3个位置”)。
- 泛化性强:正弦余弦函数是周期性的,可生成任意长度序列的位置编码,即使测试时序列长度超过训练时的最大值(比如训练时最长512词,测试时600词),也能直接计算编码,无需额外训练。
-
对比实验:论文表3(E行)显示,正弦余弦编码与“学习型位置嵌入”(随机初始化后训练)性能几乎一致(BLEU分别为25.7和25.8),但前者更节省参数且泛化性更好。
通俗类比:位置编码就像“给排队的人贴编号”——每个token都有一个唯一的“位置标签”,标签的设计很巧妙:不仅能看出“谁在第1位、谁在第10位”(绝对位置),还能通过标签计算“两人之间差几个位置”(相对位置),而且不管队伍多长(序列多长),都能快速生成新的编号。
三、核心优势:基于论文数据的“碾压式突破”
论文通过理论分析(表1)和实验结果(表2-4),论证了Transformer的三大优势,下面结合“专业数据+通俗解读”展开:
1. 并行计算效率:从“串行排队”到“并行开工”
“表 1:不同层类型的最大路径长度、每层复杂度及最小顺序操作数注:n 为序列长度,d 为表示维度,k 为卷积核大小,r 为受限自注意力中的邻域大小”
专业分析(论文表1):
- 计算复杂度对比:
- 自注意力: O ( n 2 d ) O(n^2 d) O(n2d)(n=序列长度,d=表征维度)——主要开销是计算 Q K T QK^T QKT( n × n n×n n×n矩阵)。
- RNN: O ( n d 2 ) O(nd^2) O(nd2)——每个token都要依赖前一个token的隐藏状态,无法并行,且复杂度随d增长更快。
- CNN: O ( k n d 2 ) O(kn d^2) O(knd2)(k=卷积核大小)——虽支持并行,但捕捉长距离依赖需堆叠多层(比如k=3时,捕捉n=100词的依赖需~30层)。
- 关键结论:当 n < d n < d n<d时(这是NLP任务的常见情况,比如word-piece表征中n=100,d=512),自注意力的复杂度低于RNN,且并行度极高(所有token的 Q K T QK^T QKT计算可同时进行)。
论文实验数据:Transformer(big)在8个P100 GPU上训练3.5天(300,000步),而之前的SOTA模型GNMT训练需1.1×10²¹ FLOPs(是Transformer的~48倍),却只达到41.16 BLEU,Transformer则达到41.8 BLEU。
通俗解读:
- RNN处理句子像“工厂流水线”:只有前一个token处理完,才能处理下一个,100个token要按顺序来,效率低。
- Transformer像“建筑工地”:所有token同时“开工”,各自计算与其他所有token的关联,8个GPU就是8个施工队,同时推进,效率呈指数级提升。
- 举个例子:处理100词的句子,RNN需要100个“时间步”,Transformer只需1个“时间步”就能完成所有关联计算,后续只需要处理前馈网络和归一化,并行优势一目了然。
2. 长距离依赖捕捉:从“隔山喊话”到“当面交流”
专业分析(论文表1“最大路径长度”):
- 最大路径长度:指输入序列中任意两个token的依赖关系,在网络中需要经过的“层数量”(路径越短,依赖越容易学习)。
- 自注意力: O ( 1 ) O(1) O(1)——任意两个token直接通过注意力权重关联,无需经过中间层传递。
- RNN: O ( n ) O(n) O(n)——第1个token和第n个token的依赖,需要经过n-1个时间步的传递,梯度容易衰减。
- CNN: O ( l o g k n ) O(log_k n) O(logkn)——需通过 dilated convolution(空洞卷积)堆叠,路径长度随n增长而增加。
论文实证支持:注意力可视化图3显示,编码器第5层的多个头能直接捕捉“making”(第8个token)与“difficult”(第14个token)的长距离关联,形成“making the registration process more difficult”的完整短语,而RNN需要逐次传递才能建立这种关联,容易丢失信息。
通俗解读:
- RNN处理长文本像“传话游戏”:第1个词的信息要经过第2、3、…、n-1个词才能传到第n个词,中间容易“传错话”(梯度消失),长距离依赖的信息会严重衰减。
- Transformer像“微信群聊”:不管两个词相距多远(比如第1个词和第1000个词),都能直接“@对方”,建立直接关联,信息传递无损耗,长距离依赖的捕捉准确率几乎不受距离影响。
- 比如处理“虽然他三年前离开了公司,但他的贡献至今仍被同事们铭记”这句话,Transformer能直接将“他”与“他的贡献”“同事们”关联,而RNN可能在传递“他”的指代信息时出现偏差。
“图 3:6 层编码器自注意力中第 5 层的注意力机制捕捉长距离依赖的示例。许多注意力头会关注动词 “making” 的远距离依赖,以补全短语 “making…more difficult”。此处仅展示针对单词 “making” 的注意力情况。不同颜色代表不同的注意力头。建议以彩色查看。”
3. 规模扩展性价比:从“添砖加瓦”到“搭积木”
专业分析:
-
传统模型(RNN/CNN)扩展规模时,计算量呈“线性增长”甚至“超线性增长”:比如RNN的隐藏层维度从512提升到1024,复杂度从 n d 2 nd^2 nd2变成 n ( 2 d ) 2
