云端服务器使用指南:Pytorch及显卡驱动、CUDA全流程保姆级下载教程(本地机也适用)
从零安装NVIDIA驱动、CUDA、cudnn到PyTorch/torchvision的保姆级教程,强调版本匹配链(驱动→CUDA→cudnn→Torch),含环境变量与南大镜像源选包方法。
前言
在深度学习领域,PyTorch 凭借灵活的架构和友好的 API 成为众多开发者的首选框架。但 PyTorch 的高效运行依赖显卡驱动、CUDA(英伟达显卡计算平台)和 cudnn(CUDA 加速库)的协同支持 —— 缺少其中任何一环,都可能导致 “显卡认不出”“代码跑在 CPU 上” 等问题。
无论是本地 Windows/Linux 电脑,还是阿里云、腾讯云等云端服务器,环境配置都是入门的第一道坎:驱动版本不兼容会安装失败,CUDA 和 PyTorch 版本不匹配会报 “找不到 CUDA” 错误,cudnn 漏装会让模型训练速度大幅下降。本篇教程从 “零基础” 视角出发,手把手带你完成全流程安装,每步附验证方法,帮你避开 90% 的配置坑。
一、显卡驱动安装(本地 / 云端通用逻辑)
步骤一、查看显卡驱动型号
Windows
右键桌面 → 打开 “NVIDIA 控制面板” → 左侧 “系统信息” → “显示适配器”,记录显卡型号(如 RTX 4090、GTX 1660)。
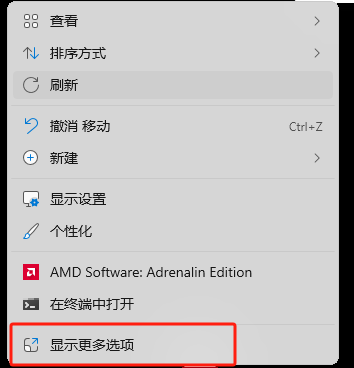
这边因为电脑截屏限制,就直接用手机拍了
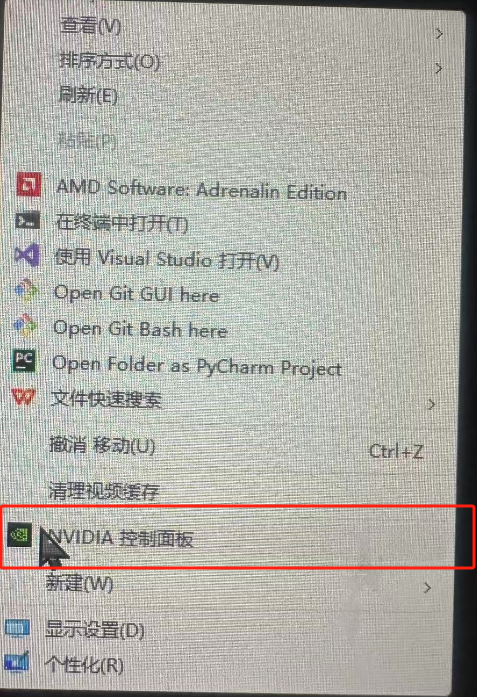
点开之后界面如下:
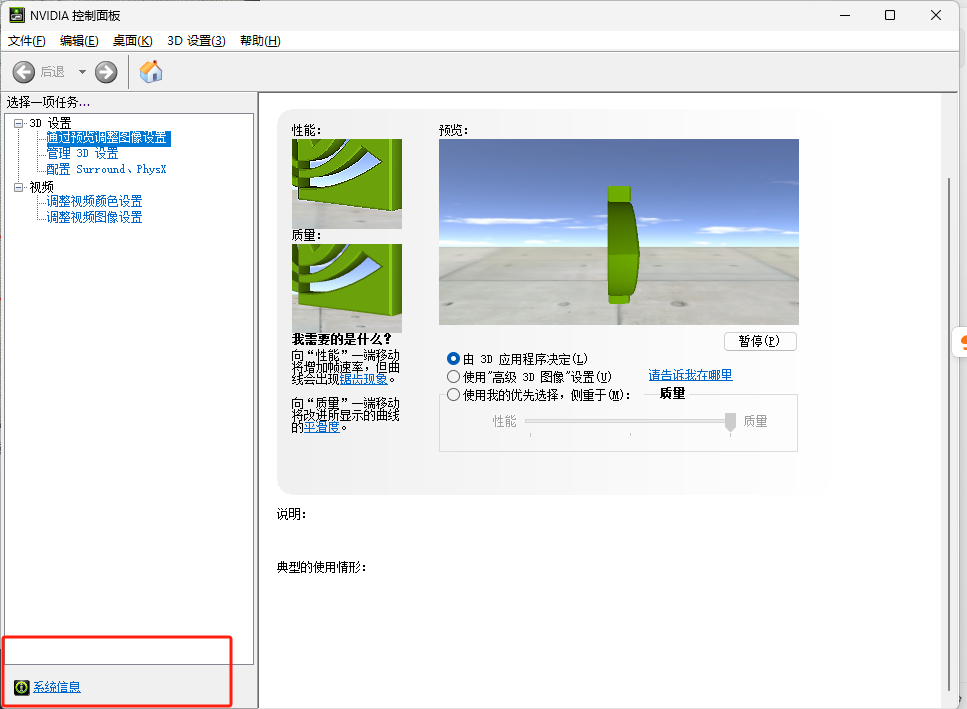
点击左下角的系统信息
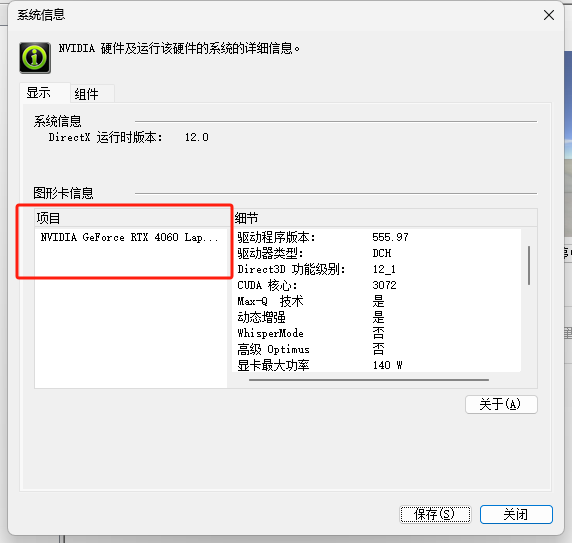
红框选住的地方就是具体的显卡信息
Linux
SSH 连接服务器后,执行命令:
lspci | grep -i nvidia # 输出类似“NVIDIA Corporation GA102 [GeForce RTX 3090]”
若云端服务器未显示显卡,先确认实例是否勾选 “GPU 机型”,如阿里云 “GN6”、腾讯云 “GT4” 系列
步骤二、下载并安装驱动
1、进入官网下载驱动
打开NVIDIA 驱动下载官网(https://www.nvidia.cn/drivers/lookup/)
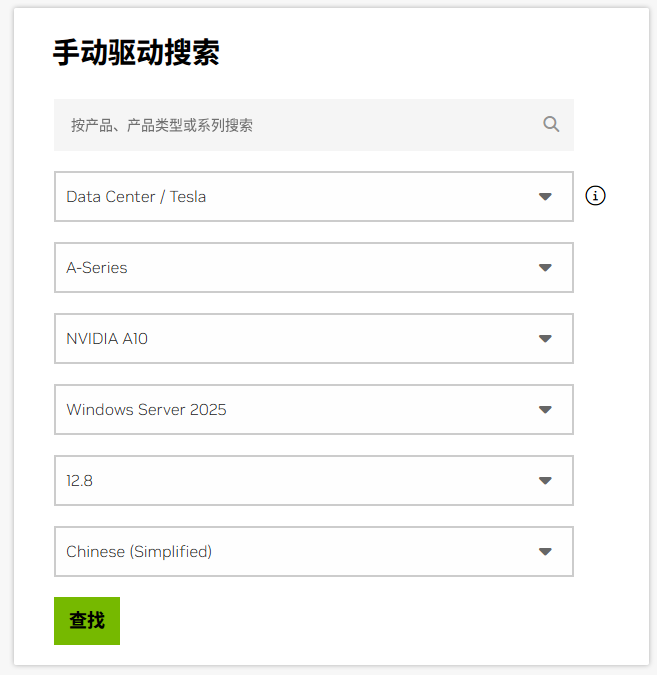
根据自己的显卡型号按以下步骤选择:
我这边用的是 所以是按我的配置选的
“产品类型”: “Data Center / Tesla”(云端服务器显卡);
“产品系列”“产品型号”:Tesla A10
