机器学习专栏:Python实现随机森林预测
介绍随机森林原理(Bootstrap、特征子空间、集成投票),并以加州房价数据集演示 sklearn 训练、MSE/MAE/R² 评估、特征重要性与 joblib 模型保存调用。
前言
在机器学习领域,随机森林(Random Forest)因其卓越的预测性能和广泛的应用场景,成为数据科学家和算法工程师的“工具箱常客”。作为集成学习的经典算法,它通过构建多棵决策树并融合结果,有效平衡了模型的准确性与泛化能力,被广泛应用于金融风控、医疗诊断、环境预测等复杂场景
一、随机森林介绍
随机森林是一种基于集成学习思想的机器学习模型,通过组合多棵决策树的预测结果提升整体模型的准确性和泛化能力。其核心设计包含双重随机性与集体决策机制,以下是原理的深度解析:
1.核心设计思想
随机森林通过以下两个关键随机性实现模型多样性:
数据随机性(Bootstrap抽样)
每棵决策树从原始训练集中有放回地随机抽取N个样本(N为原始数据集大小),形成差异化的训练子集。未被抽中的约36.8%样本称为袋外数据(OOB),可用于评估模型泛化误差。
特征随机性(随机子空间)
在每棵树的节点分裂时,仅从全部M个特征中随机选择m个候选特征(m值通常采用如下式子 )
m
M 或 m
log 2 M m = \sqrt{M} \quad \text{或} \quad m = \log_2 M m=M 或m=log2M
从中选择最优分裂方式。这种设计打破特征间的强相关性,增强模型鲁棒性
2. 算法构建流程
随机森林的构建过程可分为以下步骤:
生成Bootstrap样本
通过有放回抽样为每棵树生成独立训练集。
递归构建决策树
对每个节点随机选择m个特征子集;
基于基尼指数(分类)或均方误差(回归)选择最优分裂点;
完全生长不剪枝,依赖随机性抑制过拟合
集成预测结果
分类任务:通过多数投票法(众数)确定最终类别;
回归任务:取所有树预测值的平均值
原理图如下:
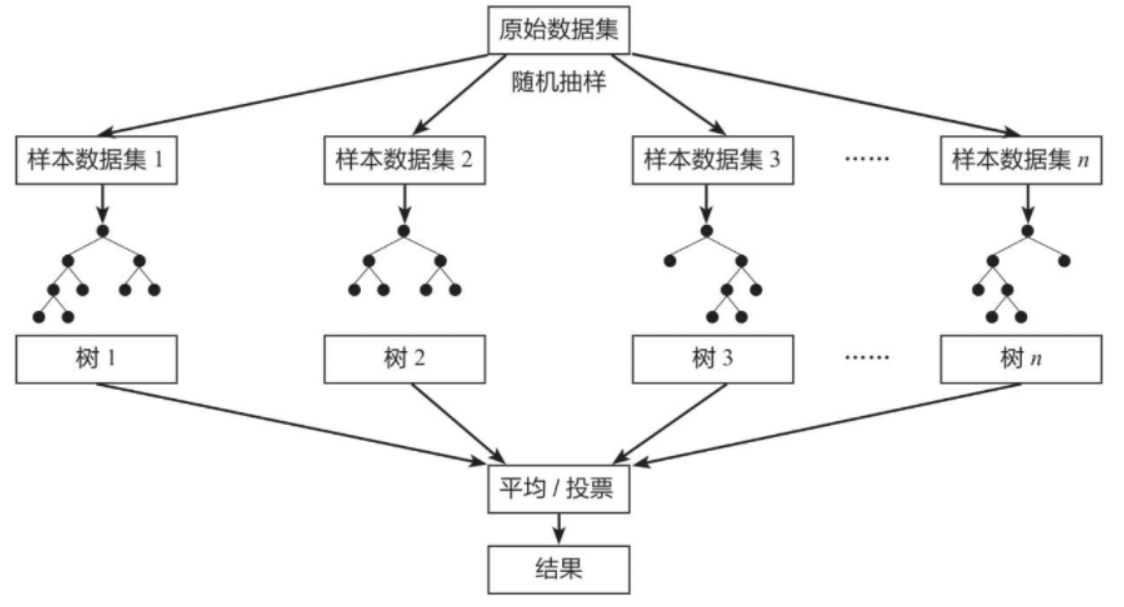
3.数学原理与误差控制
偏差-方差分解
随机森林的总误差可分解为单棵树偏差、方差与噪声之和。通过集成多棵低相关性的树,显著降低方差项。
Var ∝ 单棵树方差 n \text{Var} \propto \frac{\text{单棵树方差}}{n} Var∝n单棵树方差
特征重要性评估
基于OOB误差或分裂时的基尼指数减少量,量化特征对预测的贡献度,支持可解释性分析
4. 核心优势与适用场景
优势
抗过拟合能力强,适合高维数据(如基因表达、图像特征),且可以自动处理缺失值与非平衡数据,支持并行计算
局限性
对高稀疏数据(如文本)效果有限;模型解释性弱于单棵决策树
二、Python实现
1.引入库
代码如下(示例):
from sklearn.datasets import fetch_california_housing # 加载加州房价数据集
from sklearn.ensemble import RandomForestRegressor # 用于构建随机森林回归模型
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score # 用于计算均方误差、平均绝对误差、绝对系数
from sklearn.model_selection import train_test_split # 用于将数据集随机划分为训练集和测试集
import joblib # 用于模型持久化(保存/加载)和高效计算。
import numpy as np # 科学计算基础库
2.构建模型
代码如下(示例):
class HousingPricePredictor:
def __init__(self, n_estimators=100, max_depth=None, random_state=42):
"""初始化随机森林回归模型"""
self.n_estimators = n_estimators # 决策树数量
self.max_depth = max_depth # 树深
self.random_state = random_state # 随机性
self.model = RandomForestRegressor(
n_estimators=self.n_estimators,
max_depth=self.max_depth,
random_state=self.random_state
)
self.feature_names = None # 新增特征名称存储
核心参数详解:
| 参数 | 作用 | 调优建议 |
|---|---|---|
| n_estimators | 控制决策树数量,增加树可提升模型稳定性(默认100) | 通常设置100-500,超过阈值后收益递减 |
| max_depth | 限制树深防止过拟合,None表示不限制 | 推荐从3开始逐步增加测试效果 |
| random_state | 固定随机性,确保实验可复现 | 调试阶段必设,生产环境可取消 |
其他可设置的重要参数:
| 参数 | 作用 |
|---|---|
| criterion=‘squared_error’ | 默认使用均方误差作为分裂标准 |
| min_samples_split=2 | 内部节点分裂所需最小样本数 |
