实用程序:无需付费软件!自制音视频转字幕工具,复制代码直接运行
基于 Whisper + moviepy + tkinter 的开源音视频转 SRT 字幕工具:GUI 选文件、提取音频、中文识别、繁转简、双进度条与 ETA,附完整可运行代码与依赖安装说明。
前言
在多媒体内容爆炸的时代,为音视频添加字幕成为提升内容可访问性、传播效率的重要手段。无论是自媒体创作者、教育工作者还是普通用户,都可能面临手动制作字幕耗时费力的问题。基于此,我开发了一款”音视频转字幕工具”,借助OpenAI的Whisper语音识别模型,实现从音视频文件到标准SRT字幕的自动化转换。
这款工具结合了moviepy的音视频处理能力、whisper的语音识别能力和tkinter的可视化界面,让用户无需专业知识即可快速生成字幕。下面将详细介绍工具的实现原理与使用方法。
已在github开源:https://github.com/ChenAI-TGF/Audio_And_Video_Transcription
一、工具介绍
这款音视频转字幕工具具备以下核心功能:
- 多格式支持:兼容MP4、AVI、MOV等视频格式及MP3、WAV等音频格式
- 灵活参数配置:可选择Whisper模型(tiny/base/small/medium/large)、调整线程数和温度值
- 实时进度反馈:双进度条分别显示音频提取和字幕识别进度
- 时间估算:实时显示处理耗时和预计剩余时间
- 繁简转换:自动将识别结果转换为简体中文
- 标准字幕输出:生成符合SRT格式的字幕文件,可直接用于视频编辑
工具的优势在于可视化操作降低了技术门槛,同时保留了参数调整的灵活性,兼顾了普通用户和进阶用户的需求。
二、代码核心部分详解
1. 音频提取模块
音视频文件首先需要提取音频轨道,这一步由video_to_audio方法实现:
def video_to_audio(self, video_path: str, audio_path: str) -> bool:
try:
with VideoFileClip(video_path) as video:
total_duration = video.duration
audio = video.audio
# 记录音频转换开始时间
self.audio_start_time = datetime.now()
# 写入音频(logger=None关闭冗余输出)
audio.write_audiofile(audio_path, logger=None)
# 强制进度到100%
self.update_audio_progress(100.0)
return True
except Exception as e:
messagebox.showerror("错误", f"音视频转音频失败:{str(e)}")
return False
核心逻辑:使用moviepy的VideoFileClip读取视频文件,提取音频轨道后写入WAV格式文件。对于本身就是音频的文件(如MP3),会直接跳过提取步骤
2. Whisper模型加载与语音识别
语音转文字是工具的核心功能,基于OpenAI的Whisper模型实现:
def load_whisper_model(self) -> Optional[whisper.Whisper]:
try:
model_name = self.model_var.get()
self.update_transcribe_progress(10)
# 加载指定模型,使用CPU运行(可改为"cuda"启用GPU加速)
model = whisper.load_model(model_name, device="cpu")
self.update_transcribe_progress(20)
return model
except Exception as e:
messagebox.showerror("错误", f"模型加载失败:{str(e)}")
return None
def transcribe_audio(self, audio_path: str) -> Optional[dict]:
global is_running
self.model = self.load_whisper_model()
if not self.model or not is_running:
return None
try:
# 记录字幕识别开始时间
self.transcribe_start_time = datetime.now()
# 分段识别模拟进度
self.update_transcribe_progress(30)
result = self.model.transcribe(
audio_path,
language="zh", # 指定中文识别
temperature=self.temp_var.get(), # 控制输出随机性
)
self.update_transcribe_progress(80)
if not is_running:
return None
self.update_transcribe_progress(100)
return result
except Exception as e:
messagebox.showerror("错误", f"字幕识别失败:{str(e)}")
return None
核心逻辑:
- 先加载用户选择的Whisper模型(模型越小速度越快,精度越低)
- 通过
transcribe方法处理音频,指定language="zh"优化中文识别效果 temperature参数控制输出随机性(0表示确定性输出,适合字幕生成)
3. SRT字幕格式化
识别结果需要转换为标准SRT格式,包含序号、时间轴和文本:
def format_srt(self, result: dict) -> str:
srt_content = ""
for i, segment in enumerate(result["segments"], 1):
start = self.format_time(segment["start"])
end = self.format_time(segment["end"])
# 繁简转换(将可能的繁体转为简体)
text = self.cc.convert(segment["text"].strip())
srt_content += f"{i}\n{start} --> {end}\n{text}\n\n"
return srt_content
@staticmethod
def format_time(seconds: float) -> str:
"""将秒数格式化为SRT时间格式(hh:mm:ss,fff)"""
hours = math.floor(seconds / 3600)
minutes = math.floor((seconds % 3600) / 60)
secs = math.floor(seconds % 60)
millis = math.floor((seconds % 1) * 1000)
return f"{hours:02d}:{minutes:02d}:{secs:02d},{millis:03d}"
核心逻辑:
- 解析Whisper返回的分段结果(包含开始时间、结束时间和文本)
- 将时间戳转换为SRT要求的
hh:mm:ss,fff格式 - 使用
OpenCC进行繁简转换,确保输出统一为简体中文
4. 多线程与进度管理
为避免UI卡顿,核心处理逻辑在独立线程中运行:
def start_convert(self):
"""启动转换线程"""
thread = threading.Thread(target=self.convert_thread, daemon=True)
thread.start()
def convert_thread(self):
"""转换线程(避免UI卡顿)"""
global is_running
is_running = True
self.start_btn.config(state=tk.DISABLED)
self.stop_btn.config(state=tk.NORMAL)
# 重置进度和时间
self.update_audio_progress(0.0)
self.update_transcribe_progress(0.0)
self.result_text.delete(1.0, tk.END)
self.total_start_time = datetime.now()
# 核心处理流程
input_path = self.file_path_var.get()
# 音频提取 -> 语音识别 -> 字幕格式化 -> 保存文件
# ...(省略具体步骤)
核心逻辑:
- 将耗时的音频处理和识别任务放入子线程
- 通过全局变量
is_running实现主线程与子线程的通信 - 实时更新进度条和时间显示,提升用户体验
三、完整代码
import tkinter as tk
from tkinter import ttk, filedialog, messagebox
import os
from moviepy import VideoFileClip
import whisper
import threading
import time
from datetime import datetime, timedelta
from typing import Optional
import math
from opencc import OpenCC
# 全局变量用于控制进度和线程
audio_convert_progress = 0.0
transcribe_progress = 0.0
is_running = False
class AudioVideoToSubtitle:
def __init__(self, root):
self.root = root
self.root.title("音视频转字幕工具")
self.root.geometry("900x650") # 扩大窗口以容纳时间显示
# 初始化繁简转换器
self.cc = OpenCC('t2s')
# 时间跟踪变量
self.total_start_time = None # 总处理开始时间
self.audio_start_time = None # 音频转换开始时间
self.transcribe_start_time = None # 字幕识别开始时间
self.time_update_id = None # 时间更新定时器ID
# 初始化模型
self.model = None
self.model_path = None
self.init_ui()
def init_ui(self):
# 1. 文件选择区域
file_frame = ttk.LabelFrame(self.root, text="文件设置")
file_frame.pack(fill=tk.X, padx=10, pady=5)
self.file_path_var = tk.StringVar()
ttk.Entry(file_frame, textvariable=self.file_path_var, width=70).pack(side=tk.LEFT, padx=5, pady=5)
ttk.Button(file_frame, text="选择文件", command=self.select_file).pack(side=tk.LEFT, padx=5, pady=5)
# 2. 速度调节参数区域
param_frame = ttk.LabelFrame(self.root, text="速度调节参数")
param_frame.pack(fill=tk.X, padx=10, pady=5)
ttk.Label(param_frame, text="模型选择:").pack(side=tk.LEFT, padx=5, pady=5)
self.model_var = tk.StringVar(value="base")
model_options = ["tiny", "base", "small", "medium", "large"]
ttk.Combobox(param_frame, textvariable=self.model_var, values=model_options, width=10).pack(side=tk.LEFT, padx=5, pady=5)
ttk.Label(param_frame, text="线程数:").pack(side=tk.LEFT, padx=5, pady=5)
self.thread_var = tk.IntVar(value=4)
ttk.Spinbox(param_frame, from_=1, to=16, textvariable=self.thread_var, width=5).pack(side=tk.LEFT, padx=5, pady=5)
ttk.Label(param_frame, text="温度值:").pack(side=tk.LEFT, padx=5, pady=5)
self.temp_var = tk.DoubleVar(value=0.0)
ttk.Spinbox(param_frame, from_=0.0, to=1.0, increment=0.1, textvariable=self.temp_var, width=5).pack(side=tk.LEFT, padx=5, pady=5)
# 3. 进度条和时间显示区域
progress_frame = ttk.LabelFrame(self.root, text="处理进度与时间")
progress_frame.pack(fill=tk.X, padx=10, pady=5)
# 音视频转音频进度条
ttk.Label(progress_frame, text="音视频转音频:").pack(side=tk.LEFT, padx=5)
self.audio_progress = ttk.Progressbar(progress_frame, orient=tk.HORIZONTAL, length=300, mode='determinate')
self.audio_progress.pack(side=tk.LEFT, padx=5, pady=5)
self.audio_progress_label = ttk.Label(progress_frame, text="0%")
self.audio_progress_label.pack(side=tk.LEFT, padx=5)
# 字幕识别进度条
ttk.Label(progress_frame, text="字幕识别:").pack(side=tk.LEFT, padx=5)
self.transcribe_progress = ttk.Progressbar(progress_frame, orient=tk.HORIZONTAL, length=300, mode='determinate')
self.transcribe_progress.pack(side=tk.LEFT, padx=5, pady=5)
self.transcribe_progress_label = ttk.Label(progress_frame, text="0%")
self.transcribe_progress_label.pack(side=tk.LEFT, padx=5)
# 时间显示区域
time_frame = ttk.LabelFrame(self.root, text="时间信息")
time_frame.pack(fill=tk.X, padx=10, pady=5)
self.elapsed_time_var = tk.StringVar(value="已处理时间: 00:00:00")
ttk.Label(time_frame, textvariable=self.elapsed_time_var).pack(side=tk.LEFT, padx=20, pady=5)
self.estimated_time_var = tk.StringVar(value="预计剩余时间: --:--:--")
ttk.Label(time_frame, textvariable=self.estimated_time_var).pack(side=tk.LEFT, padx=20, pady=5)
# 4. 控制按钮区域
btn_frame = ttk.Frame(self.root)
