爬虫专栏:抗封禁实战——代理技术全解析与央视节目爬虫落地案例
从代理原理、快代理隧道配置到 requests proxies 集成与有效性校验,结合央视节目高频爬取说明如何用动态代理规避 IP 封禁。
前言
在数据采集领域,“IP 封禁” 是开发者绕不开的坎。以央视节目数据爬取为例,其 API 对单 IP 请求频率限制严格,若直接用本地 IP 高频爬取,不出 1 分钟就会出现 403(拒绝访问)或 429(请求过于频繁)错误,导致爬取中断。
而代理(Proxy) 作为 “IP 切换神器”,能让爬虫通过中间服务器转发请求,使目标网站看到的是代理 IP 而非真实 IP,从而规避封禁风险。本文将结合一份我自己写的可直接运行的央视节目爬虫代码,从代理的核心原理、获取渠道,到代码落地实现,全方位讲解如何用代理打造稳定抗封禁的爬虫系统。
一、代理是什么?
代理本质是位于客户端与目标服务器之间的中间服务器,其工作流程如下
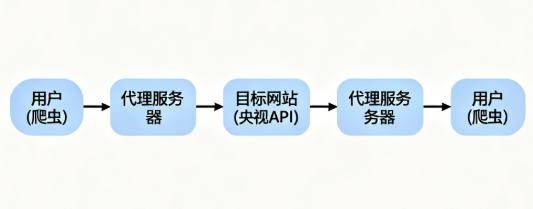
通过这一流程,代理实现了 “IP 伪装”—— 目标网站无法识别爬虫的真实 IP,仅能获取代理服务器的 IP 地址。
通过代理,我们可以实现以下的三个主要功能:
1、规避 IP 封禁:高频请求时,切换不同代理 IP,避免单 IP 被拉黑;
2、突破地域限制:部分网站内容仅对特定地区开放,通过对应地区代理 IP 可正常爬取;
3、提高爬取稳定性:部分代理服务商提供节点负载均衡,减少因单节点故障导致的爬取中断。
代理可以按照四种方式来进行分类,具体表格如下:
| 分类维度 | 具体类型 | 特点 | 适用场景 |
|---|---|---|---|
| 匿名度 | 透明代理 | 目标网站可识别代理 IP 和真实 IP | 无需隐藏 IP 的测试场景 |
| 普通匿名代理 | 目标网站仅能识别代理 IP,无法获取真实 IP | 一般反爬场景 | |
| 高匿名代理 | 目标网站无法识别请求来自代理 | 严格反爬场景(如央视、电商平台) | |
| 协议 | HTTP 代理 | 仅支持 HTTP 协议请求,数据传输未加密,易被拦截或篡改 | 爬取 HTTP 协议的网站(多为非加密的老旧站点) |
| HTTPS 代理 | 1. 支持 HTTPS 加密协议,基于 TLS/SSL 对数据传输加密,保障请求数据隐私与安全;2. 向下兼容 HTTP 协议请求,无需额外切换代理;3. 具备证书验证机制,可规避“非安全连接”拦截;4. 适配主流浏览器、爬虫工具的加密请求规范 | 1. 爬取 HTTPS 协议网站(互联网 90%以上主流站点,如搜索引擎、社交平台、资讯门户等);2. 涉及隐私/敏感数据的爬取(电商评价、金融资讯等);3. 浏览器模拟访问场景(浏览器默认优先用 HTTPS);4. 目标网站设“强制 HTTPS 跳转”的安全/反爬场景 | |