| max_features=‘auto’ | 分裂时考虑的最大特征数(默认为√n) |
3.导入数据
代码如下(示例):
def load_data(self):
"""加载房价数据并拆分为训练集和测试集"""
data = fetch_california_housing()
self.feature_names = data.feature_names # 存储特征名称
X_train, X_test, y_train, y_test = train_test_split(
data.data, data.target,
test_size=0.3,
random_state=self.random_state
)
return X_train, X_test, y_train, y_test
train方法通过fit()函数使用训练集数据(X_train特征矩阵和y_train目标值)训练预定义的随机森林回归模型,完成多棵决策树的集成学习;
| 参数 | 作用 | 默认值 | 示例值 |
|---|---|---|---|
| data.data | 特征矩阵(20640行×8列) | - | 每个样本包含8 |
| data.target | 目标变量(房价中位数) | - | 数值范围0.15-5.0(单位:10万美元) |
| test_size | 测试集比例 | 0.25 | 0.3表示30%数据作为测试集(约6192个样本) |
| random_state | 随机种子 | None | 42确保每次划分结果一致 |
| shuffle | 是否打乱数据 | True | 默认启用 保证数据随机性 |
| stratify | 分层抽样依据 | None | 常用于分类任务的类别平衡 |
数据流示例:
原始数据集(20640个样本)
train_test_split分割
├── 训练集:14448个样本(70%)
└── 测试集:6192个样本(30%)
4.模型的训练与评估
代码如下(示例):
def train(self, X_train, y_train):
"""训练模型并输出训练过程数据"""
self.model.fit(X_train, y_train)
def evaluate(self, X_test, y_test):
"""评估模型性能并输出详细结果"""
predictions = self.model.predict(X_test)
# 新增多项评估指标
mse = mean_squared_error(y_test, predictions)
mae = mean_absolute_error(y_test, predictions)
r2 = r2_score(y_test, predictions)
print("\n=== 模型验证结果 ===")
print(f"测试集样本数量: {len(X_test)}")
print(f"均方误差(MSE): {mse:.2f}")
print(f"平均绝对误差(MAE): {mae:.2f}")
print(f"决定系数(R²): {r2:.2f}")
return mse
evaluate方法则通过predict()对测试集(X_test)进行房价预测,并计算均方误差(MSE)、平均绝对误差(MAE)、决定系数(R²)三项核心指标。其具体意义如下:
| 评估指标 | 数学公式 | 核心特点 |
|---|---|---|
| MSE | 1 n ∑ i = 1 n ( y i − y i ^ ) 2 \frac{1}{n}\sum_{i=1}^{n}(y_i - \hat{y_i})^2 n1i=1∑n(yi−yi^)2 | 放大异常误差影响,单位与目标变量平方一致 |
| MAE | 1 n ∑ i = 1 n ∣ y i − y i ^ ∣ \frac{1}{n}\sum_{i=1}^{n} | y_i - \hat{y_i} |
| R² | 1 − ∑ i = 1 n ( y i − y i ^ ) 2 ∑ i = 1 n ( y i − y ˉ ) 2 1 - \frac{\sum_{i=1}^{n}(y_i - \hat{y_i})^2}{\sum_{i=1}^{n}(y_i - \bar{y})^2} 1−∑i=1n(yi−yˉ)2∑i=1n(yi−yi^)2 | 解释模型对数据变异的捕获能力,无量纲 |
5.模型持久化(模型保存)
def save_model(self, filename="rf_model.pkl"):
"""保存模型到本地"""
joblib.dump(self.model, filename)
print(f"\n=== 模型已保存至 {filename} ===")
通过joblib.dump()方法将训练完成的随机森林模型(self.model)序列化并保存到本地文件,默认存储为当前目录下的rf_model.pkl文件
6.显示特征重要性
def show_feature_importance(self):
"""显示特征重要性"""
if self.feature_names is None:
return
importances = self.model.feature_importances_
indices = np.argsort(importances)[::-1]
print("\n=== 特征重要性排序 ===")