btn_frame.pack(pady=10)
self.start_btn = ttk.Button(btn_frame, text="开始转换", command=self.start_convert)
self.start_btn.pack(side=tk.LEFT, padx=10)
self.stop_btn = ttk.Button(btn_frame, text="停止转换", command=self.stop_convert, state=tk.DISABLED)
self.stop_btn.pack(side=tk.LEFT, padx=10)
# 5. 结果显示区域
result_frame = ttk.LabelFrame(self.root, text="识别结果预览")
result_frame.pack(fill=tk.BOTH, expand=True, padx=10, pady=5)
self.result_text = tk.Text(result_frame, height=15)
scrollbar = ttk.Scrollbar(result_frame, command=self.result_text.yview)
self.result_text.configure(yscrollcommand=scrollbar.set)
self.result_text.pack(side=tk.LEFT, fill=tk.BOTH, expand=True, padx=5, pady=5)
scrollbar.pack(side=tk.RIGHT, fill=tk.Y, padx=5, pady=5)
def select_file(self):
"""选择音视频文件"""
file_types = [
("音视频文件", "*.mp4 *.avi *.mov *.mkv *.flv *.mp3 *.wav *.m4a"),
("所有文件", "*.*")
]
file_path = filedialog.askopenfilename(filetypes=file_types)
if file_path:
self.file_path_var.set(file_path)
def update_audio_progress(self, value: float):
"""更新音频转换进度条"""
global audio_convert_progress
audio_convert_progress = min(value, 100.0)
self.audio_progress["value"] = audio_convert_progress
self.audio_progress_label.config(text=f"{int(audio_convert_progress)}%")
self.root.update_idletasks()
def update_transcribe_progress(self, value: float):
"""更新字幕识别进度条"""
global transcribe_progress
transcribe_progress = min(value, 100.0)
self.transcribe_progress["value"] = transcribe_progress
self.transcribe_progress_label.config(text=f"{int(transcribe_progress)}%")
self.root.update_idletasks()
def format_time_display(self, seconds: float) -> str:
"""将秒数格式化为时分秒显示"""
hours, remainder = divmod(int(seconds), 3600)
minutes, seconds = divmod(remainder, 60)
return f"{hours:02d}:{minutes:02d}:{seconds:02d}"
def update_time_display(self):
"""更新时间显示信息"""
if not is_running or not self.total_start_time:
return
# 计算已处理时间
elapsed_seconds = (datetime.now() - self.total_start_time).total_seconds()
self.elapsed_time_var.set(f"已处理时间: {self.format_time_display(elapsed_seconds)}")
# 计算预计剩余时间
try:
if audio_convert_progress < 100:
# 音频转换阶段
if self.audio_start_time and audio_convert_progress > 0:
audio_elapsed = (datetime.now() - self.audio_start_time).total_seconds()
total_audio_estimated = audio_elapsed / (audio_convert_progress / 100)
audio_remaining = total_audio_estimated - audio_elapsed
# 假设转录时间与音频时间相当(简单估算)
total_estimated = total_audio_estimated * 2
remaining = total_estimated - elapsed_seconds
self.estimated_time_var.set(f"预计剩余时间: {self.format_time_display(remaining)}")
else:
# 字幕识别阶段
if self.transcribe_start_time and transcribe_progress > 0 and transcribe_progress < 100:
transcribe_elapsed = (datetime.now() - self.transcribe_start_time).total_seconds()
total_transcribe_estimated = transcribe_elapsed / (transcribe_progress / 100)
transcribe_remaining = total_transcribe_estimated - transcribe_elapsed
self.estimated_time_var.set(f"预计剩余时间: {self.format_time_display(transcribe_remaining)}")
elif transcribe_progress >= 100:
self.estimated_time_var.set(f"预计剩余时间: 00:00:00")
except (ZeroDivisionError, Exception):
self.estimated_time_var.set(f"预计剩余时间: 计算中...")
# 继续定时更新
self.time_update_id = self.root.after(1000, self.update_time_display)
def video_to_audio(self, video_path: str, audio_path: str) -> bool:
"""音视频转音频,带进度更新"""
try:
with VideoFileClip(video_path) as video:
total_duration = video.duration
audio = video.audio
# 记录音频转换开始时间
self.audio_start_time = datetime.now()
# 写入音频
audio.write_audiofile(audio_path, logger=None)
# 强制进度到100%
self.update_audio_progress(100.0)
return True
except Exception as e:
messagebox.showerror("错误", f"音视频转音频失败:{str(e)}")
return False
def load_whisper_model(self) -> Optional[whisper.Whisper]:
"""加载whisper模型"""
try:
model_name = self.model_var.get()
self.update_transcribe_progress(10)
model = whisper.load_model(model_name, device="cpu")
self.update_transcribe_progress(20)
return model
except Exception as e:
messagebox.showerror("错误", f"模型加载失败:{str(e)}")
return None
def transcribe_audio(self, audio_path: str) -> Optional[dict]:
"""音频转字幕,带进度更新"""
global is_running
self.model = self.load_whisper_model()
if not self.model or not is_running:
return None
try:
# 记录字幕识别开始时间
self.transcribe_start_time = datetime.now()
# 分段识别模拟进度
self.update_transcribe_progress(30)
result = self.model.transcribe(
audio_path,
language="zh",
temperature=self.temp_var.get(),
)
self.update_transcribe_progress(80)
if not is_running:
return None
self.update_transcribe_progress(100)
return result
except Exception as e:
messagebox.showerror("错误", f"字幕识别失败:{str(e)}")
return None
def format_srt(self, result: dict) -> str:
"""将识别结果格式化为SRT字幕格式"""
srt_content = ""
for i, segment in enumerate(result["segments"], 1):
start = self.format_time(segment["start"])
end = self.format_time(segment["end"])
text = self.cc.convert(segment["text"].strip())
srt_content += f"{i}\n{start} --> {end}\n{text}\n\n"
return srt_content
@staticmethod
def format_time(seconds: float) -> str:
"""将秒数格式化为SRT时间格式(hh:mm:ss,fff)"""
hours = math.floor(seconds / 3600)
minutes = math.floor((seconds % 3600) / 60)
secs = math.floor(seconds % 60)
millis = math.floor((seconds % 1) * 1000)
return f"{hours:02d}:{minutes:02d}:{secs:02d},{millis:03d}"
def save_subtitle(self, srt_content: str, input_path: str):
"""保存字幕文件"""
save_path = os.path.splitext(input_path)[0] + ".srt"
try:
with open(save_path, "w", encoding="utf-8") as f:
f.write(srt_content)
messagebox.showinfo("成功", f"字幕已保存至:\n{save_path}")
return save_path
except Exception as e:
messagebox.showerror("错误", f"字幕保存失败:{str(e)}")
return None
def convert_thread(self):
"""转换线程(避免UI卡顿)"""
global is_running
is_running = True
self.start_btn.config(state=tk.DISABLED)
self.stop_btn.config(state=tk.NORMAL)
# 重置进度和时间
self.update_audio_progress(0.0)
self.update_transcribe_progress(0.0)
self.result_text.delete(1.0, tk.END)
self.total_start_time = datetime.now()
self.audio_start_time = None
self.transcribe_start_time = None
# 启动时间更新
self.root.after(0, self.update_time_display)
input_path = self.file_path_var.get()
if not os.path.exists(input_path):
messagebox.showwarning("警告", "请选择有效的音视频文件!")
self.reset_ui()
return
# 临时音频文件路径
temp_audio = "temp_audio.wav"
try:
# 步骤1:音视频转音频
if not is_running:
return
if input_path.lower().endswith(("mp3", "wav", "m4a")):
# 已是音频文件,跳过转换
self.update_audio_progress(100.0)
audio_path = input_path
self.audio_start_time = datetime.now() # 标记音频处理完成时间
else:
if not self.video_to_audio(input_path, temp_audio):
return
audio_path = temp_audio
# 步骤2:音频转字幕
if not is_running:
return
result = self.transcribe_audio(audio_path)
if not result or not is_running:
return
# 步骤3:格式化并显示结果
srt_content = self.format_srt(result)
self.result_text.insert(1.0, srt_content)
# 步骤4:保存字幕
self.save_subtitle(srt_content, input_path)
finally:
# 清理临时文件
if os.path.exists(temp_audio) and not input_path.lower().endswith(("mp3", "wav", "m4a")):
os.remove(temp_audio)
self.reset_ui()
def start_convert(self):
"""启动转换线程"""
thread = threading.Thread(target=self.convert_thread, daemon=True)
thread.start()
def stop_convert(self):
"""停止转换"""
global is_running
is_running = False
self.stop_btn.config(state=tk.DISABLED)
self.result_text.insert(tk.END, "\n\n转换已停止!")