| SOCKS5 代理 | 支持 TCP/UDP 协议,适用多种应用,不解析应用层协议,兼容性强 | 需穿透防火墙的复杂场景(邮件客户端、P2P 传输等) | |
| 来源 | 免费代理 | 零成本,稳定性差,时效短(几分钟到几小时),多存在数据泄露风险 | 代码测试、低频率爬取 |
| 付费代理 | 稳定性高,时效长,提供技术支持,部分含专属加密通道 | 生产环境、高频率爬取 | |
| 使用方式 | 静态代理 | 代理 IP 固定,需手动切换,长期使用易被目标网站封禁 | 低频率、小规模爬取 |
| 动态代理(隧道代理) | 一个代理地址对应多个 IP,自动切换 IP,降低封禁概率,操作便捷 | 高频率、大规模爬取(如本文案例) |
二、代理获取
博主这边是直接用的免费的代理进行爬取,这边给出网站,新用户登录可以领取12个小时的时长,对于需要长期稳定爬虫任务的人来说不够,但博主是短期的大量数据需求,所以够用了,这边给出具体流程
首先登录网站: 快代理
这边直接登录/注册之后在首页进行免费试用
选择隧道代理Pro的一天试用
之后对这里面的三个代理根据自己的需要进行选择就可以了,这三个的参数各不相同,适用的场景也各不相同,将在下面展开介绍(三个都是可以选的,博主这边选择了第三个并发请求次数最高的为了快速获得数据,这个已经是选完的界面了所以不能再点)
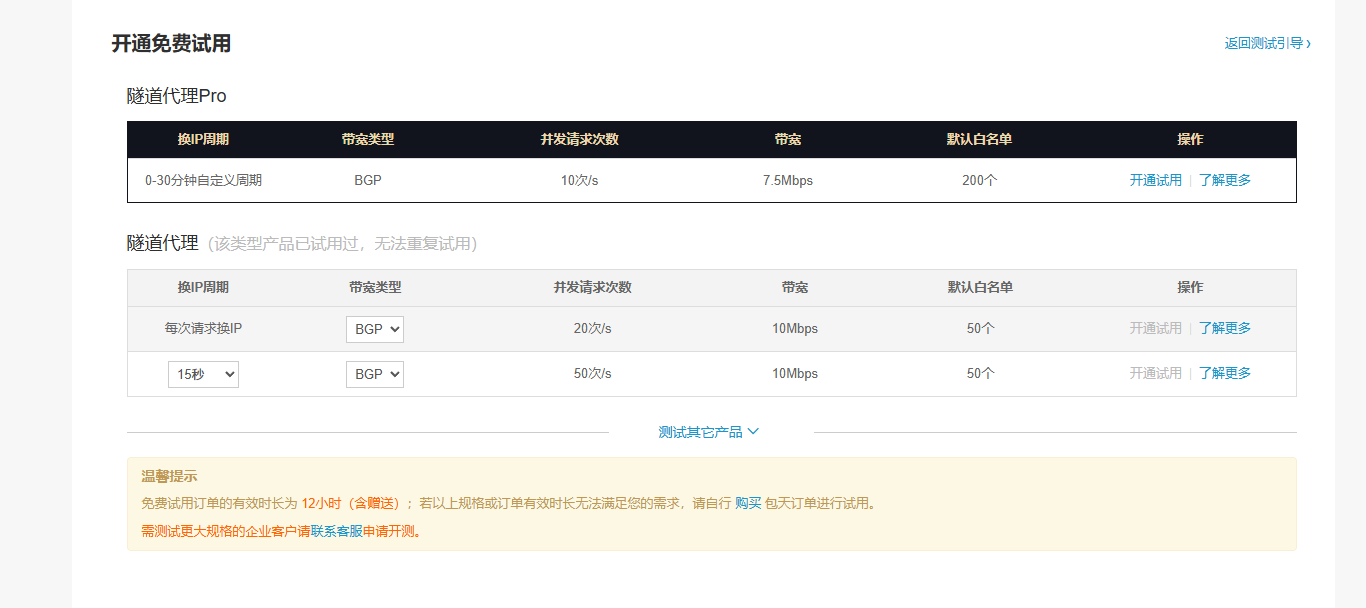
| 代理类型 | 换IP周期 | 并发请求次数 | 带宽 | 默认白名单(IP白名单数量) | 特点 |
|---|---|---|---|---|---|
| 隧道代理 Pro | 0 - 30 分钟自定义 | 10 次/秒 | 7.5Mbps | 200 个 | 换IP周期灵活,适合长期稳定爬取(如定时爬取固定数据),白名单多,适合多机器/多环境使用。 |
| 隧道代理(每次请求换IP) | 每次请求换IP | 20 次/秒 | 10Mbps | 50 个 | 每次请求都换IP,反爬规避能力最强,适合高频、易触发反爬的场景,但IP切换可能增加延迟。 |
| 隧道代理(15秒换IP) | 每15秒自动换IP | 50 次/秒 | 10Mbps | 50 个 | 兼顾“IP轮换”和“请求效率”,适合中高频爬取(如批量数据抓取),IP稳定性比“每次请求换IP”稍高。 |