for idx in indices:
print(f"{self.feature_names[idx]:<10} {importances[idx]:.4f}")
该段代码对特征重要性进行降序排列生成索引序列,最后通过格式化字符串循环输出特征名称及其重要性值,实现关键特征的贡献度排序展示,为特征选择与模型可解释性分析提供量化依据
7.完整代码
from sklearn.datasets import fetch_california_housing
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
from sklearn.model_selection import train_test_split
import joblib
import numpy as np
class HousingPricePredictor:
def __init__(self, n_estimators=100, max_depth=None, random_state=42):
"""初始化随机森林回归模型"""
self.n_estimators = n_estimators
self.max_depth = max_depth
self.random_state = random_state
self.model = RandomForestRegressor(
n_estimators=self.n_estimators,
max_depth=self.max_depth,
random_state=self.random_state
)
self.feature_names = None # 新增特征名称存储
def load_data(self):
"""加载房价数据并拆分为训练集和测试集"""
data = fetch_california_housing()
self.feature_names = data.feature_names # 存储特征名称
X_train, X_test, y_train, y_test = train_test_split(
data.data, data.target,
test_size=0.3,
random_state=self.random_state
)
return X_train, X_test, y_train, y_test
def train(self, X_train, y_train):
"""训练模型并输出训练过程数据"""
self.model.fit(X_train, y_train)
def evaluate(self, X_test, y_test):
"""评估模型性能并输出详细结果"""
predictions = self.model.predict(X_test)
# 新增多项评估指标
mse = mean_squared_error(y_test, predictions)
mae = mean_absolute_error(y_test, predictions)
r2 = r2_score(y_test, predictions)
print("\n=== 模型验证结果 ===")
print(f"测试集样本数量: {len(X_test)}")
print(f"均方误差(MSE): {mse:.2f}")
print(f"平均绝对误差(MAE): {mae:.2f}")
print(f"决定系数(R²): {r2:.2f}")
return mse
def save_model(self, filename="rf_model.pkl"):
"""保存模型到本地"""
joblib.dump(self.model, filename)
print(f"\n=== 模型已保存至 {filename} ===")
def show_feature_importance(self):
"""显示特征重要性"""
if self.feature_names is None:
return
importances = self.model.feature_importances_
indices = np.argsort(importances)[::-1]
print("\n=== 特征重要性排序 ===")
for idx in indices:
print(f"{self.feature_names[idx]:<10} {importances[idx]:.4f}")
if __name__ == "__main__":
predictor = HousingPricePredictor(n_estimators=100, max_depth=10)
X_train, X_test, y_train, y_test = predictor.load_data()
# 训练流程
predictor.train(X_train, y_train)
# 评估流程
mse = predictor.evaluate(X_test, y_test)
predictor.show_feature_importance()
predictor.save_model()
运行结果

8.模型调用
def predict_new_data(model_path="rf_model.pkl"):
"""加载已保存模型进行新数据预测"""