def reset_ui(self):
"""重置UI状态"""
global is_running
is_running = False
self.start_btn.config(state=tk.NORMAL)
self.stop_btn.config(state=tk.DISABLED)
# 停止时间更新
if self.time_update_id:
self.root.after_cancel(self.time_update_id)
self.time_update_id = None
# 重置时间显示
self.elapsed_time_var.set("已处理时间: 00:00:00")
self.estimated_time_var.set("预计剩余时间: --:--:--")
if __name__ == "__main__":
# 提示安装依赖
try:
import torch
import opencc
except ImportError as e:
missing = str(e).split("'")[1]
messagebox.showwarning("提示", f"请先安装依赖库:\npip install torch moviepy openai-whisper ffmpeg-python opencc-python-reimplemented")
exit()
root = tk.Tk()
app = AudioVideoToSubtitle(root)
root.mainloop()
四、效果演示
- 工具启动:运行程序后显示主界面,包含文件选择、参数配置、进度显示和结果预览区域。
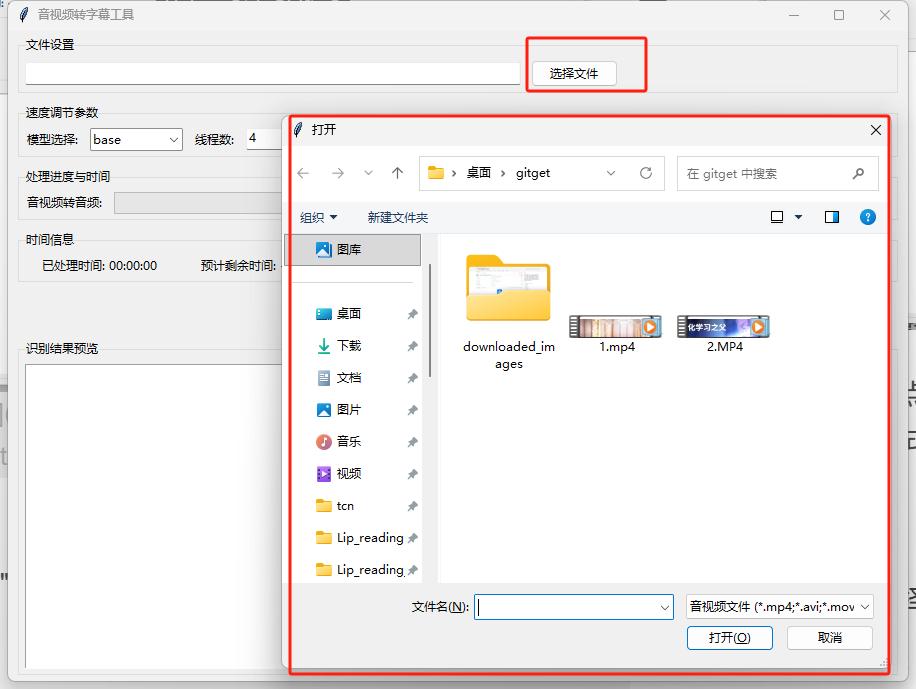
- 文件选择:点击”选择文件”按钮,选择需要转换的音视频文件(如MP4格式视频)。
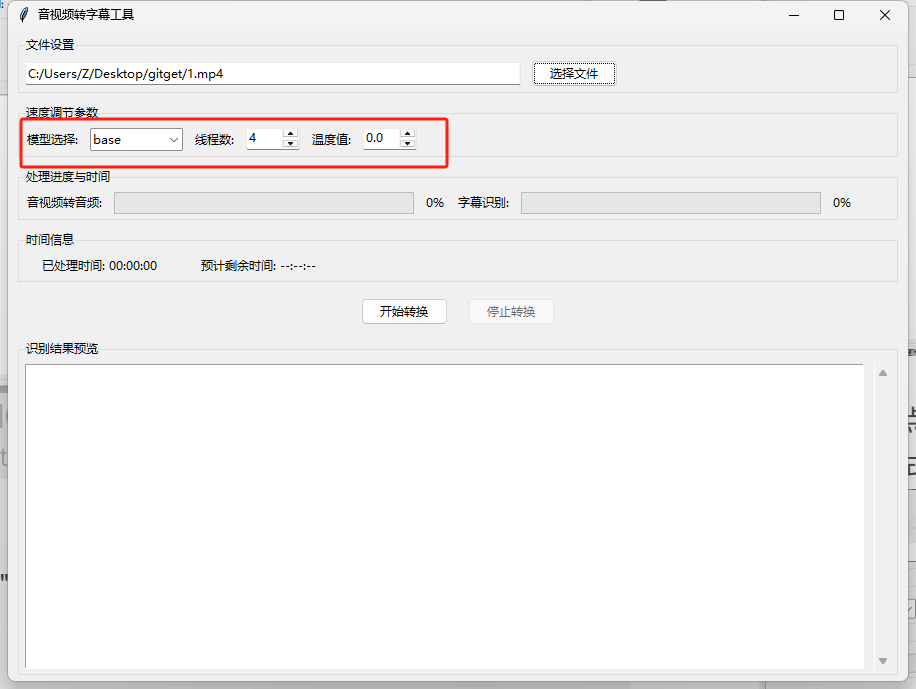
- 参数配置:
- 模型选择:根据需求选择(tiny最快,large最精准)
- 线程数:根据CPU核心数调整(建议4-8)
- 温度值:默认0.0(适合字幕生成)
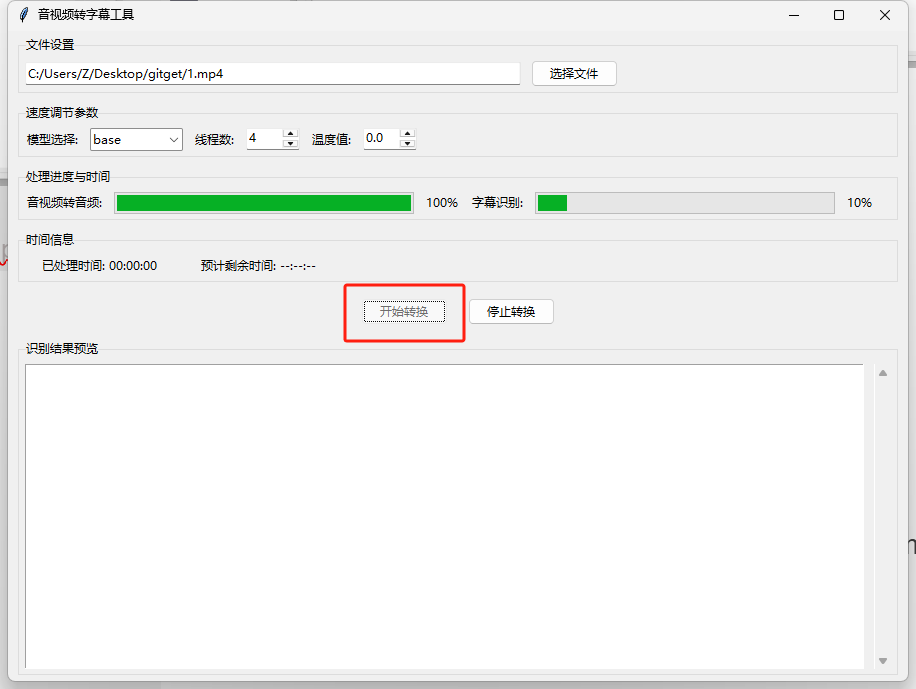
- 开始转换:
- 点击”开始转换”,音频提取进度条开始推进
- 提取完成后,字幕识别进度条启动
- 实时显示”已处理时间”和”预计剩余时间”
- 结果查看:
- 识别完成后,结果预览区显示SRT格式字幕
- 自动保存与原文件同名的SRT文件(如”视频.mp4”生成”视频.srt”)
- 弹窗提示保存路径
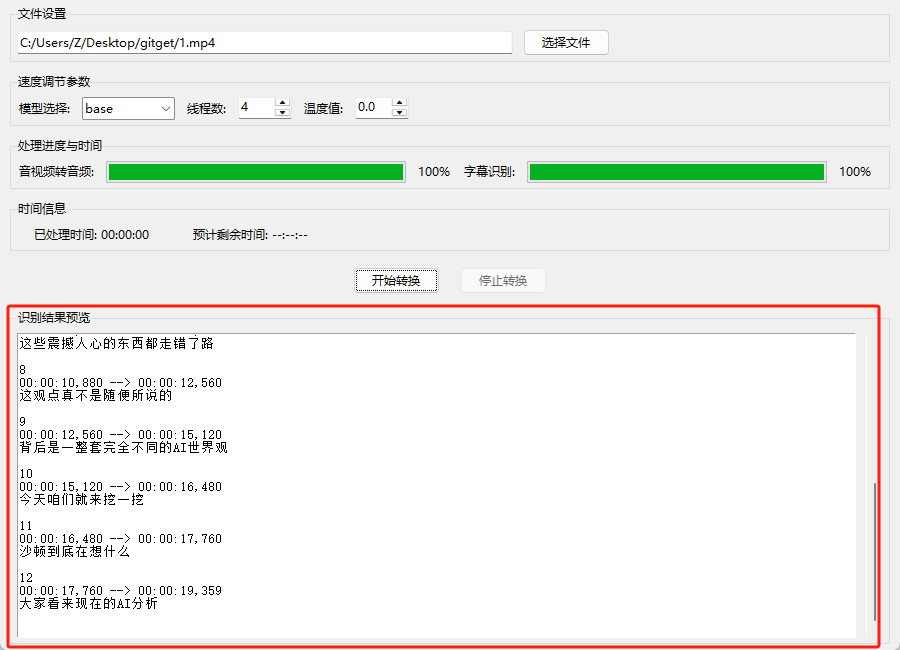
- 中途停止:如需中断,点击”停止转换”按钮,工具会清理临时文件并重置状态。
五、第三方库安装
1、需要的库
该音视频转字幕工具的代码依赖以下第三方库,以下是各库的作用及安装方法:
torch(PyTorch)
- 作用:Whisper模型运行的基础框架,用于加载和运行语音识别模型(Whisper基于PyTorch实现)。
- 安装命令:
推荐根据系统和是否需要GPU加速,从PyTorch官网获取对应命令,基础CPU版本可直接安装:pip install torch
moviepy
- 作用:音视频处理库,用于从视频中提取音频轨道(核心功能之一)。
- 安装命令:
pip install moviepy
openai-whisper
- 作用:OpenAI官方的语音识别库,提供Whisper模型(实现语音转文字的核心功能)。
- 安装命令:
pip install openai-whisper
ffmpeg-python
- 作用:
moviepy处理音视频时依赖的底层工具封装,用于实际执行音视频编解码操作。 - 注意:除了安装Python库,还需要在系统中安装
ffmpeg程序(否则moviepy可能无法正常工作):- Python库安装:
pip install ffmpeg-python - 系统级
ffmpeg安装:- Windows:从ffmpeg官网下载安装包,解压后将
bin目录添加到系统环境变量。 - Ubuntu/Debian:
sudo apt-get install ffmpeg - macOS:
brew install ffmpeg(需先安装Homebrew)
- Windows:从ffmpeg官网下载安装包,解压后将
- Python库安装:
opencc-python-reimplemented
- 作用:繁简转换库,用于将识别结果中的繁体中文自动转换为简体中文(代码中通过
OpenCC('t2s')实现)。 - 安装命令:
pip install opencc-python-reimplemented
2、一条命令安装所有依赖
可将上述命令整合为一条安装命令(推荐使用国内镜像源如-i https://pypi.tuna.tsinghua.edu.cn/simple加速):
pip install torch moviepy openai-whisper ffmpeg-python opencc-python-reimplemented -i https://pypi.tuna.tsinghua.edu.cn/simple
3、注意事项
- 首次运行时,Whisper会自动下载选择的模型(如
base模型约1GB),请确保网络畅通。 - 若电脑有NVIDIA显卡且安装了CUDA,可将代码中
device="cpu"改为device="cuda",显著提升识别速度(需安装对应CUDA版本的PyTorch)。
总结
这款音视频转字幕工具通过整合moviepy和whisper的强大功能,实现了文字识别和字幕生成的自动化流程。核心优势在于:
- 易用性:可视化界面降低了技术门槛,无需命令行操作
- 灵活性:可通过模型选择平衡速度与精度
- 实用性:生成标准SRT格式,直接适配主流视频编辑软件
无论是自媒体创作者快速制作字幕,还是学习者为教学视频添加字幕,这款工具都能显著提升效率,降低字幕制作的技术门槛。
實用程序:無需付費軟件!自制音視頻轉字幕工具,複製代碼直接運行
基於 Whisper + moviepy + tkinter 的開源音視頻轉 SRT 字幕工具:GUI 選檔、提取音頻、中文識別、繁轉簡、雙進度條與 ETA,附完整可運行程式與依賴安裝說明。
來源:https://blog.csdn.net/2403_87969572/article/details/154516658
抓取時間(ISO本地):2026-05-18 05:17:06
文章目錄
前言
在多媒體內容爆炸的時代,為音視頻添加字幕成為提升內容可訪問性、傳播效率的重要手段。無論是自媒體創作者、教育工作者還是普通用戶,都可能面臨手動製作字幕耗時費力的問題。基於此,我開發了一款”音視頻轉字幕工具”,藉助OpenAI的Whisper語音識別模型,實現從音視頻文件到標準SRT字幕的自動化轉換。
這款工具結合了moviepy的音視頻處理能力、whisper的語音識別能力和tkinter的可視化界面,讓用戶無需專業知識即可快速生成字幕。下面將詳細介紹工具的實現原理與使用方法。
已在github開源:https://github.com/ChenAI-TGF/Audio_And_Video_Transcription
一、工具介紹
這款音視頻轉字幕工具具備以下核心功能:
- 多格式支持:兼容MP4、AVI、MOV等視頻格式及MP3、WAV等音頻格式
- 靈活參數配置:可選擇Whisper模型(tiny/base/small/medium/large)、調整線程數和溫度值
- 實時進度反饋:雙進度條分別顯示音頻提取和字幕識別進度
- 時間估算:實時顯示處理耗時和預計剩餘時間
- 繁簡轉換:自動將識別結果轉換為簡體中文
- 標準字幕輸出:生成符合SRT格式的字幕文件,可直接用於視頻編輯
工具的優勢在於可視化操作降低了技術門檻,同時保留了參數調整的靈活性,兼顧了普通用戶和進階用戶的需求。
二、代碼核心部分詳解
1. 音頻提取模塊
音視頻文件首先需要提取音頻軌道,這一步由video_to_audio方法實現:
def video_to_audio(self, video_path: str, audio_path: str) -> bool:
try:
with VideoFileClip(video_path) as video:
total_duration = video.duration
audio = video.audio
# 記錄音頻轉換開始時間
self.audio_start_time = datetime.now()
# 寫入音頻(logger=None關閉冗餘輸出)
audio.write_audiofile(audio_path, logger=None)
# 強制進度到100%
self.update_audio_progress(100.0)
return True
except Exception as e:
messagebox.showerror("錯誤", f"音視頻轉音頻失敗:{str(e)}")
return False
核心邏輯:使用moviepy的VideoFileClip讀取視頻文件,提取音頻軌道後寫入WAV格式文件。對於本身就是音頻的文件(如MP3),會直接跳過提取步驟
2. Whisper模型加載與語音識別
語音轉文字是工具的核心功能,基於OpenAI的Whisper模型實現:
def load_whisper_model(self) -> Optional[whisper.Whisper]:
try:
model_name = self.model_var.get()
self.update_transcribe_progress(10)
# 加載指定模型,使用CPU運行(可改為"cuda"啟用GPU加速)
model = whisper.load_model(model_name, device="cpu")
self.update_transcribe_progress(20)
return model
except Exception as e:
messagebox.showerror("錯誤", f"模型加載失敗:{str(e)}")
return None
def transcribe_audio(self, audio_path: str) -> Optional[dict]:
global is_running
self.model = self.load_whisper_model()
if not self.model or not is_running:
return None
try:
# 記錄字幕識別開始時間
self.transcribe_start_time = datetime.now()
# 分段識別模擬進度
self.update_transcribe_progress(30)
result = self.model.transcribe(
audio_path,
language="zh", # 指定中文識別
temperature=self.temp_var.get(), # 控制輸出隨機性
)
self.update_transcribe_progress(80)
if not is_running:
return None
self.update_transcribe_progress(100)
return result
except Exception as e:
messagebox.showerror("錯誤", f"字幕識別失敗:{str(e)}")
return None
核心邏輯:
- 先加載用戶選擇的Whisper模型(模型越小速度越快,精度越低)
- 通過
transcribe方法處理音頻,指定language="zh"優化中文識別效果 temperature參數控制輸出隨機性(0表示確定性輸出,適合字幕生成)
3. SRT字幕格式化
識別結果需要轉換為標準SRT格式,包含序號、時間軸和文本:
def format_srt(self, result: dict) -> str:
srt_content = ""
for i, segment in enumerate(result["segments"], 1):
start = self.format_time(segment["start"])