可以根据以上表格以及自己的需求选择代理。
三、代理配置
在前一步挑选完之后会进入以下界面:
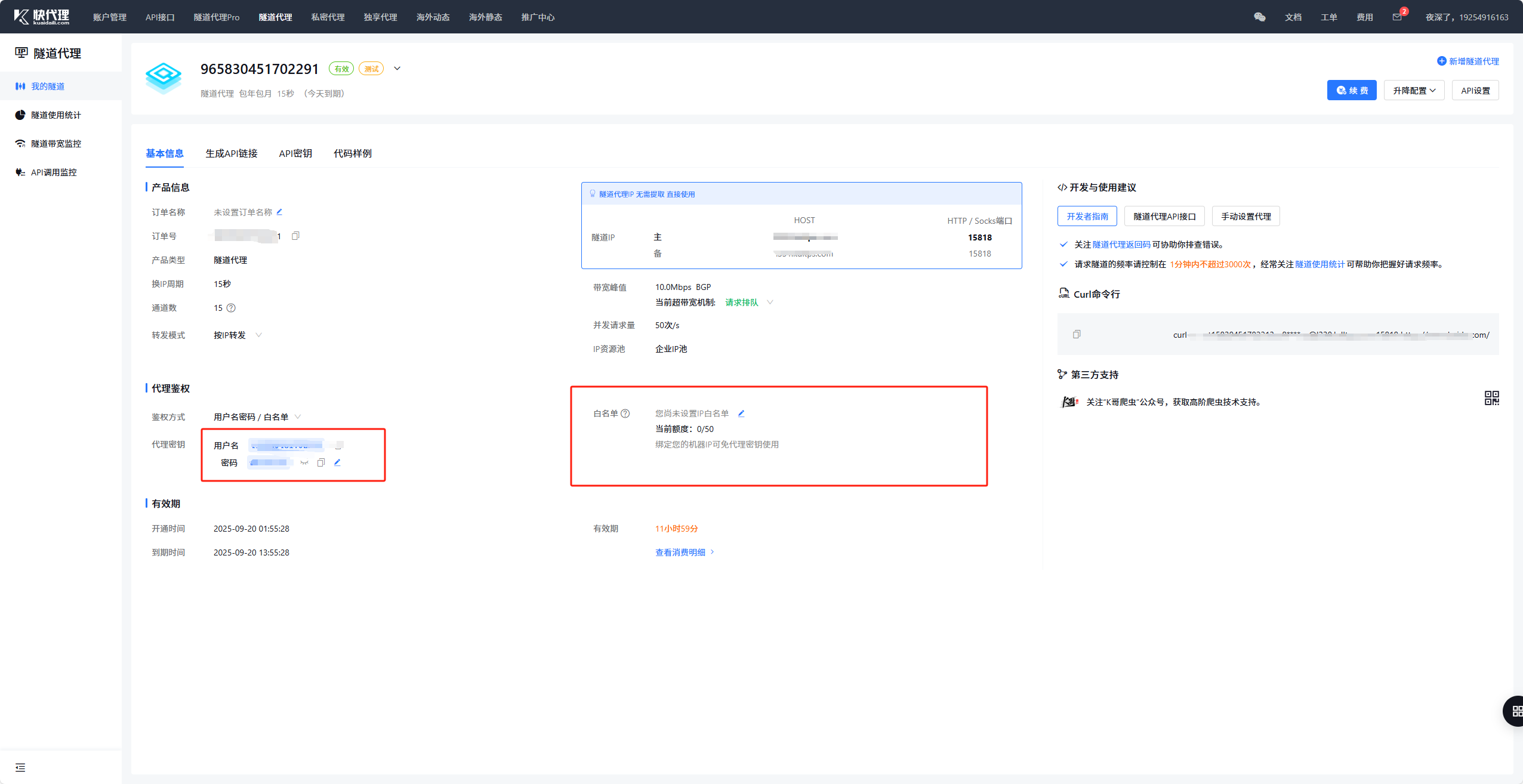
其中左边的小红色框对应的是账号以及密码,在我们在程序访问代理需要用到的。
右边的大红色框需要我们将自己的本机的IP或是服务器,反正运行爬虫程序的公网IP加入白名单。
服务器好说,本机的话很多朋友不知道如何查看自己本机的公网IP,具体步骤如下:
打开命令提示符CMD,输入以下命令即可:
curl ipinfo.io
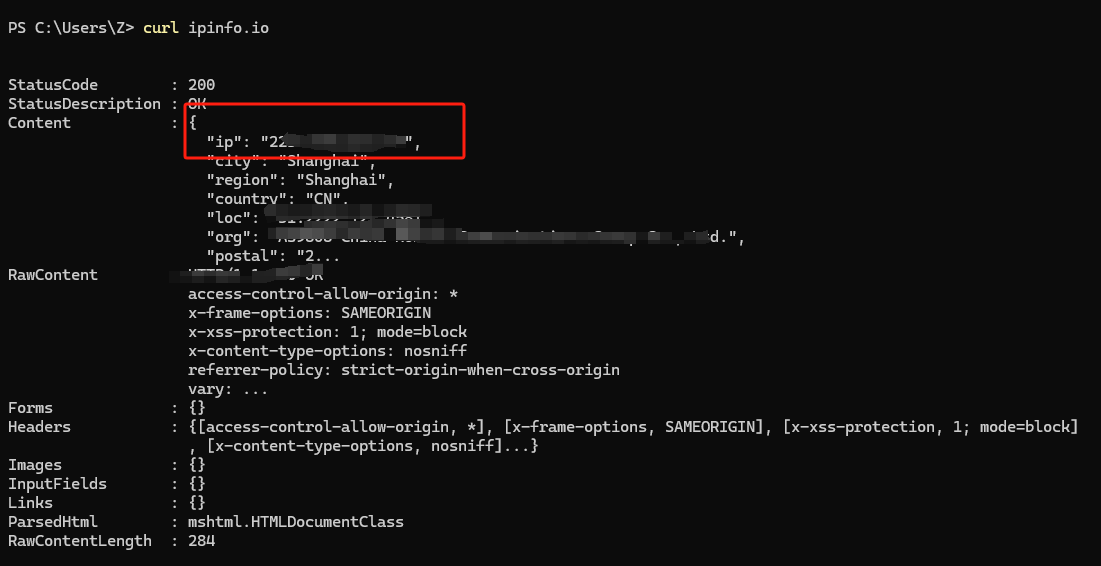
在输出的内容里面,红色框起来的就是我们的公网IP
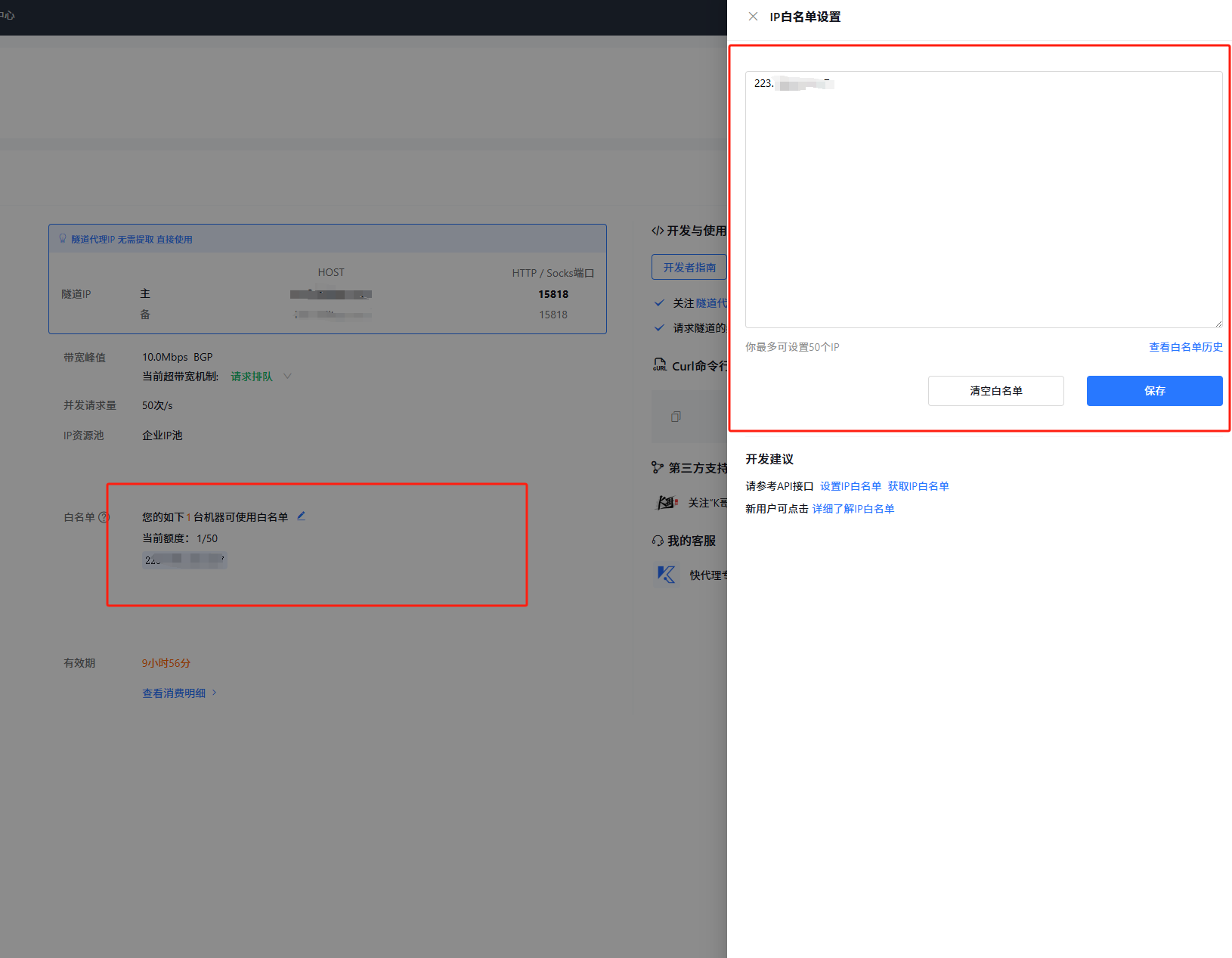
设置成功之后界面如上图所示。
四、代理应用例程
我们先来解读一下官方给的例程:
#!/usr/bin/env Python
# -*- coding: utf-8 -*-
import requests
# 隧道域名:端口号
tunnel = "XXXX"
# 用户名密码方式
username = "XXXX"
password = "XXXX"
proxies = {
"http": "http://%(user)s:%(pwd)s@%(proxy)s/" % {"user": username, "pwd": password, "proxy": tunnel},
"https": "http://%(user)s:%(pwd)s@%(proxy)s/" % {"user": username, "pwd": password, "proxy": tunnel}
}
# 白名单方式(需提前设置白名单)
# proxies = {
# "http": "http://%(proxy)s/" % {"proxy": tunnel},
# "https": "http://%(proxy)s/" % {"proxy": tunnel}
# }
# 要访问的目标网页
target_url = "https://dev.kdlapi.com/testproxy"
# 使用隧道域名发送请求
response = requests.get(target_url, proxies=proxies)
# 获取页面内容
if response.status_code == 200:
print(response.text) # 请勿使用keep-alive复用连接(会导致隧道不能切换IP)