“操作系统”:选 “Windows Server 2025;(这个是在配置服务器的时候自己选择的)
点击 “搜索” → “下载”,得到.exe 安装包。
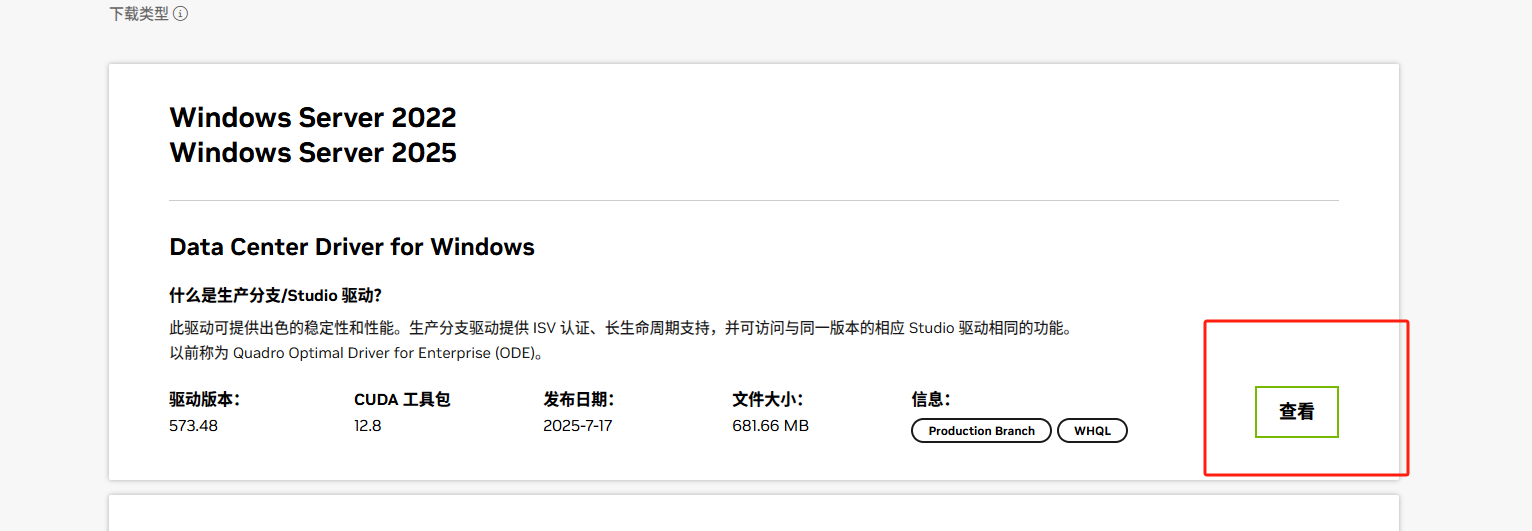
在加载之后的界面中进一步选择查看之后下载既可
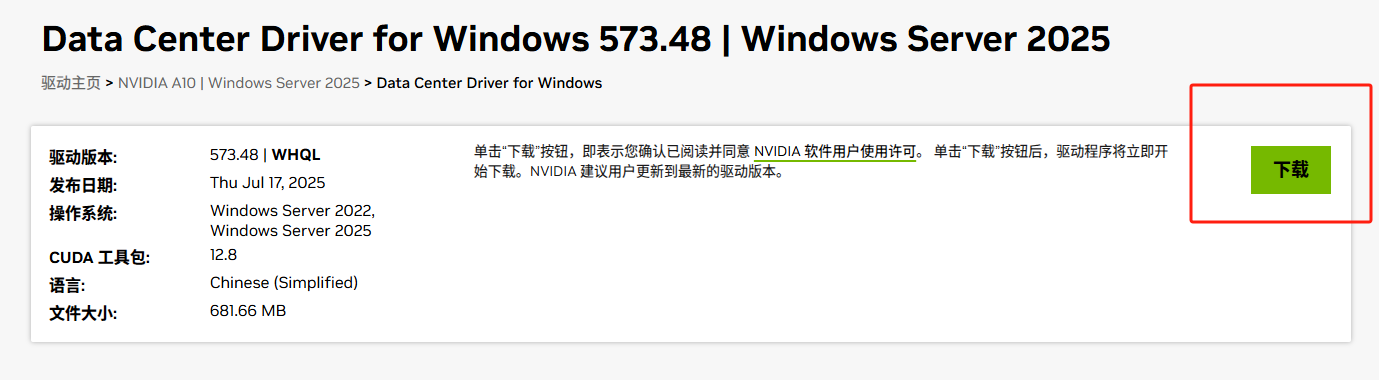
2、安装驱动
1.选择 “精简安装”(新手推荐,避免手动配置);
2.尽量选择默认安装路径
3.若提示 “已有旧驱动”,选 “覆盖安装”;
4.安装完成后重启电脑。
步骤三、验证安装是否成功
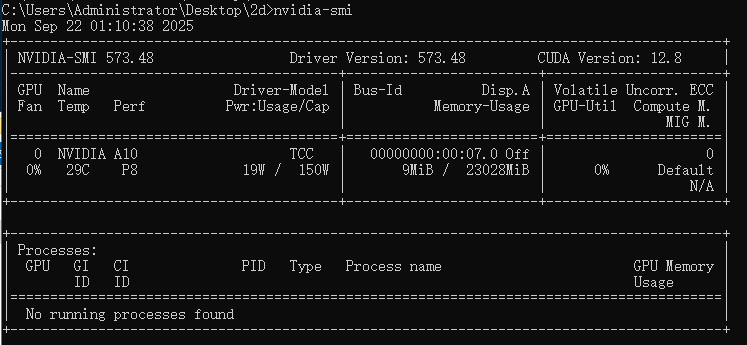
安装完成后,可以按win+r键盘,输入cmd回车,弹出如下所示终端,输入nvidia-smi,若显示如下,则说明驱动已经安装好了。
二、CUDA安装
CUDA 是英伟达提供的 “显卡计算工具包”,PyTorch 通过 CUDA 调用显卡算力。重点:CUDA 版本 ≤ 驱动支持的最高 CUDA 版本(如驱动显示 “CUDA Version: 12.4”,则可装 CUDA 12.4、12.3 等)。
步骤一、查看支持的CUDA版本
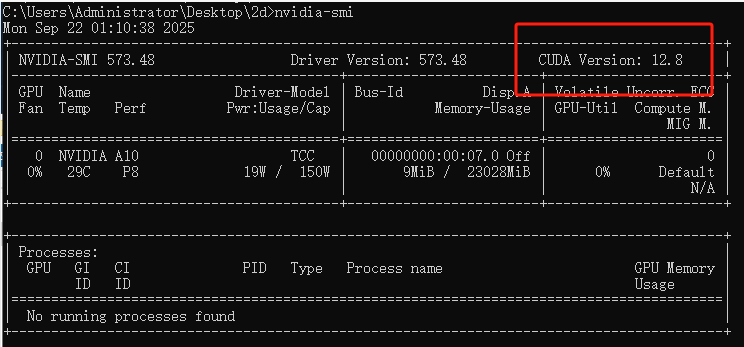
这边的CUDA Version 表示的是支持的CUDA的最高版本,也就是说我们安装的CUDA需要在版本12.8以下
步骤二、下载对应的CUDA版本
进入官网下载对应的CUDA版本(https://developer.nvidia.com/cuda-toolkit-archive)
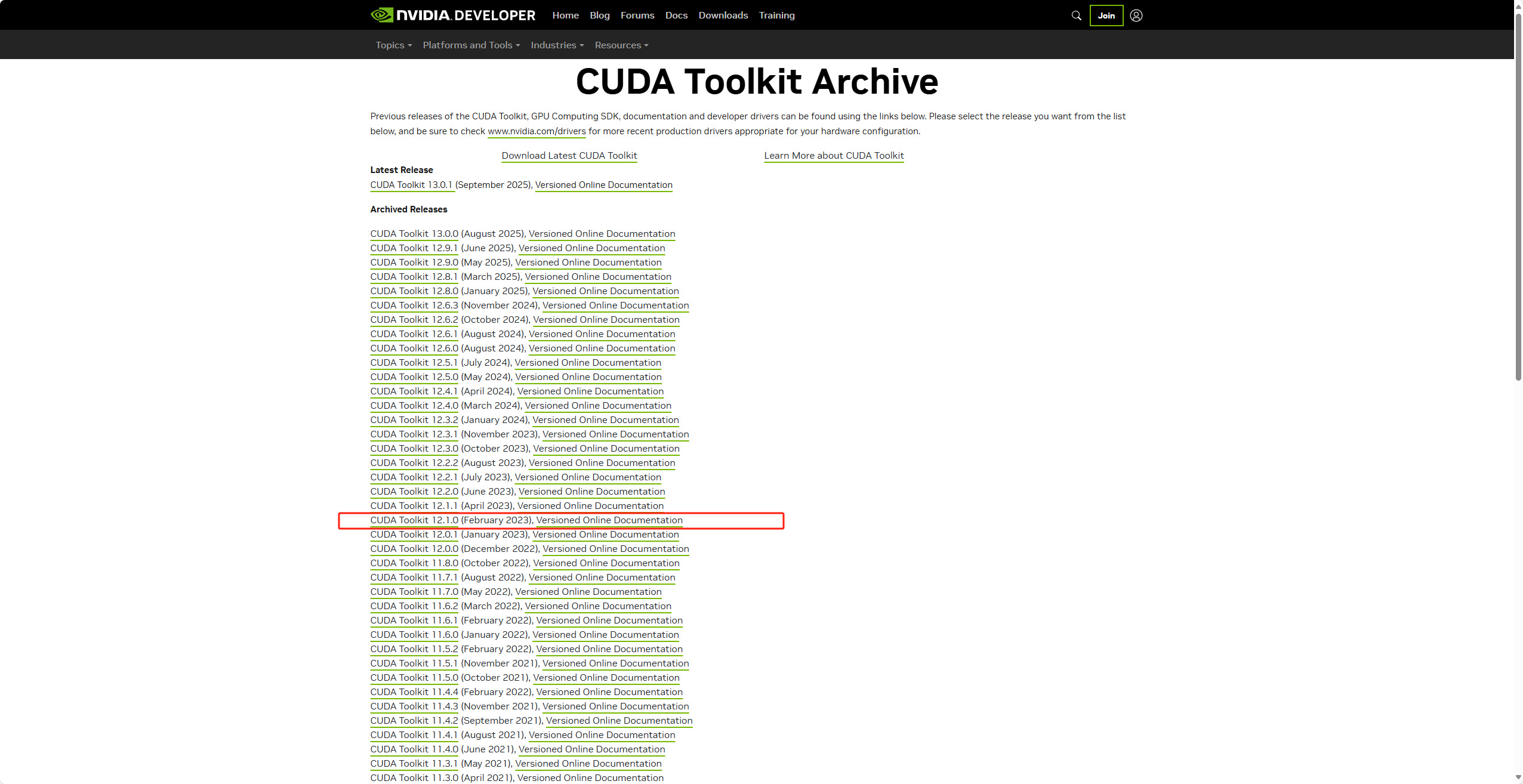
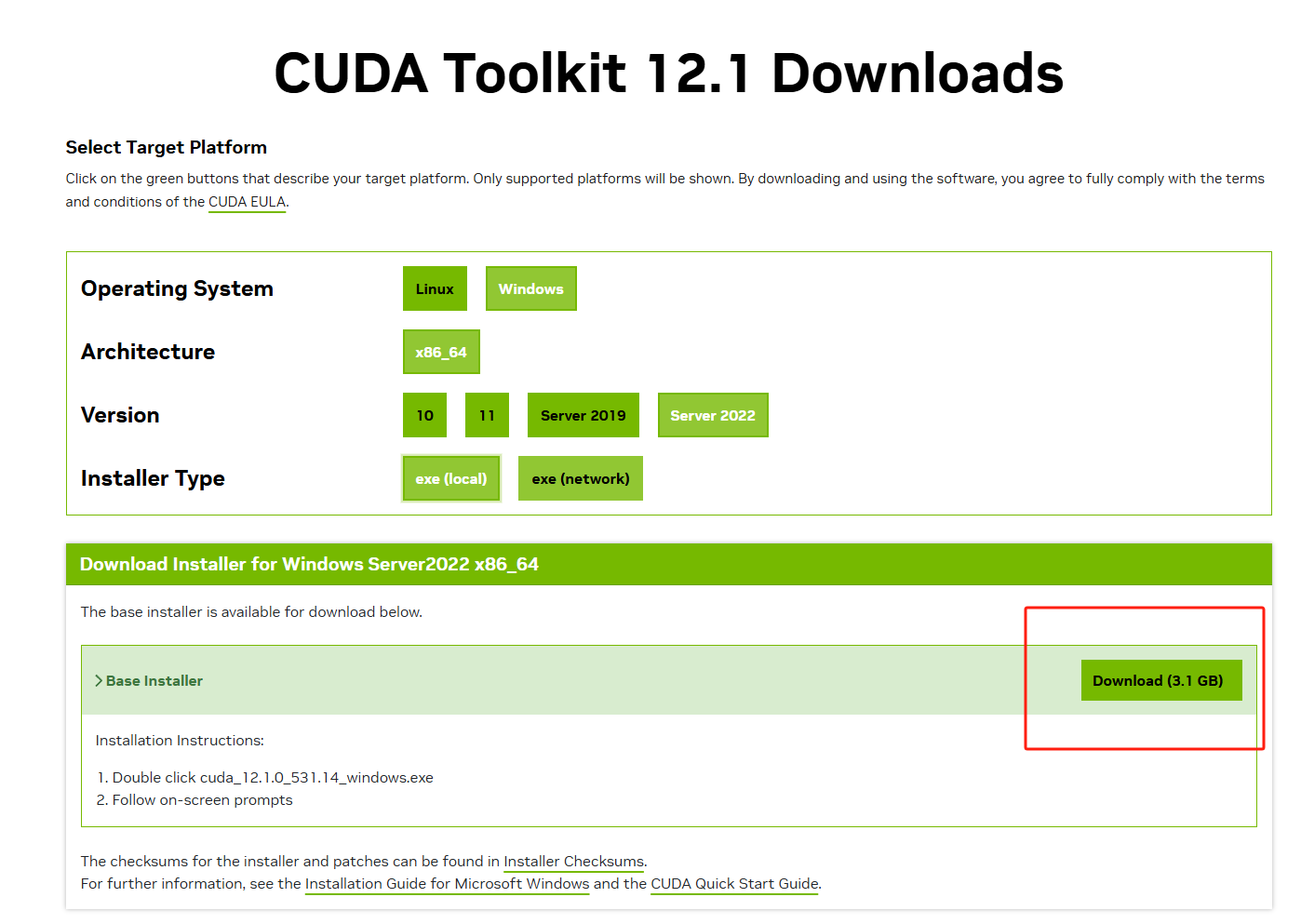
我下载12.1.0版本的cuda,是为了和我本机上的版本保持统一方便配置,同时版本太高的cuda很难找到对应的pytorch
步骤三、安装CUDA
点击下载的可执行文件
一路点击确定安装下去就可以了
步骤四、配置环境变量
在测试是否安装成功之前,我们首先需要配置CUDA的相关环境变量,尽管安装程序会自动帮我们安装一些,但是是不够的
1、首先打开CUDA的安装路径(一般在C盘下的program file里面可以看到CUDA的相关路径)
点开带有toolkit的文件夹,既可以看到CUDA
进入之后依次记录下以下路径(这边我提供的是相对路径,需要自行在文件夹里查找绝对路径并记录)
1、\bin
2、\libs\x64
3、\libnvvp
4、目前打开的该路径
下一步打开“编辑系统环境变量” 直接在Windows的搜索栏里面搜索就可以了
点击框选住的环境变量
这边注意 点击的是下面的系统变量,而非上面的用户变量中的“PATH”