end = self.format_time(segment["end"])
# 繁簡轉換(將可能的繁體轉為簡體)
text = self.cc.convert(segment["text"].strip())
srt_content += f"{i}\n{start} --> {end}\n{text}\n\n"
return srt_content
@staticmethod
def format_time(seconds: float) -> str:
"""將秒數格式化為SRT時間格式(hh:mm:ss,fff)"""
hours = math.floor(seconds / 3600)
minutes = math.floor((seconds % 3600) / 60)
secs = math.floor(seconds % 60)
millis = math.floor((seconds % 1) * 1000)
return f"{hours:02d}:{minutes:02d}:{secs:02d},{millis:03d}"
核心邏輯:
- 解析Whisper返回的分段結果(包含開始時間、結束時間和文本)
- 將時間戳轉換為SRT要求的
hh:mm:ss,fff格式 - 使用
OpenCC進行繁簡轉換,確保輸出統一為簡體中文
4. 多線程與進度管理
為避免UI卡頓,核心處理邏輯在獨立線程中運行:
def start_convert(self):
"""啟動轉換線程"""
thread = threading.Thread(target=self.convert_thread, daemon=True)
thread.start()
def convert_thread(self):
"""轉換線程(避免UI卡頓)"""
global is_running
is_running = True
self.start_btn.config(state=tk.DISABLED)
self.stop_btn.config(state=tk.NORMAL)
# 重置進度和時間
self.update_audio_progress(0.0)
self.update_transcribe_progress(0.0)
self.result_text.delete(1.0, tk.END)
self.total_start_time = datetime.now()
# 核心處理流程
input_path = self.file_path_var.get()
# 音頻提取 -> 語音識別 -> 字幕格式化 -> 保存文件
# ...(省略具體步驟)
核心邏輯:
- 將耗時的音頻處理和識別任務放入子線程
- 通過全局變量
is_running實現主線程與子線程的通信 - 實時更新進度條和時間顯示,提升用戶體驗
三、完整代碼
import tkinter as tk
from tkinter import ttk, filedialog, messagebox
import os
from moviepy import VideoFileClip
import whisper
import threading
import time
from datetime import datetime, timedelta
from typing import Optional
import math
from opencc import OpenCC
# 全局變量用於控制進度和線程
audio_convert_progress = 0.0
transcribe_progress = 0.0
is_running = False
class AudioVideoToSubtitle:
def __init__(self, root):
self.root = root
self.root.title("音視頻轉字幕工具")
self.root.geometry("900x650") # 擴大窗口以容納時間顯示
# 初始化繁簡轉換器
self.cc = OpenCC('t2s')
# 時間跟蹤變量
self.total_start_time = None # 總處理開始時間
self.audio_start_time = None # 音頻轉換開始時間
self.transcribe_start_time = None # 字幕識別開始時間
self.time_update_id = None # 時間更新定時器ID
# 初始化模型
self.model = None
self.model_path = None
self.init_ui()
def init_ui(self):
# 1. 文件選擇區域
file_frame = ttk.LabelFrame(self.root, text="文件設置")
file_frame.pack(fill=tk.X, padx=10, pady=5)
self.file_path_var = tk.StringVar()
ttk.Entry(file_frame, textvariable=self.file_path_var, width=70).pack(side=tk.LEFT, padx=5, pady=5)
ttk.Button(file_frame, text="選擇文件", command=self.select_file).pack(side=tk.LEFT, padx=5, pady=5)
# 2. 速度調節參數區域
param_frame = ttk.LabelFrame(self.root, text="速度調節參數")
param_frame.pack(fill=tk.X, padx=10, pady=5)
ttk.Label(param_frame, text="模型選擇:").pack(side=tk.LEFT, padx=5, pady=5)
self.model_var = tk.StringVar(value="base")
model_options = ["tiny", "base", "small", "medium", "large"]
ttk.Combobox(param_frame, textvariable=self.model_var, values=model_options, width=10).pack(side=tk.LEFT, padx=5, pady=5)
ttk.Label(param_frame, text="線程數:").pack(side=tk.LEFT, padx=5, pady=5)
self.thread_var = tk.IntVar(value=4)
ttk.Spinbox(param_frame, from_=1, to=16, textvariable=self.thread_var, width=5).pack(side=tk.LEFT, padx=5, pady=5)
ttk.Label(param_frame, text="溫度值:").pack(side=tk.LEFT, padx=5, pady=5)
self.temp_var = tk.DoubleVar(value=0.0)
ttk.Spinbox(param_frame, from_=0.0, to=1.0, increment=0.1, textvariable=self.temp_var, width=5).pack(side=tk.LEFT, padx=5, pady=5)
# 3. 進度條和時間顯示區域
progress_frame = ttk.LabelFrame(self.root, text="處理進度與時間")
progress_frame.pack(fill=tk.X, padx=10, pady=5)
# 音視頻轉音頻進度條
ttk.Label(progress_frame, text="音視頻轉音頻:").pack(side=tk.LEFT, padx=5)
self.audio_progress = ttk.Progressbar(progress_frame, orient=tk.HORIZONTAL, length=300, mode='determinate')
self.audio_progress.pack(side=tk.LEFT, padx=5, pady=5)
self.audio_progress_label = ttk.Label(progress_frame, text="0%")
self.audio_progress_label.pack(side=tk.LEFT, padx=5)
# 字幕識別進度條
ttk.Label(progress_frame, text="字幕識別:").pack(side=tk.LEFT, padx=5)
self.transcribe_progress = ttk.Progressbar(progress_frame, orient=tk.HORIZONTAL, length=300, mode='determinate')
self.transcribe_progress.pack(side=tk.LEFT, padx=5, pady=5)
self.transcribe_progress_label = ttk.Label(progress_frame, text="0%")
self.transcribe_progress_label.pack(side=tk.LEFT, padx=5)
# 時間顯示區域
time_frame = ttk.LabelFrame(self.root, text="時間信息")
time_frame.pack(fill=tk.X, padx=10, pady=5)
self.elapsed_time_var = tk.StringVar(value="已處理時間: 00:00:00")
ttk.Label(time_frame, textvariable=self.elapsed_time_var).pack(side=tk.LEFT, padx=20, pady=5)
self.estimated_time_var = tk.StringVar(value="預計剩餘時間: --:--:--")
ttk.Label(time_frame, textvariable=self.estimated_time_var).pack(side=tk.LEFT, padx=20, pady=5)
# 4. 控制按鈕區域
btn_frame = ttk.Frame(self.root)
btn_frame.pack(pady=10)
self.start_btn = ttk.Button(btn_frame, text="開始轉換", command=self.start_convert)
self.start_btn.pack(side=tk.LEFT, padx=10)
self.stop_btn = ttk.Button(btn_frame, text="停止轉換", command=self.stop_convert, state=tk.DISABLED)
self.stop_btn.pack(side=tk.LEFT, padx=10)
# 5. 結果顯示區域
result_frame = ttk.LabelFrame(self.root, text="識別結果預覽")
result_frame.pack(fill=tk.BOTH, expand=True, padx=10, pady=5)
self.result_text = tk.Text(result_frame, height=15)
scrollbar = ttk.Scrollbar(result_frame, command=self.result_text.yview)
self.result_text.configure(yscrollcommand=scrollbar.set)
self.result_text.pack(side=tk.LEFT, fill=tk.BOTH, expand=True, padx=5, pady=5)
scrollbar.pack(side=tk.RIGHT, fill=tk.Y, padx=5, pady=5)
def select_file(self):
"""選擇音視頻文件"""