# 加载训练好的模型
loaded_model = joblib.load(model_path)
# 获取特征名称(需与训练时一致)
data = fetch_california_housing()
feature_names = data.feature_names
# 构造新样本数据(示例数据)
new_samples = np.array([
[3.8462, 52.0, 5.323529, 1.083333, 565.0, 2.194444, 37.85, -122.25], # 示例1
[2.5769, 25.0, 3.846154, 0.961538, 322.0, 2.555556, 34.05, -118.24] # 示例2
])
# 执行预测
predictions = loaded_model.predict(new_samples)
# 输出带特征解释的预测结果
print("\n=== 新数据预测结果 ===")
for i, (sample, pred) in enumerate(zip(new_samples, predictions)):
print(f"\n样本{i + 1}特征明细:")
for name, value in zip(feature_names, sample):
print(f"{name:<15}: {value:.4f}")
print(f"预测房价: ${pred * 100000:.2f}") # 假设目标变量单位是10万美元
if __name__ == "__main__":
predict_new_data()
运行结果

总结
随机森林凭借其独特的双重随机性(数据Bootstrap抽样与特征子集选择)和集成学习机制,在机器学习领域展现出强大的预测能力与稳定性。通过构建多棵低相关性的决策树并融合结果,该算法有效平衡了模型的准确性与泛化能力,尤其适用于高维数据、非平衡数据集等复杂场景。本文以加州房价预测为案例,完整演示了从数据加载、模型训练到评估优化的全流程。引用时只需要改输入数据集以及训练参数既可、
機器學習專欄:Python實現隨機森林預測
介紹隨機森林原理(Bootstrap、特徵子空間、集成投票),並以加州房價資料集演示 sklearn 訓練、MSE/MAE/R² 評估、特徵重要性與 joblib 模型保存調用。
來源:https://blog.csdn.net/2403_87969572/article/details/147945672
抓取時間(ISO本地):2026-05-18 05:17:01
文章目錄
前言
在機器學習領域,隨機森林(Random Forest)因其卓越的預測性能和廣泛的應用場景,成為數據科學家和算法工程師的“工具箱常客”。作為集成學習的經典算法,它通過構建多棵決策樹並融合結果,有效平衡了模型的準確性與泛化能力,被廣泛應用於金融風控、醫療診斷、環境預測等複雜場景
一、隨機森林介紹
隨機森林是一種基於集成學習思想的機器學習模型,通過組合多棵決策樹的預測結果提升整體模型的準確性和泛化能力。其核心設計包含雙重隨機性與集體決策機制,以下是原理的深度解析:
1.核心設計思想
隨機森林通過以下兩個關鍵隨機性實現模型多樣性:
數據隨機性(Bootstrap抽樣)
每棵決策樹從原始訓練集中有放回地隨機抽取N個樣本(N為原始數據集大小),形成差異化的訓練子集。未被抽中的約36.8%樣本稱為袋外數據(OOB),可用於評估模型泛化誤差。
特徵隨機性(隨機子空間)
在每棵樹的節點分裂時,僅從全部M個特徵中隨機選擇m個候選特徵(m值通常採用如下式子 )
m
M 或 m
log 2 M m = \sqrt{M} \quad \text{或} \quad m = \log_2 M m=M 或m=log2M
從中選擇最優分裂方式。這種設計打破特徵間的強相關性,增強模型魯棒性
2. 算法構建流程
隨機森林的構建過程可分為以下步驟:
生成Bootstrap樣本
通過有放回抽樣為每棵樹生成獨立訓練集。
遞歸構建決策樹
對每個節點隨機選擇m個特徵子集;
基於基尼指數(分類)或均方誤差(迴歸)選擇最優分裂點;
完全生長不剪枝,依賴隨機性抑制過擬合
集成預測結果
分類任務:通過多數投票法(眾數)確定最終類別;
迴歸任務:取所有樹預測值的平均值
原理圖如下:
3.數學原理與誤差控制
偏差-方差分解
隨機森林的總誤差可分解為單棵樹偏差、方差與噪聲之和。通過集成多棵低相關性的樹,顯著降低方差項。
Var ∝ 單棵樹方差 n \text{Var} \propto \frac{\text{單棵樹方差}}{n} Var∝n單棵樹方差
特徵重要性評估
基於OOB誤差或分裂時的基尼指數減少量,量化特徵對預測的貢獻度,支持可解釋性分析
4. 核心優勢與適用場景
優勢
抗過擬合能力強,適合高維數據(如基因表達、圖像特徵),且可以自動處理缺失值與非平衡數據,支持並行計算
侷限性
對高稀疏數據(如文本)效果有限;模型解釋性弱於單棵決策樹
二、Python實現
1.引入庫
代碼如下(示例):
from sklearn.datasets import fetch_california_housing # 加載加州房價數據集
from sklearn.ensemble import RandomForestRegressor # 用於構建隨機森林迴歸模型