其中 proxies 字典用于配置 HTTP 和 HTTPS 请求的代理服务器信息,让请求通过指定的代理隧道进行发送
很简单的一个代码,和我们正常使用的Request程序相比起来只是多加了一个proxies的参数罢了,说明Request内部已经帮我们集成的很好了,我们只需要像例程一样正确传入代理信息既可。
这边补充一个·代理有效性检验的代码,不论是免费代理还是付费代理,在使用前最好都先进性有效性检验:
import requests
def check_proxy(proxy):
"""验证代理是否有效(测试能否访问目标网站)"""
test_url = "https://api.cntv.cn/NewVideo/getVideoListByColumn?id=TOPC1451558496100826&bd=20240101"
try:
response = requests.get(
test_url,
proxies=proxy,
verify=False,
timeout=5 # 短超时,快速判断
)
# 若能正常返回200状态码,且响应包含目标字段(如"id"),则代理有效
return response.status_code == 200 and "id" in response.text
except Exception as e:
return False
# 测试代理列表
proxy_list = [
{"http": "http://123.123.123.123:8080", "https": "http://123.123.123.123:8080"},
{"http": "http://124.124.124.124:8080", "https": "http://124.124.124.124:8080"}
]
# 筛选有效代理
valid_proxies = [p for p in proxy_list if check_proxy(p)]
print(f"有效代理数量:{len(valid_proxies)}/{len(proxy_list)}")
if valid_proxies:
print("第一个有效代理:", valid_proxies[0])
五、实战案例:代理在央视节目爬虫中的完整实现
博主研究这个代理的原因就是最近在爬取央视节目的节目编号信息,需要收集目标栏目的所有信息,但是由于央视频网页架构的限制,节目ID并不能批量获取,相当于每获取一个ID就必须访问一次网页,也就是因为如此高频率的访问导致我自己的ip一下子就被封禁了,所以开始研究代理这一块内容,央视频的节目信息爬取之后有时间会再出一期博客仔细讲解,也算是比较有意思的。