file_types = [
("音視頻文件", "*.mp4 *.avi *.mov *.mkv *.flv *.mp3 *.wav *.m4a"),
("所有文件", "*.*")
]
file_path = filedialog.askopenfilename(filetypes=file_types)
if file_path:
self.file_path_var.set(file_path)
def update_audio_progress(self, value: float):
"""更新音頻轉換進度條"""
global audio_convert_progress
audio_convert_progress = min(value, 100.0)
self.audio_progress["value"] = audio_convert_progress
self.audio_progress_label.config(text=f"{int(audio_convert_progress)}%")
self.root.update_idletasks()
def update_transcribe_progress(self, value: float):
"""更新字幕識別進度條"""
global transcribe_progress
transcribe_progress = min(value, 100.0)
self.transcribe_progress["value"] = transcribe_progress
self.transcribe_progress_label.config(text=f"{int(transcribe_progress)}%")
self.root.update_idletasks()
def format_time_display(self, seconds: float) -> str:
"""將秒數格式化為時分秒顯示"""
hours, remainder = divmod(int(seconds), 3600)
minutes, seconds = divmod(remainder, 60)
return f"{hours:02d}:{minutes:02d}:{seconds:02d}"
def update_time_display(self):
"""更新時間顯示信息"""
if not is_running or not self.total_start_time:
return
# 計算已處理時間
elapsed_seconds = (datetime.now() - self.total_start_time).total_seconds()
self.elapsed_time_var.set(f"已處理時間: {self.format_time_display(elapsed_seconds)}")
# 計算預計剩餘時間
try:
if audio_convert_progress < 100:
# 音頻轉換階段
if self.audio_start_time and audio_convert_progress > 0:
audio_elapsed = (datetime.now() - self.audio_start_time).total_seconds()
total_audio_estimated = audio_elapsed / (audio_convert_progress / 100)
audio_remaining = total_audio_estimated - audio_elapsed
# 假設轉錄時間與音頻時間相當(簡單估算)
total_estimated = total_audio_estimated * 2
remaining = total_estimated - elapsed_seconds
self.estimated_time_var.set(f"預計剩餘時間: {self.format_time_display(remaining)}")
else:
# 字幕識別階段
if self.transcribe_start_time and transcribe_progress > 0 and transcribe_progress < 100:
transcribe_elapsed = (datetime.now() - self.transcribe_start_time).total_seconds()
total_transcribe_estimated = transcribe_elapsed / (transcribe_progress / 100)
transcribe_remaining = total_transcribe_estimated - transcribe_elapsed
self.estimated_time_var.set(f"預計剩餘時間: {self.format_time_display(transcribe_remaining)}")
elif transcribe_progress >= 100:
self.estimated_time_var.set(f"預計剩餘時間: 00:00:00")
except (ZeroDivisionError, Exception):
self.estimated_time_var.set(f"預計剩餘時間: 計算中...")
# 繼續定時更新
self.time_update_id = self.root.after(1000, self.update_time_display)
def video_to_audio(self, video_path: str, audio_path: str) -> bool:
"""音視頻轉音頻,帶進度更新"""
try:
with VideoFileClip(video_path) as video:
total_duration = video.duration
audio = video.audio
# 記錄音頻轉換開始時間
self.audio_start_time = datetime.now()
# 寫入音頻
audio.write_audiofile(audio_path, logger=None)
# 強制進度到100%
self.update_audio_progress(100.0)
return True
except Exception as e:
messagebox.showerror("錯誤", f"音視頻轉音頻失敗:{str(e)}")
return False
def load_whisper_model(self) -> Optional[whisper.Whisper]:
"""加載whisper模型"""
try:
model_name = self.model_var.get()
self.update_transcribe_progress(10)
model = whisper.load_model(model_name, device="cpu")
self.update_transcribe_progress(20)
return model
except Exception as e:
messagebox.showerror("錯誤", f"模型加載失敗:{str(e)}")
return None
def transcribe_audio(self, audio_path: str) -> Optional[dict]:
"""音頻轉字幕,帶進度更新"""
global is_running
self.model = self.load_whisper_model()
if not self.model or not is_running:
return None
try:
# 記錄字幕識別開始時間
self.transcribe_start_time = datetime.now()
# 分段識別模擬進度
self.update_transcribe_progress(30)
result = self.model.transcribe(
audio_path,
language="zh",
temperature=self.temp_var.get(),
)
self.update_transcribe_progress(80)
if not is_running:
return None
self.update_transcribe_progress(100)
return result
except Exception as e:
messagebox.showerror("錯誤", f"字幕識別失敗:{str(e)}")
return None
def format_srt(self, result: dict) -> str:
"""將識別結果格式化為SRT字幕格式"""
srt_content = ""
for i, segment in enumerate(result["segments"], 1):
start = self.format_time(segment["start"])
end = self.format_time(segment["end"])
text = self.cc.convert(segment["text"].strip())
srt_content += f"{i}\n{start} --> {end}\n{text}\n\n"
return srt_content
@staticmethod
def format_time(seconds: float) -> str:
"""將秒數格式化為SRT時間格式(hh:mm:ss,fff)"""
hours = math.floor(seconds / 3600)
minutes = math.floor((seconds % 3600) / 60)
secs = math.floor(seconds % 60)
millis = math.floor((seconds % 1) * 1000)
return f"{hours:02d}:{minutes:02d}:{secs:02d},{millis:03d}"
def save_subtitle(self, srt_content: str, input_path: str):
"""保存字幕文件"""
save_path = os.path.splitext(input_path)[0] + ".srt"
try:
with open(save_path, "w", encoding="utf-8") as f:
f.write(srt_content)
messagebox.showinfo("成功", f"字幕已保存至:\n{save_path}")
return save_path
except Exception as e:
messagebox.showerror("錯誤", f"字幕保存失敗:{str(e)}")
return None
def convert_thread(self):
"""轉換線程(避免UI卡頓)"""
global is_running
is_running = True
self.start_btn.config(state=tk.DISABLED)
self.stop_btn.config(state=tk.NORMAL)
# 重置進度和時間
self.update_audio_progress(0.0)
self.update_transcribe_progress(0.0)
self.result_text.delete(1.0, tk.END)
self.total_start_time = datetime.now()
self.audio_start_time = None
self.transcribe_start_time = None
# 啟動時間更新
self.root.after(0, self.update_time_display)
input_path = self.file_path_var.get()
if not os.path.exists(input_path):
messagebox.showwarning("警告", "請選擇有效的音視頻文件!")