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score # 用於計算均方誤差、平均絕對誤差、絕對係數
from sklearn.model_selection import train_test_split # 用於將數據集隨機劃分為訓練集和測試集
import joblib # 用於模型持久化(保存/加載)和高效計算。
import numpy as np # 科學計算基礎庫
2.構建模型
代碼如下(示例):
class HousingPricePredictor:
def __init__(self, n_estimators=100, max_depth=None, random_state=42):
"""初始化隨機森林迴歸模型"""
self.n_estimators = n_estimators # 決策樹數量
self.max_depth = max_depth # 樹深
self.random_state = random_state # 隨機性
self.model = RandomForestRegressor(
n_estimators=self.n_estimators,
max_depth=self.max_depth,
random_state=self.random_state
)
self.feature_names = None # 新增特徵名稱存儲
核心參數詳解:
| 參數 | 作用 | 調優建議 |
|---|---|---|
| n_estimators | 控制決策樹數量,增加樹可提升模型穩定性(默認100) | 通常設置100-500,超過閾值後收益遞減 |
| max_depth | 限制樹深防止過擬合,None表示不限制 | 推薦從3開始逐步增加測試效果 |
| random_state | 固定隨機性,確保實驗可復現 | 調試階段必設,生產環境可取消 |
其他可設置的重要參數:
| 參數 | 作用 |
|---|---|
| criterion=‘squared_error’ | 默認使用均方誤差作為分裂標準 |
| min_samples_split=2 | 內部節點分裂所需最小樣本數 |
| max_features=‘auto’ | 分裂時考慮的最大特徵數(默認為√n) |
3.導入數據
代碼如下(示例):
def load_data(self):
"""加載房價數據並拆分為訓練集和測試集"""
data = fetch_california_housing()
self.feature_names = data.feature_names # 存儲特徵名稱
X_train, X_test, y_train, y_test = train_test_split(
data.data, data.target,
test_size=0.3,
random_state=self.random_state
)
return X_train, X_test, y_train, y_test
train方法通過fit()函數使用訓練集數據(X_train特徵矩陣和y_train目標值)訓練預定義的隨機森林迴歸模型,完成多棵決策樹的集成學習;
| 參數 | 作用 | 默認值 | 示例值 |
|---|---|---|---|
| data.data | 特徵矩陣(20640行×8列) | - | 每個樣本包含8 |
| data.target | 目標變量(房價中位數) | - | 數值範圍0.15-5.0(單位:10萬美元) |
| test_size | 測試集比例 | 0.25 | 0.3表示30%數據作為測試集(約6192個樣本) |
| random_state | 隨機種子 | None | 42確保每次劃分結果一致 |
| shuffle | 是否打亂數據 | True | 默認啟用 保證數據隨機性 |
| stratify | 分層抽樣依據 | None | 常用於分類任務的類別平衡 |
數據流示例:
原始數據集(20640個樣本)
train_test_split分割
├── 訓練集:14448個樣本(70%)
└── 測試集:6192個樣本(30%)
4.模型的訓練與評估
代碼如下(示例):
def train(self, X_train, y_train):
"""訓練模型並輸出訓練過程數據"""
self.model.fit(X_train, y_train)
def evaluate(self, X_test, y_test):
"""評估模型性能並輸出詳細結果"""
predictions = self.model.predict(X_test)
# 新增多項評估指標
mse = mean_squared_error(y_test, predictions)
mae = mean_absolute_error(y_test, predictions)
r2 = r2_score(y_test, predictions)
print("\n=== 模型驗證結果 ===")
print(f"測試集樣本數量: {len(X_test)}")
print(f"均方誤差(MSE): {mse:.2f}")
print(f"平均絕對誤差(MAE): {mae:.2f}")
print(f"決定係數(R²): {r2:.2f}")
return mse