代理知识点都在前面讲过了,值得一提的是为了加快爬取速度,我的代码里面也采用了异步的架构,对于异步同步这一块的内容,博主打算在下一篇博客介绍,届时会将链接附在这篇博客里面,这边我们先直接看代码与最终效果。由于爬虫代码较为敏感,这边就不给出完整代码了
如果有特殊需求现需要完整代码的话可以私信我获取完整代码
代码运行效果如下:
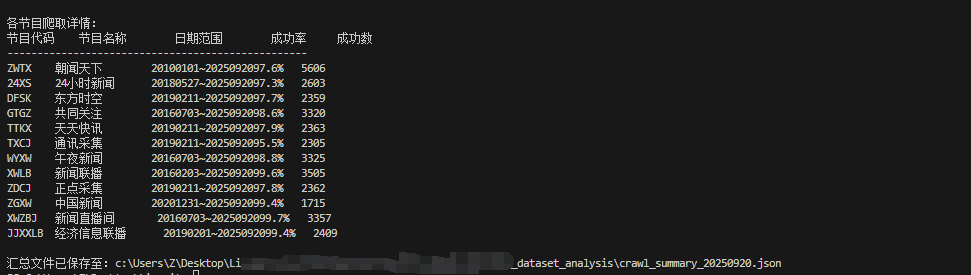
纠正一个地方,这边的ZDCJ对应的节目应该是正点财经而非正点采集,TTKX对应的是体坛快讯而非天天快讯
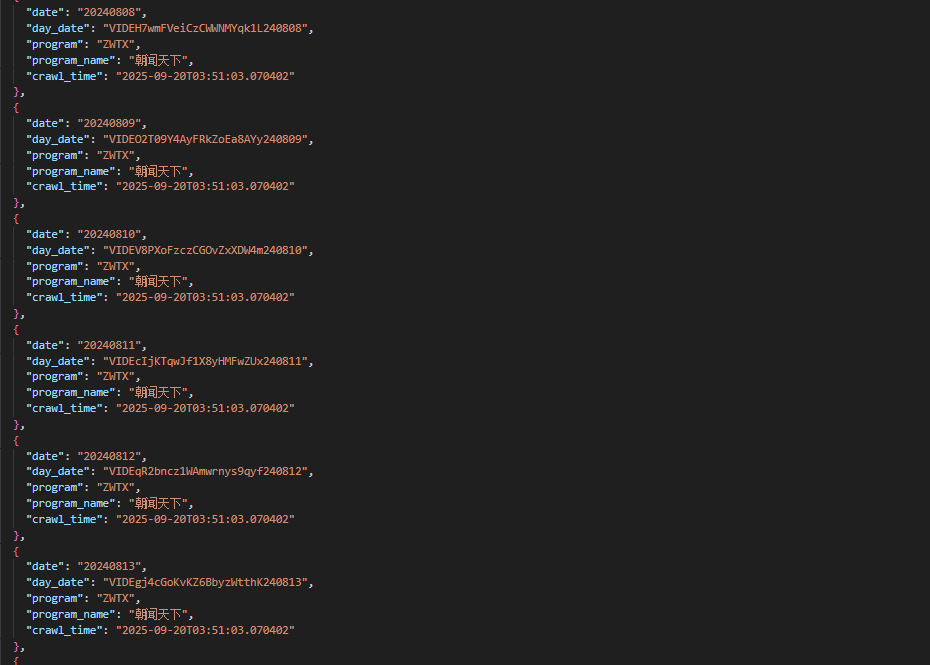
部分结果文件截图如下:
如果有特殊需求现需要完整代码的话可以私信我获取完整代码
总结
本文围绕 “爬虫抗 IP 封禁” 核心需求,从理论到实践拆解了代理的应用逻辑:先明确代理作为 “中间服务器” 的本质,通过 IP 伪装解决高频爬取中的封禁痛点;再结合匿名度、协议、来源等维度,厘清不同代理的适用场景(如高匿名 HTTPS 代理适配央视等严格反爬场景,动态隧道代理满足高频切换需求);随后以快代理为例,提供了从免费试用、白名单配置到公网 IP 查询的落地步骤;最后通过代理有效性校验代码和央视节目爬虫实战,验证了 “代理 + requests” 的简单集成逻辑 —— 仅需配置proxies字典,即可让爬虫通过中间服务器转发请求,规避真实 IP 暴露风险。
爬蟲專欄:抗封禁實戰——代理技術全解析與央視節目爬蟲落地案例
從代理原理、快代理隧道配置到 requests proxies 整合與有效性校驗,結合央視節目高頻爬取說明如何用動態代理規避 IP 封禁。
來源:https://blog.csdn.net/2403_87969572/article/details/151882403
抓取時間(ISO本地):2026-05-18 05:16:58
文章目錄
前言
在數據採集領域,“IP 封禁” 是開發者繞不開的坎。以央視節目數據爬取為例,其 API 對單 IP 請求頻率限制嚴格,若直接用本地 IP 高頻爬取,不出 1 分鐘就會出現 403(拒絕訪問)或 429(請求過於頻繁)錯誤,導致爬取中斷。
而代理(Proxy) 作為 “IP 切換神器”,能讓爬蟲通過中間服務器轉發請求,使目標網站看到的是代理 IP 而非真實 IP,從而規避封禁風險。本文將結合一份我自己寫的可直接運行的央視節目爬蟲代碼,從代理的核心原理、獲取渠道,到代碼落地實現,全方位講解如何用代理打造穩定抗封禁的爬蟲系統。
一、代理是什麼?