self.reset_ui()
return
# 臨時音頻文件路徑
temp_audio = "temp_audio.wav"
try:
# 步驟1:音視頻轉音頻
if not is_running:
return
if input_path.lower().endswith(("mp3", "wav", "m4a")):
# 已是音頻文件,跳過轉換
self.update_audio_progress(100.0)
audio_path = input_path
self.audio_start_time = datetime.now() # 標記音頻處理完成時間
else:
if not self.video_to_audio(input_path, temp_audio):
return
audio_path = temp_audio
# 步驟2:音頻轉字幕
if not is_running:
return
result = self.transcribe_audio(audio_path)
if not result or not is_running:
return
# 步驟3:格式化並顯示結果
srt_content = self.format_srt(result)
self.result_text.insert(1.0, srt_content)
# 步驟4:保存字幕
self.save_subtitle(srt_content, input_path)
finally:
# 清理臨時文件
if os.path.exists(temp_audio) and not input_path.lower().endswith(("mp3", "wav", "m4a")):
os.remove(temp_audio)
self.reset_ui()
def start_convert(self):
"""啟動轉換線程"""
thread = threading.Thread(target=self.convert_thread, daemon=True)
thread.start()
def stop_convert(self):
"""停止轉換"""
global is_running
is_running = False
self.stop_btn.config(state=tk.DISABLED)
self.result_text.insert(tk.END, "\n\n轉換已停止!")
def reset_ui(self):
"""重置UI狀態"""
global is_running
is_running = False
self.start_btn.config(state=tk.NORMAL)
self.stop_btn.config(state=tk.DISABLED)
# 停止時間更新
if self.time_update_id:
self.root.after_cancel(self.time_update_id)
self.time_update_id = None
# 重置時間顯示
self.elapsed_time_var.set("已處理時間: 00:00:00")
self.estimated_time_var.set("預計剩餘時間: --:--:--")
if __name__ == "__main__":
# 提示安裝依賴
try:
import torch
import opencc
except ImportError as e:
missing = str(e).split("'")[1]
messagebox.showwarning("提示", f"請先安裝依賴庫:\npip install torch moviepy openai-whisper ffmpeg-python opencc-python-reimplemented")
exit()
root = tk.Tk()
app = AudioVideoToSubtitle(root)
root.mainloop()
四、效果演示
- 工具啟動:運行程序後顯示主界面,包含文件選擇、參數配置、進度顯示和結果預覽區域。
- 文件選擇:點擊”選擇文件”按鈕,選擇需要轉換的音視頻文件(如MP4格式視頻)。
- 參數配置:
- 模型選擇:根據需求選擇(tiny最快,large最精準)
- 線程數:根據CPU核心數調整(建議4-8)
- 溫度值:默認0.0(適合字幕生成)
- 開始轉換:
- 點擊”開始轉換”,音頻提取進度條開始推進
- 提取完成後,字幕識別進度條啟動
- 實時顯示”已處理時間”和”預計剩餘時間”
- 結果查看:
- 識別完成後,結果預覽區顯示SRT格式字幕
- 自動保存與原文件同名的SRT文件(如”視頻.mp4”生成”視頻.srt”)
- 彈窗提示保存路徑
- 中途停止:如需中斷,點擊”停止轉換”按鈕,工具會清理臨時文件並重置狀態。
五、第三方庫安裝
1、需要的庫
該音視頻轉字幕工具的代碼依賴以下第三方庫,以下是各庫的作用及安裝方法:
torch(PyTorch)
- 作用:Whisper模型運行的基礎框架,用於加載和運行語音識別模型(Whisper基於PyTorch實現)。
- 安裝命令:
推薦根據系統和是否需要GPU加速,從PyTorch官網獲取對應命令,基礎CPU版本可直接安裝:pip install torch
moviepy
- 作用:音視頻處理庫,用於從視頻中提取音頻軌道(核心功能之一)。
- 安裝命令:
pip install moviepy
openai-whisper
- 作用:OpenAI官方的語音識別庫,提供Whisper模型(實現語音轉文字的核心功能)。
- 安裝命令:
pip install openai-whisper
ffmpeg-python
- 作用:
moviepy處理音視頻時依賴的底層工具封裝,用於實際執行音視頻編解碼操作。 - 注意:除了安裝Python庫,還需要在系統中安裝
ffmpeg程序(否則moviepy可能無法正常工作):- Python庫安裝:
pip install ffmpeg-python - 系統級
ffmpeg安裝:- Windows:從ffmpeg官網下載安裝包,解壓後將
bin目錄添加到系統環境變量。 - Ubuntu/Debian:
sudo apt-get install ffmpeg - macOS:
brew install ffmpeg(需先安裝Homebrew)
- Windows:從ffmpeg官網下載安裝包,解壓後將
- Python庫安裝:
opencc-python-reimplemented
- 作用:繁簡轉換庫,用於將識別結果中的繁體中文自動轉換為簡體中文(代碼中通過
OpenCC('t2s')實現)。 - 安裝命令:
pip install opencc-python-reimplemented
2、一條命令安裝所有依賴
可將上述命令整合為一條安裝命令(推薦使用國內鏡像源如-i https://pypi.tuna.tsinghua.edu.cn/simple加速):
pip install torch moviepy openai-whisper ffmpeg-python opencc-python-reimplemented -i https://pypi.tuna.tsinghua.edu.cn/simple
3、注意事項
- 首次運行時,Whisper會自動下載選擇的模型(如
base模型約1GB),請確保網絡暢通。 - 若電腦有NVIDIA顯卡且安裝了CUDA,可將代碼中
device="cpu"改為device="cuda",顯著提升識別速度(需安裝對應CUDA版本的PyTorch)。
總結
這款音視頻轉字幕工具通過整合moviepy和whisper的強大功能,實現了文字識別和字幕生成的自動化流程。核心優勢在於:
- 易用性:可視化界面降低了技術門檻,無需命令行操作
- 靈活性:可通過模型選擇平衡速度與精度
- 實用性:生成標準SRT格式,直接適配主流視頻編輯軟件
無論是自媒體創作者快速製作字幕,還是學習者為教學視頻添加字幕,這款工具都能顯著提升效率,降低字幕製作的技術門檻。
DIY Audio/Video-to-Subtitle Tool with Whisper—No Paid Software
Open-source GUI tool: extract audio with moviepy, transcribe with Whisper (Chinese), emit SRT with OpenCC simplification—dual progress bars, ETA, full code and install guide.
Captured at (local ISO): 2026-05-18 05:17:06
Preface
Subtitles improve accessibility and reach for video and audio. Manual captioning is slow for creators, teachers, and everyday users. This audio/video-to-subtitle tool uses OpenAI Whisper to produce standard SRT files automatically.
It combines moviepy (extract audio), whisper (speech-to-text), and tkinter (GUI) so non-experts can generate subtitles quickly. Below: design and usage.
Open source: https://github.com/ChenAI-TGF/Audio_And_Video_Transcription
I. Tool overview
- Formats: MP4, AVI, MOV, MP3, WAV, etc.
- Parameters: Whisper size (tiny→large), thread count, temperature.
- Progress: Separate bars for audio extract and transcription.
- ETA: Elapsed and estimated remaining time.
- Chinese: OpenCC traditional→simplified on output.
- SRT: Ready for editors like Premiere/DaVinci.
GUI lowers the barrier; parameters stay exposed for power users.