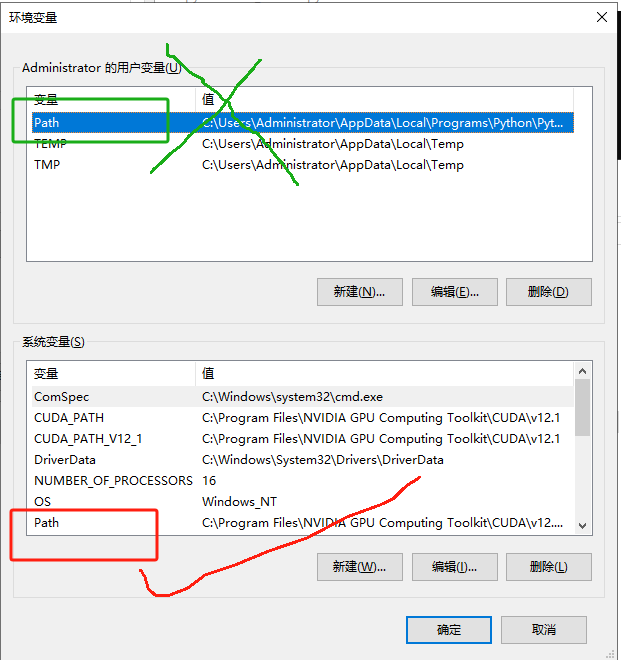
打开之后界面如下:
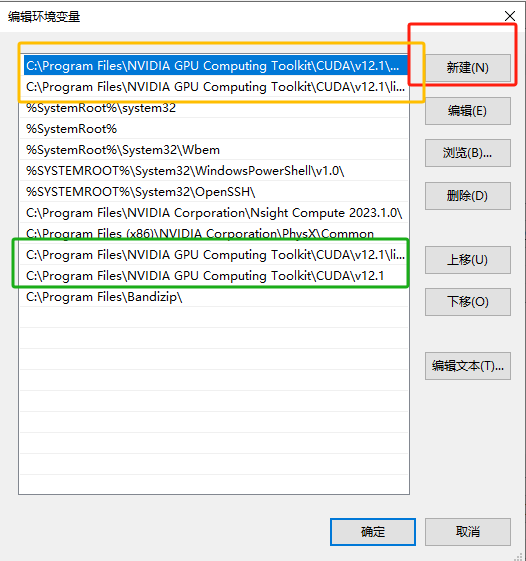
这边点击新建,既可以创建新的环境变量,值得注意的是,CUDA安装的时候会帮我们自动配置好部分驱动,我们只需要看一下这四个里面缺了那个补充一下就好
步骤五、验证是否安装成功
打开命令行
输入以下指令
ncvv -V
显示界面如下图所示就是安装成功了 在这里插入图片描述
三、CUDNN安装
cudnn 是 NVIDIA 为深度学习优化的库,能让 PyTorch、TensorFlow 等框架更快调用 CUDA,必须与 CUDA 版本完全匹配
进入网址安装 https://developer.nvidia.com/rdp/cudnn-archive
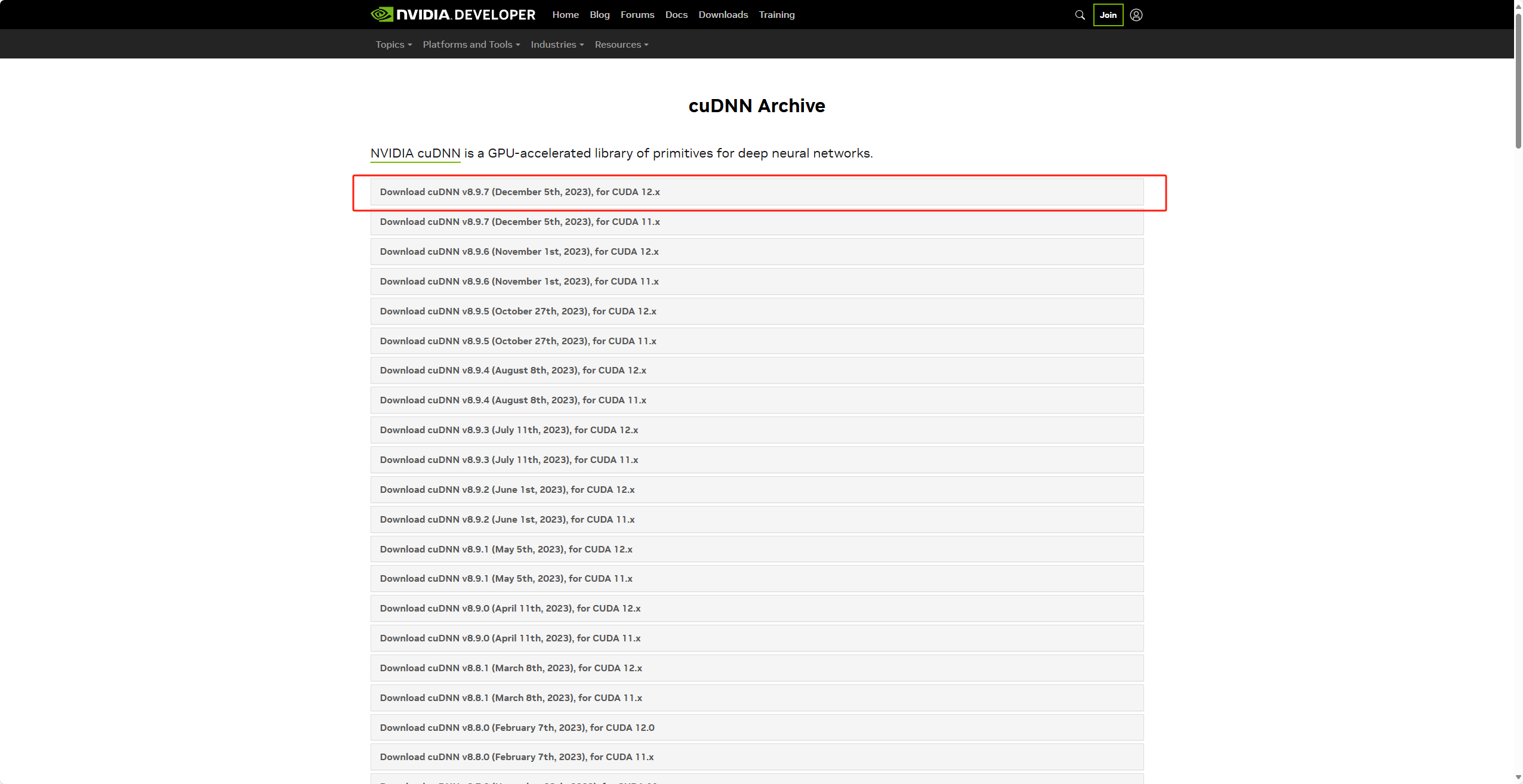
只要版本能够对应的上就可以(12.X的意思是满足所有像是12.1 12.2这样的版本)
将下载的压缩包解压打开,发现有三个文件夹
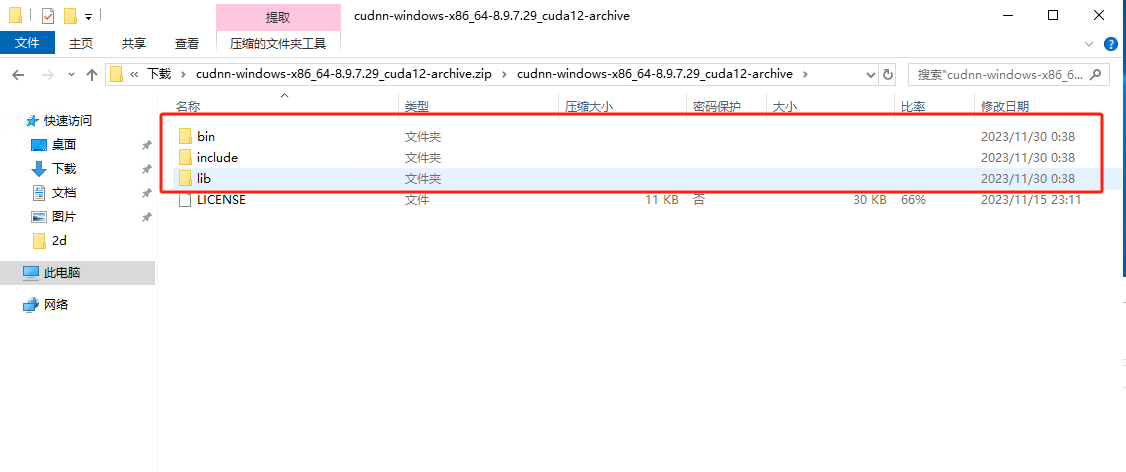
这个时候我们再打开刚才CUDA的安装路径,将路径对应的文件全部从下载的文件夹里面移动到CUDA的对应路径下即可
路径对应如下:
bin--------bin
include-------include
lib/x64--------lib/x64
移动之后就可以了,安装CUDNN成功
四、PyTorch安装
Pytorch安装跟正常的python包安装其实是一样的,最好使用镜像网站安装,pip镜像安装的方法我在上一篇博客写到了,可以参考链接:
Python :pip 下载太慢?教你 2 步配置国内镜像源,速度从 KB/s 到 MB
这边推荐使用南京大学的镜像源网站,对于Torch的包特别全并且更新很及时
镜像源网址:https://mirrors.nju.edu.cn
如果显示要安装的版本找不到的话,很可能是语法的问题,我们可以通过以下方法指定安装的版本:
pip install 直接复制下来的对应版本的网址
这边演示如何直接在镜像网站中找到需要的对应版本,这边以2.5.0+cu121为例
首先在南京大学镜像源的网址后面加上pytorch
https://mirrors.nju.edu.cn/pytorch
访问网站 界面如下:
点击whl文件,进入https://mirrors.nju.edu.cn/pytorch//whl 界面如下
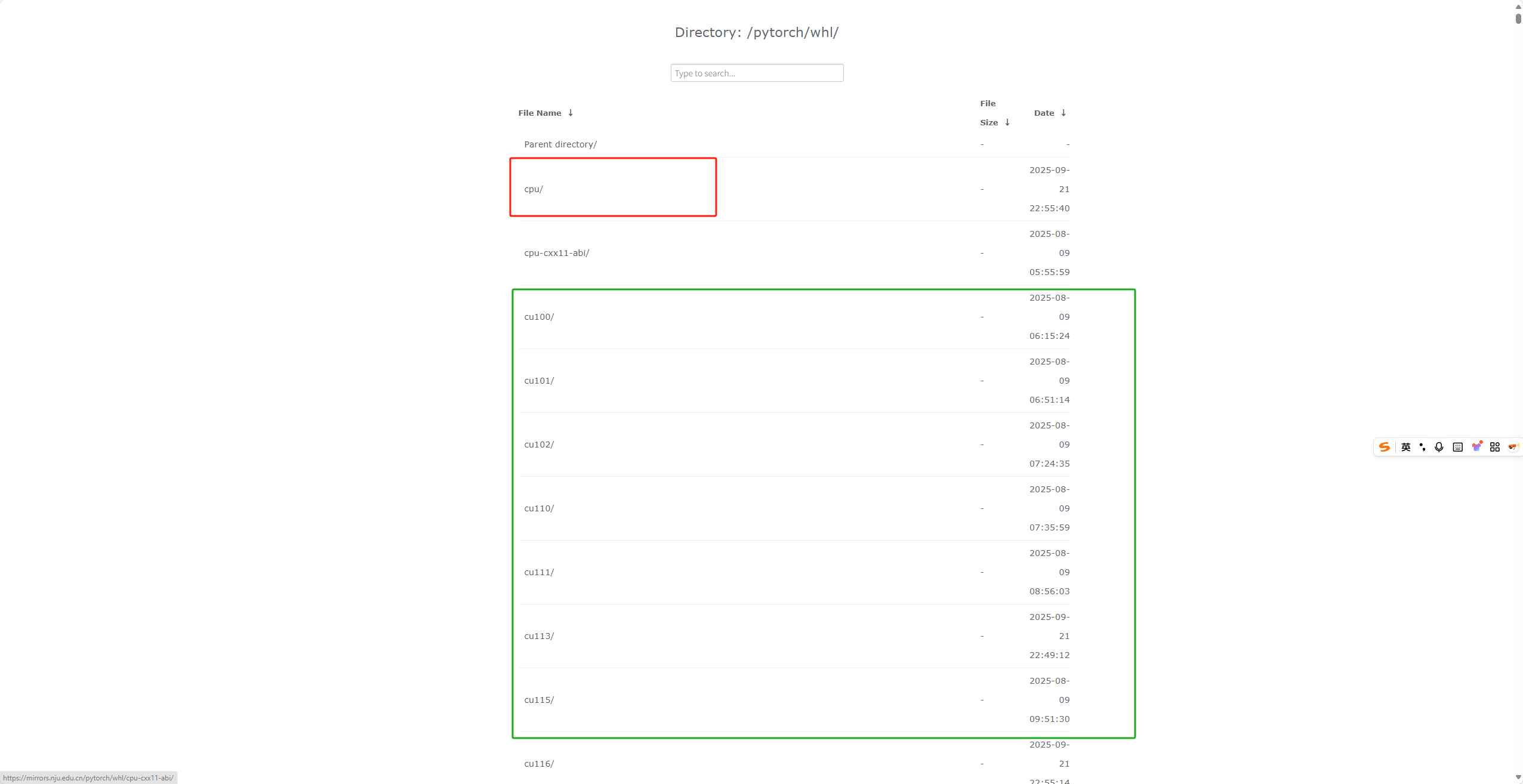
cpu代表cpu版本的pytorch,该版本不能使用gpu进行加速 加载计算速度较慢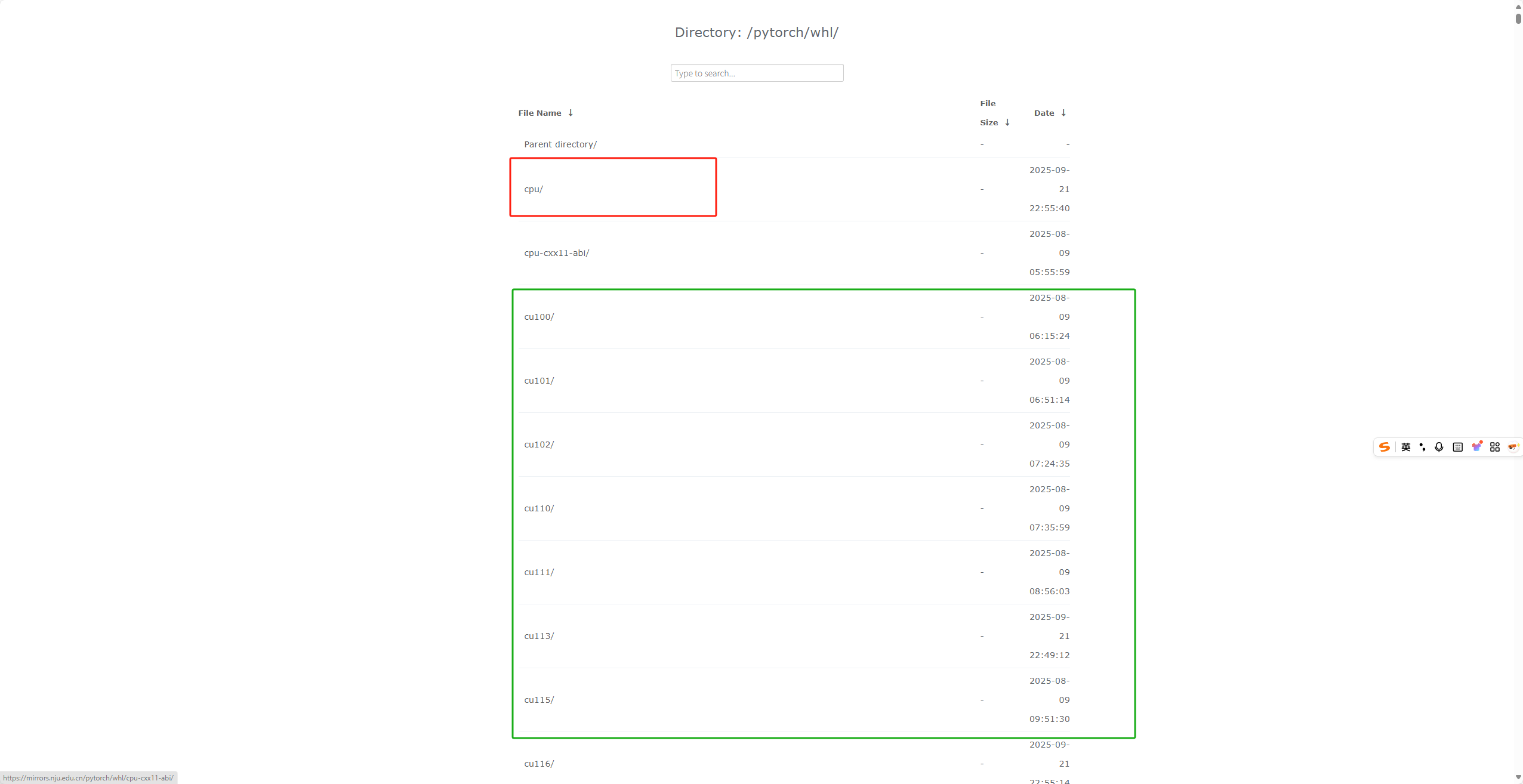