evaluate方法則通過predict()對測試集(X_test)進行房價預測,並計算均方誤差(MSE)、平均絕對誤差(MAE)、決定係數(R²)三項核心指標。其具體意義如下:
| 評估指標 | 數學公式 | 核心特點 |
|---|---|---|
| MSE | 1 n ∑ i = 1 n ( y i − y i ^ ) 2 \frac{1}{n}\sum_{i=1}^{n}(y_i - \hat{y_i})^2 n1i=1∑n(yi−yi^)2 | 放大異常誤差影響,單位與目標變量平方一致 |
| MAE | 1 n ∑ i = 1 n ∣ y i − y i ^ ∣ \frac{1}{n}\sum_{i=1}^{n} | y_i - \hat{y_i} |
| R² | 1 − ∑ i = 1 n ( y i − y i ^ ) 2 ∑ i = 1 n ( y i − y ˉ ) 2 1 - \frac{\sum_{i=1}^{n}(y_i - \hat{y_i})^2}{\sum_{i=1}^{n}(y_i - \bar{y})^2} 1−∑i=1n(yi−yˉ)2∑i=1n(yi−yi^)2 | 解釋模型對數據變異的捕獲能力,無量綱 |
5.模型持久化(模型保存)
def save_model(self, filename="rf_model.pkl"):
"""保存模型到本地"""
joblib.dump(self.model, filename)
print(f"\n=== 模型已保存至 {filename} ===")
通過joblib.dump()方法將訓練完成的隨機森林模型(self.model)序列化並保存到本地文件,默認存儲為當前目錄下的rf_model.pkl文件
6.顯示特徵重要性
def show_feature_importance(self):
"""顯示特徵重要性"""
if self.feature_names is None:
return
importances = self.model.feature_importances_
indices = np.argsort(importances)[::-1]
print("\n=== 特徵重要性排序 ===")
for idx in indices:
print(f"{self.feature_names[idx]:<10} {importances[idx]:.4f}")
該段代碼對特徵重要性進行降序排列生成索引序列,最後通過格式化字符串循環輸出特徵名稱及其重要性值,實現關鍵特徵的貢獻度排序展示,為特徵選擇與模型可解釋性分析提供量化依據
7.完整代碼
from sklearn.datasets import fetch_california_housing
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
from sklearn.model_selection import train_test_split
import joblib
import numpy as np
class HousingPricePredictor:
def __init__(self, n_estimators=100, max_depth=None, random_state=42):
"""初始化隨機森林迴歸模型"""
self.n_estimators = n_estimators
self.max_depth = max_depth
self.random_state = random_state
self.model = RandomForestRegressor(
n_estimators=self.n_estimators,
max_depth=self.max_depth,
random_state=self.random_state
)
self.feature_names = None # 新增特徵名稱存儲
def load_data(self):
"""加載房價數據並拆分為訓練集和測試集"""
data = fetch_california_housing()
self.feature_names = data.feature_names # 存儲特徵名稱
X_train, X_test, y_train, y_test = train_test_split(
data.data, data.target,
test_size=0.3,
random_state=self.random_state
)
return X_train, X_test, y_train, y_test
def train(self, X_train, y_train):
"""訓練模型並輸出訓練過程數據"""
self.model.fit(X_train, y_train)
def evaluate(self, X_test, y_test):
"""評估模型性能並輸出詳細結果"""
predictions = self.model.predict(X_test)
# 新增多項評估指標
mse = mean_squared_error(y_test, predictions)
mae = mean_absolute_error(y_test, predictions)
r2 = r2_score(y_test, predictions)