II. Core code walkthrough
1. Audio extraction
音视频文件首先需要提取音频轨道,这一步由video_to_audio方法实现:
def video_to_audio(self, video_path: str, audio_path: str) -> bool:
try:
with VideoFileClip(video_path) as video:
total_duration = video.duration
audio = video.audio
# 记录音频转换开始时间
self.audio_start_time = datetime.now()
# 写入音频(logger=None关闭冗余输出)
audio.write_audiofile(audio_path, logger=None)
# 强制进度到100%
self.update_audio_progress(100.0)
return True
except Exception as e:
messagebox.showerror("错误", f"音视频转音频失败:{str(e)}")
return False
Core logic:使用moviepy的VideoFileClip读取视频文件,提取音频轨道后写入WAV格式文件。对于本身就是音频的文件(如MP3),会直接跳过提取步骤
2. Whisper load & transcribe
语音转文字是工具的核心功能,基于OpenAI的Whisper模型实现:
def load_whisper_model(self) -> Optional[whisper.Whisper]:
try:
model_name = self.model_var.get()
self.update_transcribe_progress(10)
# 加载指定模型,使用CPU运行(可改为"cuda"启用GPU加速)
model = whisper.load_model(model_name, device="cpu")
self.update_transcribe_progress(20)
return model
except Exception as e:
messagebox.showerror("错误", f"模型加载失败:{str(e)}")
return None
def transcribe_audio(self, audio_path: str) -> Optional[dict]:
global is_running
self.model = self.load_whisper_model()
if not self.model or not is_running:
return None
try:
# 记录字幕识别开始时间
self.transcribe_start_time = datetime.now()
# 分段识别模拟进度
self.update_transcribe_progress(30)
result = self.model.transcribe(
audio_path,
language="zh", # 指定中文识别
temperature=self.temp_var.get(), # 控制输出随机性
)
self.update_transcribe_progress(80)
if not is_running:
return None
self.update_transcribe_progress(100)
return result
except Exception as e:
messagebox.showerror("错误", f"字幕识别失败:{str(e)}")
return None
Core logic:
- 先加载用户选择的Whisper模型(模型越小速度越快,精度越低)
- 通过
transcribe方法处理音频,指定language="zh"优化中文识别效果 temperature参数控制输出随机性(0表示确定性输出,适合字幕生成)
3. SRT formatting
识别结果需要转换为标准SRT格式,包含序号、时间轴和文本:
def format_srt(self, result: dict) -> str:
srt_content = ""
for i, segment in enumerate(result["segments"], 1):
start = self.format_time(segment["start"])
end = self.format_time(segment["end"])
# 繁简转换(将可能的繁体转为简体)
text = self.cc.convert(segment["text"].strip())
srt_content += f"{i}\n{start} --> {end}\n{text}\n\n"
return srt_content
@staticmethod
def format_time(seconds: float) -> str:
"""将秒数格式化为SRT时间格式(hh:mm:ss,fff)"""
hours = math.floor(seconds / 3600)
minutes = math.floor((seconds % 3600) / 60)
secs = math.floor(seconds % 60)
millis = math.floor((seconds % 1) * 1000)
return f"{hours:02d}:{minutes:02d}:{secs:02d},{millis:03d}"
Core logic:
- 解析Whisper返回的分段结果(包含开始时间、结束时间和文本)
- 将时间戳转换为SRT要求的
hh:mm:ss,fff格式 - 使用
OpenCC进行繁简转换,确保输出统一为简体中文
4. Threading & progress
为避免UI卡顿,核心处理逻辑在独立线程中运行:
def start_convert(self):
"""启动转换线程"""
thread = threading.Thread(target=self.convert_thread, daemon=True)
thread.start()
def convert_thread(self):
"""转换线程(避免UI卡顿)"""
global is_running
is_running = True
self.start_btn.config(state=tk.DISABLED)
self.stop_btn.config(state=tk.NORMAL)
# 重置进度和时间
self.update_audio_progress(0.0)
self.update_transcribe_progress(0.0)
self.result_text.delete(1.0, tk.END)
self.total_start_time = datetime.now()
# 核心处理流程
input_path = self.file_path_var.get()
# 音频提取 -> 语音识别 -> 字幕格式化 -> 保存文件
# ...(省略具体步骤)
Core logic:
- 将耗时的音频处理和识别任务放入子线程
- 通过全局变量
is_running实现主线程与子线程的通信 - 实时更新进度条和时间显示,提升用户体验
III. Full code
import tkinter as tk
from tkinter import ttk, filedialog, messagebox
import os
from moviepy import VideoFileClip
import whisper
import threading
import time
from datetime import datetime, timedelta
from typing import Optional
import math
from opencc import OpenCC
# 全局变量用于控制进度和线程
audio_convert_progress = 0.0
transcribe_progress = 0.0
is_running = False
class AudioVideoToSubtitle:
def __init__(self, root):
self.root = root
self.root.title("音视频转字幕工具")
self.root.geometry("900x650") # 扩大窗口以容纳时间显示
# 初始化繁简转换器
self.cc = OpenCC('t2s')
# 时间跟踪变量
self.total_start_time = None # 总处理开始时间
self.audio_start_time = None # 音频转换开始时间
self.transcribe_start_time = None # 字幕识别开始时间
self.time_update_id = None # 时间更新定时器ID
# 初始化模型
self.model = None
self.model_path = None
self.init_ui()
def init_ui(self):
# 1. 文件选择区域
file_frame = ttk.LabelFrame(self.root, text="文件设置")
file_frame.pack(fill=tk.X, padx=10, pady=5)
self.file_path_var = tk.StringVar()
ttk.Entry(file_frame, textvariable=self.file_path_var, width=70).pack(side=tk.LEFT, padx=5, pady=5)
ttk.Button(file_frame, text="选择文件", command=self.select_file).pack(side=tk.LEFT, padx=5, pady=5)
# 2. 速度调节参数区域
param_frame = ttk.LabelFrame(self.root, text="速度调节参数")
param_frame.pack(fill=tk.X, padx=10, pady=5)
ttk.Label(param_frame, text="模型选择:").pack(side=tk.LEFT, padx=5, pady=5)
self.model_var = tk.StringVar(value="base")
model_options = ["tiny", "base", "small", "medium", "large"]
ttk.Combobox(param_frame, textvariable=self.model_var, values=model_options, width=10).pack(side=tk.LEFT, padx=5, pady=5)
ttk.Label(param_frame, text="线程数:").pack(side=tk.LEFT, padx=5, pady=5)
self.thread_var = tk.IntVar(value=4)
ttk.Spinbox(param_frame, from_=1, to=16, textvariable=self.thread_var, width=5).pack(side=tk.LEFT, padx=5, pady=5)
ttk.Label(param_frame, text="温度值:").pack(side=tk.LEFT, padx=5, pady=5)
self.temp_var = tk.DoubleVar(value=0.0)
ttk.Spinbox(param_frame, from_=0.0, to=1.0, increment=0.1, textvariable=self.temp_var, width=5).pack(side=tk.LEFT, padx=5, pady=5)
# 3. 进度条和时间显示区域
progress_frame = ttk.LabelFrame(self.root, text="处理进度与时间")
progress_frame.pack(fill=tk.X, padx=10, pady=5)
# 音视频转音频进度条
ttk.Label(progress_frame, text="音视频转音频:").pack(side=tk.LEFT, padx=5)
self.audio_progress = ttk.Progressbar(progress_frame, orient=tk.HORIZONTAL, length=300, mode='determinate')
self.audio_progress.pack(side=tk.LEFT, padx=5, pady=5)
self.audio_progress_label = ttk.Label(progress_frame, text="0%")
self.audio_progress_label.pack(side=tk.LEFT, padx=5)
# 字幕识别进度条
ttk.Label(progress_frame, text="字幕识别:").pack(side=tk.LEFT, padx=5)
self.transcribe_progress = ttk.Progressbar(progress_frame, orient=tk.HORIZONTAL, length=300, mode='determinate')
self.transcribe_progress.pack(side=tk.LEFT, padx=5, pady=5)
self.transcribe_progress_label = ttk.Label(progress_frame, text="0%")
self.transcribe_progress_label.pack(side=tk.LEFT, padx=5)
# 时间显示区域
time_frame = ttk.LabelFrame(self.root, text="时间信息")
time_frame.pack(fill=tk.X, padx=10, pady=5)
self.elapsed_time_var = tk.StringVar(value="已处理时间: 00:00:00")
ttk.Label(time_frame, textvariable=self.elapsed_time_var).pack(side=tk.LEFT, padx=20, pady=5)
self.estimated_time_var = tk.StringVar(value="预计剩余时间: --:--:--")
ttk.Label(time_frame, textvariable=self.estimated_time_var).pack(side=tk.LEFT, padx=20, pady=5)
# 4. 控制按钮区域
btn_frame = ttk.Frame(self.root)
btn_frame.pack(pady=10)
self.start_btn = ttk.Button(btn_frame, text="开始转换", command=self.start_convert)
self.start_btn.pack(side=tk.LEFT, padx=10)
self.stop_btn = ttk.Button(btn_frame, text="停止转换", command=self.stop_convert, state=tk.DISABLED)
self.stop_btn.pack(side=tk.LEFT, padx=10)
# 5. 结果显示区域
result_frame = ttk.LabelFrame(self.root, text="识别结果预览")
result_frame.pack(fill=tk.BOTH, expand=True, padx=10, pady=5)
self.result_text = tk.Text(result_frame, height=15)
scrollbar = ttk.Scrollbar(result_frame, command=self.result_text.yview)
self.result_text.configure(yscrollcommand=scrollbar.set)
self.result_text.pack(side=tk.LEFT, fill=tk.BOTH, expand=True, padx=5, pady=5)
scrollbar.pack(side=tk.RIGHT, fill=tk.Y, padx=5, pady=5)
def select_file(self):
"""选择音视频文件"""
file_types = [
("音视频文件", "*.mp4 *.avi *.mov *.mkv *.flv *.mp3 *.wav *.m4a"),
("所有文件", "*.*")
]
file_path = filedialog.askopenfilename(filetypes=file_types)
if file_path:
self.file_path_var.set(file_path)
def update_audio_progress(self, value: float):
"""更新音频转换进度条"""
global audio_convert_progress
audio_convert_progress = min(value, 100.0)
self.audio_progress["value"] = audio_convert_progress
self.audio_progress_label.config(text=f"{int(audio_convert_progress)}%")
self.root.update_idletasks()
def update_transcribe_progress(self, value: float):
"""更新字幕识别进度条"""
global transcribe_progress
transcribe_progress = min(value, 100.0)
self.transcribe_progress["value"] = transcribe_progress
self.transcribe_progress_label.config(text=f"{int(transcribe_progress)}%")
self.root.update_idletasks()
def format_time_display(self, seconds: float) -> str:
"""将秒数格式化为时分秒显示"""
hours, remainder = divmod(int(seconds), 3600)
minutes, seconds = divmod(remainder, 60)
return f"{hours:02d}:{minutes:02d}:{seconds:02d}"
def update_time_display(self):
"""更新时间显示信息"""
if not is_running or not self.total_start_time:
return
# 计算已处理时间
elapsed_seconds = (datetime.now() - self.total_start_time).total_seconds()
self.elapsed_time_var.set(f"已处理时间: {self.format_time_display(elapsed_seconds)}")
# 计算预计剩余时间
try:
if audio_convert_progress < 100:
# 音频转换阶段
if self.audio_start_time and audio_convert_progress > 0:
audio_elapsed = (datetime.now() - self.audio_start_time).total_seconds()
total_audio_estimated = audio_elapsed / (audio_convert_progress / 100)
audio_remaining = total_audio_estimated - audio_elapsed
# 假设转录时间与音频时间相当(简单估算)
total_estimated = total_audio_estimated * 2
remaining = total_estimated - elapsed_seconds
self.estimated_time_var.set(f"预计剩余时间: {self.format_time_display(remaining)}")
else:
# 字幕识别阶段
if self.transcribe_start_time and transcribe_progress > 0 and transcribe_progress < 100:
transcribe_elapsed = (datetime.now() - self.transcribe_start_time).total_seconds()
total_transcribe_estimated = transcribe_elapsed / (transcribe_progress / 100)
transcribe_remaining = total_transcribe_estimated - transcribe_elapsed
self.estimated_time_var.set(f"预计剩余时间: {self.format_time_display(transcribe_remaining)}")
elif transcribe_progress >= 100:
self.estimated_time_var.set(f"预计剩余时间: 00:00:00")
except (ZeroDivisionError, Exception):
self.estimated_time_var.set(f"预计剩余时间: 计算中...")