而cuXXX对应的就是对应版本的CUDA,刚才我们下载的CUDA是12.1的版本,于是我们寻找并进入cu121的文件夹

进入之后界面如上,我们要寻找torch文件夹

进入之后可以看到不同的pytorch版本以及对应计算机的版本

选择适合自己的版本复制链接进行pip下载即可
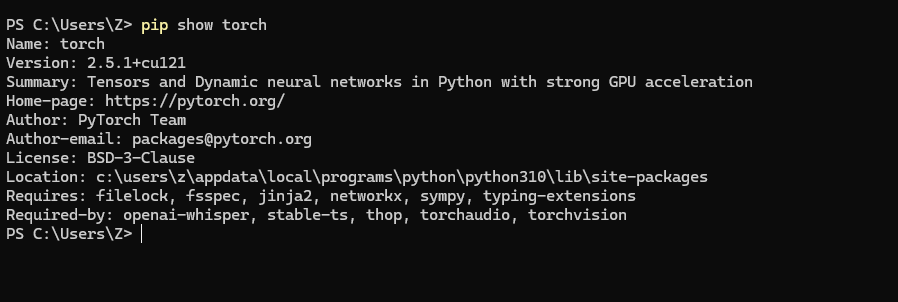
可以用以下命令验证是否安装成功
pip show torch
显示界面如下即表示安装成功
五、torchvision安装
torchvision 用于处理图像数据(如加载数据集、图像变换),必须与 PyTorch 版本严格对应,否则会报 “版本不兼容” 错误。
刚才我们下载的是2.5.1+cu121版本的PyTorch ,根据官方对应规则,我们应该选择torchvision 0.20.1
可以进入刚才的镜像源网页查找,也可以直接在pip中强制使用版本号对应,命令如下:
pip install torchvision==0.20.1+cu121 --index-url https://download.pytorch.org/whl/cu121
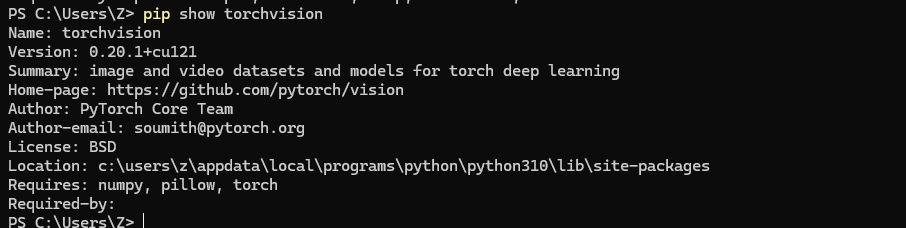
同样可以使用以下命令验证是否安装成功
pip show torchvision
显示界面如下即表示安装成功
总结
环境配置的核心是 “版本匹配”:显卡驱动→CUDA→cudnn→PyTorch→torchvision,每一步的版本都要严格对应。本地机和云端服务器的安装逻辑一致,差异仅在 Linux/Windows 的命令和路径上。
如果遇到问题,优先检查:① 驱动是否支持当前 CUDA;② nvcc -V 是否能找到 CUDA;③ PyTorch 安装命令是否选对 CUDA 版本。按教程步骤操作,基本能一次搭建成功,
雲端服務器使用指南:Pytorch及顯卡驅動、CUDA全流程保姆級下載教程(本地機也適用)
從零安裝NVIDIA驅動、CUDA、cudnn到PyTorch/torchvision的保姆級教程,強調版本匹配鏈(驅動→CUDA→cudnn→Torch),含環境變數與南大鏡像源選包方法。
來源:https://blog.csdn.net/2403_87969572/article/details/151937481
抓取時間(ISO本地):2026-05-18 05:17:02
文章目錄

前言
在深度學習領域,PyTorch 憑藉靈活的架構和友好的 API 成為眾多開發者的首選框架。但 PyTorch 的高效運行依賴顯卡驅動、CUDA(英偉達顯卡計算平臺)和 cudnn(CUDA 加速庫)的協同支持 —— 缺少其中任何一環,都可能導致 “顯卡認不出”“代碼跑在 CPU 上” 等問題。