print("\n=== 模型驗證結果 ===")
print(f"測試集樣本數量: {len(X_test)}")
print(f"均方誤差(MSE): {mse:.2f}")
print(f"平均絕對誤差(MAE): {mae:.2f}")
print(f"決定係數(R²): {r2:.2f}")
return mse
def save_model(self, filename="rf_model.pkl"):
"""保存模型到本地"""
joblib.dump(self.model, filename)
print(f"\n=== 模型已保存至 {filename} ===")
def show_feature_importance(self):
"""顯示特徵重要性"""
if self.feature_names is None:
return
importances = self.model.feature_importances_
indices = np.argsort(importances)[::-1]
print("\n=== 特徵重要性排序 ===")
for idx in indices:
print(f"{self.feature_names[idx]:<10} {importances[idx]:.4f}")
if __name__ == "__main__":
predictor = HousingPricePredictor(n_estimators=100, max_depth=10)
X_train, X_test, y_train, y_test = predictor.load_data()
# 訓練流程
predictor.train(X_train, y_train)
# 評估流程
mse = predictor.evaluate(X_test, y_test)
predictor.show_feature_importance()
predictor.save_model()
運行結果
8.模型調用
def predict_new_data(model_path="rf_model.pkl"):
"""加載已保存模型進行新數據預測"""
# 加載訓練好的模型
loaded_model = joblib.load(model_path)
# 獲取特徵名稱(需與訓練時一致)
data = fetch_california_housing()
feature_names = data.feature_names
# 構造新樣本數據(示例數據)
new_samples = np.array([
[3.8462, 52.0, 5.323529, 1.083333, 565.0, 2.194444, 37.85, -122.25], # 示例1
[2.5769, 25.0, 3.846154, 0.961538, 322.0, 2.555556, 34.05, -118.24] # 示例2
])
# 執行預測
predictions = loaded_model.predict(new_samples)
# 輸出帶特徵解釋的預測結果
print("\n=== 新數據預測結果 ===")
for i, (sample, pred) in enumerate(zip(new_samples, predictions)):
print(f"\n樣本{i + 1}特徵明細:")
for name, value in zip(feature_names, sample):
print(f"{name:<15}: {value:.4f}")
print(f"預測房價: ${pred * 100000:.2f}") # 假設目標變量單位是10萬美元
if __name__ == "__main__":
predict_new_data()
運行結果
總結
隨機森林憑藉其獨特的雙重隨機性(數據Bootstrap抽樣與特徵子集選擇)和集成學習機制,在機器學習領域展現出強大的預測能力與穩定性。通過構建多棵低相關性的決策樹並融合結果,該算法有效平衡了模型的準確性與泛化能力,尤其適用於高維數據、非平衡數據集等複雜場景。本文以加州房價預測為案例,完整演示了從數據加載、模型訓練到評估優化的全流程。引用時只需要改輸入數據集以及訓練參數既可、
Machine Learning: Random Forest Prediction in Python
Random Forest theory plus sklearn walkthrough on California housing—train, MSE/MAE/R², feature importance, and joblib save/load.
Captured at (local ISO): 2026-05-18 05:17:01
Preface
Random Forest is a staple in ML—strong accuracy and broad use in finance, healthcare, and environmental forecasting. As an ensemble method, it combines many decision trees to balance accuracy and generalization.