代理本質是位於客戶端與目標服務器之間的中間服務器,其工作流程如下
通過這一流程,代理實現了 “IP 偽裝”—— 目標網站無法識別爬蟲的真實 IP,僅能獲取代理服務器的 IP 地址。
通過代理,我們可以實現以下的三個主要功能:
1、規避 IP 封禁:高頻請求時,切換不同代理 IP,避免單 IP 被拉黑;
2、突破地域限制:部分網站內容僅對特定地區開放,通過對應地區代理 IP 可正常爬取;
3、提高爬取穩定性:部分代理服務商提供節點負載均衡,減少因單節點故障導致的爬取中斷。
代理可以按照四種方式來進行分類,具體表格如下:
| 分類維度 | 具體類型 | 特點 | 適用場景 |
|---|---|---|---|
| 匿名度 | 透明代理 | 目標網站可識別代理 IP 和真實 IP | 無需隱藏 IP 的測試場景 |
| 普通匿名代理 | 目標網站僅能識別代理 IP,無法獲取真實 IP | 一般反爬場景 | |
| 高匿名代理 | 目標網站無法識別請求來自代理 | 嚴格反爬場景(如央視、電商平臺) | |
| 協議 | HTTP 代理 | 僅支持 HTTP 協議請求,數據傳輸未加密,易被攔截或篡改 | 爬取 HTTP 協議的網站(多為非加密的老舊站點) |
| HTTPS 代理 | 1. 支持 HTTPS 加密協議,基於 TLS/SSL 對數據傳輸加密,保障請求數據隱私與安全;2. 向下兼容 HTTP 協議請求,無需額外切換代理;3. 具備證書驗證機制,可規避“非安全連接”攔截;4. 適配主流瀏覽器、爬蟲工具的加密請求規範 | 1. 爬取 HTTPS 協議網站(互聯網 90%以上主流站點,如搜索引擎、社交平臺、資訊門戶等);2. 涉及隱私/敏感數據的爬取(電商評價、金融資訊等);3. 瀏覽器模擬訪問場景(瀏覽器默認優先用 HTTPS);4. 目標網站設“強制 HTTPS 跳轉”的安全/反爬場景 | |
| SOCKS5 代理 | 支持 TCP/UDP 協議,適用多種應用,不解析應用層協議,兼容性強 | 需穿透防火牆的複雜場景(郵件客戶端、P2P 傳輸等) | |
| 來源 | 免費代理 | 零成本,穩定性差,時效短(幾分鐘到幾小時),多存在數據洩露風險 | 代碼測試、低頻率爬取 |
| 付費代理 | 穩定性高,時效長,提供技術支持,部分含專屬加密通道 | 生產環境、高頻率爬取 | |
| 使用方式 | 靜態代理 | 代理 IP 固定,需手動切換,長期使用易被目標網站封禁 | 低頻率、小規模爬取 |
| 動態代理(隧道代理) | 一個代理地址對應多個 IP,自動切換 IP,降低封禁概率,操作便捷 | 高頻率、大規模爬取(如本文案例) |
二、代理獲取
博主這邊是直接用的免費的代理進行爬取,這邊給出網站,新用戶登錄可以領取12個小時的時長,對於需要長期穩定爬蟲任務的人來說不夠,但博主是短期的大量數據需求,所以夠用了,這邊給出具體流程
首先登錄網站: 快代理
這邊直接登錄/註冊之後在首頁進行免費試用
選擇隧道代理Pro的一天試用
之後對這裡面的三個代理根據自己的需要進行選擇就可以了,這三個的參數各不相同,適用的場景也各不相同,將在下面展開介紹(三個都是可以選的,博主這邊選擇了第三個併發請求次數最高的為了快速獲得數據,這個已經是選完的界面了所以不能再點)
| 代理類型 | 換IP週期 | 併發請求次數 | 帶寬 | 默認白名單(IP白名單數量) | 特點 |
|---|---|---|---|---|---|
| 隧道代理 Pro | 0 - 30 分鐘自定義 | 10 次/秒 | 7.5Mbps | 200 個 | 換IP週期靈活,適合長期穩定爬取(如定時爬取固定數據),白名單多,適合多機器/多環境使用。 |
| 隧道代理(每次請求換IP) | 每次請求換IP | 20 次/秒 | 10Mbps | 50 個 | 每次請求都換IP,反爬規避能力最強,適合高頻、易觸發反爬的場景,但IP切換可能增加延遲。 |
| 隧道代理(15秒換IP) | 每15秒自動換IP | 50 次/秒 | 10Mbps | 50 個 | 兼顧“IP輪換”和“請求效率”,適合中高頻爬取(如批量數據抓取),IP穩定性比“每次請求換IP”稍高。 |
可以根據以上表格以及自己的需求選擇代理。
三、代理配置
在前一步挑選完之後會進入以下界面:
其中左邊的小紅色框對應的是賬號以及密碼,在我們在程序訪問代理需要用到的。
右邊的大紅色框需要我們將自己的本機的IP或是服務器,反正運行爬蟲程序的公網IP加入白名單。
服務器好說,本機的話很多朋友不知道如何查看自己本機的公網IP,具體步驟如下:
打開命令提示符CMD,輸入以下命令即可:
curl ipinfo.io
在輸出的內容裡面,紅色框起來的就是我們的公網IP
設置成功之後界面如上圖所示。
四、代理應用例程
我們先來解讀一下官方給的例程:
#!/usr/bin/env Python
# -*- coding: utf-8 -*-
import requests
# 隧道域名:端口號
tunnel = "XXXX"
# 用戶名密碼方式
username = "XXXX"
password = "XXXX"
proxies = {
"http": "http://%(user)s:%(pwd)s@%(proxy)s/" % {"user": username, "pwd": password, "proxy": tunnel},
"https": "http://%(user)s:%(pwd)s@%(proxy)s/" % {"user": username, "pwd": password, "proxy": tunnel}
}
# 白名單方式(需提前設置白名單)
# proxies = {
# "http": "http://%(proxy)s/" % {"proxy": tunnel},
# "https": "http://%(proxy)s/" % {"proxy": tunnel}
# }
# 要訪問的目標網頁
target_url = "https://dev.kdlapi.com/testproxy"
# 使用隧道域名發送請求
response = requests.get(target_url, proxies=proxies)
# 獲取頁面內容
if response.status_code == 200:
print(response.text) # 請勿使用keep-alive複用連接(會導致隧道不能切換IP)
其中 proxies 字典用於配置 HTTP 和 HTTPS 請求的代理服務器信息,讓請求通過指定的代理隧道進行發送
很簡單的一個代碼,和我們正常使用的Request程序相比起來只是多加了一個proxies的參數罷了,說明Request內部已經幫我們集成的很好了,我們只需要像例程一樣正確傳入代理信息既可。