無論是本地 Windows/Linux 電腦,還是阿里雲、騰訊雲等雲端服務器,環境配置都是入門的第一道坎:驅動版本不兼容會安裝失敗,CUDA 和 PyTorch 版本不匹配會報 “找不到 CUDA” 錯誤,cudnn 漏裝會讓模型訓練速度大幅下降。本篇教程從 “零基礎” 視角出發,手把手帶你完成全流程安裝,每步附驗證方法,幫你避開 90% 的配置坑。
一、顯卡驅動安裝(本地 / 雲端通用邏輯)
步驟一、查看顯卡驅動型號
Windows
右鍵桌面 → 打開 “NVIDIA 控制面板” → 左側 “系統信息” → “顯示適配器”,記錄顯卡型號(如 RTX 4090、GTX 1660)。
這邊因為電腦截屏限制,就直接用手機拍了
點開之後界面如下:
點擊左下角的系統信息
紅框選住的地方就是具體的顯卡信息
Linux
SSH 連接服務器後,執行命令:
lspci | grep -i nvidia # 輸出類似“NVIDIA Corporation GA102 [GeForce RTX 3090]”
若雲端服務器未顯示顯卡,先確認實例是否勾選 “GPU 機型”,如阿里雲 “GN6”、騰訊雲 “GT4” 系列
步驟二、下載並安裝驅動
1、進入官網下載驅動
打開NVIDIA 驅動下載官網(https://www.nvidia.cn/drivers/lookup/)
根據自己的顯卡型號按以下步驟選擇:
我這邊用的是 所以是按我的配置選的
“產品類型”: “Data Center / Tesla”(雲端服務器顯卡);
“產品系列”“產品型號”:Tesla A10
“操作系統”:選 “Windows Server 2025;(這個是在配置服務器的時候自己選擇的)
點擊 “搜索” → “下載”,得到.exe 安裝包。
在加載之後的界面中進一步選擇查看之後下載既可
2、安裝驅動
1.選擇 “精簡安裝”(新手推薦,避免手動配置);
2.儘量選擇默認安裝路徑
3.若提示 “已有舊驅動”,選 “覆蓋安裝”;
4.安裝完成後重啟電腦。
步驟三、驗證安裝是否成功
安裝完成後,可以按win+r鍵盤,輸入cmd回車,彈出如下所示終端,輸入nvidia-smi,若顯示如下,則說明驅動已經安裝好了。
二、CUDA安裝
CUDA 是英偉達提供的 “顯卡計算工具包”,PyTorch 通過 CUDA 調用顯卡算力。重點:CUDA 版本 ≤ 驅動支持的最高 CUDA 版本(如驅動顯示 “CUDA Version: 12.4”,則可裝 CUDA 12.4、12.3 等)。
步驟一、查看支持的CUDA版本
這邊的CUDA Version 表示的是支持的CUDA的最高版本,也就是說我們安裝的CUDA需要在版本12.8以下
步驟二、下載對應的CUDA版本