4 n d 2 n(2d)^2=4nd^2 n(2d)2=4nd2,计算量翻4倍,但性能提升有限。 - Transformer的并行特性让规模扩展的“边际成本降低”:论文中“big model”将 d m o d e l d_{model} dmodel从512提升到1024, d f f d_{ff} dff从2048提升到4096,h从8提升到16,参数从6500万增加到2.13亿(3.3倍),但训练时间仅从12小时(base model)增加到3.5天(big model),而BLEU从27.3提升到28.4(EN-DE任务【BLEU全称 Bilingual Evaluation Understudy(双语评估替补),核心是衡量模型生成文本与人工标注参考文本的相似度】),提升幅度显著。
论文实验数据:表3显示,当 d m o d e l
1024 d_{model}=1024 dmodel=1024、 d f f
4096 d_{ff}=4096 dff=4096时,模型的困惑度(PPL)从4.92降至4.33,BLEU从25.8提升到26.4,验证了规模扩展的有效性。
通俗解读:
- 传统模型扩展像“盖平房”:要想盖更高(性能更好),必须把地基、墙体都重新加固(计算量大幅增加),付出的成本很高,但高度提升有限。
- Transformer扩展像“搭乐高”:并行结构就是“标准化积木”,要想搭更高(更大规模),只需增加积木数量(参数),无需重新设计结构,付出的成本远低于传统模型,但高度(性能)能持续提升。
- 这也是为什么后续GPT-3(1750亿参数)、PaLM(5400亿参数)能基于Transformer架构实现,而无法基于RNN——RNN的串行结构根本支撑不了如此大规模的参数训练。
四、补充:训练细节与泛化能力
1. 训练关键策略
-
优化器:Adam(论文5.3节),参数 β 1
0.9 \beta_1=0.9 β1=0.9, β 2
0.98 \beta_2=0.98 β2=0.98, ϵ
1 e − 9 \epsilon=1e-9 ϵ=1e−9
β 2 \beta_2 β2接近1,说明对历史梯度平方的衰减较慢,适合稀疏梯度场景;“模型学习时既重视近期的梯度(当前数据的规律),也不忽视远期的梯度(之前数据的规律),避免学了新的忘了旧的”。
-
学习率调度: l r a t e
d m o d e l − 0.5 ⋅ m i n ( s t e p _ n u m − 0.5 , s t e p _ n u m ⋅ w a r m u p _ s t e p s − 1.5 ) lrate=d_{model}^{-0.5}·min(step\_num^{-0.5}, step\_num·warmup\_steps^{-1.5}) lrate=dmodel−0.5⋅min(step_num−0.5,step_num⋅warmup_steps−1.5)(论文公式3)
前4000步线性升温(warmup),避免初始学习率过大导致模型震荡;之后按步长的-0.5次方衰减,确保后期稳定收敛
- 正则化(论文5.4节):
-
残差dropout: P d r o p
0.1 P_{drop}=0.1 Pdrop=0.1——对每个子层输出和嵌入+位置编码的总和进行dropout,防止过拟合; -
标签平滑: ϵ l s
0.1 \epsilon_{ls}=0.1 ϵls=0.1——将真实标签的概率从1.0调整为0.9,其他标签共享0.1的概率
-
降低模型对“正确标签”的过度自信,提升泛化性。
2. 泛化能力:不止于翻译
- 任务:英语 constituency parsing( constituency 句法分析,即分析句子的短语结构,如“主语短语-谓语短语”)。
-
实验设置:4层Transformer, d m o d e l
1024 d_{model}=1024 dmodel=1024,训练数据分两种:仅WSJ(4万句)、半监督(1700万句)。 - 结果:仅WSJ训练时F1=91.3,超过多数传统模型;半监督训练时F1=92.7,接近SOTA(RNN Grammar的93.3)。
句法分析要求模型捕捉严格的结构依赖(如“定语从句修饰哪个名词”),且输出长度远大于输入(短语结构树的节点数是token数的2-3倍),Transformer能在该任务上取得好成绩,证明其注意力机制的“结构建模能力”,而非仅适用于翻译。Transformer不仅能“做好翻译”,还能“学好语法分析”,说明它掌握的是“语言的通用规律”,而非“翻译的专属技巧”,为后续迁移到文本生成、摘要、问答等任务奠定了基础。
五、总结:一篇论文,开启AI的“大模型时代”
《Attention Is All You Need》之所以成为AI工程领域的“里程碑”,不仅在于它解决了当时的技术瓶颈,更在于它为后续十年的AI发展奠定了基础:
- 技术层面:让“大规模并行训练”成为可能,直接推动模型参数从“百万级”跃升到“万亿级”(如GPT-4的万亿参数规模);
- 应用层面:基于Transformer的模型攻克了机器翻译、文本生成、问答系统等核心任务,让AI从“实验室”走进日常生活(如ChatGPT、智能客服、AI写作工具);
- 工程师视角:理解Transformer的自注意力机制、并行逻辑和架构设计,是掌握大模型开发、优化、部署的“必修课”
如果说AI的发展是一条漫长的道路,那《Attention Is All You Need》就是这条路上的“关键路标”——它不仅回答了“如何高效处理文本”的问题,更开启了“用注意力机制构建智能系统”的全新思路。直到今天,这篇论文的思想仍在影响AI前沿研究(如视觉Transformer(ViT)、多模态Transformer),足以证明其不朽的价值。
对于想要深入AI领域的朋友,建议直接阅读论文原文(篇幅仅11页,逻辑清晰、公式简洁)——理解它,你就理解了现代大模型的“技术原点”。 论文链接如下 https://arxiv.org/abs/1706.03762