I. Random Forest Overview
Random Forest uses bootstrap sampling and random feature subsets at splits to decorrelate trees.
1. Core ideas
Data randomness (Bootstrap)
Each tree trains on N samples drawn with replacement from N training points; ~36.8% OOB data can estimate generalization error.
Feature randomness (random subspace)
At each split, pick m features from M (often (m=\sqrt{M}) or (\log_2 M)) to reduce correlation.
2. Training flow
- Bootstrap subsets per tree
- Grow trees fully (Gini / MSE splits, typically no pruning)
- Classification: majority vote; Regression: mean prediction
3. Error and feature importance
Variance drops as trees are averaged. Feature importance from OOB or impurity decrease.
4. Pros and limits
Pros: Robust to overfitting, handles high-dimensional and imbalanced data, parallel-friendly.
Limits: Weak on very sparse text; less interpretable than a single tree.
II. Python Implementation
1. Imports
from sklearn.datasets import fetch_california_housing
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
from sklearn.model_selection import train_test_split
import joblib
import numpy as np
2. Model class
class HousingPricePredictor:
def __init__(self, n_estimators=100, max_depth=None, random_state=42):
self.n_estimators = n_estimators
self.max_depth = max_depth
self.random_state = random_state
self.model = RandomForestRegressor(
n_estimators=self.n_estimators,
max_depth=self.max_depth,
random_state=self.random_state
)
self.feature_names = None
| Parameter | Role | Tuning |
|---|---|---|
| n_estimators | Tree count | 100–500, diminishing returns |
| max_depth | Limit depth | Start ~3, increase if underfit |
| random_state | Reproducibility | Set in experiments |
3. Data loading
def load_data(self):
data = fetch_california_housing()
self.feature_names = data.feature_names
X_train, X_test, y_train, y_test = train_test_split(
data.data, data.target,
test_size=0.3,
random_state=self.random_state
)
return X_train, X_test, y_train, y_test
20640 samples → 70% train / 30% test with random_state=42.
4. Train and evaluate
def train(self, X_train, y_train):
self.model.fit(X_train, y_train)
def evaluate(self, X_test, y_test):
predictions = self.model.predict(X_test)
mse = mean_squared_error(y_test, predictions)
mae = mean_absolute_error(y_test, predictions)
r2 = r2_score(y_test, predictions)
print("\n=== Validation ===")
print(f"Test samples: {len(X_test)}")
print(f"MSE: {mse:.2f}")
print(f"MAE: {mae:.2f}")
print(f"R²: {r2:.2f}")
return mse
5. Save model
def save_model(self, filename="rf_model.pkl"):
joblib.dump(self.model, filename)
print(f"\n=== Saved to {filename} ===")
6. Feature importance
def show_feature_importance(self):
if self.feature_names is None:
return
importances = self.model.feature_importances_
indices = np.argsort(importances)[::-1]
print("\n=== Feature importance ===")
for idx in indices:
print(f"{self.feature_names[idx]:<10} {importances[idx]:.4f}")
7. Full script
(Same structure as Chinese content.md—HousingPricePredictor with n_estimators=100, max_depth=10, train/eval/save.)
8. Inference
def predict_new_data(model_path="rf_model.pkl"):
loaded_model = joblib.load(model_path)
data = fetch_california_housing()
feature_names = data.feature_names
new_samples = np.array([
[3.8462, 52.0, 5.323529, 1.083333, 565.0, 2.194444, 37.85, -122.25],
[2.5769, 25.0, 3.846154, 0.961538, 322.0, 2.555556, 34.05, -118.24]
])
predictions = loaded_model.predict(new_samples)
print("\n=== Predictions ===")
for i, (sample, pred) in enumerate(zip(new_samples, predictions)):
print(f"\nSample {i+1}:")
for name, value in zip(feature_names, sample):
print(f"{name:<15}: {value:.4f}")
print(f"Predicted price: ${pred * 100000:.2f}")
Summary
Random Forest’s bootstrap + feature randomness yields stable ensembles for structured data. This California housing walkthrough covers load, train, MSE/MAE/R², importance, and joblib persistence—swap dataset and hyperparameters for your task.