進入官網下載對應的CUDA版本(https://developer.nvidia.com/cuda-toolkit-archive)
我下載12.1.0版本的cuda,是為了和我本機上的版本保持統一方便配置,同時版本太高的cuda很難找到對應的pytorch
步驟三、安裝CUDA
點擊下載的可執行文件
一路點擊確定安裝下去就可以了
步驟四、配置環境變量
在測試是否安裝成功之前,我們首先需要配置CUDA的相關環境變量,儘管安裝程序會自動幫我們安裝一些,但是是不夠的
1、首先打開CUDA的安裝路徑(一般在C盤下的program file裡面可以看到CUDA的相關路徑)
點開帶有toolkit的文件夾,既可以看到CUDA
進入之後依次記錄下以下路徑(這邊我提供的是相對路徑,需要自行在文件夾裡查找絕對路徑並記錄)
1、\bin
2、\libs\x64
3、\libnvvp
4、目前打開的該路徑
下一步打開“編輯系統環境變量” 直接在Windows的搜索欄裡面搜索就可以了
點擊框選住的環境變量
這邊注意 點擊的是下面的系統變量,而非上面的用戶變量中的“PATH”
打開之後界面如下:
這邊點擊新建,既可以創建新的環境變量,值得注意的是,CUDA安裝的時候會幫我們自動配置好部分驅動,我們只需要看一下這四個裡面缺了那個補充一下就好
步驟五、驗證是否安裝成功
打開命令行
輸入以下指令
ncvv -V
顯示界面如下圖所示就是安裝成功了 在這裡插入圖片描述
三、CUDNN安裝
cudnn 是 NVIDIA 為深度學習優化的庫,能讓 PyTorch、TensorFlow 等框架更快調用 CUDA,必須與 CUDA 版本完全匹配
進入網址安裝 https://developer.nvidia.com/rdp/cudnn-archive
只要版本能夠對應的上就可以(12.X的意思是滿足所有像是12.1 12.2這樣的版本)
將下載的壓縮包解壓打開,發現有三個文件夾
這個時候我們再打開剛才CUDA的安裝路徑,將路徑對應的文件全部從下載的文件夾裡面移動到CUDA的對應路徑下即可
路徑對應如下:
bin--------bin
include-------include
lib/x64--------lib/x64
移動之後就可以了,安裝CUDNN成功
四、PyTorch安裝
Pytorch安裝跟正常的python包安裝其實是一樣的,最好使用鏡像網站安裝,pip鏡像安裝的方法我在上一篇博客寫到了,可以參考鏈接:
Python :pip 下載太慢?教你 2 步配置國內鏡像源,速度從 KB/s 到 MB
這邊推薦使用南京大學的鏡像源網站,對於Torch的包特別全並且更新很及時
鏡像源網址:https://mirrors.nju.edu.cn
如果顯示要安裝的版本找不到的話,很可能是語法的問題,我們可以通過以下方法指定安裝的版本:
pip install 直接複製下來的對應版本的網址
這邊演示如何直接在鏡像網站中找到需要的對應版本,這邊以2.5.0+cu121為例
首先在南京大學鏡像源的網址後面加上pytorch
https://mirrors.nju.edu.cn/pytorch
訪問網站 界面如下:
點擊whl文件,進入https://mirrors.nju.edu.cn/pytorch//whl 界面如下
cpu代表cpu版本的pytorch,該版本不能使用gpu進行加速 加載計算速度較慢
而cuXXX對應的就是對應版本的CUDA,剛才我們下載的CUDA是12.1的版本,於是我們尋找並進入cu121的文件夾
進入之後界面如上,我們要尋找torch文件夾
進入之後可以看到不同的pytorch版本以及對應計算機的版本
選擇適合自己的版本複製鏈接進行pip下載即可
可以用以下命令驗證是否安裝成功
pip show torch
顯示界面如下即表示安裝成功
五、torchvision安裝
torchvision 用於處理圖像數據(如加載數據集、圖像變換),必須與 PyTorch 版本嚴格對應,否則會報 “版本不兼容” 錯誤。
剛才我們下載的是2.5.1+cu121版本的PyTorch ,根據官方對應規則,我們應該選擇torchvision 0.20.1
可以進入剛才的鏡像源網頁查找,也可以直接在pip中強制使用版本號對應,命令如下:
pip install torchvision==0.20.1+cu121 --index-url https://download.pytorch.org/whl/cu121
同樣可以使用以下命令驗證是否安裝成功
pip show torchvision
顯示界面如下即表示安裝成功
總結
環境配置的核心是 “版本匹配”:顯卡驅動→CUDA→cudnn→PyTorch→torchvision,每一步的版本都要嚴格對應。本地機和雲端服務器的安裝邏輯一致,差異僅在 Linux/Windows 的命令和路徑上。
如果遇到問題,優先檢查:① 驅動是否支持當前 CUDA;② nvcc -V 是否能找到 CUDA;③ PyTorch 安裝命令是否選對 CUDA 版本。按教程步驟操作,基本能一次搭建成功,
Cloud Server Guide: Step-by-Step PyTorch, GPU Driver, and CUDA Install (Works on Local PCs Too)
Step-by-step NVIDIA driver, CUDA, cuDNN, PyTorch, and torchvision install with strict version alignment and mirror-based wheel selection.