這邊補充一個·代理有效性檢驗的代碼,不論是免費代理還是付費代理,在使用前最好都先進性有效性檢驗:
import requests
def check_proxy(proxy):
"""驗證代理是否有效(測試能否訪問目標網站)"""
test_url = "https://api.cntv.cn/NewVideo/getVideoListByColumn?id=TOPC1451558496100826&bd=20240101"
try:
response = requests.get(
test_url,
proxies=proxy,
verify=False,
timeout=5 # 短超時,快速判斷
)
# 若能正常返回200狀態碼,且響應包含目標字段(如"id"),則代理有效
return response.status_code == 200 and "id" in response.text
except Exception as e:
return False
# 測試代理列表
proxy_list = [
{"http": "http://123.123.123.123:8080", "https": "http://123.123.123.123:8080"},
{"http": "http://124.124.124.124:8080", "https": "http://124.124.124.124:8080"}
]
# 篩選有效代理
valid_proxies = [p for p in proxy_list if check_proxy(p)]
print(f"有效代理數量:{len(valid_proxies)}/{len(proxy_list)}")
if valid_proxies:
print("第一個有效代理:", valid_proxies[0])
五、實戰案例:代理在央視節目爬蟲中的完整實現
博主研究這個代理的原因就是最近在爬取央視節目的節目編號信息,需要收集目標欄目的所有信息,但是由於央視頻網頁架構的限制,節目ID並不能批量獲取,相當於每獲取一個ID就必須訪問一次網頁,也就是因為如此高頻率的訪問導致我自己的ip一下子就被封禁了,所以開始研究代理這一塊內容,央視頻的節目信息爬取之後有時間會再出一期博客仔細講解,也算是比較有意思的。
代理知識點都在前面講過了,值得一提的是為了加快爬取速度,我的代碼裡面也採用了異步的架構,對於異步同步這一塊的內容,博主打算在下一篇博客介紹,屆時會將鏈接附在這篇博客裡面,這邊我們先直接看代碼與最終效果。由於爬蟲代碼較為敏感,這邊就不給出完整代碼了
如果有特殊需求現需要完整代碼的話可以私信我獲取完整代碼
代碼運行效果如下:
糾正一個地方,這邊的ZDCJ對應的節目應該是正點財經而非正點採集,TTKX對應的是體壇快訊而非天天快訊
部分結果文件截圖如下:
如果有特殊需求現需要完整代碼的話可以私信我獲取完整代碼
總結
本文圍繞 “爬蟲抗 IP 封禁” 核心需求,從理論到實踐拆解了代理的應用邏輯:先明確代理作為 “中間服務器” 的本質,通過 IP 偽裝解決高頻爬取中的封禁痛點;再結合匿名度、協議、來源等維度,釐清不同代理的適用場景(如高匿名 HTTPS 代理適配央視等嚴格反爬場景,動態隧道代理滿足高頻切換需求);隨後以快代理為例,提供了從免費試用、白名單配置到公網 IP 查詢的落地步驟;最後通過代理有效性校驗代碼和央視節目爬蟲實戰,驗證了 “代理 + requests” 的簡單集成邏輯 —— 僅需配置proxies字典,即可讓爬蟲通過中間服務器轉發請求,規避真實 IP 暴露風險。
Crawler Column: Anti-Ban in Practice — Proxies Explained End-to-End, with a CCTV Program Scraper Case Study
Proxy fundamentals, Kuaidaili tunnel setup, requests integration, validity checks, and a CCTV program crawler case for beating IP bans at scale.
Captured at (local ISO): 2026-05-18 05:16:58
Preface
In web scraping, IP bans are unavoidable. Take CCTV program data: APIs throttle hard per IP. If you hammer them from one address, within a minute you often see 403 (forbidden) or 429 (too many requests)—and the crawl dies.
A proxy is an IP-switching tool: requests go through an intermediary so the target sees the proxy’s IP, not yours—reducing ban risk. Using a runnable CCTV-style scraper I wrote as context, this post walks from how proxies work and where to get them to how they land in code, so you can build a more ban-resistant crawler.
I. What is a proxy?
A proxy is a server between your client and the origin. The flow looks like this:
That path hides your real IP—the site only sees the proxy egress.
Typical uses:
- Avoid IP blocks: Rotate IPs under high QPS so one address is not burned.
- Bypass region locks: Some content is geo-gated; use an egress in the right region.
- Stability: Some providers load-balance across nodes, reducing single-point failures.