# 继续定时更新
self.time_update_id = self.root.after(1000, self.update_time_display)
def video_to_audio(self, video_path: str, audio_path: str) -> bool:
"""音视频转音频,带进度更新"""
try:
with VideoFileClip(video_path) as video:
total_duration = video.duration
audio = video.audio
# 记录音频转换开始时间
self.audio_start_time = datetime.now()
# 写入音频
audio.write_audiofile(audio_path, logger=None)
# 强制进度到100%
self.update_audio_progress(100.0)
return True
except Exception as e:
messagebox.showerror("错误", f"音视频转音频失败:{str(e)}")
return False
def load_whisper_model(self) -> Optional[whisper.Whisper]:
"""加载whisper模型"""
try:
model_name = self.model_var.get()
self.update_transcribe_progress(10)
model = whisper.load_model(model_name, device="cpu")
self.update_transcribe_progress(20)
return model
except Exception as e:
messagebox.showerror("错误", f"模型加载失败:{str(e)}")
return None
def transcribe_audio(self, audio_path: str) -> Optional[dict]:
"""音频转字幕,带进度更新"""
global is_running
self.model = self.load_whisper_model()
if not self.model or not is_running:
return None
try:
# 记录字幕识别开始时间
self.transcribe_start_time = datetime.now()
# 分段识别模拟进度
self.update_transcribe_progress(30)
result = self.model.transcribe(
audio_path,
language="zh",
temperature=self.temp_var.get(),
)
self.update_transcribe_progress(80)
if not is_running:
return None
self.update_transcribe_progress(100)
return result
except Exception as e:
messagebox.showerror("错误", f"字幕识别失败:{str(e)}")
return None
def format_srt(self, result: dict) -> str:
"""将识别结果格式化为SRT字幕格式"""
srt_content = ""
for i, segment in enumerate(result["segments"], 1):
start = self.format_time(segment["start"])
end = self.format_time(segment["end"])
text = self.cc.convert(segment["text"].strip())
srt_content += f"{i}\n{start} --> {end}\n{text}\n\n"
return srt_content
@staticmethod
def format_time(seconds: float) -> str:
"""将秒数格式化为SRT时间格式(hh:mm:ss,fff)"""
hours = math.floor(seconds / 3600)
minutes = math.floor((seconds % 3600) / 60)
secs = math.floor(seconds % 60)
millis = math.floor((seconds % 1) * 1000)
return f"{hours:02d}:{minutes:02d}:{secs:02d},{millis:03d}"
def save_subtitle(self, srt_content: str, input_path: str):
"""保存字幕文件"""
save_path = os.path.splitext(input_path)[0] + ".srt"
try:
with open(save_path, "w", encoding="utf-8") as f:
f.write(srt_content)
messagebox.showinfo("成功", f"字幕已保存至:\n{save_path}")
return save_path
except Exception as e:
messagebox.showerror("错误", f"字幕保存失败:{str(e)}")
return None
def convert_thread(self):
"""转换线程(避免UI卡顿)"""
global is_running
is_running = True
self.start_btn.config(state=tk.DISABLED)
self.stop_btn.config(state=tk.NORMAL)
# 重置进度和时间
self.update_audio_progress(0.0)
self.update_transcribe_progress(0.0)
self.result_text.delete(1.0, tk.END)
self.total_start_time = datetime.now()
self.audio_start_time = None
self.transcribe_start_time = None
# 启动时间更新
self.root.after(0, self.update_time_display)
input_path = self.file_path_var.get()
if not os.path.exists(input_path):
messagebox.showwarning("警告", "请选择有效的音视频文件!")
self.reset_ui()
return
# 临时音频文件路径
temp_audio = "temp_audio.wav"
try:
# 步骤1:音视频转音频
if not is_running:
return
if input_path.lower().endswith(("mp3", "wav", "m4a")):
# 已是音频文件,跳过转换
self.update_audio_progress(100.0)
audio_path = input_path
self.audio_start_time = datetime.now() # 标记音频处理完成时间
else:
if not self.video_to_audio(input_path, temp_audio):
return
audio_path = temp_audio
# 步骤2:音频转字幕
if not is_running:
return
result = self.transcribe_audio(audio_path)
if not result or not is_running:
return
# 步骤3:格式化并显示结果
srt_content = self.format_srt(result)
self.result_text.insert(1.0, srt_content)
# 步骤4:保存字幕
self.save_subtitle(srt_content, input_path)
finally:
# 清理临时文件
if os.path.exists(temp_audio) and not input_path.lower().endswith(("mp3", "wav", "m4a")):
os.remove(temp_audio)
self.reset_ui()
def start_convert(self):
"""启动转换线程"""
thread = threading.Thread(target=self.convert_thread, daemon=True)
thread.start()
def stop_convert(self):
"""停止转换"""
global is_running
is_running = False
self.stop_btn.config(state=tk.DISABLED)
self.result_text.insert(tk.END, "\n\n转换已停止!")
def reset_ui(self):
"""重置UI状态"""
global is_running
is_running = False
self.start_btn.config(state=tk.NORMAL)
self.stop_btn.config(state=tk.DISABLED)
# 停止时间更新
if self.time_update_id:
self.root.after_cancel(self.time_update_id)
self.time_update_id = None
# 重置时间显示
self.elapsed_time_var.set("已处理时间: 00:00:00")
self.estimated_time_var.set("预计剩余时间: --:--:--")
if __name__ == "__main__":
# 提示安装依赖
try:
import torch
import opencc
except ImportError as e:
missing = str(e).split("'")[1]
messagebox.showwarning("提示", f"请先安装依赖库:\npip install torch moviepy openai-whisper ffmpeg-python opencc-python-reimplemented")
exit()
root = tk.Tk()
app = AudioVideoToSubtitle(root)
root.mainloop()
IV. Demo
- 工具启动:运行程序后显示主界面,包含文件选择、参数配置、进度显示和结果预览区域。
- 文件选择:点击”选择文件”按钮,选择需要转换的音视频文件(如MP4格式视频)。
- 参数配置:
- 模型选择:根据需求选择(tiny最快,large最精准)
- 线程数:根据CPU核心数调整(建议4-8)
- 温度值:默认0.0(适合字幕生成)
- 开始转换:
- 点击”开始转换”,音频提取进度条开始推进
- 提取完成后,字幕识别进度条启动
- 实时显示”已处理时间”和”预计剩余时间”
- 结果查看:
- 识别完成后,结果预览区显示SRT格式字幕
- 自动保存与原文件同名的SRT文件(如”视频.mp4”生成”视频.srt”)
- 弹窗提示保存路径
- 中途停止:如需中断,点击”停止转换”按钮,工具会清理临时文件并重置状态。
V. Dependencies
1、需要的库
该音视频转字幕工具的代码依赖以下第三方库,以下是各库的作用及安装方法:
torch(PyTorch)
- 作用:Whisper模型运行的基础框架,用于加载和运行语音识别模型(Whisper基于PyTorch实现)。
- 安装命令:
推荐根据系统和是否需要GPU加速,从PyTorch官网获取对应命令,基础CPU版本可直接安装:pip install torch
moviepy
- 作用:音视频处理库,用于从视频中提取音频轨道(核心功能之一)。
- 安装命令:
pip install moviepy
openai-whisper
- 作用:OpenAI官方的语音识别库,提供Whisper模型(实现语音转文字的核心功能)。
- 安装命令:
pip install openai-whisper
ffmpeg-python
- 作用:
moviepy处理音视频时依赖的底层工具封装,用于实际执行音视频编解码操作。 - 注意:除了安装Python库,还需要在系统中安装
ffmpeg程序(否则moviepy可能无法正常工作):- Python库安装:
pip install ffmpeg-python - 系统级
ffmpeg安装:- Windows:从ffmpeg官网下载安装包,解压后将
bin目录添加到系统环境变量。 - Ubuntu/Debian:
sudo apt-get install ffmpeg - macOS:
brew install ffmpeg(需先安装Homebrew)
- Windows:从ffmpeg官网下载安装包,解压后将
- Python库安装:
opencc-python-reimplemented
- 作用:繁简转换库,用于将识别结果中的繁体中文自动转换为简体中文(代码中通过
OpenCC('t2s')实现)。 - 安装命令:
pip install opencc-python-reimplemented
2、一条命令安装所有依赖
可将上述命令整合为一条安装命令(推荐使用国内镜像源如-i https://pypi.tuna.tsinghua.edu.cn/simple加速):
pip install torch moviepy openai-whisper ffmpeg-python opencc-python-reimplemented -i https://pypi.tuna.tsinghua.edu.cn/simple
3、注意事项
- 首次运行时,Whisper会自动下载选择的模型(如
base模型约1GB),请确保网络畅通。 - 若电脑有NVIDIA显卡且安装了CUDA,可将代码中
device="cpu"改为device="cuda",显著提升识别速度(需安装对应CUDA版本的PyTorch)。
Summary
这款音视频转字幕工具通过整合moviepy和whisper的强大功能,实现了文字识别和字幕生成的自动化流程。核心优势在于:
- 易用性:可视化界面降低了技术门槛,无需命令行操作
- 灵活性:可通过模型选择平衡速度与精度
- 实用性:生成标准SRT格式,直接适配主流视频编辑软件
无论是自媒体创作者快速制作字幕,还是学习者为教学视频添加字幕,这款工具都能显著提升效率,降低字幕制作的技术门槛。