Captured at (local ISO): 2026-05-18 05:17:02
Preface
In deep learning, PyTorch is a top choice thanks to its flexible design and friendly API. Efficient PyTorch use depends on GPU drivers, CUDA (NVIDIA’s compute platform), and cuDNN (CUDA acceleration libraries) working together—missing any piece can mean “GPU not detected” or code falling back to CPU.
Whether on a local Windows/Linux machine or cloud servers (Alibaba Cloud, Tencent Cloud, etc.), environment setup is the first hurdle: incompatible driver versions fail installs; mismatched CUDA and PyTorch trigger “CUDA not found”; skipping cuDNN slows training a lot. This tutorial walks through the full install from zero, with verification at each step, helping you avoid most common pitfalls.
1. GPU Driver Install (local / cloud same logic)
Step 1: Check GPU model
Windows
Right-click desktop → open “NVIDIA Control Panel” → left “System Information” → “Display”, note the GPU model (e.g. RTX 4090, GTX 1660).
Screenshot limits made me photograph the screen with a phone
After opening:
Click “System Information” at the bottom left
The red box shows the exact GPU info
Linux
After SSH to the server, run:
lspci | grep -i nvidia # e.g. "NVIDIA Corporation GA102 [GeForce RTX 3090]"
If no GPU appears on cloud, confirm the instance type includes GPU (e.g. Alibaba “GN6”, Tencent “GT4” series).
Step 2: Download and install driver
1. Download from NVIDIA
Open the NVIDIA driver lookup site (https://www.nvidia.cn/drivers/lookup/)
Pick options for your GPU—for example:
“Product Type”: “Data Center / Tesla” (cloud server GPUs);
“Product Series / Model”: Tesla A10;
“Operating System”: “Windows Server 2025” (chosen when provisioning the server);
Click “Search” → “Download” for the .exe.
On the results page, review and download
2. Install driver
- Choose “Express install” (recommended for beginners);
- Prefer default install path;
- If prompted about an old driver, choose “overwrite”;
- Reboot after install.
Step 3: Verify install
Press Win+R, type cmd, Enter. In the terminal run nvidia-smi. Output like below means the driver is installed:
2. CUDA Install
CUDA is NVIDIA’s toolkit for GPU computing; PyTorch uses it to run on the GPU. Rule: CUDA version ≤ highest CUDA version your driver supports (e.g. driver shows “CUDA Version: 12.4” → you can install CUDA 12.4, 12.3, etc.).
Step 1: Check supported CUDA version
“CUDA Version” is the maximum supported—install CUDA below that (e.g. below 12.8 here).
Step 2: Download matching CUDA
Download from the archive: https://developer.nvidia.com/cuda-toolkit-archive
I used CUDA 12.1.0 to match my local machine and because very new CUDA versions are harder to pair with PyTorch builds.
Step 3: Install CUDA
Run the downloaded executable
Click through the installer with defaults.
Step 4: Configure environment variables
Before testing, set CUDA environment variables—the installer sets some, but not all.
- Open the CUDA install path (often under
C:\Program Files, look for CUDA folders)
Open the folder with “toolkit” to see CUDA
Note these paths (relative below—find the full absolute paths on your machine):
**1.\bin \lib\x64\libnvvp- The toolkit root you have open**
Next open “Edit the system environment variables” (search in Windows).
Click Environment Variables
Edit PATH under System variables (bottom), not user variables
Then:
Click New to add entries. The installer may have added some—add any of the four paths that are missing.
Step 5: Verify install
Open a command prompt and run:
ncvv -V
Success screen looks like this
3. cuDNN Install
cuDNN is NVIDIA’s deep-learning library; it speeds PyTorch/TensorFlow on CUDA and must match your CUDA version exactly.
Download from https://developer.nvidia.com/rdp/cudnn-archive
Pick a build that matches your CUDA major version (12.x covers 12.1, 12.2, etc.).
Extract the zip—you get three folders
Open your CUDA install directory and copy files from the cuDNN folders into the matching CUDA folders:
bin → bin
include → include
lib/x64 → lib/x64
After copying, cuDNN is installed.
4. PyTorch Install
PyTorch installs like any Python package; mirrors help. For pip mirrors see:
Python: pip too slow? Two steps to configure a domestic mirror
Nanjing University’s mirror is recommended—full PyTorch wheels and frequent updates: https://mirrors.nju.edu.cn
If a version is “not found”, check pip syntax; you can install from a direct wheel URL:
pip install <paste the wheel URL from the mirror>
Example: finding 2.5.0+cu121 on the mirror:
Add pytorch to the NJU mirror base URL → https://mirrors.nju.edu.cn/pytorch
Open whl → https://mirrors.nju.edu.cn/pytorch//whl
cpu = CPU-only PyTorch (no GPU)—slower
cuXXX = CUDA builds; we used CUDA 12.1, so open cu121
Find the torch folder
Pick your Python version and platform, copy the link, pip install it.
Verify:
pip show torch
Success looks like:
5. torchvision Install
torchvision handles image data (datasets, transforms) and must match your PyTorch version.
For PyTorch 2.5.1+cu121, use torchvision 0.20.1 per official compatibility. Find it on the same mirror or:
pip install torchvision==0.20.1+cu121 --index-url https://download.pytorch.org/whl/cu121
Verify:
pip show torchvision
Success:
Summary
The core rule is version matching: GPU driver → CUDA → cuDNN → PyTorch → torchvision, each step aligned. Local and cloud logic are the same; only Linux/Windows commands and paths differ.
If something fails, check: ① driver supports your CUDA; ② nvcc -V finds CUDA; ③ PyTorch install targets the right CUDA tag. Follow this guide and you should get a working stack in one pass.