Proxies can be grouped along four axes:
| Dimension | Type | Traits | When to use |
|---|---|---|---|
| Anonymity | Transparent | Origin can see both proxy and real IP | Testing only |
| Anonymous | Origin sees proxy IP, not the real one | Everyday anti-scrape | |
| High-anonymity | Origin cannot tell the path is proxied | Strict sites (e.g., CCTV, e-commerce) | |
| Protocol | HTTP | No TLS on the tunnel—easy to intercept or tamper | Legacy HTTP-only sites |
| HTTPS | TLS to origin; often backward-compatible with HTTP; certificate checks; fits browsers and modern scrapers | Most HTTPS sites; sensitive data; browser-like traffic; strict HTTPS-only policies | |
| SOCKS5 | TCP/UDP, no app-layer parsing—flexible | P2P, mail clients, firewall punch-through | |
| Source | Free | $0, flaky, short-lived, leakage risk | Tests, low rate |
| Paid | Stable, long sessions, support, sometimes dedicated tunnels | Production, high rate | |
| Mode | Static | Fixed IP, manual rotation—predictable blocking | Small / infrequent jobs |
| Dynamic (tunnel) | One endpoint, many egress IPs, auto rotation—lower ban odds, easier ops | High rate / scale (this article’s pattern) |
II. How to get proxies
I used a free trial from a commercial provider—fine for a short, heavy burst; not for always-on jobs. Flow:
- Open 快代理 (Kuaidaili).
- Log in / register, then start a free trial from the homepage.
- Pick tunnel proxy Pro one-day trial.
- Choose one of three tunnel products—different rotation, concurrency, and bandwidth (all selectable; I picked the highest per-request concurrency for speed—the UI shown is already committed so buttons look disabled).
| Product | IP rotation | Concurrency | Bandwidth | Default IP whitelist slots | Notes |
|---|---|---|---|---|---|
| Tunnel Pro | 0–30 min configurable | 10 req/s | 7.5 Mbps | 200 | Flexible rotation; good for steady jobs; many whitelist slots for multi-machine setups. |
| Tunnel (per request) | New IP every request | 20 req/s | 10 Mbps | 50 | Strongest anti-ban; more latency churn. |
| Tunnel (15 s) | Auto rotate every 15 s | 50 req/s | 10 Mbps | 50 | Middle ground for medium/high rate; IPs a bit stickier than “every request.” |
Pick based on the table and your workload.
III. How to configure a proxy
After checkout you’ll see a dashboard like this:
The small red box is username/password for programmatic access.
The large red box is IP whitelist: add your laptop or server’s public IP—the host that runs the crawler.
On a home PC, people often don’t know their public IP. From CMD:
curl ipinfo.io
In the output, the highlighted block is your public IP.
After saving, the panel should look like the screenshot above.
IV. Example usage
First, the vendor’s minimal example:
#!/usr/bin/env Python
# -*- coding: utf-8 -*-
import requests
# 隧道域名:端口号
tunnel = "XXXX"
# 用户名密码方式
username = "XXXX"
password = "XXXX"
proxies = {
"http": "http://%(user)s:%(pwd)s@%(proxy)s/" % {"user": username, "pwd": password, "proxy": tunnel},
"https": "http://%(user)s:%(pwd)s@%(proxy)s/" % {"user": username, "pwd": password, "proxy": tunnel}
}
# 白名单方式(需提前设置白名单)
# proxies = {
# "http": "http://%(proxy)s/" % {"proxy": tunnel},
# "https": "http://%(proxy)s/" % {"proxy": tunnel}
# }
# 要访问的目标网页
target_url = "https://dev.kdlapi.com/testproxy"
# 使用隧道域名发送请求
response = requests.get(target_url, proxies=proxies)
# 获取页面内容
if response.status_code == 200:
print(response.text) # 请勿使用keep-alive复用连接(会导致隧道不能切换IP)
The proxies dict tells requests to route HTTP/HTTPS via your tunnel. Compared to normal requests, you only add proxies=—the library already integrates cleanly.
A quick health check before production (works for free or paid lists):
import requests
def check_proxy(proxy):
"""验证代理是否有效(测试能否访问目标网站)"""
test_url = "https://api.cntv.cn/NewVideo/getVideoListByColumn?id=TOPC1451558496100826&bd=20240101"
try:
response = requests.get(
test_url,
proxies=proxy,
verify=False,
timeout=5 # 短超时,快速判断
)
# 若能正常返回200状态码,且响应包含目标字段(如"id"),则代理有效
return response.status_code == 200 and "id" in response.text
except Exception as e:
return False
# 测试代理列表
proxy_list = [
{"http": "http://123.123.123.123:8080", "https": "http://123.123.123.123:8080"},
{"http": "http://124.124.124.124:8080", "https": "http://124.124.124.124:8080"}
]
# 筛选有效代理
valid_proxies = [p for p in proxy_list if check_proxy(p)]
print(f"有效代理数量:{len(valid_proxies)}/{len(proxy_list)}")
if valid_proxies:
print("第一个有效代理:", valid_proxies[0])
V. Case study: proxies in a CCTV program crawler
I dug into proxies while collecting CCTV program IDs. Yangshipin’s layout forces one page hit per ID—brutal QPS—so my home IP got blocked fast. A follow-up post may deep-dive the Yangshipin scrape; here we focus on proxies.
Everything above applies. For speed I also used async I/O (another post—link TBD). Full source is sensitive, so it’s truncated here.
If you need the complete script, message me privately.
Runtime:
Correction: ZDCJ maps to 正点财经 (On the Hour: Finance), not “正点采集”; TTKX is 体坛快讯 (Sports Flash), not “天天快讯.”
Sample output files:
If you need the complete script, message me privately.
Conclusion
Centered on anti-IP-ban scraping, this article wired theory to practice: proxies as middleboxes that mask your IP; a taxonomy by anonymity, protocol, sourcing, and static vs dynamic; a Kuaidaili trial path from signup through whitelist + public IP lookup; and validation plus a CCTV-oriented case proving proxies + requests is enough to steer traffic away from your real address.